

Продолжая цикл заметок про реальные проблемы в Data Science, мы сегодня разберемся с живой задачей и посмотрим, какие проблемы нас ждут в пути.
Например, помимо Data Science, я давно увлекаюсь атлетикой и одной из целей в беге для меня, конечно, является марафон. А где марафон там и вопрос — за сколько же бежать? Часто ответ на этот вопрос дается на глаз — «ну в среднем бегут» или «вот Х хорошее время»!
И сегодня мы займемся важным делом — применим Data Science в реальной жизни и ответим на вопрос:
А что нам говорят данные о московском марафоне?
Точнее, как уже понятно по таблице в начале — мы соберем данные, разберемся, кто и как бежал. А заодно это поможет понять, стоит ли нам соваться и позволит здраво оценить свои силы!
TL;DR: Я собрал данные по забегам московского марафона за 2018/2019, проанализиворовал время и показатели участников, а код и данные выложил в открытый доступ.
Сбор данных
Путем шустрого гугления мы обнаружили результаты прошлых пары лет, 2019 и 2018 годов.
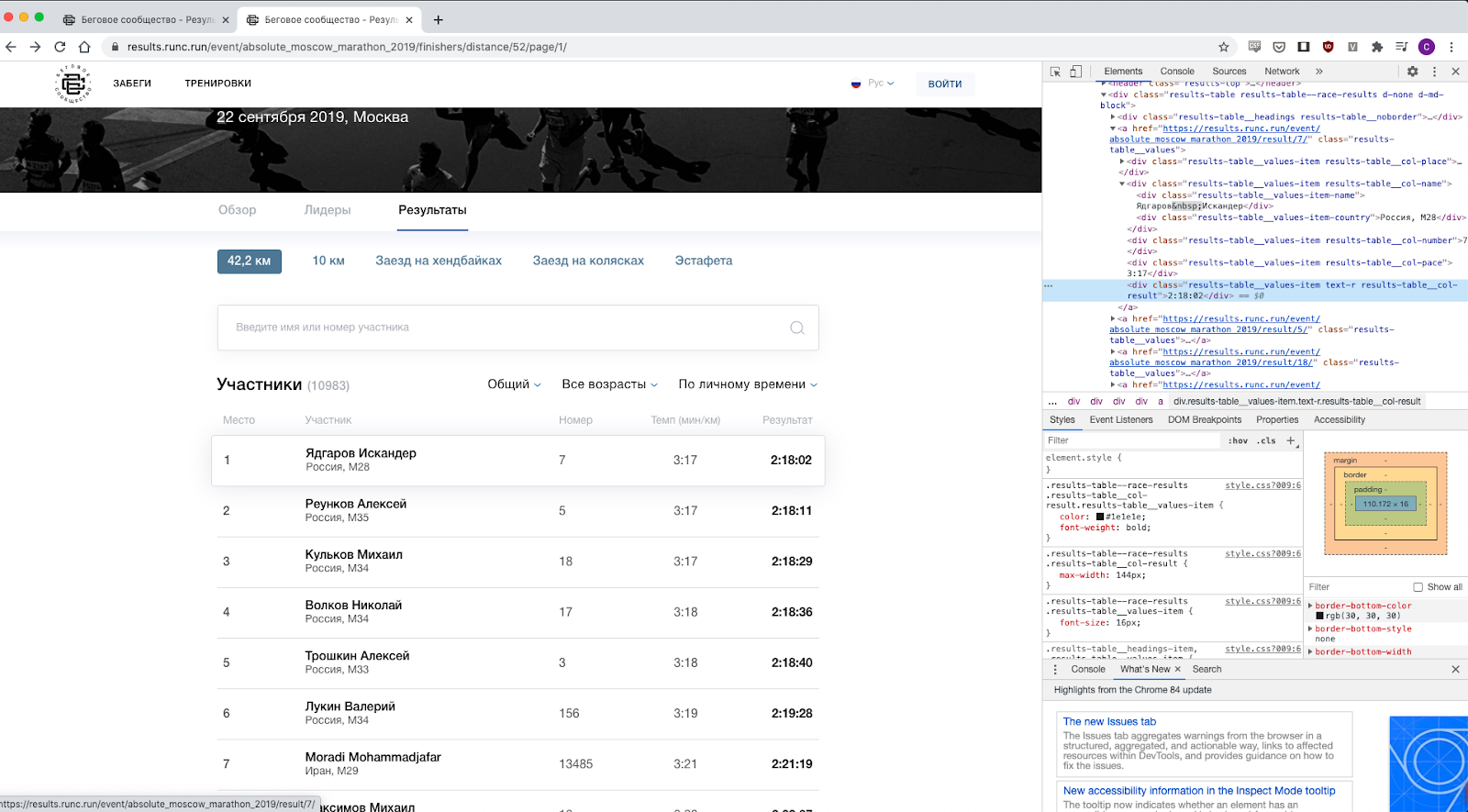
Внимательно посмотрел на веб страницу, стало понятно, что данные довольно просто достать — нужно лишь разобраться, какие классы за что отвечают, например, класс “results-table__col-result”, понятное дело, за результат и тд.
