
Кластер — это разновидность параллельной
или распределённой системы, которая:
1. состоит из нескольких связанных
между собой компьютеров;
2. используется как единый,
унифицированный компьютерный ресурс
Gregory F. Pfister, «In search of clusters».
Дано: есть бизнес-приложение (например, ERP-система), с которым работают одновременно тысячи (возможно, десятки тысяч) пользователей.
Требуется:
Чтобы решить эти задачи, мы в платформе 1С:Предприятие используем кластерную архитектуру.
К желаемому результату мы пришли не сразу.
В этой статье расскажем о том, какие бывают кластеры, как мы выбирали подходящий нам вид кластера и о том, как эволюционировал наш кластер от версии к версии, и какие подходы позволили нам в итоге создать систему, обслуживающую десятки тысяч одновременных пользователей.
Как писал автор эпиграфа к этой статье Грегори Пфистер в своей книге «In search of clusters», кластер был придуман не каким-либо конкретным производителем железа или софта, а клиентами, которым не хватало для работы мощностей одного компьютера или требовалось резервирование. Случилось это, по мнению Пфистера, ещё в 60-х годах прошлого века.
Традиционно различают следующие основные виды кластеров:
Для решения наших задач (устойчивость к выходу из строя компонентов системы и эффективное использование ресурсов) нам требовалось объединить функциональность отказоустойчивого кластера и кластера с балансировкой нагрузки. Пришли мы к этому решению не сразу, а приближались к нему эволюционно, шаг за шагом.
Для тех, кто не в курсе, коротко расскажу, как устроены бизнес-приложения 1С. Это приложения, написанные на предметно-ориентированном языке, «заточенном» под автоматизацию учётных бизнес-задач. Для выполнения приложений, написанных на этом языке, на компьютере должен быть установлен рантайм платформы 1С:Предприятия.
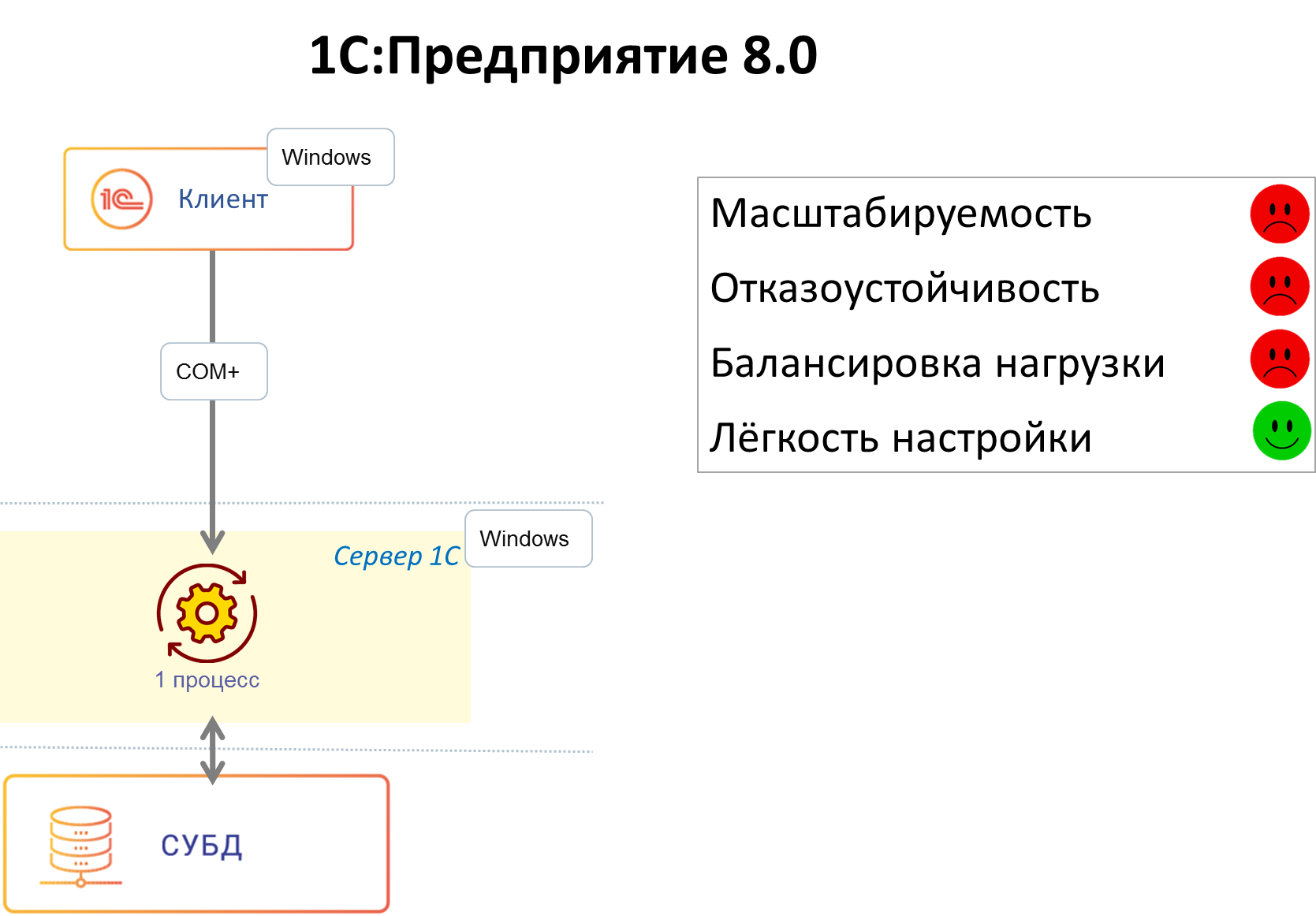
Первая версия сервера приложений 1С (еще не кластер) появилась в версии платформы 8.0. До этого 1С работала в клиент-серверном варианте, данные хранились в файловой СУБД или MS SQL, а бизнес-логика работала исключительно на клиенте. В версии же 8.0 был сделан переход на трехзвенную архитектуру «клиент – сервер приложений – СУБД».
Сервер 1С в платформе 8.0 представлял собой СОМ+ сервер, умеющий исполнять прикладной код на языке 1С. Использование СОМ+ обеспечивало нам готовый транспорт, позволяющий клиентским приложениям общаться с сервером по сети. Очень многое в архитектуре и клиент-серверного взаимодействия, и прикладных объектов, доступных разработчику 1С, проектировалось с учетом использования СОМ+. В то время в архитектуру не было заложено отказоустойчивости, и падение сервера вызывало отключение всех клиентов. При падении серверного приложения СОМ+ поднимал его при обращении к нему первого клиента, и клиенты начинали свою работу с начала – с коннекта к серверу. В то время всех клиентов обслуживал один процесс.
