
Информации на тему микросервисной архитектуры приложений, успевшей уже набить оскомину, сегодня вполне достаточно для того, чтобы определиться, подходит она вашему продукту или нет. И совершенно не секрет, что компаниям, решившим выбрать этот путь, предстоит принять множество инженерных и культурных вызовов. Одним из источников проблем является множащийся всюду оверхед, и это в равной степени касается и рутины, связанной с производственными процессами.

Как можно догадаться, Антиплагиат – как раз такая компания, где постепенно пришло понимание, что нам с микросервисами по пути. Но прежде чем начать есть кактус, мы решили его почистить и приготовить. А так как все единственно верные и правильные решения для каждого уникальны, то вместо универсальных DevOps-слайдов с красивыми стрелками мы решили просто поделиться собственным опытом и рассказать, как мы уже прошли немалую часть нашего особого пути к, я надеюсь, успеху.
Если вы делаете действительно уникальный продукт, вдоль и поперек состоящий из ноу-хау, увернуться от этого особого пути шансов почти нет, ведь формируется он из многих частных: начиная от сложившейся в компании культуры и исторических данностей, заканчивая собственной его спецификой и используемым технологическим стеком.
Одним из задач для любой компании и команды является поиск оптимального баланса между свободами и правилами, а микросервисы выводят эту проблему на новый уровень. Это может казаться противоречием самой идее микросервисов, которая предполагает широкую свободу в выборе технологий, но если не фокусироваться на непосредственно архитектурных и технологических вопросах, а посмотреть на проблемы производства в целом, то риск оказаться где-то в сюжете «Сада земных наслаждений» вполне ощутим.
Впрочем, в книге «Создание микросервисов» Сэм Ньюмэн предлагает решение этой проблемы, где буквально с первых страниц говорит о необходимости ограничить творчество команд рамками технических соглашений. Так одним из ключей успеха, особенно в условиях ограниченности ресурса свободных рук, становится стандартизация всего того, о чем только получится договориться и чем бы никто на самом деле не хотел бы постоянно заниматься. Вырабатывая соглашения, мы создаем ясные правила игры для всех участников процесса производства и эксплуатации компонентов системы. А зная правила игры, согласитесь, играть в нее должно быть проще и даже приятнее. Однако, само следование этим правилам может превратиться в рутину и доставлять участникам дискомфорт, что прямо ведет ко всевозможным отступлениям от них и, как следствие, несостоятельности всей идеи. И самым очевидным выходом будет поместить все соглашения в код, ведь ни одному регламенту не под силу то, что может автоматизация и удобные инструменты, использование которых интуитивно и естественно.
Двигаясь в этом направлении, нам удавалось автоматизировать все больше и больше, и тем сильнее наш процесс становился похоже на end-to-end конвейер по производству библиотек и микро(или не очень)сервисов.
— Разработка в компании в 90% случаев ведется на C#;
— Не было необходимости начинать с нуля, часть принятых стандартов, подходов и технологий – это — результат накопленного опыта или просто историческое наследие;
— Репозиториев с .NET проектами, в отличии от команд, десятки (и будет все больше);
— Нам нравится использовать очень простой CI-пайплайн, максимально избегая vendor lock-in;
— У рядового .NET разработчика слова «контейнер», «докер» и «линукс» все еще могут вызывать приступы легкого экзистенциального ужаса, а ломать через колено никого не хочется.
Немного предыстории
Весной 2017-го компания Microsoft представила миру превью .NET Core 2.0, и этот год C#-астрологи сразу же поспешили объявить Годом Linux, поэтому…

Некоторое время мы, не доверяя магии, собирали и тестировали все и в Windows, и в Linux, публиковали артефакты какими-то скриптами по SSH, пытались настраивать старые CI/CD пайплайны в режиме швейцарского ножа. Но спустя некоторое время поняли, что делаем что-то не то. К тому же, все чаще вокруг зазвучали упоминания микросервисов и контейнеров. Так и мы решили тоже оседлать волну хайпа и поисследовать эти направления.
Уже на стадии размышлений о нашем возможном микросервисном будущем возник ряд вопросов, игнорируя которые, мы рисковали столкнуться в этом самом будущем с новыми проблемами, которые создали бы себе сами взамен решенных.
