
Руслан Ароматов, главный разработчик, МКБ

Добрый день, хабровчане! Я работаю бэкенд-разработчиком в Московском кредитном банке, и в этот раз я бы хотел рассказать о том, как мы организовали доставку рантаймового контента в наше мобильное приложение «МКБ Онлайн». Статья может пригодиться тем, кто занимается проектированием и разработкой фронт-серверов для мобильных приложений, в которые необходимо постоянно доставлять разнообразные обновления, будь то банковские документы, точки геолокации, обновлённые иконки и т. п. без обновления самого приложения в магазинах. Тем, кто разрабатывает мобильные приложения, она тоже не повредит. Статья не содержит примеров кода, только некоторые рассуждения на тему.
Думаю, что любой разработчик мобильных приложений сталкивался с проблемой обновления какой-то части контента своего приложения. Например, изменить пункт пользовательского соглашения, иконку или координаты магазина заказчика, который внезапно переехал. Вроде бы, что может быть проще? Пересобираем приложение и выкладываем в магазин. Клиенты обновляются, все довольны.
Но эта простая схема не работает по одной простой причине — не все клиенты обновляются. И таких клиентов, судя по статистике, достаточно много.
В случае банковского приложения недоставка актуальной информации может стоить и денег, и недовольства клиентов. Например, первого числа следующего месяца изменяются тарифы по картам, включаются новые правила бонусной программы или же добавляются новые виды получателей платежей. И если клиент ровно в 0 часов 01 минуту запустит приложение, то должен увидеть обновлённый контент.
«Элементарно!» — скажете вы. — «Грузите эти данные с сервера и будет вам счастье».
И будете правы. Мы так и делаем.Всё, расходимся.
Однако не всё так просто. Приложения у нас есть как для iOS, так и для android. Каждая платформа имеет несколько разных версий, которые имеют отличающийся функционал и api.
В итоге может случиться, что нам необходимо обновить файл для приложения на android с версией api выше 27, но не трогать iOS и более ранние версии.
Ещё интереснее получается, когда нам, допустим, необходимо обновить иконки получателей платежей или добавить новые пункты с новыми иконками. Каждый экземпляр иконки мы рисуем в семи разных разрешениях под каждый конкретный тип экрана: для андроида у нас их 4 (hdpi, xhdpi, xxhdpi, xxxhdpi) и 3 для iOS (1х, 2х, 3х). Какую из них присылать в конкретное приложение?
«Ну так шлите параметры файлов, которые необходимы конкретному приложению».
Правильно! О том, какой именно файл нужен приложению, кроме приложения, никто не знает.
Тем не менее, и это ещё не всё. В приложениях есть довольно много файлов, взаимосвязанных между собой. Например, списки получателей платежей (один json-файл) связаны с реквизитами получателей платежей (другой json-файл). И если мы получим первый файл и по какой-то причине не сможем получить второй, то клиенты не смогут провести оплату услуги. И это не очень хорошо, прямо скажем.
Второй случай: мы обновляем весь набор иконок получателей платежей (а их там больше сотни) при заходе на страницу оплаты. В зависимости от скорости интернета, она может занимать от 10 секунд до нескольких минут. Каково должно быть правильное поведение страницы? Например, можно просто отображать предыдущую версию иконок, а новые качать в фоне, затем кэшировать и только при следующем заходе клиента на страницу показывать новые. Как-то не очень, да?
Другой вариант — динамически подменять уже скачанные иконки на новые. Не слишком красиво, правда? А если какая-то иконка не скачается вообще? Тогда мы будем видеть красивый ряд новых иконок с куском старого дизайна посередине.
«Загружайте тогда весь набор иконок одним архивом при старте приложения».
Неплохая мысль. Нет, правда. Но есть нюанс.
Нередко бывает так, что дизайнер перерисовал только пару иконок из сотни, и надо подменить только их. Они весят 200 байт, а весь архив у нас 200 килобайт. Это что, клиенту придётся заново выкачивать то, что у него и так есть?