Осталось понять — как достать все данные оттуда.
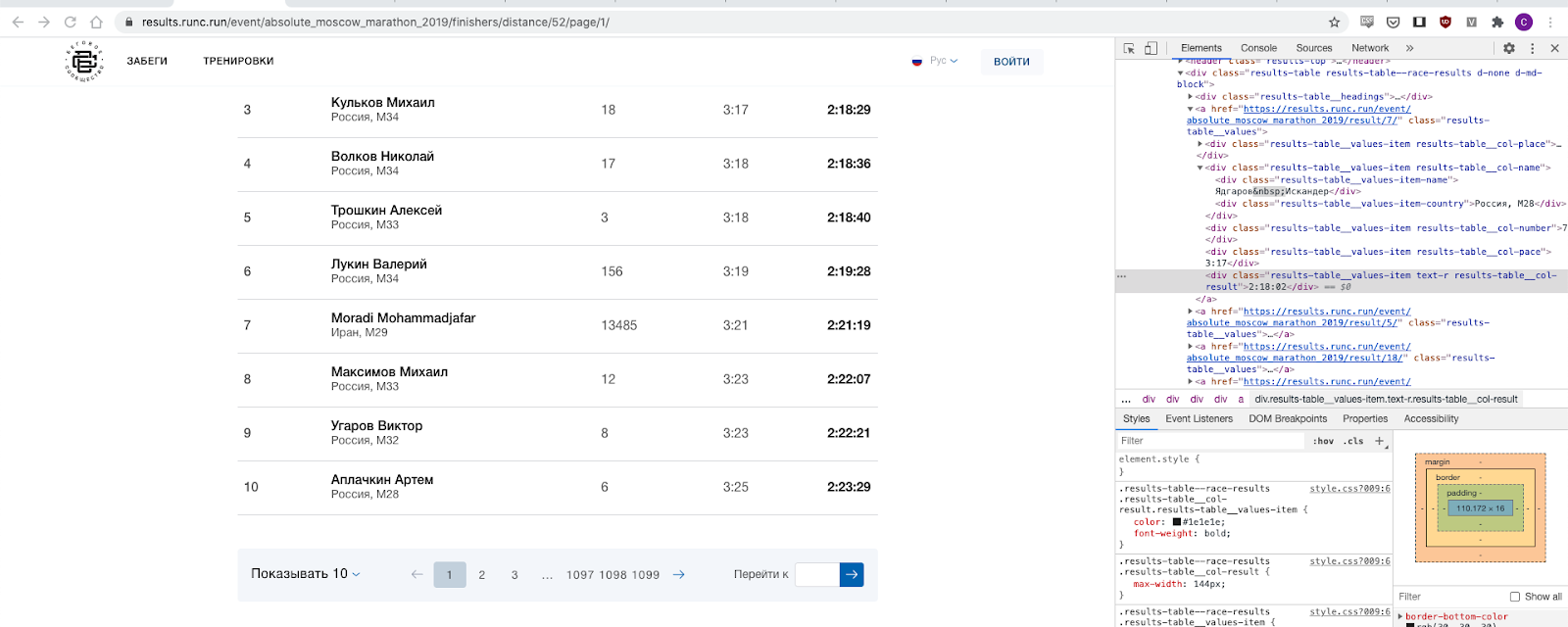
И это, оказывается, несложно, ибо тут есть прямая пагинация и собственно мы итерируем по всему отрезку чисел. Бинго, выкладываю собранные данные за 2019 и 2018 год здесь, если кому-то интересно для последующего анализа, то сами данные можно скачать здесь: здесь и здесь.
