

Низкочастотные запросы (для экономии чернил будем называть их НЧ) в SEO нужны. Особенно когда по СЧ и ВЧ топ забит колдунщиками, контекстом и агрегаторами. С НЧ при небольшом бюджете можно занять верхние строчки выдачи и получать недорогой и стабильный трафик.
Но тут проблема: если вы собираете НЧ с помощью привычных Яндекс.Вордстата и Планировщика Google, ваши конкуренты делают то же самое. Решение — найти НЧ, о которых ваши конкуренты не догадываются (а если и догадываются, то не все). Рассказываем, как это сделать.
Парсинг аккордеона с вопросами в Google-поиске с помощью Xpath
Когда вы в Google-поиске вводите информационный запрос, часто появляется блок с похожими запросами. Здесь выводятся вопросы по теме. При клике по вопросу открывается рекомендованный контент и появляются новые вопросы.
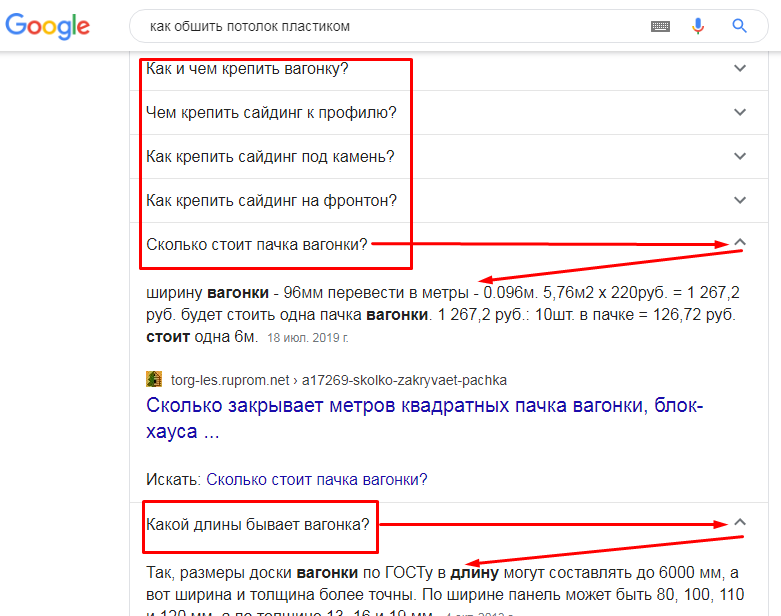
Так вот, если собрать эти вопросы, вы получите НЧ фразы для оптимизации под них блоков контента или целых страниц. Можно пойти простым путем: открыть как можно больше вопросов, скопировать их и вставить в Excel. Но вы получите тогда примерно такую картину:

Придется потом сидеть и все это чистить.
Более изящный способ собрать вопросы — спарсить с помощью Xpath. Кто не знает, Xpath — это язык запросов к элементам XML-документа. Но не будем вдаваться в детали — просто покажем, как это работает.
1. Установите расширение Scraper для Chrome. Это бесплатный XPath-парсер.
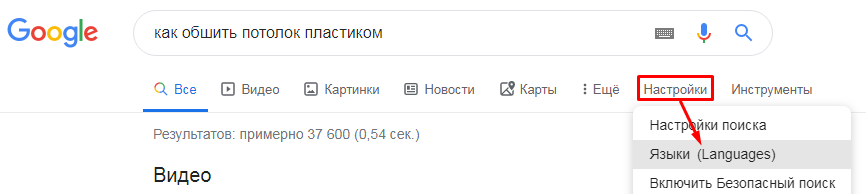
2. Откройте поисковик Google и установите английский язык (это нужно, чтобы парсер работал корректно).
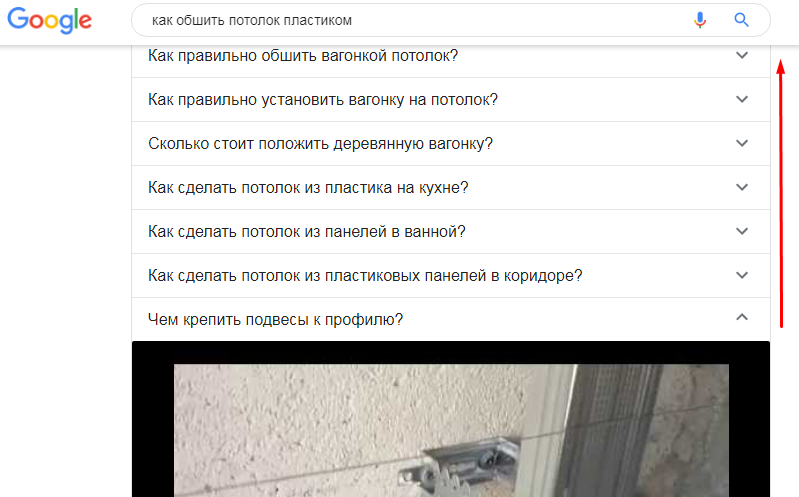
3. Введите запрос и найдите блок «People also ask». Откройте как можно больше вопросов (например, 50, 100 или даже 200). Лайфхак: вопросы намного удобней открывать снизу вверх.
