

В предыдущей статье мы обсуждали, почему функциональное программирование это совсем не то, что распиарено, и что оно совершенно не противоречит ООП, так, что даже сам Фаулер пишет про хороший ФП дизайн порождающий хороший ООП дизайн программы (и наоборот).
Сейчас же я хочу рассказать, что такое монады на самом деле, чем они полезны для обычного практикующего разработчика, и приведу примеры, почему недостаточная поддержка их в распространенных языках приводит к копипасте и ненадежным решениям.
Но ведь в интернете буквально сотни статей про ФП и монады, зачем писать еще одну?
Дело в том, что все их (по крайней мере те что я читал) можно поделить условно на две категории: с одной стороны это статьи где вам объяснят что монада это моноид в категории эндофункторов, и что если монада T над неким топосом имеет правый сопряжённый, то категория T-алгебр над этой монадой — топос. На другой стороне располагаются статьи, где вам рассказывают, что монады — это коробки, в которых живут собачки, кошечки, и вот они из одних коробок перепрыгивают в другие, размножаются, исчезают… В итоге за горой аналогий понять что-то содержательное решительно невозможно.
Получается, что первые обычно полезны тем, кто и так знает обсуждаемую тему, а вторые даже не знаю на кого рассчитаны: сколько я их не прочитал, ничего полезного понять из них мне не удалось.
Я же хотел бы занять промежуточную позицию, и рассказать про монады без заумных терминов, но и без котиков, используя понятные ООП разработчикам термины: интерфейсы, паттерны, копипаста, инкапсуляция сложности, бойлерплейт, и так далее. В процессе работы над статьёй ни один термин теории категории использован не был.
Вступление
Итак, с чего бы начать? В нашем случае имеет место проблема курицы и яйца: чтобы мотивировать узнать про монады, я должен привести примеры их использования, но чтобы привести примеры использования, вы должны их уже знать. Поэтому я попрошу вас набраться немного терпения, и сначала узнать, что же это такое, а потом уже я обещаю показать, почему это знание полезное, и как его можно применить на практике.
Я долго думал на каком языке писать примеры, перебрал все варианты, которые знал. В итоге остановился на модифицированном C#. Scala оказалась слишком вербозной, Rust хотя и имеет концепцию трейтов, не может выразить самый простой из требуемых тайпклассов, ну а Haskell знают не все.
Но обычный сишарп не обладает нужными фичами, поэтому в статье я буду использовать синтаксис C# 10 (который еще не вышел), в частности расширение Shapes и расширение HKT. Первый из них добавляет в язык шейпы (aka тайпклассы, aka трейты). Если привести пример зачем они нужны, то вот так мы могли бы объявить тайпкласс для того, чтобы помечать классы как сериализуемые
public shape JsonDeserialize<T>
{
static T Deserialize(JObject input);
}Такой тайпкласс превратил бы рантайм эксепшн JsonSerializationException: Could not create an instance в ошибку времени компиляции. Лично я с этой ошибкой часто встречаюсь на проектах с десериализацией нетривиальных типов в кастомных форматах, поэтому и пример про него.
Шейпы отличаются от интерфейсов двумя особенностями: во-первых, они позволяют объявлять статические методы (и даже константы), а не только инстансные, а во-вторых, позволяют расширять чужие классы. Например, ICollection<T> не наследует IReadOnlyCollection<T>, и мы ничего с этим не можем поделать. Будь они тайпклассами, мы легко могли бы зачинить эту проблему. Или мы можем расширить функциональность стандартных классов. Если вы когда-нибудь хотели написать генерик-функцию вида where T : Number, работающую с любыми числами, то вы сразу должны оценить, какая это нужная штука: с тайпклассами объявить такой Number не составляет никаких проблем.
Второе расширение нам поможет работать с открытыми генерик-аргументами как типами. Например, это может выглядеть так:
public static T<int> CreateSomethingOfInts<T>() where T : <>, new()
{
return new T<int>();
}Возможно, выглядит страшновато, но просто посмотрите на пример использования, и всё станет понятно:
// можем создать инстанс любого типа с одним генерик параметром
var list = CreateSomethingOfInts<List>();
var hashSet = CreateSomethingOfInts<HashSet>();
// …
// Array<T>, Nullable<T>, LinkedList<T>, ... - можно использовать любой подобный тип
// получим в результате Array<int>, Nullable<int>, LinkedList<int>, ...Ко всему этому в статье будут ссылки на плейграунд с реализацией на актуальном C# 8. Они явно выигрывают в том, что их можно запускать, однако пользы в таком виде от них не очень много. Они приложены только для лучшего понимания написанного, потому что их можно позапускать и потыкать в дебаггере.
Что ж, прелюдия довольно ощутимо затянулась, приступим.
Functor
И первое с чего мы начнем — с функтора. "Как же так, ты же про монады рассказать обещал!" — скажете вы. Да, но функтор — базовый строительный блок многих ФП понятий, в том числе и монады, поэтому без него не обойтись.
Итак, что такое функтор? Можно долго рассуждать в терминах объектов категорий и морфизмов между ними, а можно взять наш понятийный аппарат ООП разработчиков и сказать, что Функтор — это любой объект, реализизующий тайпкласс Functor следующего вида:
public shape Functor<T> where T : <>
{
static T<B> Map<A, B>(T<A> source, Func<A, B> mapFunc);
}Собственно, это всё. Это полное определение, прочитав которое вы можете смело сказать "я знаю, что такое функтор". Если бы терминологию придумали джависты, то они назвали бы его Mappable, потому что он, собственно, определяет единственный метод Map, который позволяет преобразовать наш тип-контейнер, параметризованный типом A, в такой же контейнер, но уже с элементами типа B.
Например, был у нас массив чисел и функция ToString, получили массив строк. Или был список строк, а получили список длин этих строк. А может и не список, и не массив, а стек какой-нибудь. Суть одна — у нас есть наша структура данных, в которой лежат какие-то объекты. У нас есть функция A => B, которая преобразует один такой объект в другой такой объект. Тогда с использованием функции Map мы можем сделать такой же контейнер, как тот, что хранит A, но теперь в нём будут B.
Для Map сущестует единственное правило: если наша mapFunc это Identity-функция вида x => x, то контейнер должен остаться неизменным. То есть, чтобы считаться "законным" функтором, для нашего контейнера всегда должно выполняться вот это равенство:
Map(something, x => x) === somethingЭто правило достаточно очевидное, оно, по сути, говорит, что сам контейнер по себе ничего со значением не делает, и всё взаимодействие с его элементами мы можем контролировать при помощи mapFunc. Там нет никаких рандомов, внешних взаимодействий, и так далее, мы можем безопасно вызывать Map как угодно.
Давайте подумаем какие типы из стандартной библиотеки удовлетворяют этому правилу?
Ну, самое простое, это итераторы:
public extension EnumerableFunctor of IEnumerable : Functor<IEnumerable>
{
public static IEnumerable<B> Map<A, B>(IEnumerable<A> source, Func<A, B> map) =>
source.Select(map);
}
// проверяем закон функторов
var range = Enumerable.Range(1, 10);
Console.WriteLine(Map(range, x => x).SequenceEquals(x)) // выведет TrueРаз этот код компилируется и тест проходит, то мы доказали, что итератор в дотнете является функтором! Хотя в дотнете нет тайпклассов, тем не менее IEnumerable — это функтор, раз закон выполняется
Какой еще тип может вести себя подобным образом? Подумайте немного, вы с ним работаете каждый день по 100 раз на дню.
И конечно же это Nullable. Давайте реализуем для него тайпкласс функтора:
public extension NullableFunctor of Nullable : Functor<Nullable>
{
public static B? Map<A, B>(A? source, Func<A, B> map) =>
source is A notNullSource ? map(notNullSource) : default(B?);
}
// проверяем закон функторов
int? nullableTen = 10;
int? nullableNull = null;
Console.WriteLine(Map(nullableTen, x => x) == nullableTen); // выведет True
Console.WriteLine(Map(nullableNull, x => x) == nullableNull); // выведет TrueТаким образом мы доказали, что Nullable — это тоже функтор.
Другой очевидный ответ — Task, для него нетрудно реализовать Map самостоятельно.
В учебниках по ФП часто упоминают про еще один закон для функторов, но тут есть один нюанс: если вы соблюдаете первый закон, то второй соблюдается автоматически. Это математический факт, так называемая "бесплатная теорема". Так что для того, чтобы проверить является ли наш класс функтором, достаточно проверить только одно простое правило, которое мы обсудили.

Map позволяет абстрагироваться от структуры контейнера, давая способ менять содержимое контейнера, ничего про эту структуру не зная
Вот мы и познакомились с одним из страшнейших зверей мира ФП — целым функтором! А дальше нас ждет ещё более сложный тайпкласс и зовут его...
