
В течение некоторого времени я тестировал Microsoft Azure DataFactory, чтобы сравнить его функциональность (пока не производительность) с существующим у моего клиента решением ETL — IBM Infosphere DataStage 11 (под YARN, но это не принципиально в данном случае). Это сравнение было призвано помочь клиенту сделать выбор, что использовать в среднесрочной перспективе для процессов ETL: ADF или DataStage. Мне были непонятны мотивы клиента мигрировать все ETL процессы на движок ADF, поэтому я попытался найти аргументы для того, чтобы предотвратить этот процесс.
Результаты моего небольшого сравнения под катом. Возможно вам оно пригодится тоже при составлении предложения клиентам.
Это сравнение не является исчерпывающим, в нем перечислены лишь аспекты, которые показались лично мне важными для разработки ETL процессов.
Azure DataFactory позиционируется как инструмент ETL, не требующий написания кода (code-free), с этой точки зрения я и пытался его рассматривать. Тем не менее, мы все знаем, что рано или поздно возникает необходимость усилить функциональность любой платформы обработки данных своимикостылями расширениями — внешними модулями, функциями трансформации и т.д. Поэтому я попытался прикинуть уровень, на котором возникает необходимость внедрения самописных модулей. Чем выше этот уровень — тем ниже порог входа для специалистов (не нужно требовать привлечения сеньоров), тем более гибкая платформа и тем дешевле будет разработка простых и средних по сложности процедур переливки данных.
Также, моей целью не было сравнение всех продуктов, входящих в сюиту IBM Information Server и всех приложений Azure (Профилирование данных, управление качеством данных, Data Gouvernance и т.д.), я постарался сконцентрироваться лишь на функциональности средств ETL.
Также я не скрываю своей предвзятости: я имею больше опыта работы с DataStage, чем с Azure DataFactory, поэтому, возможно я что-то упустил в своих выводах. Предлагаю тогда обсудить спорные моменты в комментариях.
Кроме того, Azure DataFactory — продукт довольно молодой и продолжает развиваться. Возможно, часть возможностей из предложенного списка будет добавлена позднее. Возможно, но крайне маловероятно, этому поспособствует данная статья. Но я бы хотел иметь в своем арсенале больше могущественных ETL средств.
Для каждого пункта я попытался подобрать несколько возможных сценариев применения, а также — некоторые способы обхода выявленных ограничений, если они имели место.
Грубя говоря — все метаданные потока должны быть заданы во время разработки. Мы не сможем во время выполнения динамически выбирать над какими полями какие действия совершать.
Отсутствие такой возможности сильно ограничивает разработчика при создании общих правил трансформации. Например, данные, загружаемые в Staging или в Landing Area не содержат сложных правил трансформации. Как правило, нужно добавить несколько технических полей, таких как дата загрузки, идентификатор источника, возможно — номер текущей версии строки при историзации данных. Все остальные поля, содержащие данные, нужно протолкнуть без изменений, вне зависимости от их имен и количества.
В DataStage это решается за счет Runtime Column Propagation (RCP), схем данных OSH и этапами (стейджами) импорта/экспорта колонок.
Пример: Для всех входящих таблиц создать две колонки KEY_HASH и DATA_HASH, содержащие хеш MD5 ключеых полей и полей данных соответственно. Разумеется, количество ключевых полей может варьироваться от таблицы к таблице. Их имена также не детерминированы.
Решение на DS:
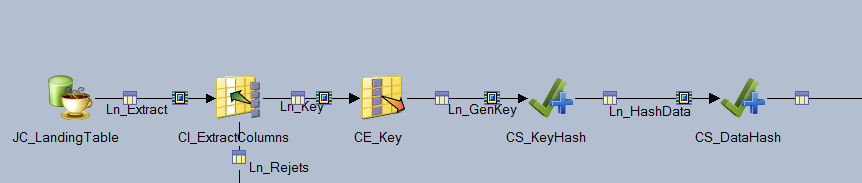
Мы просто извлекаем все колонки из исходной таблицы, на основе файла схемы данной таблицы (это такие файлы, которые содержат описание метаданных таблицы) генерируем на этапе CE_KeyHash техническое поле TECH_KEY, содержащее все ключевые поля таблицы, на этапе CS_KEY вычисляем хеш этого поля, а на этапе CS_DataHash вычисляем хеш всех полей, кроме технического.
