
Если вы используете Docker, следующим логичным шагом кажется переход на Kubernetes, он же K8s, правильно? Ну, предположим. Однако решения, предназначенные для 500 инженеров-программистов, одновременно разрабатывающих одно приложение, достаточно сильно отличаются от решений для 50 человек. А решение для команды из 5 программистов — это и вовсе другая история.
Если вы работаете в маленькой команде, Kubernetes, вероятнее всего, не для вас. Он принесет вам много боли в обмен на крайне скромные преимущества.
Давайте разберемся, почему это может произойти.
У Kubernetes двигается и меняется очень многое: концепции, подсистемы, процессы, машины, код… И все это означает массу сложностей.
Kubernetes является распределенной системой: в нем присутствует главная машина, которая которая контролирует остальные, рабочие. Каждая машина производит работу в контейнерах.
Итак, мы уже говорим минимум о двух физических или виртуальных машинах, необходимых только для того, чтобы всё это заработало. Но по факту вы получаете… всего одну машину. Если вы собираетесь масштабироваться (вот, где собака зарыта!), вам понадобятся три, четыре, а может, целых семнадцать виртуальных машин.
Кодовая база Kubernetes на начало марта 2020 года включает в себя более 580 000 строк кода на Go. И это только чистый код, исключая комментарии, пустые строки, а также вендорские пакеты. Security review 2019 года описывает кодовую базу следующим образом:
«Кодовая база Kubernetes имеет значительный простор для улучшения. Она велика и сложна, содержит крупные секции кода с минимальной документацией и огромное количество зависимостей, включая системы, не входящие в Kubernetes. Также в кодовой базе присутствует много случаев повторной реализации логики, которая могла бы быть централизована в поддерживающих библиотеках, что позволило бы сократить сложность, упростить внесение исправлений и снизить документальную нагрузку в различных областях кодовой базы».
Если честно, то же самое можно сказать и о многих других крупных проектах, но весь этот код должен корректно функционировать, если вы не хотите, чтобы ваше приложение отказало.
Kubernetes — это комплексная система со множеством различных сервисов, систем и прочего.
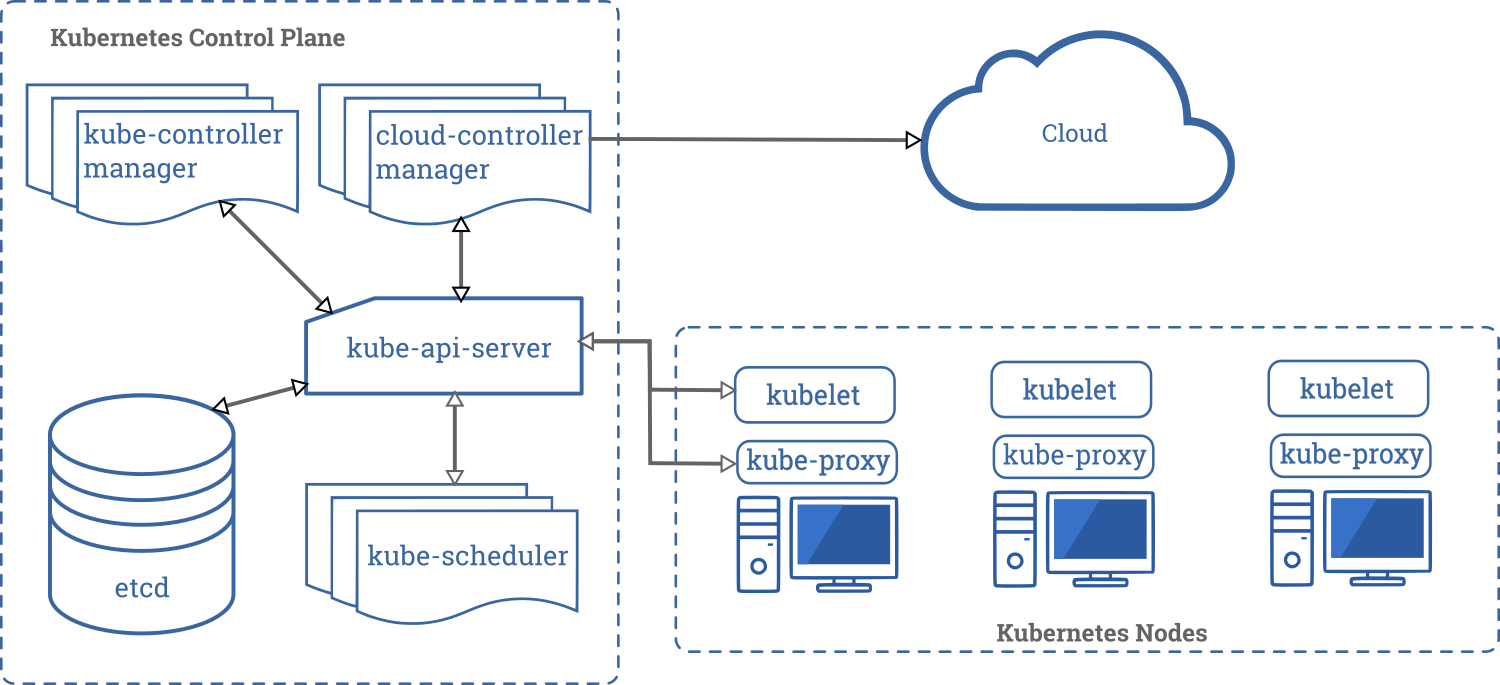
Прежде чем вы сможете запустить свое единственное приложение, вам придется обеспечить следующую, сильно упрощенную архитектуру (оригинальное изображение взято из документации по Kubernetes):
