

Привет, Хабр! Я работаю бэкенд-разработчиком в Московском кредитном банке, и за время работы у меня накопился некоторый опыт, которым я хотел бы поделиться с сообществом. Сегодня я расскажу, как мы писали свой собственный сервис кэша для фронт-серверов наших клиентов, использующих мобильное приложение «МКБ Онлайн». Статья может быть полезна тем, кто занимается проектированием сервисов и знаком с микросервисной архитектурой, in-memory базой данных Tarantool и библиотекой ZeroMQ. В статье практически не будет примеров кода и объяснения основ, а только описание логики работы сервисов и их взаимодействия на конкретном примере, работающем у нас на бою уже более двух лет.
Как всё начиналось
Лет эдак 6 назад схема была простая. В наследство от аутсорсинговой компании нам досталось два мобильных банк-клиента под iOS и андроид, а также фронт-сервер, их обслуживающий. Сам сервер был написан на java, в свой бэкенд ходил разными способами (в основном soap), а с клиентами общался путем передачи xml по https.
Клиентские приложения умели как-то аутентифицироваться, показывать список продуктов и… вроде бы умели совершать какие-то переводы и платежи, но по факту делали это не очень хорошо и не всегда. Поэтому ни большого количества пользователей, ни каких-то серьезных нагрузок фронт-сервер не испытывал (что, однако, не мешало ему падать примерно раз в один-два дня).
Понятно, что нас (а на тот момент наша команда состояла из четырех человек), как ответственных за мобильный банк, такая ситуация не устраивала, и для начала мы привели в порядок текущие приложения, а вот фронт-сервер оказался совсем плох, поэтому его пришлось быстро переписать целиком, попутно заменив xml на json и переехав в сервер приложений WildFly. Растянувшийся на пару лет рефакторинг не тянет на тему отдельного поста, так как всё делалось в основном для того, чтобы система просто стабильно работала.
Постепенно приложения и сервер развивались, стали работать стабильнее, а их функционал постоянно расширялся, что принесло свои плоды — пользователей становилось всё больше и больше.
При этом всё чаще начали вставать такие вопросы, как отказоустойчивость, резервирование, репликация и — страшно подумать — highload.
Быстрым решением проблемы стало добавление второго сервера WildFly, а приложения научились переключаться между ними. Проблему одновременной работы с клиентскими сессиями решили встроенным в WildFly модулем Infinispan.
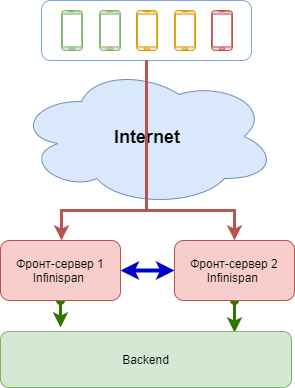
Казалось, что жизнь налаживается…
Так жить нельзя
Однако такой вариант работы с сессиями по факту оказался не лишён недостатков. Упомяну те, которые нас не устраивали.
- Потеря сессий. Самый важный минус. Например, приложение шлёт два запроса на сервер-1: первый запрос это аутентификация, а второй — запрос списка счетов. Аутентификация проходит успешно, на сервере-1 создаётся сессия. В это время второй клиентский запрос внезапно обламывается из-за плохой связи, и приложение переключается на сервер-2, перепосылая переадресуя второй запрос. Но при определённой загруженности Infinispan может не успеть синхронизировать данные между нодами. В результате, сервер-2 не может верифицировать клиентскую сессию, посылает клиенту гневный ответ, клиент печалится и завершает свою сессию. Пользователю приходится логиниться ещё раз. Грустно.
- Перезапуск сервера также может вызывать потерю сессий. Например, после обновления (а это случается достаточно часто). При старте сервера-2 он не может работать, пока не пройдет синхронизация данных с сервером-1. Вроде сервер стартовал, но по факту принимать запросы не должен. Это неудобно.
- Это встроенный модуль WildFly, который мешает нам уйти от этого сервера приложений в сторону микросервисов.
Отсюда как-то сам собой сформировался список того, чего нам бы хотелось.
- Мы хотим хранить клиентские сессии так, чтобы любой сервер (сколько бы их ни было) сразу после старта имел к ним доступ.
- Мы хотим сохранять любые клиентские данные между запросами (например, параметры платежей и всё такое).
- Мы хотим сохранять вообще любые произвольные данные по произвольному ключу.
- А ещё мы хотим получать клиентские данные до того, как пройдёт аутентификация. Например, пользователь аутентифицируется, а все его продукты тут как тут, свежие и тёпленькие.
- И масштабироваться хотим по нагрузке.
- И запускаться в докере, и писать логи в единый стек, и считать метрики, и так далее…
- Ах, да, и чтобы быстро всё работало.
Муки выбора
Ранее мы не занимались реализацией микросервисной архитектуры, поэтому для начала сели читать, смотреть и пробовать разные варианты. Ясно было сразу, что нам нужно быстрое хранилище и какая-то надстройка над ним, занимающаяся бизнес-логикой и являющаяся интерфейсом доступа в хранилище. Кроме этого, неплохо бы прикрутить быстрый транспорт между сервисами.
