
Прим. перев.: хотя этот обзор не претендует на статус тщательно проработанного технического сравнения существующих решений для постоянного хранения данных в Kubernetes, он может стать хорошей отправной точкой для администраторов, которым актуален данный вопрос. Наибольшего внимания здесь удостоилось решение Piraeus, знакомство с которым пойдет на пользу не только любителям Linstor, но и тем, кто об этих проектах ещё не слышал.

Это ненаучный обзор решений для хранения данных для Kubernetes. Постановка задачи: требуется возможность создания Persistent Volume на дисках узла, данные которого будут сохранны в случае повреждения или перезапуска узла.
Мотивация для проведения этого сравнения — потребность миграции серверного парка компании со множества выделенных bare metal-серверов в кластер Kubernetes.
Моя компания — стартап Escavador из Бразилии с огромными потребностями в вычислительной мощности (преимущественно в CPU) и весьма ограниченным бюджетом. Мы разрабатываем решения в области NLP для структурирования юридических данных.
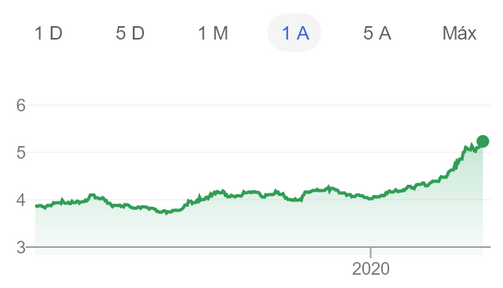
Из-за кризиса с COVID-19 бразильский реал подешевел до рекордно низкого уровня по отношению к доллару США
Наша национальная валюта на самом деле очень недооценена, поэтому средняя зарплата старшего разработчика составляет всего 2000 USD в месяц. Таким образом, мы не можем позволить себе роскошь тратить значительные средства на облачные сервисы. Когда я проводил расчеты в последний раз, [благодаря использованию своих серверов] мы экономили 75 % в сравнении с тем, что пришлось бы заплатить за AWS. Другими словами, на сэкономленные деньги можно нанять еще одного разработчика — думаю, что это гораздо более рациональное использование средств.
Вдохновленный серией публикаций от Vito Botta, я решил создать кластер K8s с помощью Rancher (и с ним пока всё хорошо…). Vito также провел отличный анализ различных решений для хранения. Явным победителем оказался Linstor (он даже выделил его в особую лигу). Спойлер: я с ним согласен.
В течение некоторого времени я слежу за движением вокруг Kubernetes, но только недавно решил поучаствовать в нем. Связано это в первую очередь с тем, что у используемого провайдера появилась новая линейка процессоров Ryzen. И тогда я сильно удивился, увидев, что многие решения до сих пор находятся в разработке или незрелом состоянии (особенно это касается кластеров на bare metal: виртуализация VM, MetalLB и т.д.). Хранилища на bare metal всё ещё пребывают в стадии созревания, хоть и представлены множеством коммерческих и Open Source-решений. Я решил сравнить основные перспективные и бесплатные решения (попутно протестировав один коммерческий продукт, чтобы понять, чего лишаюсь).

Спектр решений для хранения в CNCF Landscape
Но прежде всего хочу предупредить, что являюсь новичком в области K8s.
Для экспериментов использовались 4 worker'a со следующей конфигурацией: процессор Ryzen 3700X, 64 GB памяти ECC, NVMe размером 2 TB. Бенчмарки делались с помощью образа
Longhorn мне очень понравился. Он полностью интегрирован с Rancher и установить его через Helm можно одним кликом.
Установка Longhorn из Rancher
Это инструмент с открытым исходным кодом и статусом sandbox-проекта от Cloud Native Computing Foundation (CNCF). Его разработку финансирует Rancher — довольно успешная компания с известным [одноименным] продуктом.
Также доступен отличный графический интерфейс — все можно делать из него. С производительностью все в порядке. Проект пока находится на бета-стадии, что подтверждают issues на GitHub.
При тестировании я запустил бенчмарк с использованием 2 реплик и Longhorn 0.8.0:
Этот проект также имеет статус sandbox от CNCF. С большим числом звезд на GitHub он выглядит вполне перспективным решением. В своем обзоре Vito Botta пожаловался на недостаточную производительность. Вот что ему на это ответил гендиректор Mayadata:
На странице проекта OpenEBS есть такое пояснение по его статусу:
У него есть множество движков, и последний из них представляется довольно перспективным в плане производительности: «MayaStor — alpha engine with NVMe over Fabrics». Увы, я не стал его тестировать из-за статуса альфа-версии.