Документация по концепциям K8s включает множество сугубо «образовательных» вещей, таких как приведенный ниже фрагмент:
На самом деле, мне понятно, о чем здесь речь, но обратите внимание, как много понятий требуется изучить: EndpointSlice, Service, selector, Pod, Endpoint.
И — да, большую часть времени вы не будете использовать все эти возможности. Следовательно, большую часть времени вам вообще не будет нужен Kubernetes.
Вот еще один случайный фрагмент:
Вот что по этому поводу говорится в Security review:
Чем больше вы приобретаете в Kubernetes, тем сложнее становится нормальный процесс разработки: вам нужны все эти концепции (Pod, Deployment, Service, и т.д.) просто чтобы ваш код заработал. Таким образом, вам нужно раскрутить полноценную K8s систему даже просто для тестирования через виртуальную машину или вложенные контейнеры Docker.
И, поскольку ваше приложение становится труднее запустить локально, разработка усложняется за счет множества вариантов решения этой задачи, от стендового окружения до проксирования локального процесса в кластер (специально для этого я пару лет назад написал этот инструмент) и проксирования удаленного процесса на локальную машину…
Можно выбрать любой вариант, но ни один из них не будет идеален. Проще всего вообще не использовать Kubernetes.
Второстепенная проблема состоит в том, что, поскольку ваша система позволяет вам запускать множество сервисов, вам приходится писать это множество сервисов. Плохая идея.
Распределенное приложение тяжело написать качественно. На самом деле, чем больше движущихся частей, тем больше эти проблемы мешают работе.
Распределенные приложения тяжело отлаживать. Вам понадобится совершенно новый тип инструментов отладки и логирования, которые все равно дадут вам меньше, чем логи монолитного приложения.
Микросервисы — это одна из техник масштабирования в организациях: когда у вас в штате 500 разработчиков, которые обслуживают один продуктивный веб-сайт, имеет смысл смириться со стоимостью крупномасштабной распределенной системы, если это позволит командам разработчиков работать независимо друг от друга. Таким образом, каждая команда из 5 человек получает единственный микросервис, и делает вид, что все остальные микросервисы являются внешними службами, которым не стоит доверять.
Если же вся ваша команда состоит из 5 человек, у вас 20 микросервисов и обстоятельства непреодолимой силы не вынуждают вас создавать распределенную систему, то где-то вы просчитались. Вместо 5 человек на 1 микросервис, как у больших компаний, у вас получается 0,25 человека.