И это мы ещё не посчитали стоимость такой работы на сервере. Допустим, к нам заходят 10000 клиентов в час (это среднее значение, бывает больше). Старт приложения инициирует фоновое обновление справочников (да, вы теперь знаете, как это у нас называется). Если одному клиенту требуется обновить 1 килобайт, то за час сервер отдаст более 10 мегабайт. Копейки, правда? А если набор обновлений весит 1 мегабайт? в этом случае нам придётся отдать уже 10 гигабайт. В какой-то момент мы приходим к мысли, что нужно считать траффик.
Тогда нужно научиться понимать, какие файлы изменились, а какие нет, и качать только нужные.
Верно. А как понять, какие файлы изменились, а какие нет? Мы для этого считаем хэш. Таким образом, в приложении появляется некий файловый кэш, в котором содержится набор файлов справочников. Эти файлы используются в качестве ресурсов по мере необходимости. А на серверной стороне у нас в итоге родился…
Вообще, это обычный веб-сервис, который по http отдаёт файлы с учётом всех требований приложения. Он состоит из энного количества докер-контейнеров, внутри которых работает java-приложение с веб-сервером jetty на борту. Бэкендом является БД Tarantool на движке vinyl (здесь не было какого-то мучительного выбора — просто под эту БД уже была вся обвязка; об этом можно прочитать в моей предыдущей статье Умный сервис кэша на базе ZeroMQ и Tarantool) с репликацией master-slave. Для управления файлами есть служебный веб-интерфейс, также полностью написанный своими руками.
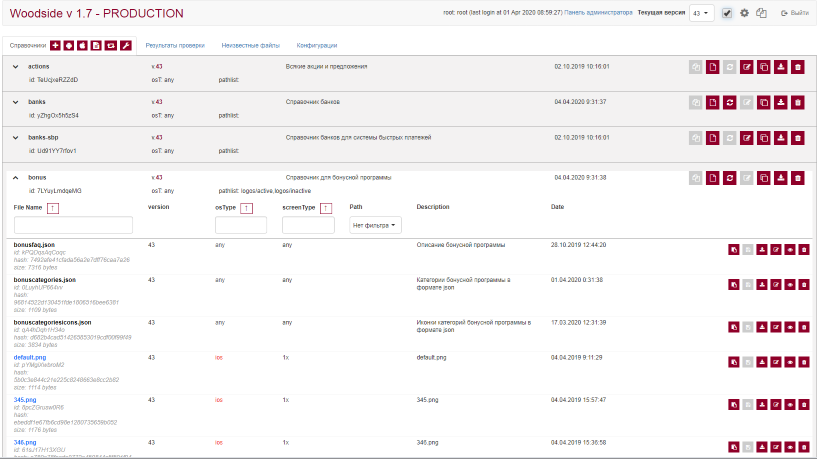
Технические детали реализации в теме данной статьи не имеют особого значения. Это мог бы быть php+apache+mysql, С#+IIS+MSSQL или любая другая связка, в том числе и без базы данных вообще.
На схеме ниже показано, как работает сервис, который мы назвали Woodside. Мобильные клиенты через балансировщик идут на инстансы веб-сервисов, а те в свою очередь достают из БД необходимые файлы.