Возможные решения на ADF: Использование Azure Functions. Да, это выход. Но мы еще вернемся к нему. Но это уже выход за пределы парадигмы code-free.
В некоторых случаях, возможно импортировать метаданные каждой таблицы при помощи этапа Lookup, на основе их сгенерировать запрос SQL, содержащий конкатенацию нужных колонок и вычисления хеша. Но это возможно только в случае, если источник данных поддерживает SQL, либо необходимо создавать в Polybase внешние таблицы над файлами (как в Hive — external tables). Ну, либо создавать на каждую таблицу отдельный DataFlow или Pipeline…
На самом деле, очень востребованная функциональность в ETL. Сильно ее не хватает в ADF. А без нее невозможно создать общие для нескольких источников процедуры переливки данных. Время на разработку увеличивается, ухудшается поддерживаемость решения. Использование Azure Functions тут же поднимает стоимость, усложняет процесс разработки. Так как теперь разработчику необходимо согласовать использование функции (которые оплачиваются за каждый вызов) с ответственным за бюджет проекта.
Это означает, что вы не можете создавать состояния, которые бы определяли способ обработки входящей строки от значения полей предыдущих (это, разумеется важно, когда данные отсортированы в каждой партиции). Кроме того, невозможно для одной входящей строки сгенерировать несколько исходящих.
Классический пример: WordCount — подсчет встречаемости каждого слова в документе. Одним из способов решить ее средствами ETL — превратить строчку из N слов в N строчек, содержащих эти слова и только эти слова. А дальше — агреггация и подсчет вхождений каждого слова.

Обратите внимание, что количество строк после трансформера T_ExtractWords больше, чем до него.
Как решить эту задачу стандартными средствами ADF я не смог придумать. Это не значит, что этого сделать нельзя — отнюдь. Но придется опять же дополнительно подготавливать данные до скармливания их этому ETL средству. Опять же, возникает необходимость привлекать внешние утилиты и языки программирования — Java, .Net, Spark…
Ну, тут все просто — нельзя читать и писать XML файлы стандартными средствами. Немножко был обескуражен, когда не смог найти способа этого сделать. Думал, наверное, сказывается моя неопытность обращения с ADF, попытался поискать по форумам и ресурсам Microsoft. Нашел вот этот вопрос и ответ. Т.е. предлагается использовать LogicApp чтобы конвертировать XML в какой-нибудь другой формат, подходящий для DataFactory, либо читать XML программно (что там про code-free?). LogicApp оплачивается, разумеется, отдельно. Ну, ребята, XXI век на дворе, все-таки.
Сравните с возможностями этапа Hierarchical File от DataStage. Он тоже не без греха, его нужно тюнить для больших XML, но это целый комбайн, который позволяет производить трансформации непосредственно со структурой XML файла: джойнить данные между тегами, трансформировать структуру без XSLT (но и с ним тоже возможно) и выполнять другие операции.
Сложно это было сформулировать, проясню: некоторые различные ETL процессы могут иметь общие участки трансформаций. Так вот нельзя этот участок вынести и сохранить отдельно, создав в каждом процессе ссылку на этот участок.
Это важная возможность. Так как минимизирует процесс поддержки и правки процессов. Если бы такая возможность была, мы бы могли изменять этот общий участок только единожды, без необходимости править каждый из процессов. Это как вынести общий участок кода в библиотеку.
В DataStage можно создавать Shared Containers. Это как раз то, о чем я говорю.