В тестах же использовалась версия 1.8.0 на движке jiva. Кроме того, ранее я проверял и cStor, но не сохранял результаты, которые, впрочем, оказались чуть медленнее jiva. Для бенчмарка был установлен Helm-чарт со всеми настройками по умолчанию и использовался Storage Class, стандартно созданный Helm'ом (
OpenEBS 1.8.0 с движком jiva (3 реплики?):
Дополнение от переводчика. Эти результаты прокомментировал Evan Powell, возглавляющий проект OpenEBS (также он известен тем, что ранее основал StackStorm и Nexenta):
Это коммерческое решение, которое бесплатно при использовании до 110 ГБ пространства. Бесплатную лицензию (Developer license) можно получить, зарегистрировавшись через пользовательский интерфейс продукта; она дает до 500 ГБ пространства. В Rancher'е оно значится как партнерское, поэтому установка с помощью Helm'а прошла легко и беззаботно.
Пользователю предлагается базовая контрольная панель. Тестирование этого продукта было ограниченным, поскольку он является коммерческим и по своей стоимости нам не подходит. Но все равно хотелось поглядеть, на что способны коммерческие проекты.
В тесте задействован имеющийся Storage Class под названием «Fast» (Template 0.2.19, 1 Master + 0 Replica?). Результаты поразили. Они значительно превзошли предыдущие решения.
Лицензия: GPLv3
Уже упомянутый Vito Botta в конечном итоге остановился именно на Linstor, что стало дополнительным поводом попробовать это решение. На первый взгляд, проект выглядит довольно странно. Почти нет звезд на GitHub, необычное название и его даже нет на CNCF Landscape. Но при ближайшем рассмотрении все оказывается не так страшно, поскольку:
Окей, проект выглядит достаточно убедительно, чтобы доверить ему свои драгоценные данные. Но способен ли он переиграть альтернативы? Давайте посмотрим.
Vito рассказывает об установке Linstor здесь. Однако в комментариях один из разработчиков Linstor рекомендует новый проект под названием Piraeus. Насколько я понял, Piraeus становится Open Source-проектом Linbit, который объединяет в себе всё связанное с K8s. Команда работает над соответствующим оператором, а пока Piraeus можно установить с помощью этого YAML-файла:
Внимание! Вы забираете конфиги из моего личного репозитория. Проверьте официальный репозиторий! Я обновил версии образов, чтобы решить ошибку, возникающую при использовании в Ubuntu.
Официальный репозиторий Piraeus доступен здесь.
Также можно воспользоваться репозиторием от kvaps (он кажется даже более динамичным, чем официальный репозиторий piraeus): https://github.com/kvaps/kube-linstor (пользуясь случаем, передаем привет Андрею kvaps — прим. перев.).
Все узлы работают после установки
Администрирование осуществляется с помощью командной строки. Доступ к ней возможен из командной оболочки узла piraeus-controller.

На controller-узле запущен linstor-server. Он представляет собой слой абстракции над drbd, способный управлять всем парком узлов. На скриншоте ниже приведены некоторые полезные команды для наиболее востребованных задач, например:

Команды Linstor
Полный список команд доступен в официальной документации: User´s Guide LINSTOR.
В случае возникновения ситуаций вроде split brain доступ к drbd можно получить непосредственно через узлы.
Я изо всех сил старался уронить свой кластер, в том числе делал hard reset'ы на узлах. Но linstor оказался удивительно живуч.
Drbd отлично распознает проблему, называемую split brain. В моей ситуации вторичный узел выпал из репликации.
Подробности можно почерпнуть из официальной документации drbd.

Вторичный узел выпал из репликации
В моем случае для решения проблемы я отбросил вторичные данные и запустил синхронизацию с primary-узлом. Поскольку предпочитаю графические интерфейсы, воспользовался для этого утилитой drbdtop. С ее помощью можно визуально контролировать состояние и выполнять команды внутри узлов.
Мне понадобилось зайти в консоль на проблемном узле piraues (им был

Заходим на узел
Там я установил drdbtop. Скачать эту утилиту можно здесь:

Работающая утилита drbdtop
Взгляните на нижнюю панель. На ней расположены команды, с помощью которых можно исправить split brain:

После это узлы подключаются и синхронизируются автоматически.