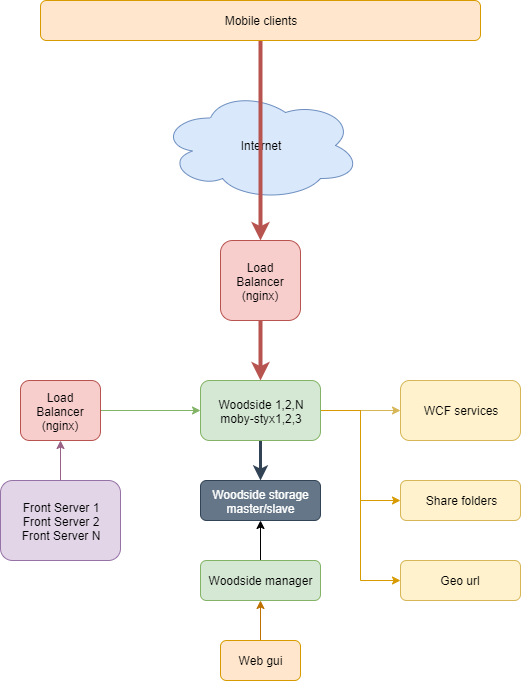
Но в этой статье я расскажу только про структуру системы справочников, и о том, как мы их используем в приложениях.
Файлы, необходимые в приложениях, мы делим на 3 разных типа.
Первые 2 типа файлов в виде архивов сразу же кладутся в сборку приложения — свежий релиз по умолчанию включает в себя самый новый набор справочников. Они же попадают в систему автоматического обновления, которая запускается в фоновом режиме при старте приложения, и работает следующим образом.
1. Сервис справочников в автоматическом режиме получает часть данных из различных мест: базы данных, смежные сервисы, сетевые шары — это какая-то важная общебанковская информация, которую обновляют другие подразделения. Другая часть — это справочники, созданные внутри нашей команды через веб-интерфейс, и содержащие файлы, предназначенные только для мобильных приложений.
2. По расписанию (или по кнопке) сервис пробегается по всем файлам всех справочников, и на их основе формирует набор индексных файлов (внутри json) как для файлов первого типа (2 версии для iOS и андроид), так и для файлов-ресурсов второго типа (7 версий для каждого типа экрана).
Выглядит это примерно так:
В индексах содержится информация по всем файлам заданного типа, на основе которой строится механизм обновления справочников на приложениях.
3. Приложения при старте первым делом скачивают себе индексные файлы в каталог /new внутри своего файлового кэша. А в каталоге /current у них лежат индексы для текущего набора файлов вместе с самими файлами.
4. На основе нового и старого индексных файлов (с участием всех текущих файлов, от которых считается хэш) создаются списки файлов, которые требуется обновить или удалить, а также вообще устанавливается необходимость обновления.
5. После этого в каталог /new приложения качают необходимые файлы с сервера по прямой ссылке (за это отвечает id файла в индексе). При этом учитываются ещё наличие и хэши файлов, уже находящихся в каталоге /new, ведь это может быть докачка.
6. Как только весь набор файлов получен в каталог /new, происходит их проверка по индексному файлу (иногда бывало, что файлы не полностью скачивались).
7. Если проверка была успешной, всё дерево файлов перемещается с заменой в каталог /current. Свежий индексный файл становится текущим.
8. Если проверка окажется неуспешной, перемещения файлов не произойдёт, и приложение продолжит использовать текущий набор справочников. При следующем старте приложения механизм обновления попытается это исправить. Если же у нас случается глобальный сбой при перемещении файлов, то мы вынуждены откатиться к самой первой версии справочников, которая шла вместе со сборкой. Пока прецедентов не было.
Но почему так сложно?
В реальности, не очень сложно. Но дело в том, что нам постоянно приходится экспериментировать и искать компромиссы между количеством постоянно обновляемых файлов и рантаймовой загрузкой, между экономией траффика и скоростью. Большую роль в выборе типа файла играет то, когда именно он нужен в приложении. Допустим, если иконка должна отображаться сразу на главной странице после логина, то такой файл приложение может грузить в рантайме сразу же, а не помещать в долгий механизм обновления. Сейчас общий размер архива только с основными файлами у нас 12 мегабайт, не считая экранозависимых ресурсов. А так как обновление у нас по сути атомарная операция, необходимо дождаться, пока оно закончится. Это может занимать до нескольких минут в случаях, когда связь плохая, а новых файлов много.