Разве Kubernetes вообще не полезен?
Kubernetes мог бы вам пригодиться, если вам требуется серьезное масштабирование. Тем не менее, давайте посмотрим, какие у вас есть альтернативы:
Предполагается, конечно же, что увеличение количества рабочих ВМ также сыграет вам на руку:
Чем больше движущихся частей, тем больше возможностей для возникновения ошибки.
Возможности Kubernetes, заточенные под увеличение надежности (health checks, rolling deploys), во многих случаях могут быть уже встроенными или реализованными гораздо проще. Например, nginx может делать health checks рабочих процессов, а еще можно использовать docker-autoheal или нечто подобное, чтобы автоматически перезапускать эти процессы.
Если же вас особенно волнует даунтайм, первой мыслью, которая вас посетит не должно быть «как мне сократить даунтайм при развертывании с 1 секунды до 1 миллисекунды), а должно быть «как мне убедиться, что изменения в схеме базы данных позволят откатиться, если я где-то накосячу?».
И если вам нужны надежные web worker'ы без единой машины в качестве точки отказа, есть много способов реализовать это и без Kubernetes.
На самом деле, никаких Самых Лучших Практик не существует в природе. Есть только лучшие практики для каждой конкретной ситуации. Поэтому если что-то находится в тренде и пользуется популярностью, это вовсе не значит, что конкретно для вас это правильный выбор.
В каких-то случаях Kubernetes — это самый лучший вариант. В остальных — напрасная трата времени.
Пока вы не испытываете острой необходимости во всех этих сложностях, перед вами широкий выбор инструментов, которые решат ваши задачи: Docker Compose для одной машины, Hashicorp’s Nomad для оркестрации, Heroku и похожие системы для масштабирования и что-то вроде Shakemake для вычислительных конвейеров.
Будучи облачным провайдером, мы регулярно сталкиваемся с самыми разными клиентами, от небольших стартапов до крупных организаций со сложными бизнес-процессами и соответствующими запросами к инфраструктуре. Вне зависимости от того, насколько хороша технология, всегда найдутся прецеденты, в которых её применение обернется лишними трудностями. Всегда следует исходить из ситуации и аккуратно взвешивать плюсы и минусы доступных вариантов. Автор статьи несколько сгустил краски, но его посыл вполне понятен: иногда, чтобы принять правильное решение, стоит отвернуться от трендов и непредвзято оценить свой проект. Это и разработчикам силы сэкономит, и расходование ресурсов компании сделает более целесообразным.
Если вы работаете в маленькой команде, Kubernetes, вероятнее всего, не для вас. Он принесет вам много боли в обмен на крайне скромные преимущества.
Давайте разберемся, почему это может произойти.
Всем нравятся «движущиеся части»
У Kubernetes двигается и меняется очень многое: концепции, подсистемы, процессы, машины, код… И все это означает массу сложностей.
Несколько машин
Kubernetes является распределенной системой: в нем присутствует главная машина, которая которая контролирует остальные, рабочие. Каждая машина производит работу в контейнерах.
Итак, мы уже говорим минимум о двух физических или виртуальных машинах, необходимых только для того, чтобы всё это заработало. Но по факту вы получаете… всего одну машину. Если вы собираетесь масштабироваться (вот, где собака зарыта!), вам понадобятся три, четыре, а может, целых семнадцать виртуальных машин.
Очень, очень много кода
Кодовая база Kubernetes на начало марта 2020 года включает в себя более 580 000 строк кода на Go. И это только чистый код, исключая комментарии, пустые строки, а также вендорские пакеты. Security review 2019 года описывает кодовую базу следующим образом:
«Кодовая база Kubernetes имеет значительный простор для улучшения. Она велика и сложна, содержит крупные секции кода с минимальной документацией и огромное количество зависимостей, включая системы, не входящие в Kubernetes. Также в кодовой базе присутствует много случаев повторной реализации логики, которая могла бы быть централизована в поддерживающих библиотеках, что позволило бы сократить сложность, упростить внесение исправлений и снизить документальную нагрузку в различных областях кодовой базы».
