
Добавить разметку в текст руками легко. Можно разметить текст прямо здесь, на Хабре, а потом скопировать на сайт. Можно сделать поиск с заменой в Notepad++ или в Atom.
Если это 1 текст. Если текстов много, хочется иметь инструмент для выделения фрагментов текста html-тегами или формирование исходного кода для React. На Питоне это не сложно (несколько строк кода на цвет).
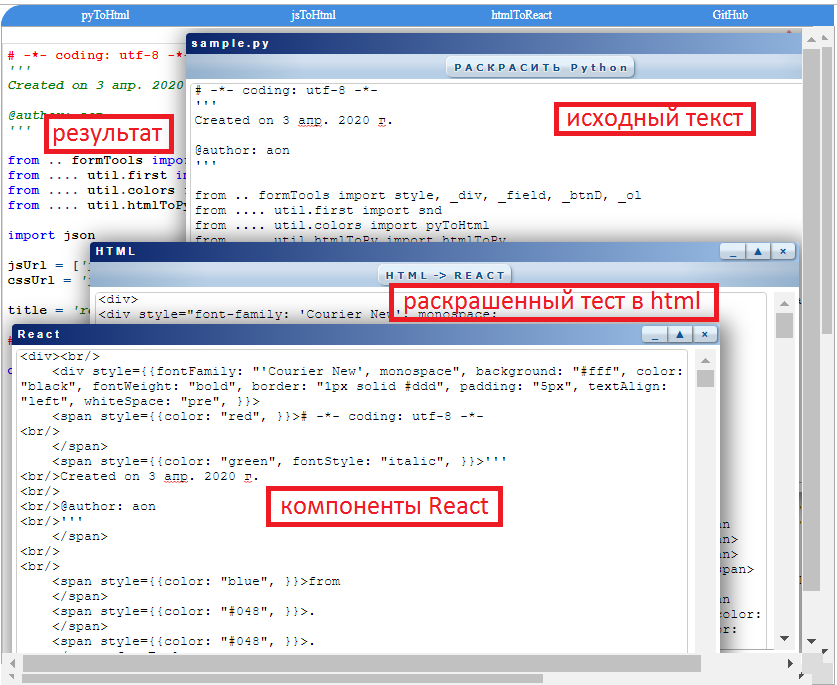
Если вы знаете Питон и регулярные выражения, переходите по ссылке.
Там и примеры, и исходные коды. Под катом подробное описание.
Рассмотрим функцию:
На входе исходный текст, возвращает html.
Задаем переменные, определяющие атрибуты блоков. В примере для наглядности используются стили, в дальнейшем логичней заменить их на классы.
Разметка.
Первое, что нужно сделать — это заэкранировать символы '&', '<', '>'
'&' экранируется, чтобы правильно отображать буквосочетания '<', '>' и прочие '&...;',
Символы '<' и '>' экранируются, чтобы не конфликтовать с тэгами.
Можно много чего заэкранировать, но, на мой взгляд, в utf-8 этого достаточно.
Алгоритм разметки:
Заглушка должна быть уникальной, но у нас же в тексте нет ни одного символа '<' и ни одного '>'.
Делаем заглушку:
где i – номер заглушки. Такого в тексте точно нет.
Что делать, если внутри фрагмента уже есть заглушка.
Например, в исходном тексте были строки:
Вариантов 2:
Делаем функцию, которая все это реализует (10 строк кода, 10 строк комментария):
Это демонстрационный пример: разметка регулярных выражений может быть некорректной, экранированные символы (\', \") не обрабатываются.
Для справки: выражение:
в редакторах Notepad++ и в Atom раскрашено по разному.
Теперь, когда есть oneRe, раскраска фрагментов делается просто. Пример, раскрашивающий строки в апострофах и кавычках:
Пример боле сложной раскраски. Нужно в js раскрасить выражения в многостроках
сначала находим многосторки:
re.findall(r'`[\s\S]+?`', s) возвращает список блоков текста между символами обратных кавычек.
Каждый блок содержит либо пробелы, либо не пробелы ([\s\S] т.е. что угодно).
Длина блока 1 или более (+).
Без жадности ("?" означает, что символа "`" внутри блока нет).
Копируем найденный блок(переменная mStr) в переменную newFstr.