Выбирали долго, много спорили и экспериментировали. Я не буду сейчас описывать плюсы и минусы всех кандидатов, это не относится к теме данной статьи, просто скажу, что хранилищем будет tarantool, сервис напишем свой на java, а в качестве транспорта поработает ZeroMQ. Даже не стану спорить, что выбор весьма неоднозначный, однако на него во многом повлияло то, что мы не слишком любим разные большие и тяжелые фреймворки (за их вес и неповоротливость), коробочные решения (за их универсальность и недостаток кастомизации), но при этом любим контролировать все части нашей системы, насколько это возможно. А для контроля работы сервисов мы выбрали сервер сбора метрик Prometheus с его удобными агентами, которые можно встроить практически в любой код. Логи всего этого поедут в стек ELK.
Ладно, мне кажется, уже слишком много теории было.
Начать и кончить
Результатом проектирования стала примерно такая схема.
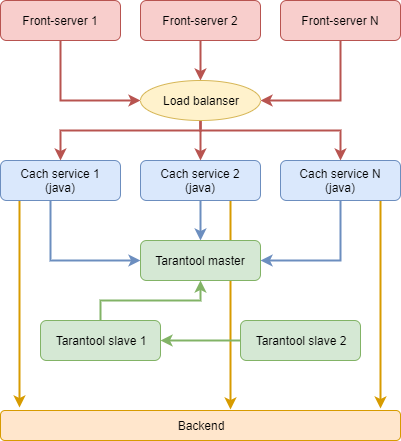
Хранилище
Оно должно быть максимально тупым, только чтобы хранить данные и их текущие состояния, зато работать всегда без перезапусков. Проектируется так, чтобы обслуживать разные версии фронт-серверов. Все данные держим в памяти, восстановление в случае перезапуска через .snap- и .xlog-файлы.
Таблица (space) для клиентских сессий:
- ID сессии;
- ID клиента;
- версия (сервиса)
- время обновления (timestamp);
- время жизни (ttl);
- сериализованные сессионные данные.
Здесь всё просто: клиент аутентифицируется, фронт-сервер создаёт сессию и сохраняет в хранилище, запоминая время. При каждом запросе данных время обновляется, таким образом, сессия поддерживается в живом состоянии. Если при запросе данные окажутся устаревшими (или их вообще не будет), то вернём специальный код возврата, после чего клиент завершит свою сессию.
Таблица простого кэша (для любых сессионных данных):
- ключ;
- ID сессии;
- тип хранимых данных (произвольное число);
- время обновления (timestamp);
- время жизни (ttl);
- сериализованные данные.
Таблица клиентских данных, которые нужно прогревать еще до логина:
- ID клиента;
- ID сессии;
- версия (сервиса)
- тип хранимых данных (произвольное число);
- время обновления (timestamp);
- состояние;
- сериализованные данные.
Здесь важное поле — состояние. Собственно, их всего два — idle и updating. Ставятся они вышележащим сервисом, который ходит в бэкенд за данными клиента для того, чтобы другой инстанс этого сервиса не занимался той же самой (уже бесполезной) работой и не грузил бэкенд.
Таблица устройств:
- ID клиента;
- ID устройства;
- время обновления (timestamp);
Таблица устройств необходима для того, чтобы еще до того, как клиент аутентифицируется в системе, узнать его ID и начать получение его продуктов (прогрев кэша). Логика такая: первый вход у нас всегда холодный, так как до аутентификации мы не знаем, что за клиент входит с незнакомого нам устройства (ID устройства мобильные клиенты передают всегда в любых запросах). Все последующие входы с этого устройства будут сопровождаться прогревом кэша для ассоциированного с ним клиента.
Работа с данными изолирована от java-сервиса серверными процедурами. Да, пришлось подучить lua, но это не заняло много времени. Кроме собственно управления данными, lua-процедуры еще отвечают за возврат текущих состояний, выборки по индексам, подчистку устаревших записей в фоновых процессах (fibers) и работу встроенного веб-сервера, через который осуществляется прямой служебный доступ к данным. Вот она — прелесть написания всего руками — возможность неограниченного контроля. Но и минус в том же — всё нужно писать самому.
Сам tarantool работает в докер-контейнере, все необходимые lua-файлы кладутся туда на этапе сборки образа. Вся сборка через gradle-скрипты.
Репликация по схеме master-slave. На другом хосте запускается точно такой же контейнер, выполняющий роль реплики основного хранилища. Он нужен на случай аварийного падения мастера — тогда java-сервисы переключаются на slave, и он становится мастером. Есть еще третий slave на всякий случай. Впрочем, даже полная потеря данных в нашем случае печальна, но не смертельна. По худшему сценарию пользователям придётся перелогиниться и заново получить все данные, которые снова попадут в кэш.
Java-сервис
Проектировался как типичный stateless-микросервис. Не имеет никакого конфига, все необходимые параметры (а их штук 6) передаются через переменные окружения при создании докер-контейнера. С фронт-сервером работает через транспорт ZeroMQ (org.zeromq.jzmq — java-интерфейс к нативной libzmq.so.5.1.1, которую мы сами собирали) по нашему собственному протоколу. С тарантулом работает через java-коннектор (org.tarantool.connector).