По умолчанию Piraeus/Linstor/drbd демонстрируют отличную производительность (в этом вы можно убедиться ниже). Настройки по умолчанию разумны и безопасны. Однако скорость записи оказалась слабовата. Поскольку серверы в моем случае разбросаны по разным ЦОД (хотя и физически они находятся сравнительно недалеко), я решил попробовать подстроить их производительность.
Отправной пункт оптимизации — определение протокола репликации. По умолчанию используется Protocol C, предусматривающий ожидание подтверждения записи на удаленном вторичном узле. Ниже приведено описание возможных протоколов:
Из-за этого в Linstor я также использую асинхронный протокол (он поддерживает синхронную/полусинхронную/асинхронную репликацию). Включить его можно следующей командой:
Результатом ее выполнения станет активация асинхронного протокола и увеличение буфера до 1 Мб. Это относительно безопасно. Или можно использовать следующую команду (она игнорирует сбросы на диск и значительно увеличивает буфер):
Учтите, что при выходе из строя первичного узла небольшая часть данных может не дойти до реплик.
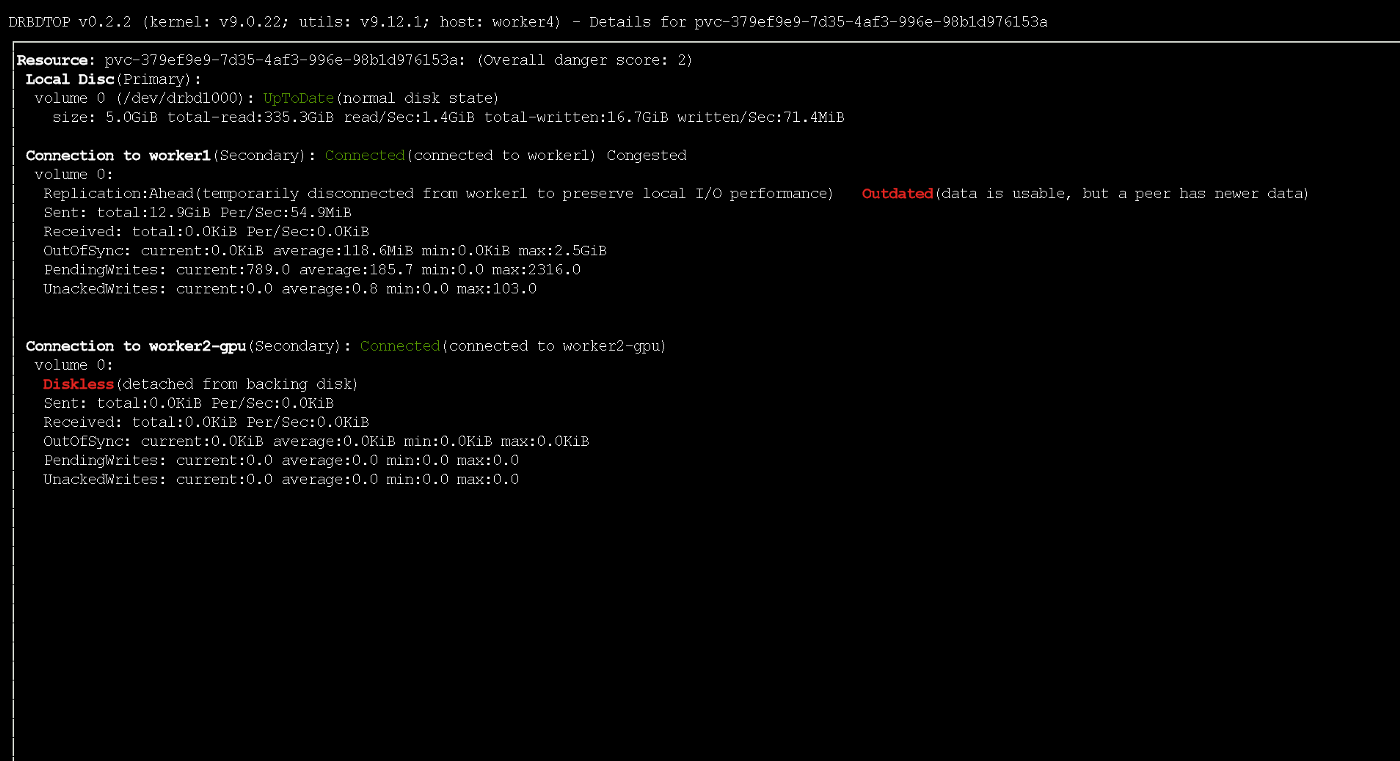
Во время активной записи узел временно получил статус outdated при использовании протокола ASYNC
Все бенчмарки проводились с использованием следующей Job:
Задержка между машинами составляет:
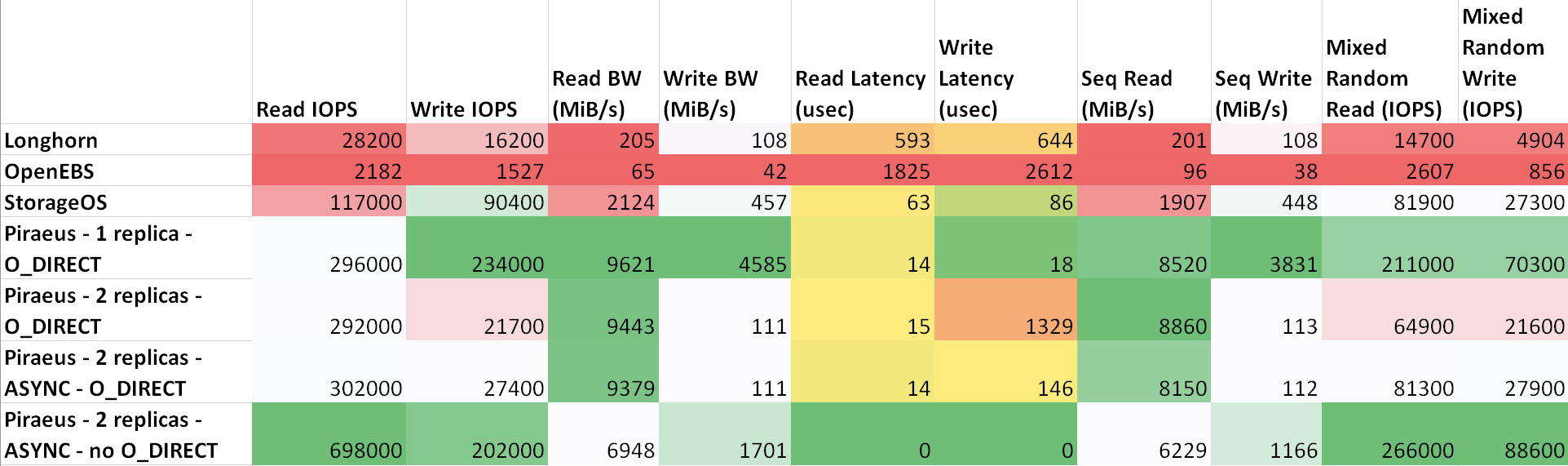
Результаты (таблица на sheetsu.com)
Как видно из таблицы, лучшие результаты показали Piraeus и StorageOS. Лидером стал Piraeus с двумя репликами и асинхронным протоколом.