Находим в блоке подблоки с выражениями ${...}.
re.findall(r"\$\{[\s\S]*?\}", mStr) возвращает список таких подблоков. Сохраняем разметку в массиве ls и заменяем подблок на заглушку в переменной newFstr.
Когда подблоки кончатся, заменяем в исходной строке s первоначальное значение блока на новое.
Set не лишний. Если findall вернет несколько одинаковых блоков, при обработке первого блока в исходном тексте заменятся на заглушки сразу все одинаковые. При обработке второго такого же блока его уже не будет в исходном тексте. Set убирает дублирование.
Преобразовать html в исходный код React можно на сайте htmltoreact.com. Там же есть ссылка на GitHub.
Меня это не устроило: во первых он формирует не совсем то, что мне надо, во вторых – как я это чудо затащу к себе на сервер.
Написал свой.
Устанавливаем библиотеку lxml (pip install lxml или pip3 install lxml).
Импортируем:
Преобразуем html-текст в xhtml-текст. Это почти одно и то же, но все теги закрыты.
Полученный xhtml парсим в дом-дерево с помощью минидома.
Делаем функцию, которая рекурсивно скачет по нодам и формирует результат в виде исходного кода React.
Dom-дерево после вызова parseString – это нода-папа, у которай есть ноды-дети, у которых есть еще дети и т.д.
Каждая нода – это словарь, содержащий ее описание:
Пример:
После преобразований получим:
Преобразовать dom в строку несложно (есть pprint), при формировании React-кода, я заменил class на className и переделал атрибут style.
В текстовых нодах заэкранированы '{', '}', '<', '>'.
Примеры и исходные тексты здесь.
P.S. На Хабре раскраска питоновского кода (а может и других) не идеальна. Если в питоновской строке есть буквосочетание &, оно отображается как &. В своих кодах я подправил, чтобы выглядело правильно. Если хабр ошибку исправит, мои тексты перекривятся.
Если это 1 текст. Если текстов много, хочется иметь инструмент для выделения фрагментов текста html-тегами или формирование исходного кода для React. На Питоне это не сложно (несколько строк кода на цвет).
Если вы знаете Питон и регулярные выражения, переходите по ссылке.
Там и примеры, и исходные коды. Под катом подробное описание.
Разметка текста на примере раскраски исходного кода на Javascript
Рассмотрим функцию:
def jsToHtml(s):На входе исходный текст, возвращает html.
Задаем переменные, определяющие атрибуты блоков. В примере для наглядности используются стили, в дальнейшем логичней заменить их на классы.
comm = 'style="color: red;"' # цвет для комментариев
blue = 'style="color: blue;"' # синий
...Разметка.
Первое, что нужно сделать — это заэкранировать символы '&', '<', '>'
s = s.replace('&', '&').replace('<', '<').replace('>', '>')'&' экранируется, чтобы правильно отображать буквосочетания '<', '>' и прочие '&...;',
Символы '<' и '>' экранируются, чтобы не конфликтовать с тэгами.
Можно много чего заэкранировать, но, на мой взгляд, в utf-8 этого достаточно.
Алгоритм разметки:
- Берем re-шаблон и ищем все фрагменты текста, которые ему удовлетворяют.
- Вырезаем каждый фрагмент, добавляем к нему разметку и сохраняем размеченный фрагмент в массиве (заодно сохраняем оригинальный текст: пригодится).
- На его место вставляем заглушку с номером.
- И так для каждого цвета.
- Когда все раскрашено, заменяем заглушки на раскрашенные фрагменты из массива.
Заглушка должна быть уникальной, но у нас же в тексте нет ни одного символа '<' и ни одного '>'.
Делаем заглушку:
f'<{i}>'где i – номер заглушки. Такого в тексте точно нет.
Что делать, если внутри фрагмента уже есть заглушка.
Например, в исходном тексте были строки:
` пример вложенности: строка /* а в ней комментарий */ `
/* комментарий, ` а в нем строка ` */Вариантов 2:
- Проигнорировать. В этом случае строка будет иметь двойной окрас.
- Найти вложенные заглушки и заменить их на исходный (неразмеченный) текст.
Делаем функцию, которая все это реализует (10 строк кода, 10 строк комментария):
def oneRe(reStr, s, attr, ls, multiColor=False):
'''
Ищет в исходной строке s нужные блоки, добавляет в них разметку и сохраняет результат в массиве ls,
на их место вставляет заглушки с номерами (<0>, <1> ...<1528>...).