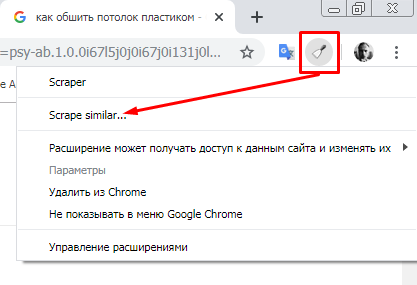
4. Кликните по значку установленного расширения и в выпадающем меню выберите «Scrape similar…».
5. В открывшемся приложении в блоке Selector выберите Xpath и в поле введите текст //g-accordion-expander (обратите внимание, чтобы блок Column был заполнен точно так же, как показано на скриншоте). После этого нажмите Scrape.
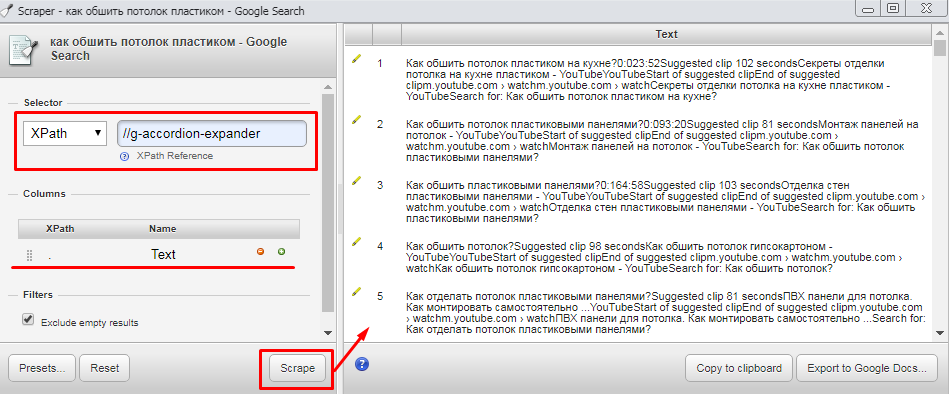
Итак, данные мы спарсили. Но нужно еще их привести в юзабельный вид. Если просто скопировать и вставить в Excel, то получится не совсем приятно:
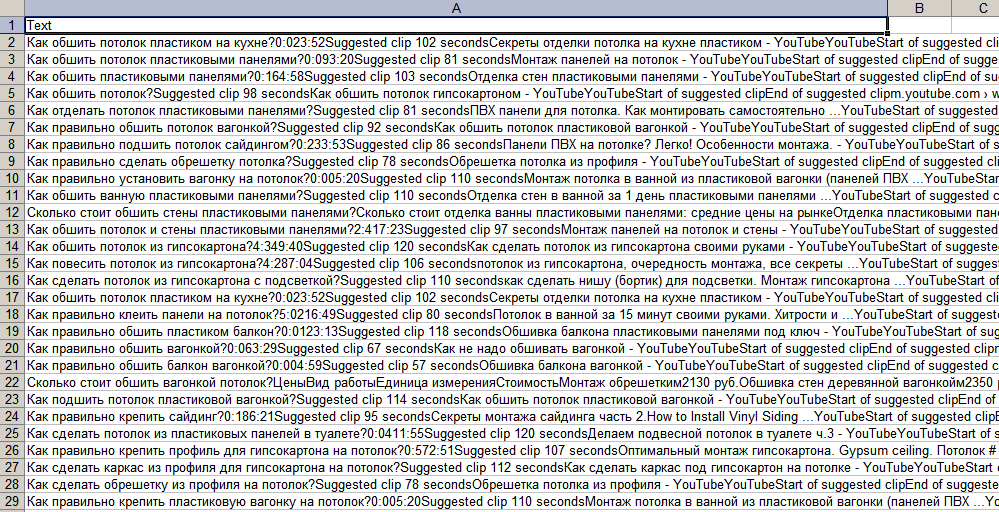
Можно, конечно, помудрить с формулами и разбить этот текст на колонки. Но есть более простое решение.
Создайте копию шаблона. Этот шаблон сделан в Google Таблицах и помогает извлечь данные, полученные в результате парсинга вопросов.
Откройте свою копию шаблона, перейдите на лист «Google Questions and Answers», установите курсор в ячейке А10 и нажмите Ctrl+Shift+V.
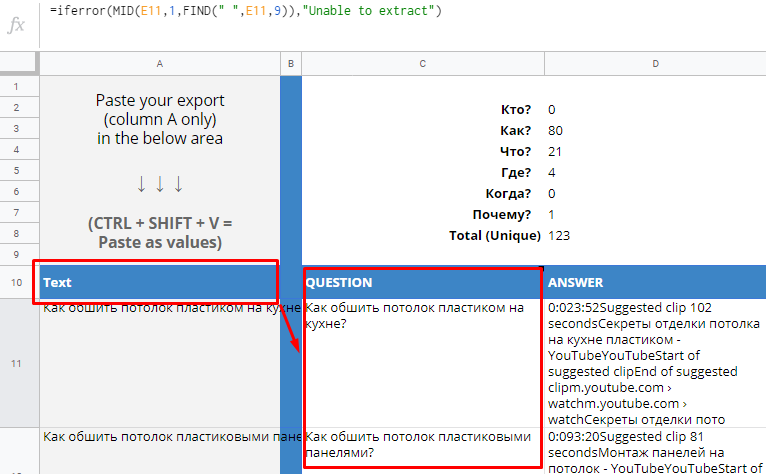
Далее перейдите на лист «Clean Data» и загрузите список вопросов.