Во-первых, при взгляде со стороны эксплуатации на теоретический микросервисный мир без правил нас пугала перспектива хаоса со всеми вытекающими последствиями, включая не только непредсказуемое качество результата, но и конфликты между командами или разработчиками и инженерами. А пытаться давать какие-то рекомендации, не имея возможности обеспечить контроль их соблюдения, сразу выглядело пустой затеей.
Во-вторых, никто толком не знал, как правильно делать контейнеры и писать докерфайлы, которые, тем не менее, уже начали бодро селиться в наших репозиториях. К тому же, многие «где-то читали», что там не все так просто. А значит, кто-то должен был нырнуть поглубже и разобраться, вернувшись потом с лучшими практиками контейнерной сборки. Но перспектива занять роль штатного docker-упаковщика, оставшись наедине со штабелями докерфайлов, почему-то никого в компании не воодушевляла. К тому же, как выяснилось, нырнуть один раз явно недостаточно, и даже выглядящее на первый взгляд хорошим и правильным может оказаться ошибочным или просто не очень хорошим.
И в-третьих, хотелось уверенности, что получаемые образы с сервисами будут не только правильными с точки зрения контейнерных практик, но и окажутся предсказуемыми в своем поведении и будут обладать всеми необходимыми свойствами и атрибутами для упрощения контроля запускаемых контейнеров. Иными словами, хотелось получать образы с приложениями, которые одинаково конфигурируются и пишут логи, предоставляют единый интерфейс получения метрик, имеют один согласованный набор меток и тому подобное. Также важно было, чтобы сборка на компьютере разработчика давала такой же результат, что и сборка в любой системе CI, включая прохождение тестов и генерацию артефактов.
Так родилось понимание, что потребуется какой-то процесс для управления и централизации новых знаний, практик и стандартов, и путь от первого коммита до полностью готового к продуктовой инфраструктуре docker-образа должен должен быть единым и максимально автоматизированным, не выходящим за рамки терминов, начинающихся с слова continuous.
CLI vs. GUI
Отправной точкой для нового компонента, будь то сервис или библиотека, является создание репозитория. Этот этап можно разделить на две части: создание и конфигурация репозитория на хостинге системы контроля версий (у нас это Bitbucket) и его инициализация с созданием файловой структуры. К счастью, и для того, и для другого уже имелся ряд требований. Поэтому формализация их в коде была логичной задачей.
Итак, каким должен быть наш репозиторий:
- Располагаться в одном из проектов, от чего будут зависеть название, права доступа, политики принятия pull-реквестов и т.п.;
- Содержать обязательные файлы и директории, такие как:
- файл с конфигурацией и информацией о репозитории
SolutionInfo.props(об этом ниже); - исходные коды проекта в директории
src; .gitignore,README.mdи т.п.;
- файл с конфигурацией и информацией о репозитории
- Содержать необходимые Git-сабмодули;
- Проект должен быть производным от одного из шаблонов.
Так как Bitbucket REST API дает полный контроль над конфигурацией репозиториев, для взаимодействия с ним и была сделана специальная утилита – генератор репозиториев. В режиме «вопрос-ответ» она получает от пользователя все необходимые данные и создает полностью отвечающий всем нашим требованиям репозиторий, а именно:
- Определяет проект в Bitbucket, которые стоит выбрать;
- Валидирует имя в соответствии с нашим соглашением;
- Производит все необходимые настройки, которые не могут быть унаследованы от проекта;
- Актуализирует список кастомных темплейтов (мы используем dotnet templating) для проекта и предлагает из него выбрать;
- Заполняет минимально необходимую информацию о репозитории в файле конфигурации и в
*.mdдокументах; - Подключает сабмодули с конфигурацией CI/CD пайплайна (в нашем случае это Bamboo Specs) и сборочными скриптами.
Иными словами, разработчик, начиная новый проект, запускает утилиту, заполняет несколько полей, выбирает тип проекта и получает, например, полностью готовый «Hello world!» сервис, который уже подключен к CI-системе, откуда сервис даже может быть опубликован, если сделать коммит, изменяющий версию на ненулевую.
Первый шаг сделан. Никакого ручного труда и ошибок, поиска документации, регистраций и смс. Теперь перейдем к тому, что же там нагенерировалось.