Продемонстрирую на примере. Вот содержимое контейнера. Все, что он делает — проверяет существование внешних ключей. Вот его содержимое:

А вот так мы можем его использовать в одном из процессов (а также и в других процессах тоже). Нам достаточно лишь указать некоторые параметры, которые будут определять какие ключи и из каких таблиц необходимо проверить:

Уже в первом пункте нам потребовалось использовать какую-либо возможность расширения функциональности за счет сторонних средств. Языков программирования или утилит. Так вот вы не сможете внедрить написанную вами функцию в DataFlow. Это возможно только в pipeline. Т.е. все трансформации над источниками данных (джойны, лукапы, оконные трансформации, и т.д.) можно делать в DataFlow, а что-то посложнее — в Pipeline. Это немного тоже обескураживает. Т.е. данные либо нужно приземлять в каком-либо временном хранилище (BlobStorage или в таблицах базы данных), а затем их вычитывать для применения своих собственных трансформаций (например, вот как мы хотели — вычислять хеши полей в рантайме).
Такое обособление увеличивает количество сущностей в процессах переливки данных. Либо форсирует использовать только pipeline, а джойны и другие операции, в таком случае, вам придется выполнять вручную.
Как нам объяснил архитектор Microsoft, под капотом у ADF DataFlow — Spark. Наверное поэтому, язык описания метаданных достаточно примитивный, Т.е. можно указать типы данных полей, достаточно близких к типам, которыми оперирует Spark: string, numeric, timestamp. Нельзя указать максимальную длину строки, или указать флаг нулябельности поля.
Это приводит к таким сложностям как:
Многим наверное покажется, что я попытался сравнить слона и пингвина. Но зачастую компании, при решении мигрировать в облако, думают, что нужно заменить и все приложения.
Зачастую это решение необдуманно и грозит головной болью консультантам и увеличением стоимости разработки и поддержки решения. Не говоря уже о vendor lock и других прелестях.
Этим небольшим сравнением я пытался убедить руководство своего клиента не принимать поспешных выводов при выборе ETL решения при миграции в облако Azure.
Пока статья была в черновиках, мы провели встречу с архитектором облачных решений Microsoft, чтобы он подтвердил или опроверг мои выводы и мог бы прояснить есть ли в roadmap что-то, что могло бы облегчить решение задач, описанных в главах выше.
Все пункты, кроме манипулирования полями в run-time были подтверждены и некоторые объяснены с точки зрения истории развития продукты. Что касается Run time column propagation, архитектор взял паузу, чтобы обсудить это с коллегами, но так и не вернулся к нам со своими выводами. Прошло уже два месяца. Наверное, все-таки нельзя реализовать такую схему манипуляции данными полноценно.
P.S. Клиент отказался от использования ADF для ETL, сейчас размышляет между Spark и DataStage :-)
Результаты моего небольшого сравнения под катом. Возможно вам оно пригодится тоже при составлении предложения клиентам.
Это сравнение не является исчерпывающим, в нем перечислены лишь аспекты, которые показались лично мне важными для разработки ETL процессов.
Немного о приоритетах сравнения
Azure DataFactory позиционируется как инструмент ETL, не требующий написания кода (code-free), с этой точки зрения я и пытался его рассматривать. Тем не менее, мы все знаем, что рано или поздно возникает необходимость усилить функциональность любой платформы обработки данных своими
Также, моей целью не было сравнение всех продуктов, входящих в сюиту IBM Information Server и всех приложений Azure (Профилирование данных, управление качеством данных, Data Gouvernance и т.д.), я постарался сконцентрироваться лишь на функциональности средств ETL.
Также я не скрываю своей предвзятости: я имею больше опыта работы с DataStage, чем с Azure DataFactory, поэтому, возможно я что-то упустил в своих выводах. Предлагаю тогда обсудить спорные моменты в комментариях.
Кроме того, Azure DataFactory — продукт довольно молодой и продолжает развиваться. Возможно, часть возможностей из предложенного списка будет добавлена позднее. Возможно, но крайне маловероятно, этому поспособствует данная статья. Но я бы хотел иметь в своем арсенале больше могущественных ETL средств.
Для каждого пункта я попытался подобрать несколько возможных сценариев применения, а также — некоторые способы обхода выявленных ограничений, если они имели место.
1. Отсутствие возможности манипулирования полями в run-time
Грубя говоря — все метаданные потока должны быть заданы во время разработки. Мы не сможем во время выполнения динамически выбирать над какими полями какие действия совершать.