Возвращает результат в виде строки с заглушками.
reStr - re
s - строка
attr - атрибуты style/class/etc
ls - массив с разметкой
multiColor=False, если надо убрать вложенную разметку
'''
for block in set(re.findall(reStr, s)):
toArr = block
if not multiColor: # если multiColor==False, убрать вложенную разметку
for prev in set(re.findall(r'<[\d]+>', block)): # ищем вложенность: <0> ... <21>
iPrev = int(prev[1:-1], 10) # выделяем номер строки в массиве
toArr = toArr.replace(prev, ls[iPrev][1]) # в строке '<0> qwe <21>' заменяем ссылки(<0>,<21>) на первонач. значения
ls.append([f'<span {attr}>{toArr}</span>', toArr]) # в каждом элеменете массива ls 2 элемента: размеченный текст и оригинал
s = s.replace(block, f'<{len(ls)-1}>')
return sЭто демонстрационный пример: разметка регулярных выражений может быть некорректной, экранированные символы (\', \") не обрабатываются.
Для справки: выражение:
s = s.replace(/A + B/g, 'A - B');в редакторах Notepad++ и в Atom раскрашено по разному.
Теперь, когда есть oneRe, раскраска фрагментов делается просто. Пример, раскрашивающий строки в апострофах и кавычках:
s = oneRe(r"'[\s\S]*?'", s, green, ls, multiColor=False) # убираем из кода 'строки' в массив ls
s = oneRe(r'"[\s\S]*?"', s, green, ls, multiColor=False) # убираем из кода "строки" в массив ls
Пример боле сложной раскраски. Нужно в js раскрасить выражения в многостроках
`многострочная строка с выражениями ${A + B} и ${A - B}`for mStr in set(re.findall(r'`[\s\S]+?`', s)): # раскраска переменных внутри многострок
newFstr = mStr
for val in set(re.findall(r"\$\{[\s\S]+?\}", mStr)):
ls.append([f'<span {darkRed}>{val}</span>', val])
newFstr = newFstr.replace(val, f'<{i}>')
i += 1
s = s.replace(mStr, newFstr)
s = oneRe(r'`[\s\S]+?`', s, green, ls, multiColor=True) # убираем из кода `многостроки` в массив ls
сначала находим многосторки:
re.findall(r'`[\s\S]+?`', s) возвращает список блоков текста между символами обратных кавычек.
Каждый блок содержит либо пробелы, либо не пробелы ([\s\S] т.е. что угодно).
Длина блока 1 или более (+).
Без жадности ("?" означает, что символа "`" внутри блока нет).
Копируем найденный блок(переменная mStr) в переменную newFstr.
Находим в блоке подблоки с выражениями ${...}.
re.findall(r"\$\{[\s\S]*?\}", mStr) возвращает список таких подблоков. Сохраняем разметку в массиве ls и заменяем подблок на заглушку в переменной newFstr.
Когда подблоки кончатся, заменяем в исходной строке s первоначальное значение блока на новое.
Set не лишний. Если findall вернет несколько одинаковых блоков, при обработке первого блока в исходном тексте заменятся на заглушки сразу все одинаковые. При обработке второго такого же блока его уже не будет в исходном тексте. Set убирает дублирование.
Файл jsToHtml.py
# -*- coding: utf-8 -*-
'''
AON 2020
'''
import re
# *** *** ***
def oneRe(reStr, s, attr, ls, multiColor=False):
'''
Ищет в исходной строке s нужные блоки, добавляет в них разметку и сохраняет результат в массиве ls,
на их место вставляет заглушки с номерами (<0>, <1> ...<1528>...).
Возвращает результат в виде строки с заглушками.
reStr - re
s - строка
attr - атрибуты style/class/etc
ls - массив с разметкой
multiColor=False, если надо убрать вложенную разметку
'''
i = len(ls) # номер очередной заглушки
for block in set(re.findall(reStr, s)):
toArr = block
if not multiColor: # если multiColor==False, убрать вложенную разметку
for prev in set(re.findall(r'<[\d]+>', block)): # ищем вложенность: <0> ... <21>
iPrev = int(prev[1:-1], 10) # выделяем номер строки в массиве
toArr = toArr.replace(prev, ls[iPrev][1]) # в строке '<0> qwe <21>' заменяем ссылки(<0>,<21>) на первонач. значения
ls.append([f'<span {attr}>{toArr}</span>', toArr]) # в каждом элеменете массива ls 2 элемента: размеченный текст и оригинал
s = s.replace(block, f'<{i}>') # заменяем блок текста на зауглушку с номером
i += 1
return s
# *** *** ***
def operColor(s, ls, color):
'''
раскрашивает операторы.
