

Занимаясь подготовкой некоторых результатов для публикации в журнале, возник вопрос: как равномерно распределить данные вдоль оси в gnuplot. Вопрос решил, графики получил. Кому интересно как, прошу под кат.
Изначально, во время рабочего процесса, все графики строились в MS Excel. В нем достаточно удобно по-быстренькому набросать данные, построить парочку кривых и двигаться дальше. Но работая в MS Excel, не чувствуется контроль над результирующим рисунком. Поэтому при оформлении результатов для статей часто использую gnuplot.
Требуется получить вот такой график:

По такому набору данных
data.csv
7.3; 0.0251; 250; 217.9006251
5.3; 0.0348; 293; 238.6280188
3.3; 0.0398; 176; 177.7890558
7.4; 0.0413; 262; 229.6579533
3.2; 0.0438; 186; 180.6920998
7.2; 0.0468; 265; 233.6496388
5.1; 0.0486; 247; 248.6435206
5.2; 0.0685; 239; 263.0861645
3.4; 0.0697; 180; 199.4893097
3.1; 0.0717; 167; 200.9408317
4.3; 0.0718; 405; 358.2750638
2.2; 0.0728; 267; 255.5794728
1.1; 0.0797; 226; 314.1587397
1.3; 0.0797; 225; 314.1587397
1.2; 0.0822; 292; 315.9731422
2.4; 0.0852; 276; 264.5789092
1.4; 0.0879; 299; 320.1099799
6.4; 0.098; 362; 311.209506
2.3; 0.102; 331; 276.771694
2.1; 0.1021; 233; 276.8442701
6.1; 0.1182; 372; 325.8698782
4.1; 0.1263; 335; 397.8290383
4.4; 0.1436; 459; 410.3847036
4.2; 0.1455; 435; 411.7636495
6.2; 0.153; 360; 351.126361
Если прогнать это через gnuplot, то получится следующее: точки сливаются.
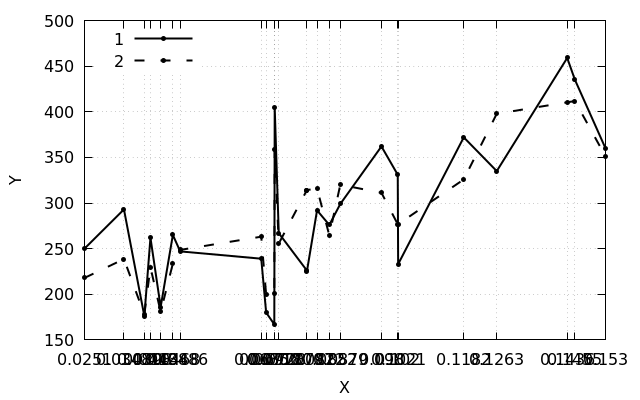
Но это мало похоже на то, что мне хотелось получить.
Официальная документация помогла разобраться с собственными именами меток на оси (xtic) и метками в области графика (sprintf):
set xtics rotate by -60
Label(String,Size) = sprintf("{/=%d %s}", Size, String)
plot "data.csv" using 2:3:xtic(2) title "1" w lp ls 1 , "data.csv" using 2:4 title "2" w lp ls 2 , "data.csv" using 2:($3>$4?$3+20:$4+20):(Label(stringcolumn(2), 12)) with labels notitle
Кусочек
($3>$4?$3+20:$4+20)позволяет устанавливать метки на рисунке выше выбранных точек на 20 единиц.
Получилось так:

