
 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).По долгу работы я примерно 3 года занимаюсь разработкой и поддержкой нескольких проектов, которые используют MongoDB в качестве основной БД, и в этой статье хочу рассказать, почему на мой взгляд с MongoDB далеко не все так просто, как написано в мануалах, и к чему вы должны быть готовы, если вдруг решите взять MongoDB в качестве основной БД в ваш новый модный стартап :-)
Все что описано ниже можно воспроизвести с использованием библиотеки PyMongo для работы с MongoDB из языка программирования Python. Однако скорее всего с аналогичными ситуациями вы можете столкнуться и при использовании других библиотек для других языков программирования.
PyMongo, проблема с Failover и AutoReconnect exception
Практически во всех мануалах равно как и в многочисленных статьях в интернетах говорится, что Mongo поддерживает failover из коробки за счет встроенного механизма репликации. В нескольких статьях, причем даже в официальных курсах от 10gen, приводится очень популярный пример, как если развернуть на одном хосте несколько процессов mongod и настроить между ними репликацию, а потом kill-нуть один из процессов, то репликация не порушится, новый мастер переизберется и все будет ок. И это действительно так и работает… но только на localhost-е! В реальных же условиях все немного иначе.
Вот допустим проэкспериментируем с виртуалками на Amazon-е. Поднимем 5ть small машин — 3 под базы, и 2 под тестовые процессы writer и reader — один непрерывно записывает значения в базу, другой их считывает.
Берем CentOS 6.x, ставим на него mongodb из стандартных реп, ставим supervisor. Конфигурация каждого из процессов mongod в supervisor-е выглядит следующим образом:
# touch /etc/supervisord.d/mongo.conf
[program:mongo]
directory=/mnt/mongo
command=mongod --dbpath /mnt/mongo/ --logappend --logpath /mnt/mongo/log --port 27017 --replSet abc
Настраиваем репликацию:
# mongo --port 27017
> rs.initiate({
_id: 'abc',
members: [
{_id: 0, host:'db1:27017'},
{_id: 1, host:'db2:27017'},
{_id: 2, host:'db3:27017'}
]
})
Процесс writer.py выглядит так:
import datetime, random, time, pymongo
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
cl = con.test.entities
while True:
time.sleep(1)
try:
res = cl.insert({
'time': time.time(),
'value': random.random(),
'title': random.choice(['python', 'php', 'ruby', 'java', 'cpp', 'javascript', 'go', 'erlang']),
'type': random.randint(1, 5)
})
print '[', datetime.datetime.utcnow(), ']', 'wrote:', res
except pymongo.errors.AutoReconnect, e:
print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e
except Exception, e:
print '[', datetime.datetime.utcnow(), ']', 'error:', e
А вот процесс reader.py:
import datetime, time, random, pymongo
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
cl = con.test.entities
while True:
time.sleep(1)
try:
res = cl.find_one({'type': random.randint(1, 5)}, sort=[("time", pymongo.DESCENDING)])
print '[', datetime.datetime.utcnow(), ']', 'read:', res
except Exception, e:
print '[', datetime.datetime.utcnow(), ']', 'error'
print e
Запускаем процессы writer.py и reader.py в параллели, а потом берем и stop-аем машину с Primary-нодой в консоли Amazon-а.
Что должно произойти по логике? Согласно документации MongoDB репликсет 'abc' должен переизбрать нового мастера и это должно произойти прозрачно для скриптов writer.py и reader.py, и если вы тестируете на локали (т.е. разворачиваете все три процесса на одном хосте), то действительно так все и происходит. В нашем же случае скрипты writer.py и reader.py попросту повисают и остаются в таком подвешенном состоянии до тех пор пока вы не пошлете им сигнал прерывания (даже когда новый primary уже выбран и активен).
[ 2015-08-28 21:57:44.694668 ] wrote: 55e0d958671709042a4918b5
[ 2015-08-28 21:57:45.696838 ] wrote: 55e0d959671709042a4918b6
[ 2015-08-28 21:57:46.698918 ] wrote: 55e0d95a671709042a4918b7
[ 2015-08-28 21:57:47.703834 ] wrote: 55e0d95b671709042a4918b8
[ 2015-08-28 21:57:48.712134 ] wrote: 55e0d95c671709042a4918b9
^CTraceback (most recent call last):
File "write.py", line 18, in <module>
'type': random.randint(1, 5)
File "/usr/lib64/python2.6/site-packages/pymongo/collection.py", line 409, in insert
gen(), check_keys, self.uuid_subtype, client)
File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 393, in _do_batched_write_command
results.append((idx_offset, send_message()))
File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 345, in send_message
command=True)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1511, in _send_message
response = self.__recv_msg(1, rqst_id, sock_info)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1444, in __recv_msg
header = self.__recv_data(16, sock)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1432, in __recv_data
chunk = sock_info.sock.recv(length)
KeyboardInterrupt
Согласитесь, что не самая хорошая ситуация для системы, которая позиционирует себя как отказоустойчивая из коробки? Конечно, пример немного утрирован — например если вы используете PyMongo и MongoDB в своем web-проекте, то велика вероятность, что все python-хозяйство у вас крутится под uwsgi, а в uwsgi настроен какой-нибудь harakiri mode, который прибьет скрипты по timeout-у… Но тем не менее хотелось бы как-то перехватывать подобного рода ситуации в коде. Для этого нужно видоизменить скрипты. В скрипте reader.py нужно заменить:
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000, read_preference=pymongo.ReadPreference.SECONDARY_PREFERRED)
А в скрипте writer.py:
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000)
Что в итоге мы получим. Повторив эксперимент с вырубанием Primary ноды процесс reader.py продолжит работать как ни в чем не бывало (поскольку обращается к Secondary-ноде, которая в нашем примере остается без изменений), а вот процесс writer.py примерно на минуту уйдет в астрал при этом выкидывая ошибки типа AutoReconnect:
[ 2015-08-28 21:49:06.303250 ] wrote: 55e0d75267170904208d3e01
[ 2015-08-28 21:49:07.306277 ] wrote: 55e0d75367170904208d3e02
[ 2015-08-28 21:49:13.313476 ] autoreconnect error: timed out
[ 2015-08-28 21:49:24.315754 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:33.338286 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:44.340396 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:53.361185 ] autoreconnect error: No primary available
[ 2015-08-28 21:50:04.363322 ] autoreconnect error: No primary available
[ 2015-08-28 21:50:13.456355 ] wrote: 55e0d79267170904208d3e09
[ 2015-08-28 21:50:14.459553 ] wrote: 55e0d79667170904208d3e0a
[ 2015-08-28 21:50:15.462317 ] wrote: 55e0d79767170904208d3e0b
[ 2015-08-28 21:50:16.465371 ] wrote: 55e0d79867170904208d3e0c
Опять-таки не слишком здорово для системы, которая позиционируется как отказоусточивая, уходить в даун на минуту (повторюсь, что если тестировать на локали, то никаких таймаутов нет — все гладко), но это неизбежное зло и об этом даже написано в документации:
It varies, but a replica set will select a new primary within a minute.Но вернемся к нашему примеру и к ошибкам AutoReconnect. Как вы наверное догадались, мы поставили таймаут 5секунд на сокет. Если через 5ть секунд драйвер PyMongo не получает от базы никакого ответа, то он сбрасывает соединение и выплевывает ошибку. Не самое классное решение — вдруг база перенагружена или запрос очень тяжелый и выполняется более 5ти секунд (какая-нибудь агрегирующая функция которая шерстит всю базу). Самый главный вопрос — почему драйвер сам не пытается перезапустить запрос в случае, когда видит, что произошел AutoReconnect Error. Первая причина — драйвер не знает, что на самом деле произошло — вдруг “лег” не один процесс, а весь репликсет. Вторая причина — дубликаты! Оказывается в случае ошибки AutoReconnect драйвер не знает, удалось ли ему записать данные или не удалось. Это немного странно звучит для базы, которая претендует на мировое господство, но это действительно так, и чтобы наш пример работал корректно, скрипт writer.py нужно переписать следующим образом:
It may take 10-30 seconds for the members of a replica set to declare a primary inaccessible. This triggers an election. During the election, the cluster is unavailable for writes.
