

Это скорее не статья, а небольшая заметка о некоторых особенностях работы с большими таблицами в MySQL.
Причиной написания стало вроде бы будничное добавление новой колонки в таблицу. Но все оказалось не так просто, как предполагалось.
Итак, как-то вечерком, дабы не тревожить наших дорогих заказчиков, понадобилось нам добавить колонку в таблицу.
Чтобы было понятнее, характеристики таблицы и базы:
- размер таблицы 110Gb
- число строк: 7.5 млн
- storage engine: InnoDB
- есть два sql-сервера, соединенных по схеме master-slave, при этом master — на SSD, а slave — на HDD
Вроде бы очевидное решение для добавления колонки — Alter Table.
alter table table_name add source varchar(32)Им мы и воспользовались (да, мы понимали, что это плохо, но в данном конкретном случае риски были минимальны).
Результаты оказались довольно неприятными:
- на мастере процесс добавления колонки шел около часа (!)
- на слейве он начался после окончания процесса на мастере и продолжался около 8 часов (!!)
- во время выполнения alter table на слейве полностью остановилась репликация данных (!!!)
Но нет худа без добра: небольшой бонус оказался в том, что после добавления колонки размер таблицы уменьшился на 10%.
На графиках ниже это наглядно видно.
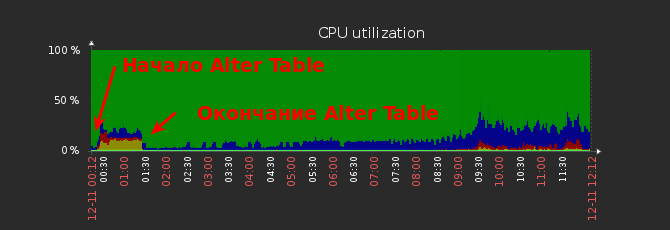
График загрузки CPU на мастере.

График загрузки CPU на слейве.

Отставание репликации.
Какие неприятности ждут тех, кто делает это на боевых таблицах?
Во-первых, на время выполнения Alter Table нельзя писать данные в таблицу (но можно читать). На самом деле это зависит от версии MySQL, в последних это не так, но тем не менее надо понимать, на что способна именно Ваша версия, дабы избежать неприятностей.
Соответственно, если таблица большая, то время недоступности будет значительным (как у нас, при использовании SSD это заняло час, а на обычном диске — 8 часов), что вряд ли ожидают Ваши заказчики.
Во-вторых, как в нашем случае, на время выполнения Alter Table на слейве полностью остановилась синхронизация всех таблиц, а не только той, которую мы изменяли. Поэтому в случае, если у Вас данные на втором сервере критичны и должны быть свежими — Вы рискуете остаться без обновлений со всеми вытекающими последствиями.
Еще один неочевидный момент, с которым мы столкнулись во время добавления колонки (но это было в другой раз) — на диске нужно дополнительное место.
Дело в том, что некоторые изменения таблиц пересоздают таблицу с нуля, поэтому места нужно не меньше, чем уже существующая таблица. Для больших таблиц, соответственно, места нужно, мягко говоря, немало. Согласно документации, временная таблица создается в том же каталоге, что и оригинальная.
Кроме того, во время выполнения всяких Alter Table все изменения записываются в лог-файл, чтобы после изменений накатить данные за то время, в течение которого проводилась операция. И тут тоже может ждать неприятный сюрприз: если таблица изменяется долго, а объем операций большой, то может закончится не только место на диске, но и превыситься лимит на размер файла, указанный в настройках SQL. В любом случае Вас ожидает «the online DDL operation fails, and uncommitted concurrent DML operations are rolled back».
Мы столкнулись с тем, что каталог для временных файлов был маловат, в результате пришлось переопределить innodb_tmpdir.
Посмотреть, куда указывает переменная в данный момент, можно так:
select @@GLOBAL.innodb_tmpdir;Имейте ввиду, что размер временного каталога также может быть нужен размером с таблицу + индексы. В общем, запасайтесь местом.
Дабы не повторять документацию, более детально читайте по ссылке https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-space-requirements.html
А как же делать надо? На самом деле нет единого рецепта на все случаи жизни.
Один из возможных вариантов, как делаем мы для таблиц, которые не критичны на обновление:
- Создаем новую таблицу с нужной структурой
- Заполняем поля из старой таблицы
- Удаляем или переименовываем старую таблицу
- Переименовываем новую
Повторюсь, что это работает для не критичных к обновлению таблиц. И при этом позволяет избежать блокировки репликации. При этом надо учитывать, что заполнение новой таблицы надо делать так, чтобы давать возможность продолжать репликацию, а поскольку она проходит последовательно, то нельзя обойтись одним sql-выражением, надо разбивать на несколько маленьких запросов, между выполнениями которых будет проходить репликация других данных. В других случаях возможны другие варианты, может быть кто-нибудь поделится в комментариях.
UPD. Пользователь syavadee посоветовал использовать percona online schema change. По сути она реализует описанный выше алгоритм с дополнительными плюшками.
UPD. Пользователь arheops рекомендует включить parallel replication/gtid для решения проблем с репликацией.
Ну и попутно, иногда, чтобы понять, насколько большая таблица и сколько в ней строк, нужно, как учат, сделать
select count(*) from table_nameНо на больших и нагруженных таблицах это тоже не самая быстрая операция, особенно когда у вас с пол миллиона строк и больше.
Поэтому для примерной оценки объема можно воспользоваться следующим способом:
SHOW TABLE STATUS FROM express where name='table_name'К сожалению, на движке InnoDB полученный размер может отличаться процентов на 50 (в нашем случае с таблицей выше реальное число записей порядка 7.5 млн, а указанный способ показал только 5 млн), но для ориентировочной оценки это вполне подходит.
На этом все, надеюсь, заметка кому-то поможет избежать больших неприятностей с якобы безобидными командами SQL.
Комментарии (27)