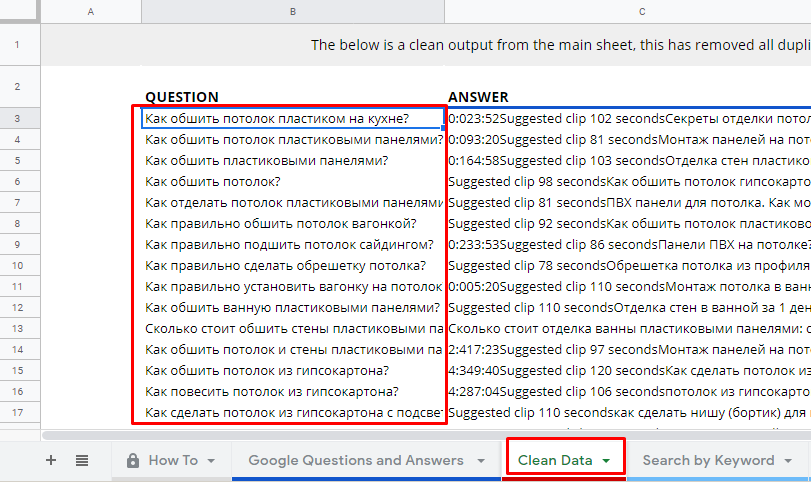
Теперь у вас не просто список НЧ запросов, но и масса идей для контента.
Подбор «хвостов» с помощью QA-площадок
Площадки вопросов-ответов — это хороший способ найти «живую» семантику. В России самая популярная — Ответы Mail.ru. Также есть тематические QA-площадки (например, для айтишников — Toster). Среди западных QA-площадок самая известная — Quora.
Итак, как с ними работать. Заходим на выбранный QA-сайт и вводим интересующий запрос. Получаем похожие вопросы по теме. По сути, это и есть НЧ семантика.
Копировать вопросы вручную — не наш путь. Выделяем любой вопрос, кликаем по нему правой кнопкой мыши и контекстном меню выбираем «Scrape similar…» (используем расширение Scraper, о котором рассказывали в предыдущем пункте).
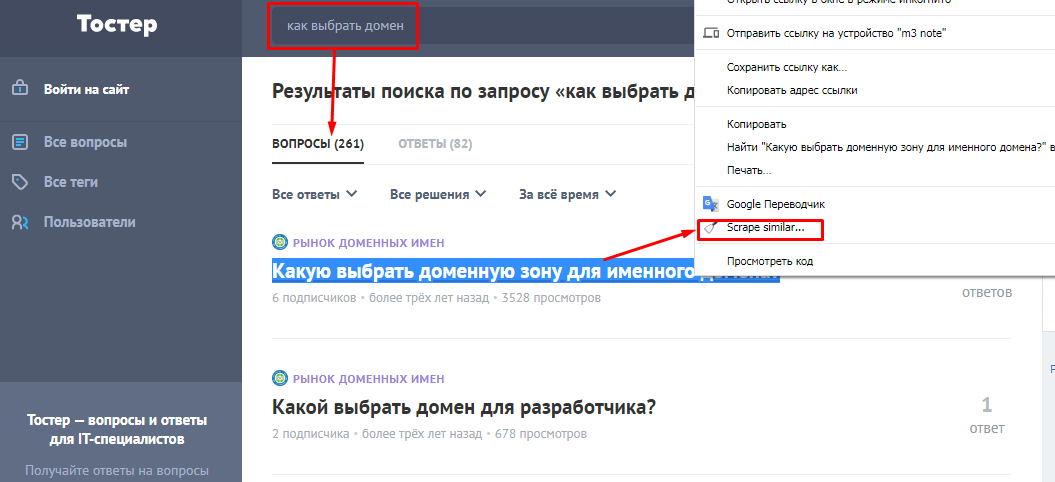
Парсер собирает все вопросы на странице. Копируем и забираем в «эксельку».
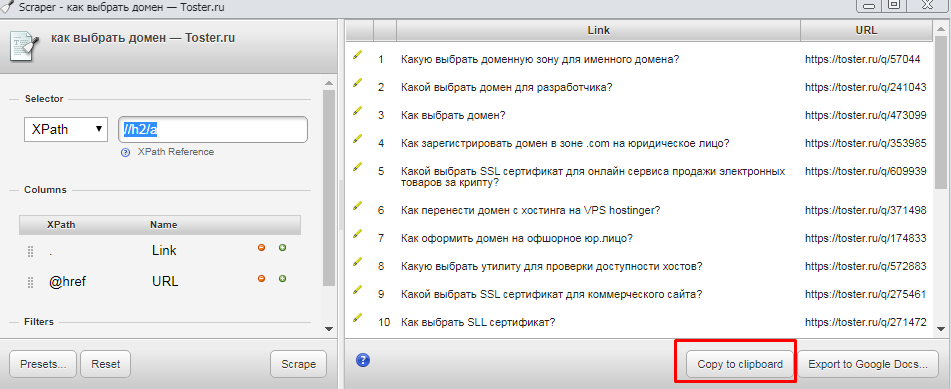
Если вы используете другой Xpath-парсер, кликните по интересующему объекту правой кнопкой мыши и в контекстном меню выберите «Просмотреть код». Кликните по подсвеченному участку кода правой кнопкой мыши и в пункте «Copy» выберите «Copy Xpath».