Если честно, то же самое можно сказать и о многих других крупных проектах, но весь этот код должен корректно функционировать, если вы не хотите, чтобы ваше приложение отказало.
Архитектурная, операционная, конфигурационная и концептуальная сложность
Kubernetes — это комплексная система со множеством различных сервисов, систем и прочего.
Прежде чем вы сможете запустить свое единственное приложение, вам придется обеспечить следующую, сильно упрощенную архитектуру (оригинальное изображение взято из документации по Kubernetes):
Документация по концепциям K8s включает множество сугубо «образовательных» вещей, таких как приведенный ниже фрагмент:
In Kubernetes, an EndpointSlice contains references to a set of network endpoints. The EndpointSlice controller automatically creates EndpointSlices for a Kubernetes Service when a selector is specified. These EndpointSlices will include references to any Pods that match the Service selector. EndpointSlices group network endpoints together by unique Service and Port combinations.
By default, EndpointSlices managed by the EndpointSlice controller will have no more than 100 endpoints each. Below this scale, EndpointSlices should map 1:1 with Endpoints and Services and have similar performance.
На самом деле, мне понятно, о чем здесь речь, но обратите внимание, как много понятий требуется изучить: EndpointSlice, Service, selector, Pod, Endpoint.
И — да, большую часть времени вы не будете использовать все эти возможности. Следовательно, большую часть времени вам вообще не будет нужен Kubernetes.
Вот еще один случайный фрагмент:
By default, traffic sent to a ClusterIP or NodePort Service may be routed to any backend address for the Service. Since Kubernetes 1.7 it has been possible to route “external” traffic to the Pods running on the Node that received the traffic, but this is not supported for ClusterIP Services, and more complex topologies — such as routing zonally — have not been possible. The Service Topology feature resolves this by allowing the Service creator to define a policy for routing traffic based upon the Node labels for the originating and destination Nodes.
Вот что по этому поводу говорится в Security review:
Kubernetes — это большая система, обладающая значительной операционной сложностью. Команда оценки сочла, что конфигурация и развертывание Kubernetes — нетривиальный процесс, определенные компоненты имеют спорные значения по умолчанию, не хватает оперативного контроля, а меры безопасности определены неявно.
Сложности при разработке
Чем больше вы приобретаете в Kubernetes, тем сложнее становится нормальный процесс разработки: вам нужны все эти концепции (Pod, Deployment, Service, и т.д.) просто чтобы ваш код заработал. Таким образом, вам нужно раскрутить полноценную K8s систему даже просто для тестирования через виртуальную машину или вложенные контейнеры Docker.
И, поскольку ваше приложение становится труднее запустить локально, разработка усложняется за счет множества вариантов решения этой задачи, от стендового окружения до проксирования локального процесса в кластер (специально для этого я пару лет назад написал этот инструмент) и проксирования удаленного процесса на локальную машину…
Можно выбрать любой вариант, но ни один из них не будет идеален. Проще всего вообще не использовать Kubernetes.
Микросервисы (это плохая идея)
Второстепенная проблема состоит в том, что, поскольку ваша система позволяет вам запускать множество сервисов, вам приходится писать это множество сервисов. Плохая идея.
Распределенное приложение тяжело написать качественно. На самом деле, чем больше движущихся частей, тем больше эти проблемы мешают работе.
Распределенные приложения тяжело отлаживать. Вам понадобится совершенно новый тип инструментов отладки и логирования, которые все равно дадут вам меньше, чем логи монолитного приложения.
Микросервисы — это одна из техник масштабирования в организациях: когда у вас в штате 500 разработчиков, которые обслуживают один продуктивный веб-сайт, имеет смысл смириться со стоимостью крупномасштабной распределенной системы, если это позволит командам разработчиков работать независимо друг от друга. Таким образом, каждая команда из 5 человек получает единственный микросервис, и делает вид, что все остальные микросервисы являются внешними службами, которым не стоит доверять.