Инициализация сервиса достаточно простая:
- Стартуем логгер (log4j2);
- Из переменных окружения (мы в докере) читаем необходимые для работы параметры;
- Стартуем сервер метрик (jetty);
- Соединяемся с тарантулом (асинхронно);
- Стартуем необходимое количество нитей-обработчиков (workers);
- Стартуем брокер (zmq) — бесконечный цикл обработки сообщений.
Из всего вышеперечисленного интересен только движок обработки сообщений. Ниже представлена схема работы микросервиса.
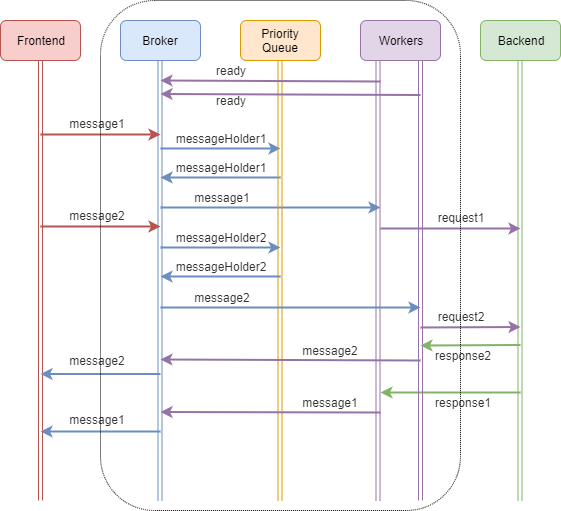
Начнём со старта брокера. Брокер у нас это набор zmq-сокетов типа ROUTER, который принимает соединения от различных клиентов и занимается диспетчеризацией сообщений, приходящих от них.
В нашем случае у нас есть один слушающий сокет на внешнем интерфейсе, принимающий сообщения от клиентов по протоколу tcp и другой — принимающий сообщения от нитей-воркеров (workers) по протоколу inproc (он значительно быстрее tcp).
/**
// Общий контекст (один на всё приложение, тут для наглядности)
ZContext zctx = new ZContext();
// сокет для клиентов
ZMQ.Socket clientServicePoint = zctx.createSocket(ZMQ.ROUTER);
// сокет для обработчиков
ZMQ.Socket workerServicePoint= zctx.createSocket(ZMQ.ROUTER);
// создаем точку прослушивания клиентов
clientServicePoint.bind("tcp://*:" + Config.ZMQ_LISTEN_PORT);
// создаем точку прослушивания обработчиков
workerServicePoint.bind("inproc://worker-proc");
После инициализации сокетов запускаем бесконечный цикл обработки событий.
/**
* Основная функция нити обработки запросов
*/
public int run() {
int status;
try {
ZMQ.Poller poller = new ZMQ.Poller(2);
poller.register(workerServicePoint, ZMQ.Poller.POLLIN);
poller.register(clientServicePoint, ZMQ.Poller.POLLIN);
int rc;
while (true) {
// Опрашиваем обработчиков
rc = poller.poll(POLL_INTERVAL);
if (rc == -1) {
status = -1;
logger.errorInternal("Broker run error rc = -1");
break; // Случилось что-то страшное
}
// Обработка сообщений от воркеров (бэкенд)
if (poller.pollin(0)) {
processBackendMessage(ZMsg.recvMsg(workerServicePoint));
}
// Обработка сообщений от клиентов
if (poller.pollin(1)) {
processFrontendMessage(ZMsg.recvMsg(clientServicePoint));
}
processQueueForBackend();
}
} catch (Exception e) {
status = -1;
} finally {
clientServicePoint.close();
workerServicePoint.close();
}
return status;
}
Логика работы очень простая: мы принимаем сообщения из разных мест и что-либо с ними делаем. Если у нас что-то критично сломалось, мы выходим из цикла, что вызывает аварийное завершение процесса, который будет автоматически перезапущен демоном докер.
Основная мысль — брокер не занимается никакой бизнес-логикой, он только анализирует заголовок сообщения и раздаёт задания нитям-воркерам (workers), запущенным ранее при старте сервиса. В этом ему помогает единая очередь сообщений с приоритезацией фиксированной длины.
Разберём алгоритм на примере схемы и кода выше.
После старта нити-воркеры, которые стартовали позже брокера, инициализируются и отправляют брокеру сообщение о готовности. Брокер их принимает, анализирует и добавляет каждый воркер в список.
На клиентском сокете случается событие — мы получили message1. Брокер вызывает обработчик входящего сообщения, задачей которого является:
- анализ заголовка сообщения;
- помещение сообщения в объект-холдер с заданным приоритетом (на основе анализа заголовка) и временем жизни;
- помещение холдера в очередь сообщений;
- если очередь не переполнена, на этом задача обработчика закончена;
- если очередь переполнена, мы вызываем метод отправки клиенту сообщения об ошибке.