The election itself may take another 10-30 seconds.
import datetime, time, random, pymongo
from pymongo.objectid import ObjectId
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000)
cl = con.test.entities
while True:
time.sleep(1)
data = { '_id': ObjectId(), …. }
# Try for five minutes to recover from a failed primary
for i in range(60):
try:
res = cl.insert(data)
print '[', datetime.datetime.utcnow(), ']', 'wrote:', res
break
except pymongo.errors.AutoReconnect, e:
print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e
time.sleep(5)
except pymongo.errors.DuplicateKeyError:
break
Проблема Global lock
Огромный подводный камень MongoDB. Наверное то, за что монгу критикуют больше всего. Под удар попадают массовые операции, производимые по группе документов. То есть грубо говоря несколько тяжелых операций update-ов по большой группе документов могут создать проблемы с производительностью и заблокировать выполнение других запросов. Конечно, начиная с версии 2.2 ситуация немного улучшилась, когда научились приспускать лок (lock yielding), а так же перевели лок с уровня процесса mongod на уровень выбранной БД. В новой версии 3.0 создатели утверждают, что с переходом на альтернативный движок WiredTiger ситуация должна улучшиться, поскольку он использует блокировки на уровне документа, а не блокирует базу целиком, как было в движке MMAPv1.
Я написал небольшой бенчмарк, для наглядного воспроизведения ситуации с global lock. При желании вы можете сделать git pull и воспроизвести все эти тесты у себя.
- Рассмотрим 1 000 пользователей (значение может быть изменено через конфиг)
- У каждого пользователя 5 000 документов. То есть всего 5 000 000 документов в базе. Каждый документ содержит поле, которое хранит некоторое булевое значение.
- Процесс тестирования представляет собой параллельное выполнение 1 000 задач — по одной на каждого пользователя. Каждая задача — обновление булевого поля всех 5 000 документов пользователя.