В следующей версии мы захотели:
При этом мы не хотели разрабатывать новую версию платформы с нуля – это было бы слишком ресурсозатратно. Мы хотели по максимуму использовать наши наработки, а также сохранить совместимость с прикладными приложениями, разработанными для версии 8.0.
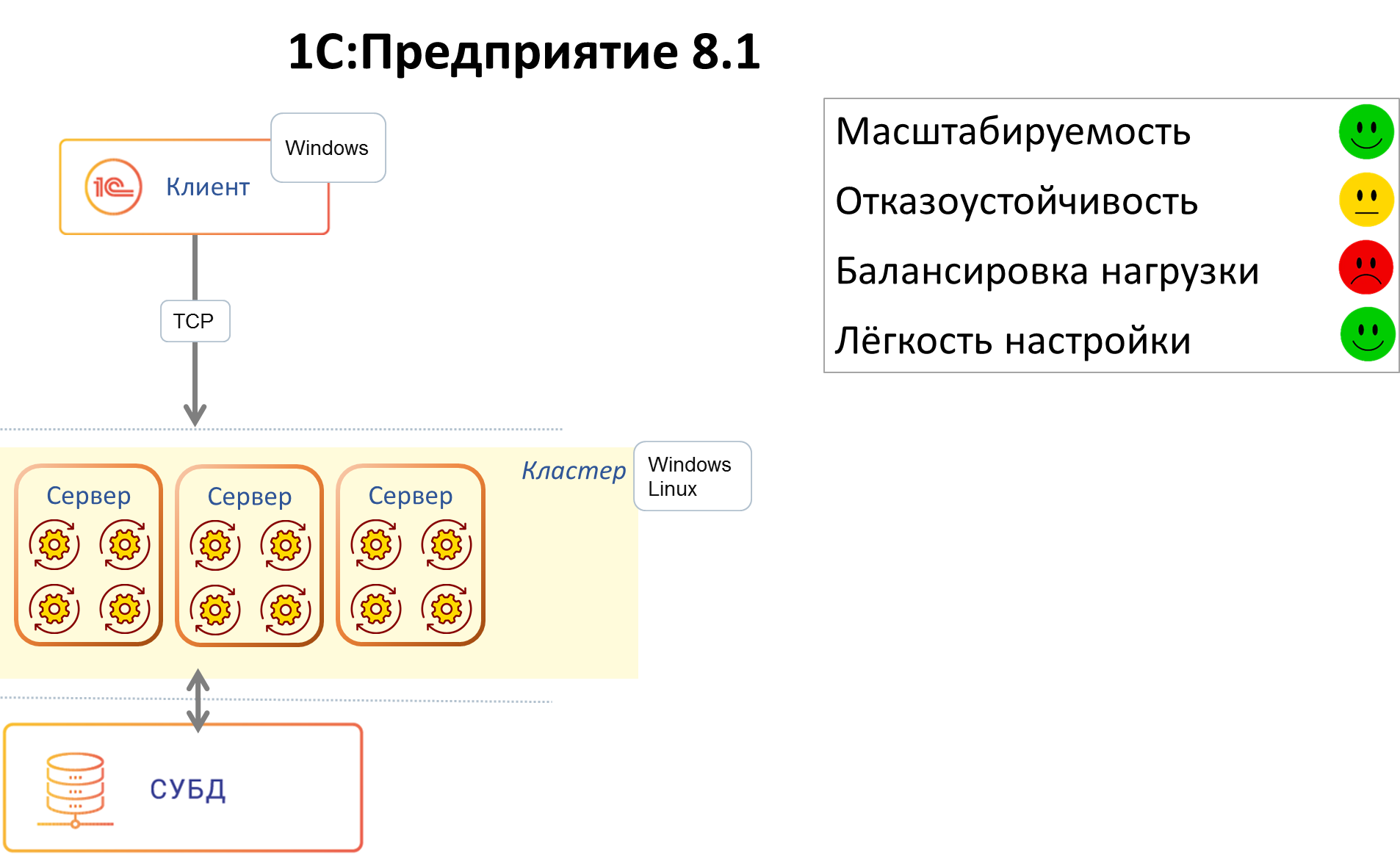
Так в версии 8.1 появился первый кластер. Мы реализовали свой протокол удаленного вызова процедур (поверх ТСР), который по внешнему виду выглядел для конечного потребителя-клиента практически как СОМ+ (т.е. нам практически не пришлось переписывать код, отвечающий за клиент-серверные вызовы). При этом сервер, реализованный нами на С++, мы сделали платформенно-независимым, способным работать и на Windows, и на Linux.
На смену монолитному серверу версии 8.0 пришло 3 вида процессов – рабочий процесс, обслуживающий клиентов, и 2 служебных процесса, поддерживающих работу кластера:
Клиент на протяжении сессии работал с одним рабочим процессом, падение рабочего процесса означало для всех клиентов, которых этот процесс обслуживал, аварийное завершение сессии. Остальные клиенты продолжали работу.