Отсутствие такой возможности сильно ограничивает разработчика при создании общих правил трансформации. Например, данные, загружаемые в Staging или в Landing Area не содержат сложных правил трансформации. Как правило, нужно добавить несколько технических полей, таких как дата загрузки, идентификатор источника, возможно — номер текущей версии строки при историзации данных. Все остальные поля, содержащие данные, нужно протолкнуть без изменений, вне зависимости от их имен и количества.
В DataStage это решается за счет Runtime Column Propagation (RCP), схем данных OSH и этапами (стейджами) импорта/экспорта колонок.
Пример: Для всех входящих таблиц создать две колонки KEY_HASH и DATA_HASH, содержащие хеш MD5 ключеых полей и полей данных соответственно. Разумеется, количество ключевых полей может варьироваться от таблицы к таблице. Их имена также не детерминированы.
Решение на DS:
Мы просто извлекаем все колонки из исходной таблицы, на основе файла схемы данной таблицы (это такие файлы, которые содержат описание метаданных таблицы) генерируем на этапе CE_KeyHash техническое поле TECH_KEY, содержащее все ключевые поля таблицы, на этапе CS_KEY вычисляем хеш этого поля, а на этапе CS_DataHash вычисляем хеш всех полей, кроме технического.
Возможные решения на ADF: Использование Azure Functions. Да, это выход. Но мы еще вернемся к нему. Но это уже выход за пределы парадигмы code-free.
В некоторых случаях, возможно импортировать метаданные каждой таблицы при помощи этапа Lookup, на основе их сгенерировать запрос SQL, содержащий конкатенацию нужных колонок и вычисления хеша. Но это возможно только в случае, если источник данных поддерживает SQL, либо необходимо создавать в Polybase внешние таблицы над файлами (как в Hive — external tables). Ну, либо создавать на каждую таблицу отдельный DataFlow или Pipeline…
На самом деле, очень востребованная функциональность в ETL. Сильно ее не хватает в ADF. А без нее невозможно создать общие для нескольких источников процедуры переливки данных. Время на разработку увеличивается, ухудшается поддерживаемость решения. Использование Azure Functions тут же поднимает стоимость, усложняет процесс разработки. Так как теперь разработчику необходимо согласовать использование функции (которые оплачиваются за каждый вызов) с ответственным за бюджет проекта.
2. Отсутствие взаимодействия между строками
Это означает, что вы не можете создавать состояния, которые бы определяли способ обработки входящей строки от значения полей предыдущих (это, разумеется важно, когда данные отсортированы в каждой партиции). Кроме того, невозможно для одной входящей строки сгенерировать несколько исходящих.
Классический пример: WordCount — подсчет встречаемости каждого слова в документе. Одним из способов решить ее средствами ETL — превратить строчку из N слов в N строчек, содержащих эти слова и только эти слова. А дальше — агреггация и подсчет вхождений каждого слова.
Обратите внимание, что количество строк после трансформера T_ExtractWords больше, чем до него.
Как решить эту задачу стандартными средствами ADF я не смог придумать. Это не значит, что этого сделать нельзя — отнюдь. Но придется опять же дополнительно подготавливать данные до скармливания их этому ETL средству. Опять же, возникает необходимость привлекать внешние утилиты и языки программирования — Java, .Net, Spark…
3. Нет поддержки XML
Ну, тут все просто — нельзя читать и писать XML файлы стандартными средствами. Немножко был обескуражен, когда не смог найти способа этого сделать. Думал, наверное, сказывается моя неопытность обращения с ADF, попытался поискать по форумам и ресурсам Microsoft. Нашел вот этот вопрос и ответ. Т.е. предлагается использовать LogicApp чтобы конвертировать XML в какой-нибудь другой формат, подходящий для DataFactory, либо читать XML программно (что там про code-free?). LogicApp оплачивается, разумеется, отдельно. Ну, ребята, XXI век на дворе, все-таки.
Шутки из маршрутки

Сравните с возможностями этапа Hierarchical File от DataStage. Он тоже не без греха, его нужно тюнить для больших XML, но это целый комбайн, который позволяет производить трансформации непосредственно со структурой XML файла: джойнить данные между тегами, трансформировать структуру без XSLT (но и с ним тоже возможно) и выполнять другие операции.