С чем тут пришлось повозиться
- Страница не отдает ошибок — если что-то идет не так, никто не посигналит, сайт просто отдает какие-то данные (например, повторяет прошлую страницу с результатами).
- В какой-то момент сервер решает, что он устал и перестает отдавать данные и виснет — проблема решается с помощью «поспать и продолжить сбор с прошлой точки».
- Url-магия — сайт что-то мудрит со ссылками, и нельзя просто поменять год в url и получить результаты другой гонки — приходится ручками через поиск искать и перепроверять, что мы действительно получаем свежие данные — иначе отгружает молча данные последнего года.
- В какой момент я собирал данные и параметризовал скрипт сбора данных годом — запустил и стал собирать — через час другой у меня было четыре датасета за 2016, 2017… и оказалось, что страница молча отдавала данные за 2019 год — потому что в том месте год вообще игнорировался, что было совершенно неожиданно — вывод стоит всегда проверять такие вещами руками, а не только постфактум — хотя и постфактум, конечно, надо проверять данные.
- Здесь есть несколько типов NA: DNF, DQ, "-" — придется проводить анализ и перепроверять, и чистить данные, иначе на выходе мусор.
- Типы данных: время здесь — это timedelta, но из-за перезапусков и невалидных значений приходится поработать с фильтрами и очисткой временных значений, чтобы мы оперировали над чистыми временными результатами для подсчета средних значений — все результаты здесь — это усреднение по тем, кто финишировал и у кого зафиксировано валидное время.
А вот и код спойлера, если кто-то решит продолжить собирать интересные беговые данные.
Код парсера
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Анализ времени и результатов
Перейдем к анализу данных и собственно результатов забега.
Использовались pandas, numpy, matplotlib и seaborn — все по классике.
Помимо средних значений по всем массивам, мы отдельно рассмотрим следующие группы:
- Мужчины — так как я вхожу в эту группу мне интересны именно эти результаты.
- Женщины — для симметрии.
- Мужчины до 35 — это условно одна из самых «соревновательных» групп и понятно, что сравнивать мне стоит именно с ними — так как я в этой группе.
- Отдельно посмотрим на 2018 и 2019 годы — а вдруг что поменялось?.
Сначала бегло глянем на таблицу ниже — здесь еще раз, чтобы не скроллить: участников стало больше, 95% в среднем добегает до финиша и большая часть участников мужчины. Хорошо, это значит, что в среднем я в основной группе и данные в среднем должно хорошо отображать среднее время для меня. Продолжаем.
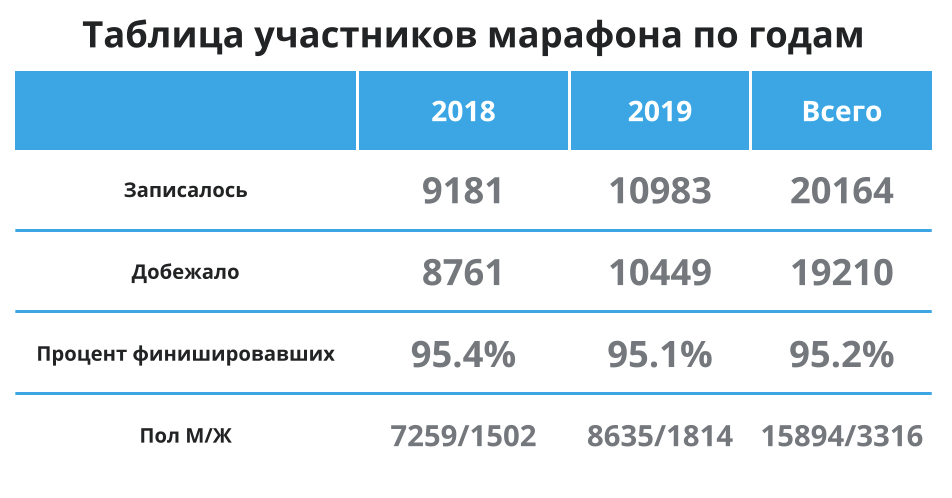

Как мы видим средние показатели за 2018 и 2019 практически не изменились — примерно 1.5 минуты стали быстрее бегуны в 2019 году. Разница между интересующими меня группами незначительна.
Перейдем к распределениям целиком. И сначала к общему времени забега.