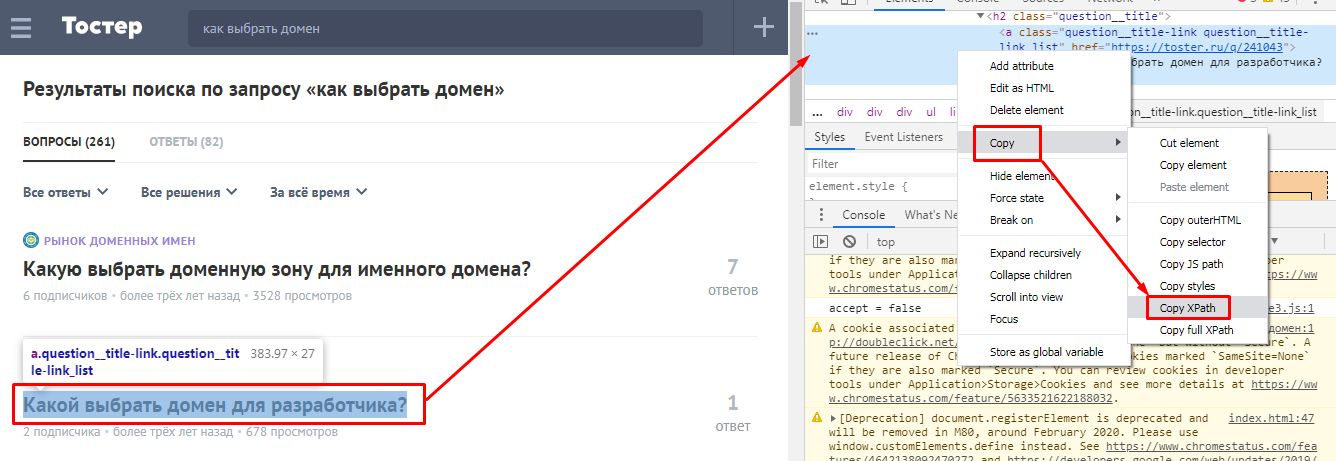
Полученный код вставьте в парсер и загрузите список URL для проверки. Например, это можно сделать в Screaming Frog SEO Spider. Как? Читайте здесь.
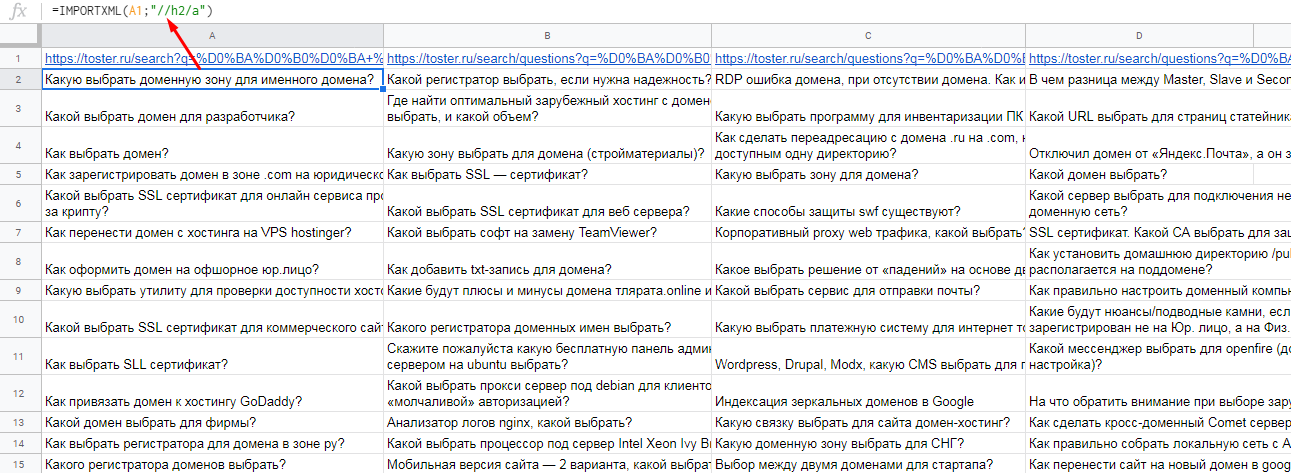
Бесплатная альтернатива — Google Таблицы. С помощью функции IMPORTXML и Xpath-запроса вы без проблем выгрузите данные со страницы.
Синтаксис формулы такой:
=IMPORTXML("URL";"Xpath-запрос")Достаточно указать URL, сослаться на этот URL в формуле, и Google автоматически спарсит все элементы страницы, которые соответствуют Xpath-запросу.
Больше о полезных формулах Google Таблиц для SEO читайте в нашей подборке.
Помимо QA-площадок можно найти НЧ с помощью сервиса AnswerThePublic. Он собирает вопросы с вхождением ключа, «хвосты» с предлогами, сравнения, связанные запросы. Раньше сервис был англоязычным, и приходилось переводить полученные ключи и вопросы. Но недавно появилась поддержка русского языка.