4. Нет возможности выносить общие куски процессов
Сложно это было сформулировать, проясню: некоторые различные ETL процессы могут иметь общие участки трансформаций. Так вот нельзя этот участок вынести и сохранить отдельно, создав в каждом процессе ссылку на этот участок.
Это важная возможность. Так как минимизирует процесс поддержки и правки процессов. Если бы такая возможность была, мы бы могли изменять этот общий участок только единожды, без необходимости править каждый из процессов. Это как вынести общий участок кода в библиотеку.
В DataStage можно создавать Shared Containers. Это как раз то, о чем я говорю.
Продемонстрирую на примере. Вот содержимое контейнера. Все, что он делает — проверяет существование внешних ключей. Вот его содержимое:
А вот так мы можем его использовать в одном из процессов (а также и в других процессах тоже). Нам достаточно лишь указать некоторые параметры, которые будут определять какие ключи и из каких таблиц необходимо проверить:
5. Обособление пользовательских расширений и потока данных
Уже в первом пункте нам потребовалось использовать какую-либо возможность расширения функциональности за счет сторонних средств. Языков программирования или утилит. Так вот вы не сможете внедрить написанную вами функцию в DataFlow. Это возможно только в pipeline. Т.е. все трансформации над источниками данных (джойны, лукапы, оконные трансформации, и т.д.) можно делать в DataFlow, а что-то посложнее — в Pipeline. Это немного тоже обескураживает. Т.е. данные либо нужно приземлять в каком-либо временном хранилище (BlobStorage или в таблицах базы данных), а затем их вычитывать для применения своих собственных трансформаций (например, вот как мы хотели — вычислять хеши полей в рантайме).
Такое обособление увеличивает количество сущностей в процессах переливки данных. Либо форсирует использовать только pipeline, а джойны и другие операции, в таком случае, вам придется выполнять вручную.
6. Слабые возможности описания метаданных, слабое управление нулябельными полями
Как нам объяснил архитектор Microsoft, под капотом у ADF DataFlow — Spark. Наверное поэтому, язык описания метаданных достаточно примитивный, Т.е. можно указать типы данных полей, достаточно близких к типам, которыми оперирует Spark: string, numeric, timestamp. Нельзя указать максимальную длину строки, или указать флаг нулябельности поля.
Это приводит к таким сложностям как:
- Невозможность работы с файлам с фиксированной длиной полей. Такие данные часто генерируются унаследованными системами, мейнфреймами, AS400 и т.д. Выход, конечно, есть — использовать ручное разделения полей с substring(data, start, len), но поддерживать это все не очень весело.
- Невозможно контролировать возникновения Null в полях, которые не предназначены для этого. Например, нельзя объявить некоторое поле Not Null и в случае появления нулового значения автоматически его реджектить. Придется каждое поле проверять на наличие нулов вручную.
Послесловие
Многим наверное покажется, что я попытался сравнить слона и пингвина. Но зачастую компании, при решении мигрировать в облако, думают, что нужно заменить и все приложения.
Зачастую это решение необдуманно и грозит головной болью консультантам и увеличением стоимости разработки и поддержки решения. Не говоря уже о vendor lock и других прелестях.
Этим небольшим сравнением я пытался убедить руководство своего клиента не принимать поспешных выводов при выборе ETL решения при миграции в облако Azure.
Пока статья была в черновиках, мы провели встречу с архитектором облачных решений Microsoft, чтобы он подтвердил или опроверг мои выводы и мог бы прояснить есть ли в roadmap что-то, что могло бы облегчить решение задач, описанных в главах выше.
Все пункты, кроме манипулирования полями в run-time были подтверждены и некоторые объяснены с точки зрения истории развития продукты. Что касается Run time column propagation, архитектор взял паузу, чтобы обсудить это с коллегами, но так и не вернулся к нам со своими выводами. Прошло уже два месяца. Наверное, все-таки нельзя реализовать такую схему манипуляции данными полноценно.
P.S. Клиент отказался от использования ADF для ETL, сейчас размышляет между Spark и DataStage :-)