Если же вся ваша команда состоит из 5 человек, у вас 20 микросервисов и обстоятельства непреодолимой силы не вынуждают вас создавать распределенную систему, то где-то вы просчитались. Вместо 5 человек на 1 микросервис, как у больших компаний, у вас получается 0,25 человека.
Разве Kubernetes вообще не полезен?
Масштабирование
Kubernetes мог бы вам пригодиться, если вам требуется серьезное масштабирование. Тем не менее, давайте посмотрим, какие у вас есть альтернативы:
- Вы можете приобрести ВМ в облаке, и у них будет до 416 виртуальных CPU и 8 ТБ RAM, то есть совершенно невдолбительные мощности. Это влетит вам в копеечку, но будет крайне просто сделать.
- Многие простые веб-приложения можно масштабировать достаточно легким путем с помощью таких сервисов как Heroku.
Предполагается, конечно же, что увеличение количества рабочих ВМ также сыграет вам на руку:
- Большинству приложений не требуется существенное масштабирование, им будет достаточно качественной оптимизации.
- Узким местом масштабирования большинства веб-приложений являются базы данных, а не web worker'ы
Надежность
Чем больше движущихся частей, тем больше возможностей для возникновения ошибки.
Возможности Kubernetes, заточенные под увеличение надежности (health checks, rolling deploys), во многих случаях могут быть уже встроенными или реализованными гораздо проще. Например, nginx может делать health checks рабочих процессов, а еще можно использовать docker-autoheal или нечто подобное, чтобы автоматически перезапускать эти процессы.
Если же вас особенно волнует даунтайм, первой мыслью, которая вас посетит не должно быть «как мне сократить даунтайм при развертывании с 1 секунды до 1 миллисекунды), а должно быть «как мне убедиться, что изменения в схеме базы данных позволят откатиться, если я где-то накосячу?».
И если вам нужны надежные web worker'ы без единой машины в качестве точки отказа, есть много способов реализовать это и без Kubernetes.
Лучшие практики?
На самом деле, никаких Самых Лучших Практик не существует в природе. Есть только лучшие практики для каждой конкретной ситуации. Поэтому если что-то находится в тренде и пользуется популярностью, это вовсе не значит, что конкретно для вас это правильный выбор.
В каких-то случаях Kubernetes — это самый лучший вариант. В остальных — напрасная трата времени.
Пока вы не испытываете острой необходимости во всех этих сложностях, перед вами широкий выбор инструментов, которые решат ваши задачи: Docker Compose для одной машины, Hashicorp’s Nomad для оркестрации, Heroku и похожие системы для масштабирования и что-то вроде Shakemake для вычислительных конвейеров.
Послесловие от редактора
Будучи облачным провайдером, мы регулярно сталкиваемся с самыми разными клиентами, от небольших стартапов до крупных организаций со сложными бизнес-процессами и соответствующими запросами к инфраструктуре. Вне зависимости от того, насколько хороша технология, всегда найдутся прецеденты, в которых её применение обернется лишними трудностями. Всегда следует исходить из ситуации и аккуратно взвешивать плюсы и минусы доступных вариантов. Автор статьи несколько сгустил краски, но его посыл вполне понятен: иногда, чтобы принять правильное решение, стоит отвернуться от трендов и непредвзято оценить свой проект. Это и разработчикам силы сэкономит, и расходование ресурсов компании сделает более целесообразным.



VolCh
Да не сказал бы, что он сгустил краски. Как по мне, то если вы не можете постоянно выделять 40 человеко-часов в неделю на k8s, то результаты перехода на него вас могут не обрадовать — проблем может оказаться больше чем пользы, по крайней мере пока инфраструктура не устаканетится.
Sm1le291
А как же требование почти во всех вакансиях для бэкэндеров, это работа с микросервисами и докером? Вот и суют люди это там где надо и там где не надо, чтобы в тренде быть.
