
Мне было необходимо делать 2 раза в сутки бэкап сайта на «1С-Битрикс: Управление сайтом» (файлов и базы mysql) и хранить историю изменений за 90 дней.
Сайт расположен на VDS под управлением ОС CentOS 7 с установленным «1С-Битрикс: Веб-окружение». Дополнительно делать резервную копию настроек ОС.
Требования:
Важным моментом являлась возможность быстро создавать бэкапы с минимальным потреблением дополнительного места и ресурсов системы.
Речь идет не о снапшоте для быстрого восстановления всей системы, а именно о файлах и базе и историей изменения.
Исходные данные:
Стандартное резервное копирование встроенное в 1С-Битрикс — исключил сразу. Оно подойдет только небольшим сайтам, т.к.:
Решение которое предлагает хостер, это диск для бэкапов находящийся в том же дата-центре, где и VDS, но на другом сервере. С диском можно работать по FTP и использовать свои сценарии, либо если на VDS установлен ISPManager, то через его модуль резервного копирования. Данный вариант не подходит из-за использования того же дата-центра.
Из всего вышесказанного оптимальным для меня выбором является инкрементальный бэкап по собственному сценарию в Яндекс.Облако (Object Storage) или Amazon S3 (Amazon Simple Storage Service).
Для этого требуется:
Разницы между Яндекс.Облаком и Amazon S3 в данном случае для меня нет. Яндекс поддерживает основную часть API Amazon S3, поэтому с ним можно работать используя решения, которые есть для работы с S3. В моём случае это утилита duplicity.
Основным плюсом Яндекса может быть оплата в рублях, если данных будет очень много, то не будет привязки к курсу. В плане скорости Европейские дата-центры Amazon работают соизмеримо с российскими в Яндексе, например можно использовать Франкфурт. Я ранее использовал Amazon S3 для подобных задач, сейчас решил попробовать Яндекс.
1. Необходимо создать платежный аккаунт в Яндекс.Облаке. Для этого нужно авторизоваться в Яндекс.Облаке через свой аккаунт Яндекса или создать новый.
2. Создать «Облако».
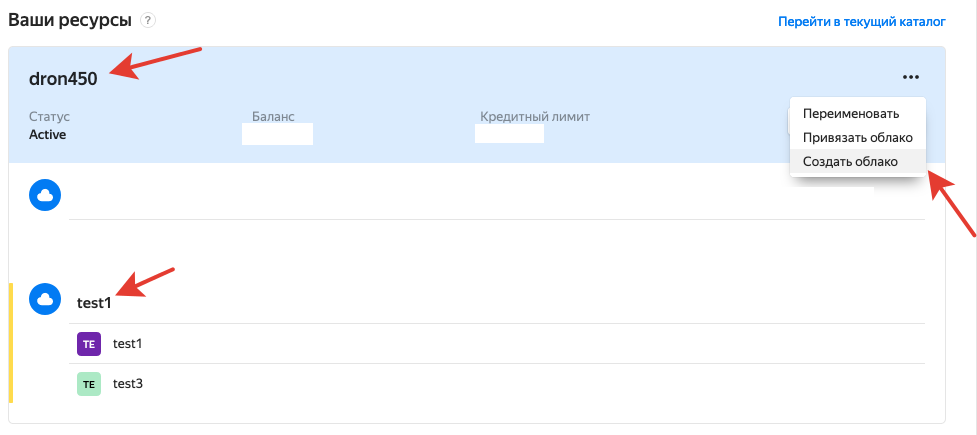
3. В «Облаке» создать «Каталог».