Applicative
Аппликативный функтор! Который определяет не один метод, а целых два:
public shape Applicative<T> where T : <>
{
static T<A> Pure<A>(A a);
static T<C> LiftA2<A, B, C>(T<A> ta, T<B> tb, Func<A,B,C> map2);
}Что мы тут видим? Аппликативный функтор, это любой тип, который умеет:
- Создаваться из одного значения любого типа. По сути аналогичен констрейнту
where T : new(), за исключением того, чтоnew()не принимает аргументов, а мы принимаем один. - А тут уже интересно. Интерфейс говорит нам, что если у нас есть два значения
T<A>иT<B>и функция, преобразующая пару значенийA, BвC, то мы можем получитьT<C>. НазваниеLiftA2происходит из того, что мы как бы "поднимаем" вычисление над двумя голыми переменнымиAиBв вычисление над аппликативамиT<A>иT<B>соответственно.
Непонятно? Давайте разбираться. Самый простой способ разобраться в чем-то – сделать это что-то своими руками. Класс называется аппликативный функтор, в предыдущем разделе мы как раз пару функторов разобрали, возможно, они как-то связаны?
"Talk is cheap, show me the code", поэтому в качестве доказательства что наш класс является аппликативом мы, как и раньше, постараемся просто реализовать соответствующий интерфейс. Если компилятор нас не остановит — то значит мы успешно доказали то, что хотели, если же у нас в какой-то момент возникнут трудности — значит мы не правы. Давайте начнем с итератора:
public extension EnumerableApplicative of IEnumerable : Applicative<IEnumerable>
{
static IEnumerable<A> Pure<A>(A a) => new[] { a };
static IEnumerable<C> LiftA2<A, B, C>(IEnumerable<A> ta,
IEnumerable<B> tb,
Func<A, B, C> map2) =>
ta.SelectMany(a => tb.Select(b => map2(a, b)));
}Ну, вроде у нас всё получилось. Что интересно — всё это дело прекрасно компилируется восьмым сишарпом, если закомментировать часть про public extension. То есть в обычном кроваво-энтерпрайзном языке есть давно все эти прелести, просто они не оформлены в виде тайпкласса, от которого можно абстрагироваться (зачем это вообще может понадобиться я покажу ниже).
Что же насчёт Nullable? Тоже никаких проблем:
public extension NullableApplicative of IEnumerable : Applicative<Nullable>
{
static A? Pure<A>(A a) => a;
static C? LiftA2<A, B, C>(A? ta, B? tb, Func<A, B, C> map2) =>
(ta, tb) switch {
(A a, B b) => map2(a, b), // Если оба не null - то вычисляем
_ => default(C?) // кто-то нулл - результат null
};
}В примере с итератором выше мы релизовали семантику "каждый с каждым", но мы все прекрасно знаем, что есть другая равнозначная семантика "первый с первым, второй со вторым, ...". К сожалению, реализовать один и тот же интерфейс для одного типа двумя различными способами нельзя, поэтому нам подойдет паттерн Адаптер, который в ФП мире называют ньютайп. Для итератора таким адаптером является класс ZipList:
public class ZipList<T> : IEnumerable<T>
{
private IEnumerable<T> _inner;
// .. конструктор и реализация IEnumerable<T> опущена для краткости
}
public extension ZipListApplicative of ZipList : Applicative<IEnumerable>
{
static IEnumerable<A> Pure<A>(A a) =>
// вообще тут должен быть бесконечный генератор элемента 'a'
Enumerable.Repeat(a, int.MaxValue);
static IEnumerable<C> LiftA2<A, B, C>(IEnumerable<A> ta,
IEnumerable<B> tb,
Func<A, B, C> map2) =>
ta.Zip(tb, map2);
}Оказывается, ZipList давно существует в стандартной поставке, просто очень хорошо скрывается. Но без общего зонтичного типа Applicative он не особо полезен, поэтому дотнет обходится просто одинокой функцией Zip.
Мы узнали, что такое аппликативы, а какие-нибудь примеры использования будут? Что мы можем с ними сделать? Ну, с ними можно много чего интересного делать — библиотеку парсер-комбинаторов с их помощью удобно выражать, проперти-тест фреймворк можно написать, но для статьи такие примеры слишком большие, поэтому давайте возьмем чего-нибудь попроще. Например, можно написать функцию, которая из пары аппликативных функторов нам сделает аппликатив пары оригинальных значений, то есть: (F<A>, F<B>) -> F<(A, B)>. Давайте напишем:
public static T<(A, B)> Combine(T<A> ta, T<B> tb) =>
LiftA2(ta, tb, (a, b) => (a, b));
var eta = Enumerable.Range(3, 2);
var etb = Enumerable.Range(15, 4);
int? nta = 10;
int? ntb = null;
Combine(eta, etb) // [(3, 15), (3, 16), (3, 17), (3, 18), (4, 15), (4, 16), (4, 17), (4, 18)]
Combine(nta, nta) // (10, 10)
Combine(nta, ntb) // Null
Combine(new ZipList<int>(eta), new ZipList<int>(etb)) // [(3, 15), (4, 16)]С одной стороны, функция простая, можно даже сказать скучная. А с другой — посмотрите, мы написали очень абстрактную функцию Combine, которая совершенно ничего не знает о переданных значениях, но при этом умеет производить очень сильно различающиеся действия. Для двух списков она считает комбинаторику всех пар, для нуллейблов оно возвращает либо пару элементов, если оба переданных параметра имели значение, либо null. Для ZipList мы сцепили соответствующие элементы двух списков, причем результирующий список был усечен до самого короткого из двух. Таким образом, аппликатив позволяет нам разделить действие над элементами контейнера (это наша функция (a, b) => (a, b)) и форму контейнера (это T<>). То есть, с одной стороны, мы можем описывать вычисления, не заботясь о форме контейнера (опциональное значение/список/промис/что угодно), а с другой мы, наоборот, можем реализовать некий контейнер, а варианты работы с этим контейнером оставить на откуп клиентскому коду.
Остаётся добавить, что еще есть всякие законы, которые должны выполняться, но они достаточно очевидны, вроде ассоциативности операций и так далее. Чтобы не раздувать текст статьи я их доказывать не буду, потому что, по сути, эти законы просто проверяют соблюдение "Принципа наименьшего удивления". Можно почитать про них по ссылке и удостовериться, что они накладывают достаточно ожидаемые ограничения.