VolCh
У нас такое "будет плюсом" есть. Микросервисы и докеры — нормально. docker-compose очень многое закроет. Может даже docker swarm в кластере из нескольких нод, если реально нужна отказоустойчивость и/или распределение нагрузки по нодам. У нас даже k8s есть в "будет плюсом" вроде бы. Но это уже чтобы с девопсом нормально взаимодейстовать.
В общем, если решили перейти на докер, то начать с docker-compose, потом docker swarm, только потом k8s, может посмотрев сначала на настройки над ним, прячущие большую часть его сложности. Поработав с полгода с кубером, убедился в высказывании (недословно) "k8s — это не оркестратор, это фреймворк для сборки оркестраторов"
apapacy
Docker-compose на проде это приключение не для слабонервных. Docker тянет за собой необходимость оркестрации на проде. Не обязательно кубер. Если не покупать кубер у облачных провайдеров я за nomad. Так как поддерживать кубер самостоятельно для небольшой организации просто нереально. Поэтому сейчас и ездят по миру прославленные спикеры которые трпят за докер и микросервисы. А на деле за aws, google или digitalocen, к услугам которых придется прибегнуть после неудачных попыток реализовать микросервисы на докере своими силами. Но микросервисы архитектура может быть даже круче и удобнее без всего этого. Например есть стандарт wamp не путать с аналогом денвера. Я думаю этот стандарт незаслуженно почти забыт и у него будет еще свое место в истории
VolCh
Да нормально композ работает на проде, пока сервисов с пяток, пскай с десяток, динамические домены не нужны, балансировка не нужна, и нормально на одном хосте помещаются, ну и далее по списку. В общем пока то, что можно и просто руками поднять/обновить на одном хосте.
Наверное очень забытый, раз даже вики о нём не знает, можно ссылочку какую-нить? А то только с денвером и вебсокетами ассоциации.
apapacy
Проблемы начинаются при обновлении. Без даунтайма сложно компоузом делать замену контейнера. А если еще к тому же что-то пойдет не так. Я для себя сделал вывод примерно такой. На проде или докер+оркестратор или без докера.
По базам данных — после того как у меня при рестарте контейнеров начал рушиться постгрес — никогда на докере. Я так понимаю что кроме каталога data который можно вынести на том, базы данных могут писать еще временные файлы в другие каталоги. И если повезет можно попасть на краш. Аналогичную историю мне рассказал один опытнейший DevOps только по MySQL серверу.
VolCh
Забыл упомянуть про zero downtime и прочие rolling updates отдельно — это тоже не к docker-compose. Ну и продакшен баз данных никогда под докером не держал, и даже на том же хосте не доводилось как-то.
SirEdvin
У вас есть на выбор blue-green или же просто завести две ноды. И то и другое спокойно решается при помощи условного docker-compose + nginx/traefik.
Уже больше 3 лет всегда держу базы в докере, перед этим все файлы прокидывая через mount на хостовую систему, никогда ничего не разлеталось. Я вот никогда не понимал, мне везло или просто я аккуратно пользуюсь докером.
apapacy
Мне хватило одного раза чтобы отказаться. Хотя два проекта под mysql у меня уже не один год под докером. Думаю дело во временных файлах которые могут быть в директории /tmp или еще где то. Возможно я попал на очень редкое стечение обстоятельств. Но зачем рисковать после этого?
См. Например https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
gecube
везло, 100%.
ansible? в топку компоуз
SirEdvin
И чувакам из Zalando тоже везло. И еще куче людей. Как в мире много везения, не находите?)
