

В прошлой статье мы рассмотрели кластеризацию RabbitMQ для обеспечения отказоустойчивости и высокой доступности. Теперь глубоко покопаемся в Apache Kafka.
Здесь единицей репликации является раздел (partition). У каждого топика один или несколько разделов. В каждом разделе есть лидер с фолловерами или без них. При создании топика указывается количество разделов и коэффициент репликации. Обычное значение 3, это означает три реплики: один лидер и два фолловера.
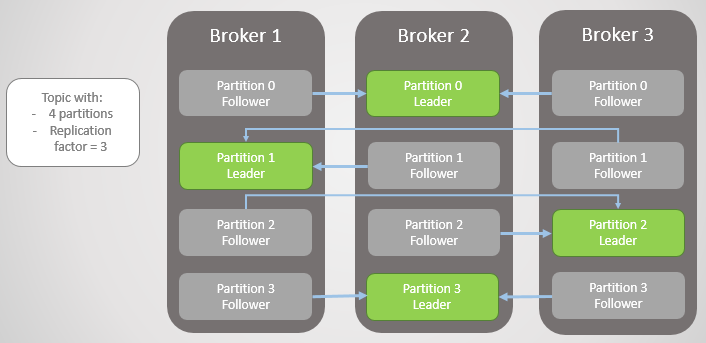
Рис. 1. Четыре раздела распределены между тремя брокерами
Все запросы на чтение и запись поступают лидеру. Фолловеры периодически посылают лидеру запросы на получение последних сообщений. Потребители никогда не обращаются к фолловерам, последние существуют только для избыточности и отказоустойчивости.

Сбой раздела
Когда отваливается брокер, часто выходят из строя лидеры нескольких разделов. В каждом из них лидером становится фолловер с другого узла. На самом деле это не всегда так, поскольку влияет еще фактор синхронизации: есть ли синхронизированные фолловеры, а если нет, то разрешен ли переход на несинхронизированную реплику. Но пока не будем усложнять.
Из сети уходит брокер 3 — и для раздела 2 избирается новый лидер на брокере 2.

Рис. 2. Брокер 3 умирает, и его фолловер на брокере 2 избирается новым лидером раздела 2
Затем уходит брокер 1 и раздел 1 тоже теряет своего лидера, роль которого переходит к брокеру 2.
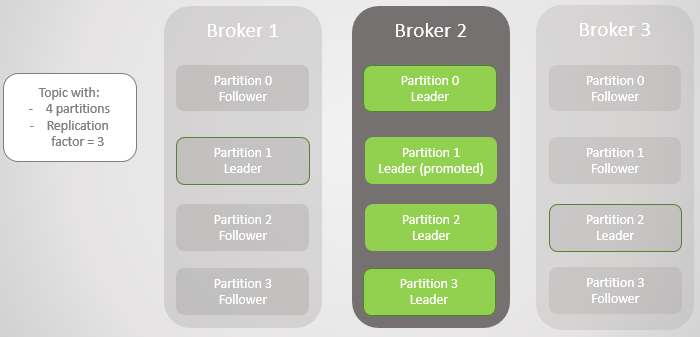
Рис. 3. Остался один брокер. Все лидеры находятся на одном брокере с нулевой избыточностью
Когда брокер 1 возвращается в сеть, то добавляет четырех фолловеров, обеспечивая некоторую избыточность каждому разделу. Но все лидеры по-прежнему остались на брокере 2.

Рис. 4. Лидеры остаются на брокере 2
Когда поднимается брокер 3, мы возвращаемся к трем репликам на раздел. Но все лидеры по-прежнему на брокере 2.

Рис. 5. Несбалансированное размещение лидеров после восстановления брокеров 1 и 3
У Kafka есть инструмент для более качественной перебалансировки лидеров, чем у RabbitMQ. Там приходилось использовать сторонний плагин или скрипт, который изменял политики для миграции главного узла за счет снижения избыточности во время миграции. Кроме того, для больших очередей приходилось смириться с недоступностью во время синхронизации.
У Kafka есть концепция «предпочтительных реплик» на роль лидера. Когда создаются разделы топика, Kafka пытается равномерно распределить лидеров по узлам и отмечает этих первых лидеров как предпочтительных. Со временем из-за перезагрузки серверов, сбоев и нарушения связности лидеры могут оказаться на других узлах, как в вышеописанном крайнем случае.
Чтобы исправить это, Kafka предлагает два варианта:
- Опция auto.leader.rebalance.enable=true позволяет узлу контроллера автоматически переназначить лидеров обратно на предпочтительные реплики и тем самым восстановить равномерное распределение.
- Администратор может запустить скрипт kafka-preferred-replica-election.sh для переназначения вручную.
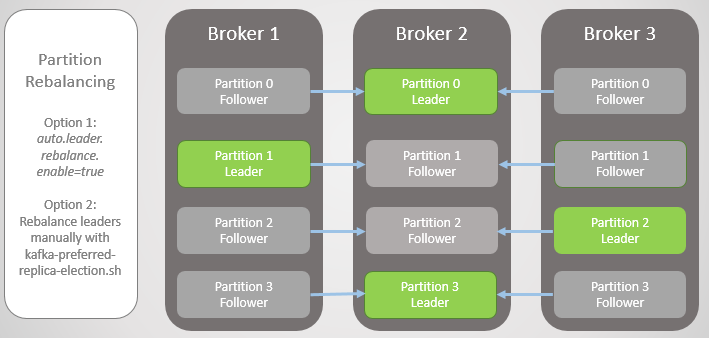
Рис. 6. Реплики после перебалансировки
Это была упрощенная версия сбоя, но реальность более сложна, хотя ничего слишком сложного здесь нет. Все сводится к синхронизированным репликам (In-Sync Replicas, ISR).
Синхронизированные реплики (ISR)
ISR — это набор реплик раздела, который считается «синхронизированным» (in-sync). Тут есть лидер, а фолловеров может не быть. Фолловер считается синхронизированным, если он сделал точные копии всех сообщений лидера до истечения интервала replica.lag.time.max.ms.
Фолловер удаляется из набора ISR, если он:
- не сделал запрос на выборку за интервал replica.lag.time.max.ms (считается мертвым)
- не успел обновиться за интервал replica.lag.time.max.ms (считается медленным)
Фолловеры делают запросы на выборку в интервале replica.fetch.wait.max.ms, который по умолчанию составляет 500 мс.
Чтобы четко объяснить цель ISR, нужно посмотреть на подтверждения от производителя (producer) и некоторые сценарии отказа. Производители могут выбрать, когда брокер отправляет подтверждение:
- acks=0, подтверждение не отправляется
- acks=1, подтверждение отправляется после того, как лидер записал сообщение в свой локальный лог
- acks=all, подтверждение отправляется после того, как все реплики в ISR записали сообщение в локальные логи
В терминологии Kafka, если ISR сохранил сообщение, происходит его «коммит». Acks=all — самый безопасный вариант, но и дополнительная задержка. Рассмотрим два примера отказа и как разные опции 'acks' взаимодействуют с концепцией ISR.
Acks=1 и ISR
В этом примере мы увидим, что если лидер не ждет сохранения каждого сообщения от всех фолловеров, то при сбое лидера возможна потеря данных. Переход к несинхронизированному фолловеру может быть разрешен или запрещен настройкой unclean.leader.election.enable.
В этом примере у производителя установлено значение acks=1. Раздел распределен по всем трем брокерам. Брокер 3 отстает, он синхронизировался с лидером восемь секунд назад и сейчас отстает на 7456 сообщений. Брокер 1 отстал всего на одну секунду. Наш производитель отправляет сообщение и быстро получает обратно ack, без оверхеда на медленных или мертвых фолловеров, которых лидер не ждет.