В этой же итерации цикла мы вызываем обработчик очереди сообщений:
- запрашиваем у очереди самое актуальное сообщение (очередь решает это сама на основе приоритета и порядка добавления сообщения);
- проверяем время жизни сообщения (если оно истекло, вызываем метод отправки клиенту сообщения об ошибке);
- если сообщение на обработку актуально, пытаемся получить первого свободного воркера, готового к работе;
- если таких нет, помещаем сообщение обратно в очередь (точнее, просто не удаляем его оттуда, оно будет болтаться там, пока не истечёт его время жизни);
- если готовый к работе воркер у нас есть, мы помечаем его как занятого и пересылаем ему сообщение на обработку;
- удаляем сообщение из очереди.
Таким же образом поступаем со всеми последующими сообщениями. Сама нить-воркер устроена точно также, как брокер — в ней крутится такой же бесконечный цикл обработки сообщений. Но в нём нам уже не требуется моментальная обработка, он предназначен для выполнения длительных заданий.
После того, как воркер выполнил своё задание (например, сходил в бэкенд за продуктами клиента или в тарантул – за сессией), он шлёт брокеру сообщение, которое брокер отсылает обратно клиенту. Адрес клиента, которому нужно отправить ответ, запоминается с самого прихода сообщения от клиента в объекте-холдере, который в виде сообщения немного другого формата отправляется воркеру, а потом возвращается назад.
Формат сообщений, которые я постоянно упоминаю, у нас собственного изготовления. Из коробки ZeroMQ предоставляет нам классы ZMsg — собственно сообщение, и ZFrame — составная часть этого сообщения, по сути просто массив байт, которую я волен использовать, если есть такое желание. Наше сообщение состоит из двух частей (двух ZFrame), первая из которых — бинарный заголовок, а вторая — данные (тело запроса, например, в виде json-строки, представленной массивом байт). Заголовок сообщения универсальный и ездит как от клиента к серверу, так и от сервера клиенту.
По сути, у нас нет понятия «запрос» или «ответ», только сообщения. Заголовок содержит в себе: версию протокола, тип системы (какой системе адресовано), тип сообщения, код ошибки транспортного уровня (если он не 0, то что-то случилось в движке передачи сообщений), ID запроса (сквозной идентификатор, приезжающий от клиента — нужен для трэйсинга), ID клиентской сессии (не обязателен), а также признак наличия ошибки уровня данных (например, если не удалось распарсить ответ бэкенда, мы ставим этот флаг, чтобы парсер на стороне клиента не занимался десериализацией ответа, а доставал данные об ошибке другим способом).
Благодаря единому протоколу между всеми микросервисами и такому заголовку, мы можем достаточно просто манипулировать составными частями наших сервисов. Например, можно вынести брокер в отдельный процесс и сделать из него единый брокер сообщений на уровне всей системы микросервисов. Или, например, запустить воркеры не в виде нитей внутри процесса, а в виде отдельных независимых процессов. И при этом код внутри них не изменится. В общем, есть простор для творчества.
Немного о производительности и ресурсах
Сам брокер работает быстро, а общая пропускная способность сервиса ограничена скоростью бэкенда и количеством воркеров. Удобно то, что всё необходимое количество памяти выделяется сразу при старте сервиса, а также сразу стартуют все нити. Размер очереди также фиксированный. В рантайме идёт работа только с сообщениями.
В качестве примера: наш текущий боевой сервис кэша кроме основной нити, запускает еще 100 нитей-воркеров, а размер очереди ограничен тремя тысячами сообщений. В обычном режиме работы каждый инстанс обрабатывает до 200 сообщений в секунду и потребляет около 250 МБ памяти и около 2-3% CPU. Иногда при пиковых нагрузках скачет до 7-8%. Работает это всё на каком-то двухъядерном виртуальном ксеоне.
Штатная работа сервиса подразумевает одновременную занятость 3-5 воркеров (из 100) при количестве сообщений в очереди 0 (то есть, в обработку они уходят сразу). Если вдруг бэкенд начинает тормозить, то количество занятых воркеров увеличивается пропорционально времени его отклика. В случаях, если случается авария и бэкенд встаёт, то сначала кончаются все воркеры, после чего начинает забиваться очередь сообщений. Когда она забьётся полностью, мы начинаем отвечать клиентам отказами в обработке. При этом мы не начинаем есть память или ресурсы CPU, стабильно отдавая метрики и внятно отвечая клиентам, что происходит.
На первом скриншоте представлена штатная работа сервиса.