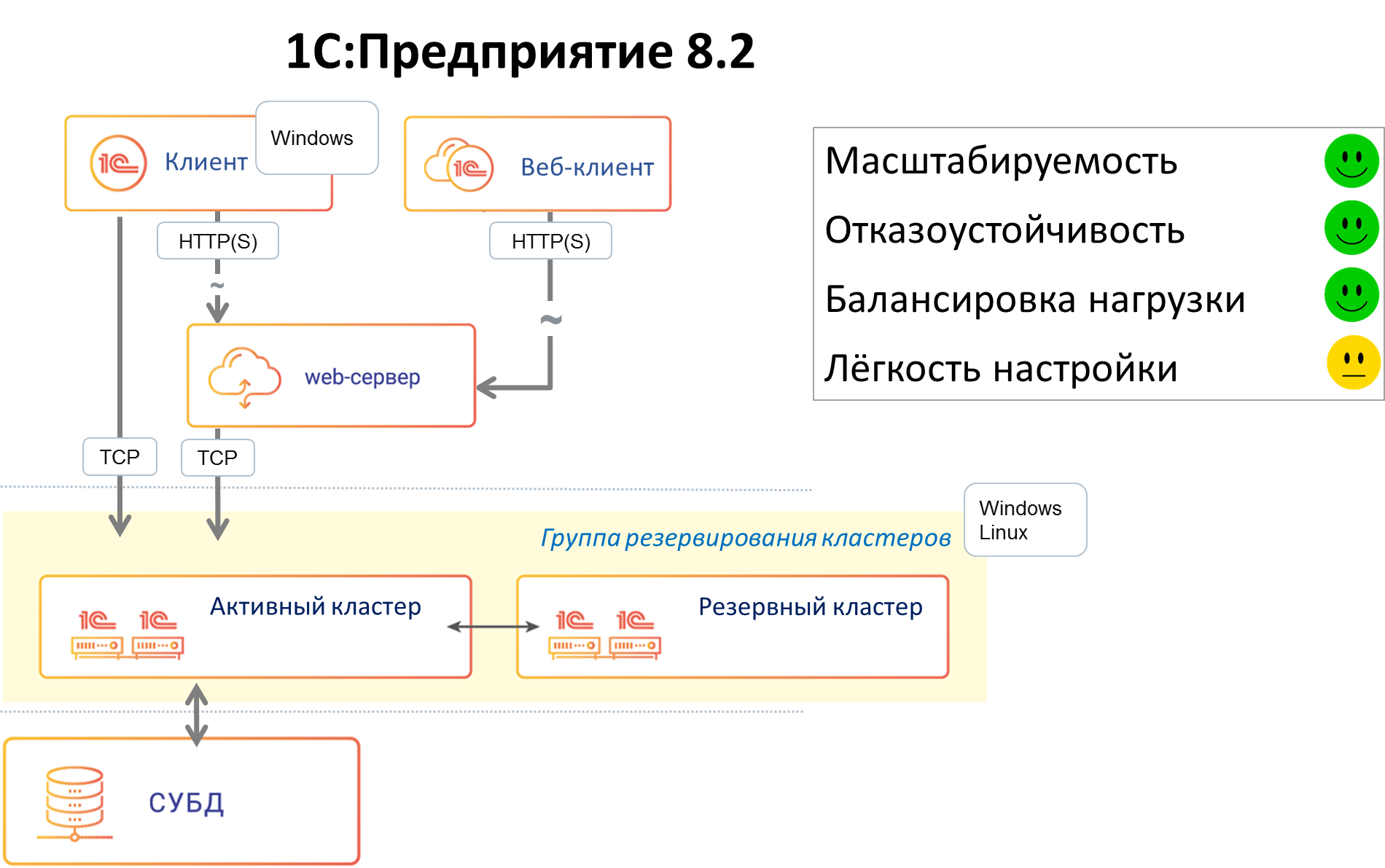
В версии 8.2 мы захотели, чтобы приложения 1С могли запускаться не только в нативном (исполняемом) клиенте, а ещё и в браузере (без модификации кода приложения). В связи с этим, в частности, встала задача отвязать текущее состояние приложения от текущего соединения с рабочим процессом rphost, сделать его stateless. Как следствие возникло понятие сеанса и сеансовых данных, которые нужно было хранить вне рабочего процесса (потому что stateless). Был разработан сервис сеансовых данных, хранящий и кэширующий сеансовую информацию. Появились и другие сервисы — сервис управляемых транзакционных блокировок, сервис полнотекстового поиска и т.д.
В этой версии также появились несколько важных нововведений – улучшенная отказоустойчивость, балансировка нагрузки и механизм резервирования кластеров.
Поскольку процесс работы стал stateless и все необходимые для работы данные хранились вне текущего соединения «клиент – рабочий процесс», в случае падения рабочего процесса клиент при следующем обращении к серверу переключался на другой, «живой» рабочий процесс. В большинстве случаев такое переключение происходило незаметно для клиента.
Механизм работает так. Если клиентский вызов к рабочему процессу по какой-то причине не смог исполниться до конца, то клиентская часть способна, получив ошибку вызова, этот вызов повторить, переустановив соединение с тем же рабочим процессом или с другим. Но повторять вызов можно не всегда; повтор вызова означает, что мы отправили вызов на сервер, а результата не получили. Мы стараемся повторить вызов, при этом при выполнении повторного вызова мы оцениваем, каков результат на сервере был у предшествующего вызова (информация об этом сохраняется на сервере в данных сеанса), потому что если вызов успел там «наследить» (закрыть транзакцию, сохранить сеансовые данные и т.п.) – то просто так повторять его нельзя, это приведет к рассогласованию данных. Если повторять вызов нельзя, клиент получит сообщение о неисправимой ошибке, и клиентское приложение придется перезапустить. Если же вызов «наследить» не успел (а это наиболее частая ситуация, т.к. многие вызовы не меняют данных, например, отчеты, отображение данных на форме и т.п., а те, которые меняют данные – пока транзакция не зафиксирована или пока изменение сеансовых данных не отправлено в менеджер – следов вызов не оставил) — его можно повторить без риска рассогласования данных. Если рабочий процесс упал или произошел обрыв сетевого соединения – такой вызов повторяется, и эта «катастрофа» для клиентского приложения происходит полностью незаметно.
Задача балансировки нагрузки в нашем случае звучит так: в систему заходит новый клиент (или уже работающий клиент совершает очередной вызов). Нам надо выбрать, на какой сервер и в какой рабочий процесс направить вызов клиента, чтобы обеспечить клиенту максимальное быстродействие.
Это стандартная задача для кластера с балансировкой нагрузки. Есть несколько типовых алгоритмов её решения, например:
Для нашего кластера мы выбрали алгоритм, близкий по сути к Least Response Time. У нас есть механизм, собирающий статистику производительности рабочих процессов на всех серверах кластера. Он делает эталонный вызов каждого процесса сервера в кластере; эталонный вызов задействует некоторое подмножество функций дисковой подсистемы, памяти, процессора, и оценивает, насколько быстро выполняется такой вызов. Результат этих измерений, усредненный за последние 10 минут, является критерием — какой сервер в кластере является наиболее производительным и предпочтительным для отправки к нему клиентских соединений в данный период времени. Запросы клиентов распределяются таким образом, чтобы получше нагрузить наиболее производительный сервер – грузят того, кто везет.
Запрос от нового клиента адресуется на наиболее производительный на данный момент сервер.
Запрос от существующего клиента в большинстве случаев адресуется на тот сервер и в тот рабочий процесс, в который адресовался его предыдущий запрос. С работающим клиентом связан обширный набор данных на сервере, передавать его между процессами (а тем более между серверами) – довольно накладно (хотя мы умеем делать и это).
Запрос от существующего клиента передается в другой рабочий процесс в двух случаях:
Мы решили повысить отказоустойчивость кластера, прибегнув к схеме Active / passive. Появилась возможность конфигурировать два кластера – рабочий и резервный. В случае недоступности основного кластера (сетевые неполадки или, например, плановое техобслуживание) клиентские вызовы перенаправлялись на резервный кластер.