Я провел простое и, возможно, не слишком корректное сравнение некоторых решений для хранения в Kubernetes.
Больше всего мне понравился Longhorn из-за его приятного графического интерфейса и интеграции с Rancher. Однако результаты не вдохновляют. Очевидно, разработчики в первую очередь фокусируются на безопасности и корректности, оставив скорость на потом.
Уже некоторое время я использую Linstor/Piraeus в production-средах некоторых проектов. До сих пор все было отлично: диски создавались и удалялись, узлы перезапускались без простоев…
По моему мнению, Piraeus вполне готов к использованию в production, но нуждается в доработке. О некоторых багах написал в канал проекта в Slack'e, но в ответ мне только посоветовали подучить Kubernetes (и это правильно, поскольку я еще плохо в нем разбираюсь). После небольшой переписки мне все же удалось убедить авторов, что в их init-скрипте есть баг. Вчера, после обновления ядра и перезагрузки, узел отказался загружаться. Оказалось, что компиляция скрипта, который интегрирует модуль drbd в ядро, завершилась неудачно. Проблему решил откат к предыдущей версии ядра.
Вот, в общем, и все. Учитывая, что они реализовали его поверх drbd, получилось очень надежное решение с отличной производительностью. В случае возникновения каких-либо проблем можно напрямую обратиться к управлению drbd и все исправить. В интернете есть множество вопросов и примеров по данной теме.