Структура
Стандартизация структуры репозитория прижилась у нас довольно давно и понадобилась для упрощения сборки, интеграции с системой CI и со средой разработки. Изначально мы отталкивались от идеи, что пайплайн в CI должен быть максимально простым и, как можно догадаться, стандартным, что обеспечивало бы переносимость и воспроизводимость сборки. То есть, один и тот же результат можно было бы легко получить как в любой системе CI, так и на рабочем месте разработчика. Поэтому все, что не относится к особенностям конкретной среды непрерывной интеграции, вынесено в специальный Git-сабмодуль и является самодостаточной системой сборки. Точнее, системой стандартизации сборки. Сам пайплайн, в минимальном приближении, должен только запускать скрипт build.sh, забирать отчет о прохождении тестов и инициировать деплой, если необходимо. Для наглядности посмотрим, что получится, если сгенерировать репозиторий сервиса SampleService в проекте с говорящим именем Sandbox.
.
+-- [bamboo-specs]
+-- [devops.build]
¦ +-- build.sh
¦ L-- ...
+-- [docs]
+-- [.scripts]
+-- [src]
¦ +-- [CodeAnalysis]
¦ +-- [Sandbox.SampleService]
¦ +-- [Sandbox.SampleService.Bootstrap]
¦ +-- [Sandbox.SampleService.Client]
¦ +-- [Sandbox.SampleService.Tests]
¦ +-- Directory.Build.props
¦ +-- NLog.config
¦ +-- NuGet.Config
¦ L-- Sandbox.SampleService.sln
+-- .gitattributes
+-- .gitignore
+-- .gitmodules
+-- CHANGELOG.md
+-- README.md
L-- SolutionInfo.propsПервые две директории – это сабмодули Git. bamboo-specs – это «Pipeline as Code» для CI-системы Atlassian Bamboo (на его месте мог бы быть какой-нибудь Jenkinsfile), devops.build – наша система сборки, о которой подробнее расскажу ниже. К ней же относится и директория .scripts. В src располагается сам .NET проект: NuGet.Config содержит конфигурацию приватного NuGet-репозитория, NLog.config – dev-time конфигурацию NLog. Как можно догадаться, использование NLog в компании – это тоже один из стандартов. Из интересного здесь – почти что магический файл Directory.Build.props. Почему-то мало кто знает о такой возможности в .NET проектах, как кастомизация сборки. Если совсем коротко, то файлы с названием Directory.Build.props и Directory.Build.targets автоматически импортируются в ваши проекты и позволяют настроить в одном месте общие свойства для всех проектов. Например, так мы подключаем ко всем проектам code-style анализатор StyleCop.Analyzers и его конфигурацию из директории CodeAnalysis, устанавливаем правила версионирования и некоторые общие атрибуты для библиотек и пакетов (Company, Copyright и т.д.), а также подключаем через директиву <Import> файл SolutionInfo.props, который как раз и является тем самым файлом конфигурации репозитория, о котором шла речь выше. В нем уже содержится текущая версия, информация об авторах, URL репозитория и его описание, а также несколько свойств, оказывающих влияние на поведение системы сборки и получаемые на выходе артефакты.
<?xml version="1.0"?>
<Project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="devops.build/SolutionInfo.xsd">
<PropertyGroup>
<!-- Product name -->
<Product>Sandbox.SampleService</Product>
<!-- Product version. Version 0.0.0 wouldn't be published! -->
<BaseVersion>0.0.0</BaseVersion>
<!-- Project name which contains Main() -->
<EntryProject>Sandbox.SampleService.Bootstrap</EntryProject>
<!-- Exposed port -->
<ExposedPort>4000/tcp</ExposedPort>
<!-- DOTNET_SYSTEM_GLOBALIZATION_INVARIANT value. See https://github.com/dotnet/corefx/blob/master/Documentation/architecture/globalization-invariant-mode.md -->
<GlobalizationInvariant>false</GlobalizationInvariant>
<!-- Project URL -->
<RepositoryUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/</RepositoryUrl>
<!-- Documentation URL -->
<DocumentationUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/browse/README.md</DocumentationUrl>
<!-- Your name here -->
<Authors>User Name <username@contoso.com></Authors>
<!-- Project description -->
<Description>The sample service for demo purposes.</Description>
<!-- Bamboo plan key (required for Bamboo Specs -->
<BambooBlanKey>SMPL</BambooBlanKey>
</PropertyGroup>
</Project><Project>
<Import Condition="Exists('..\SolutionInfo.props')" Project="..\SolutionInfo.props" />
<ItemGroup>
<None Include="$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.json"
Link="stylecop.json"
CopyToOutputDirectory="Never"/>
<PackageReference Include="StyleCop.Analyzers" Version="1.*" PrivateAssets="all" />