Однако эта конструкция была довольно сложна в настройке. Администратору приходилось вручную собирать две группы серверов в кластеры и конфигурировать их. Иногда администраторы допускали ошибки, устанавливая противоречащие друг другу настройки, т.к. не было централизованного механизма проверки настроек. Но, тем не менее, этот подход повышал отказоустойчивость системы.
В версии 8.3 мы существенно переписали код серверной части, отвечающий за отказоустойчивость. Мы решили отказаться от схемы Active / passive кластеров ввиду сложности её конфигурирования. В системе остался только один отказоустойчивый кластер, состоящий из любого количества серверов – это ближе к схеме на Active / active, в которой запросы на отказавший узел распределяются между оставшимися рабочими узлами. За счет этого кластер стал проще в настройке. Ряд операций, повышающих отказоустойчивость и улучшающих балансировку нагрузки, стали автоматизированными. Из важных нововведений:
Главная идея этих наработок – упростить работу администратора, позволяя ему настраивать кластер в привычных ему терминах, на уровне оперирования серверами, не опускаясь ниже, а также минимизировать уровень «ручного управления» работой кластера, дав кластеру механизмы для решения большинства рабочих задач и возможных проблем «на автопилоте».
Как известно, даже если компоненты системы по отдельности надёжны, проблемы могут возникнуть там, где компоненты системы вызывают друг друга. Мы хотели свести количество мест, критичных для работоспособности системы, к минимуму. Важным дополнительным соображением была минимизация переделок прикладных механизмов в платформе и исключение изменений в прикладных решениях. В версии 8.3 появилось 3 звена обеспечения отказоустойчивости «на стыках»:
Благодаря механизму отказоустойчивости приложения, созданные на платформе 1С:Предприятие, благополучно переживают разные виды отказов рабочих серверов в кластере, при этом бо?льшая часть клиентов продолжают работать без перезапуска.
Бывают ситуации, когда мы не можем повторить вызов, или падение сервера застает платформу в очень неудачный момент времени, например, в середине транзакции и не очень понятно, что с ними делать. Мы стараемся обеспечить статистически хорошую выживаемость клиентов при падении серверов в кластере. Как правило, средние потери клиентов за отказ сервера – единицы процентов. При этом все «потерянные» клиенты могут продолжить работу в кластере после перезапуска клиентского приложения.
Надежность кластера серверов 1С в версии 8.3 существенно повысилась. Уже давно не редкость внедрения продуктов 1С, где количество одновременно работающих пользователей достигает нескольких тысяч. Есть и внедрения, где одновременно работают и 5 000, и 10 000 пользователей — например, внедрение в «Билайне», где приложение «1С: Управление Торговлей» обслуживает все салоны продаж «Билайн» в России, или внедрение в грузоперевозчике «Деловые Линии», где приложение, самостоятельно созданное разработчиками ИТ-отдела «Деловых Линий» на платформе 1С:Предприятие, обслуживает полный цикл грузоперевозок. Наши внутренние нагрузочные тесты кластера эмулируют одновременную работу до 20 000 пользователей.
В заключение хочется кратко перечислить что ещё полезного есть в нашем кластере (список неполный):
или распределённой системы, которая:
1. состоит из нескольких связанных
между собой компьютеров;
2. используется как единый,
унифицированный компьютерный ресурс
Gregory F. Pfister, «In search of clusters».
Дано: есть бизнес-приложение (например, ERP-система), с которым работают одновременно тысячи (возможно, десятки тысяч) пользователей.
Требуется:
- Сделать приложение масштабируемым, чтобы при увеличении количества пользователей можно было за счёт наращивания аппаратных ресурсов обеспечить необходимую производительность приложения.
- Сделать приложение устойчивым к выходу из строя компонентов системы (как программных, так и аппаратных), потере связи между компонентами и другим возможным проблемам.
- Максимально эффективно задействовать системные ресурсы и обеспечить нужную производительность приложения.
- Сделать систему простой в развертывании и администрировании.
Чтобы решить эти задачи, мы в платформе 1С:Предприятие используем кластерную архитектуру.
К желаемому результату мы пришли не сразу.
В этой статье расскажем о том, какие бывают кластеры, как мы выбирали подходящий нам вид кластера и о том, как эволюционировал наш кластер от версии к версии, и какие подходы позволили нам в итоге создать систему, обслуживающую десятки тысяч одновременных пользователей.
Как писал автор эпиграфа к этой статье Грегори Пфистер в своей книге «In search of clusters», кластер был придуман не каким-либо конкретным производителем железа или софта, а клиентами, которым не хватало для работы мощностей одного компьютера или требовалось резервирование. Случилось это, по мнению Пфистера, ещё в 60-х годах прошлого века.
Традиционно различают следующие основные виды кластеров:
- Отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
- Кластеры с балансировкой нагрузки (Load balancing clusters, LBC)
- Вычислительные кластеры (High performance computing clusters, HPC)
- Системы распределенных вычислений (grid) иногда относят к отдельному типу кластеров, который может состоять из территориально разнесенных серверов с отличающимися операционными системами и аппаратной конфигурацией. В случае grid-вычислений взаимодействия между узлами происходят значительно реже, чем в вычислительных кластерах. В grid-системах могут быть объединены HPC-кластеры, обычные рабочие станции и другие устройства.
Для решения наших задач (устойчивость к выходу из строя компонентов системы и эффективное использование ресурсов) нам требовалось объединить функциональность отказоустойчивого кластера и кластера с балансировкой нагрузки. Пришли мы к этому решению не сразу, а приближались к нему эволюционно, шаг за шагом.
Для тех, кто не в курсе, коротко расскажу, как устроены бизнес-приложения 1С. Это приложения, написанные на предметно-ориентированном языке, «заточенном» под автоматизацию учётных бизнес-задач. Для выполнения приложений, написанных на этом языке, на компьютере должен быть установлен рантайм платформы 1С:Предприятия.
1С:Предприятие 8.0
Первая версия сервера приложений 1С (еще не кластер) появилась в версии платформы 8.0. До этого 1С работала в клиент-серверном варианте, данные хранились в файловой СУБД или MS SQL, а бизнес-логика работала исключительно на клиенте. В версии же 8.0 был сделан переход на трехзвенную архитектуру «клиент – сервер приложений – СУБД».
Сервер 1С в платформе 8.0 представлял собой СОМ+ сервер, умеющий исполнять прикладной код на языке 1С. Использование СОМ+ обеспечивало нам готовый транспорт, позволяющий клиентским приложениям общаться с сервером по сети. Очень многое в архитектуре и клиент-серверного взаимодействия, и прикладных объектов, доступных разработчику 1С, проектировалось с учетом использования СОМ+. В то время в архитектуру не было заложено отказоустойчивости, и падение сервера вызывало отключение всех клиентов. При падении серверного приложения СОМ+ поднимал его при обращении к нему первого клиента, и клиенты начинали свою работу с начала – с коннекта к серверу. В то время всех клиентов обслуживал один процесс.