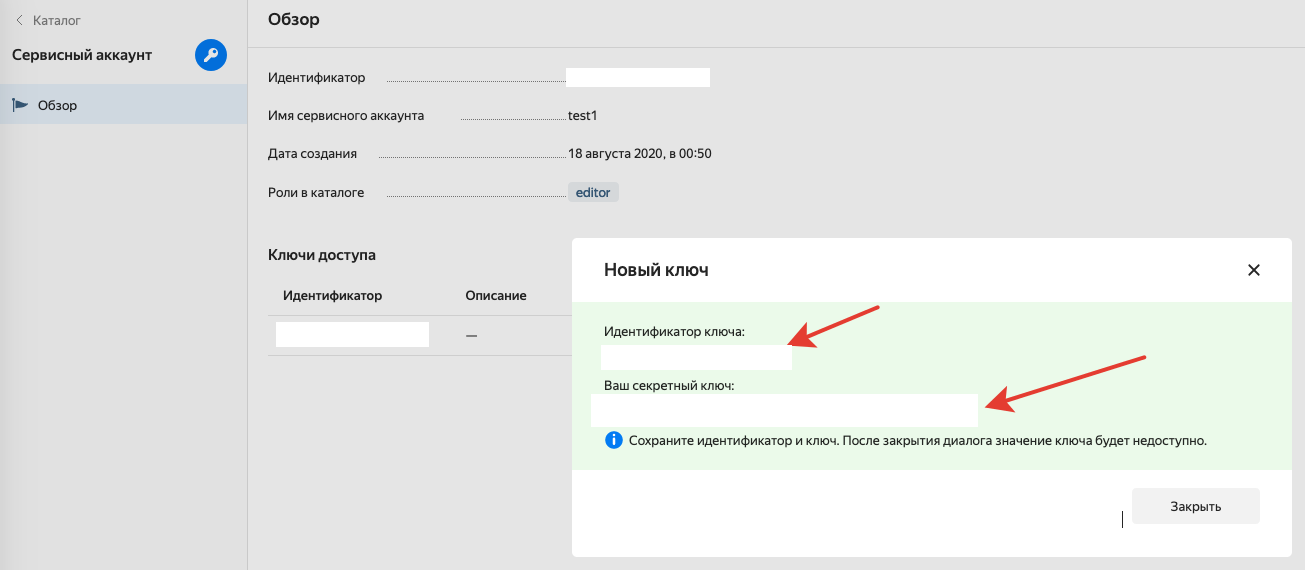
4. Для «Каталога» создать «Сервисный аккаунт».

5. Для «Сервисного аккаунта» создать ключи.

6. Ключи сохранить, они нужны будут в дальнейшем.
7. Для «Каталога» создать «Бакет», в него будут попадать файлы.

8. Рекомендую задать лимит и выбрать «Холодное хранилище».

Данное руководство предполагает наличие базовых навыков администрирования.
1. Установить на VDS утилиту duplicity
2. Создать папку для дампов mysql, в моём случае это /backup_db в корне VDS
3. Создать папку для bash скриптов /backup_scripts и сделать первый скрипт, который будет выполнять бэкап /backup_scripts/backup.sh
Содержание скрипта:
4. Запустить скрипт первый раз и проверить результат, в «Бакете» должны появиться файлы.

5. Добавить скрипт в cron для пользователя root на выполнение 2 раза в день, либо с нужной вам частотой.
1. Сделать папку для восстановления /backup_restore
2. Сделать bash скрипт для восстановления /backup_scripts/restore.sh
Я привожу самый востребованный пример восстановления определенного файла:
3. Запустить скрипт и дождаться результата.
В папке /backup_restore/ вы найдёте файл index.php, который ранее попал в резервную копию.
Более тонкую настройку можете производить под свои нужды.
Минус duplicity
У duplicity есть один минус — нет возможности задать лимит использования канала. С обычным каналом это не создает проблемы, а с при использовании канала с защитой от DDoS с тарификацией по скорости в сутки, я бы хотел иметь возможность установить ограничение в 1-2 мегабита.
Резервирование в Яндекс.Облаке или Amazon S3 дает независимую копию сайта и настроек ОС к которой можно обратится с любого другого сервера или локального компьютера. При этом данная копия не видна ни в панели управления хостингом, ни в админке битрикса, что дает дополнительную безопасность.