</ItemGroup>
<PropertyGroup>
<CodeAnalysisRuleSet>$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.ruleset</CodeAnalysisRuleSet>
<!-- Enable XML docs generating-->
<GenerateDocumentationFile>true</GenerateDocumentationFile>
<!-- Enable C# 7.x features -->
<LangVersion>latest</LangVersion>
<!-- default base version -->
<BaseVersion Condition="'$(BaseVersion)' == ''">0.0.0</BaseVersion>
<!-- default build number and format -->
<BuildNumber Condition="'$(BuildNumber)' == ''">0</BuildNumber>
<BuildNumber>$([System.String]::Format('{0:0000}',$(BuildNumber)))</BuildNumber>
<!-- default version suffix -->
<VersionSuffix Condition="'$(VersionSuffix)' == ''">local</VersionSuffix>
<!-- empty version suffix instead of 'prod' -->
<VersionSuffix Condition="'$(VersionSuffix)' == 'prod'"></VersionSuffix>
<!-- format version prefix -->
<VersionPrefix>$(BaseVersion).$(BuildNumber)</VersionPrefix>
<!-- disable IsPackable by default -->
<IsPackable>false</IsPackable>
<PackageProjectUrl>$(RepositoryUrl)</PackageProjectUrl>
<Company>Contoso</Company>
<Copyright>Copyright $([System.DateTime]::Now.Date.Year) Contoso Ltd</Copyright>
</PropertyGroup>
</Project>Сборка
Сразу стоит сказать, что и у меня лично, и у коллег уже был вполне успешный опыт использования разных систем сборки. И вместо того, чтобы обвешивать совершенно нехарактерным функционалом уже существующий инструмент, было решено сделать другой, специализированный для нашего нового процесса, а старый оставить в покое для выполнения своих задач в рамках legacy-проектов. Идеей фикс стало желание получить инструмент, который единым стандартным процессом будет превращать код в отвечающий всем нашим требованиям docker-образ, одновременно избавляя разработчиков от необходимости погружаться в тонкости сборки, но сохранив возможности некоторой кастомизации.
Начался подбор подходящего фреймворка. Исходя из требований воспроизводимости результата как на билд-машинах с Linux, так и на Windows-машинах любого разработчика, ключевым условием стали настоящая кроссплатформенность и минимум предустановленных зависимостей. В разное время я успел неплохо познакомиться с некоторыми сборочными фреймворками для .NET разработчиков: от MSBuild и его монструозных конфигураций в XML, которые позже переводил на Psake (Powershell), до экзотического FAKE (F#). Но в этот раз хотелось чего-то свежего и легкого. Тем более, уже было решено, что сборку и тестирование нужно проводить целиком в изолированной среде контейнеров, так что я не планировал запускать внутри что-то кроме команд Docker CLI и Git, то есть большая часть процесса должна была быть описана в Dockerfile.
На тот момент и FAKE 5, и Cake для .NET Core все еще не были готовы, так что с кроссплатформенностью у этих проектов было так себе. А вот нежно любимый мною PowerShell 6 Core уже вышел, и я им вовсю пользовался. Поэтому я решил снова обратиться к Psake, и пока обращался, совершенно случайно наткнулся на интересный проект Invoke-Build, который является переосмыслением Psake и, как указывает сам автор, такой же, только лучше и проще. Так и есть. Я не буду подробно на нем останавливаться в рамках этой статьи, отмечу лишь, что меня в нем подкупает компактность при наличии всех основных функций для такого класса продуктов:
- Последовательность действий описывается набором взаимосвязанных задач (tasks), управлять которыми можно с помощью их взаимозависимостей и дополнительных условий.
- Есть несколько удобных хелперов, например, exec {} для корректной обработки кодов выхода консольных приложений.
- Любое исключение или остановка с помощью Ctrl+C будут корректно обработаны в специальном встроенном блоке Exit-Build. Например, там можно удалить все временные файлы, тестовое окружение или нарисовать приятный глазу отчет.
Универсальный Dockerfile
Сам по себе Dockerfile и сборка с помощью docker build предоставляют довольно слабые возможности параметризации, и гибкость этих инструментов едва ли чуть выше, чем у черенка лопаты. К тому же, существует большое количество способов сделать «неправильный» образ, слишком большой, слишком небезопасный, слишком неинтуитивный или попросту непредсказуемый. К счастью, документация от Microsoft уже предлагает несколько примеров Dockerfile, которые позволяют быстрее понять основные концепции и сделать свой первый Dockerfile, постепенно потом его улучшая. Он уже использует multi-stage паттерн и сборку специального «Test Runner» образа для запуска тестов.