1С:Предприятие 8.1
В следующей версии мы захотели:
- Обеспечить нашим клиентам отказоустойчивость, чтобы аварии и ошибки у одних пользователей не приводили авариям и ошибкам у других пользователей.
- Избавиться от технологии СОМ+. СОМ+ работала только на Windows, а в то время уже начала становиться актуальной возможность работы под Linux.
При этом мы не хотели разрабатывать новую версию платформы с нуля – это было бы слишком ресурсозатратно. Мы хотели по максимуму использовать наши наработки, а также сохранить совместимость с прикладными приложениями, разработанными для версии 8.0.
Так в версии 8.1 появился первый кластер. Мы реализовали свой протокол удаленного вызова процедур (поверх ТСР), который по внешнему виду выглядел для конечного потребителя-клиента практически как СОМ+ (т.е. нам практически не пришлось переписывать код, отвечающий за клиент-серверные вызовы). При этом сервер, реализованный нами на С++, мы сделали платформенно-независимым, способным работать и на Windows, и на Linux.
На смену монолитному серверу версии 8.0 пришло 3 вида процессов – рабочий процесс, обслуживающий клиентов, и 2 служебных процесса, поддерживающих работу кластера:
- rphost – рабочий процесс, обслуживающий клиентов и исполняющий прикладной код. В составе кластера может быть больше одного рабочего процесса, разные рабочие процессы могут исполняться на разных физических серверах – за счёт этого достигается масштабируемость.
- ragent – процесс агента сервера, запускающий все другие виды процессов, а также ведущий список кластеров, расположенных на данном сервере.
- rmngr – менеджер кластера, управляющий функционированием всего кластера (но при этом на нем не работает прикладной код).
Под катом – схема работы этих трёх процессов в составе кластера.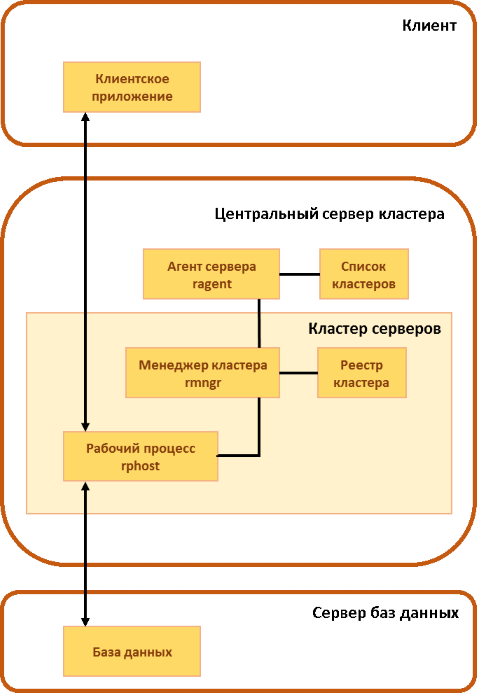
Клиент на протяжении сессии работал с одним рабочим процессом, падение рабочего процесса означало для всех клиентов, которых этот процесс обслуживал, аварийное завершение сессии. Остальные клиенты продолжали работу.
1С:Предприятие 8.2
В версии 8.2 мы захотели, чтобы приложения 1С могли запускаться не только в нативном (исполняемом) клиенте, а ещё и в браузере (без модификации кода приложения). В связи с этим, в частности, встала задача отвязать текущее состояние приложения от текущего соединения с рабочим процессом rphost, сделать его stateless. Как следствие возникло понятие сеанса и сеансовых данных, которые нужно было хранить вне рабочего процесса (потому что stateless). Был разработан сервис сеансовых данных, хранящий и кэширующий сеансовую информацию. Появились и другие сервисы — сервис управляемых транзакционных блокировок, сервис полнотекстового поиска и т.д.
В этой версии также появились несколько важных нововведений – улучшенная отказоустойчивость, балансировка нагрузки и механизм резервирования кластеров.
Отказоустойчивость
Поскольку процесс работы стал stateless и все необходимые для работы данные хранились вне текущего соединения «клиент – рабочий процесс», в случае падения рабочего процесса клиент при следующем обращении к серверу переключался на другой, «живой» рабочий процесс. В большинстве случаев такое переключение происходило незаметно для клиента.
Механизм работает так. Если клиентский вызов к рабочему процессу по какой-то причине не смог исполниться до конца, то клиентская часть способна, получив ошибку вызова, этот вызов повторить, переустановив соединение с тем же рабочим процессом или с другим. Но повторять вызов можно не всегда; повтор вызова означает, что мы отправили вызов на сервер, а результата не получили. Мы стараемся повторить вызов, при этом при выполнении повторного вызова мы оцениваем, каков результат на сервере был у предшествующего вызова (информация об этом сохраняется на сервере в данных сеанса), потому что если вызов успел там «наследить» (закрыть транзакцию, сохранить сеансовые данные и т.п.) – то просто так повторять его нельзя, это приведет к рассогласованию данных. Если повторять вызов нельзя, клиент получит сообщение о неисправимой ошибке, и клиентское приложение придется перезапустить. Если же вызов «наследить» не успел (а это наиболее частая ситуация, т.к. многие вызовы не меняют данных, например, отчеты, отображение данных на форме и т.п., а те, которые меняют данные – пока транзакция не зафиксирована или пока изменение сеансовых данных не отправлено в менеджер – следов вызов не оставил) — его можно повторить без риска рассогласования данных. Если рабочий процесс упал или произошел обрыв сетевого соединения – такой вызов повторяется, и эта «катастрофа» для клиентского приложения происходит полностью незаметно.
Балансировка нагрузки
Задача балансировки нагрузки в нашем случае звучит так: в систему заходит новый клиент (или уже работающий клиент совершает очередной вызов). Нам надо выбрать, на какой сервер и в какой рабочий процесс направить вызов клиента, чтобы обеспечить клиенту максимальное быстродействие.
Это стандартная задача для кластера с балансировкой нагрузки. Есть несколько типовых алгоритмов её решения, например:
- Round-Robin (циклический) – серверам присваиваются порядковые номера, первый запрос отправляется на первый сервер, второй запрос – на второй и т. д. до достижения последнего сервера. Следующий запрос направляется на первый сервер и всё начинается с начала. Алгоритм прост в реализации, не требует связи между серверами и неплохо подходит для «легковесных» запросов. Но при балансировке по этому алгоритму не учитывается производительность серверов (которая может быть разной) и текущая загруженность серверов.