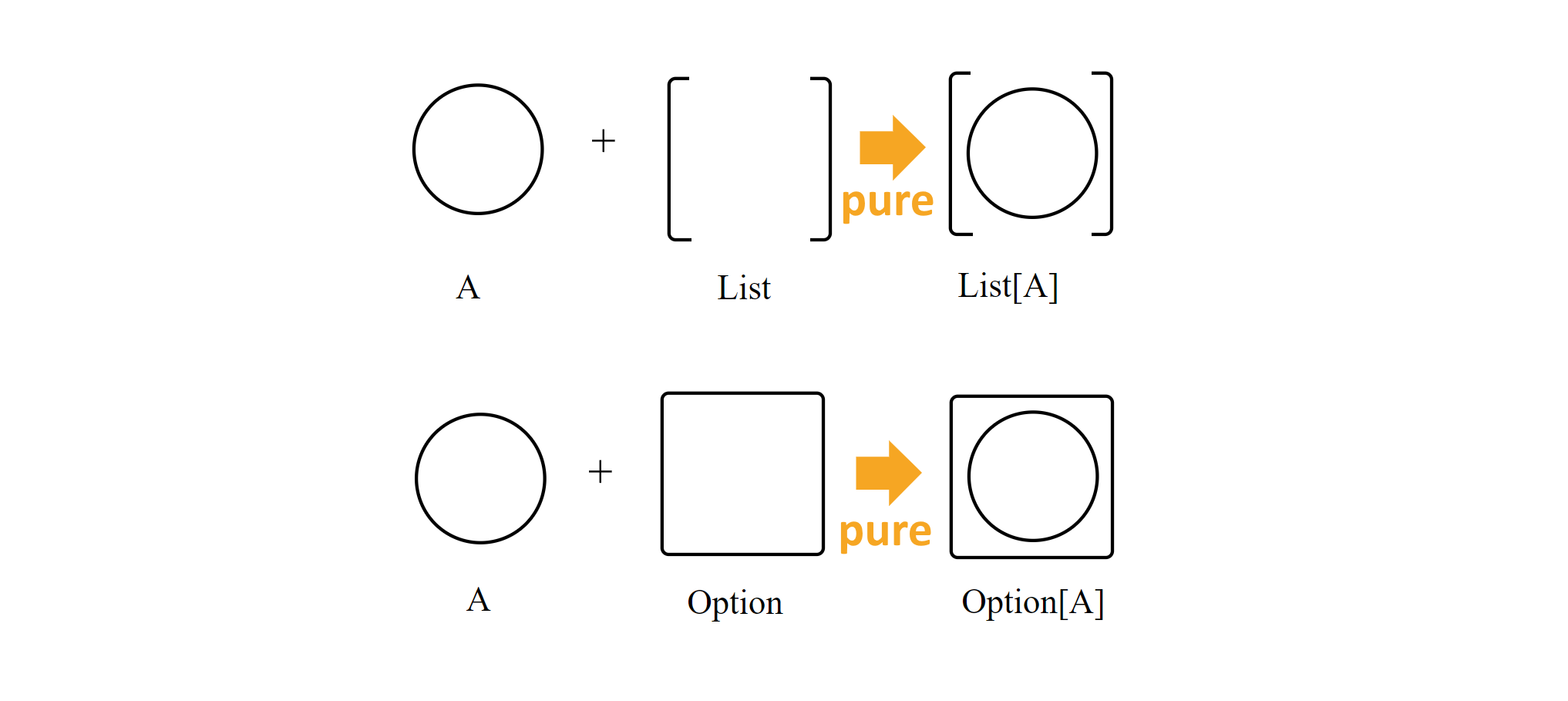
pure позволяет нам создать контейнер, содержащее единственное значение
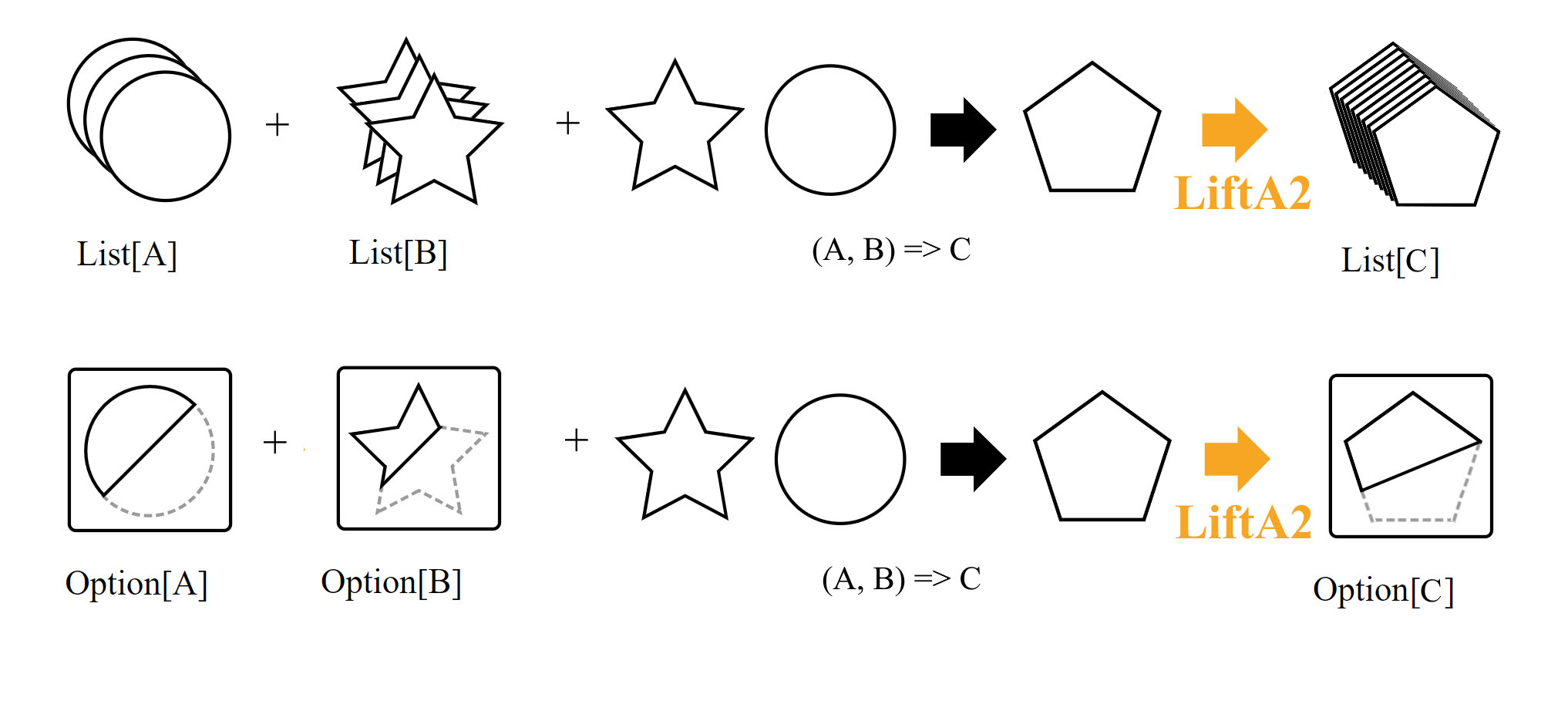
liftA2 позволяет нам использовать функцию от двух аргументов, имея на руках
два контейнера с соответствующими типами, упакованными внутри
Прежде, чем мы приступим к герою сегодняшнего дня, хочу обратить внимание, что тайпкласс который мы только что обсудили называется "Аппликативный функтор". Почему именно так? "Аппликативный" означает что с ним мы можем применять упакованные функции к упакованным значениям. Например, у нас может быть список функций, и список значений. Применив к ним LiftA2 мы получим список результатов каждой функции примененной к каждому значению. Ну, это нужно бывает не часто, а вот из двух опциональных значений сделать третье, если в обоих не null — буквально каждый день. Или выполнить две асинхронные операции и вычислить на их основании какой-то ответ.
А почему функтор? Имея функции LiftA2 и Pure легко реализовать Map:
static T<B> MapAnyFunctor<T, A, B>(T<A> source, Func<A, B> map) where T : Applicative =>
LiftA2(source, Pure(0), (a, _) => map(a));Как это работает? Очень просто — мы создаем мусорное значение и с помощью функции Pure оборачиваем его в аппликатив T<>. Теперь у нас есть T<A> и T<НашМусорныйТип>, которые по типам подходят для LiftA2. Нам остаётся только её вызвать, а в передаваемом коллбеке игнорировать это мусорное значение, вызывая map для элементов настоящего контейнера T<A>. Написав эту функцию мы доказали, что любой аппликатив является функтором. Можно дополнить нашу изначальную сигнатуру:
public shape Applicative<T> : Functor<T> where T : <>
{
static T<A> Pure<A>(A a);
static T<C> LiftA2<A, B, C>(T<A> ta, T<B> tb, Func<A,B,C> map2);
}Ссылка на плейграунд. Можно убедиться, что поведение такое же, какое было изначально.
Также легко реализовать тайплкасс аппликатива для Task<T>:
public extension TaskApplicative of Task: Applicative<Task>
{
public static Task<A> Pure<A>(A a) => Task.FromResult(a);
public static async Task<C> LiftA2<A, B, C>(Task<A> ta, Task<B> tb, Func<A, B, C> map2)
{
await Task.WhenAll(ta, tb);
return map2(ta.Result, tb.Result);
}
}Monad
И вот он. Тайпкласс, одним своим названием повергающий в ужас. И который состоит
из целых двух функций, одну из которых мы уже знаем:
public shape Monad<T> where T : <>
{
static T<A> Pure<A>(A a);
static T<B> Bind<A, B>(T<A> ta, Func<A, T<B>> mapInner);
}Если говорить по-русски, то:
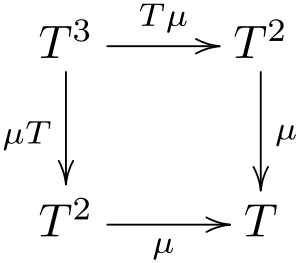
Монада — это любой класс с функциями Pure и Bind, которая принимает аргумент типаT<A>и функцию, преобразующую распакованное значениеAвT<B>, и возвращает значение того же типаT<B>
И никаких моноидов в категориях эндофункторов, заметьте. Сигнатура может выглядит немного перегруженной, но она иллюстрирует простую идею: у вас есть упакованное в контейнер значение типа А. И у вас есть функция из голого A в такой же контейнер, но уже со значением B. Функция Bind позволяет "связать" эти два выражения вместе, получив из пары (T<A>, A => T<B>) значение T<B>.