Multi-stage паттерн и аргументы
Первым делом стоит раздробить стадии сборки на более мелкие и добавить новые. Так, стоит выделить запуск dotnet build в отдельную стадию, потому как для проектов, содержащих только библиотеки, нет никакого смысла запускать dotnet publish. Теперь, по своему усмотрению, мы можем запускать только требуемые стадии сборки, используя
dotnet build --target <name>
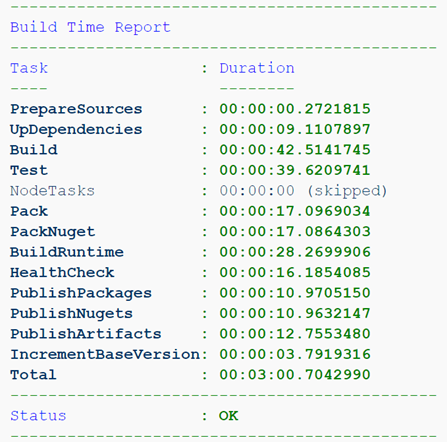
Например, вот мы собираем проект, содержащий только библиотеки. Артефактами здесь являются лишь NuGet-пакеты, а значит, собирать runtime-образ не имеет смысла.
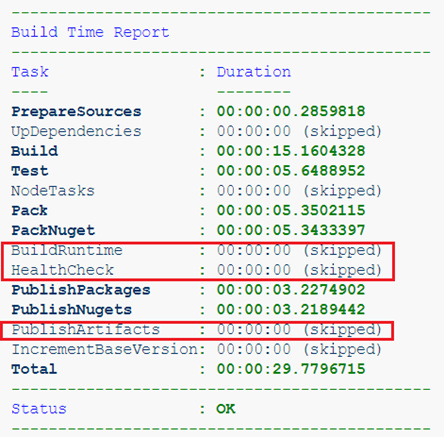
Или собираем уже сервис, но из feature-ветки. Артефакты такой сборки нам совсем не нужны, важно лишь прохождение тестов и healthcheck.
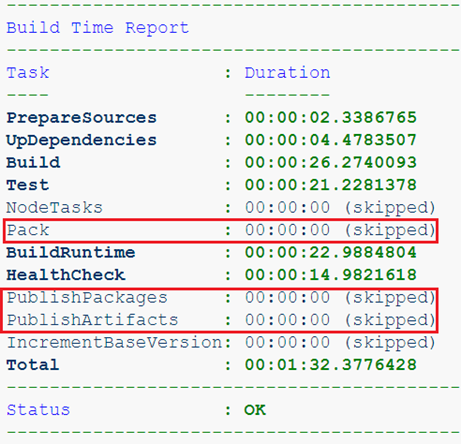
Следующее, что стоит сделать – это параметризировать использование базовых образов. С некоторых пор в Dockerfile директиву ARG можно размещать вне стадий сборки, а передаваемые значения использовать в имени базового образа.
ARG DOTNETCORE_VERSION=2.2
ARG ALPINE_VERSION=
ARG BUILD_BASE=mcr.microsoft.com/dotnet/core/sdk:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION}
ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/runtime:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION}
FROM ${BUILD_BASE} AS restore
...
FROM ${RUNTIME_BASE} AS runtime
...Так мы получили новые и на первый взгляд и не очевидные возможности. Во-первых, если мы хотим собрать образ с ASP.NET Core приложением, то runtime-образ потребуется уже другой: mcr.microsoft.com/dotnet/core/aspnet. Параметр с нестандартным базовым образом нужно сохранить в конфигурации репозитория SolutionInfo.props и передавать его как аргумент во время сборки. А еще мы облегчили разработчику возможность использовать другие версии .NET Сore образов: превью, например, или вообще кастомные (мало ли!).
Во-вторых, еще более интересной оказывается возможность «расширить» Dockerfile, сделав часть операций в другой сборке, результат которой будет взят за основу при подготовке runtime-образа. Например, в некоторых наших сервисах используется JavaScript и Vue.js, код которого мы подготовим в отдельном образе, просто добавив в репозиторий такой «расширяющий» Dockerfile:
ARG DOTNETCORE_VERSION=2.2
ARG ALPINE_VERSION=
ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION}
FROM node:alpine AS install
WORKDIR /build
COPY package.json .