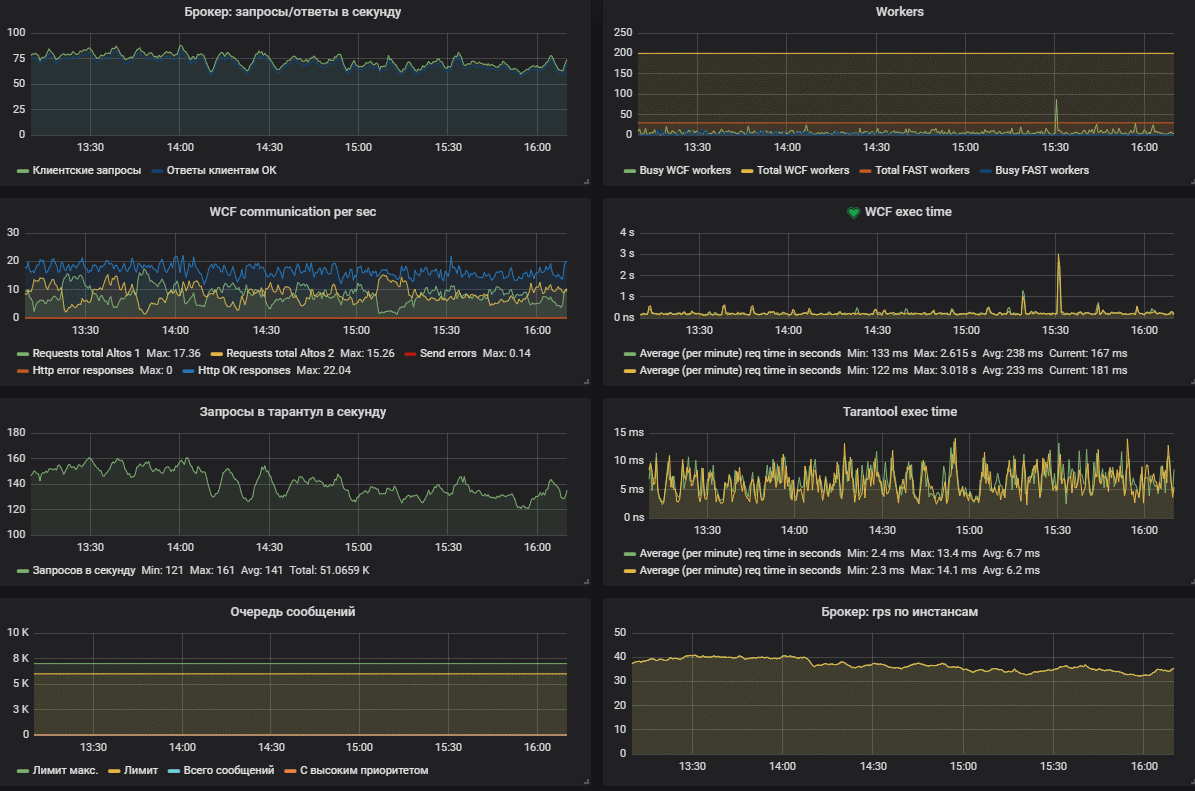
А на втором произошла авария — бэкэнд по какой-то причине не отвечал за 30 секунд. Видно, что сначала кончились все воркеры, после чего начала забиваться очередь сообщений.
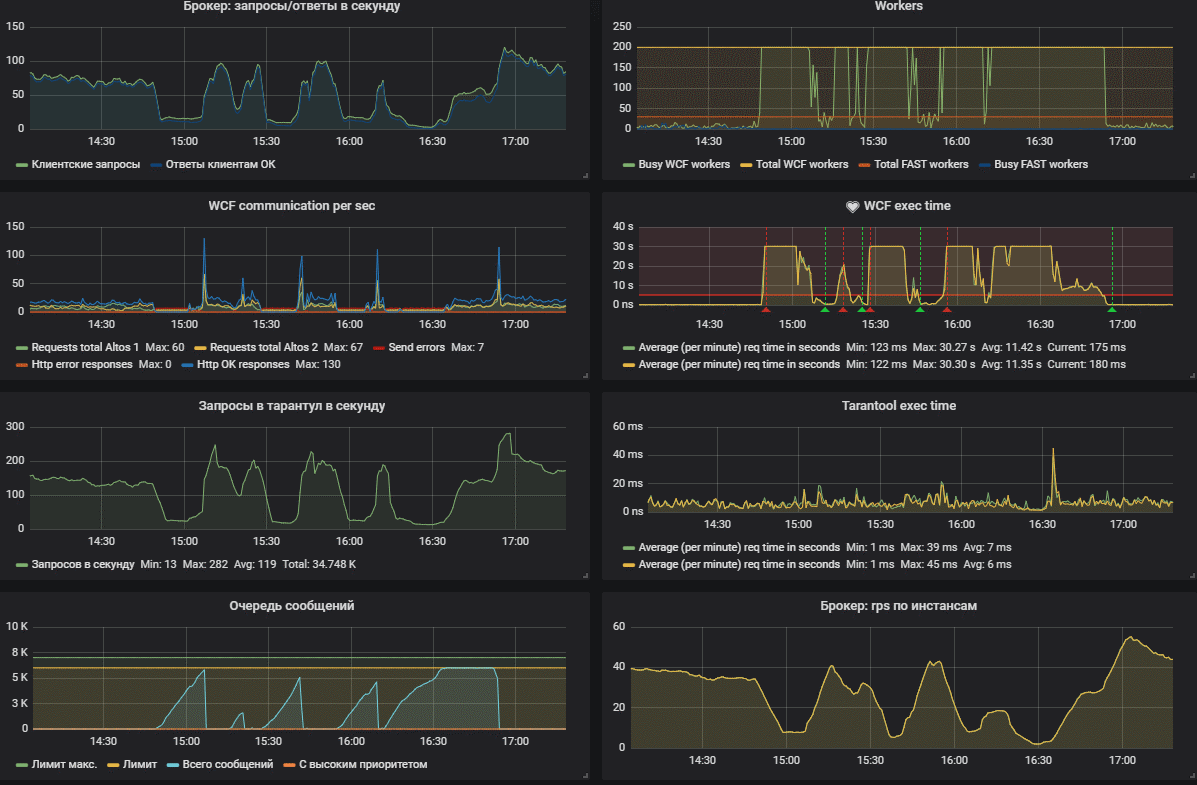
Тесты производительности
Синтетические тесты на моей рабочей машине (CentOS 7, Core i5, 16Gb RAM) показали следующее.