Таким образом монада — это простейший интерфейс, который тривиально реализовать для того же итератора, что мы в очередной раз и сделаем:
public extension EnumerableMonad of IEnumerable : Monad<IEnumerable>
{
static IEnumerable<B> Bind<A, B>(IEnumerable<A> ta, Func<A, IEnumerable<B>> mapInner) =>
ta.SelectMany(mapInner);
// Pure такой же как и в аппликативе
}Легко увидеть, что Nullable тоже является монадой. А что насчет ZipList? А вот он, оказывается, не подходит: если вы попробуете для него реализовать такой интерфейс, то у вас ничего не выйдет, потому что у монад тоже есть тройка законов, которые типы должны соблюдать (хотя они тоже тривиальные).
Некоторое время назад я сделал небольшую песочницу на расте, в котором можно проверить, выполняются ли законы для произвольного типа. Можно попробовать подставить туда ZipList со своей реализацией и убедиться, что один или несколько тестов пройти не получится.
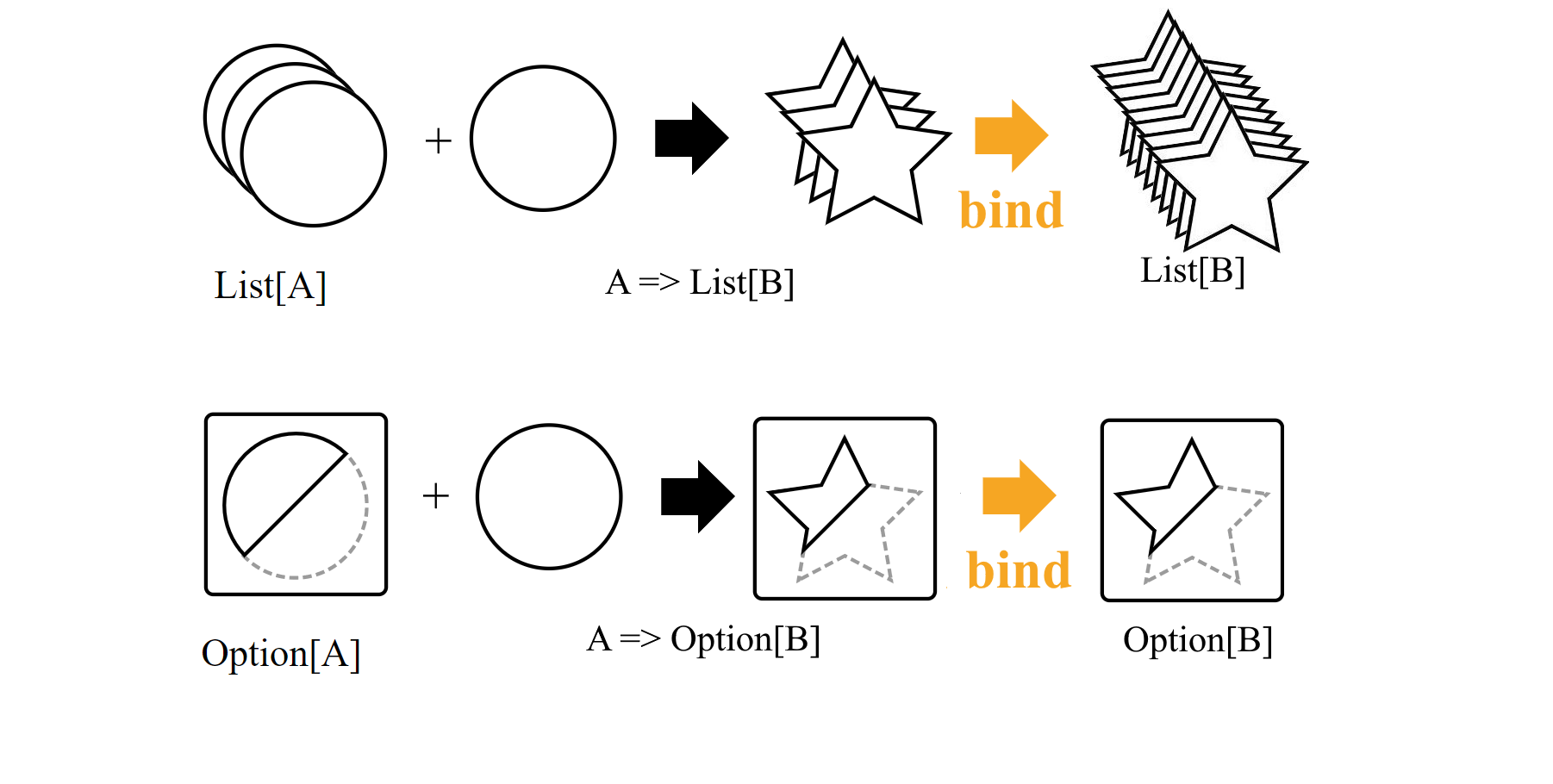
Монады позволяют имея на руках контейнер с элементами типа А и функцией из А в такой же контейнер типа В получить контейнер типа В
Любая монада также является аппликативом, поэтому реализацию Pure копипастить не надо: её можно отнаследовать от базового аппликатива. Что до LiftA2, то в качестве упражнения предлагаю реализовать её при помощи функций Pure и Bind, там нет ничего сложного.
Кроме того, что монады чрезвычайно просты, они еще и настолько полезны, что захардкожены в большинстве языков. Думаю, многим хабровчанам известно, что в хаскелле и скале есть так называемая do-нотация. Она рассахаривает такой хаскель код:
let foo = do
a <- someA
b <- someB
pure (doSomethingWith a b)в последовательность вызовов функции Bind которую мы только что разобрали:
var foo = Bind(someA, a => Bind(SomeB, b => Pure(DoSomethingWIth(a,b)))Паттерн очень простой. Всё что справа от стрелочки <- идет как первый аргумент функции Bind,
то, что слева — становится именем параметра лямбды, которая передаётся как второй аргумент.
Элементарно.
Как видите, это одна простая конструкция, которая работает по одному паттерну.
А что у нас в сишарпе? А в нём есть аж целых три его захардкоженных вариации. Например, что это за код?
var values = from x in new []{ 1, 2, 3 }
from y in new []{ 4, 5, 6 }
select x + y;Это ни что иное, как do-нотация для монады итератора (в хаскелле итератор называется списком):
let values = do
x <- [1,2,3]
y <- [4,5,6]
pure (x + y)Давайте теперь посмотрим на такой код:
var maybeA = GetMaybeA();
var maybeB = maybeA?.GetB();
var maybeC = maybeB?.GetC();
var result = maybeC;А это do-нотация для монады Maybe (она же Option, она же с некоторой натяжкой — Nullable):
let result = do
maybeA <- getMaybeA
maybeB <- getB maybeA
maybeC <- getC maybeB
pure maybeCЧто насчет вот такого кода?
var valueA = await GetSomeA();
var valueB = await GetSomeB(valueA);
var result = valueB;А это do-нотация для монады IO (про которую мы не говорили, но, по сути, это просто аналог Task из сишарпа):
let result = do
valueA <- getSomeA
valueB <- getSomeB valueA
pure valueBТаким образом у нас в языке образовалось сразу три различных синтаксиса для того,
чтобы делать абсолютно одно и то же: имея на руках объект типа T<А> и функцию
из A в T<B>, получить T<B>, будь то A[] и A -> B[], или A? и A -> B?,
или Task<A> и A -> Task<B>,… И это далеко не полный перечень.
На этой ноте предлагаю перейти к первому пункту обещанного параграфа под названием...
Зачем нам монады
Упрощение синтаксиса языка
Первым пунктом, следующим из предыдущего абзаца, стоит выделить упрощение языка. Посмотрите, сколько мусора натащил сишарп, чтобы выразить простую идею "Сделай что-нибудь, а затем сделай что-нибудь еще". И асинк-авейт, и LINQ, и null propagation являются частными случаями общей идеи. Причем которые очень часто ломаются на ровном месте. Захотел вызвать статический метод на nullable-параметре? Всё, элвис-оператор использовать не получится, пиши, как в старые-добрые времена проверку на нулл. Захотел заавейтиться внутри лямбды? Тебе компилятор скажет всё, что он думает об этой затее. Ну, хоть в случае списка, ломаться особо нечему, за исключением уродливых скобочек если нужно сделать хоть что-то выходящее за рамки LINQ-синтаксиса (например, вызвать First в конце запроса).
А еще большая проблема различного синтаксиса в том, что это всего лишь сахар: ту же функцию MapAnyFunctor написать в текущем сишарпе не выйдет. Мы годами ждали фичу async enumerable, которую наконец-таки релизнули (как всегда с кучкой костылей, все ведь например уже в курсе магических атрибутов для CancallationToken?), но сколько лет мы её ждали? Сколько человеко-лет понадобилось, чтобы её реализовать?