Важный момент это экономия траффика. Бывали случаи, когда мы полностью утилизировали канал в 100 мегабит после толстых обновлений. Пришлось расширять до 300. Пока хватает. В среднем, метрики показывают, что обычно клиенты скачивают днём от 25 до 50 гигабайт в час (это происходит потому, что у нас существуют довольно объемные файлы, которые обновляются ежедневно). Есть ещё куда развиваться в плане экономии, но и бизнес тоже не дремлет — всё время добавляют разнообразные новые красивости.
В заключение, могу добавить, что сервисом пользуются также и сами фронт-сервера, которые при старте скачивают себе необходимые для обработки клиентских запросов данные.
А каким образом вы доставляете обновления контента в приложения?
Добрый день, хабровчане! Я работаю бэкенд-разработчиком в Московском кредитном банке, и в этот раз я бы хотел рассказать о том, как мы организовали доставку рантаймового контента в наше мобильное приложение «МКБ Онлайн». Статья может пригодиться тем, кто занимается проектированием и разработкой фронт-серверов для мобильных приложений, в которые необходимо постоянно доставлять разнообразные обновления, будь то банковские документы, точки геолокации, обновлённые иконки и т. п. без обновления самого приложения в магазинах. Тем, кто разрабатывает мобильные приложения, она тоже не повредит. Статья не содержит примеров кода, только некоторые рассуждения на тему.
Предпосылки
Думаю, что любой разработчик мобильных приложений сталкивался с проблемой обновления какой-то части контента своего приложения. Например, изменить пункт пользовательского соглашения, иконку или координаты магазина заказчика, который внезапно переехал. Вроде бы, что может быть проще? Пересобираем приложение и выкладываем в магазин. Клиенты обновляются, все довольны.
Но эта простая схема не работает по одной простой причине — не все клиенты обновляются. И таких клиентов, судя по статистике, достаточно много.
В случае банковского приложения недоставка актуальной информации может стоить и денег, и недовольства клиентов. Например, первого числа следующего месяца изменяются тарифы по картам, включаются новые правила бонусной программы или же добавляются новые виды получателей платежей. И если клиент ровно в 0 часов 01 минуту запустит приложение, то должен увидеть обновлённый контент.
«Элементарно!» — скажете вы. — «Грузите эти данные с сервера и будет вам счастье».
И будете правы. Мы так и делаем.
Однако не всё так просто. Приложения у нас есть как для iOS, так и для android. Каждая платформа имеет несколько разных версий, которые имеют отличающийся функционал и api.
В итоге может случиться, что нам необходимо обновить файл для приложения на android с версией api выше 27, но не трогать iOS и более ранние версии.
Ещё интереснее получается, когда нам, допустим, необходимо обновить иконки получателей платежей или добавить новые пункты с новыми иконками. Каждый экземпляр иконки мы рисуем в семи разных разрешениях под каждый конкретный тип экрана: для андроида у нас их 4 (hdpi, xhdpi, xxhdpi, xxxhdpi) и 3 для iOS (1х, 2х, 3х). Какую из них присылать в конкретное приложение?
«Ну так шлите параметры файлов, которые необходимы конкретному приложению».
Правильно! О том, какой именно файл нужен приложению, кроме приложения, никто не знает.
Тем не менее, и это ещё не всё. В приложениях есть довольно много файлов, взаимосвязанных между собой. Например, списки получателей платежей (один json-файл) связаны с реквизитами получателей платежей (другой json-файл). И если мы получим первый файл и по какой-то причине не сможем получить второй, то клиенты не смогут провести оплату услуги. И это не очень хорошо, прямо скажем.
Второй случай: мы обновляем весь набор иконок получателей платежей (а их там больше сотни) при заходе на страницу оплаты. В зависимости от скорости интернета, она может занимать от 10 секунд до нескольких минут. Каково должно быть правильное поведение страницы? Например, можно просто отображать предыдущую версию иконок, а новые качать в фоне, затем кэшировать и только при следующем заходе клиента на страницу показывать новые. Как-то не очень, да?