Работа с хранилищем (производилась запись в тарантул и сразу же чтение этой записи размером 100 байт — имитация работы с сессией) — 12000 rps.
Тоже самое, только скорость измерялась уже не между точками сервис — тарантул, а между клиентом и сервисом. Клиента для нагрузочного тестирования конечно пришлось писать самостоятельно. В пределах одной машины удалось получить 7000 rps. В локальной сети (а у нас много разных виртуальных машин непонятно как соединенных физически) результаты разнятся, но до 5000 rps к одному инстансу вполне получается. Не бог весть какая производительность, однако это более чем в десять раз покрывает наши пиковые нагрузки. И это только если работает один инстанс сервиса, но их у нас несколько, и в любой момент можно запустить ещё столько, сколько потребуется. Когда сервисы перекроют скорость работы хранилища, можно будет масштабировать тарантул горизонтально (шардить на основе ID клиента, например).
Умность сервиса
Внимательный читатель наверняка уже задаётся вопросом — а в чём же «умность» этого сервиса, о которой упоминается в заголовке. Вскользь я об этом уже упоминал, а сейчас расскажу подробнее.
Одной из основных задач сервиса являлось сокращение времени выдачи пользователям их продуктов (списки счетов, карт, вкладов, кредиты, пакеты услуг и так далее) при одновременном снижении нагрузки на бэкенд (уменьшении количества запросов в большой и тяжелый оракл) благодаря кэшированию в тарантуле.
И это у него вполне получилось. Логика прогрева клиентского кэша следующая:
- пользователь запускает мобильное приложение;
- на фронт-сервер идёт запрос AppStart, содержащий ID устройства;
- фронт-сервер отправляет сообщение с этим ID в кэш-сервис;
- сервис ищет в таблице устройств ID клиента по данному устройству;
- если его там нет, ничего не происходит (даже не отправляется ответ, сервер его не ждёт);
- если ID клиента находится, то воркер формирует набор сообщений на получение списков продуктов пользователя, которые сразу же попадают в обработку брокером и раздаются воркерам в обычном режиме;
- каждый воркер посылает запрос на получение определенного типа данных для пользователя, проставляя соответствующей записи в БД статус «updating» (этот статус защищает бэкенд от повторения таких же запросов, если они придут с других инстансов сервиса);
- после получения данных они записываются в тарантул;
- пользователь заходит в систему, и приложение шлёт запросы на получение его продуктов, а сервер пересылает эти запросы в виде сообщений в кэш-сервис;
- если данные пользователя уже получены, мы просто отдаём их из кэша;
- если данные находятся в процессе получения (статус «updating»), то внутри воркера запускается цикл ожидания данных (он равен таймауту запроса к бэкэнду);
- как только данные будут получены (то есть, статус этой записи (tuple) в таблице перейдет в «idle», сервис отдаст их клиенту;
- если данные не будут получены за определённый интервал времени, клиенту вернётся ошибка.
Таким образом, на практике нам удалось сократить среднее время получения продуктов для фронт-сервера с 200 мс до 20 мс, то есть, примерно в 10 раз, а количество запросов к бэкенду примерно в 4 раза.
Проблемы
Кэш-сервис работает на бою около двух лет и на текущий момент удовлетворяет нашим потребностям.
Конечно, остались еще нерешённые вопросы, иногда случаются проблемы. Java-сервисы на бою не падали еще ни разу. Тарантул пару раз падал по SIGSEGV, но то была какая-то старая версия, и после обновления это не повторялось. При нагрузочном тестировании у него отваливается репликация, на мастере случался broken pipe, после чего slave отваливался, хотя мастер продолжал работу. Решалось перезапуском slave.
Однажды случилась какая-то авария в дата-центре, и получилось так, что операционная система (CentOS 7) перестала видеть жесткие диски. Файловая система перешла в режим read-only. Самым удивительным оказалось то, что сервисы продолжили работу, так как все данные мы держим в памяти. Тарантул не мог писать .xlog файлы, никто ничего не логгировал, но как-то при этом все работали. Но попытка перезапуска оказалась безуспешной — стартовать никто не смог.
Есть одна большая нерёшенная задача, и мне хотелось бы послушать мнение сообщества на этот счёт. При падении тарантула-мастера, java-сервисы умеют переключаться на slave, который продолжает работать как мастер. Однако, это происходит только, если мастер падает и не может работать.