Сервис работает так: вводите ключевое слово, и получаете «вал» ключей с визуализацией связей:
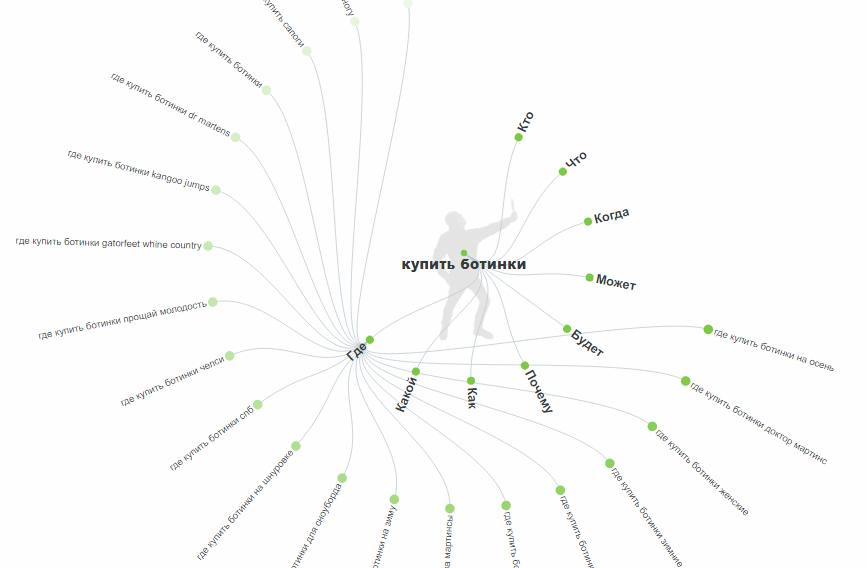
Для выгрузки ключевых слов нажмите «Download CSV».
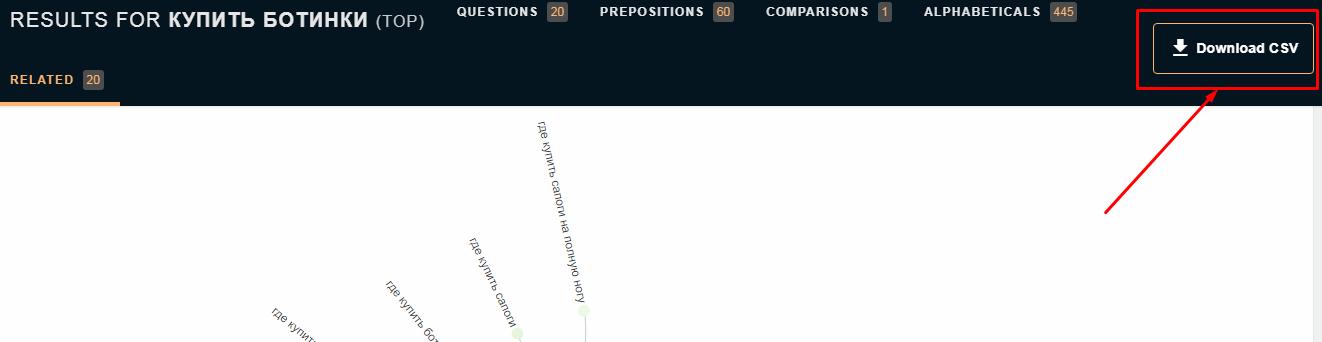
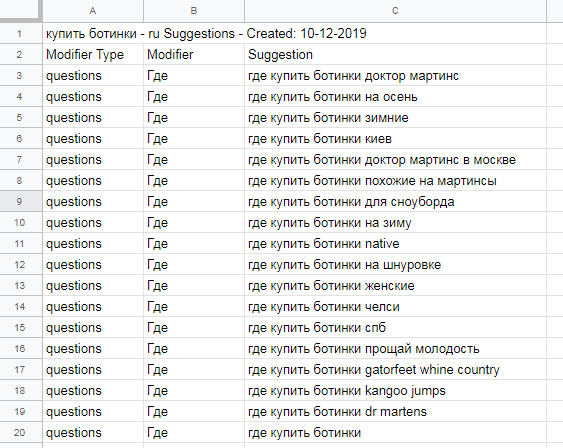
В загруженной таблице будут все собранные слова:
Парсинг семантики конкурентов с последующим ее углублением
Суть способа в том, чтобы собрать ключевые слова с сайтов конкурентов и от них уже углубиться в семантику. Так вы соберете ключи, которые, вероятно, упускают ваши конкуренты.
Для этой задачи подходит платформа PromoPult. Для ее использования нужно зарегистрироваться, добавить ваш сайт и создать проект. Система предложит список инструментов — выберите «Поисковое продвижение SEO».
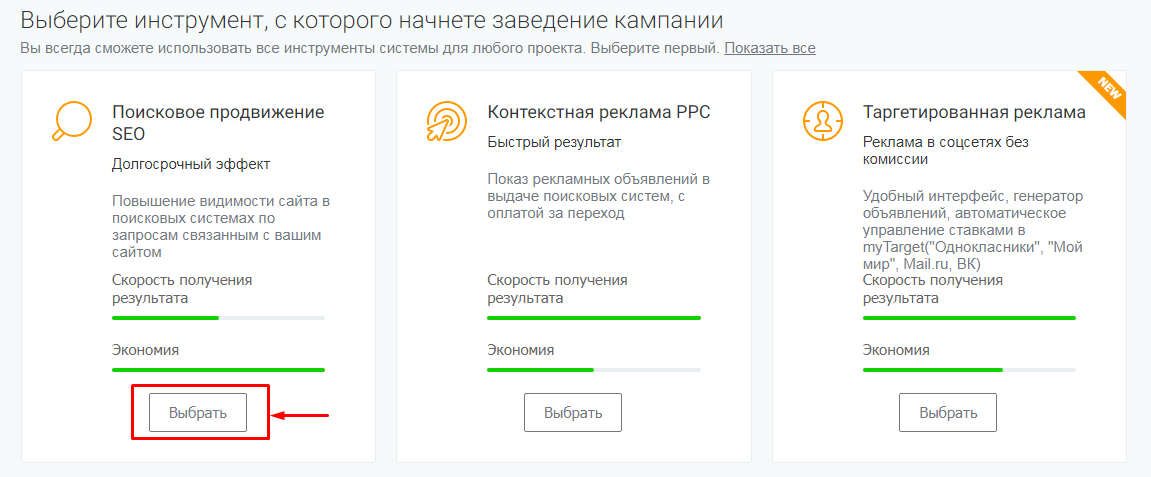
Далее укажите URL сайта, регион продвижение и назовите проект.