При самом печальном исходе можно собрать новый сервер и развернуть сайт за любую дату. Хотя наиболее востребованным функционалом будет возможность обратиться к файлу за определённую дату.
Использовать данную методику можно с любыми VDS или Dedicated серверами и сайтами на любых движках, не только 1С-Битрикс. ОС также может быть отличная от CentOS, например Ubuntu или Debian.
Сайт расположен на VDS под управлением ОС CentOS 7 с установленным «1С-Битрикс: Веб-окружение». Дополнительно делать резервную копию настроек ОС.
Требования:
- Частота — 2 раза в сутки;
- Хранить копии за последние 90 дней;
- Возможностью достать отдельные файлы за определенную дату, при необходимости;
- Бэкап должен храниться в отличном от VDS дата-центре;
- Возможность получить доступ к бэкапу из любого места (другой сервер, локальный компьютер и т.д.).
Важным моментом являлась возможность быстро создавать бэкапы с минимальным потреблением дополнительного места и ресурсов системы.
Речь идет не о снапшоте для быстрого восстановления всей системы, а именно о файлах и базе и историей изменения.
Исходные данные:
- VDS на виртуализации XEN;
- ОС CentOS 7;
- 1С-Битрикс: Веб-окружение;
- Сайт на базе «1С-Битрикс: Управление сайтом», версия Стандарт;
- Размер файлов — 50 Гб и будет расти;
- Размер базы — 3 Гб и будет расти.
Стандартное резервное копирование встроенное в 1С-Битрикс — исключил сразу. Оно подойдет только небольшим сайтам, т.к.:
- Делает полную копию сайта каждый раз, соответственно каждая копия будет занимать столько же места, сколько занимаю файлы, в моём случае это 50 Гб.
- Резервное копирование делается средствами PHP, что с такими объемами файлов — невозможно, оно перегрузит сервер и не закончится никогда.
- И конечно же ни о каких 90 днях речи идти не может при хранении полной копии.
Решение которое предлагает хостер, это диск для бэкапов находящийся в том же дата-центре, где и VDS, но на другом сервере. С диском можно работать по FTP и использовать свои сценарии, либо если на VDS установлен ISPManager, то через его модуль резервного копирования. Данный вариант не подходит из-за использования того же дата-центра.
Из всего вышесказанного оптимальным для меня выбором является инкрементальный бэкап по собственному сценарию в Яндекс.Облако (Object Storage) или Amazon S3 (Amazon Simple Storage Service).
Для этого требуется:
- root доступ к VDS;
- установленная утилита duplicity;
- аккаунта в Яндекс.Облаке.
Инкрементальный бэкап — метод при котором архивируются только измененные с момента последнего бэкапа данные.
duplicity — бэкап утилита использующая rsync алгоритмы и умеющая работать с Amazon S3.
Яндекс.Облако vs Amazon S3
Разницы между Яндекс.Облаком и Amazon S3 в данном случае для меня нет. Яндекс поддерживает основную часть API Amazon S3, поэтому с ним можно работать используя решения, которые есть для работы с S3. В моём случае это утилита duplicity.
Основным плюсом Яндекса может быть оплата в рублях, если данных будет очень много, то не будет привязки к курсу. В плане скорости Европейские дата-центры Amazon работают соизмеримо с российскими в Яндексе, например можно использовать Франкфурт. Я ранее использовал Amazon S3 для подобных задач, сейчас решил попробовать Яндекс.
Настройка Яндекс.Облака
1. Необходимо создать платежный аккаунт в Яндекс.Облаке. Для этого нужно авторизоваться в Яндекс.Облаке через свой аккаунт Яндекса или создать новый.
2. Создать «Облако».
3. В «Облаке» создать «Каталог».
4. Для «Каталога» создать «Сервисный аккаунт».
5. Для «Сервисного аккаунта» создать ключи.