- В процессе тестирования по нарастающей от 1го до 30ти (опять-таки значение можно изменить через конфиг) увеличиваем количество конкурентных процессов, которые единовременно расхватывают пул задач.
- Сохраняем время выполнения каждой задачи. Строим графики. Сравниваем результаты тестирования для различных версий MongoDB.
- В качестве альтернативы рассмотрим аналогичную задачу на MySQL 5.5 (InnoDB). И сравним результаты.
В результате тестирования получилось следующее.
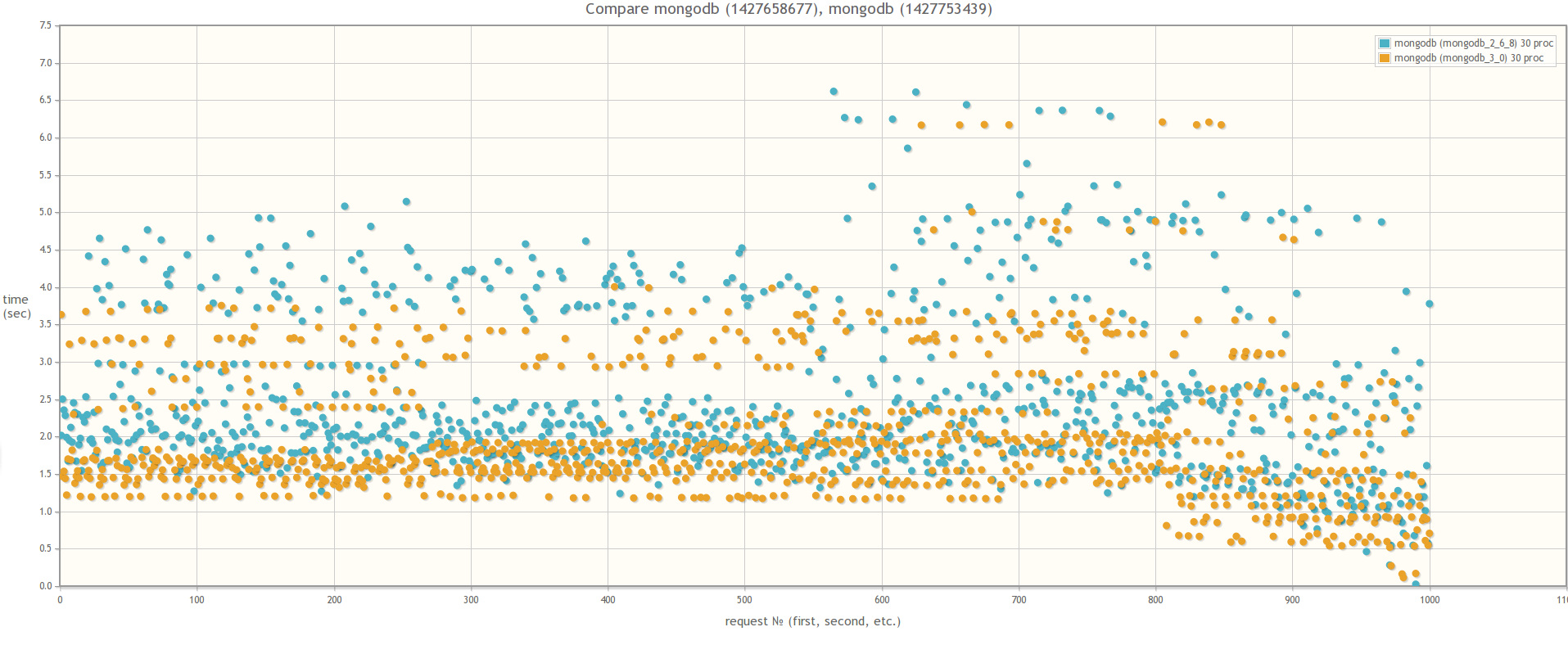
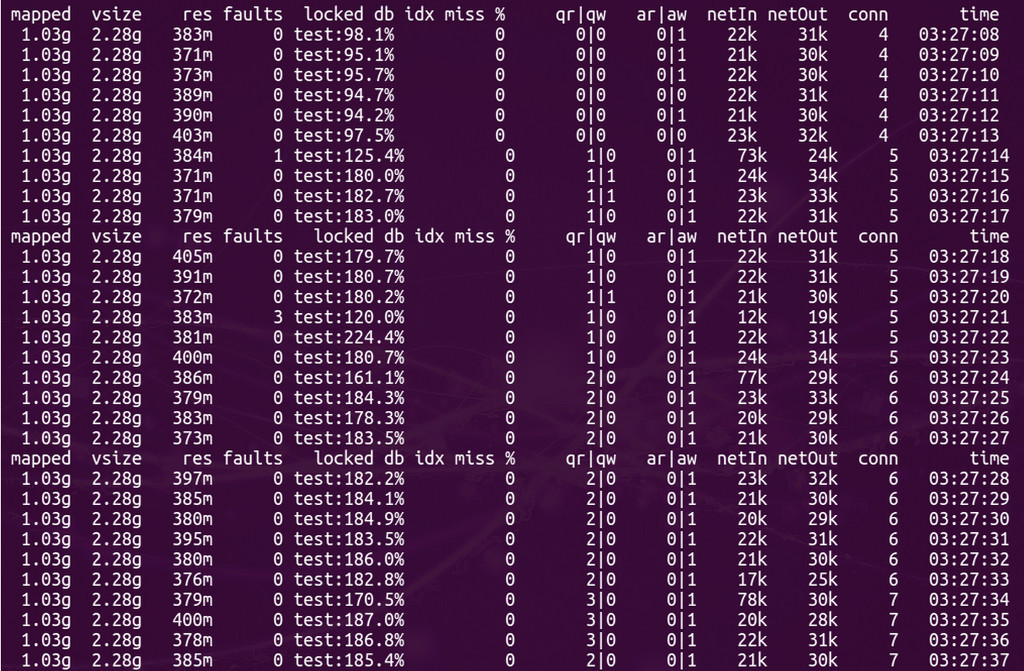
Если сравнивать версию MongoDB 2.6 и версию MongoDB 3.0 (MMAPv1, не WiredTiger), то результаты не сильно различаются, хотя в случае 30ти одновременных процессов worker-ов при использовании MongoDB 3.0 время выполнения запросов все же слегка поменьше. Кстати во время тестирования если посмотреть утилиткой mongostat на процент лока, то он будет зашкаливать:
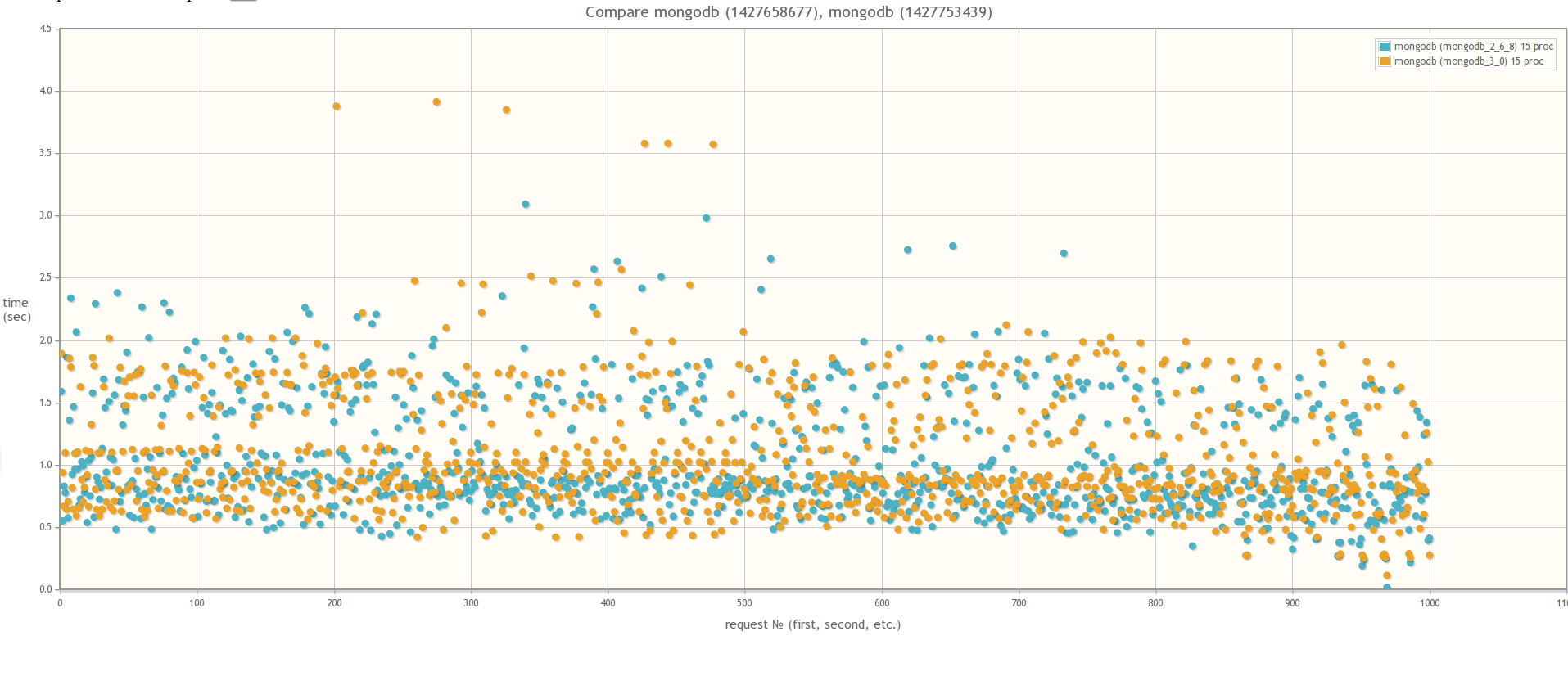
В 30ть параллельных процессов:
mongostat:
При сравнении MongoDB 3.0 MMAPv1 и MongoDB 3.0 WiredTiger результаты разительно отличаются, что свидетельствует о том, что влияние блокировок на быстродействие массовых операций действительно значительно меньше в случае использования WiredTiger:
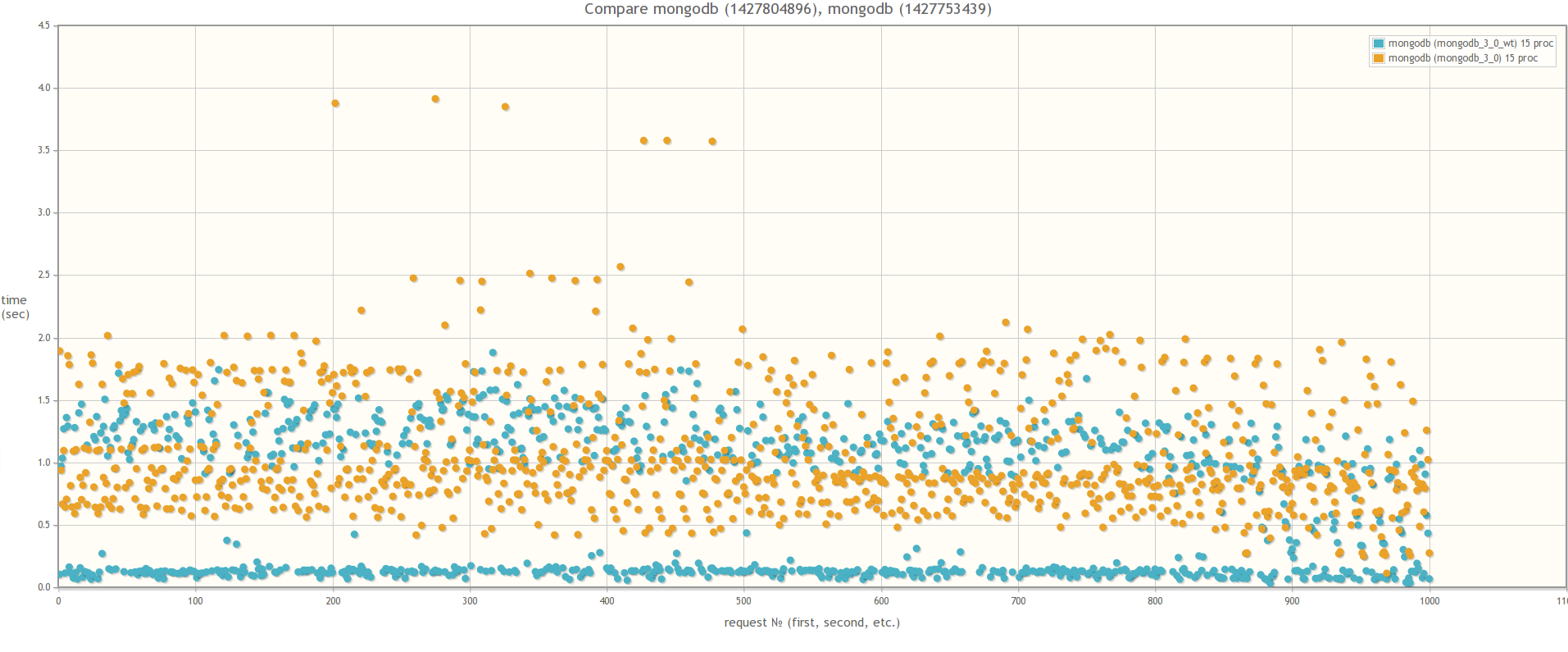
В 30ть параллельных процессов:
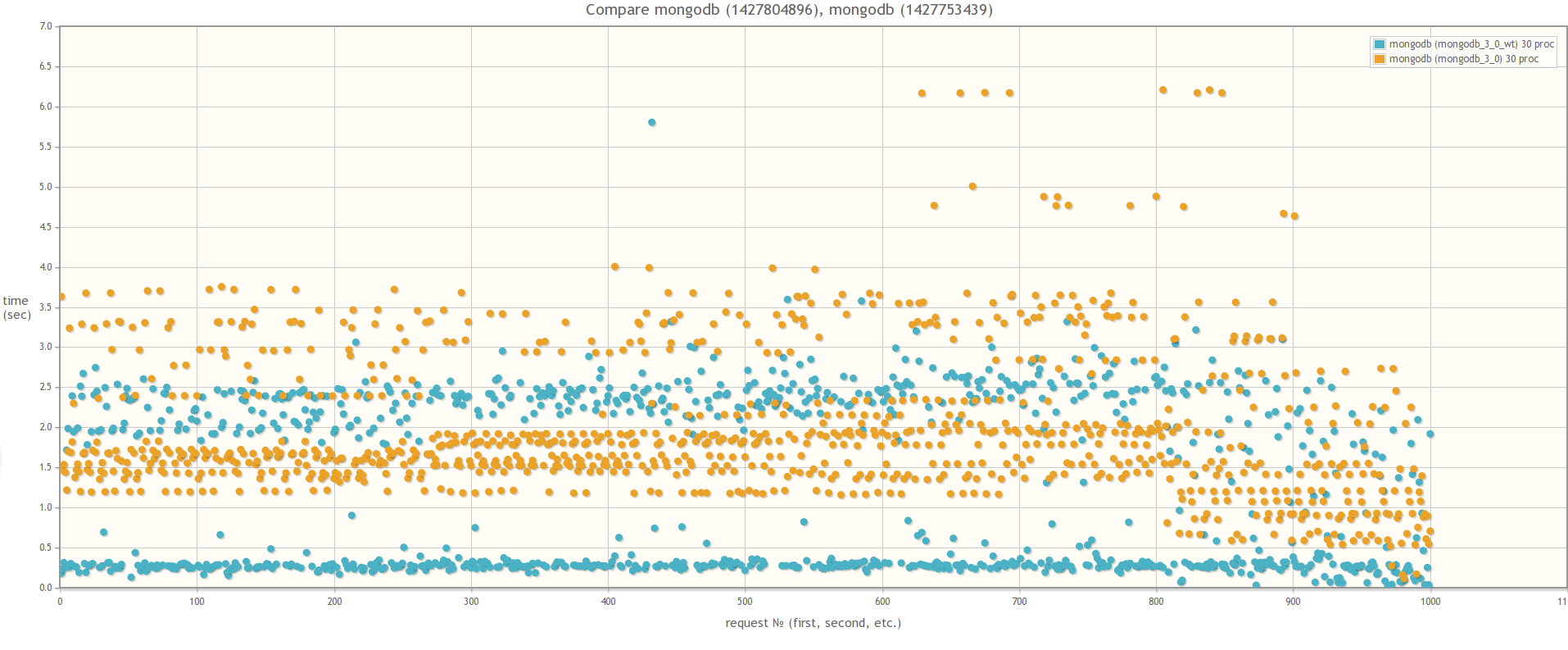
А теперь сравним MongoDB 3.0 WiredTiger и MySQL 5.5. База MySQL была выбран исключительно из индивидуальных предпочтений. Если у кого-то будет желание, можете провести аналогичный тест на PostgreSQL. Вся логика работы с базой инкапсулирована с специальных адаптерах. Так что для этого надо лишь написать класс, унаследовав его от абстрактного класса AbstractDBAdapter и переопределив все абстрактные методы для работы с PostgreSQL.