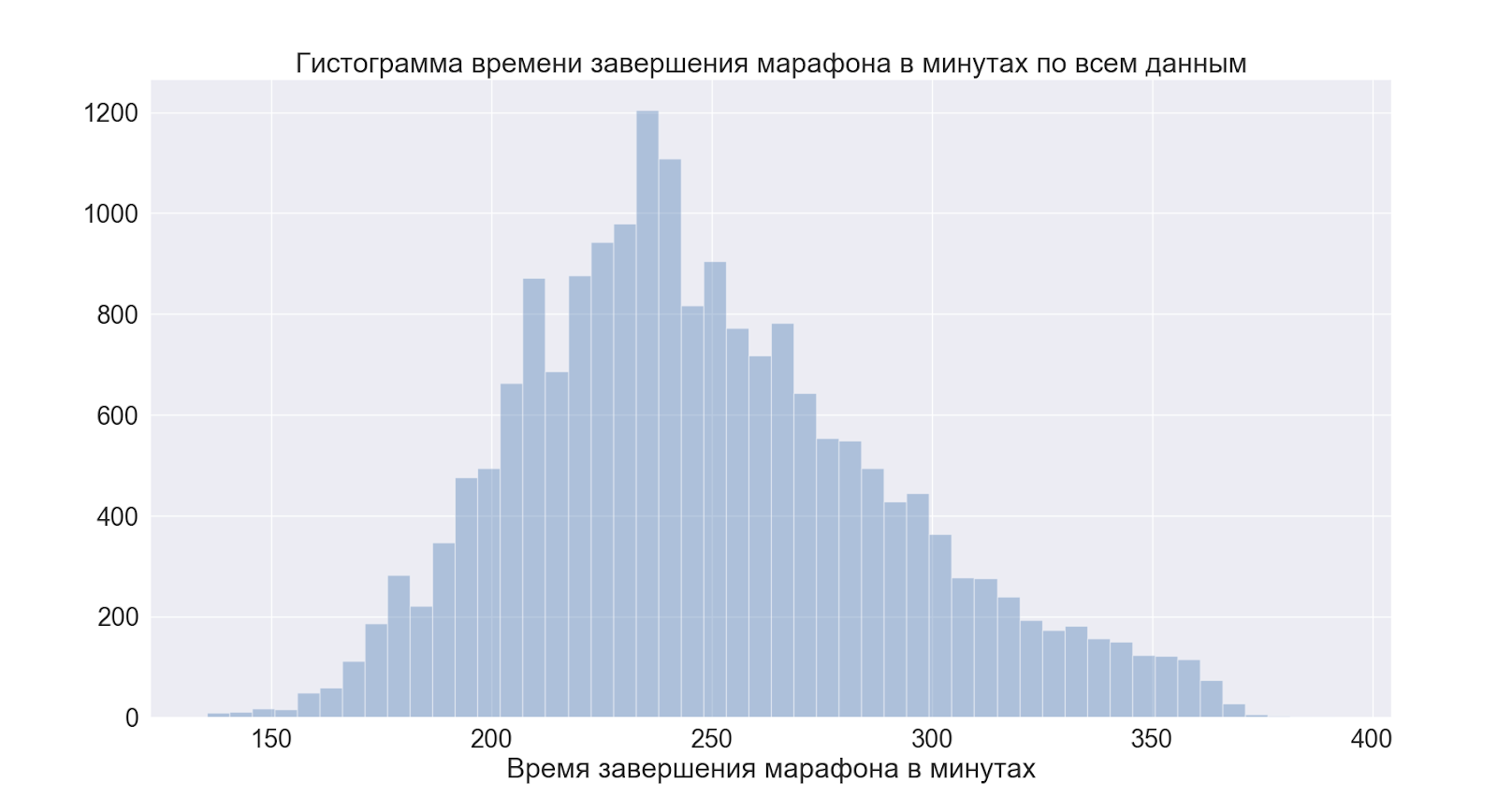
Как мы видим пик прямо перед 4 часами — это условная отметка для любителей «пробежать хорошо» = «выбежать из 4-х часов», данные подтверждают народную молву.
Далее, посмотрим, как в среднем изменилась ситуация за год.