6. Ключи сохранить, они нужны будут в дальнейшем.
7. Для «Каталога» создать «Бакет», в него будут попадать файлы.
8. Рекомендую задать лимит и выбрать «Холодное хранилище».
Настройка резервного копирования по расписанию на сервере
Данное руководство предполагает наличие базовых навыков администрирования.
1. Установить на VDS утилиту duplicity
yum install duplicity2. Создать папку для дампов mysql, в моём случае это /backup_db в корне VDS
3. Создать папку для bash скриптов /backup_scripts и сделать первый скрипт, который будет выполнять бэкап /backup_scripts/backup.sh
Содержание скрипта:
#!`which bash`
# /backup_scripts/backup.sh
# Это условие проверяет не идёт ли в данный момент процесс резервного копирования, если идёт, то на email отправляется сообщение об ошибке (этот блок можно не использовать)
if [ -f /home/backup_check.mark ];
then
DATE_TIME=`date +"%d.%m.%Y %T"`;
/usr/sbin/sendmail -t <<EOF
From:backup@$HOSTNAME
To:<Ваш EMAIL>
Subject:Error backup to YANDEX.CLOUD
Content-Type:text/plain; charset=utf-8
Error backup to YANDEX.CLOUD
$DATE_TIME
EOF
else
# Основной блок отвечающий за резервное копирование
# Если нет ощибки ставим метку и запускаем backup
echo '' > /home/backup_check.mark;
# Удаляем файлы с дампами базы оставшиеся от предыдущего backup
/bin/rm -f /backup_db/*
# Делаем дамп всех mysql баз, предполагается что доступ добавлен в файле /root/.my.cnf
DATETIME=`date +%Y-%m-%d_%H-%M-%S`;
`which mysqldump` --quote-names --all-databases | `which gzip` > /backup_db/DB_$DATETIME.sql.gz
# Добавляем данные для отправки в Яндекс.
export PASSPHRASE=<Придумайте пароль для шифрования архива>
export AWS_ACCESS_KEY_ID=<Идентификатор ключа полученный у Яндекса>
export AWS_SECRET_ACCESS_KEY=<Секретный ключ полученный у Яндекса>
# Запускаем duplicity для резервирования необходимых папок на сервере.
# Данная команда будет создавать полный backup раз в месяц и до следующего месяца добавлять инкрементальные к нему
# -- exclude это папки, которые нужно исключить, я исключаю все папки с кешем битрикса
# --include папки которые нужно резервировать в моём случае это:
# - /backup_db
# - /home
# - /etc
# s3://storage.yandexcloud.net/backup , backup это имя созданного выше бакета
# Техническая особенность и значения некоторых параметров:
# Две строки "--exclude='**'" и "/" нужны, чтобы можно было выше оперировать --include и --exclude для разных папок. Эти две строчки сначала добавляют в бэкап весь сервер "/", потом исключают его "--exclude='**'"
# --full-if-older-than='1M' - создавать полную копию каждый месяц
# --volsize='512' - максимальный размер каждого из файлов в бэкапе в мегабайтах
# --log-file='/var/log/duplicity.log' - куда писать лог файл
`which duplicity` --s3-use-ia --s3-european-buckets --s3-use-new-style --s3-use-multiprocessing --s3-multipart-chunk-size='128' --volsize='512' --no-print-statistics --verbosity=0 --full-if-older-than='1M' --log-file='/var/log/duplicity.log' --exclude='**/www/bitrix/backup/**' --exclude='**/www/bitrix/cache/**' --exclude='**/www/bitrix/cache_image/**' --exclude='**/www/bitrix/managed_cache/**' --exclude='**/www/bitrix/managed_flags/**' --exclude='**/www/bitrix/stack_cache/**' --exclude='**/www/bitrix/html_pages/*/**' --exclude='**/www/bitrix/tmp/**' --exclude='**/www/upload/tmp/**' --exclude='**/www/upload/resize_cache/**' --include='/backup_db' --include='/home' --include='/etc' --exclude='**' / s3://storage.yandexcloud.net/backup