VuX
11.12.2019 14:13Значение из SHOW TABLE STATUS судя по документации может отличаться на 40%-50% от реальных и рекомендуется использовать SELECT COUNT(*) для точных значений.

eaa Автор
11.12.2019 14:19Вопрос в том, что именно Вы хотите получить. Если Вас не пугает время выполнения и лишняя нагрузка и Вам реально нужно более-менее точное значение, то COUNT как раз то, что нужно.
Но даже пока вы считаете SELECT COUNT, значения могут быть добавлены или удалены, т.е. не факт, что значение будет точным.
Но часто точное значение и не нужно, и тогда приходят альтернативные варианты. Т.е., например, исходя из того же SHOW TABLE STATUS Вы можете приблизительно понять, точно ли Вы хотите запустить SELECT COUNT, или на таких объемах это нежелательно, или может запустить-то надо, но когда нагрузка спадет. Это уже область нюансов, где единственного верного решения нет.
apapacy
11.12.2019 14:34Пара слов про Alter Table
Недавно был удивлен тем что в Postgres добавление колонки это очень быстро.
Раньше был ошибочно уверен, что это общая для всех систем управления реляционными базами данных проблемаvvm13
11.12.2019 15:31Скорее удивительно, почему MySQL так странно себя ведёт.

Antohin
11.12.2019 19:28+1Все очень сильно зависит как от архитектуры словаря базы, так и принципов хранения данных.
Postgres фактически меняет только метаданные о таблице, никак не затрагивая самих данных. Поскольку Postgres это версионная СУБД, то при заполнении нового столбца значениями, будут создаваться новые версии строк, но точно также они бы создавались при изменении значений «старых» столбцов. С одной стороны мы растягиваем во времени процесс увеличения места под таблицу и делаем это только по необходимости, но платим за это тем, что в таблице остаются старые версии строк даже когда они нам уже не нужны. Таким образом если мы проставим значения нового столбца для всех строк, то таблица может вырасти более чем в 2 раза и придется ее жать vacuum'ом. И да, ему нужен эксклюзивный доступ к таблице. Так что проблема та же, просто она откладывается на потом.
В Oracle добавление нового поля тоже выполняется быстро. Там фишка в том что «хвостовые» значения столбцов не хранятся в блоках данных пока их значения null. Но при попытке установки значения, если в блоке не хватит места, то «хвост» строки уедет в другой блок, т.н. chained rows и чтобы прочитать строку придется физически читать 2 блока. Если таких строк много, то производительность может упасть в 2 раза. И да, придется фактически пересоздавать таблицу (alter table move...) что тоже требует эксклюзивной блокировки на таблицу и требует больших ресурсов.
Так что хотя везде свои тонкости, закон сохранения никто не отменял

NickyX3
11.12.2019 15:01Но на больших и нагруженных таблицах это тоже не самая быстрая операция, особенно когда у вас с пол миллиона строк и больше.
SELECT COUNT(*) на любых таблицах с автоинкрементным первичным ключом очень быстрая операция, ибо сервер и так хранит количество записей в схеме. Более того, для движков MyISAM/Aria вообще не будут дергаться никакие данные и получится план «Select tables optimized away». Для InnoDB/XtraDB такие запросы тоже достаточно быстрые, сервер знает количество ключей в индексе.
P.S> только что проверил на Aria табличке в 800к записей. Нулевое время. Завтра попрошу коллегу прогнать на XtraDB в 17кк записей, будет примерно тоже самоеeaa Автор
11.12.2019 15:20Я вынужден Вас разочаровать, это отнюдь не так быстро, как хотелось бы, ниже пример для базы на SSD — полторы минуты:
mysql> select count(*) from offer;
+-----------+
| count(*) |
+-----------+
| 681382000 |
+-----------+
1 row in set (1 min 34.53 sec)NickyX3
13.12.2019 08:43InnoDB скорее всего.
Сейчас проверили на табличке с сообщениями форума
Aria Engine
30кк строк. Время «нулевое», ну и план «Select tables optimized away» конечно.
Aria как раз потому, что чтения там очень много. InnoDB тормознее
Naves
11.12.2019 20:00ENGINE=InnoDB
46М записей, 38Гб таблица
другой вопрос, что ключ не автоинкрементный
mysqlmysql> explain SELECT COUNT(SOPInstanc) FROM dicomimages USE INDEX (PRIMARY);
+----+-------------+-------------+-------+---------------+---------+---------+--
----+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | r
ef | rows | Extra |
+----+-------------+-------------+-------+---------------+---------+---------+--
----+----------+-------------+
| 1 | SIMPLE | dicomimages | index | NULL | PRIMARY | 194 | N
ULL | 57212716 | Using index |
+----+-------------+-------------+-------+---------------+---------+---------+--
----+----------+-------------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(SOPInstanc) FROM dicomimages USE INDEX (PRIMARY);
+-------------------+
| COUNT(SOPInstanc) |
+-------------------+
| 46977734 |
+-------------------+
1 row in set (16 min 30.45 sec)
edo1h
11.12.2019 20:22+1а чем бы помог автоинкрементный индекс?
select max(id)он даст посчитать быстро, но это же не число строк
NickyX3
11.12.2019 15:11Вдогонку. Скорость Alter Table зависит не только от скорости дисков/объема доступной памяти и всех выше упомянутых вещей. Она сильно зависит от фрагментации таблицы в innodb, количества записей, типа добавляемой колонки (колонка int1 может добавится существенно быстрее varchar 256) и наличия индексом, которые возможно будет перестроены