В языках с описываемыми возможностями системы типов это делается за день силами одного разработчика, достаточно написать адаптер для двух монад: List и IO.
Если вы думаете, что сишарп в этом плане выделяется, то спешу вас обрадовать: это не так. Тот же Rust с удовольствием прошелся по тем же граблям, и продолжает идти. Сюда относятся: и try-блоки, и Try-трейт, и всё тот же элвис-оператор, а асинк-авейт. Уверен, в будущем кортима раста будет еще годами запиливать async enumerable, как это сделала команда сишарпа, тратя кучу ресурсов на проблему, которой изначально не должно было быть.
А в другом углу ринга у нас do-нотация, которая выглядит абсолютно одинаково во всех случаях, которая позволяет всё, что позволяет родная монада, и которая состоит всего из одного ключевого слова, вместо россыпи операторов и кейвордов в случаях других языков.
И главное: при этом она базируется на интерфейсах, а не на захардкоженных в компиляторе эвристиках преобразования кода в стейт-машины. На интерфейсах, которые позволяет разработчику не ждать годами, пока команда языка соблаговолит наконец реализовать комбинатор пары монад, и которые не требуют костылить в язык кучу хаков. Что насчёт асинк энумерейбла, который автоматически параллелит получение данных по сети (мы не обсуждали, но в хаскелле для параллелизации есть монада Par)? Ну, пока ничего, ждем C# 15, в котором, возможно, это появится. А может и не появится.
Упрощение стандартной библиотеки языка
В сишарпе есть некоторое количество функций, работающих по принципу "сделай что-то, а потом еще что-то". Как мы уже выяснили, все функции такого вида отлично ложатся на монадический Bind. Это и ContinueWith, и SelectMany, и некоторые другие. Но если сишарпе их хотя бы не так уж и много, то в Rust это выглядит совершенно вопиюще. В Option/Result/Future накокопипащены буквально десятки функций, делающих ровно одно и то же, и которые могли бы быть выражены в терминах общего тайпкласса: большая часть операций через Monad, некоторые потребовали бы более редких вроде MonadFail/Bifunctor/..., но общий смысл остается тем же.
А по факту что мы имеем? Абсолютно ужасную копи-пасту в стандартной библиотеке. Вот в версии 1.29 появляется flatten для итератора, а вот спустя более чем год он же, но для опшна. Для футур он живет в стороннем крейте, который надо подключать.
Вот год назад появился transpose для Option/Result друг в друга, при том, что transpose из итератора для них появился аж в версии 0.8 в 2013 году. transpose для футур (которые как мы помним реализация IO монады для раста) до сих пор нет, еще 7 лет подождем, и они появятся.
Продолжать можно ещё долго, но суть остается прежней: можно было реализовать Monad трейт один раз, и дальше эти transpose/flatten/... появлялись бы во всех совместимых типах автоматически. Да, для конкретных классов реализация по-умолчанию может быть не оптимальной, но ведь всегда можно выполнить специализацию, особенно в стандартной библиотеке. В итоге имеется огромная проблема, которой в языке от 2015 года вообще не должно было быть изначально. Но, монад нет, и починить это в текущей версии языка невозможно, остается только копипастить однотипные реализации из типа в тип.
Сишарп тут в абсолютно схожей ситуации. Посмотрите на вот этот пакет System.Linq.Async. Разработчики из майкрософта в нём занимаются буквально тем, что копипастят реализацию LINQ из corefx, расставляя где надо async-await. Ну, там всё немного сложнее, но суть та же. Это еще один пример библиотеки, которой никогда не должно было существовать. Люди пишут руками код, который компиляторы давным-давно научились генерировать. Уже в первых версиях хаскелля были комбинаторы filterM/mapM/whateverM, которые как вы можете догадаться по их названию позволяют сделать фильтрацию/маппинг/… коллекции, производя при этом монадический эффект (отсюда буковка M в конце), в случае обсуждаемой библиотеки этим эффектом был бы асинхронный запрос.
Однако, не стандартной библиотекой единой живы, и наш следующий пункт
Сторонние библиотеки
Благодаря тому, что тайпкласс Monad (да и в целом тайпклассы) чрезвычайно абстрактный, можно создавать совершенно потрясающие удобные библиотеки. Например, возможно, вы помните мою статью, где я попробовал написать простенькое приложение на хаскелле и на го. В комментариях мне справделиво указали на то, что сравнение было "нечестным" — в го я старательно писал всё с нуля, в процессе чего я собственно несколько раз и ошибся, а в хаскелле я взял пару библиотек (для работы с деревьями и последовательностями), и написал только пару строчек, которая их склеивает вместе, где ошибиться было просто негде, ну оно и заработало как надо.
Но в тех же комментариях один из хабровчан дал замечательный ответ, который объясняет, что вовсе не случайно в хаскеле такие библиотеки есть, а в Go нет. Именно возможность спрятать конкретные реализации за тайпклассами Functor/Applicative/Monad/… и позволяет таким библиотекам существовать. Нет тайпклассов и HKT — не будет крутых библиотек, зато нужны будут разработчики, которые на зарплате будут копипастить реализации для новых конкретных монад, буде условному майкрософту или мозилле вздумается добавить их в язык. И, в отличие от общего решения, они будут это делать для тех кейсов, которые сочтут достойными. Если ваша монада не такая популярная, как список или опциональное значение, то останетесь без удобного способа смоделировать предметную область.
Для опытных шарпистов, кстати, это вовсе не новость. Например, есть куча полезных библиотек, на базе IEnumerable. Не будь такого интерфейса — не было бы и их. Куча удобных ORM в сишарпе основанна на IQueryable, который является такой специализированной монадой списка для БД, и без которого я думаю ситуация с ORM в сишарпе была бы куда печальнее. Именно подобные абстракции дают возможность творить по-настоящему мощные библитеки, и если даже на единственной монаде списка мы можем делать такое, то чего мы можем достичь с их совокупной мощью? А если мы еще и комбинировать их будем?
И именно благодаря им появляется возможность вместо сотен строчек кода написать десяток, который просто склеивает уже существующий библиотечный код. И это не обязательно код от высоколобых математиков из стандартной библиотеки Haskell, это может быть и ваш собственный My.Big.Corporation.Utils, который решает вашу конкретную практическую проблему, но решение которой чуть сложнее чем "отнаследовались от пары базовых классов и порядок". И дело не в том, что задача такая простая, что её может решить даже библиотечный код, а библиотечный код настолько абстрактный, что без проблем сможет помочь вам в вашей сложнейшей бизнес-логике.
Хотел заметить, что абстрактный — не значит сложный, а скорее наоборот. Как известно — любую проблему в программировании можно решить еще одним уровнем абстракции, кроме слишком большого количества уровней абстракции. Поэтому, когда я говорю "смотрите какая абстрактная мощь", я говорю про то, что эта мощь позволяет просто рассуждать о сложных процессах, а не просто никому не нужная акробатика на типах. Абстракции — упрощают программирование, а не усложняют.
Да, нужно изучить, какие бывают тайпклассы и что они умеют, хотя не так уж это и страшно: мы в статье рассмотрели где-то треть основных. Но потом этим знанием можно пользоваться до конца жизни. Посмотрите на объем документации Akka, там её действительно очень много. Но теперь спросите у людей, которые на ней пишут — хотели бы они сами с нуля реализовывать весь функционал, который в ней есть? Да, верю, что многие разработчики пожурят что они-то дескать лучше бы сами все сделали, и было бы их решение простое, красивое, да еще и производительное как у гугла. Но вот только велика вероятность что они лукавят, и если у них на проекте используется и персистентность, и автобалансировка акторов, и гарантированная доставка, и какие-нибудь другие нетривиальны фичи, то куда проще разобраться один раз в документации и настроить всю машинерию, чем сделать что-то подобное с нуля. Потому что умные люди написали удобную абстракцию, и работать с ней куда проще, чем делать такое самому. Это правда, что чем сложнее система типов, тем более инопланетную фигню можно навертеть, но так же верно и то, что некоторые вещи просто невозможно сделать удобно в более слабых системах типов.

Поэтому я считаю, что будущее именно за мощными языками, позволяющими делать удобные библиотеки, а не за кодом, который быстро написал — быстро выбросил и сделал новый. Такой подход работает, да, но по-моему опыту на проектах не больше пары сотен строк кода, как только их стало больше — лучше с библиотеками, которые кто-то написал, и хорошо бы, чтобы они были достаточно абстрактными и удобными, чтобы их можно было взять и использовать. Плюс монады — вещь стандартизованная, с простым интерфейсом, и что немаловажно — предсказуемыми свойствами, а гениальные архитектурные решения в каждой компании — свои уникальные, и последствия от их использования бывают самые разные.