- Weighted Round Robin – усовершенствованный Round-Robin: каждому серверу присваивается весовой коэффициент в соответствии с его производительностью, и сервера с бо?льшим весом обрабатывают больше запросов.
- Least Connections: новый запрос передается на сервер, обрабатывающий в данный момент наименьшее количество запросов.
- Least Response Time: сервер выбирается на основе времени его ответа: новый запрос отдаётся серверу, ответившему быстрее других серверов.
Для нашего кластера мы выбрали алгоритм, близкий по сути к Least Response Time. У нас есть механизм, собирающий статистику производительности рабочих процессов на всех серверах кластера. Он делает эталонный вызов каждого процесса сервера в кластере; эталонный вызов задействует некоторое подмножество функций дисковой подсистемы, памяти, процессора, и оценивает, насколько быстро выполняется такой вызов. Результат этих измерений, усредненный за последние 10 минут, является критерием — какой сервер в кластере является наиболее производительным и предпочтительным для отправки к нему клиентских соединений в данный период времени. Запросы клиентов распределяются таким образом, чтобы получше нагрузить наиболее производительный сервер – грузят того, кто везет.
Запрос от нового клиента адресуется на наиболее производительный на данный момент сервер.
Запрос от существующего клиента в большинстве случаев адресуется на тот сервер и в тот рабочий процесс, в который адресовался его предыдущий запрос. С работающим клиентом связан обширный набор данных на сервере, передавать его между процессами (а тем более между серверами) – довольно накладно (хотя мы умеем делать и это).
Запрос от существующего клиента передается в другой рабочий процесс в двух случаях:
- Процесса больше нет: рабочий процесс, с которым ранее взаимодействовал клиент, более недоступен (упал процесс, стал недоступен сервер и т.п.).
- Есть более производительный сервер: если в кластере есть сервер, отличающийся по производительности в два и более раза по сравнению с сервером, где запушен текущий рабочий процесс, то платформа считает, что даже ценой миграции клиентского контекста нам выгоднее выполнять запросы на более производительном сервере. Переноситься клиенты с одного сервера на другой будут постепенно, по одному, с периодической оценкой результата – что в плане производительности стало с серверами после переноса каждого из клиентских процессов. Цель этой процедуры – выравнивание производительности серверов в кластере (т.е. равномерная загрузка серверов).
Резервирование кластеров
Мы решили повысить отказоустойчивость кластера, прибегнув к схеме Active / passive. Появилась возможность конфигурировать два кластера – рабочий и резервный. В случае недоступности основного кластера (сетевые неполадки или, например, плановое техобслуживание) клиентские вызовы перенаправлялись на резервный кластер.
Однако эта конструкция была довольно сложна в настройке. Администратору приходилось вручную собирать две группы серверов в кластеры и конфигурировать их. Иногда администраторы допускали ошибки, устанавливая противоречащие друг другу настройки, т.к. не было централизованного механизма проверки настроек. Но, тем не менее, этот подход повышал отказоустойчивость системы.
1С:Предприятие 8.3
В версии 8.3 мы существенно переписали код серверной части, отвечающий за отказоустойчивость. Мы решили отказаться от схемы Active / passive кластеров ввиду сложности её конфигурирования. В системе остался только один отказоустойчивый кластер, состоящий из любого количества серверов – это ближе к схеме на Active / active, в которой запросы на отказавший узел распределяются между оставшимися рабочими узлами. За счет этого кластер стал проще в настройке. Ряд операций, повышающих отказоустойчивость и улучшающих балансировку нагрузки, стали автоматизированными. Из важных нововведений:
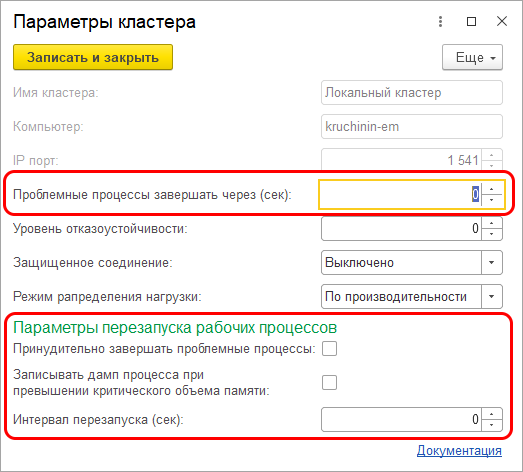
- Новая настройка кластера «Уровень отказоустойчивости»: число, указывающее, сколько серверов может выйти из строя без последствий в виде аварийного завершения сеансов подключенных пользователей. Исходя из этой настройки кластер будет тратить определённый объём ресурсов на синхронизацию данных между рабочими серверами, чтобы иметь всю необходимую для продолжения работы клиентов информацию на «живых» серверах в случае выхода из строя одного или нескольких серверов.
- Количество рабочих процессов не задается вручную, как раньше, а автоматически рассчитывается исходя из описаний требований задач по отказоустойчивости и надежности.
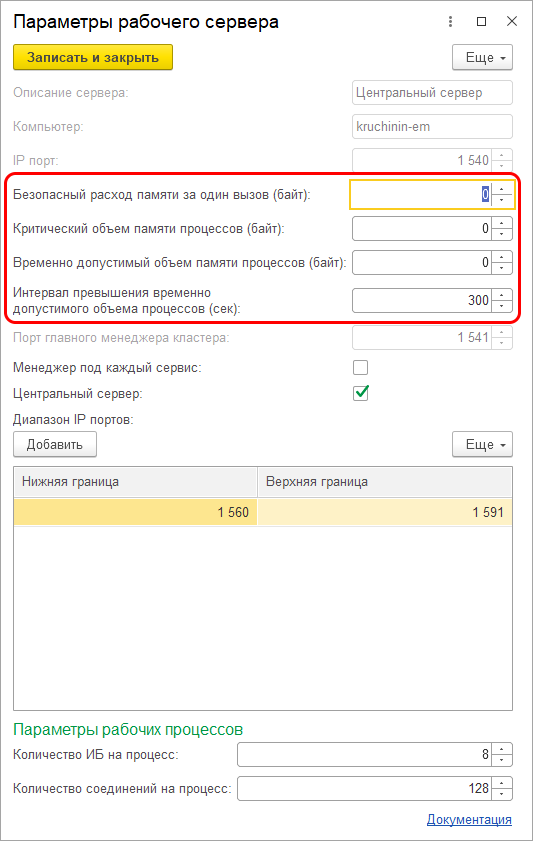
- Появился ряд настроек, связанных с максимальными объемами памяти, которые разрешается потреблять рабочим процессам, а также настройки, определяющие что делать, если эти объемы превышены:
Главная идея этих наработок – упростить работу администратора, позволяя ему настраивать кластер в привычных ему терминах, на уровне оперирования серверами, не опускаясь ниже, а также минимизировать уровень «ручного управления» работой кластера, дав кластеру механизмы для решения большинства рабочих задач и возможных проблем «на автопилоте».