Как известно, тестировать базу из коробки — занятие неблагодарное и бессмысленное. Что касается MongoDB — то тут увы все плохо. База практически не тюнится, настроек по минимуму. Основной принцип MongoDB — выделять под базу отдельный сервер, а дальше база сама решит, какие данные ей сохранять в памяти, а какие сбрасывать на диск. В нескольких источниках я слышал мнение, что свободной памяти на сервере должно быть хотя бы столько, чтобы в неё умещались индексы. В случае же с MySQL настроек масса, и перед запуском бенчмарка была произведена следующая настройка:
max_connections = 10000
query_cache_limit = 32M
query_cache_size = 1024M
innodb_buffer_pool_size = 8192M
innodb_log_file_size = 512M
innodb_thread_concurrency = 16
innodb_flush_log_at_trx_commit = 2
thread_cache = 32
thread_cache_size = 16
Первое, что бросается в глаза при выполнении теста на MySQL — общее время выполнения всех задач при нарастании числа процессов-worker-ов практически не меняется:
...
Run test with 5 proceses
Test is finished! Save results
Full time: 20.7063720226
Run test with 6 proceses
Test is finished! Save results
Full time: 19.1608040333
Run test with 7 proceses
Test is finished! Save results
Full time: 19.0062150955
…
Run test with 15 proceses
Test is finished! Save results
Full time: 18.5613899231
Run test with 16 proceses
Test is finished! Save results
Full time: 18.4244360924
…
Run test with 29 proceses
Test is finished! Save results
Full time: 16.8106219769
Run test with 30 proceses
Test is finished! Save results
Full time: 19.3497707844

В 30ть параллельных процессов:
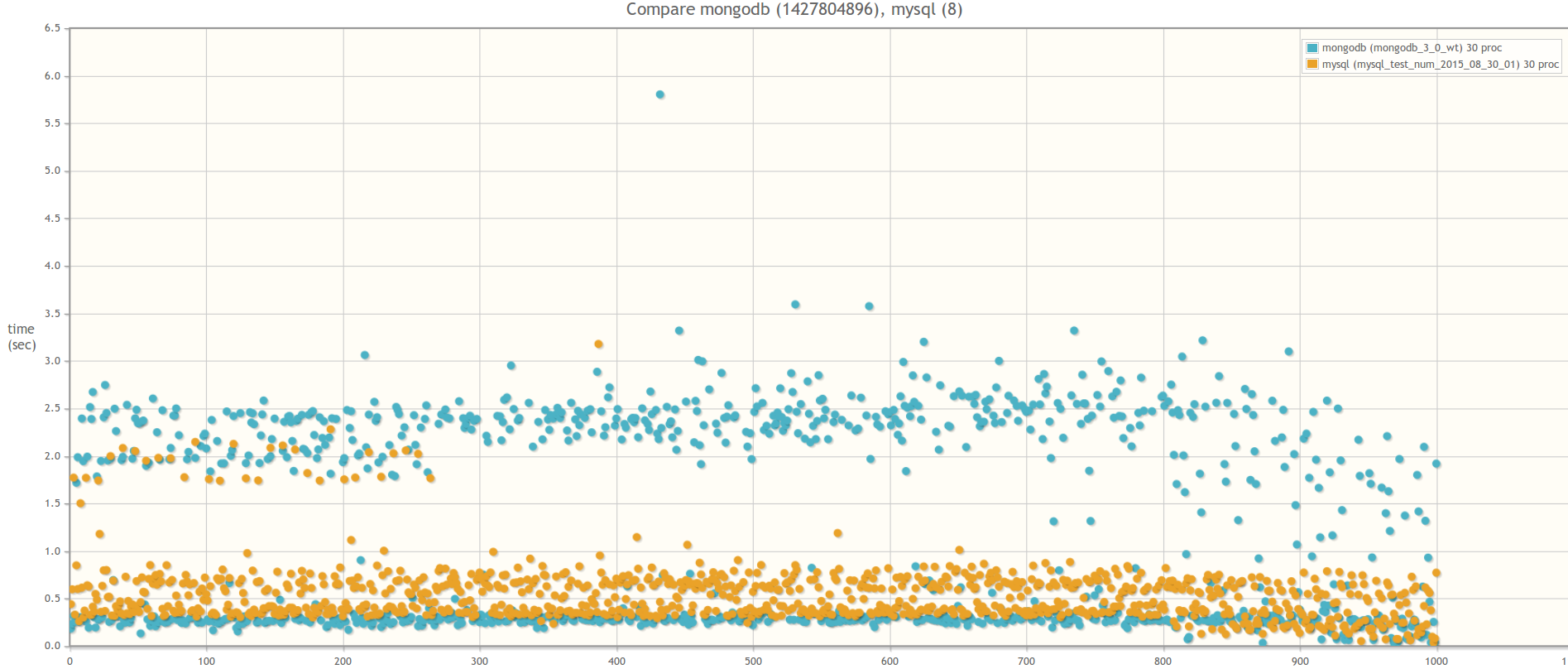
Какие выводы из этого можно сделать?
Лично я вижу для себя следующий паттерн, когда в проекте можно использовать MongoDB:
- схема данных хорошо укладывается в концепцию “толстых” слабо связных документов
- отсутствие транзакций компенсируется атомарностью операций над документами
- бизнес-логика приложения не подразумевает многочисленные массовые операции над документами.
Так же желательно, чтобы документы не удалялись часто. С этим связана еще одна небольшая проблема (я решил не выносить её в отдельный пункт). При удалении документов свободное место на диске не освобождается. MongoDB помечает блок на диске как свободный и при удобном случае использует этот блок для нового документа. По моим наблюдениям до версии 2.6 эта стратегия работала крайне неэффективно, потому как после выполнения repairDatabase на долгоживущей базе можно было уменьшить размер данных и индексов в 2 с лишним раза (!). Начиная с версии 2.6 для новых коллекций по умолчанию стала использоваться новая стратегия для преаллоцирования диска под новые документы (опция usePowerOf2Sizes) — в результате её использования размер выделяемого места под новые документы стал немного больше чем раньше, но зато свободное место после удаления документов стало использоваться более эффективно. А в версии 3.0 для движка MMAPv1 пошли еще дальше и еще раз изменили стратегию преаллоцирования, однако её эффективность в продакшене мне оценить пока не удалось. Что же происходит с движком WiredTiger в плане преаллоцирования диска, если честно, я тоже не знаю. Если у вас есть какая-либо информация по этому поводу — пишите в комментариях :-)
Комментарии (61)
PerlPower
31.08.2015 10:26Пользуясь случаем спрошу, может кто-то сталкивался с ситуацией, что в Mongo очень медленный первый поиск после рестарта. В базе не больше 100 000 записей формата { «текстовый id»: «блоб с данными» }. Первый поиск по ID может занимать около минуты, а все последующие(по любому ID) — доли секунды.