RUN npm install
FROM install AS src
COPY [".babelrc", ".eslintrc.js", ".stylelintrc", "./"]
COPY ClientApp ./ClientApp
FROM src AS publish
RUN npm run build-prod
FROM ${RUNTIME_BASE} AS appbase
COPY --from=publish /build/wwwroot/ /app/wwwroot/Соберем этот образ с тэгом, который передадим в стадию сборки runtime-образа ASP.NET сервиса в качестве аргумента RUNTIME_BASE. Так можно расширять сборку сколько угодно, в том числе, можно параметризировать то, что нельзя просто так в docker build. Хочется параметризировать добавление Volume? Легко:
ARG DOTNETCORE_VERSION=2.2
ARG ALPINE_VERSION=
ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION}
FROM ${RUNTIME_BASE} AS runtime
ARG VOLUME
VOLUME ${VOLUME}Запускаем сборку этого Dockerfile столько раз, сколько директив VOLUME хотим добавить. Полученный образ используем как базовый для сервиса.
Запуск тестов
Вместо запуска тестов прямо в стадиях сборки правильнее и удобнее делать это в специальном «Test Runner» контейнере. Коротко передавая суть такого подхода, отмечу, что он позволяет:
- Выполнять все запланированные запуски, даже если какой-то из них упадет;
- Смонтировать в контейнер директорию хостовой файловой системы для получения отчета о тестах, что жизненно необходимо при сборке в CI системе;
- Запускать тестирование во временном окружении, передавая название его сети в параметр
docker run --network <test_network_name>.
Последний пункт означает, что мы теперь можем запускать не только модульные тесты, но и интеграционные. Описываем окружение, например, в docker-compose.yaml, и запускаем его на время всей сборки. Теперь можно проверить взаимодействие с базой данных или другим нашим сервисом, а логи из них сохранить на случай, если они понадобится для анализа.
Полученный runtime-образ мы всегда проверяем на прохождение healthcheck, что тоже является своеобразным тестом. Временное тестовое окружение может пригодиться и здесь, если проверяемый сервис имеет зависимости от своего окружения.
Замечу еще, что подход с runner-контейнерами, собранным на стадии с dotnet build, отлично потом послужит и для запуска dotnet publish, dotnet pack и dotnet nuget push. Это позволит нам сохранитять артефакты сборки локально.
Healthcheck и зависимости ОС
Довольно быстро стало понятно, что наши стандартизированные сервисы все равно будут по-своему уникальны. У них могут быть разные требования к предустановленным пакетам операционной системы внутри образа и разные способы проверки healthcheck. И если для проверки состояния Web-приложения нам подойдет утилита curl, то для gRPC-бэкенда или, тем более, headless сервиса она окажется бесполезной, да еще и будет лишним пакетом в контейнере.
Чтобы дать разработчикам возможность кастомизировать образ и расширять его конфигурацию, мы используем соглашение о нескольких специальных скриптах, которые и могут быть переопределены в репозитории:
.scripts
+-- healthcheck.sh
+-- run.sh
L-- runtime-deps.shСкрипт healthcheck.sh содержит в себе команды, необходимые для проверки состояния:
Для Web с помощью curl:
#!/bin/ash set –e curl -sIf -o /dev/null -w "%{http_code}\n" 127.0.0.1/health || exit 1
Другие сервисы с помощью собственной cli утилиты:
#!/bin/ash set –e healthcheck || exit 1
С помощью runtime-deps.sh устанавливаются зависимости и, если требуется, выполняются любые другие действия над базовой ОС, необходимые для нормального функционирования приложения внутри контейнера. Типичные примеры:
Для Web приложения:
#!/bin/ash apk add --no-cache curl icu-libs
Для gRPC сервиса:
#!/bin/ash apk add --no-cache libc6-compat
Таким образом стандартизирован способ управления зависимостями и проверки состояния, но оставлено место для некоторой гибкости. Что до run.sh, то нем дальше.