Выразительность
Тайпкласс монады позволяет очень четко выражать намерения в коде. К слову, пример того, как хорошо дружит ООП с ФП: монады позволяют удобно и красиво следовать четвертому принципу SOLID. Каким образом? А таким, что код, написанный с использованием монад, выглядит подобным образом:
public M<Comment> GetArticleComment<M>(int articleId)
where M : MonadWriter<LogMessage[]>, MonadReader<Config>, MonadHttp<AllowedSite>Где MonadWriter/MonadReader/MonadHttp — это те самые сегрегированные по принципу SOLID интерфейсы, каждый из которых отвечает за свой маленький аспект. То есть наша функция говорит о том, что ей нужно уметь писать логи (при этом только в формате LogMessage!), читать конфиг (но только Config!) и ходить по Http (но только на AllowedSite!), и используя всё это она в качестве результата вернет комментарий.
Возможно, это выглядит немного чужеродно, но концепт на самом деле очень простой. Мы делаем это сотни раз, когда после авейта возвращаем значение, а оно завернуто в Task. Мы пишем return 10, тогда как возвращаемое значение Task<int>.
Тут ровно та же история, только вместо Task может быть любая монада M, а соотвественно действием — любой эффект, а не только асинхронный запрос.
Причем, таким образом с монадами мы одновременно следуем и последней букве SOLID, решая одну из самых больших головных болей в ООП разработке — инверсию зависимостей. Нам не нужны гигантские Autofac/Windsor/Ninject/… которые падают в рантайме "нишмагла найти зависимость", вы просто описываете в обычных where условиях нужный функционал, и если вы забыли передать зависимость, то компилятор вам об этом напомнит. Вам не нужна магия, внешняя по отношению к языку, вы просто пишете на сишарпе, а компилятор вам поможет.
Тестируемость
Частично связанное с предыдущим пунктом, абстрагированность от некоторых особенностей логики вроде того, является ли функция асинхронной, позволяет избавиться от моков.
Один из примеров, как ФП помогает избавиться от моков, я демонстрировал в предыдущей статье, на примере заказа кофе в кофейне. Другой пример можно привести такой: допустим, мы написали типичный код, который по сети достает какие-то данные и как-то их преобразует.
class MyService
{
async Task<Comment> SomeBusinessLogicAsync(int commentId) {
var comment = await this.remoteClient.GetAsync($"some/url/{commentId}");
// .. do stuff ..
return await DoOtherStuffAsync(comment);
}
}Теперь мы хотим этот код протестировать. Что мы обычно делаем в C# в таком случае?
Ну, хорошим стилем в сишарпе считается делать тестируемые типы, поэтому наш MyService принимает remoteClient в виде аргумента конструктора, который мы и будем мокать.
Соответственно для этого берем какой-нибудь мок фреймворк, делаем фейковый httpClient, настраиваем его что должно возвращаться по каким урлам (таким образом мы еще и в кишки метода залезли, непрямым образом), ну и act/assert после этого.
А что нам даёт механизм с монадами? Предлагаю вашему внимание простейшую, и бесполезную (но только на первый взгляд) монаду Id, которая просто оборачивает своё значение и больше ничего не делает:
public class Id<T>
{
public T Value { get; }
public Id(T value)
{
Value = value
}
}
public extension IdMonad of Id : Monad<Id>
{
static IdMonad<A> Pure<A>(A a) => new Id<A>(a); // просто создаем обертку
static IdMonad<B> Bind<A, B>(IdMonad<A> ta, Func<A, IdMonad<B>> mapInner) =>
mapInner(ta.Value); // просто вызываем функцию над обернутым значением
// реализации map и liftA2 возмем по-умолчанию
}Теперь вместо функции:
Task<Comment> SomeBusinessLogicAsync(int commentId);Давайте напишем
M<Comment> SomeBusinessLogicAsync<M>(int commentId) where M : Monad =>
this.remoteClient.Get($"some/url/{commentId}").Bind(comment =>
// .. do stuff ..
return DoOtherStuff(comment);
);С do-нотацией было бы вообще 1к1, но и так сойдет. Соответственно в нашем бизнесовом коде будет:
var comment = await myService.SomeBusinessLogicAsync<Task>(547);А в коде с тестами:
var comment = myService.SomeBusinessLogicAsync<Id>(547).Value;И никаких моков асинхронного взаимодействия! Потому что мы сделали ту самую инверсию контроля, про которую говорит SOLID (и снова нам в этом помогли практики ФП). Раньше вызываемый код решал сам, что он хочет запустить асинхронную операцию, что приводило к головной боли у вызывающего, которому приходилось давать фейковое асинхронное взаимодействие. Но оказалось, что это знание лишнее. Наша функция всего лишь хотела сделать операцию, а когда получит её результат сделать что-то еще. И в очередной раз мы сталкиваемся с тем, что нам для этого нужен просто монадический интерфейс. То есть функция ошибочно накладывает слишком много ограничений на вызывающего. Изолировав это знание в бизнесовом коде мы получили возможность на своей стороне решать, в каком виде мы хотим иметь результат.
Как следствие — у нас очень сильно упрощается код. Не нужно писать моки, не нужно лепить бесконечные Task.FromResult из-за того что интерфейс асинхронный. Можно просто писать бизнесовую логику, и на месте решать, какой эффект мы хотим. Причем это работает не только для тестов: мы можем написать общий интерфейс с двумя реалзиациями: синхронной и асинхронной, и использовать подходящий. Прощай вопросы вроде "должен ли я делать асинхронные врапперы над синхронными функциями", или может наоборот. Просто пишите в контексте монады, а дальше вызывающий код решит, как вас использовать.
Более того, в качестве монады M может быть любая, а не только Task или Id, поэтому мы автоматически получаем функцию, которая, например, автоматически умеет в ретраи (если в качестве M мы передали такую монаду которая умеет их делать), может ничего не вернуть (если M — Option), может завершиться с ошибкой (если M — Result), и так далее. И что самое главное — да нам это тут вообще не важно. Мы хотим просто написать функцию получения комментария, а будет ли он качаться синхронно, асинхронно, с ретраям или без — это инфраструктурная хрень, и желательно чтобы она конфигурировалась снаружи. Поэтому: логика — отдельно, инфраструктура — отдельно.
Заключение

Если честно, я даже не думал, что получится так много текста. Первоначально я планировал рассказать и про Traversable, и Foldable, и как они помогли решить ту задачу с деревьями, но сейчас я понимаю, что уже полностью исчерпал лимит внимательности у вас, как читателей.
Давайте подытожим, какие в итоге существуют основные тайпклассы и что они умеют:
Функтор (ооп. Mappable)
Что такое: это любой класс, реализующий функцию
Mapопределенной сигнатуры, для которой выполняется одно простое правило.
Назначение: Класс позволяет заниматься маппингом значения внутри контейнера, преобразуя
T<A>вT<B>.
Пример: преобразование итератора одних значений в итератор других значений;
преобразование результата асинхронной операции
Аппликативный функтор (Аппликатив, ооп. PairMappable)
Что такое: это любой класс, реализующий пару функций
PureиLiftA2, для которых выполняются
их простые правила (в основном, связанные с композицией). Реализация этих методов
гарантирует автоматическую реализацию тайпкласса "Функтор".
Назначение: Класс позволяет комбинировать вместе пару независимых вычислений
T<A>иT<B>в общийT<C>.
Пример: сцепление двух контейнеров (например, List, Option, ZipList, ..);
парсинг языка с контекстно-независимой грамматикой
Монада (ооп. NestedJoinMappable):
Что такое: это любой класс, реализующий пару функций
PureиBind(и опять правила).
Реализация этих методов гарантирует автоматическую реализацию тайпкласса "Аппликатив".
Назначение: Класс позволяет комбинировать зависимые вычисления, где
T<B>зависит отA, который
в свою очередь находится в контейнере того же типаT<A>
Пример: выполнение нескольких асинхронных операций, зависящих друг от друга; парсинг языка с контекстно-независимой грамматикой
Надеюсь, я смог показать, что монады (и остальные упомянутые в статье тайпклассы) это не какие-то страшные монстрозвери, которые не дают спать, а
- Максимально простые интерфейсы (пусть и довольно абстрактные)
- Которые при этом очень мощные, и позволяющие понятно выражать даже сложные вещи
К сожалению, одну статью физически невозможно невозможно уместить все возможные применения, поэтому я предлагаю просто потыкать их самостоятельно, и убедиться самому, что эта концепция действительно выручает во многих случаях.