Должна вызываться последней, когда в тексте не осталось ни строк, ни комментариев
'''
i = len(ls)
for c in ['<=', '>=', '=<', '=>', '<', '>', '&&', '&',
'===', '!==', '==', '!=', '+=', '-=', '++', '--', '||']:
ls.append([f'<span {color}>{c}</span>',0])
s = s.replace(c, f'<{i}>')
i += 1
for c in '!|=+-?:,.[](){}%*/':
ls.append([f'<span {color}>{c}</span>',0])
s = s.replace(c, f'<{i}>')
i += 1
return s
# *** *** ***
def jsToHtml(s):
'''
Демонстрационный раскрасчик кода.
Заменяет строки, комментарии и ключевые слова на элементы разметки <span>.
'''
black = '''style="font-family: 'Courier New', monospace;
background: #fff;
color: black;
font-weight: bold;
border: 1px solid #ddd;
padding: 5px;
text-align: left;
white-space: pre;"'''
comm = 'style="color: red;"'
green = 'style="color: green; font-style: italic;"'
blue = 'style="color: blue;"'
red2 = 'style="color: #840;"'
s = s.replace('&', '&').replace('<', &'<').replace('>', '>') # экранируем символы '&', '<', '>'
ls = []
i = 0
for mStr in set(re.findall(r'`[\s\S]+?`', s)): # раскраска переменных внутри многострок
newFstr = mStr
for val in set(re.findall(r"\$\{[\s\S]+?\}", mStr)):
ls.append([f'<span {darkRed}>{val}</span>', val])
newFstr =newFstr.replace(val, f'<{i}>')
i += 1
s = s.replace(mStr, newFstr)
s = oneRe(r'`[\s\S]+?`', s, green, ls, multiColor=True) # убираем из кода `многостроки` в массив ls
s = oneRe(r"'[\s\S]*?'", s, green, ls, multiColor=False) # убираем из кода 'строки' в массив ls
s = oneRe(r'"[\s\S]*?"', s, green, ls, multiColor=False) # убираем из кода "строки" в массив ls
s = oneRe(r'/[\s\S].*?/g\b', s, green, ls, multiColor=False) # убираем из кода re-строки в массив ls
s = oneRe(r'/[\s\S].*?/\.', s, green, ls, multiColor=False) # убираем из кода re-строки в массив ls
s = oneRe(r'/\*[\s\S]+?\*/', s, comm, ls, multiColor=False) # убираем из кода /* комментарии */ в массив ls (лучший цвет - красный)
s = oneRe(r'//[\s\S]*?\n', s, comm, ls, multiColor=False) # убираем из кода // комментарии в массив ls (лучший цвет - красный)
i = len(ls)
# теперь можно раскрасить синтаксис
for c in ['new', 'JSON', 'Promise', 'then', 'catch', 'let', 'const', 'var', 'true', 'false', 'class', 'from', 'import', 'set', 'list', 'for', 'in', 'if', 'else', 'return', 'null']:
ls.append([f'<span {blue}>{c}</span>',0])
s = re.sub (r'\b%s\b' % c, f'<{i}>', s)
i += 1
# теперь можно раскрасить мои переменные
for c in ['window', 'doc', 'cmd', 'init','init2', 'recalc', 'hide', 'readOnly', 'validate']:
ls.append([f'<span {darkRed}>{c}</span>',0])
s = re.sub (r'\b%s\b' % c, f'<{i}>', s)
i += 1
s = operColor(s, ls, darkBlue) # теперь можно раскрасить операторы
for j in range(len(ls), 0, -1): # восстанавливаем операторы, переменные, комментарии, строки с новым окрасом
s = s.replace(f'<{j-1}>', ls[j-1][0])
return f'<div {black}>{s}</div>'
# *** *** ***
Html в React
Преобразовать html в исходный код React можно на сайте htmltoreact.com. Там же есть ссылка на GitHub.