Entrypoint скрипт
Уверен, что каждый, кто хоть раз писал свой Dockerfile, задавался вопросом, какую директиву ему использовать – CMD или ENTRYPOINT. Более того, эти команды еще и имеют по два варианта синтаксиса, которые самым драматичным образом влияют на получаемый результат. Я не стану подробно объяснять разницу, повторяя за теми, кто уже все разъяснил. Просто рекомендую запомнить, что в 99% ситуаций правильно использовать ENTRYPOINT и exec-синтаксис:
ENTRYPOINT ["/path/to/executable"]
В противном случае, запускаемое приложение не сможет корректно обрабатывать команды ОС, такие как SIGTERM и т.п., а еще можно получить неприятности в виде зомби-процессов и всего, что связано с проблемой PID 1. Но что делать, если хочется запустить контейнер, не запуская приложения? Да, можно переопределить точку входа:
docker run --rm -it --entrypoint ash <image_name> <params>
Выглядит не слишком удобно и интуитивно, правда? Но есть хорошая новость: можно сделать лучше! А именно, использовать entrypoint-скрипт. Такой скрипт позволяет сделать сколь угодно сложную (пример) инициализацию, обработку параметров и все, что пожелаете.
У нас же по умолчанию используется максимально простой, но в тоже время функциональный сценарий:
#!/bin/sh
set -e
if [ ! -z "$1" ] && $(command -v $1 >/dev/null 2>&1)
then
exec $@
else
exec /usr/bin/dotnet /app/${ENTRY_PROJECT}.dll $@
fiОн позволяет управлять запуском контейнера очень интуитивно:
docker run <image> env – просто выполнит env в образе, показав переменные окружения.
docker run <image> -param1 value1 – запустит сервис с указанными аргументами.
Отдельно нужно обратить внимание на команду exec: ее наличие перед вызовом исполняемого приложения обеспечит ему работу с заветным PID 1 в вашем контейнере.
Что еще
Конечно, за более чем полтора года использования в системе сборки накопилось много разного функционала. Помимо управления условиями запуска тех или иных стадий, работы с хранилищем артефактов, версионированием и других возможностей развивался и наш «стандарт» контейнера. Он наполнился важными атрибутами, которые делают его более предсказуемым и удобным с точки зрения администрирования:
- Устанавливаются все нужные метки образа: версии, номера ревизий, ссылки на документацию, автора и другие.
- В runtime-контейнере переопределяется конфигурация NLog, чтобы после публикации все логи сразу были представлены в структурированном виде с помощью json, версия схемы которого версионируется.
- Автоматически поддерживается актуальность правил статического анализа и любых других стандартов.
Такой инструмент, безусловно, всегда можно улучшать и развивать. Здесь все зависит от потребностей и фантазии. Например, в дополнение ко всему была реализована возможность упаковки в образ дополнительных cli утилит. Разработчик может легко помещать их в образ, указав в файле конфигурации лишь требуемое имя утилиты и название .NET проекта, из которого она должна собираться (например, наш healthcheck).
Заключение
Описанное здесь является лишь частью комплексного подхода к стандартизации. За кадром остались сами сервисы, которые создаются из наших шаблонов, а потому они достаточно унифицированы по множеству критериев, таких как единый подход к конфигурированию, общие методы для доступа к метрикам, кодогенерация и так далее. Об этом будет подробно рассказано в отдельной статье. А в качестве заключения я поделюсь своими ощущениями от того, что получилось.
Ради перехода на контейнеры мы не ломали привычный процесс производства для наших разработчиков, не пришлось никого пересаживать на Linux и альтернативные среды разработки, ведь для кого-то это было бы весьма болезненным шагом. Процесс следования правилам тоже не выглядит тоталитаризмом, напротив, многое из новых практик и правил воспринимается органично и естественно. Есть, конечно, и исключения, такие как контроль Code Style, но с этим ничего не поделать, ведь так происходит при внедрении любых систем автоматизированного контроля качества кода.
Признаюсь, лично меня результат воодушевляет! Пройдя эволюционный путь, избежав при этом «бунтов на корабле», мы сегодня легко можем создавать новые сервисы, которые сразу же готовы быть встроенными в нашу инфраструктуру вообще без дополнительных усилий. Разработчикам остается только писать хороший код, а знакомство с Docker у них начинается с ими же написанных сервисов.
ypastushenko
Спасибо, интересная статья.
Кто у вас накатывает миграции БД во время деплоя? Если это делает CI система, то где она берет кренделя для подключения к базе?
supcry
Немного за рамки настоящей статьи, но коротко отвечу.
В каждом случае по-разному. Это уже определяет команда разработки. Либо зашивается в переменных билд-системы, либо берётся из отдельного репозитория с настройками.