# Данная команда нужна для чистки.
# Она оставляет 3 последних полных backup и ассоциированных с ними инкрементальных backup.
# Т.о. у меня остаются backup за 3 месяца, т.к. первая команда каждый месяц делает новый полный backup
`which duplicity` remove-all-but-n-full 3 --s3-use-ia --s3-european-buckets --s3-use-new-style --verbosity=0 --force s3://storage.yandexcloud.net/backup
unset PASSPHRASE
unset AWS_ACCESS_KEY_ID
unset AWS_SECRET_ACCESS_KEY
# Удаляем метку об идущем backup
/bin/rm -f /home/backup_check.mark;
fi4. Запустить скрипт первый раз и проверить результат, в «Бакете» должны появиться файлы.
`which bash` /backup_scripts/backup.sh5. Добавить скрипт в cron для пользователя root на выполнение 2 раза в день, либо с нужной вам частотой.
10 4,16 * * * `which bash` /backup_scripts/backup.shВосстановление данных из Яндекс.Облака
1. Сделать папку для восстановления /backup_restore
2. Сделать bash скрипт для восстановления /backup_scripts/restore.sh
Я привожу самый востребованный пример восстановления определенного файла:
#!`which bash`
export PASSPHRASE=<Пароль для шифрования архива используемый при бэкапе>
export AWS_ACCESS_KEY_ID=<Идентификатор ключа полученный у Яндекса>
export AWS_SECRET_ACCESS_KEY=<Секретный ключ полученный у Яндекса>
# 3 примера, раскомментировать нужный
# Получить статус backup
#`which duplicity` collection-status s3://storage.yandexcloud.net/backup
# Восстановить index.php из корня сайта
#`which duplicity` --file-to-restore='home/bitrix/www/index.php' s3://storage.yandexcloud.net/backup /backup_restore/index.php
# Восстановить index.php из корня сайта 3х дневной давности
#`which duplicity` --time='3D' --file-to-restore='home/bitrix/www/index.php' s3://storage.yandexcloud.net/backup /backup_restore/index.php
unset PASSPHRASE
unset AWS_ACCESS_KEY_ID
unset AWS_SECRET_ACCESS_KEY3. Запустить скрипт и дождаться результата.
`which bash` /backup_scripts/backup.shВ папке /backup_restore/ вы найдёте файл index.php, который ранее попал в резервную копию.
Более тонкую настройку можете производить под свои нужды.
Минус duplicity
У duplicity есть один минус — нет возможности задать лимит использования канала. С обычным каналом это не создает проблемы, а с при использовании канала с защитой от DDoS с тарификацией по скорости в сутки, я бы хотел иметь возможность установить ограничение в 1-2 мегабита.
В качестве вывода
Резервирование в Яндекс.Облаке или Amazon S3 дает независимую копию сайта и настроек ОС к которой можно обратится с любого другого сервера или локального компьютера. При этом данная копия не видна ни в панели управления хостингом, ни в админке битрикса, что дает дополнительную безопасность.
При самом печальном исходе можно собрать новый сервер и развернуть сайт за любую дату. Хотя наиболее востребованным функционалом будет возможность обратиться к файлу за определённую дату.
Использовать данную методику можно с любыми VDS или Dedicated серверами и сайтами на любых движках, не только 1С-Битрикс. ОС также может быть отличная от CentOS, например Ubuntu или Debian.



s37
Спасибо за подробную инструкцию! Мучались (мучаемся) длительное время с бекапами, сначала делали стандартным инструментом от Битрикса, но когда сайт с базой и файлами (много фото и видео) перевалил за 90 Гб начались проблемы + не было истории изменений по файлам, знаем что «что-то» менялось, а что конкретно не знаем.
DRon450 Автор
Рад, что статья вам помогла!