Labutin
31.08.2015 10:29+2Может быть медленные диски и долго индексы в память загружаются? (как версия)

grossws
01.09.2015 02:07Посмотрев на сегменты с помощью утилиты vmtouch, так можно понять в какой части файла был индекс. Потом можно после перезапуска базы с непрогретыми кэшами руками почитать те части файла, на которые указал vmtouch и посмотреть изменится ли поведение первого поиска.
Labutin
31.08.2015 10:28+9Почему про MongoDB в основном два типа статей?
1. Как все круто и все бегите сюда.
2. Как все плохо и близко не подходите к MongoDB.
Лично мне было бы интересней читать статьи в стиле: «Если делать вот так бездумно, то будут такие-то проблемы. Вы лучше так не делайте, а делайте вот так и будет вам счастье».
Вон про MySQL тоже есть и негатив и позитив. Но самое главное, есть те самые статьи, которые говорят о том, как обойти подводные камни и сделать то, что хотелось правильным путем.
StraNNikk
31.08.2015 10:35+6Ни в коем разе не хотел этой статьёй сказать «как все плохо и близко не подходите».
Когда на рынке появляется новая технология, которая при этом еще и активно раскручивается, то хочешь-не хочешь по началу люди начинают исполюзовать её везде, где только можно и где нельзя. Смысл этой статьи как раз в том, чтобы поделиться сложностями и своим видением на то, когда эту базу лучше использовать.

megareez
31.08.2015 12:19+3Применительно к первой проблеме описываемой автором:
Запускали монгу в полном фарше mongos + configserv + mongod. Хотя и без шардов, но все равно использовали весь стек. Все в трех ипостасиях. Приложение (php-fpm) конектилось на один из трех mongos. Как вариант можно еще воткнуть локалько на каждых сервер с приложением haproxy который будет конектиться к mongos. Описываемой проблемы подвисания конекта не возникало.
А вот с локами да, до третьей версии совсем беда. На бд размером 10-20 Гб испытывали постоянные подвисания.mobilesfinks
31.08.2015 19:22+1Относительно первой проблемы:
У нас было так. Было 2 машины с монгой (3.x версия). Одна мастер, вторая слейв. В таком варианте при выключении мастера происходит затык и подвисание. Если я не ошибаюсь и правильно помню, то восстановление так и не происходило пока обратно бывшего мастера не втыкали.
Добавили в репликасет третью машину — арбитра. После этого переключения стали достаточно быстрыми, что бы их не замечать и подвисания прекратились.StraNNikk
31.08.2015 20:11+1Да на двух машинах отказоустойчивость тестировать смысла особо нет. Надо как минимум 3 машины для кворума, ну или любое нечетное число больше 3х.
mobilesfinks
31.08.2015 20:20Поднимем 5ть small машин — 3 под базы,
Тогда в вашем случае полюбому арбитр нужен. 3-1=2 — привет splitbrain.
Попробуйте сделать то же самое только в варианте 3 под базы +1 арбитр. Я думаю подвиса не должно быть. Если сделаете тесты, то результат интересен.StraNNikk
31.08.2015 20:42Ненене, всего в реплик сете должно быть четное количество машин (минимум 3). У меня в тесте — как раз 3 машины. То, что третья машина — арбитр или просто ещё один secondary — это уже не принципиально. Если мощностей достаточно и хочется более надежной реплизкации, то делаем его еще одной репликой, если мощностей мало — то только под арбитр. При голосовании их голоса равноценны.

wickedweasel
01.09.2015 12:46+5Начало вашего комментария напомнило:
У нас было два Оптерона, 16 гигабайт оперативки, 2 гига под мемкеш, полвинчестера свободно и целое множество плагинов и модулей всех сортов и расцветок, а также Апач, MySQL и гигабайт чистого свопа. Не то чтобы это был необходимый набор для Друпала, но если начал писать на PHP, становится трудно остановиться. Единственное, что вызывало у меня опасение — это своп. Нет ничего более беспомощного, безответственного и испорченного, чем свопящийся сервер. Я знал, что рано или поздно мы перейдем и на эту дрянь.
ibash.org.ru/quote.php?id=16079wickedweasel
01.09.2015 12:50Впрочем, мой предыдщий комментарий напомнил мне вот этот: habrahabr.ru/company/pvs-studio/blog/235189/#comment_7922327
StraNNikk
31.08.2015 20:25А в какой инфраструктуре смотрели? В Amazon/DigitalPcean/VPS или прям на железках?
У меня стабильно воспроизводится на Amazon-е для версии MongoDB 2.6.x (3ку не смотрел).
Кстати, а как проверяли? Просто описанная траббла с подвисанием особенно актуальна для процессов-демонов, которые держат коннект постоянно.
Но казалось бы и фик с этой проблемой, в конце концов 45сек-1минуту даунтайма может и можно себе позволить в случае аварии, в конце концов сервера тоже не каждый день вылетают. Меня больше смущают эксепшены типа AutoReconnect, дубликаты и неоднозначное поведение python-драйвера
CeyT
31.08.2015 11:43-7Больше всего по прочтении статьи волнует непостоянность автора в использовании изобретённого им правописания числительных (даже в одном предложении: «как при 15ти процессах-обработчиках, так и при 30»). Неправильно записаны «5 000 000онов», «MySQL 5ть.5ть», «vCPU 8ight, 15teen Gb RAM» и, конечно же, «2ва» и «3ри».

alterpub
01.09.2015 10:46-2За что человека минусуют?
Абсолютно верно написал, тяжко читать такие цифры, а главное зачем?
Неужели вокруг на столько тупые люди, что «от 1 до 30» не могут прочитать и автору зачем-то пришло в голову писать «от 1го до 30ти»?
solver
01.09.2015 11:35+8Просто во круг достаточно умные люди, что бы не обращать внимания в технической статье на такую херню как написание числительных. Тем более, что все понятно.

Chamie
01.09.2015 11:54-1Понятно-то понятно, но читать штуки вроде «от 10есяти до 15ятнадцати» — несколько раздражает, согласитесь.
Chamie
01.09.2015 12:03-1Удивляет «15ть» — 15 же и так читается как «пятнадцать», к чему там дописывать «ть»?
solver
01.09.2015 15:24+5Не соглашусь.
Я в технических статьях в первую очередь смотрю на суть.
И я благодарен человеку, потратившему свое время, чтобы рассказать о своем полезном опыте.
P.S. Раздражать это может только учителей Русского языка, которым не важно что написано, а важно как.CeyT
01.09.2015 16:53-5Вы «русский» специально с большой буквы написали?
«Извозчик довезёт», всё как обычно.
alterpub
01.09.2015 11:57+4Если статья техническая, то это не подразумевает что она может быть написана как угодно, всё-таки это публичный ресурс.
Выглядит как элементарное неуважение к читателю, ИМХО.
PS: Статья хорошая, тут претензий нет.
CeyT
01.09.2015 14:20Ага, «умные люди», попробуйте не ставить знаки препинания и начинать предложения со строчной, а потом доказывайте, что это «такая херня» и «всё понятно». Не понятно. За каждое «пятьть» цепляется глаз, и внимание переходит с предмета обсуждения на то, чтобы понять, что автор в данный символ ничего особенного не закладывал, просто малограмотен. Повторите ошибки много раз, и, вместо технических выводов, статья породит только желание разгадать, по каким (неочевидным) законам ставится или не ставится костыль к цифре.
Пользоваться более чем пятью тысячами ста двадцатью девятью формами числительных в своих текстах, насколько я знаю, никто не запрещал. Более того, это предпочтительный вариант, если число само по себе не является центральным предметом интереса. Если оно важно, то можно записать его цифрой для удобства выделения из текста и сопоставления с другими. «На 3 потоках падение производительности практически незаметно: <результат теста>, но уже на 10 всё гораздо хуже: <результат теста>, из чего мы можем сделать вывод, что рост нагрузки нелинеен и при 100 потоках пользоваться системой будет невозможно». Я не верю, что есть человек, который способен тут прочесть «на три потоках», «на десять всё гораздо хуже», «при сто потоках». Следовательно, к украшательствам, да ещё и заново изобретённым без оглядки на существующие правила, можно 0тН0сиЦЦа соответственно.