Монады — просто инструмент, которым надо уметь пользоваться. Его изучение — это удачная инвестиция, которая сэкономит не один месяц жизни, уничтожив причину многих вопросов "ну КАКОГО хрена оно не работает, я же всё проверил" в зародыше. И хотя ни одна техника программирования не убережет вас от всех проблем, грех не воспользоваться инструментом, который решает значительную их часть.







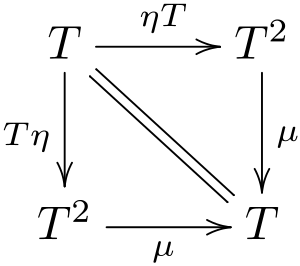




nlinker
Добавлю, что если определить операцию
>=>(называется "композиция Клейсли" (Kleisli composition)) таким образом:Можно тогда определить операции
bind(который>>=) иjoinчерез эту операцию>=>, так что определение монады можно эквивалентно делать через разные операции, они всё равно друг через друга выражаются.Тогда монадические законы становятся намного проще для запоминания и понимания:
f >=> return ? freturn >=> g ? g(f >=> g) >=> h ? f >=> (g >=> h)То есть
returnоказывается правой и левой единицей в такой структуре, и операция>=>обладает ассоциативностью.Такие структуры называют страшным словом моноид, но на самом деле ничего страшного нет, такими свойствами обладают множество вещей: числа относительно сложения, числа относительно умножения, строки относительно конкатенации, множества относительно объединения и так далее.
PsyHaSTe Автор
Не уверен, что этот пример упрощает понимание) Я специально придерживался C# где можно чтобы не пугать людей. 2 года назад у меня сигнатура и определение
>=>вызвали бы паническую атаку.PsyHaSTe Автор
Для людей, незнакомых с хаскеллем, переведу на сишарп:
И соответственно законы:
returnэто алиас наpure, который задеприкейтили потому что он похож наreturnв императивных языках, но по сути ощутимо отличается.PsyHaSTe Автор
Последний закон должен быть
FishOperator(FishOperator(f, g), h) = FishOperator(f, FishOperator(g, h))очепятался немного
dreesh
.
mikeus
Такое описание с использованием стрелки Клейсли на мой взгляд наглядно раскрывает сущность монад: собственно это есть один из вариантов реализации композиции функциональности с помощью типов. Всё.
Все языки натуральным образом его поддерживают без необходимости вводить дополнительные реализующие его операторы.А чем больше пытаются объяснить разными способами, что такое монады, тем менее понятно для непосвященных это становится. Хотя достаточно просто задать вопрос: какие способы композиции функциональности (сиречь кода, или функций) вы знаете? Я лично знаю три:
1) естественный — операция композиции (.)
2) с помощью типов, просто надо вспомнить что код — это тоже обычный тип данных и часть функциональности можно спокойно структурировать/вынести/обернуть в единообразный тип T результата функции) — операция композиции (>=>) Операция bind (>>=) здесь вводится как функция внутренней реализации композиции.
3) сопрограммы (но это не точно).
sshikov
А не присоветуете хороший текст, который раскрыл бы вот какую тему: связь между теорией категорий и ее применением в коде? Ну т.е., вот мы имеем числа, и сложение. И они обладают определенными свойствами. И тоже самое в коде, в виде реализации моноида. Какие конкретно выводы мы можем сделать применительно к коду из того, что доказали наличие определенных свойств у чисел?
Я, честно говоря, надеялся что автор тут это раскроет, но как-то не сложилось. То есть, получился подход к теме еще с одной стороны (помимо чистой теории категорий и картинок с коробочками), но вот объединения всех взглядов на предмет опять в одном тексте как-то не получилось.
PsyHaSTe Автор
Связь между теорией категорий и применением не прям существенная, потому что как следует из названия теория категорий исследует множество категорий, а в программировании она одна — категория типов. Поэтому всё богатство теорката сводится просто к аналогиям, что вот смотрите, тут есть математическая структура с некоторыми свойствами, и очень похожая структура данных, которая ведет себя почти так же.
Теоркат — скорее источник вдохновения, нежели вещь которая находит непосредственное применение в коде.
Реализация моноида — это просто способ сделать некоторые вычисления более удобными, например выразить операции суммы, произведения, all, any, и так далее. Я через моноид например делал многопоточный подсчёт количества слов в тексте: разбиваем текст на какое-то количество чанков, независимо считаем в каждом сколько слов. В итоге получаем множество объектов вида (кусок предыдущего слова, количество слов, начало следующего слова). Склеивая их друг с другом, подсчитываем слова, профит. Реализация в виде моноида позволяет не писать никакой многопоточный код — можноиспользовать стандартный, просто даёте на вход файл и говорите "сверните моим моноидом", на выходе — подсчитанное количество слов в этом файле. Просто и удобно.
Про связь типов и чисел можно почитать занимательные статьи вроде этой про АДТ, но кроме этого ничего прям супер классного нет.
technic93
Так стоп, прикладная математика работает так: есть реальная сущность -> формализируем -> получаем мат.модель -> делаем лукап в мат теории -> получаем полезную теорему -> все развернули обратно в реальность -> ура есть профит.
Если же у меня просто какие то реальные сущености. И я их классифицирую то это ботаника.
PsyHaSTe Автор
Не всегда же так. Например, сначала придумываем, как обобщить сумму ряда, чтобы для расходящегося натурального ряда она давала -1/12, а потом через сотню лет находим физический процесс (стр.85), который как раз описывается такой формулой.
technic93
Аналогия весьма отдалённая, т.к. в физике всегда есть что то что на текущий момент нельзя объяснить :)
Например, у вас уже есть вот эта бесплатная теорема которая вроде бы упрощает тестирование. Может еще что то уже есть, или про категорию типов известно мало полезных свойств?
Например, какой нужен минимум фич чтобы программировать над типами? вот если в раст завезут наконец эти HKT то уже можно радоваться или нет?) Я думаю в первую очередь это интересно создателем новых ЯП или развивателям текущих.
PsyHaSTe Автор
Так ведь наоборот же, оказалось что объяснение давно уже было)
Бесплатные теоремы можно получать достаточно просто, у хаскеллистов даже есть бот который делает это автоматически. Но, чтобы получить бесплатную теорему, нужно сначала сформулировать, что собственно хотим. А правильно заданный вопрос, как известно, это половина ответа.
Что до хкт и остального — радоваться можно каждой хорошей фиче, но какого-то супер-формального обоснования для них пока нет. Всё же программирование всё еще не доросло до инженерной дисциплины, куча вещей продолжает делаться методом тыка и "у гугла так принято".
technic93
Мне вот интересно как система темплейтов сами знаете где относится к другим системам типов, например тот же хаскель. Но ничего с теор подходом не нагуглилось, а если бы нагуглилось я бы все равно не понял)
sshikov
Я, честно говоря, рассчитывал бы от математики получить примерно вот что: если мы реализовали в коде математическую структуру X, и доказали, что выполняются некоторые правила (типа наличия единицы и ассоциативности), то наш код будет обладать еще вот такими свойствами. Ну т.е., доказательства наличия некоторых свойства нашего кода, если он уже обладает некоторыми другими, более простыми.
PsyHaSTe Автор
Ну, такие свойства есть. Собственно, основное свойство такое, что если мы пишем монады, то мы всегда можем их композировать друг с другом. А всё программирование заключается в том, чтобы побить сложную задачу накучку мелких, решить их по-отдельности, и собрать обратно. И вот когда мы собираем их обратно, обычно и возникают проблемы, потому что паззл не совпадает, и мы начинаем молотком их забивать, "закостыливая" некоторые места. Отсюда все эти эксепшны "should never throw" и так далее.
Гарантия того, что паззл гарантированно собирается — очень неплохая штука.
sshikov
>всегда можем их композировать друг с другом
Ну как-бы из ассоциативности нечто похожее и должно вытекать, вроде )))
В целом это все понятно — на интуитивном уровне. Т.е. есть у нас единица, и есть ассцоиативная операция — можем сделать fold при помощи этой операции и этой единицы. Разве что гарантией я бы это не называл (ну или я не вижу, откуда у нас тут гарантии).
PsyHaSTe Автор
Потому что стрелка клейсли. Потому что монады описывают эффекты, и у вас не получится случайно вызвать в цикле функцию которая ходит в рест сервис и получить бан за ддос апи. Потому что стрелки клейсли:
У нас есть функция a -> m b и b -> m c, и мы их хотим скомпозировать в a -> m c. В этом нам монады и помогают.