Рис. 7. ISR с тремя репликами
Брокер 2 выходит из строя, и производитель получает ошибку соединения. После перехода лидерства к брокеру 1 мы теряем 123 сообщения. Фолловер на брокере 1 входил в ISR, но не полностью синхронизировался с лидером, когда тот упал.

Рис. 8. При сбое теряются сообщения
В конфигурации bootstrap.servers у производителя перечислено несколько брокеров, и он может спросить другого брокера, кто стал новым лидером раздела. Затем он устанавливает соединение с брокером 1 и продолжает отправлять сообщения.

Рис. 9. Отправка сообщений возобновляется после краткого перерыва
Брокер 3 отстает еще больше. Он делает запросы на выборку, но не может синхронизироваться. Это может быть связано с медленным сетевым соединением между брокерами, проблемой хранения и т. д. Он удаляется из ISR. Теперь ISR состоит из одной реплики — лидера! Производитель продолжает отправлять сообщения и получать подтверждения.

Рис. 10. Фолловер на брокере 3 удаляется из ISR
Брокер 1 падает, и роль лидера переходит к брокеру 3 с потерей 15286 сообщений! Производитель получает сообщение об ошибке подключения. Переход к лидеру за пределами ISR был возможен только из-за настройки unclean.leader.election.enable=true. Если она установлена в false, то переход бы не произошел, а все запросы чтения и записи были бы отклонены. В этом случае мы ждем возвращения брокера 1 с его нетронутыми данными в реплике, которая вновь возьмет на себя лидерство.
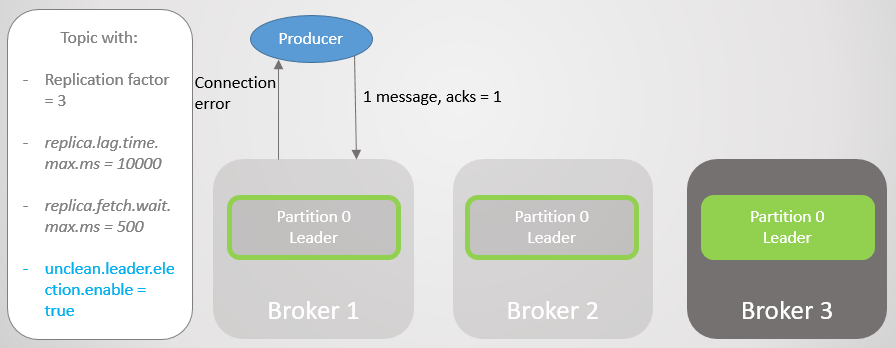
Рис. 11. Брокер 1 падает. При сбое теряется большое количество сообщений
Производитель устанавливает соединение с последним брокером и видит, что тот теперь лидер раздела. Он начинает отправлять сообщения брокеру 3.