Меня это не устроило: во первых он формирует не совсем то, что мне надо, во вторых – как я это чудо затащу к себе на сервер.
Написал свой.
Устанавливаем библиотеку lxml (pip install lxml или pip3 install lxml).
Импортируем:
from xml.dom.minidom import parseString
from lxml import html, etreeПреобразуем html-текст в xhtml-текст. Это почти одно и то же, но все теги закрыты.
doc = html.fromstring(htmlText)
ht = etree.tostring(doc, encoding='utf-8').decode()Полученный xhtml парсим в дом-дерево с помощью минидома.
dom = parseString(ht)Делаем функцию, которая рекурсивно скачет по нодам и формирует результат в виде исходного кода React.
Dom-дерево после вызова parseString – это нода-папа, у которай есть ноды-дети, у которых есть еще дети и т.д.
Каждая нода – это словарь, содержащий ее описание:
- nodeName — имя ноды, строка
- childNodes — ноды-дети, список
- attributes- атрибуты, словарь
- У ноды с названием #text есть nodeValue(строка)
Пример:
<div class="A" style="color: red;">Red of course,<br> Сэр</div>После преобразований получим:
{ 'nodeName':'div',
'attributes': {'style': 'color: red;', 'class': 'A'},
'childNodes': [
{'nodeName':'#text', 'nodeValue': 'Red of course,'},
{'nodeName':'br'},
{'nodeName':'#text', 'nodeValue': 'Сэр'},
],
}
Преобразовать dom в строку несложно (есть pprint), при формировании React-кода, я заменил class на className и переделал атрибут style.
В текстовых нодах заэкранированы '{', '}', '<', '>'.
Файл htmlToReact.py
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
from xml.dom.minidom import parseString
from lxml import html, etree
# *** *** ***
_react = ''
def htmlToReact(buf):
'''
buf - html-строка
возвращает ReactJS-строку
'''
global _react
_react = ''
try:
r = re.search('<[\\s\\S]+>', buf)
if r:
doc = html.fromstring(r.group(0))
ht = etree.tostring(doc, encoding='utf-8').decode()
xHtmlToReact(parseString(ht).childNodes[0], '')
return _react
else:
return '<empty/>'
except Exception as ex:
s = f'htmlToReact: \n{ex}'
print(s)
return s
# *** *** ***
def sU(a, c):
'''
xlink:show -> xlinkShow
font-weight -> fontWeight
'''
l, _, r = a.partition(c)
return ( (l + r[0].upper() + r[1:]) if r else a).strip()
# *** *** ***
def xHtmlToReact(n, shift='\n '):
'''
Нужен для показа реакт-кода
на входе нода, рекурсия по нодам с заменой минусов на upperCase
результат формирует в global переменной _react
'''
global _react
if n.nodeName.lower() in ['head', 'script']:
return
_react += shift + '<' + n.nodeName.lower()
if n.attributes:
for k, v in n.attributes.items():
if k == 'style':
style = ''
for s in v.split(';'):
if s.strip():
l, _, r = s.partition(':')
style += f'''{sU(l, '-')}: "{r.strip()}", '''
if style:
_react += ' style={{' + style + '}}'
elif k == 'class':
_react += f' className="{v}"'
else:
kk = k.replace('xlink:href', 'href') # deprcated
_react += f''' {sU( sU(kk, ':'), '-' )}="{v}"'''
_react += '>'
if n.childNodes:
for child in n.childNodes:
if child.nodeName == '#text':
tx = child.nodeValue
for x in ['{', '}', '<', '>']:
tx = tx.replace(x, '{"' + x + '"_{_')
tx = tx.replace('_{_', '}')
if tx[-1] == ' ':
tx = tx[:-1] + '\xa0'
_react += tx.replace('\n', '<br/>')
else:
xHtmlToReact(child)
_react += f'{shift}</{n.nodeName.lower()}>'
# *** *** ***
Примеры и исходные тексты здесь.
P.S. На Хабре раскраска питоновского кода (а может и других) не идеальна. Если в питоновской строке есть буквосочетание &, оно отображается как &. В своих кодах я подправил, чтобы выглядело правильно. Если хабр ошибку исправит, мои тексты перекривятся.