А когда мы не можете отличить a -> b и a -> m b и используем одно вместо другого, и получается заддосивание шлюзов и другие неприятные вещи. Потому что это знание все равно есть, но вместо проверки компилятором одно живет в духе "давайте венгерской нотацией называть функции с суффиксом Async и сделаем правило не вызывать Async функции в цикле", а может и еще хуже: где-нибудь закопанно на корпоративной вики.
Druu
Вообще никакой связи. Обычная ф-я — это тоже стрелка Клейсли, но никто не мешает вызвать в цикле ф-ю, которая ходит в рест сервис и получить бан за ддос апи. Вообще с чего бы это были проблемы с вызовами стрелок Клейсли в цикле, когда есть forM_
PsyHaSTe Автор
forM_явно показывет, что тут происходит эффект (причем какой конкретно), поэтому можно догадаться, что что-то не то. А вот когда обычныйmapвдруг так делает, результат совсем иной.Druu
Какой эффект явно происходит в Id?
У меня map так не делает, только forEach.
PsyHaSTe Автор
Если я пишу коде (Monad m) =>… то мне не важно, какой там эффект, я даю возможность вставить любой. В том числе и "no-op". Было быстранно, если бы не разрешал.
А я вот в дотнете видел
.Select(x => {Console.WriteLine(x); return x*2;})не раз.Druu
Это софистика сейчас, если no-op это эффект, то тогда не-монадический код имеет эффект — тот самый no-op.
Но это же плюс, что можно внутрь мапа засунуть спокойно лог и почекать че там, разве нет?
PsyHaSTe Автор
Монада дает возможность встроить эффект, но-оп это тоже эффект. Точно так же как ФВП дают возможность передавать функцию, которая может быть
() -> {}— нооп. От этого возможность выполнить произвольную функцию про которую мы ничего не знаем — не перестала быть ценной.Нет, это минус, у меня так эластик умер. А заодно и БД, когда орм не смогла это странслировать в SQL и попыталась выгрузить всю таблицу в память.
mayorovp
Ну вот это к монадам и ФП точно отношения не имеет. Проблема-то не в
Console.WriteLine, а в отсутствии маппинга.PsyHaSTe Автор
Проблема в том, что без ссылочной прозрачности изменение сигнатуры
CommentId -> CommentнаCommentId -> IO Commentне является ломающим изменением.mayorovp
Ну так при чём тут ссылочная прозрачность-то?
ORM для трансляции нужна не она
PsyHaSTe Автор
Без неё нет смысла в IO, потому что это просто маркер "здесь значение может поменяться"
mayorovp
Но при чём тут IO?
Druu
Дело в том, что в реальности они не выполняются. В ИРЛ-программировании не существует "настоящих" монад, по-этому любое утверждение о свойствах может неожиданно и нетривиально обломаться. И если в хаскеле это еще можно как-то подшаманить — то в энергичном языке нет. Да и некоторые монады просто в логике своей работы противоречат "монадичности".
Но свойства эти бесполезные и на практике неприменимые (за очень редким исключением) — по-этому никто обычно и не парится тем, что монада на самом деле не монада (вон для Nullable в c# тупо не пишется джойн, но менее монадой Nullable от этого не становится).
С другой стороны, выполняются "слабые конструктивные" утверждения — навроде того, что если у вас есть монада, то почти наверняка она определенным образом выражается через call/cc-монаду.
fori
А можно чуть пояснить что такое ИРЛ-программирование и почему там нет настоящих монад? Либо ссылкой кинуть.
Druu
"ИРЛ-программирование" — это чем программисты на работе занимаются. Настоящих монад там нету по той же самой причине, по которой в реальности нету настоящих квадратов или кругов.
fori
Все абстракции текут, тут ничего не поделать. С другой стороны если нам не нужен какой то из законов, то почему бы его не выкинуть? Если выяснили что для композиции достаточно быть просто моноидом и не нужно ограничивать функтор до эндо, то давайте его выкинем вместе с ненужными нам свойствами типа join. Мат законы кажутся ненужными, так как мы начинаем думать о них как о само собой разумеющимся и не требующим доказательств. А потом когда встречаем случай где он не соблюдается и вся наша логика ломается — то сильно удивляемся.
Druu
Все правильно, все законы можно выкинуть. Более того — не надо даже быть функтором (тем более аппликативом). Все, что нужно — это бинд, притом от него даже не требуется иметь заданную сигнатуру. Если вы его напишите, то сможете без каких-либо проблем использовать полученную штуку в качестве монады.
Здесь просто есть один не всем очевидный момент — монада задает некоторое подмножество для более общей конструкции. Нам на практике нужна вот именно эта более общая конструкция. Не монада.
Что у нас в реальности? В реальности мы отдаем наверх некоторый объект x: a и продолжение cont: b -> c. Потом мы делаем f(x, cont) — это та самая общая конструкция, которая определяет, каким образом нам следует применить продолжение к тому, что мы реально туда засунули. Если здесь теперь a = m a', b = a', c = m c', то cont: a' -> m c', и f — это бинд. Общий тип f будет a -> (b -> c) -> d. Ограничение на типы при этом возникает из требования универсальности бинда: тип d должен быть связан с типом c, и тип a с типом b, собственно, a = m b, c = d в случае монады. Но вы можете выбрать другие варианты, какие захотите, все будет работать. Ну и никто, конечно, не требует ни законов ни даже функториальности тут.
fori
Не совсем все выкинуть, а просто не думать о тех из них, про которые думает компилятор. Пока о них думает компилятор например проверяя типы — все хорошо. Ну вот допустим написали хитрый fold, а потом выяснилось что с ним ассоциативность не работает за которой компилятор не следит — что результат будет зависеть от того в каком порядке фолдить. И узнаем об этом на проде где много ядер и потоков, где возникли кейсы, в которых он стал меняться.
Druu
Думать надо о тех, которые нужны, и не думать о тех, которые не нужны. Монадические законы нам, по факту не нужны почти никогда. Исключение одно — если вы пишите на хаскеле и используете комбинаторы, которые написаны с оглядкой на эти законы.
А при чем тут fold? Мы конкретно про монады. Ну и операция для folda в принципе не должна быть ассоциативна (часто это и не возможно), от нее это не требуется.
St_one
Можете подробнее объяснить почему ReaderT, например, не настоящая монада? Или на примере — что настоящая монада, а что нет.
Спрашиваю из интереса, не ради спора. Если можно — простое объяснение, пожалуйста.
koldyr
ReaderT это трансформер. Монадой будет ReaderT m, где m-монада.
St_one
Да, точно. Вопрос тогда — точно ли будет? И какая есть "не монада", скрывающаяся за личиной монады.
Может у Вас есть идеи?
koldyr
Непонятно, что такое ненастоящая монада. В теории категорий монада определяется строго. Все это определение слышали и мусолить его смысла нет. Если нуженипример функтора, не являющегося монадой, то — ZipList. Доказательство не знаю.
St_one
Спасибо за ответ. Мне тоже непонятно что такое «ненастоящая монада». Или что имелось в виду.
Просто не раз уже подобные утверждения слышал, хотел узнать подробнее.
mayorovp
Пример ненастоящей монады — это Promise в Javascript.
Оно подчиняется основным монадическим законам, но при этом не является функтором из-за особенностей обработки вложенных обещаний.
Также некоторая "ненастоящесть" наблюдается в монаде Promsie/Task/Future/… во многих нефункциональных языках — "настоящая"-то монада должна быть ленивой, чего обычно не наблюдается.
PsyHaSTe Автор
А вот про ленивость я не помню требований. Если говорить про категорию, то там важно только чтобы стрелки коммутировали. "Ленивость" — внешнее свойство по отношению к тому что теоркат моделирует. Если вспомнить, то мы в япах нас интересует категория Set. А отображения между множествами просто "есть", никто не "вычисляет" функции, соответственно и ленивости/жадности никакой тоже нет.
mayorovp
Тут противоречие не столько с теоркатом, сколько со стандартной интерпретацией теорката в программировании. Условный
Task<int>— это не просто некоторое значение, а фоновой процесс, имеющий наблюдаемые сторонние эффекты.Возможно, можно построить интерпретацию, которая рассматривает не значения, а процессы. Но мне кажется что так не получится.
technic93
Почему наблюдаемые? На уровне абстракции тасков вы их не наблюдаете.
PsyHaSTe Автор
Ну мы же всегда в модели оцениваем. А то так получится что fmap id != id, потому что разное количество памяти выделяем, а это тоже можно пронаблюдать, и сделать вывод что функторы не работают. Или замерять количество выделяемого процессором тепла, для двух фмапов будет больше, чем для одного. Ну и так далее.
Есть некоторые разумные рамки модели, в которых мы считаем эквивалентность действий. Наличие или отсутствие ленивости не дает заметных для модели особенностей.