Рис. 12. После краткого перерыва сообщения снова отправляются в раздел 0
Мы видели, что кроме кратких прерываний на установку новых соединений и поиск нового лидера, производитель постоянно отправлял сообщения. Такая конфигурация обеспечивает доступность за счет согласованности (безопасности данных). Kafka потерял тысячи сообщений, но продолжал принимать новые записи.
Acks=all и ISR
Давайте повторим этот сценарий еще раз, но с acks=all. Задержка брокера 3 в среднем четыре секунды. Производитель отправляет сообщение с acks=all, и теперь не получает быстрый ответ. Лидер ждет, пока сообщение сохранят все реплики в ISR.
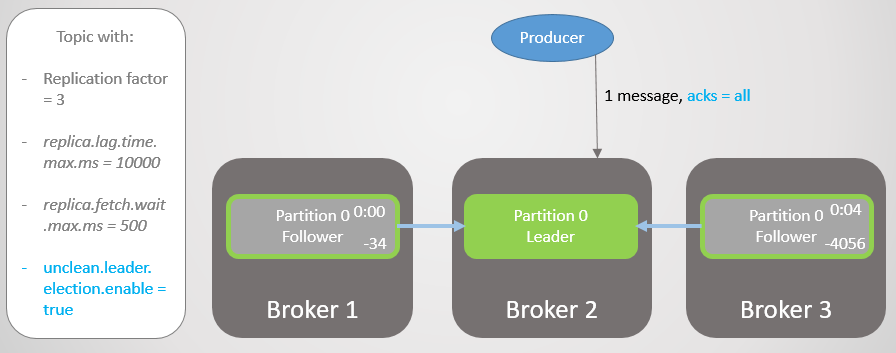
Рис. 13. ISR с тремя репликами. Одна работает медленно, что приводит к задержке записи
После четырех секунд дополнительной задержки брокер 2 отправляет ack. Все реплики теперь полностью обновлены.
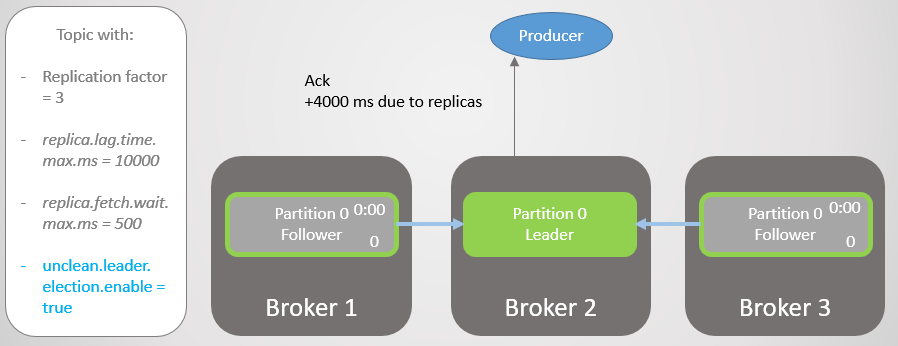
Рис. 14. Все реплики сохраняют сообщения и отправляется ack
Брокер 3 теперь отстает еще больше и удаляется из ISR. Задержка значительно уменьшается, поскольку в ISR не осталось медленных реплик. Брокер 2 теперь ждет только брокера 1, а у него средний лаг 500 мс.

Рис. 15. Реплика на брокере 3 удаляется из ISR
Затем падает брокер 2, и лидерство переходит к брокеру 1 без потери сообщений.

Рис. 16. Брокер 2 падает
Производитель находит нового лидера и начинает посылать ему сообщения. Задержка еще уменьшается, ведь теперь ISR состоит из одной реплики! Поэтому опция acks=all не добавляет избыточности.
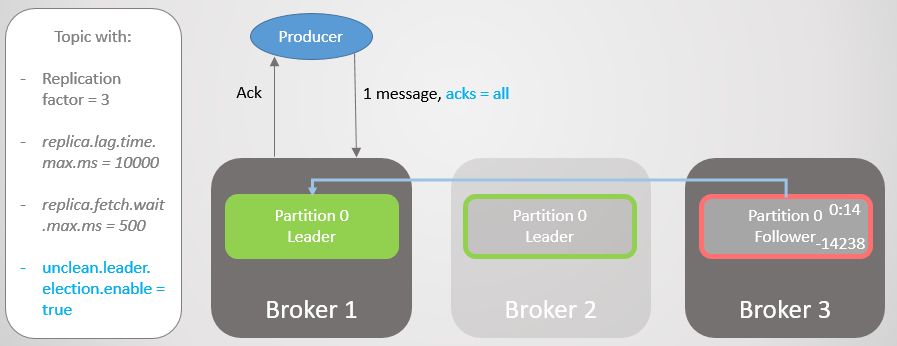
Рис. 17. Реплика на брокере 1 берет на себя лидерство без потери сообщений
Затем падает брокер 1, и лидерство переходит к брокеру 3 с потерей 14238 сообщений!