Тут есть два нюанса:
gecube
я saltstack юзаю с докерами — проблем нет. Касательно ансибла решение же простое — запинить версию, как и любого инфраструктурного решения. Те же docker-compose с докером от версии к версии подкидывают сюрпризы. И не надо мне говорить, что их никогда не бывает — начиная от того, что sysctl надо на хосте выставлять для какого-нибудь эластика и кончая странными эффектами при работе с nvidia-runtime. Я даже видел пацанов на центоси с докер 1.13 :-(
С компоузом прекрасный баг — https://bugs.launchpad.net/ubuntu/+source/docker-compose/+bug/1792824 и это не первая и не последняя история, чтоб их, чертовых смузихлебов
там дьявол в деталях. Пытались ли они ту же сциллу в кубернетес на шаред хосты затащить? И с постгресом они сами говорят, что есть нюансы. Т.е. тестовые стенды в кубере с постгрес-оператором — ваще не вопрос, давайте — быстро, сердито, можно тиражировать пачками. Прод — стоит подумать десять раз
SirEdvin
У saltstack, если я правильно помню, файл с тасками тоже по факту шаблон, это убирает проблематику первого пункта, например :)
Это, кстати, вообще не проблема докера :) Это эластик сам развлекается и если запустить его вне контейнера такая же фигня будет.
Ну, мне как-то везло и мне docker-compose не подкидывал сюрпризов.
К сожалению, с ним нюансов полно и докер не самый первый в очереди :(
gecube
ну, это скорее к вопросу того, что докер — это, по мнению разрабов, изоляция уровня Бог, что в корне не так )
SirEdvin
Ну, если они не читают документацию, кто им доктор :(
ckpunT
Из своего опыта могу сказать, что один человек может поддерживать несколько кластеров кубера, при этом тратя на это минимальное количество времени по сравнению с другими оркестраторами.
apapacy
Вес вопрос в том где этот кубер. Если он купен в облаке — то да согласен. Если свой домашний кубер — все интересное начнется не когда кубер идеально работает а когда что-то пойдет не так. Не уверен что если обеспечением кубра занимается меньше десятка специалистов разного профиля они в состоянии будут справиться с неожиданно возникшими проблемами неизвестного происхождения. Да еще без даунтайма.
ckpunT
В облаках «свой» кубер на виртуалках. За 2,5 года работы с кубером уже с многими проблемами столкнулся и набил кучу шишок. За последние 8 месяцев 2 или 3 раза проблемы были и решались в пределах 15 минут. На самом деле кубер изначально кажется сложным. После нескольких развертываний кубера руками начинаешь понимать его внутреннее устройство и оно достаточно простое для понимания одним человеком. Последний мой косяк был, решил не заставлять ждать разработчиков, пока доеду до работы, а через web-консоль запустить остановленные ноды дев-стендов и случайно их удалил. Кнопки «Start» и «Delete» находятся рядом. Через 3 минуты понял это и через 5 минут вернул их обратно по средствам terraform.
gecube
Это очень обманчивое ощущение. Да, кубер простой. Но он при этом и сложный. Из кубера можно сварить бесконечное количество разных конфигураций с разной степенью проблемности. И скорее всего вы даже и не охватите за всю свою жизнь их всех. Короче — если пользоваться только подмножеством возможностей кубера и "безопасным" подмножеством конфигураций — возможно, что все и будет ок. Но шаг влево или вправо — начинаются приключения. Ну, например — базы данных в кубере, стейтфул в целом, SIP — все решаемо, но это пот и кровь. И еще при обновлении кубера что-то может пойти не так.
VolCh
А в "поддерживать" что входит?
ckpunT
Развертывание/обновление кластеров.
Решение проблем на дев-стендах разработчиков, тоже в кубере. Написание разных тулз(admission controllers/crd), позволяющих автоматизировать некоторые операции по работе с кубером.
Так как у нас есть on-premise поставка нашего продукта, то приходится заранее окружение заказчика воспроизводить и пробовать деплоить/править наши чарты.
Прод и инфраструктурный кубер… там особо нечего делать, они просто работают. Недавно «отвалилась» одна нода, так клиенты даже не заметили.
VolCh
А создание и поддержание дев, тест-стендов, да и продакшена? Все эти сотни и тысячи, где-то, манифесты, чарты для целевой системы он же пишет, подерживает и развивает? Меня, одного разработчика, на это хватает только если на фуллтайме "обслуживать" десяток других разработчиков.
gecube
Только не на bare metal. Для поддержки куба на баре метал нужна целая команда инфраструктурщиков