DoctorChaos
03.09.2015 12:59Фразы «во круг», «что бы», «херню» и «умные люди» плохо смотрятся в одном предложении :)
lega
31.08.2015 15:38+1Во всех графиках я не увидел очень важного параметра — общее затраченное время, может быть монга отрабатывает весь тест в 10х раз быстрее, пытаясь выполнить все задачи одновременно, что вызывает торможение на каждой операции. Когда Mysql (за счет транзакции) выполняет операции последовательно, тем самым давая хорошее время для единичной операции, но большее время в итоге.
Операция обновления большого кол-ва документов — не частая задача, чаще происходит обновление по одному документу (типичное обновление), поэтому больший смысл был бы тестировать именно его.StraNNikk
31.08.2015 21:00+1Про общее затраченное время — в случае MySQL оно составляет в районе 18ти секунд на один проход количеством N (1..30) процессов по всем юзерам и практически не меняется при нарастани числа воркеров. В случае MongoDB оно составляет в районе 40секунд:
вывод консоли тут(mongodb-performance-tests)[foo@ip-10-0-0-158 tool]$ python run_test.py --adapter mongodb --name mongodb_3_0_wt
Running «mongodb_3_0_wt» test
Prepare database
Create user documents
Full time: 97.6963868141
OK! Users were created!
Run test with 1 proceses
Test is finished! Save results
Full time: 145.417565107
Run test with 2 proceses
Test is finished! Save results
Full time: 72.3193061352
Run test with 3 proceses
Test is finished! Save results
Full time: 56.4604640007
Run test with 4 proceses
Test is finished! Save results
Full time: 43.2622559071
Run test with 5 proceses
Test is finished! Save results
Full time: 38.1150348186
…
Run test with 10 proceses
Test is finished! Save results
Full time: 40.7822709084
Run test with 11 proceses
Test is finished! Save results
Full time: 39.3015518188
Run test with 12 proceses
Test is finished! Save results
Full time: 37.2085850239
Run test with 13 proceses
Test is finished! Save results
Full time: 42.0286569595
Run test with 14 proceses
Test is finished! Save results
Full time: 40.7457239628
Run test with 15 proceses
Test is finished! Save results
Full time: 45.9798600674
…
Run test with 20 proceses
Test is finished! Save results
Full time: 44.4311590195
Run test with 21 proceses
Test is finished! Save results
Full time: 46.1173479557
…
Run test with 25 proceses
Test is finished! Save results
Full time: 43.7823390961
…
Run test with 29 proceses
Test is finished! Save results
Full time: 42.1524219513
Run test with 30 proceses
Test is finished! Save results
Full time: 43.6515491009
Finish!
miga
31.08.2015 17:15+1Вы, между тем, забыли главное — в случае отвала мастера монга секунд 15 потупит и нового выберет сама, а тот же мускуль — нет.
Попробуйте, кстати, запустить тест с pymongo 3.0 — они там обещали накрутить много ништяков в плане мониторинга репликасета.
reji
31.08.2015 17:58Не могу сказать насчет репликасета, но сама монга с третьей версии стала гораздо быстрее. В реальном проекте на процентов тридцать(!).
Но нужно использовать их новый «движок».miga
31.08.2015 18:14Не только быстрее, но и меньше места жрет за счет сжатия. Когда я проверял — в разы меньше.
StraNNikk
31.08.2015 21:08-1Дык я и не говорю, что «Монго — это зло, давайте дружно переходить на MySQL» :-)
Репликация и шардинг из коробки вообще как киллер фича монги, очень подкупают.
Про эти 15ть секунд, как я и писал выше в комментариях, тоже не так страшно.
Основная траббла, в подвисании воркеров, ошибках AutoReconnect и в том, что pymongo не знает, удалось ли ему создать документ или не удалось. А самому руками генерить ObjectId в коде на каждый insert — далеко нетривиальная штука.miga
31.08.2015 21:18Не очень понял про запись. Поставьте write concern нужный и все. Там, конечно, есть свои подводные камни, но нормальным людям достаточно :)
StraNNikk
31.08.2015 21:57-1Вы не совсем меня поняли, да и наверное я объяснил не совсем правильно. Все почему-то набросились на 15ть секунд таймаута, хотя это тут вообще дело 10ое.
Основная проблема в эксепшенах типа AutoReconnect. Эти эксепшены происходят из-за проблем с сетью, не важно работаете ли вы на репликсете или шардированной конфигурации или же на одном сервере монги без ничего. Т.е. если драйвер pymongo в какой-то момент работы не получает ответ от сервера, то он райзит такой эксепшен. Один из частных случаев, как это воспроизвести — это отрубание primary в репликсете из 3х машин.
Проблема pymongo (и возможно MongoDB тоже) в том, что он не может проконтролировать, добавился ли документ в момент insert-а или же нет. Т.е. вы должны контролировать это сами в своем коде.miga
31.08.2015 23:12Почему эксепшен это проблема? Если вы его словили, то операция не выполнилась, и у вас есть выбор — попробовать еще раз или забить. Если вы пишете с определенным write concern, то база и драйвер вам более-менее гарантируют то, что после возвращения из функции записи данные попали на выбранное количество реплик. Если это не так — кидается эксепшен.
StraNNikk
31.08.2015 23:22+2Почему эксепшен это проблема?
Потому что эксепшен в данном конкретном случае не гарантирует, что запись не прошла — она могла пройти, а погла не пройти. write concern здесь вообще не при чем
emptysqua.re/blog/save-the-monkey-reliably-writing-to-mongodb
jira.mongodb.org/browse/PYTHON-197

jsirex
31.08.2015 19:34+4Вставлю свои 5 копеек. Может кто-то сталкивался и подскажет как решать вопрос.
Дано: mongodb cluster: 3 config server, 4 shard, каждый shard это реплика из 3х серверов + арбитр.
Шардирования на уровне коллекций нет. У нас много мелких баз и они равномерно размазаны по шардам.
Кластер приложения. Рядом с каждой нодой стоит router.
Баг 1.
Как воспроизвести точно не знаю. Но сценарий такой:
1. Создаём базу main (допустим она попала на sh 001)
2. Пишем туда что-нибудь
3. Удаляем базу (да. нам иногда надо снести базу полностью чтоб просто её пересоздать)
4. Создаём её опять (для примера, она попадает на sh 002)
И вот теперь проблема: роутер через который это делали, знает что база на sh 002. а остальные роутеры видимо хранят кэш и думают что база на sh 001. Последствия катастрофические: пишем документ — ок. тут же читаем — даже базы нету. Или два процесса пишут свои данные в разные базы main.
Баг 2.
Я считаю его практически блокером: отсутствие нормального бэкапа. Да, я читал все мануалы, да, я знаю про mms. Сделать консистентный бэкап — та ещё задача. Но я не придираюсь. Я готов и на «хоть какой-нибудь бэкап кое-как».
Сценарий:
1. Для бэкапа максимально одновременно я блокирую по одному слэйву из каждого шарда на запись.
2. Делаю mongodump (отрабатывает успешно) со всех шардов.
Восстановление: делаю mongorestore — в 70% я получаю duplicate error при попытке построить индекс в конце восстановления. Пробовал и с oplog, и без. Кстати, индекс применяется ДО того как oplog накатывается. Возможно, этот oplog и исправил бы проблему.
Вывод: бэкап вы сделаете. А вот восстановить — как повезёт.
Тут есть ещё разные варианты: я тестировал бэкап через LVM + тянуть прямо с файлов, а не из процесса. Работает стабильнее. Вероятно придётся перейти на этот способ.
Баг 3.
Мутный баг. Иногда просто нельзя удалить коллекцию или базу. Помогает рестарт роутеров.
И это я только с позиции админа. С позицию девелопера я лучше промолчу.
StraNNikk
31.08.2015 21:36По поводу бага 2 — вы какую версию mongo используете (с которой дамп снимаете)? случаем не 2.4? а в какую версию восстанавливаете — 2.6-3.0?