Рис. 18. Брокер 1 умирает, а переход лидерства с настройкой unclean приводит к обширной потере данных
Мы могли бы не устанавливать опцию unclean.leader.election.enable в значение true. По умолчанию оно равно false. Настройка acks=all с unclean.leader.election.enable=true обеспечивает доступность с некоторой дополнительной безопасностью данных. Но, как вы видите, мы все еще можем потерять сообщения.
Но что, если мы хотим увеличить безопасность данных? Можно поставить unclean.leader.election.enable = false, но это не обязательно защитит нас от потери данных. Если лидер упал жестко и унес с собой данные, то сообщения по-прежнему потеряны, плюс теряется доступность, пока администратор не восстановит ситуацию.
Лучше гарантировать избыточность всех сообщений, а в противном случае отказаться от записи. Тогда хотя бы с точки зрения брокера потеря данных возможна только при двух или более одновременных сбоях.
Acks=all, min.insync.replicas и ISR
С конфигурацией топика min.insync.replicas мы повышаем уровень безопасности данных. Давайте еще раз пройдемся по последней части прошлого сценария, но на этот раз с min.insync.replicas=2.
Итак, у брокера 2 есть лидер реплики, а фолловер на брокере 3 удален из ISR.
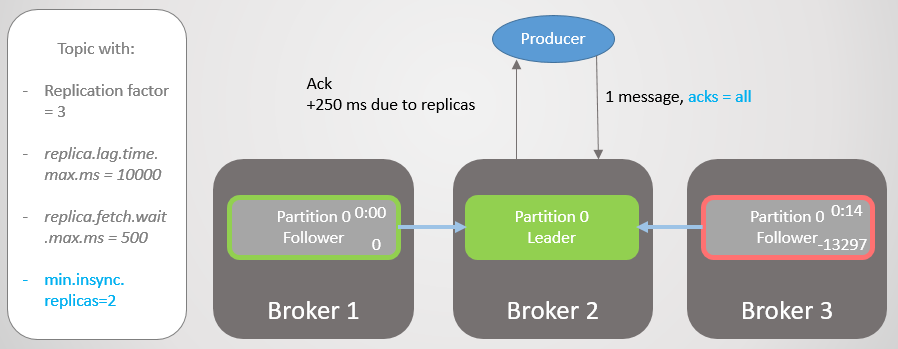
Рис. 19. ISR из двух реплик
Брокер 2 падает, а лидерство переходит к брокеру 1 без потери сообщений. Но теперь ISR состоит только из одной реплики. Это не соответствует минимальному числу для получения записей, и поэтому брокер отвечает на попытку записи ошибкой NotEnoughReplicas.
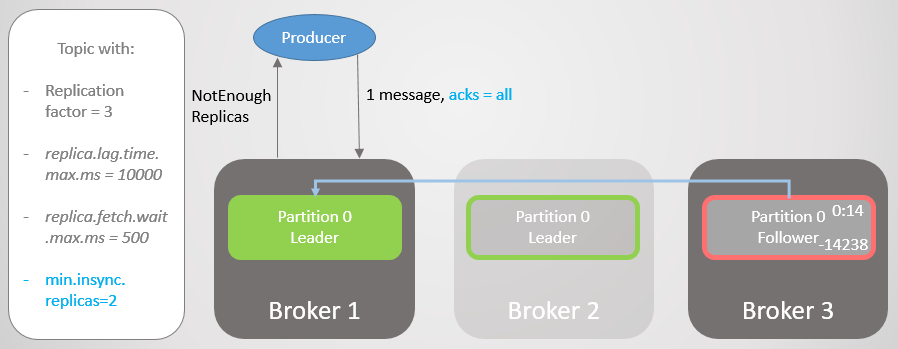
Рис. 20. Число ISR на один ниже, чем указано в min.insync.replicas
Эта конфигурация жертвует доступностью ради согласованности. Прежде чем подтвердить сообщение, мы гарантируем, что оно записывается по крайней мере на две реплики. Это дает производителю гораздо большую уверенность. Здесь потеря сообщений возможна только в случае одновременного сбоя двух реплик в краткий интервал, пока сообщение не реплицировано дополнительному фолловеру, что маловероятно. Но если вы суперпараноик, то можете установить коэффициент репликации 5, а min.insync.replicas на 3. Тут сразу три брокера должны упасть одновременно, чтобы потерять запись! Конечно, за такую надежность вы заплатите дополнительной задержкой.
Когда доступность необходима для безопасности данных
Как и в случае с RabbitMQ, иногда доступность необходима для безопасности данных. Вам нужно подумать вот о чем:
- Может ли паблишер просто вернуть ошибку, а вышестоящая служба или пользователь повторить попытку позже?
- Может ли паблишер сохранить сообщение локально или в базе данных, чтобы повторить попытку позже?
Если ответ отрицательный, то оптимизация доступности повышает безопасность данных. Вы потеряете меньше данных, если выберете доступность вместо отказа от записи. Таким образом, все сводится к поиску баланса, а решение зависит от конкретной ситуации.
Смысл ISR
Набор ISR позволяет выбрать оптимальный баланс между безопасностью данных и задержкой. Например, обеспечить доступность в условиях сбоя большинства реплик, минимизируя влияние мертвых или медленных реплик с точки зрения задержки.
Мы сами выбираем значение replica.lag.time.max.ms в соответствии со своими потребностями. По сути этот параметр означает, какую задержку мы готовы принять при acks=all. Значение по умолчанию — десять секунд. Если для вас это слишком долго, можете ее уменьшить. Тогда вырастет частота изменений в ISR, поскольку фолловеры будут чаще удаляться и добавляться.
В RabbitMQ просто набор зеркал, которые нужно реплицировать. Медленные зеркала привносят дополнительную задержку, а отклика мертвых зеркал можно ждать до истечения времени жизни пакетов, которые проверяют доступность каждого узла (net tick). ISR — интересный способ избежать этих проблем с увеличением задержки. Но мы рискуем потерять избыточность, поскольку ISR может сократиться только до лидера. Чтобы избежать этого риска, используйте настройку min.insync.replicas.
Гарантия подключения клиентов
В настройках bootstrap.servers производителя и потребителя можно указать несколько брокеров для подключения клиентов. Идея в том, что при отключении одного узла остается несколько запасных, с которыми клиент может открыть соединение. Это не обязательно лидеры разделов, а просто плацдарм для для начальной загрузки. Клиент может спросить их, на каком узле размещается лидер раздела для чтения/записи.
В RabbitMQ клиенты могут подключаться к любому узлу, а внутренняя маршрутизация отправляет запрос куда надо. Это означает, что вы можете установить перед RabbitMQ балансировщик нагрузки. Kafka требует, чтобы клиенты подключались к узлу, на котором размещается лидер соответствующего раздела. В такой ситуации балансировщик нагрузки не поставить. Список bootstrap.servers критически важен, чтобы клиенты могли обращаться к нужным узлам и находить их после сбоя.
Архитектура консенсуса Kafka
До сих пор мы не рассмотрели, как кластер узнает о падении брокера и как выбирается новый лидер. Чтобы понять, как Kafka работает с сетевыми разделами, сначала нужно понять архитектуру консенсуса.
Каждый кластер Kafka развертывается вместе с кластером Zookeeper — это служба распределенного консенсуса, которая позволяет системе достичь консенсуса у некоторого заданного состояния с приоритетом согласованности над доступностью. Для одобрения операций чтения и записи требуется согласие большинства узлов Zookeeper.
Zookeeper хранит состояние кластера:
- Список топиков, разделов, конфигурацию, текущие реплики лидера, предпочтительные реплики.
- Члены кластера. Каждый брокер пингует в кластер Zookeeper. Если тот не получает пинг в течение заданного периода времени, то Zookeeper записывает брокера в недоступные.
- Выбор основного и запасного узлов для контроллера.
Узел контроллера — один из брокеров Kafka, который отвечает за избрание лидеров реплик. Zookeeper отправляет контроллеру уведомления о членстве в кластере и изменениях топика, и контроллер должен действовать в соответствии с этими изменениями.
Например, возьмем новый топик с десятью разделами и коэффициентом репликации 3. Контроллер должен выбрать лидера каждого раздела, пытаясь оптимально распределить лидеров между брокерами.
Для каждого раздела контроллер:
- обновляет информацию в Zookeeper о ISR и лидере;
- отправляет команду LeaderAndISRCommand каждому брокеру, который размещает реплику этого раздела, информируя брокеров об ISR и лидере.
Когда падает брокер с лидером, Zookeeper отправляет уведомление контроллеру, и тот выбирает нового лидера. Опять же, контроллер сначала обновляет Zookeeper, а затем отправляет команду каждому брокеру, уведомляя их об изменении лидерства.
Каждый лидер несет ответственность за набор ISR. Настройка replica.lag.time.max.ms определяет, кто туда войдет. При изменении ISR лидер передает Zookeeper новую информацию.
Zookeeper всегда информирован о любых изменениях, чтобы в случае сбоя руководство плавно перешло к новому лидеру.