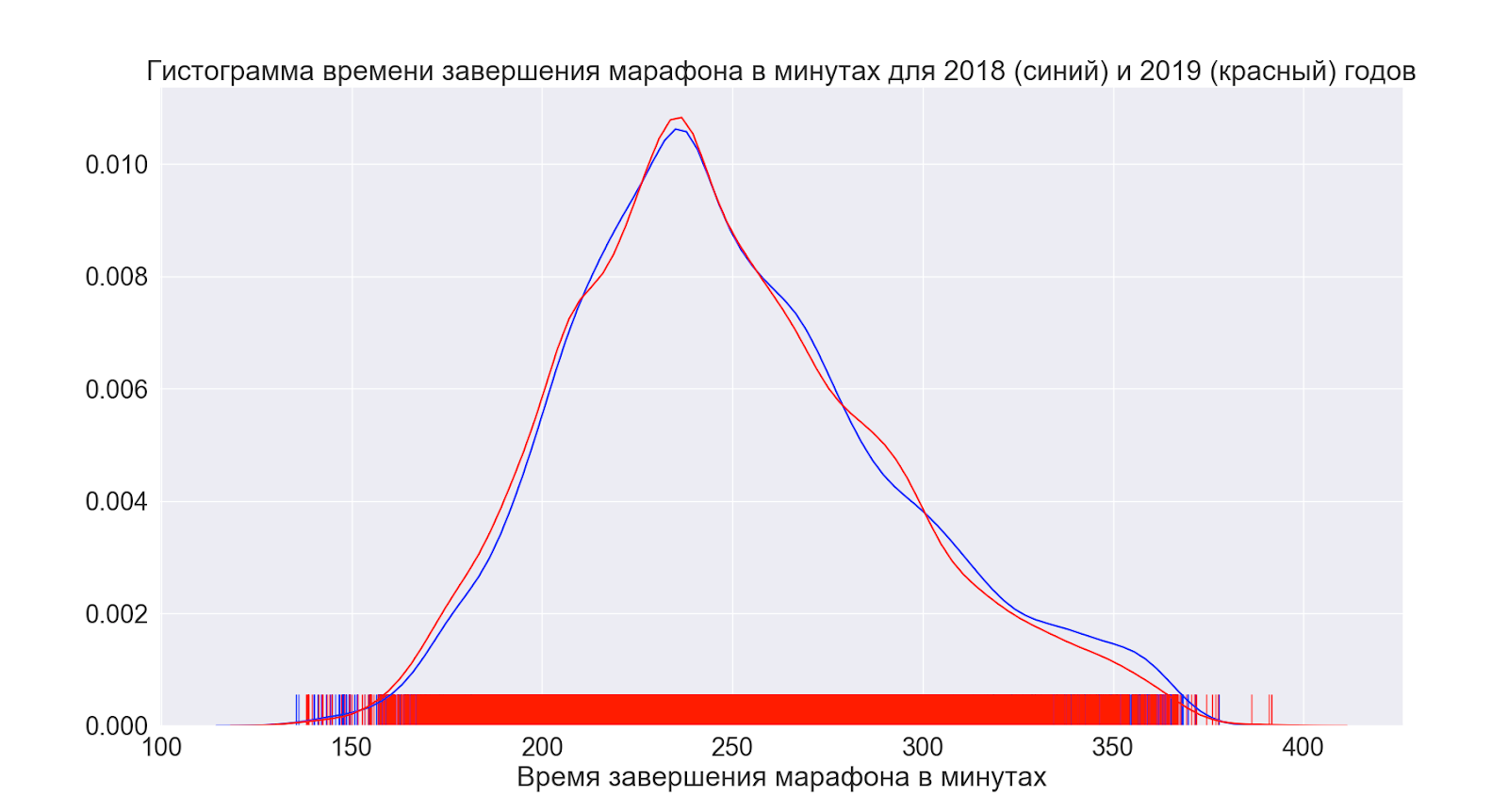
Как мы видим фактически вообще ничего не поменялось — распределения выглядят фактически идентичными.