Другой вариант — динамически подменять уже скачанные иконки на новые. Не слишком красиво, правда? А если какая-то иконка не скачается вообще? Тогда мы будем видеть красивый ряд новых иконок с куском старого дизайна посередине.
«Загружайте тогда весь набор иконок одним архивом при старте приложения».
Неплохая мысль. Нет, правда. Но есть нюанс.
Нередко бывает так, что дизайнер перерисовал только пару иконок из сотни, и надо подменить только их. Они весят 200 байт, а весь архив у нас 200 килобайт. Это что, клиенту придётся заново выкачивать то, что у него и так есть?
И это мы ещё не посчитали стоимость такой работы на сервере. Допустим, к нам заходят 10000 клиентов в час (это среднее значение, бывает больше). Старт приложения инициирует фоновое обновление справочников (да, вы теперь знаете, как это у нас называется). Если одному клиенту требуется обновить 1 килобайт, то за час сервер отдаст более 10 мегабайт. Копейки, правда? А если набор обновлений весит 1 мегабайт? в этом случае нам придётся отдать уже 10 гигабайт. В какой-то момент мы приходим к мысли, что нужно считать траффик.
Тогда нужно научиться понимать, какие файлы изменились, а какие нет, и качать только нужные.
Верно. А как понять, какие файлы изменились, а какие нет? Мы для этого считаем хэш. Таким образом, в приложении появляется некий файловый кэш, в котором содержится набор файлов справочников. Эти файлы используются в качестве ресурсов по мере необходимости. А на серверной стороне у нас в итоге родился…
Сервис справочников
Вообще, это обычный веб-сервис, который по http отдаёт файлы с учётом всех требований приложения. Он состоит из энного количества докер-контейнеров, внутри которых работает java-приложение с веб-сервером jetty на борту. Бэкендом является БД Tarantool на движке vinyl (здесь не было какого-то мучительного выбора — просто под эту БД уже была вся обвязка; об этом можно прочитать в моей предыдущей статье Умный сервис кэша на базе ZeroMQ и Tarantool) с репликацией master-slave. Для управления файлами есть служебный веб-интерфейс, также полностью написанный своими руками.
Технические детали реализации в теме данной статьи не имеют особого значения. Это мог бы быть php+apache+mysql, С#+IIS+MSSQL или любая другая связка, в том числе и без базы данных вообще.
На схеме ниже показано, как работает сервис, который мы назвали Woodside. Мобильные клиенты через балансировщик идут на инстансы веб-сервисов, а те в свою очередь достают из БД необходимые файлы.
Но в этой статье я расскажу только про структуру системы справочников, и о том, как мы их используем в приложениях.
Файлы, необходимые в приложениях, мы делим на 3 разных типа.
- Файлы, которые обязаны быть в приложении всегда, и независимые от типа операционной системы. Например, это pdf-файл с договором банковского обслуживания.
- Файлы-ресурсы, также обязательные в приложении, но зависящие от операционной системы и параметров экрана (плотность пикселов) устройства. Например, иконки получателей платежей.
- Файлы, которым не требуется быть в наличии в файловом кэше постоянно, они запрашиваются приложением по требованию. Это могут быть какие-то документы, которые клиент может никогда не открыть или тяжелые картинки партнёрской программы, в которую клиент может ни разу не зайти. Такие файлы в зависимости от выбранной политики могут удаляться из кэша после выхода из приложения, дабы не занимать место.
Первые 2 типа файлов в виде архивов сразу же кладутся в сборку приложения — свежий релиз по умолчанию включает в себя самый новый набор справочников. Они же попадают в систему автоматического обновления, которая запускается в фоновом режиме при старте приложения, и работает следующим образом.
1. Сервис справочников в автоматическом режиме получает часть данных из различных мест: базы данных, смежные сервисы, сетевые шары — это какая-то важная общебанковская информация, которую обновляют другие подразделения. Другая часть — это справочники, созданные внутри нашей команды через веб-интерфейс, и содержащие файлы, предназначенные только для мобильных приложений.