Но вопрос с неравномерным распределением данных вдоль оси остался открытым.
Решение сформировалось в процессе блужданий по форумам и статьям — пронумеровать строки.
Самый простой вариант — пронумеровать вручную.
Второй вариант — пронумеровать автоматически:
nl -v 0 -s ';' -w 1 data.csv >> data_nums.csv Если нужно исключить закомментированные строки, то команда приобретает вид:
grep -v "^#" data.csv | nl -v 0 -s ';' -w 1 >> data_nums.csv data_nums.csv
0; 7.3; 0.0251; 250; 217.9006251
1; 5.3; 0.0348; 293; 238.6280188
2; 3.3; 0.0398; 176; 177.7890558
3; 7.4; 0.0413; 262; 229.6579533
4; 3.2; 0.0438; 186; 180.6920998
5; 7.2; 0.0468; 265; 233.6496388
6; 5.1; 0.0486; 247; 248.6435206
7; 5.2; 0.0685; 239; 263.0861645
8; 3.4; 0.0697; 180; 199.4893097
9; 3.1; 0.0717; 167; 200.9408317
10; 4.3; 0.0718; 405; 358.2750638
11; 2.2; 0.0728; 267; 255.5794728
12; 1.1; 0.0797; 226; 314.1587397
13; 1.3; 0.0797; 225; 314.1587397
14; 1.2; 0.0822; 292; 315.9731422
15; 2.4; 0.0852; 276; 264.5789092
16; 1.4; 0.0879; 299; 320.1099799
17; 6.4; 0.098; 362; 311.209506
18; 2.3; 0.102; 331; 276.771694
19; 2.1; 0.1021; 233; 276.8442701
20; 6.1; 0.1182; 372; 325.8698782
21; 4.1; 0.1263; 335; 397.8290383
22; 4.4; 0.1436; 459; 410.3847036
23; 4.2; 0.1455; 435; 411.7636495
24; 6.2; 0.153; 360; 351.126361
При работе с таким набором данных, gnuplot распределит данные вдоль оси через равные промежутки:
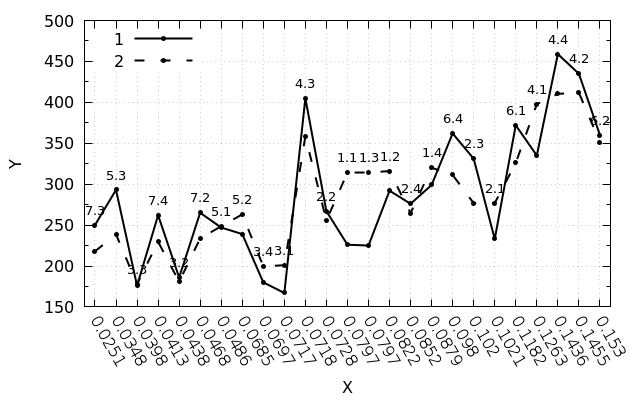
Итоговый скрипт:
#!/usr/bin/gnuplot -persist
set encoding utf8
set terminal pngcairo size 640,400 enhanced monochrome
set output "img.png"
set ylabel "Y"
set xlabel "X"
set key left top samplen 5 spacing 1.15 width 2
set xrange [-0.5:24.5]
set mytics 2
set xtics rotate by -60
set grid
set pointsize 0.5
set datafile separator ";"
set style line 1 linetype 1 pointtype 7 linewidth 2 linecolor black
set style line 2 linetype 2 pointtype 7 linewidth 2 linecolor black
Label(String,Size) = sprintf("{/=%d %s}", Size, String)
plot "data_nums.csv" using 1:4:xtic(3) title "1" w lp ls 1 , "data_nums.csv" using 1:5 title "2" w lp ls 2 , "data_nums.csv" using 1:($4>$5?$4+20:$5+20):(Label(stringcolumn(2), 10)) with labels notitle
update:
Благодаря внимательности Deosis и точной отсылке к документации (параграф Pseudocolumns) выяснилось, что можно обойтись без искусственной нумерации.
Для равномерности распределения данных вдоль оси можно воспользоваться нулевым столбцом ($0), который предоставляет индексы строк.
В этом случае есть возможность использовать исходный набор данных — data.csv, а в скрипте внести следующие изменения:
plot "data.csv" using 0:3:xtic(2) title "1" w lp ls 1 , "data.csv" using 0:4 title "2" w lp ls 2 , "data.csv" using 0:($3>$4?$3+20:$4+20):(Label(stringcolumn(2), 12)) with labels notitle
BkmzSpb
Немного оффтоп, но есть например вот такая статья, где как раз обсуждаются способы генерации равномерно распределенных тиков. Зачастую, встроенные инструменты если и генерируют тики, то делают это абы как.
Алгоритм из статьи, в частности, используется в
{scales}, который в свою очередь используется в {ggplot2}, топовом пакете для визуализации вR.Для себя я сделал более простой инструмент генерации равномерных тиков (
ggplot2-совместимый), который в вашем случае, для интервала(0.0251, 0.153)генерируетlarge_ticks: 0.04, 0.06, 0.08, 0.1, 0.12, 0.14
small_ticks: 0.028, 0.032, 0.036, 0.044, 0.048, 0.052, 0.056, 0.064, 0.068, 0.072, 0.076, 0.084, 0.088, 0.092, 0.096, 0.104, 0.108, 0.112, 0.116, 0.124, 0.128, 0.132, 0.136, 0.144, 0.148, 0.152
Deosis
Проблема в том, что вы передаете пары (x;y) и программа, согласно документации, считает их координатами точек. Там же в документации предлагают использовать колонку $0.