Если я сделал что-то не так, если что-то можно улучшить или вам требуется помощь, обращайтесь ко мне в Twitter или на GitHub.
Читайте также в нашем блоге:
Это ненаучный обзор решений для хранения данных для Kubernetes. Постановка задачи: требуется возможность создания Persistent Volume на дисках узла, данные которого будут сохранны в случае повреждения или перезапуска узла.
Мотивация для проведения этого сравнения — потребность миграции серверного парка компании со множества выделенных bare metal-серверов в кластер Kubernetes.
Моя компания — стартап Escavador из Бразилии с огромными потребностями в вычислительной мощности (преимущественно в CPU) и весьма ограниченным бюджетом. Мы разрабатываем решения в области NLP для структурирования юридических данных.
Из-за кризиса с COVID-19 бразильский реал подешевел до рекордно низкого уровня по отношению к доллару США
Наша национальная валюта на самом деле очень недооценена, поэтому средняя зарплата старшего разработчика составляет всего 2000 USD в месяц. Таким образом, мы не можем позволить себе роскошь тратить значительные средства на облачные сервисы. Когда я проводил расчеты в последний раз, [благодаря использованию своих серверов] мы экономили 75 % в сравнении с тем, что пришлось бы заплатить за AWS. Другими словами, на сэкономленные деньги можно нанять еще одного разработчика — думаю, что это гораздо более рациональное использование средств.
Вдохновленный серией публикаций от Vito Botta, я решил создать кластер K8s с помощью Rancher (и с ним пока всё хорошо…). Vito также провел отличный анализ различных решений для хранения. Явным победителем оказался Linstor (он даже выделил его в особую лигу). Спойлер: я с ним согласен.
В течение некоторого времени я слежу за движением вокруг Kubernetes, но только недавно решил поучаствовать в нем. Связано это в первую очередь с тем, что у используемого провайдера появилась новая линейка процессоров Ryzen. И тогда я сильно удивился, увидев, что многие решения до сих пор находятся в разработке или незрелом состоянии (особенно это касается кластеров на bare metal: виртуализация VM, MetalLB и т.д.). Хранилища на bare metal всё ещё пребывают в стадии созревания, хоть и представлены множеством коммерческих и Open Source-решений. Я решил сравнить основные перспективные и бесплатные решения (попутно протестировав один коммерческий продукт, чтобы понять, чего лишаюсь).
Спектр решений для хранения в CNCF Landscape
Но прежде всего хочу предупредить, что являюсь новичком в области K8s.
Для экспериментов использовались 4 worker'a со следующей конфигурацией: процессор Ryzen 3700X, 64 GB памяти ECC, NVMe размером 2 TB. Бенчмарки делались с помощью образа
sotoaster/dbench:latest (на fio) с флагом O_DIRECT.Longhorn
- Лицензия: Apache 2
- Коммерческая поддержка: Rancher
- URL: github.com/longhorn/longhorn
- Звезды на GitHub: 1,3 тыс.
Longhorn мне очень понравился. Он полностью интегрирован с Rancher и установить его через Helm можно одним кликом.
Установка Longhorn из Rancher
Это инструмент с открытым исходным кодом и статусом sandbox-проекта от Cloud Native Computing Foundation (CNCF). Его разработку финансирует Rancher — довольно успешная компания с известным [одноименным] продуктом.
Также доступен отличный графический интерфейс — все можно делать из него. С производительностью все в порядке. Проект пока находится на бета-стадии, что подтверждают issues на GitHub.
При тестировании я запустил бенчмарк с использованием 2 реплик и Longhorn 0.8.0:
- Случайное чтение/запись, IOPS: 28.2k / 16.2k;
- Пропускная способность чтения/записи: 205 Мб/с / 108 Мб/с;
- Средняя задержка чтения/записи (usec): 593.27 / 644.27;
- Последовательное чтение/запись: 201 Мб/с / 108 Мб/с;
- Смешанное случайное чтение/запись, IOPS: 14.7k / 4904.
OpenEBS
- Лицензия: Apache 2
- Коммерческая поддержка: несколько компаний(?); mayadata.io представляется самой большой
- URL: github.com/openebs/openebs
- Звезды на GitHub: 6 тыс.