Просто интерсный баг был в версии 2.4. Вот например есть у нас коллекция со следующей структурой:
>db.entites.findOne() { "_id" : ObjectId("54837b27bf0a898b0cbb3b78"), "path" : "/home/foo/bar/", "owner_id" : 42, "some_value_1" : 1, "some_value_2" : 2, "some_value_3" : 3 } >db.entites.ensureIndex({"path": 1, “owner_id”: 1})
Т.е. поле path — хранит путь — строку произвольной длины. И вот, допустим, пользователь создает документ, где поле path длиной более 1024 символов:
>db.entites.insert({path: new Array(1025).join('x'), owner_id: 42, "some_value_1" : 1, "some_value_2" : 2, "some_value_3" : 3})
И все. Документ пропал. Выполняя запрос:
>db.entites.find({path: new Array(1025).join('x'), owner_id: 42}).count() 0
вы его не найдете. А все потому-то:
http://docs.mongodb.org/manual/reference/limits/#Index-Key-Limit
The total size of an index entry, which can include structural overhead depending on the BSON type, must be less than 1024 bytes.
То есть монга 2.4 разрешает документ создать, но не добавляет его в индекс, потому что поле path больше максимально возможной длины.
Кстати вот такой запрос-таки найдет пропавший документ:
>db.entites.find({path: new Array(1025).join('x'), owner_id: 42}).hint({_id: 1}).pretty()
А вот монга 2.6 такой документ создавать не разрешает и на моменте insert-а кидает эксепшен:
> db.entites.insert({path: new Array(1025).join('x'), owner_id: 42, "some_value_1" : 1, "some_value_2" : 2, "some_value_3" : 3}) WriteResult({ "nInserted" : 0, "writeError" : { "code" : 17280, "errmsg" : "insertDocument :: caused by :: 17280 Btree::insert: key too large to index, failing test.entites.$path_1_owner_id_1 1037 { : \"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx...\" }" } })
В любом случае, я бы посоветовал бы вам делать mongorestore c ключиками --drop (чтобы на всякий пожарный удалить существующую коллекцию если она есть) и --noIndexRestore (чтобы при восстановлении восстановить без индексов, а потом их нагнать руками)jsirex
31.08.2015 21:44Монгу используем 2.6.6
Восстанавливаю всегда в пустую базу.
noIndexRestore + потом руками — в чём смысл? А если я не знаю какие индексы надо создавать. Ковыряться в дампе и искать их?
А что насчёт автоматизации? Мне надо автоматически раскидывать дампы на разные окружения. И я не могу сделать нормальный restore.
А как же 3 вида админов: кто не делает бэкапы, кто делает и тот кто проверяет :)StraNNikk
31.08.2015 21:47не, ну я к тому, что для начала надо понять почему нельзя сделать нормальный ресторе. Т.е. локализовать проблему — т.е. это проблема утилиты mongorestore или проблема схемы данных или проблема что дамп при помощи утилиты mongodump делается как-то неправильно. Т.е. один раз руками расковырять, разобраться, решить проблему, а потом автоматизация и пр.
jsirex
31.08.2015 21:54Легко на словах. А на деле не так просто понять.
Вот я залочил базу (слэйв).
Я сделал mongodump. Результат — ок. Ошибок не было. Команда успешно завершена.
Как мне определить, что mongodump отработал не верно?
Делаю restore — ошибка. Плохие данные? Ошибка в restore?
А размер 45 GB дампа.
ПС. И это хорошо, что мы пока коллекции не шардируем. С таким ненадёжным бэкапом если оно упадёт, а все коллекции размазаны по всем базам, до кучи баги роутеров с кэшем, восстановить это будет нереально.
StraNNikk
31.08.2015 22:07ну я бы для начала накатил бы коллекцию без индексов (mongorestore --noIndexRestore), далее посмотрел бы какие индексы используются в той коллекции, с которой вы сняли дамп, затем по одной начал бы накатывать эти индексы на восстановленную коллекцию, а там уже — на каком индексе сломалось, надо смотреть, что не так с данными. Скорее всего команда, которая ракатывает индекс, выдаст сообщение на каких конкретно данных она сломалась, и что ей не понравилось.
Да, я понимаю, что процесс не быстрый. Но как вариант решения — сгодится

antage
01.09.2015 02:47+2query_cache_size = 1024M
Я бы не рекомендовал ставить такие большие значения. MySQL будет блокироваться при инвалидации кэша ощутимо дольше, чем при кэше в 128-256MB, что на практике может приводить к «затыкам».
haydenjames.io/mysql-query-cache-size-performance
SerPro
01.09.2015 15:26В новой версии 3.0 создатели утверждают, что с переходом на альтернативный движок WiredTiger ситуация должна улучшиться, поскольку он использует блокировки на уровне документа, а не блокирует базу целиком, как было в движке MMAPv1.
В MMAPv1 блокировка на уровне коллекции, а не базы.StraNNikk
01.09.2015 15:34Да, точно. С 3.0 блокировка на уровне коллекций:
docs.mongodb.org/manual/release-notes/3.0/#mmapv1-concurrency-improvement
MMAPv1 Concurrency Improvement
In version 3.0, the MMAPv1 storage engine adds support for collection-level locking.
Как-то упустил это из виду. Видимо слишком увлекся релиз нотисами про WiredTiger.

uaoleg
01.09.2015 21:52+1Вообще-то ещё в марте вышла 3.0, где lock на уровне документа. И перейти на новый движок WiredTiger ничего не стоит. Так что статья не актуальна с момента публикации.
StraNNikk
01.09.2015 22:05Мне кажется вы как-то поспешно делате выводы, не прочитав пункт про Global lock. Там говорится и про 3.0 и про WiredTiger в том числе
uaoleg
01.09.2015 22:12Не ясно зачем писать про global lock, который неактуален уже несколько лет, писать заголовком. А где-то в тексте дописать, мол да, не актуально уже. И даже collection lock не актуален, т.к. повторюсь, что смигрировать на WiredTiger можно очень быстро. Собрать плюсиков от толпы хейтеров?
п.с. статью, если что, прочитал полностью ;)StraNNikk
01.09.2015 22:42+11. То что в Mongo 3.0 MMAP лок на уровне коллекции, а не на уровне базы — это не сильно спасает. А про WiredTiger в плане производительности говорить о каком-то прорыве еще рано. Да он в каких-то кейсах он быстрее MMAP, но реляционным БД продолжает проигрывать. Вот тут например пишут, что у WiredTiger медленный поиск по ключу, потому что он не может поместить индекс в память. Совсем не good.
2. Даже если проект делается с нуля — использовать ли WiredTiger или не использовать — это большой вопрос. WiredTiger — если что, еще даже не движок по умолчанию. Если посмотреть багтрекер 10gen, то в WiredTiger много всего интересного. Например, вот:
jira.mongodb.org/browse/SERVER-20204
или вот:
jira.mongodb.org/browse/SERVER-17456
Вы с такими багами пойдете в продакшен? я вот что-то сомневаюсь.
3.смигрировать на WiredTiger можно очень быстро
Начнем с того, что данные надо мигрировать через backup-restore. Это процедура совсем не быстрая Вот у меня есть база 2.6 на 20млн нод активных данных с двумя шардами и репликацией. Запись идет постоянно, чтение тоже постоянно.
Вы думаете я рискну взять и обновить базу только потому что вышел новый движок? :-) Да даже если бы и не надо было делать backup-restore обновление продакшен базы с одной мажорной версии на другую черевато проблемами. А уж зная MongoDB и как ребята по стартаперски рубят обратную совместимость…uaoleg
01.09.2015 22:57-21. Ещё раз, DB Level Lock был пофикшен в MongoDB 2.2 ещё в далёком 2012 году.
2. WiredTiger пока не по умолчанию исключительно по одной причине: чтобы разработчики не боялись обновляться на 3-ю версию.
3. Да, вот так жестоко зарублена обратная совместимость, что даже новый, полностью совместимый движок, не включен по умолчанию.StraNNikk
02.09.2015 00:55+11. Ещё раз, DB Level Lock был пофикшен в MongoDB 2.2 ещё в далёком 2012 году.
У меня складывается ощущение что вы не смотрели ссылку, которую сюда же сами и написали. Там написано «MongoDB 2.2 increases the server’s capacity for concurrent operations with the following improvements: DB Level Locking, Improved Yielding on Page Faults»
В MongoDB 2.2 global lock был переведен с уровня процесса mongod на уровень базы. Плюс добавили «приспускание» лока во время долгих операций (аля update/delete). Ни о каком фиксе и речи не идет. Он как был так до сих пор и есть. Просто сужают область — сначала был процесс mongod, потом сделали на уровне БД. В MongoDB 3.0 сделали на уровне коллекции.