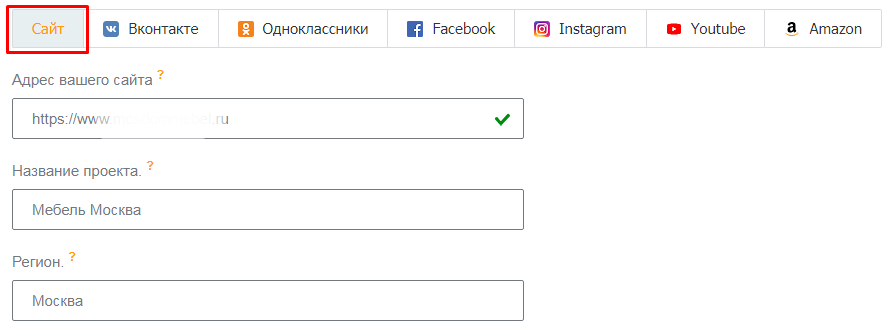
После того как вы нажмете «Создать проект», система начнет автоматически подбирать ключевые слова, по которым ваш сайт занимает ТОП-50 в Яндексе и/или Google. Их можно взять за основу и поискать «хвосты». Но нас сейчас интересует семантика конкурентов — переходим на вкладку «Слова ваших конкурентов». Добавляем URL конкурентов и нажимаем «Показать слова всех конкурентов».
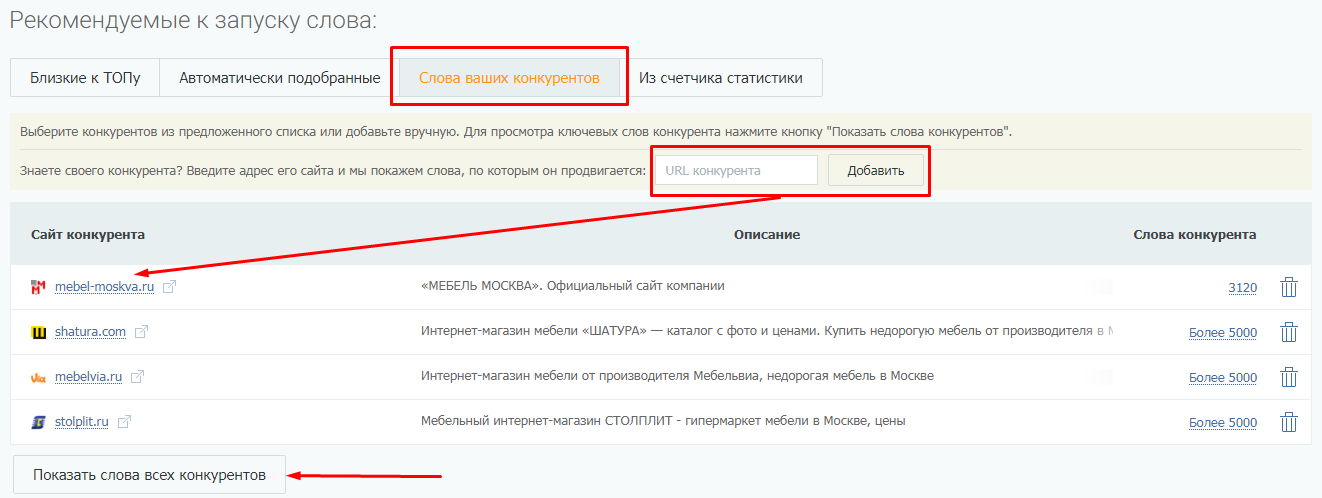
Отметьте слова, по которым хотите углубить семантику, и нажмите «добавить к опорным для расширения».
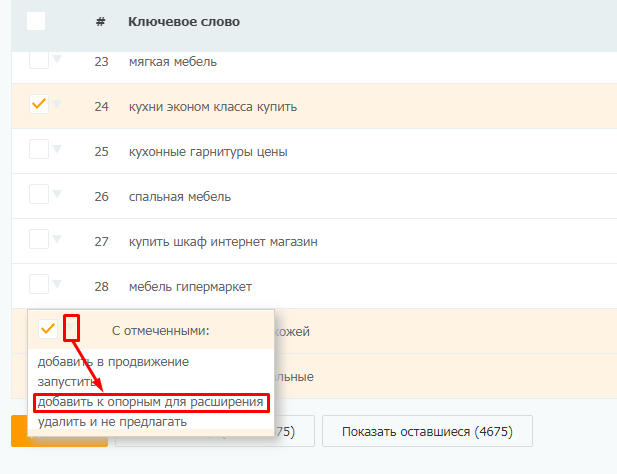
Опорные слова появятся в ручном подборщике (находится под списком фраз конкурентов). Сразу переключаемся в профессиональный режим.