Этот проект также имеет статус sandbox от CNCF. С большим числом звезд на GitHub он выглядит вполне перспективным решением. В своем обзоре Vito Botta пожаловался на недостаточную производительность. Вот что ему на это ответил гендиректор Mayadata:
Информация сильно устарела. OpenEBS раньше поддерживал 3, а сейчас поддерживает 4 движка, если включить динамическое обеспечение и оркестрацию localPV, которая может работать на скоростях NVMe. Вдобавок, движок MayaStor теперь открыт и уже получает положительные отзывы (хотя и имеет альфа-статус).
На странице проекта OpenEBS есть такое пояснение по его статусу:
OpenEBS — одна из наиболее широко используемых и проверенных инфраструктур для хранения данных под Kubernetes. OpenEBS приобрела статус sandbox-проекта CNCF в мае 2019-го и является первой и единственной системой хранения, обеспечивающей согласованный набор программно-определяемых возможностей на различных бэкендах (local, nfs, zfs, nvme) как в on-premise, так и в облачных системах. OpenEBS первой открыла свой фреймворк для хаос-инжиниринга под stateful-нагрузки — Litmus Project, — который позволяет сообществу автоматически проверять на готовность ежемесячные обновления OpenEBS. Корпоративные клиенты используют OpenEBS в production с 2018 года; еженедельно выполняется более 2,5 млн docker pull'ов.
У него есть множество движков, и последний из них представляется довольно перспективным в плане производительности: «MayaStor — alpha engine with NVMe over Fabrics». Увы, я не стал его тестировать из-за статуса альфа-версии.
В тестах же использовалась версия 1.8.0 на движке jiva. Кроме того, ранее я проверял и cStor, но не сохранял результаты, которые, впрочем, оказались чуть медленнее jiva. Для бенчмарка был установлен Helm-чарт со всеми настройками по умолчанию и использовался Storage Class, стандартно созданный Helm'ом (
openebs-jiva-default). Производительность оказалась самой плохой из всех рассматриваемых решений (буду признателен за советы по ее повышению).OpenEBS 1.8.0 с движком jiva (3 реплики?):
- Случайное чтение/запись, IOPS: 2182 / 1527;
- Пропускная способность чтения/записи: 65.0 Мб/с / 41.9 Мб/с;
- Средняя задержка чтения/записи (usec): 1825.49 / 2612.87;
- Последовательное чтение/запись: 95.5 Мб/с / 37.8 Мб/с;
- Смешанное случайное чтение/запись, IOPS: 2607 / 856.
Дополнение от переводчика. Эти результаты прокомментировал Evan Powell, возглавляющий проект OpenEBS (также он известен тем, что ранее основал StackStorm и Nexenta):
Спасибо за проделанную работу, Bruno! Мы немного не согласны с выводами по сравнению OpenEBS с альтернативами. Был использован движок Jiva, который в основном применяется на ARM или схожих конфигурациях для минимального overhead'а и простоты. Клиенты же вроде Bloomberg предпочитают работать с DynamicLocal PV от OpenEBS. Такой же подход рекомендуется ребятами вроде Elastic и для других рабочих нагрузок, требующих отказоустойчивости. К слову, всеми движками можно управлять всегда бывшим бесплатным OpenEBS Director (https://account.mayadata.io/signup). В любом случае — спасибо за обзор и надеюсь, что мы останемся на связи.
StorageOS
- Лицензия: коммерческая
- URL: storageos.com
Это коммерческое решение, которое бесплатно при использовании до 110 ГБ пространства. Бесплатную лицензию (Developer license) можно получить, зарегистрировавшись через пользовательский интерфейс продукта; она дает до 500 ГБ пространства. В Rancher'е оно значится как партнерское, поэтому установка с помощью Helm'а прошла легко и беззаботно.
Пользователю предлагается базовая контрольная панель. Тестирование этого продукта было ограниченным, поскольку он является коммерческим и по своей стоимости нам не подходит. Но все равно хотелось поглядеть, на что способны коммерческие проекты.
В тесте задействован имеющийся Storage Class под названием «Fast» (Template 0.2.19, 1 Master + 0 Replica?). Результаты поразили. Они значительно превзошли предыдущие решения.
- Случайное чтение/запись, IOPS: 117k / 90.4k;
- Пропускная способность чтения/записи: 2124 Мб/с / 457 Мб/с;
- Средняя задержка чтения/записи (usec): 63.44 / 86.52;
- Последовательное чтение/запись: 1907 Мб/с / 448 Мб/с;
- Смешанное случайное чтение/запись, IOPS: 81.9k / 27.3k.