Рис. 21. Консенсус Kafka
Протокол репликации
Понимание деталей репликации помогает лучше понять потенциальные сценарии потери данных.
Запросы на выборку, Log End Offset (LEO) и Highwater Mark (HW)
Мы рассмотрели, что фолловеры периодически отправляют лидеру запросы на выборку (fetch). Интервал по умолчанию составляет 500 мс. Это отличается от RabbitMQ тем, что в RabbitMQ репликация инициируется не зеркалом очереди, а мастером. Мастер пушит изменения на зеркала.
Лидер и все фолловеры сохраняют смещение конца лога (Log End Offset, LEO) и метку Highwater (HW). Отметка LEO хранит смещение последнего сообщения в локальной реплике, а HW — смещение последнего коммита. Помните, что для статуса «коммит» сообщение должно быть сохранено во всех репликах ISR. Это означает, что LEO обычно чуть опережает HW.
Когда лидер получает сообщение, он сохраняет его локально. Фолловер делает запрос на выборку, передав свой LEO. Затем лидер отправляет пакет сообщений, начиная с этого LEO, а также передает текущий HW. Когда лидер получает информацию, что все реплики сохранили сообщение с заданным смещением, он перемещает отметку HW. Только лидер может переместить HW, и так все фолловеры узнают текущее значение в ответах на свой запрос. Это означает, что фолловеры могут отставать от лидера и по сообщениям, и относительно знания HW. Потребители получают сообщения только до текущего HW.
Обратите внимание, что «сохраненный» (persisted) означает записанный в память, а не на диск. Для производительности, Kafka выполняет синхронизацию на диск с определенным интервалом. У RabbitMQ тоже есть такой интервал, но он отправит подтверждение паблишеру только после того, как мастер и все зеркала записали сообщение на диск. Разработчики Kafka по соображениям производительности приняли решение отправлять ack, как только сообщение записано в память. Kafka делает ставку на то, что избыточность компенсирует риск краткосрочного хранения подтвержденных сообщений только в памяти.
Сбой лидера
Когда падает лидер, Zookeeper уведомляет контроллер, и тот выбирает новую реплику лидера. Новый лидер устанавливает новую отметку HW в соответствии со своим LEO. Затем информацию о новом лидере получают фолловеры. В зависимости от версии Kafka, фолловер выберет один из двух сценариев:
- Усечёт локальный лог до известного HW и отправит новому лидеру запрос на сообщения после этой отметки.
- Отправит лидеру запрос, чтобы узнать HW на момент его избрания лидером, а затем усечет лог до этого смещения. Затем начнет делать периодические запросы на выборку, начиная с этого смещения.
Фолловеру может понадобиться урезать лог по следующим причинам:
- Когда происходит сбой лидера, первый фолловер из набора ISR, зарегистрированный в Zookeeper, выигрывает выборы и становится лидером. Все фолловеры в ISR, хотя и считаются «синхронизированными», могли и не получить от бывшего лидера копии всех сообщений. Вполне возможно, что у избранного фолловера не самая актуальная копия. Kafka гарантирует, что между репликами нет расхождения. Таким образом, чтобы избежать расхождения, каждый фолловер должен усечь свой лог до значения HW нового лидера на момент его избрания. Это еще одна причина, почему настройка acks=all так важна для согласованности.
- Сообщения периодически записываются на диск. Если все узлы кластера отказали одновременно, то на дисках сохранятся реплики с разным смещением. Вполне возможно, что когда брокеры снова вернутся в сеть, новый лидер, который будет избран, окажется позади своих фолловеров, потому что он сохранился на диск раньше других.
Воссоединение c кластером
При воссоединении с кластером реплики поступают так же, как и при сбое лидера: проверяют реплику лидера и усекают свой лог до его HW (на момент избрания). Для сравнения, RabbitMQ одинаково расценивает воссоединенные узлы как совершенно новые. В обоих случаях брокер отбрасывает любое существующее состояние. Если используется автоматическая синхронизация, то мастер должен реплицировать абсолютно все текущее содержимое в новое зеркало способом «и пусть весь мир подождет». Во время этой операции мастер не принимает никаких операций чтения или записи. Такой подход создает проблемы в больших очередях.
Kafka — это распределенный лог, и в целом он хранит больше сообщений, чем очередь RabbitMQ, где данные удаляются из очереди после их чтения. Активные очереди должны оставаться относительно небольшими. Но Kafka — это лог с собственной политикой хранения, которая может установить срок в дни или недели. Подход с блокировкой очереди и полной синхронизацией абсолютно неприемлем для распределенного лога. Вместо этого фолловеры Kafka просто обрезают свой лог до HW лидера (на момент его избрания) в том случае, если их копия опережает лидера. В более вероятном случае, когда фолловер находится позади, он просто начинает делать запросы на выборку, начиная с своего текущего LEO.
Новые или воссоединенные фолловеры начинают за пределами ISR и не участвуют в коммитах. Они просто работают рядом с группой, получая сообщения так быстро, как могут, пока не догонят лидера и не войдут в ISR. Здесь нет блокировки и не нужно выбрасывать все свои данные.
Нарушение связности
У Kafka больше компонентов, чем в RabbitMQ, поэтому здесь более сложный набор поведений, когда в кластере нарушается связность. Но Kafka изначально проектировалась для кластеров, так что решения очень хорошо продуманы.
Ниже приведены несколько сценариев нарушения связности:
- Сценарий 1. Фолловер не видит лидера, но все еще видит Zookeeper.
- Сценарий 2. Лидер не видит ни одного фолловера, но все еще видит Zookeeper.
- Сценарий 3. Фолловер видит лидера, но не видит Zookeeper.
- Сценарий 4. Лидер видит фолловеров, но не видит Zookeeper.
- Сценарий 5. Фолловер полностью отделен и от других узлов Kafka, и от Zookeeper.
- Сценарий 6. Лидер полностью отделен и от других узлов Kafka, и от Zookeeper.
- Сценарий 7. Узел контроллера Kafka не видит другой узел Kafka.
- Сценарий 8. Контроллер Kafka не видит Zookeeper.
Для каждого сценария предусмотрено свое поведение.
Сценарий 1. Фолловер не видит лидера, но все еще видит Zookeeper