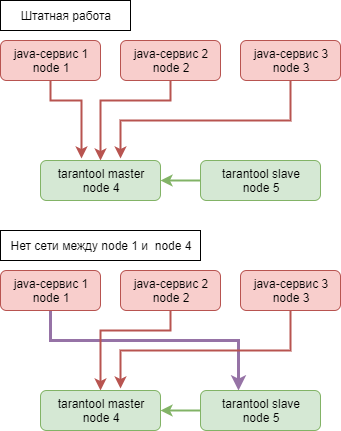
Допустим, у нас есть 3 инстанса сервиса, которые работают с данными на тарантуле мастер. Сами сервисы не падают, репликация БД идёт, всё хорошо. Но внезапно у нас разваливается сеть между node-1 и node-4, где работает мастер. Сервис-1 через какое-то количество неудачных попыток решает переключиться на резервную БД и начинает слать туда запросы.
Сразу после этого тарантул слэйв начинает принимать запросы на изменение данных, в результате этого репликация с мастера разваливается, и мы получаем неконсистентные данные. При этом, сервисы-2 и 3 отлично работают с мастером, а сервис-1 прекрасно общается с бывшим слэйвом. Понятно, что в этом случае мы начинаем терять клиентские сессии и любые другие данные, хотя с технической стороны всё работает. Вот такую потенциальную проблему мы пока не решили. К счастью, за 2 года такого еще не случалось, но ситуация вполне реальная. Сейчас каждый сервис знает номер хранилища, в которое он ходит, и на эту метрику у нас стоит алерт, который сработает при переключении с мастера на слэйв. И придётся чинить всё руками. А как вы решаете такие проблемы?
Планы
В планах у нас работа над вышеописанной проблемой, ограничение количества одновременно занятых одним типом запроса воркеров, безопасная (без потери текущих запросов) остановка сервиса и дальнейшая полировка.
Заключение
На этом, пожалуй, всё, хотя по теме я прошёлся довольно поверхностно, но общая логика работы должна быть понятна. Поэтому по возможности готов отвечать в комментариях. Я вкратце описал, как работает одна небольшая вспомогательная подсистема фронт-серверов банка, предназначенная для обслуживания мобильных клиентов.
Если тема будет интересна сообществу, то я могу рассказать еще о нескольких наших решениях, которые способствуют повышению качества обслуживания клиентов банка.
Комментарии (23)

alhimik45
12.11.2019 21:44Сразу после этого тарантул слэйв начинает принимать запросы на изменение данных, в результате этого репликация с мастера разваливается, и мы получаем неконсистентные данные.
А разве слейв не должен возвращать ошибку при попытке записать? Он ведь знает что он не мастер.

aromatov Автор
12.11.2019 22:12Да, он, в принципе, знает, что репликация развалилась, но на уровне логов ядра, а как получить такое событие в lua-скрипте, я не знаю. И вполне может при этом начать работать на запись данных, если индексы это позволяют. Ошибки есть только если дублирование по индексам происходит, но это не поможет решить нашу проблему.
alhimik45
12.11.2019 22:25По вашему описанию у кластера тарантула всё хорошо, это у одного из клиентов связь до мастера пропала. Что-то не понимаю тогда почему и в какой момент разваливается репликация у тарантула.
aromatov Автор
12.11.2019 22:40Всё правильно, им хорошо, они оба стали независимыми инстансами без репликации. Так как один из сервисов начал писать на слэйв, а слэйву ничего не мешает принимать запросы на добавление данных (больше того, так и было задумано), но возникают ошибки репликации, которые мы видим в логах ядра, после чего репликация разваливается. Ошибок именно на запись данных в lua-коде я не наблюдал, сервисы просто становятся назависимыми и продолжают работу.
alhimik45
12.11.2019 22:58слэйву ничего не мешает принимать запросы на добавление данных
Вроде как у реплик должно свойство read_only быть в true.
aromatov Автор
13.11.2019 07:21Тоже верно, но нам нужно, чтобы реплика становилась мастером, а делает это она, когда начинает принимать запросы на запись снаружи, как и было запланировано )
alhimik45
13.11.2019 10:56А почему клиенты решают, кто будет мастером? Это же должен делать сам тарантул на основе какого-то консенсуса о состоянии нод. Ну а если ни на стороне тарантула, ни на стороне клиента нет консенсуса о том, кто мастер, то очевидно при split-brain будет твориться всякая хрень.
aromatov Автор
13.11.2019 14:43А что делать приложению, которому надо работать, но база отвалилась? У него есть резервный адрес, куда можно ходить, и он туда идёт. Оно не знает, мастер там или не мастер.
alhimik45
13.11.2019 15:41Вспоминать CAP теорему). У вас не получится сделать консистентную и высокодоступную БД, которая не ломается от split brain.
Можно конечно повышать надежность сети как предложили ниже и надеяться что она не сломается — для неважных данных типа сессий это вполне решение. Но важные данные я бы не стал так хранить.aromatov Автор
13.11.2019 16:16+1Соглашусь, пожалуй. А для важных данных другие требования и другие решения нужны. Здесь важна в первую очередь скорость. Если бы надежность стояла на первом месте, я бы смотрел куда-нибудь в сторону кассандры, например, с фактором репликации 2 или 3.

dishar43
13.11.2019 16:07Вам нужны before_replace триггеры, в которых вы можете порешать конфликты репликации (через last write wins, например)
www.tarantool.io/en/doc/1.10/book/box/box_space/#box-space-before-replacearomatov Автор
13.11.2019 16:10Допустим, конфликты репликации я порешаю, но они — это следствие проблемы, а не причина. Один сервис так и будет писать в первый тарантул, а второй — в другой. Слэйв будет иметь все данные мастера, но мастер данных слэйва всё равно не получит.