Три звена отказоустойчивости
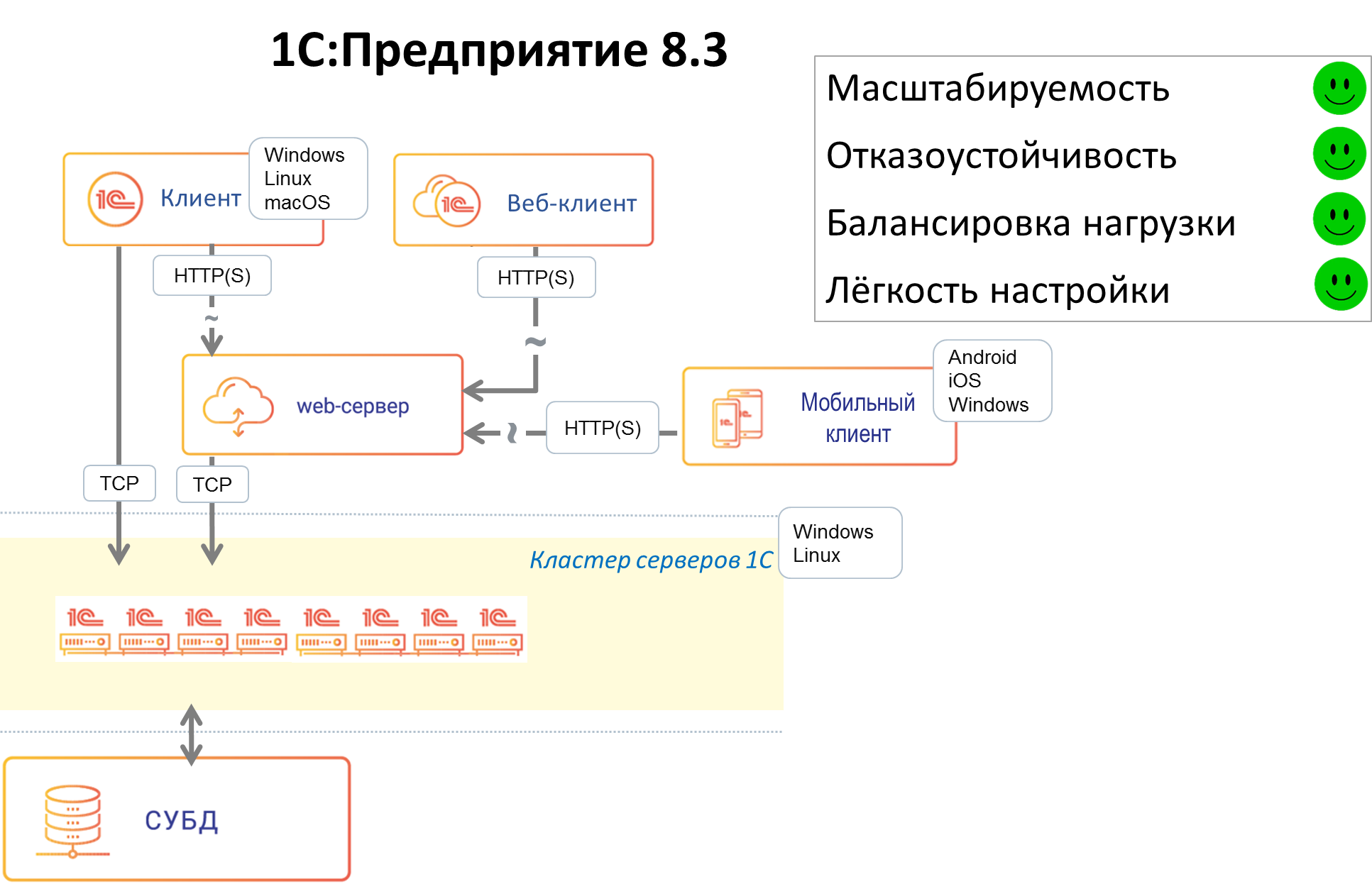
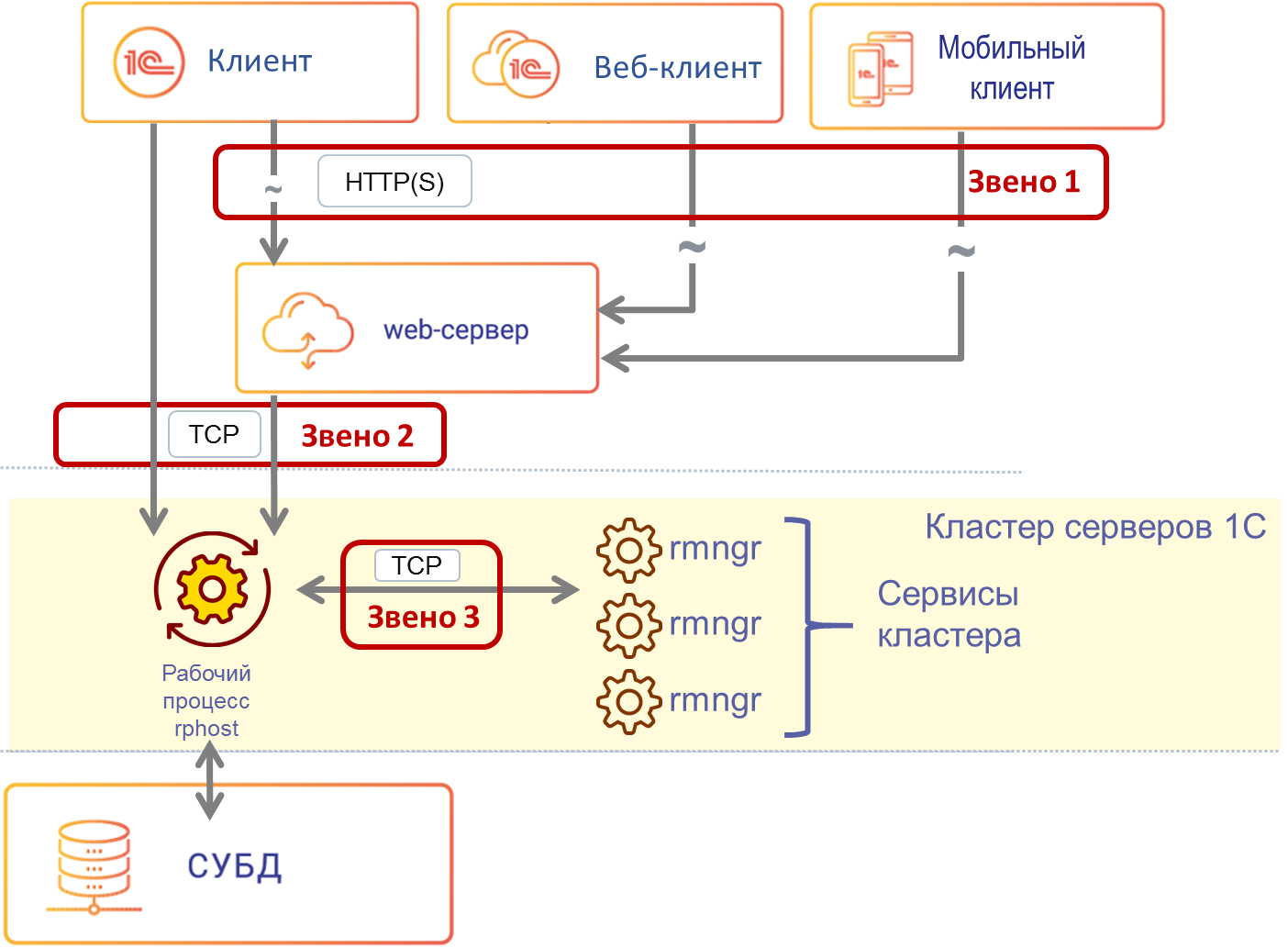
Как известно, даже если компоненты системы по отдельности надёжны, проблемы могут возникнуть там, где компоненты системы вызывают друг друга. Мы хотели свести количество мест, критичных для работоспособности системы, к минимуму. Важным дополнительным соображением была минимизация переделок прикладных механизмов в платформе и исключение изменений в прикладных решениях. В версии 8.3 появилось 3 звена обеспечения отказоустойчивости «на стыках»:
- Связь между клиентом, работающим по HTTP(S), и веб-сервером. В случае веб-клиента этот механизм стандартно реализуется веб-технологиями. В случае тонкого клиента, работающего по HTTP с веб-сервером, или мобильного клиента (мобильный клиент всегда работает по HTTP) мы используем библиотеку libcurl с открытым исходным кодом.
- Отслеживание разрывов соединений, механизм балансировки нагрузки и механизм повторов вызовов позволяют как можно раньше узнать о возникшей проблеме и предпринять действия по её устранению.
- Связь между ТСР-клиентом и рабочим процессом. Клиентом ТСР может выступать либо клиент 1С, либо расширение веб-сервера при работе клиента через НТТР. При выполнении каждого НТТР-вызова происходит выбор наиболее подходящего соединения с рабочим процессом и отправка этого вызова. Наиболее подходящее соединение выбирается исходя из того, в какой рабочий процесс отправлялся предыдущий вызов данного клиента. Если следующий вызов клиента можно отправить в тот же рабочий процесс, куда ушел предыдущий вызов – мы так и поступаем. Только если по какой-то причине в данный рабочий процесс вызов отправить нельзя (потому, что рабочий процесс стал недоступен, либо мы знаем, что есть другой рабочий процесс с существенно лучшей производительностью) – мы отправляем новый клиентский вызов в более подходящий рабочий процесс.
- Связь между рабочими процессами сервисами кластера, реализованными в процессах rmngr. Сервисов кластера около 20 (в зависимости от версии платформы) — сервис сеансовых данных, сервис транзакционных блокировок и т.д. На этом уровне существенную роль играют механизм распределения сервисов по серверам и репликация данных сервисов кластера. Балансировка нагрузки на уровне 1С:Предприятия позволяет получать приблизительно одинаковую лучшую производительность от всех рабочих серверов.
В заключение
Благодаря механизму отказоустойчивости приложения, созданные на платформе 1С:Предприятие, благополучно переживают разные виды отказов рабочих серверов в кластере, при этом бо?льшая часть клиентов продолжают работать без перезапуска.