Далее рассмотрим распределения по полу:

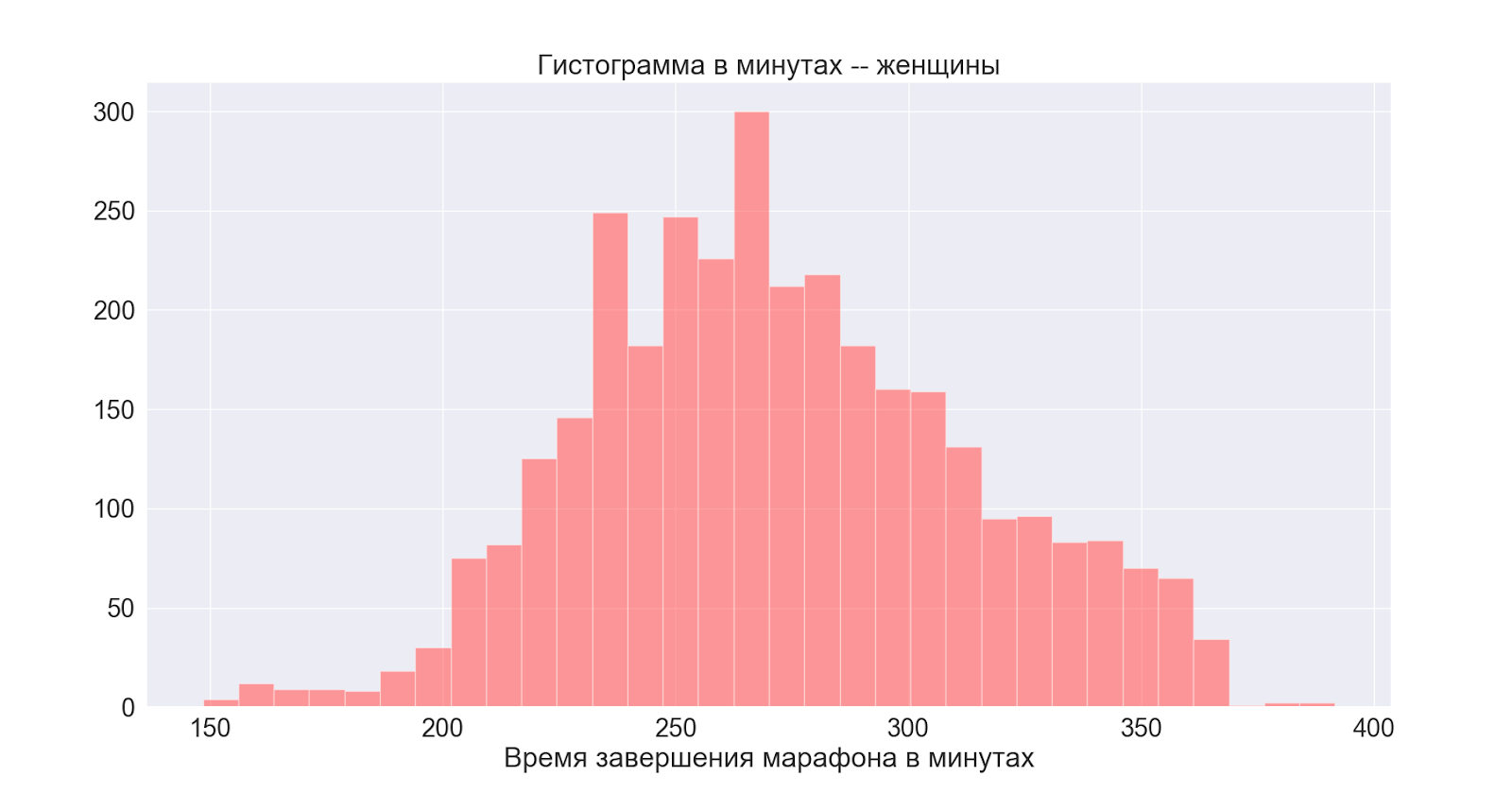
В целом оба распределения нормальные с чуть разным центром — мы видим, что пик на мужском так же проявляет себя на основном (общем) распределении.