WiredTiger пока не по умолчанию исключительно по одной причине: чтобы разработчики не боялись обновляться на 3-ю версию.
Сомневаюсь. Баги на багтрекере говорят об обратном
Да, вот так жестоко зарублена обратная совместимость, что даже новый, полностью совместимый движок, не включен по умолчанию.
Про проблемы обратной совместимости хотя бы между 2.4 и 2.6 я писал уже выше.grossws
02.09.2015 05:22+1Недавно в WT был баг с silent data corruption при использовании zlib. Потом мы словили развал всей базы (kernel panic на операции записи на диск), что привело к невосстановимо поврежденной базе… Но это было на уровне 3.0.1-3.0.2, может сейчас ситуация получше ,)
uaoleg
02.09.2015 11:27+1Да, я дейтсвительно недопонял, что это только импрувмент, а не выпиливание. А выпили (заменили на collection-level locking для MMAPv1, и на document-level locking для WiredTiger) таки только в 3.0.
lega
01.09.2015 23:57но реляционным БД продолжает проигрывать
Это зависит от задачи, можно наделать тестов где mysql будет проигрывать, например поиск в массивах, вычерпывание очереди, upsert, sparse, плавающие размеры данных и т.д.
Тут например монга обошла в 20-100 раз mysql.
Так же пару лет назад были популярные статьи как компании переходили с *sql на mongodb и получали х10 ускорение…
А то что у вас такие конские апдейты, возможно говорит о не продуманной архитектуреКаждая задача — обновление булевого поля всех 5 000 документов пользователя.
В данном случае можно было просто обновить один документ пользователя и все.StraNNikk
02.09.2015 01:10Это зависит от задачи, можно наделать тестов где mysql будет проигрывать, например поиск в массивах, вычерпывание очереди, upsert, sparse, плавающие размеры данных и т.д.
Тесты тестам рознь. Если тестировать БД что называется «из коробки», то грош цена таким тестам. В той статье, что вы привели, помоему так и есть. Особенно судя по вот этому абзацу:
Тут например монга обошла в 20-100 раз mysql.
>Use case #1: Insertion of millions of records in parallel:
…
>The winner in this use case is MyISAM engine. MyISAM doesn’t neither support foreign key constraint nor transactions (unlike InnoDB). MyISAM index works good in insertion operation given that the record size will be changed, but it will be bad in case of delete/update operation.
То есть люди явно не настроили параметр innodb_flush_log_at_trx_commit в конфигах для InnoDB. Но казалось бы и пофик. Пусть даже этот тест правдив. Еще раз хочу сказать, цель данной статьи — не сказать, какая MongoDB плохая, а MySQL такой весь из себя хороший. Цель — поделиться мнением, когда MongoDB можно использовать, а когда могут возникнуть сложности.
А то что у вас такие конские апдейты, возможно говорит о не продуманной архитектуре
Конкретно в моем проекте такого количества апдейтов нет. Но тем не менее проблема с массовыми операциями есть — они выполняются не так быстро, как хотелось бы. Пример, который я привел в статье — это бэнчмарк.

umputun
03.09.2015 08:23+1А зачем ReadPreference.SECONDARY_PREFERRED, как оно вообще относится к отказо-устойчивам write?
По поводу проблем подвисания коннекта, я советую попробовать вместо остановки инстанса в вашем тест убить процесс монги — результат может удивить. Я не на 100% уверен, т.к. с питоновым драйвером почти не общался, но у меня есть такое ощущение, что проблема вечного коннекта и неполучения отлупа это либо специфика AWS сетевой инфраструктуры, либо косяк в питоновом драйвере.
А что касается многократной записи и дупликатов — в относительно свежих версиях java драйвера есть поддержка retry policy, которая как раз для этого придумана. Ну и очевидно, что и без всякой поддержки в драйвере это решается элементарно, созданием DBObject (или что там вместо него в питоне) вне цикла, и запись с одним и тем же _id не пройдет.
По поводу выбора нового мастера за минуту — ни разу такого не видел, обычно это вопрос 2-5 секунд.
> Если через 5ть секунд драйвер PyMongo не получает от базы никакого ответа, то он сбрасывает соединение и выплевывает ошибку. Не самое классное решение — вдруг база перенагружена или запрос очень тяжелый и выполняется более 5ти секунд
Тут какая-то путаница. Эти 5 секунд не таймаут на запрос, но таймаут на коннект. И если запрос выполняется даже 10 минут, драйвер его не сбросит, во всяком случае нормально написанный драйвер.
Я бы скорее назвал статью «особенности питонового драйвера монги в AWS инфраструктуре», чем такое желтоватое как сейчас.StraNNikk
03.09.2015 10:31>А зачем ReadPreference.SECONDARY_PREFERRED, как оно вообще относится к отказо-устойчивам write?
потому что read тоже зависает. чтобы он не зависал при гибели мастера нужно чтобы он читал с secondary
>По поводу проблем подвисания коннекта, я советую попробовать вместо остановки инстанса в вашем тест убить процесс монги — результат может удивить
зачем? мне интересна именно смерть инстанса а не смерть процесса. Смерть процесса это как раз-таки случай не такой частый
>Ну и очевидно, что и без всякой поддержки в драйвере это решается элементарно, созданием DBObject (или что там вместо него в питоне) вне цикла, и запись с одним и тем же _id не пройдет.
ну собственно в статье про это и написано. Только это совсем не элементарно и не интуитивно понятно. Да и выглядит как костыль костылем
>Тут какая-то путаница. Эти 5 секунд не таймаут на запрос, но таймаут на коннект. И если запрос выполняется даже 10 минут, драйвер его не сбросит, во всяком случае нормально написанный драйвер.
нет, на коннект как раз-таки есть свой таймаут. он называется connectTimeoutMS: api.mongodb.org/python/current/api/pymongo/mongo_client.html#pymongo.mongo_client.MongoClient
umputun
03.09.2015 11:10> потому что read тоже зависает. чтобы он не зависал при гибели мастера нужно чтобы он читал с secondary
это какая-то мистика. ReadPreference.SECONDARY_PREFERRED не значит, что «если мастер недоступен, то читать с slave», но значит, что мы всегда позволяем читать с него. Единственное, чему это поможет в смысле высокой доступности, что чтение будет доступно пока не закончились выборы нового мастера.
> зачем? мне интересна именно смерть инстанса а не смерть процесса.
Затем, что если остановка инстанса не закрывает коннект (я такое читал на их форуме) по причинам/особенностям организации сетевого стека AWS, то это тогда не про «монго не поняла / работает не так», но коннект не сбросился на стороне амазона, что относится к монго ровно настолько, насколько оно относится к любому приложению работающему с сокетами.
> Только это совсем не элементарно и не интуитивно понятно
А какого волшебного поведения вы в этой ситуации ожидали? Что произойдет что именно? На фоне отсутствия транзакций, такое поведение как раз вполне ожидаемо. Если хочется транзакций — ну так либо сделайте их сами, либо принимайте то, что в монге их нет и обеспечение целостности данных это задача приложения.
umputun
03.09.2015 11:18и да, с практической точки зрения вам надо использовать heartbeat, где можно задать для пула и частоту, и таймаут и все прочее (в java driver это heartbeatConnectRetryFrequency и прочие heartbeatConnectTimeout). Тогда зависший коннект не подвесит весь мир.
StraNNikk
03.09.2015 12:29>ReadPreference.SECONDARY_PREFERRED не значит, что «если мастер недоступен, то читать с slave», но значит, что мы всегда позволяем читать с него.
Ну таки да. Всегда читаем со слейв, и тем самым обходим проблему. Именно это я и имел ввиду.
>Затем, что если остановка инстанса не закрывает коннект (я такое читал на их форуме) по причинам/особенностям организации сетевого стека AWS,
Как то очень странно звучит. У других приложений такой проблемы не наблюдалось :-)
>А какого волшебного поведения вы в этой ситуации ожидали?
Ну как минимум, что будет гарантирован результат — удалось записать данные или не удалось. А не просто «ошибка, а дальше сам гадай, записалось оно или нет». Тут дело не в транзакциях. Тарнзакции это дело 10ое. В тех же самых РСУБД вы можете не использовать транзакции, и тем не менее они гарантируют результат записи.
Optik
Подброшу еще камней в огород.