Бывают ситуации, когда мы не можем повторить вызов, или падение сервера застает платформу в очень неудачный момент времени, например, в середине транзакции и не очень понятно, что с ними делать. Мы стараемся обеспечить статистически хорошую выживаемость клиентов при падении серверов в кластере. Как правило, средние потери клиентов за отказ сервера – единицы процентов. При этом все «потерянные» клиенты могут продолжить работу в кластере после перезапуска клиентского приложения.
Надежность кластера серверов 1С в версии 8.3 существенно повысилась. Уже давно не редкость внедрения продуктов 1С, где количество одновременно работающих пользователей достигает нескольких тысяч. Есть и внедрения, где одновременно работают и 5 000, и 10 000 пользователей — например, внедрение в «Билайне», где приложение «1С: Управление Торговлей» обслуживает все салоны продаж «Билайн» в России, или внедрение в грузоперевозчике «Деловые Линии», где приложение, самостоятельно созданное разработчиками ИТ-отдела «Деловых Линий» на платформе 1С:Предприятие, обслуживает полный цикл грузоперевозок. Наши внутренние нагрузочные тесты кластера эмулируют одновременную работу до 20 000 пользователей.
В заключение хочется кратко перечислить что ещё полезного есть в нашем кластере (список неполный):
- Настройки безопасности, ограничивающие прикладному решению потенциально опасные для функционирования кластера операции. Например, можно ограничить доступ к файловой системе сервера или запретить прикладному решению запускать приложения, установленные на сервере.
- Требования назначения функциональности – механизм, позволяющий администратору указать, какие сервисы кластера, прикладные решения (или даже отдельные функции прикладных решений – отчёты, фоновые и регламентные задания и т.д.) должны работать на каждом из серверов. Например, если заранее известно, что с конкретным прикладным решением (например, бухгалтерией) будет работать существенно меньше пользователей, чем с ERP, возможно, имеет смысл настроить более мощный сервер на работу исключительно с ERP.
- Управление потреблением ресурсов – механизм, отслеживающий потребление кластером ресурсов (память, процессорное время, вызовы СУБД и т.д.). Он позволяет, в частности, выставлять пользователям квоты ресурсов, которые они не могут превысить, и прерывать операции, выполнение которых влияет на производительность сервера в целом.





Gamm
Всё звучит хорошо. Но странная функциональность, которая приводит к появлению ошибок на клиенте «Обратитесь к администратору для решения вопросов приобретения и установки лицензий уровня КОРП», при этом в интерфейсе администрирования и настройки кластера эта функциональность никак отдельно не выделена. Это явно не «лёгкость настройки».
PeterG Автор
Да, запрос на явное выделение в настройке КОРП-параметров есть, работаем над этим.