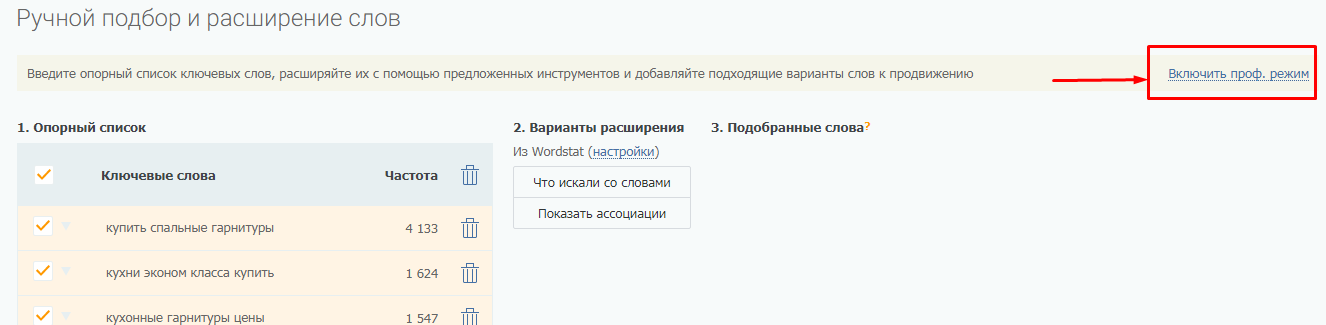
Далее есть разные варианты работы с опорными словами: углубиться на основе парсинга левой колонки Вордстат, собрать фразы-ассоциации (правая колонка Вордстат). Мы же воспользуемся инструментом «СЧ+НЧ». Он специально создан для подбора НЧ фраз на основе опорных ключей.
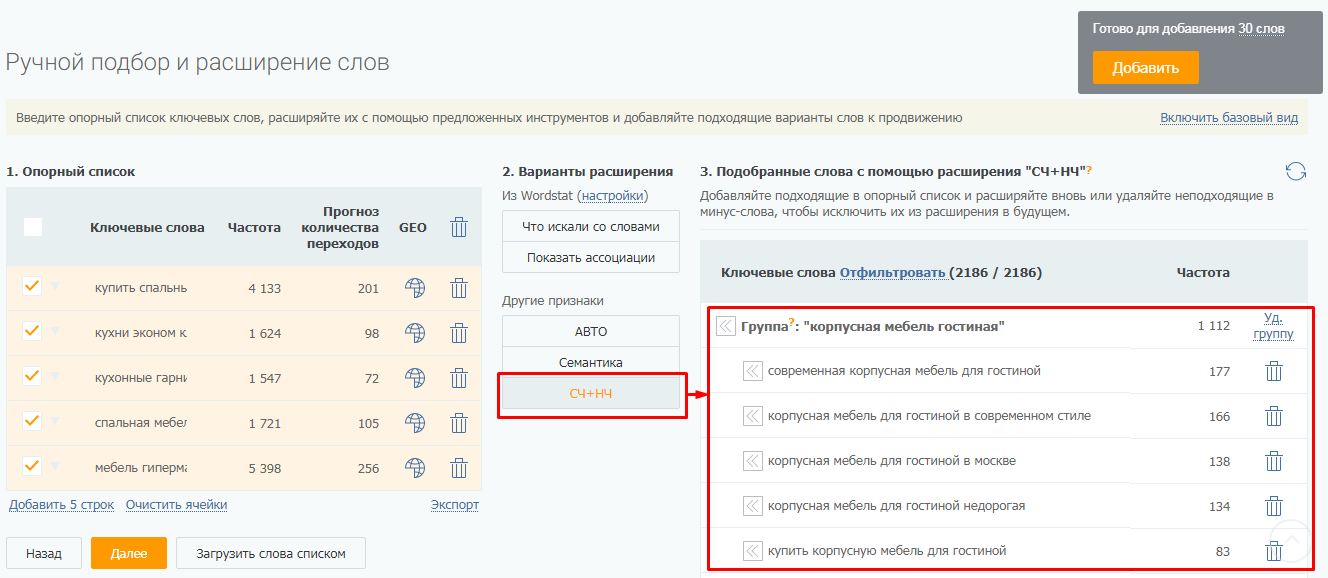
На основе всего 5 опорных фраз система собрала 2186 ключей. Вы можете добавлять собранные ключи к опорным и вновь углубляться. Для выгрузки ключей тут же есть функция экспорта.
Для использования автоматического и ручного подборщика PromoPult не нужно пополнять баланс, оплачивать подписку, нет ограничений на количество проверок, ключевых слов или функционал. Все бесплатно.
Детально работа подборщика на примере интернет-магазина гироскутеров разобрана здесь.
Выгрузка поисковых запросов из Google Ads/Яндекс.Директа
Если у вас есть активные рекламные кампании на поиске Яндекса и/или Google, вы без проблем пополните запасы НЧ фраз. Важно только, чтобы реклама была запущена по ключам в широком соответствии (фразовое и тем более точное — не вариант).
Рассмотрим, как выгрузить запросы, на примере кампании в Google Ads. Открываем кампанию и переходим в раздел «Ключевые слова» (вкладка «Запросы»). Затем скачиваем запросы.