Отдельно перейдем к самой интересной для меня группе:
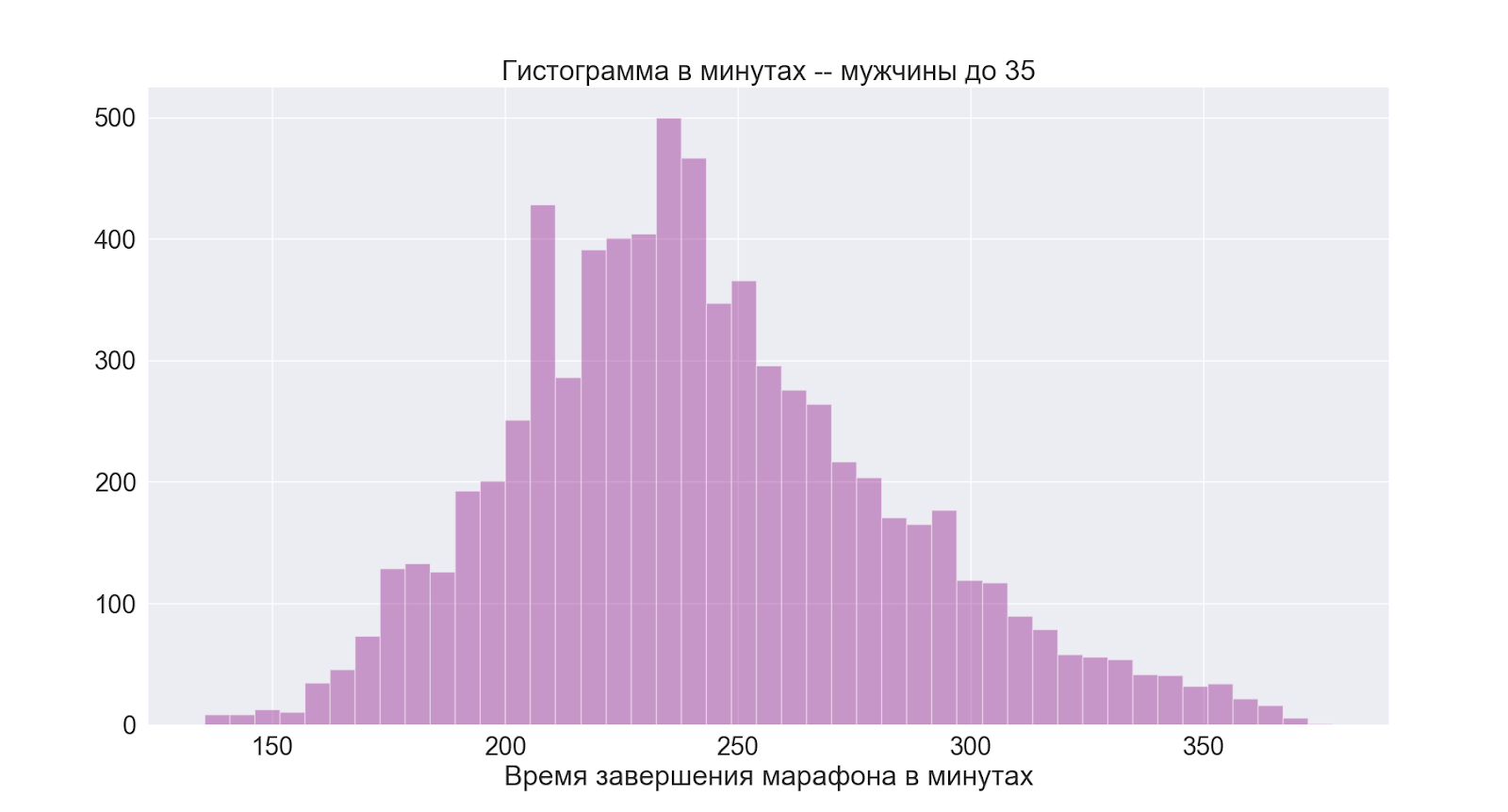
Как мы видим принципиально картина такая же, как и в целом в мужской группе.
Отсюда делаем вывод, что 4 часа для меня тоже являются хорошим средним временем.
Изучаем улучшения участников 2018 > 2019
Из интересностей: я почему-то думал, что сейчас быстренько соберу данных и можно углубиться в анализ, искать там закономерности часами и тд. Оказалось все наоборот, сбор данных оказался сложнее самого анализа — по классике работа с сетью, сырыми данными, очисткой, форматирование, приведение типов и тд заняло куда больше времени — чем анализ и визуализация. Не стоит забывать, что мелочи отнимают немного времени — но их [мелочей] совсем не мало и в конце они-то и скушают весь ваш вечер.