skymal4ik
11.12.2019 17:12Интересно, а использование MariaDB дало бы какие-то бонусы, или нет? Есть среди местных жителей кто-то с такой экспертизой?
arheops
11.12.2019 21:10У меня mariadb 10.4 и большие таблицы постоянно(200m+).
Последней колонку добавляет быстро. Если в средину — долго.

disc
11.12.2019 21:26Начиная с MariaDB 10.3 появилась возможность мгновенного добавления новых колонок в таблицу, с некоторыми ограничениями.
Instant ADD COLUMN for InnoDB
NickyX3
13.12.2019 08:34Бонусы — Aria Engine. Правда есть и плюсы и минусы по сравнению с MyISAM, но плюсы часто перевешивают
alexkuzmenko7
11.12.2019 17:36zfs'a вам не хватает, он бы при компресии не увеличил на столько объем диска
eaa Автор
11.12.2019 17:38В реальности у нас mysql живет на zfs, иначе нам SSD мы бы просто не поместились.
arheops
11.12.2019 21:12+1Вопрос с репликацией решается через parallel replication/gtid. Естественно, если ваши транзакции не используют эту таблицу. Просто выставляете другой gtid для данной операции и репликация работает.
А вообще на больших таблицах я предпочитают сначала попробывать на slave чтоб узнать время, потом выбирается время минимальной загрузки и клиент предупреждается.

Akina
12.12.2019 13:22Вообще для понимания среды желательно было бы указать:
1) Исходную структуру таблицы (расчёты показывают, что у Вас там чуть ли не 14 килобайт на запись) — ибо от неё в значительной степени зависит, насколько сложным получится преобразование.
2) Сведения о том, какой алгоритм использовался реально для выполнения операции — COPY или INPLACE. В тексте запроса на изменение таблицы Вы вообще не указываете метод. С другой стороны, то, что потребовалось много пространства во временном каталоге, намекает на COPY, что на времени выполнения операции не могло не сказаться в худшую сторону.
3) innodb_file_per_table (хотя весь текст просто кричит о том, что установлено, но хотелось бы об этом узнать явно). Да и значение innodb_page_size тоже играет не последнюю роль.

gecube
12.12.2019 19:11Не спец в мускуле. Но у вас там, что ли, логическая репликация? Тогда в принципе все понятно...
eaa Автор
13.12.2019 23:17Что Вы имеете ввиду под логической репликацией?
gecube
13.12.2019 23:21Мне казалось, что это вполне устоявшийся термин. Нет?
Это когда на слейв передается сама команда sql, а он ее применяет. При этом могут быть спецэффекты, например, с автоинкрементными значениями или time().
Спрашиваю в противовес бинарной репликации, которая реальный diff измененных данных передает и, соответственно, лишена таких проблем, но и имеет свои особенности. Это если совсем краткоeaa Автор
13.12.2019 23:39С данными все понятно, оно так и есть (кстати, у нас стоит бинарная репликация в Ваших терминах), но вот при выполнении DDL на мастере, как по мне, наиболее логично все-таки менять структуру таблицы на слейве одной DDL командой, чем построчно, потому что структуру таблицы все равно менять надо, но зачем потом поштучно пустые значения новой колонки синхронизировать?
Vasyalike
13.12.2019 23:16Ещё вот такое может быть, я получал зависание на минуту, а бывает прям до смерти: https://blog.pythian.com/mysql-crashes-ddl-statement-lesson-purge-threads/
syavadee
percona online schema change
пробовали?
eaa Автор
Не было особой нужды, но судя по описанию того, как это работает, сей тул действует примерно так же, как я предлагал ручной алгоритм, правда там еще триггеры наброшены для апдейта новой таблицы, если были изменения за время процедуры.
Спасибо, может быть пригодится, не нам, так другим.