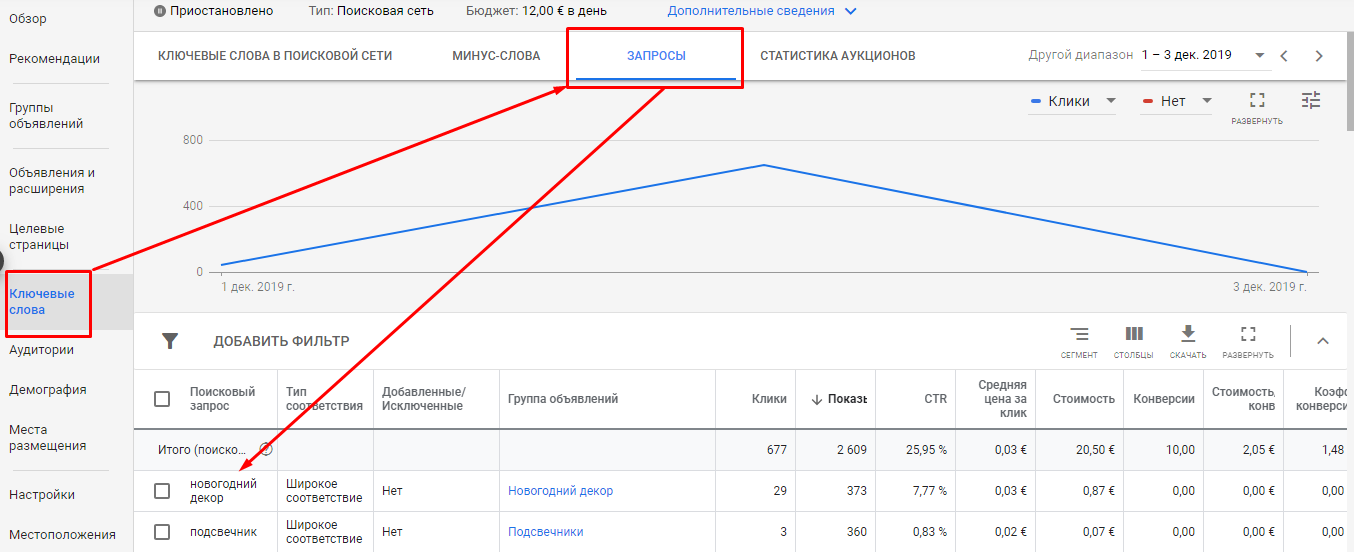
Если у вас нет рекламной кампании, вы можете запустить ее и буквально за неделю или даже меньше собрать запросы по базовым ключам.
Подход хорош тем, что вы получаете самую актуальную и разнообразную семантику. В итоге вы можете раньше конкурентов заточить под нее страницы (все-таки данные в тот же Вордстат поступают с задержкой).
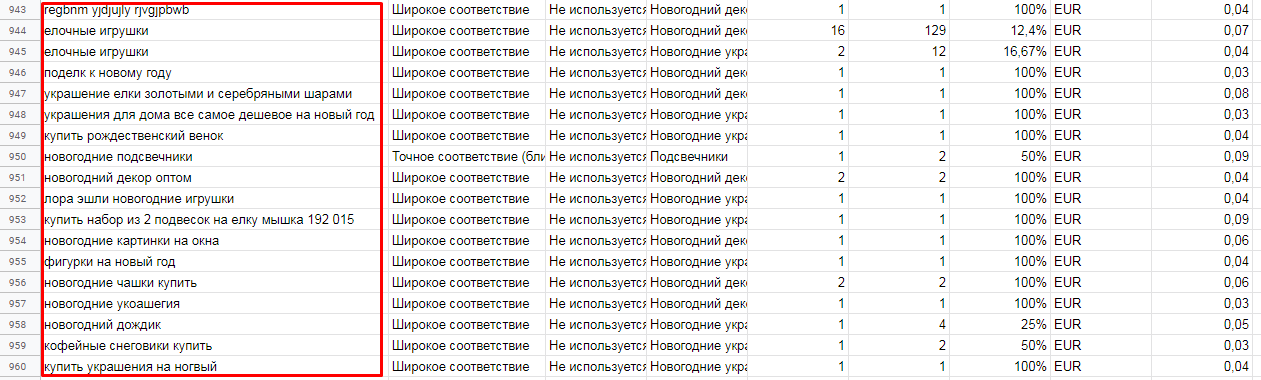
Вам останется проверить частотность запросов и выбрать подходящие из них. Кроме того, вы можете углубить семантику с помощью подборщика слов PromoPult, описанного выше.
Что делать с полученным массивом ключей? То, что вам нужно: добавлять новые страницы на сайт, писать новые статьи или оптимизировать старые под дополнительные ключи, пересобрать вообще сем.ядро — на ваше усмотрение.
NikSolovov
Еще многие до сих пор заполняют тег keywords можно и от туда тащить, во многих конкурентных тематиках, это обычная практика)
Clickru Автор
По данным исследования, тег keywords заполнен примерно на трети сайтов. Конечно, можно и отсюда парсить. Функция =IMPORTXML("URL";"//keywords") справится с этим без проблем. Но на практике тут особо нечем поживиться в плане НЧ запросов — чаще здесь прописывают более общие ключи, нежели интересные с хвостами. Хотя способ имеет право на жизнь, почему нет)