Рис. 22. Сценарий 1. ISR из трех реплик
Нарушение связности отделяет брокера 3 от брокеров 1 и 2, но не от Zookeeper. Брокер 3 больше не может отправлять запросы на выборку. По истечении времени replica.lag.time.max.ms он удаляется из ISR и не участвует в коммитах сообщений. Как только связность восстановлена, он возобновит запросы на выборку и присоединится к ISR, когда догонит лидера. Zookeeper продолжит получать пинги и считать, что брокер жив и здоров.
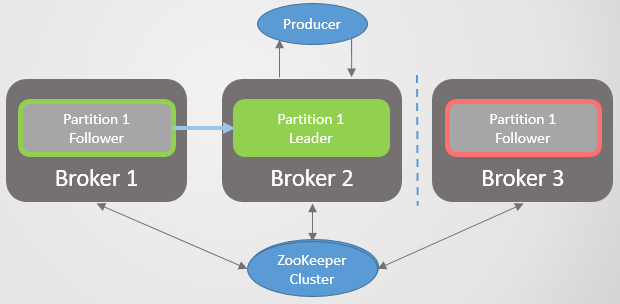
Рис. 23. Сценарий 1. Брокер удаляется из ISR, если от него не получен запрос на выборку в течение интервала replica.lag.time.max.ms
Нет никакого логического разделения (split-brain) или приостановки узла, как в RabbitMQ. Вместо этого уменьшается избыточность.
Сценарий 2. Лидер не видит ни одного фолловера, но все еще видит Zookeeper

Рис. 24. Сценарий 2. Лидер и два фолловера
Нарушение сетевой связности отделяет лидера от фолловеров, но брокер все еще видит Zookeeper. Как и в первом сценарии, ISR сжимается, но на этот раз только до лидера, поскольку все фолловеры перестают отправлять запросы на выборку. Опять же, нет никакого логического разделения. Вместо этого происходит потеря избыточности для новых сообщений, пока связность не восстановится. Zookeeper продолжает получать пинги и считает, что брокер жив и здоров.

Рис. 25. Сценарий 2. ISR сжался только до лидера
Сценарий 3. Фолловер видит лидера, но не видит Zookeeper
Фолловер отделяется от Zookeeper, но не от брокера с лидером. В результате фолловер продолжает делать запросы выборки и быть членом ISR. Zookeeper больше не получает пинги и регистрирует падение брокера, но поскольку это только фолловер, нет никаких последствий после восстановления.
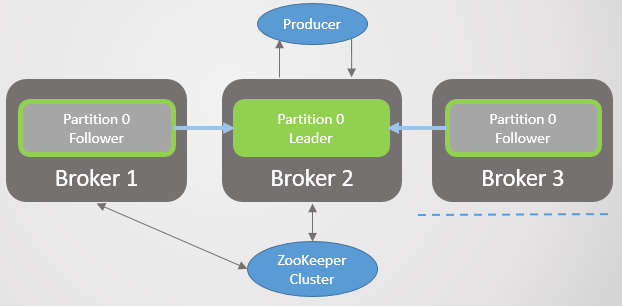
Рис. 26. Сценарий 3. Фолловер продолжает отправлять лидеру запросы на выборку
Сценарий 4. Лидер видит фолловеров, но не видит Zookeeper
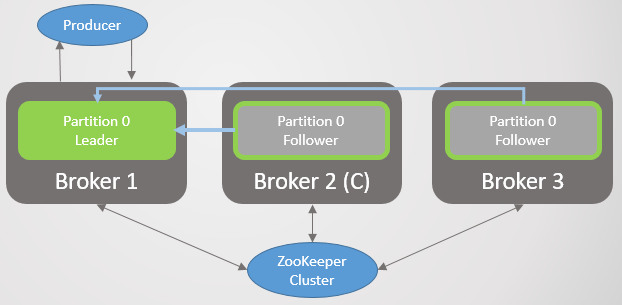
Рис. 27. Сценарий 4. Лидер и два фолловера
Лидер отделен от Zookeeper, но не от брокеров с фолловерами.

Рис. 28. Сценарий 4. Лидер изолирован от Zookeeper
Через некоторое время Zookeeper зарегистрирует падение брокера и уведомит об этом контроллер. Тот выберет среди фолловеров нового лидера. Однако исходный лидер будет продолжать думать, что он является лидером и будет продолжать принимать записи с acks=1. Фолловеры больше не отправляют ему запросы на выборку, поэтому он посчитает их мертвыми и попытаться сжать ISR до самого себя. Но поскольку у него нет подключения к Zookeeper, он не сможет это сделать, и в этот момент откажется от дальнейшего приема записей.
Сообщения acks=all не получат подтверждения, потому что сначала ISR включает все реплики, а до них сообщения не доходят. Когда первоначальный лидер попытается удалить их из ISR, он не сможет этого сделать и вообще перестанет принимать какие-либо сообщения.
Клиенты вскоре замечают смену лидера и начинают отправлять записи на новый сервер. Как только сеть восстанавливается, исходный лидер видит, что он больше не лидер, и обрезает свой лог до значения HW, которое было у нового лидера в момент сбоя, чтобы избежать расхождения логов. Затем он начнет отправлять запросы на выборку новому лидеру. Теряются все записи исходного лидера, не реплицированные новому лидеру. То есть будут потеряны сообщения, не подтвержденные первоначальным лидером в те несколько секунд, когда работало два лидера.