Отдельно хотелось посмотреть, а как улучшили свои результаты люди, которые участвовали оба раза, путем сопоставления данных между годами мне удалось установить следующее:
- 14 человек участвовали оба года и ни разу не финишировали
- 89 человека добежали в 18 м, но не смогли в 19
- 124 наоборот
- Те, кто смогли добежать оба раза в среднем улучшили на 4 минуты свой результат
Но тут оказалось довольно интересно все:
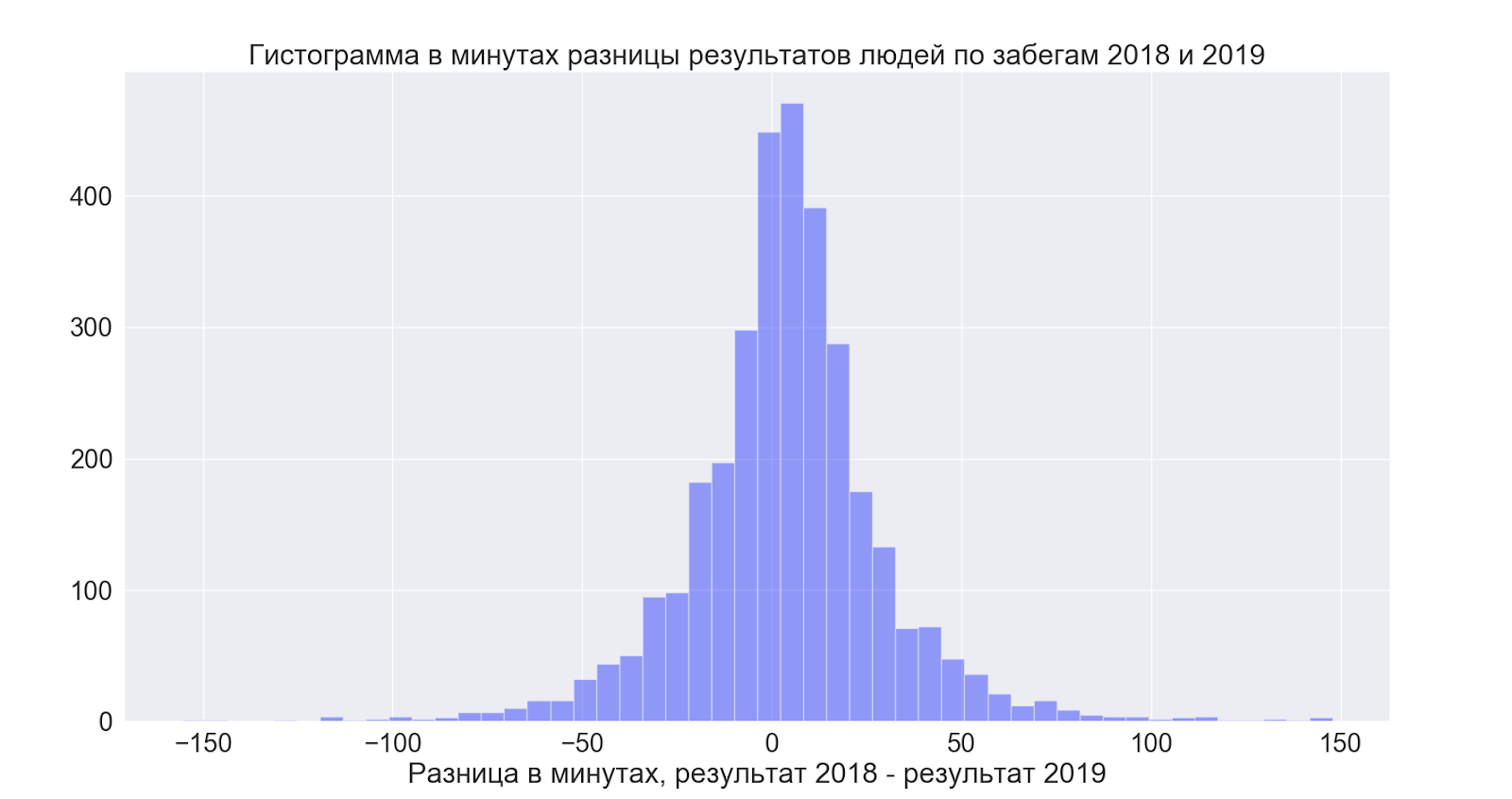
То есть в среднем люди чуть чуть улучшают результаты — но вообще разброс невероятный и в обе стороны — то есть хорошо надеяться, что будет лучше — но судя по данным, получается вообще как угодно!
Выводы
Я сделал для себя следующие выводы из проанализированных данных
- В целом 4 часа — хорошая цель «в среднем».
- Основная группа бегущих — как раз уже в самом соревновательном возрасте (и одной группе со мной).
- В среднем люди чуть чуть улучшают свой результат, но вообще судя по данным там как попадет вообще.
- Средние результаты всего забега примерно одинаковые оба года.
- С дивана очень комфортно рассуждать о марафоне.





alexanderkuk
Красивая визуализация для 2017 года moscowmarathon2017.datalaboratory.ru/results?runners=1,18