baltazorbest
15.11.2019 18:41Вообще у тарантула есть мастер-мастер репликация. А слейву на самом деле нужно выставить read_only что бы при попытке записи в тарантул, тарантул возвращал ошибку и отправить вам алерт как минимум.
Но с мастер-мастер репликацией нужно быть аккуратным, так как словить duplicate primary key можно очень легко.
А так вам нужна некая промежуточная технология которая будет говорить вашим бэкендам кто сейчас мастер, тот же haproxy с неким чеком можно
То есть будет схема
Бэкенд — то что вы выбрали, выдало вам адрес текущего мастера — тарантул
Таким образом у всех бэкендов будет всегда один и тот же мастер.
Кстати если что, для haproxy тут есть пример как проверять доступностьaromatov Автор
15.11.2019 20:47Включал я мастер-мастер, когда идёт по 300 запросов в секунду, не успевает она. Особенно фигово, когда репликация разваливается, очень сложно потом хоть что-то поднять. Haproxy в работе использую, но не в данном случае. Может быть, стоит поэкспериментировать.
ggo
13.11.2019 10:02Обычно, когда требуется быстро решить проблемы с производительностью в legacy-приложении, по-быстрому прикручивают какой-нибудь кэш (пусть будет redis).
И после этого начинают потихоньку распиливать legacy на кусочки. А в кусочках уже используют все что считают полезным — очереди, хитрые стратегии распределения нагрузки, in-memory db и прочее.

ximik13
13.11.2019 11:35По вашей схеме работы видится два решения, которые могли бы помочь избежать проблем потери связи между node 1 и node 4.
1) Повышение отказоустойчивости самой сети между нодами с использованием агрегации физических интерфейсов серверов например по LACP и/или FSN (fail safe network) и т.п. С линками между нодами, поключенными в том числе через разные физические Ethernet свитчи, пусть даже и стекированные. Главное что бы потеря любого физического линка или целиком свитча не приводила к потере связи между нодами.
2) Использование дополнительного witness (tie-breaker) сервиса, стоящего "сбоку", который отслеживает насколько жив tarantool master (например опрашивая все ноды java-сервис, видят ли они мастер ноду tarantool) и на основании получаемых статусов переключал все ноды java-сервиса на slave или запрещал им это делать. Логику работы при той или иной аварии тут нужно подбирать. Например: если большинство нод java-сервис видит что tarantool master жив, то принудительно (временно) выводить из эксплуатации ноды потерявшие связь с мастером, на давая им переключится на slave. Или в обратной ситуации, когда мастер видит меньшинство принудительно всех переключать на slave tarantool. В общем логика срабатывания дискуссионный вопрос.aromatov Автор
13.11.2019 14:51Первый вариант вообще хорош, и кодить не нужно ) Вообще мы пока не поимели этой проблемы, а пока в разряде вероятных. Но меня беспокоит.
Второй вариант я обдумывал, но сервис «сбоку» точно также гипотетически может потерять только одну ноду, при том, что сами java-сервисы его будут нормально видеть. Как вариант, если мы примем допущение, что слэйв видит мастер, то он по факту начала приемов запросов на запись может послать запрос мастеру на прекращение работы. Однако здесь мы оказываемся в той же самой ситуации, что слэйв может потерять мастер. Мне кажется, что если ваш первый вариант дополнить грамотным размещением серверов с учетом топологии сети, то вероятность таких ошибок можно минимизировать. Но не исключить.ximik13
13.11.2019 15:05Идеала нет.
Со вторым вариантом важно что-бы и сами ноды знали, что есть witness и прежде чем куда-то переключатся нужно спросить у него, сам wintess может быть тоже распределенным сервисом с "авто-перевыборами" мастера при потере текущего. Логику работы нод в случае потери связи с каким либо компонентом, в том числе и с witness-сервисом, нужно тщательно продумывать. Сам witness не будет панацеей от всех проблем, но ряд возможных неприятностей позволит исключить. Ну и никто не мешает использовать оба варианта вместе, о чем я забыл упомянуть.aromatov Автор
13.11.2019 15:30Обвязка вокруг всего этого получается большая и сложная, сопоставимая по сложности с самим сервисом. А хочется чего-то такого, чтобы раз — и заработало. Хотя бы того, чтобы затраты окупились, ибо потеря клиентских сессий на короткий промежуток времени раз в год экономически выгоднее поддержки сложной инфраструктуры. Сейчас сервис по доступности вполне укладывается в 99,99%.
den_labs
Подскажите, rps по WCF по своим метрикам на графиках или есть из коробки?
Пытался понять, как это вывести для http-rest запросов из коробки, не понял…
aromatov Автор
Все метрики у нас свои, встроены в код через prometheus-агенты, которые есть для всех основных языков. На самих WCF у нас сделана рест-дырка, а на стороне java-сервиса используется Apache http client, подсчитать запросы которого обычным Counter от Prometheus не составляет труда.