Рис. 29. Сценарий 4. Лидер на брокере 1 становится фолловером после восстановления сети
Сценарий 5. Фолловер полностью отделен и от других узлов Kafka, и от Zookeeper
Фолловер полностью изолирован и от других узлов Kafka, и от Zookeeper. Он просто удаляется из ISR, пока сеть не восстановится, а потом догоняет остальных.
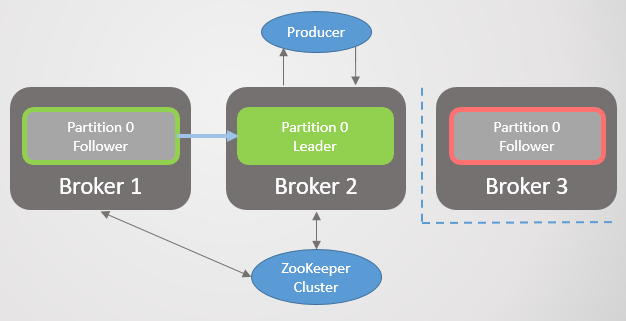
Рис. 30. Сценарий 5. Изолированный фолловер удаляется из ISR
Сценарий 6. Лидер полностью отделен и от других узлов Kafka, и от Zookeeper

Рис. 31. Сценарий 6. Лидер и два фолловера
Лидер полностью изолирован от своих фолловеров, контроллера и Zookeeper. В течение короткого периода он продолжит принимать записи с acks=1.

Рис. 32. Сценарий 6. Изоляция лидера от других узлов Kafka и Zookeeper
Не получив запросов по истечении replica.lag.time.max.ms, он попытается сжать ISR до самого себя, но не сможет этого сделать, поскольку нет связи с Zookeeper, тогда он прекратит принимать записи.
Между тем, Zookeeper отметит изолированного брокера как мертвого, а контроллер выберет нового лидера.
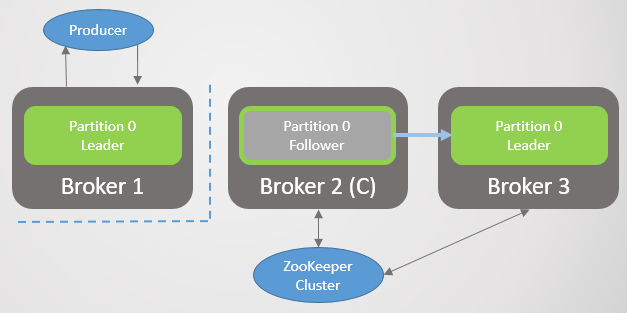
Рис. 33. Сценарий 6. Два лидера
Исходный лидер может принимать записи в течение нескольких секунд, но затем перестает принимать любые сообщения. Клиенты обновляются каждые 60 секунд с последними метаданными. Они будут проинформированы о смене лидера и начнут отправлять записи новому лидеру.

Рис. 34. Сценарий 6. Производители переключаются на нового лидера
Будут потеряны все подтверждённые записи, сделанные исходным лидером с момента потери связности. Как только сеть восстановлена, исходный лидер через Zookeeper обнаружит, что больше не является лидером. Затем усечет свой лог до HW нового лидера на момент избрания и начнет отправлять запросы как фолловер.