Piraeus (основан на Linstor)
Лицензия: GPLv3
- Коммерческая поддержка: LINBIT
- URL: github.com/piraeusdatastore/piraeus
- Основан на: github.com/LINBIT/linstor-server
- Звезды на GitHub: менее 100 (не скупитесь, поставьте звездочку проекту!)
Уже упомянутый Vito Botta в конечном итоге остановился именно на Linstor, что стало дополнительным поводом попробовать это решение. На первый взгляд, проект выглядит довольно странно. Почти нет звезд на GitHub, необычное название и его даже нет на CNCF Landscape. Но при ближайшем рассмотрении все оказывается не так страшно, поскольку:
- В качестве базового механизма репликации используется DRBD (на самом деле, он разработан теми же людьми). При этом DRBD 8.x уже более 10 лет входит в состав официального ядра Linux. И мы говорим о технологии, которая оттачивается более 20 лет.
- Носителями управляет LINSTOR — также зрелая технология от той же компании. Первая версия Linstor-server появилась на GitHub в феврале 2018-го. Она совместима с различными технологиями/системами, такими как Proxmox, OpenNebula и OpenStack.
- По всей видимости, Linbit активно развивает проект, постоянно внедряет в него новые функции и улучшения. 10-я версия DRBD пока имеет альфа-статус, но уже может похвастаться некоторыми уникальными возможностями, такими как erasure coding (аналог функциональности из RAID5/6 — прим. перев.).
- Компания предпринимает определенные меры, чтобы попасть в число проектов CNCF.
Окей, проект выглядит достаточно убедительно, чтобы доверить ему свои драгоценные данные. Но способен ли он переиграть альтернативы? Давайте посмотрим.
Установка
Vito рассказывает об установке Linstor здесь. Однако в комментариях один из разработчиков Linstor рекомендует новый проект под названием Piraeus. Насколько я понял, Piraeus становится Open Source-проектом Linbit, который объединяет в себе всё связанное с K8s. Команда работает над соответствующим оператором, а пока Piraeus можно установить с помощью этого YAML-файла:
kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yamlВнимание! Вы забираете конфиги из моего личного репозитория. Проверьте официальный репозиторий! Я обновил версии образов, чтобы решить ошибку, возникающую при использовании в Ubuntu.
Официальный репозиторий Piraeus доступен здесь.
Также можно воспользоваться репозиторием от kvaps (он кажется даже более динамичным, чем официальный репозиторий piraeus): https://github.com/kvaps/kube-linstor (пользуясь случаем, передаем привет Андрею kvaps — прим. перев.).
Все узлы работают после установки
Администрирование
Администрирование осуществляется с помощью командной строки. Доступ к ней возможен из командной оболочки узла piraeus-controller.
На controller-узле запущен linstor-server. Он представляет собой слой абстракции над drbd, способный управлять всем парком узлов. На скриншоте ниже приведены некоторые полезные команды для наиболее востребованных задач, например:
-
linstor node list— вывести список подключенных узлов и их статус; -
linstor volume list— показать список созданных томов и их местоположение; -
linstor node info— показать возможности каждого узла.
Команды Linstor
Полный список команд доступен в официальной документации: User´s Guide LINSTOR.
В случае возникновения ситуаций вроде split brain доступ к drbd можно получить непосредственно через узлы.
Восстановление после сбоев
Я изо всех сил старался уронить свой кластер, в том числе делал hard reset'ы на узлах. Но linstor оказался удивительно живуч.
Drbd отлично распознает проблему, называемую split brain. В моей ситуации вторичный узел выпал из репликации.
Split brain — это ситуация, когда из-за временного сбоя сетевых подключений между узлами кластера, вмешательства ПО для управления кластером или из-за человеческой ошибки оба узла становятся Primary, находясь в «оторванном» состоянии. Опасность этого состояния в том, что измененные данные на любом из узлов не будут реплицированы на другой. Другими словами, могут возникнуть два расходящихся набора данных, которые невозможно объединить тривиальным образом.
Split brain в DRBD отличается от кластерного, который означает потерю связности хостов, управляемых распределенным ПО для управления кластером вроде Heartbeat.
Подробности можно почерпнуть из официальной документации drbd.
Вторичный узел выпал из репликации
В моем случае для решения проблемы я отбросил вторичные данные и запустил синхронизацию с primary-узлом. Поскольку предпочитаю графические интерфейсы, воспользовался для этого утилитой drbdtop. С ее помощью можно визуально контролировать состояние и выполнять команды внутри узлов.