2. По расписанию (или по кнопке) сервис пробегается по всем файлам всех справочников, и на их основе формирует набор индексных файлов (внутри json) как для файлов первого типа (2 версии для iOS и андроид), так и для файлов-ресурсов второго типа (7 версий для каждого типа экрана).
Выглядит это примерно так:
{
"version": "43",
"date": "04 Apr 2020 12:31:59",
"os": "android",
"screen": "any",
"hashType": "md5",
"ts": 1585992719,
"files": [
{
"id": "WBRbDUlWhhhj",
"name": "action-in-rhythm-of-life.json",
"dir": "actions",
"ts": 1544607853,
"hash": "68c589c4fa8a44ded4d897c3d8b24e5c"
},
{
"id": "o3K4mmPOOnxu",
"name": "banks.json",
"dir": "banks",
"ts": 1583524710,
"hash": "c136d7be420b31f65627f4200c646e0b"
}
]
}В индексах содержится информация по всем файлам заданного типа, на основе которой строится механизм обновления справочников на приложениях.
3. Приложения при старте первым делом скачивают себе индексные файлы в каталог /new внутри своего файлового кэша. А в каталоге /current у них лежат индексы для текущего набора файлов вместе с самими файлами.
4. На основе нового и старого индексных файлов (с участием всех текущих файлов, от которых считается хэш) создаются списки файлов, которые требуется обновить или удалить, а также вообще устанавливается необходимость обновления.
5. После этого в каталог /new приложения качают необходимые файлы с сервера по прямой ссылке (за это отвечает id файла в индексе). При этом учитываются ещё наличие и хэши файлов, уже находящихся в каталоге /new, ведь это может быть докачка.
6. Как только весь набор файлов получен в каталог /new, происходит их проверка по индексному файлу (иногда бывало, что файлы не полностью скачивались).
7. Если проверка была успешной, всё дерево файлов перемещается с заменой в каталог /current. Свежий индексный файл становится текущим.
8. Если проверка окажется неуспешной, перемещения файлов не произойдёт, и приложение продолжит использовать текущий набор справочников. При следующем старте приложения механизм обновления попытается это исправить. Если же у нас случается глобальный сбой при перемещении файлов, то мы вынуждены откатиться к самой первой версии справочников, которая шла вместе со сборкой. Пока прецедентов не было.
Но почему так сложно?
В реальности, не очень сложно. Но дело в том, что нам постоянно приходится экспериментировать и искать компромиссы между количеством постоянно обновляемых файлов и рантаймовой загрузкой, между экономией траффика и скоростью. Большую роль в выборе типа файла играет то, когда именно он нужен в приложении. Допустим, если иконка должна отображаться сразу на главной странице после логина, то такой файл приложение может грузить в рантайме сразу же, а не помещать в долгий механизм обновления. Сейчас общий размер архива только с основными файлами у нас 12 мегабайт, не считая экранозависимых ресурсов. А так как обновление у нас по сути атомарная операция, необходимо дождаться, пока оно закончится. Это может занимать до нескольких минут в случаях, когда связь плохая, а новых файлов много.
Важный момент это экономия траффика. Бывали случаи, когда мы полностью утилизировали канал в 100 мегабит после толстых обновлений. Пришлось расширять до 300. Пока хватает. В среднем, метрики показывают, что обычно клиенты скачивают днём от 25 до 50 гигабайт в час (это происходит потому, что у нас существуют довольно объемные файлы, которые обновляются ежедневно). Есть ещё куда развиваться в плане экономии, но и бизнес тоже не дремлет — всё время добавляют разнообразные новые красивости.
В заключение, могу добавить, что сервисом пользуются также и сами фронт-сервера, которые при старте скачивают себе необходимые для обработки клиентских запросов данные.
А каким образом вы доставляете обновления контента в приложения?