Рис. 35. Сценарий 6. Исходный лидер становится фолловером после восстановления связности сети
В этой ситуации в течение короткого периода может наблюдаться логическое разделение, но только если acks=1 и min.insync.replicas тоже 1. Логическое разделение автоматически завершается либо после восстановления сети, когда исходный лидер понимает, что он больше не лидер, либо когда все клиенты понимают, что лидер изменился и начинают писать новому лидеру — в зависимости от того, что произойдет раньше. В любом случае произойдет потеря некоторых сообщений, но только с acks=1.
Существует другой вариант этого сценария, когда непосредственно перед разделением сети фолловеры отстали, а лидер сжал ISR до одного себя. Затем он изолируется из-за потери связности. Избирается новый лидер, но первоначальный лидер продолжает принимать записи, даже acks=all, потому что в ISR кроме него никого нет. Эти записи будут потеряны после восстановления сети. Единственный способ избежать такого варианта — min.insync.replicas = 2.
Сценарий 7. Узел контроллера Kafka не видит другой узел Kafka
В целом, после потери связи с узлом Kafka контроллер не сможет передать ему никакой информации по изменению лидера. В худшем случае это приведет к краткосрочному логическому разделению, как в сценарии 6. Чаще всего брокер просто не станет кандидатом на лидерство в случае отказа последнего.
Сценарий 8. Контроллер Kafka не видит Zookeeper
От отвалившегося контроллера Zookeeper не получит пинга и выберет контроллером новый узел Kafka. Исходный контроллер может продолжать представлять себя таковым, но он не получает уведомления от Zookeeper, поэтому у него не будет никаких задач для выполнения. Как только сеть восстановится, он поймёт, что больше не является контроллером, а стал обычным узлом Kafka.
Выводы из сценариев
Мы видим, что потеря связности фолловеров не приводят к потере сообщений, а просто временно уменьшает избыточность, пока сеть не восстановится. Это, конечно, может привести к потере данных, если потеряны один или несколько узлов.
Если из-за потери связности лидер отделился от Zookeeper, это может привести к потере сообщений с acks=1. Отсутствие связи с Zookeeper вызывает кратковременное логическое разделение с двумя лидерами. Эту проблему решает параметр acks=all.
Параметр min.insync.replicas в две или более реплик дает дополнительные гарантии, что такие краткосрочные сценарии не приведут к потере сообщений, как в сценарии 6.
Резюме по потере сообщений
Перечислим все способы, как можно потерять данные в Kafka:
- Любой сбой лидера, если сообщения подтверждались с помощью acks=1
- Любой нечистый (unclean) переход лидерства, то есть на фолловера за пределами ISR, даже с acks=all
- Изоляция лидера от Zookeeper, если сообщения подтверждались с помощью acks=1
- Полная изоляция лидера, который уже сжал группу ISR до самого себя. Будут потеряны все сообщения, даже acks=all. Это верно только в том случае, если min.insync.replicas=1.
- Одновременные сбои всех узлов раздела. Поскольку сообщения подтверждаются из памяти, некоторые могут ещё не записаться на диск. После перезагрузки серверов некоторых сообщений может не хватать.
Нечистых переходов лидерства можно избежать, либо запретив их, либо обеспечив избыточность не менее двух. Наиболее прочная конфигурация — это сочетание acks=all и min.insync.replicas больше 1.
Прямое сравнение надёжности RabbitMQ и Kafka
Для обеспечения надёжности и высокой доступности обе платформы реализуют систему первичной и вторичной репликации. Однако у RabbitMQ есть ахиллесова пята. При воссоединении после сбоя узлы отбрасывают свои данные, а синхронизация блокируется. Этот двойной удар ставит под вопрос долговечность больших очередей в RabbitMQ. Вам придётся смириться либо с сокращением избыточности, либо с длительными блокировками. Снижение избыточности увеличивает риск массовой потери данных. Но если очереди небольшие, то ради обеспечения избыточности с краткими периодами недоступности (несколько секунд) можно справиться с помощью повторных попыток подключения.
В Kafka нет такой проблемы. Она отбрасывает данные только с точки расхождения лидера и фолловера. Все общие данные сохраняются. Кроме того, репликация не блокирует систему. Лидер продолжает принимать записи, пока новый фолловер его догоняет, так что для девопсов присоединение или воссоединение кластера становится тривиальной задачей. Конечно, по-прежнему остаются проблемы, такие как пропускная способность сети при репликации. Если одновременно добавляются несколько фолловеров, можно столкнуться с лимитом пропускной способности.
RabbitMQ превосходит Kafka в надёжности при одновременном сбое нескольких серверов в кластере. Как мы уже говорили, RabbitMQ отправляет паблишеру подтверждение только после записи сообщения на диск у мастера и всех зеркал. Но это добавляет дополнительную задержку по двум причинам:
- fsync каждые несколько сотен миллисекунд
- Сбой зеркала могут заметить только по истечении времени жизни пакетов, которые проверяют доступность каждого узла (net tick). Если зеркало тормозит или упало, это добавляет задержку.
Kafka делает ставку на то, что если сообщение хранится на нескольких узлах, можно подтверждать сообщения, как только они попали в память. Из-за этого возникает риск потери сообщений любого типа (даже acks=all, min.insync.реплики=2) в случае одновременного отказа.
В целом Kafka демонстрирует более высокую производительность по и изначально спроектирована для кластеров. Количество фолловеров можно увеличить до 11-ти, если это нужно для надёжности. Коэффициент репликации 5 и минимальное число реплик в синхронизированном состоянии min.insync.replicas=3 сделают потерю сообщения очень редким событием. Если ваша инфраструктура способна обеспечить такой коэффициент репликации и уровень избыточности, то можете выбрать этот вариант.
Кластеризация RabbitMQ хороша для небольших очередей. Но даже маленькие очереди могут быстро вырасти при больших трафике. Как только очереди становятся большими, придётся делать жесткий выбор между доступностью и надёжностью. Кластеризация RabbitMQ лучше всего подходит для не самых типичных ситуаций, где преимущества гибкости RabbitMQ перевешивают любые недостатки его кластеризации.
Одно из противоядий от уязвимости RabbitMQ в отношении больших очередей — разбить их на множество меньших. Если не требовать полного упорядочения всей очереди, а только соответствующих сообщений (например, сообщений конкретного клиента), или вообще ничего не упорядочивать, то такой вариант приемлем: посмотрите мой проект Rebalanser для разбиения очереди (проект пока на ранней стадии).
Наконец, не забывайте о ряде багов в механизмах кластеризации и репликации как у RabbitMQ, так и у Kafka. Со временем системы стали более зрелыми и стабильными, но ни одно сообщение никогда не будет на 100% защищено от потери! Кроме того, в дата-центрах случаются крупномасштабные аварии!
Если я что-то пропустил, допустил ошибку или вы не согласны с любым из тезисов, не стесняйтесь написать комментарий или связаться со мной.
Меня часто спрашивают: «Что выбрать, Kafka или RabbitMQ?», «Какая платформа лучше?». Правда в том, что это действительно зависит от вашей ситуации, текущего опыта и т. д. Я не решаюсь высказывать своё мнение, поскольку будет слишком большим упрощением рекомендовать какую-то одну платформу для всех вариантов использования и возможных ограничений. Я написал этот цикл статей, чтобы вы могли сформировать собственное мнение.
Хочу сказать, что обе системы являются лидерами в данной области. Возможно, я немного предвзят, потому что по опыту своих проектов больше склонен ценить такие вещи, как гарантированное упорядочение сообщений и надёжность.
Я вижу другие технологии, которым не хватает этой надёжности и гарантированного упорядочения, затем смотрю на RabbitMQ и Kafka — и понимаю невероятную ценность обеих этих систем.
Комментарии (3)

Dimano
09.11.2019 09:24Спасибо за перевод. Для меня остаётся непонятным понятие "большая очередь" каков порядок цифр? Тысяча, сто тысяч, миллион сообщений?

RNZ
09.11.2019 15:30rabbitmq-server:
- не умеет автоматически закрывать отвалившие подключения, при этом подключения поддерживаются в established состоянии (и это не связанно с настройками tcp хоста), а для закрытия в ручную требует выяснить какие именно подключения отвалились.
- производительность кластера сильно ниже производительности отдельного хоста, даже если все (-1) ноды ram, а интерконнект 10Gbps.
kafka — требует zookeeper, т.е. имеем по jvm на каждый хост kafka и по jvm на каждый хост zookeeper…
Есть nats и nats stream server...
maxim_ge
Вот мне нравится такой вариант перевода — когда при появлении термина в тексте его вариант для русского языка сопровождается оригиналом, и далее используется русскоязычная версия. Понимаю, что весь текст так трудно проработать, например, просочился «топик», можно было бы использовать «тема».
Но в целом — хороший перевод на хорошую тему.