Мне понадобилось зайти в консоль на проблемном узле piraues (им был
worker2-gpu):Заходим на узел
Там я установил drdbtop. Скачать эту утилиту можно здесь:
wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64Работающая утилита drbdtop
Взгляните на нижнюю панель. На ней расположены команды, с помощью которых можно исправить split brain:
После это узлы подключаются и синхронизируются автоматически.
Как повысить скорость?
По умолчанию Piraeus/Linstor/drbd демонстрируют отличную производительность (в этом вы можно убедиться ниже). Настройки по умолчанию разумны и безопасны. Однако скорость записи оказалась слабовата. Поскольку серверы в моем случае разбросаны по разным ЦОД (хотя и физически они находятся сравнительно недалеко), я решил попробовать подстроить их производительность.
Отправной пункт оптимизации — определение протокола репликации. По умолчанию используется Protocol C, предусматривающий ожидание подтверждения записи на удаленном вторичном узле. Ниже приведено описание возможных протоколов:
- Protocol A — протокол асинхронной репликации. Локальные операции записи на первичном узле считаются завершенными, как только произошла запись на локальный диск, а репликационный пакет был помещен в локальный TCP-буфер на отправку. Важный нюанс заключается в том, что буфер отправки TCP ОЧЕНЬ мал. Его можно увеличить до определенного предела.
- Protocol B — протокол полусинхронной репликации. Локальные операции записи на первичном узле считаются завершенными, как только произошла запись на локальный диск, а репликационный пакет дошел до другого узла.
- Protocol C (по умолчанию) — протокол синхронной репликации. Локальная операция на первичном узле считается завершенной только после подтверждения записи на локальный и удаленный диски.
Из-за этого в Linstor я также использую асинхронный протокол (он поддерживает синхронную/полусинхронную/асинхронную репликацию). Включить его можно следующей командой:
linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576Результатом ее выполнения станет активация асинхронного протокола и увеличение буфера до 1 Мб. Это относительно безопасно. Или можно использовать следующую команду (она игнорирует сбросы на диск и значительно увеличивает буфер):
linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576Учтите, что при выходе из строя первичного узла небольшая часть данных может не дойти до реплик.
Во время активной записи узел временно получил статус outdated при использовании протокола ASYNC
Тестирование
Все бенчмарки проводились с использованием следующей Job:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4Задержка между машинами составляет:
ttl=61 time=0.211 ms. Измеренная пропускная способность между ними составила 943 Мбит/с. Все узлы работают под управлением Ubuntu 18.04.Результаты (таблица на sheetsu.com)
Как видно из таблицы, лучшие результаты показали Piraeus и StorageOS. Лидером стал Piraeus с двумя репликами и асинхронным протоколом.
Выводы
Я провел простое и, возможно, не слишком корректное сравнение некоторых решений для хранения в Kubernetes.
Больше всего мне понравился Longhorn из-за его приятного графического интерфейса и интеграции с Rancher. Однако результаты не вдохновляют. Очевидно, разработчики в первую очередь фокусируются на безопасности и корректности, оставив скорость на потом.
Уже некоторое время я использую Linstor/Piraeus в production-средах некоторых проектов. До сих пор все было отлично: диски создавались и удалялись, узлы перезапускались без простоев…
По моему мнению, Piraeus вполне готов к использованию в production, но нуждается в доработке. О некоторых багах написал в канал проекта в Slack'e, но в ответ мне только посоветовали подучить Kubernetes (и это правильно, поскольку я еще плохо в нем разбираюсь). После небольшой переписки мне все же удалось убедить авторов, что в их init-скрипте есть баг. Вчера, после обновления ядра и перезагрузки, узел отказался загружаться. Оказалось, что компиляция скрипта, который интегрирует модуль drbd в ядро, завершилась неудачно. Проблему решил откат к предыдущей версии ядра.
Вот, в общем, и все. Учитывая, что они реализовали его поверх drbd, получилось очень надежное решение с отличной производительностью. В случае возникновения каких-либо проблем можно напрямую обратиться к управлению drbd и все исправить. В интернете есть множество вопросов и примеров по данной теме.
Если я сделал что-то не так, если что-то можно улучшить или вам требуется помощь, обращайтесь ко мне в Twitter или на GitHub.
P.S. от переводчика
Читайте также в нашем блоге: