
Стек TypeScript, Сanvas и веб-аудио позволяет эмулировать компьютерные системы с использованием веб-технологий. В докладе я на примере приставки NES рассказал, как устроена архитектура компьютеров — процессор, программа, периферийные устройства, отображение I/O на память.
Доклад можно разделить на три части:
Я постарался дать советы по оптимизации. Всё же эмуляция — дело такое, при 60 FPS остаётся мало времени на выполнение кода.
— Всем привет, меня зовут Женя. Сейчас будет немного необычный доклад, субботний, о проекте на много суббот. Поговорим об эмуляции компьютерных систем, которую можно реализовать поверх существующих веб-технологий. На самом деле в вебе уже довольно богатый инструментарий, и можно делать совершенно поразительные штуки. Если конкретно, мы поговорим об эмуляторе всем, наверное, известной приставки Денди из 90-х, которая на самом деле называется Nintendo Entertainment System.

Давайте немножко вспомним историю. Она началась в 1983 году, когда в Японии вышла приставка Famicom. Ее выпустила компания Nintendo. В 1985 году вышла американская версия, которая называлась Nintendo Entertainment System. В 90-х у нас был тот самый тайваньский регион под названием Денди, но по секрету, это неофициальная приставка. И последний такой железный подарок от Nintendo был в 2016-м, когда вышла NES mini. У меня, к сожалению, NES mini нет. Есть SNES mini, Super Nintendo. Посмотрите, какая маленькая штука, и прямо на этом слайде можно наблюдать закон Мура во всей красе.
Если мы посмотрим на 1985 год и соотношение приставки к джойстику, и на 2016-й, то можно заметить, насколько все стало меньше, потому что руки у людей не меняются, джойстик меньше не сделаешь, но сама приставка стала крохотной.
Как мы уже заметили, эмуляторов много. Мы это не проговорили, но как минимум один официальный заметили. Эта штучка — SNES mini или NES mini — на самом деле, не настоящая приставка. Это железяка, которая делает эмуляцию приставки. То есть по сути это официальный эмулятор, но который идет в таком забавном железном виде.
Но как мы знаем, еще с 2000-х есть программы, которые эмулируют NES, благодаря которым мы можем до сих пор наслаждаться играми из той эпохи. И эмуляторов много. Зачем еще один, тем более на JavaScript, спросите вы меня? Когда я эту штуку делал, то для себя нашел три ответа на этот вопрос.
Я еще смотрел презентацию Мэтта Годболда, который тоже рассказывал про эмуляцию процессора, на котором работает NES. Он сказал — забавно, что мы эмулируем такую низкоуровневую штуку на таком высокоуровневом языке. У нас нет доступа к железу, мы работаем опосредованно.

Давайте уже перейдем к рассмотрению того, что мы же будем эмулировать, как мы будем эмулировать и т. д. Начнем мы с процессора. Сама приставка NES — знаковая. Для России — понятно, это культурный феномен. Но и на Западе, и на Востоке, в Японии, это тоже был культурный феномен, потому что приставка, по сути, спасла всю индустрию домашних видеоигр.
Процессор в ней тоже установлен знаковый, это MOS6502. В чем его знаковость? В то время, когда он появился, его конкуренты стоили 180 долларов, а MOS6502 стоил 25 долларов. То есть этот процессор запустил революцию персональных компьютеров. И тут у меня представлены два компьютера. Первый — Apple II, мы все знаем и представляем, насколько знаковым для мира персональных компьютеров было это событие.
Еще есть компьютер BBC Micro. Он был больше популярен в Британии, BBC — британская телевизионная корпорация. То есть этот процессор внес компьютеры в массы, благодаря ему мы сейчас программисты, фронтендеры.
Давайте рассмотрим программу-минимум. Что нам нужно, чтобы сделать вычислительную систему?

Сам по себе CPU — устройство довольно бесполезное. Как мы знаем, CPU выполняет программу. Но как минимум для того, чтобы эта программа где-то хранилась, нужна память. И в программу-минимум она, разумеется, входит. А память у нас состоит из ячеек по восемь бит, которые называются байтами.
В JavaScript мы можем использовать типизированные массивы Uint8Array, чтобы эмулировать эту память, то есть мы можем выделить массив.
Чтобы память имела интерфейс с процессором, существует шина. Шина позволяет процессору адресовать память через адреса. Адреса состоят уже не из восьми бит, как данные, а из 16, что позволяет нам адресовать 64 килобайта памяти.

В процессоре находится некое состояние, тут есть три регистра — A, X, Y. Регистр — это как бы хранилище для промежуточных значений. Размер регистра — один байт или восемь бит. Это говорит нам о том, что процессор восьмибитный, он оперирует восьмибитными данными.
Пример использования регистра. Мы хотим сложить два числа, но шина в памяти одна. Получается, нужно где-то промежуточно сохранить первое число. Сохраняем его в регистр A, можем взять из памяти второе значение, сложить их, и результат опять же помещается в регистр A.
Функционально эти регистры довольно независимые — их можно использовать как общие. Но у них появляется смысл, как, например, сложение, в регистре A получается результат и берется значение первого операнда.
Или, например, адресуем данные. Про это мы поговорим чуть позже. Можем указать режим адресации со смещением и использовать регистр X для получения финального значения.
Что еще входит в состояние процессора? Есть регистр PC, который указывает на адрес текущей команды, поскольку адрес — это два байта.
Еще у нас есть регистр Status, который указывает на флаги статуса. К примеру, если мы вычли два значения и получилось отрицательное, то зажигается определенный бит в регистре флага.
Наконец, есть SP, указатель на стек. Стек — это просто обычная память, она никак не отделена от всего остального, от всех остальных программ. Просто есть инструкция у процессора, который управляет этим указателем SP. Таким образом реализован стек. Потом мы посмотрим на одну великую компьютерную идею, которая приводит к таким интересным решениям.

Теперь мы знаем, что есть процессор, память, состояние в процессоре. Посмотрим, что же представляет собой наша программа. Это некая последовательность байт. Она даже не обязательно должна быть последовательной. Сама программа может находиться в разных участках памяти.
Мы можем представить программу, у меня здесь кусочек кода — 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. Это реальная программа на 6502. Каждый байт этой программы, каждая цифра в этом массиве представляет собой такую сущность, как опкод. Опкод — код операции. «то, опять же, обычное число.
Например, есть опкод 169. Он кодирует в себе две штуки — во-первых, инструкцию. Инструкция при выполнении меняет состояние процессора, памяти и так далее, то есть состояние системы. Например, мы складываем два числа, в регистре A появится результат. Это пример инструкции. Еще у нас есть инструкция LDA, которую мы будем более детально рассматривать. Она загружает значение из памяти в регистр A.
Вторая штука, которую кодирует опкод, — режим адресации. Он говорит инструкции о том, где ей взять данные. Например, если это режим адресации IMM, то он говорит: возьми данные, которые находятся в ячейке, следующей за текущим программным счетчиком. Мы тоже посмотрим, как работает этот режим и как его можно реализовать на JavaScript.
Такая вот программа. Помимо этих байтиков, все очень похоже на JavaScript, только более низкоуровневое.

Если вспомнить, о чем я рассказывал, может выйти забавный парадокс. Мы, получается, храним программу в памяти, и данные тоже. Можно задать такой вопрос: может ли программа выступать в роли данных? Ответ — да. Мы можем из программы изменить ее же саму в момент выполнения этой программы.
Или другой вопрос: могут ли данные выступать в роли программы? Тоже да. Процессору без разницы. Он просто, как мельница, перемалывает байты, которые ему скармливают и выполняет инструкции. Парадоксальная штука. Если вдуматься, это супернебезопасно. Можно начать выполнять программу, которая является просто данными на стеке и т. д. Но преимущество в том, что это суперпросто. Не надо сложную схемотехнику делать.
Это такая первая великая идея, с которой мы сегодня столкнемся. Называется она архитектурой фон Неймана. Но там на самом деле было много соавторов.
Тут иллюстрируется. Есть программа 1, опкод 169, за ним 10, какие-то данные. Окей. Эту программу можно рассмотреть еще и так: 169 — данные, а 10 — опкод. Это будет легальная программа для 6502. Всю эту программу, опять же, можно рассматривать как данные.
Если у нас есть компилятор, мы можем собрать что-то, положить в этот участок памяти, и будет такая забавная штука.
Давайте посмотрим на первую составляющую нашей программы — инструкции.

6502 предоставляет доступ к 73 инструкциям, среди которых есть арифметика: сложение, вычитание. Нет умножения и деления, извините. Есть битовые операции, они про манипуляции с битами в восьмибитных словах.
Есть прыжки, которые у нас во фронтенде запрещены: оператор jump, который просто переносит программный счетчик к какому-то участку кода. Такое запрещено в программировании, но если вы имеете дело с low level, это единственный способ сделать ветвление. Есть операции для стека и т. д. Они сгруппированы. Да у нас 73 инструкции, но если посмотреть по группам и на то, что они делают, то их на самом деле не так много и они все довольно похожи.
Вернемся к инструкции LDA. Как мы говорили, это «загрузи из памяти значение в регистр A». Вот так суперпросто ее можно реализовать в JavaScript. На входе адрес, который нам поставляет режим адресации. Мы меняем внутри состояние, говорим, что this._a равно прочитанному значению из памяти.
Нам еще нужно установить в статусном регистре два этих битовых поля — нулевой флаг и флаг отрицательного значения. Тут множество всяких побитовых штук. Но если вы будете делать эмулятор, это станет вашей второй натурой — заниматься этими OR, отрицаниями и т. д. Единственное, что тут забавно, — есть такой % 256 во второй ветке. Он отсылает нас, опять же, к природе нашего любимого языка JavaScript, к тому, что у него нет типизированных значений. Значение, которое мы помещаем в Status, может выйти за 256, которые помещаются в один байт. Приходится заниматься такими ухищрениями.
Теперь посмотрим на финальную часть нашего опкода, на режим адресации.

У нас есть 12 режимов адресации. Как мы уже говорили раньше, они позволяют нам доставать и указывать для инструкции, откуда ей взять данные.
Давайте рассмотрим три штучки. Последний — ABS, абсолютный режим адресации, начнем рассматривать с него, извиняюсь за небольшой конфуз. Он делает примерно следующее. Мы на вход ему даем полный адрес, 16 бит. Он нам достает значение из этой ячейки памяти. В ассемблере во второй колонке можно наблюдать, как это выглядит: LDA $ccbb. ccbb — шестнадцатеричное число, обычное число, просто записанное в другой нотации. Если вы здесь чувствуете себя некомфортно, помните, что это просто число.
В третьей колонке можно наблюдать, как это выглядит в машинном коде. Впереди идет опкод — 173, подсвечен синим. А 187 и 204 — это уже данные адреса. Но поскольку мы оперируем с восьмибитными значениями, нам нужно две ячейки памяти, чтобы записать адрес.
Я еще забыл сказать, что опкод выполняется некоторое время на CPU, у него есть определенная стоимость. LDA с абсолютной адресацией выполняются четыре цикла CPU.
Тут уже можно понять, зачем нужно столько режимов адресации. Рассмотрим следующий режим адресации, ZP0. Это режим адресации по нулевой странице. А нулевая страница — это первые 256 байт, размещенные в памяти. Это адреса от нуля до 255.
В ассемблере, опять же, LDA *10. Что этот режим адресации делает? Он говорит: сходи в нулевую страницу, вот в эти первые 256 байт, с таким-то смещением. в данном случае 10, и возьми оттуда значение. Тут мы уже замечаем существенное различие между режимами адресации.
В случае с абсолютной адресацией нам потребовалось, во-первых, три байта, чтобы записать такую программу. Во-вторых, нам потребовалось четыре цикла CPU. А в режиме адресации ZP0 потребовалось всего три цикла CPU и два байта. Но да, мы потеряли гибкость. То есть мы можем помещать свои данные только в первую страницу, вот эту.
Финальный режим адресации IMM говорит: возьми данные из ячейки, следующей за опкодом. Эта LDA #10 в ассемблере такое делает. И получается, программа выглядит как [169, 10]. Она уже требует два цикла CPU. Но тут понятно, что мы тоже теряем гибкость, и нам нужно, чтобы опкод был рядом с данными.
Реализовать это в JavaScript проще простого. Вот пример кода. Есть адрес. Это IMM адресация, которая как раз берет из программного счетчика данные. Мы просто говорим, что наш адрес — это программный счетчик, и увеличиваем его на один, чтобы при следующем выполнении программы он уже перескочил на следующую команду.
Вот такая забавная штука. Мы теперь умеем читать машинный код как фронтендеры. И даже умеем смотреть, что там в ассемблере написано.

Мы уже в принципе знаем все, что нужно. Есть программа, она состоит из байт. Каждый байт — опкод, каждый опкод — инструкция и т. д. Посмотрим, как выполняется наша программа. А выполняется она как раз в этих циклах CPU.
Как такой код можно сделать? Пример. Нам нужно считать опкод из программного счетчика, потом просто его увеличить на один. Теперь нам нужно этот опкод как раз декодировать в инструкцию и в режим адресации. Если подумать, опкод — это простое число, 169. А в байте у нас всего 256 чисел. Мы можем сделать массив на 256 значений. Каждый элемент этого массива просто будет отсылать нас к тому, какую инструкцию надо использовать, какой нужен режим адресации и сколько циклов это займет. То есть это суперпросто. И массив у меня лежит как раз в состоянии процессора.
Дальше мы просто выполняем функцию режима адресации на 36 строке, которая дает нам адрес, и скармливаем его инструкции.
Что нам нужно сделать финально, так это разобраться с циклами. opcodeResolver возвращает количество циклов, мы их записываем в переменную remainingCycles. На каждый цикл процессора мы смотрим: если осталось ноль циклов, то можем выполнить следующую команду, если больше нуля — мы просто уменьшаем его на один. И все, суперпросто. Так выполняется программа на 6502.

Но как мы уже говорили, программа может находиться в разных участках памяти, в разных соотношениях и т. д. Как вообще процессору понять, откуда начать выполнять эту программу. Нам нужен такой int main из мира C.
На самом деле, все просто. У процессора есть процедура сброса его состояния. В этой процедуре мы берем адрес начальной команды из адреса 0xfffxc. 0xfffxc — опять шестнадцатеричное число. Если чувствуете себя не комфортно, забейте, это обычное число. Так они в JavaScript пишутся, через 0x.
Нам нужно считать два байта адреса, адрес 16 бит. Мы считаем младшие байты из этого адреса, старшие байты из следующего за ним адреса. И потом складываем это дело такой магией битовых операций. Кроме того, сброс состояния процессора сбрасывает еще значение в регистрах — регистр A, X, Y, указатель на стек, статус. Сброс занимает восемь циклов. Такая вот штука.
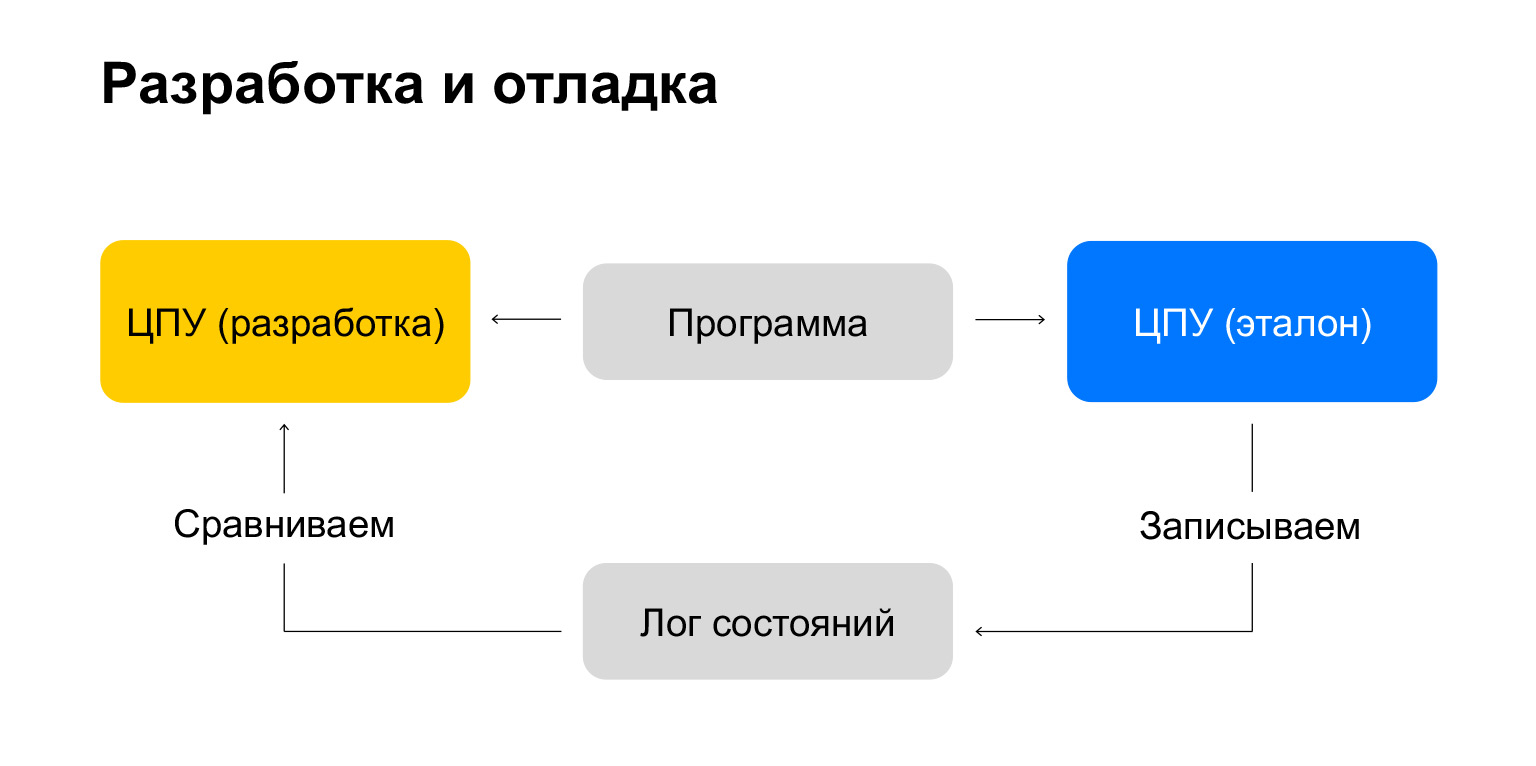
Мы теперь уже все, на самом деле, знаем. Честно скажу: для меня было отчасти сложно все это написать, потому что я вообще не понимал, как это тестировать. Мы пишем целый компьютер, который может выполнять любую когда-либо созданную для него программу. Как понять, что мы двигаемся правильно?
Есть супергениальный и замечательный способ! Берем два CPU. Первый — тот, который мы делаем, второй — эталонный CPU, мы точно знаем, что он работает хорошо. Например, есть эмулятор для NES, nintendulator, который считается таким эталоном CPU.
Берем определенную тестовую программу, выполняем ее на эталонном CPU и на каждую команду записываем состояние процессора в лог состояний. Потом берем эту программу и выполняем ее на нашем CPU. И каждое состояние после каждой команды сравниваем с этим логом. Суперидея!
Конечно, нам эталон CPU не нужен. Нам просто нужен лог выполнения программы. Этот лог можно найти на Nesdev. На самом деле, эмулятор процессора можно написать, не знаю, за пару дней на выходных — это прямо суперштука!
И все. Берем лог, сравниваем состояние, и у нас получается интерактивный тест. Выполняем первую команду, она у нас не реализована в процессоре, который мы разрабатываем. Мы ее реализовываем, переходим к следующей строке лога и опять же реализовываем. Супероперативно! Позволяет двигаться быстро.
Теперь у нас есть CPU, который, по сути, сердце нашего компьютера. И мы можем посмотреть, из чего состоит архитектура самой NES и как делаются такие сложные составные компьютерные системы. Потому что, если подумать, ну есть CPU, есть память. Мы можем значения получать, записывать и т. д.

Но в NES, в любой телевизионной приставке есть еще экран, звуковые устройства и т. д. Нам нужно учиться работать с периферией. Для этого даже не нужно узнавать ничего нового, достаточно концепции нашей шины. Это, наверное, вторая такая гениальная идея, гениальное открытие, которое я для себя сделал в процессе написания эмулятора.
Давайте представим, что мы возьмем нашу память, в которой было 64 килобайта, и разобьем ее на два диапазона по 32 килобайта. В младшем диапазоне будет находиться некое устройство, которое представляет собой массив лампочек, как на картинке с этим табло.
Скажем, что при записи в этот младший 32-килобайтный диапазон лампочка будет зажигаться либо тухнуть. Если мы записываем туда значение 1, лампочка зажигается, если 0 — тухнуть. При этом мы можем считать значение и понять состояние системы, понять, какая картинка выведена на этот экран.
Опять же, в старший диапазон адресов мы ставим обычную память, в которой находится программа, потому что нам нужно, чтобы при процедуре сброса в старшем диапазоне был адрес.
Это на самом деле супергениальная идея. Чтобы взаимодействовать с периферией, не нужны дополнительные команды и т. д. Мы просто пишем в старую добрую память, как раньше. Но при этом память уже может представлять собой дополнительные устройства.

Теперь мы уже полностью готовы рассмотреть архитектуру NES. У нас есть CPU и его шина, как обычно. Есть два дополнительных килобайта памяти. Есть APU — устройство вывода звука. К сожалению, сейчас мы его не рассмотрим, но там тоже все суперкруто. И есть картридж. Он помещен в верхний диапазон и поставляет данные о программе. Еще он поставляет данные графики, сейчас рассмотрим. Последняя штука, которая есть на шине CPU, — это PPU, picture processing unit, такая протовидеокарта. Если вы хотели научиться работать с видеокартами, мы сейчас даже узнаем, как реализовать одну.
У PPU тоже есть своя шина, на которую смещаются таблицы имен, палитры и графические данные. Но графические данные поставляет картридж. И еще есть память объекта. Вот такая архитектура.

Давайте посмотрим, что такое картридж. Это намного более крутая идея, чем компакт-диск, если учесть, что она из прошлого.
Чем же она крута? Слева мы можем видеть картридж американского региона, знаменитую игру Zelda, если кто не играл — поиграйте, супер. И если мы разберем этот картридж, то обнаружим в нем микросхемы. Там нет лазерного диска и т. д. Обычно эти микросхемы просто содержат некие данные. Также картридж напрямую врезается в нашу компьютерную систему, в шину CPU и PPU. Это позволяет делать удивительные вещи, расширять пользовательский опыт.
На борту картриджа есть mapper, он заправляет трансляцией адресов. Предположим, у нас большая игра. Но в NES есть всего 32 килобайта памяти, которые она может адресовать под программу. А игра, предположим, 128 килобайт. mapper может на лету, во время выполнения программы, подменить определенный диапазон памяти на совершенно новые данные. Мы можем сказать в программе: загрузи нам уровень 2, и память напрямую, почти что мгновенно подменится.
Плюс там есть забавные штуки. Например, mapper может поставлять чипы, которые расширяют звуковые дорожки, добавляют новые и т. д. Если вы играли в Castlevania, послушайте, как звучит Castlevania японского региона. Там дополнительный звук, звучит совершенно по-другому. При этом все выполняется на одном и том же железе. То есть эта идея больше сродни той, когда вы видеокарту купили, воткнули в компьютер, и у вас появилась дополнительная функциональность. Тут то же самое. Это супер. Но мы застряли с компакт-дисками.

Перейдем к финальной части — рассмотрим, как же работает это устройство вывода картинок. Потому что если вы хотите сделать эмулятор, программа-минимум — сделать процессор и вот эту штуку, чтобы смотреть, как картинки и видеоигры выглядят.
Начнем с самой верхнеуровневой сущности — самой картинки. Она состоит из двух планов. Есть передний план, на котором размещаются более динамические сущности, и задний, где размещаются более статичные сущности вроде сцены.
Здесь можно посмотреть разбиение. Слева — та же знаменитая игра Castlevania, поэтому все наше путешествие в PPU произойдет с Саймоном Бельмонтом. Будем вместе с ним рассматривать, как все устроено.
Тут фон, колонны и т. д. Мы видим, что они рисуются на заднем фоне, но при этом все персонажи — сам Саймон (слева, коричневый) и призраки — рисуются уже на переднем плане. То есть передний план существует для более динамичных сущностей, а задний — для более статичных.

Картинка на растровом дисплее состоит из пикселей. Пиксели — это просто цветные точки. Как минимум нам нужны цвета. В NES есть системная палитра. Она состоит из 64 цветов, это, к сожалению, все цвета, которые NES способна воспроизводить. Но мы не можем взять любой цвет из палитры. Для пользовательских палитр есть определенный диапазон в памяти, который, в свою очередь, тоже разбит на два таких поддиапазона.
Есть диапазон заднего и переднего плана. Каждый диапазон разбит на четыре палитры по четыре цвета. Например, задний план, нулевая палитра состоит из белого, синего, красного цветов. А четвертый цвет в каждой палитре всегда отсылает к прозрачному цвету, что позволяет нам делать прозрачный пиксель.

Этот диапазон с палитрами размещен уже не на шине CPU, а на шине PPU. Давайте посмотрим, как мы можем писать туда данные, потому что мы не имеем доступа к шине PPU через шину CPU.
Тут мы опять возвращаемся к идее memory mapped I/O. Есть адрес 0x2006 и 0x2007, это шестнадцатеричные адреса, но это просто цифры. И записываем мы так. Поскольку у нас адрес 16-битный, в регистр адреса ox2006 мы записываем адрес в два подхода по восемь бит и потом уже можем записать наши данные через адрес 0x2007. Такая забавная штука. То есть на самом деле нам надо выполнить три операции, чтобы как минимум записать что-то в палитру.

Отлично. У нас есть палитра, но нам нужны структуры. Цвета это всегда хорошо, но растровые картинки имеют определенную структуру.
Для графики есть две таблицы по четыре килобайта, которые содержат тайлы. И вся эта память представляет своего рода атлас. Раньше, когда все пользовались растровым изображением, то делали большой атлас, из которого потом через background-image по координатам выбирали нужные картинки. Здесь такая же идея.
В каждой таблице есть по 256 тайлов. Опять же забавная нумерология: именно 256 позволяет указывать один байт, 256 различных значений. То есть за один байт мы можем указать любой тайл, который нам нужен. Получаются две таблицы. Одна таблица для фонов, другая для переднего плана.

Посмотрим, как эти тайлики хранятся. Здесь тоже забавная штука. Вспомним, что у нас в палитре четыре цвета. Снова нумерология: в байте восемь бит, а тайл — восемь на восемь. Получается, одним байтом мы можем представить полоску тайла, где каждый бит будет отвечать за какой-то цвет. А восемью байтами мы можем представить полноценный тайл восемь на восемь.
Но тут есть одна проблема. Как мы говорили, один бит отвечает за цвет, но может представить всего два значения. Тайлы хранятся в двух плоскостях. Есть плоскость старшего и младшего бита. Чтобы получить финальный цвет, мы комбинируем данные из обеих плоскостей.
Можно рассмотреть — здесь, например, буква «Я», нижняя часть, там стоит цифра «3», которая получается так: берем плоскость младшего и старшего бита и получаем двоичное число 11, которое будет равно десятичному 3. Такая забавная структура данных.
Теперь мы наконец-то можем отобразить задний план!

Для него есть таблица имен. У нас их две штуки, каждая по 960 байт, каждый байт отсылает нас к определенному тайлу. То есть в предыдущей таблице указывается идентификатор тайла. Если мы представим эти 960 байт как матрицу, получится экран 32 на 30 тайлов. Разрешение NES у нас будет 256 пикселей на 240 пикселей.
Отлично. Мы можем записать туда тайлы. Но как вы могли заметить, тайлы не указывают палитру, с которой они должны отображаться. Мы можем разные тайлы отображать с разными палитрами, и нам тоже нужно где-то хранить эту информацию. К сожалению, у нас всего 64 байта на одну таблицу имен для хранения информации о палитре.
И тут возникает проблема. Если мы разобьем таблицу дальше, чтобы там было всего 64 значения, то получим квадраты четыре на четыре тайла, которые выглядят, как такой красный квадратик. Это просто огромная порция экрана. Она была бы подчинена одной палитре, если бы не одно но.
Как мы помним, в подпалитре есть четыре палитры, и нам нужно всего два бита для указания нужной. Каждый этот байт из 64-х копирует информацию о палитре для сетки четыре на четыре. Но эта сетка еще разбивается на такие подсетки два на два. Конечно, тут есть ограничение: сетка два на два тайла привязана к одной палитре. Таковы ограничения в мире отображения фонов на Nintendo. Забавный факт, но в целом играм он не особо мешает.

Еще есть скролинг. Если вспомнить, например, «Марио» или Castlevania, то мы знаем: если в этих играх герой двигается направо, то мир как бы раскрывается вдоль экрана. Это сделано за счет скролинга.
Вспомним, что у нас есть две таблицы имен, которые уже кодируют два экрана. И когда наш герой движется, мы как бы дозаполняем данные в таблицу имен, которые следуют далее. Мы прямо на лету, когда наш герой движется, дозаполняем таблицу имен. Получается, мы можем указать, с какого тайла в таблице имен нам нужно начать отображать данные, и будем их разворачивать по полоскам. Весь фокус скролинга — чтение из двух таблиц имен.
То есть если мы выходим за одну таблицу имен по горизонтали, то начинаем автоматически читать из другой и т. д. И не забываем, опять же, заполнять данные.
Кстати, скролинг в то время был довольно большой штукой. Первые свершения Джона Кармака были как раз на поприще скролинга. Посмотрите эту историю, довольно забавно.
И передний план. На первом плане, как мы говорили, есть динамические сущности, и хранятся они в памяти объектов и атрибутов.

Там есть 256 байт, в которые мы можем записать 64 объекта, четыре байта на объект. Каждый объект кодирует X и Y, это смещение по пикселям на экране. Плюс адрес тайла и атрибуты. Мы можем указать приоритет перед фоном, видите внизу картинку? Можем указать палитру. Приоритет перед фоном говорит PPU, что фон должен быть отрисован поверх спрайта. Это позволяет нам поместить Саймона за статую.
Еще мы можем сделать ориентацию, развернуть мимо какой-либо оси, например, горизонтальной, вертикальной, как буковку «Я» на картинке. Записываем мы примерно так же, как и палитру: через адрес 0x2003, 0x2004.
Наконец, финал. Как же мы отображаем объекты переднего плана?
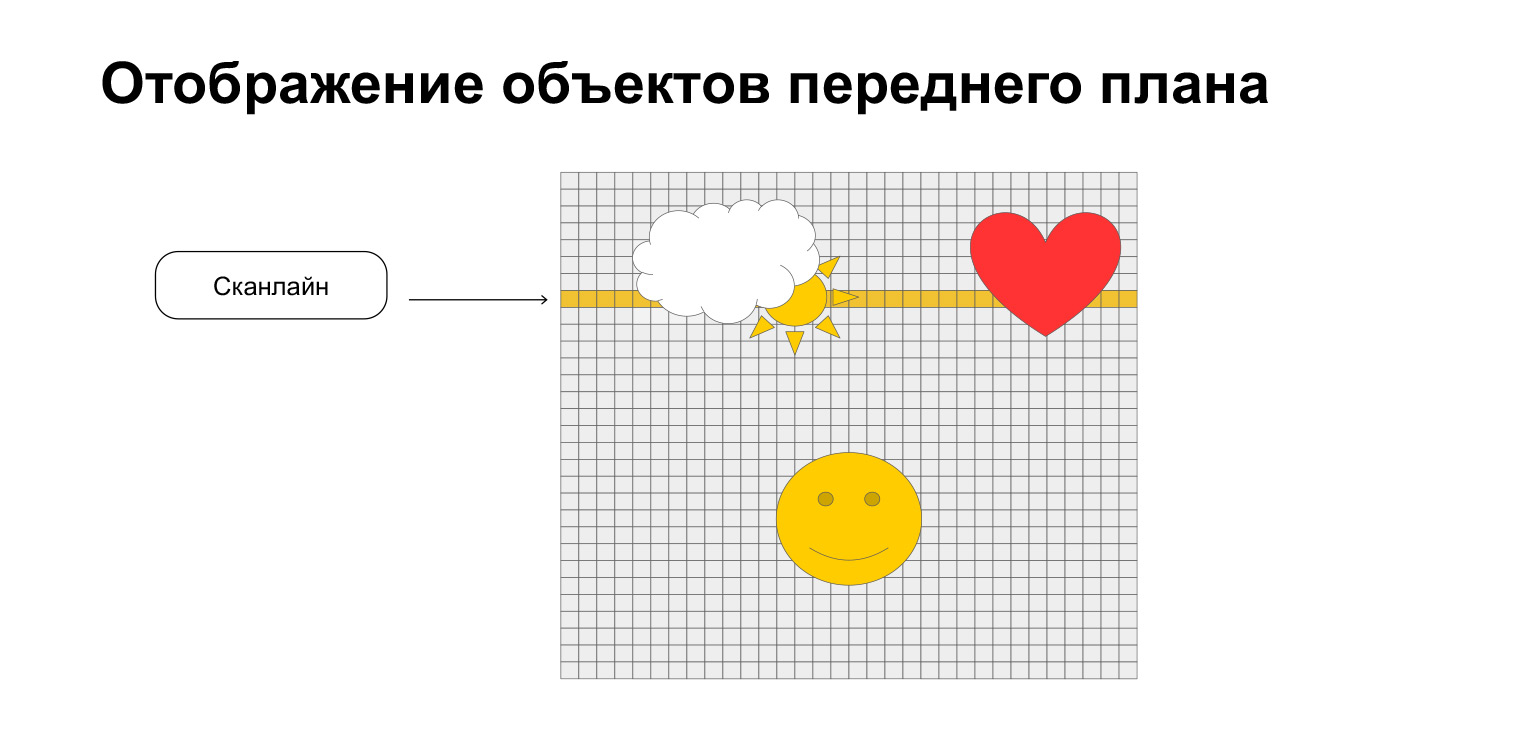
Картинка разворачивается по линиям, которые называются сканлайны, это телевизионный термин. Перед каждым сканлайном мы просто берем восемь спрайтов из памяти объектов и атрибутов. Не больше восьми, поддерживаются только восемь. Есть и такое ограничение. Мы просто их построчно отображаем, как тут, например. На текущем сканлайне желтым мы отображаем облачко, солнышко и сердечко в полосочке. А смайлик не отображаем. Но он все равно радуется.
Посмотрите суперканал One Lone Coder. Там есть сам процесс программирования, в частности — программирования эмулятора NES. А на Nesdev собрана вся информация по эмуляции — из чего она состоит и т. д. Финальная ссылка — код моего эмулятора. Посмотрите, если интересно. Написано на TypeScript.
Спасибо. Надеюсь, вам понравилось.
Доклад можно разделить на три части:
- как устроен процессор 6502 и как его эмулировать, используя JavaScript,
- как работает устройство вывода графики и как игры хранят свои ресурсы,
- как синтезируется звук с использованием веб-аудио и как это параллелится на два потока с помощью аудиоворклета.
Я постарался дать советы по оптимизации. Всё же эмуляция — дело такое, при 60 FPS остаётся мало времени на выполнение кода.
— Всем привет, меня зовут Женя. Сейчас будет немного необычный доклад, субботний, о проекте на много суббот. Поговорим об эмуляции компьютерных систем, которую можно реализовать поверх существующих веб-технологий. На самом деле в вебе уже довольно богатый инструментарий, и можно делать совершенно поразительные штуки. Если конкретно, мы поговорим об эмуляторе всем, наверное, известной приставки Денди из 90-х, которая на самом деле называется Nintendo Entertainment System.
Давайте немножко вспомним историю. Она началась в 1983 году, когда в Японии вышла приставка Famicom. Ее выпустила компания Nintendo. В 1985 году вышла американская версия, которая называлась Nintendo Entertainment System. В 90-х у нас был тот самый тайваньский регион под названием Денди, но по секрету, это неофициальная приставка. И последний такой железный подарок от Nintendo был в 2016-м, когда вышла NES mini. У меня, к сожалению, NES mini нет. Есть SNES mini, Super Nintendo. Посмотрите, какая маленькая штука, и прямо на этом слайде можно наблюдать закон Мура во всей красе.
Если мы посмотрим на 1985 год и соотношение приставки к джойстику, и на 2016-й, то можно заметить, насколько все стало меньше, потому что руки у людей не меняются, джойстик меньше не сделаешь, но сама приставка стала крохотной.
Как мы уже заметили, эмуляторов много. Мы это не проговорили, но как минимум один официальный заметили. Эта штучка — SNES mini или NES mini — на самом деле, не настоящая приставка. Это железяка, которая делает эмуляцию приставки. То есть по сути это официальный эмулятор, но который идет в таком забавном железном виде.
Но как мы знаем, еще с 2000-х есть программы, которые эмулируют NES, благодаря которым мы можем до сих пор наслаждаться играми из той эпохи. И эмуляторов много. Зачем еще один, тем более на JavaScript, спросите вы меня? Когда я эту штуку делал, то для себя нашел три ответа на этот вопрос.
- Это отличный, просто замечательный способ изучить компьютерную архитектуру в таком интерактивном режиме. Вы узнаете что-то новое, можете это сделать в коде. Код у вас не работает. Вы еще раз возвращаетесь к этой теме, еще раз что-то узнаете, какие-нибудь детали. И опять это выливаете в код. Получается цикл. Это хорошая альтернатива таким университетским учебникам, где будет теория, но не будет практики. А тут это все есть, есть такой фидбек-луп.
- Эмуляция затрагивает почти все, что можно сделать с компьютером, что бы мы ни представили. Есть звук, графика, геймпады, довольно хардкорная оптимизация, потому что NES — приставка телевизионная, и телевизор, регион NTSC, выдает 60 кадров в секунду. У вас есть 16 миллисекунд, чтобы наэмулировать на целый кадр. Тут без жестких оптимизаций никуда.
- Это весело и сложно. На самом деле, очень весело. И когда весь этот пазл сходится воедино, игры запускаются и вы можете в них играть, ощущение просто супер. А насчет того, что сложно, — это не сложно, когда ты это сделал. На самом деле это довольно просто. Но пока делаешь, пока пазл не сложился и ничего не запустилось, это может быть довольно удручающе.
Я еще смотрел презентацию Мэтта Годболда, который тоже рассказывал про эмуляцию процессора, на котором работает NES. Он сказал — забавно, что мы эмулируем такую низкоуровневую штуку на таком высокоуровневом языке. У нас нет доступа к железу, мы работаем опосредованно.
Давайте уже перейдем к рассмотрению того, что мы же будем эмулировать, как мы будем эмулировать и т. д. Начнем мы с процессора. Сама приставка NES — знаковая. Для России — понятно, это культурный феномен. Но и на Западе, и на Востоке, в Японии, это тоже был культурный феномен, потому что приставка, по сути, спасла всю индустрию домашних видеоигр.
Процессор в ней тоже установлен знаковый, это MOS6502. В чем его знаковость? В то время, когда он появился, его конкуренты стоили 180 долларов, а MOS6502 стоил 25 долларов. То есть этот процессор запустил революцию персональных компьютеров. И тут у меня представлены два компьютера. Первый — Apple II, мы все знаем и представляем, насколько знаковым для мира персональных компьютеров было это событие.
Еще есть компьютер BBC Micro. Он был больше популярен в Британии, BBC — британская телевизионная корпорация. То есть этот процессор внес компьютеры в массы, благодаря ему мы сейчас программисты, фронтендеры.
Давайте рассмотрим программу-минимум. Что нам нужно, чтобы сделать вычислительную систему?
Сам по себе CPU — устройство довольно бесполезное. Как мы знаем, CPU выполняет программу. Но как минимум для того, чтобы эта программа где-то хранилась, нужна память. И в программу-минимум она, разумеется, входит. А память у нас состоит из ячеек по восемь бит, которые называются байтами.
В JavaScript мы можем использовать типизированные массивы Uint8Array, чтобы эмулировать эту память, то есть мы можем выделить массив.
Чтобы память имела интерфейс с процессором, существует шина. Шина позволяет процессору адресовать память через адреса. Адреса состоят уже не из восьми бит, как данные, а из 16, что позволяет нам адресовать 64 килобайта памяти.
В процессоре находится некое состояние, тут есть три регистра — A, X, Y. Регистр — это как бы хранилище для промежуточных значений. Размер регистра — один байт или восемь бит. Это говорит нам о том, что процессор восьмибитный, он оперирует восьмибитными данными.
Пример использования регистра. Мы хотим сложить два числа, но шина в памяти одна. Получается, нужно где-то промежуточно сохранить первое число. Сохраняем его в регистр A, можем взять из памяти второе значение, сложить их, и результат опять же помещается в регистр A.
Функционально эти регистры довольно независимые — их можно использовать как общие. Но у них появляется смысл, как, например, сложение, в регистре A получается результат и берется значение первого операнда.
Или, например, адресуем данные. Про это мы поговорим чуть позже. Можем указать режим адресации со смещением и использовать регистр X для получения финального значения.
Что еще входит в состояние процессора? Есть регистр PC, который указывает на адрес текущей команды, поскольку адрес — это два байта.
Еще у нас есть регистр Status, который указывает на флаги статуса. К примеру, если мы вычли два значения и получилось отрицательное, то зажигается определенный бит в регистре флага.
Наконец, есть SP, указатель на стек. Стек — это просто обычная память, она никак не отделена от всего остального, от всех остальных программ. Просто есть инструкция у процессора, который управляет этим указателем SP. Таким образом реализован стек. Потом мы посмотрим на одну великую компьютерную идею, которая приводит к таким интересным решениям.
Теперь мы знаем, что есть процессор, память, состояние в процессоре. Посмотрим, что же представляет собой наша программа. Это некая последовательность байт. Она даже не обязательно должна быть последовательной. Сама программа может находиться в разных участках памяти.
Мы можем представить программу, у меня здесь кусочек кода — 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. Это реальная программа на 6502. Каждый байт этой программы, каждая цифра в этом массиве представляет собой такую сущность, как опкод. Опкод — код операции. «то, опять же, обычное число.
Например, есть опкод 169. Он кодирует в себе две штуки — во-первых, инструкцию. Инструкция при выполнении меняет состояние процессора, памяти и так далее, то есть состояние системы. Например, мы складываем два числа, в регистре A появится результат. Это пример инструкции. Еще у нас есть инструкция LDA, которую мы будем более детально рассматривать. Она загружает значение из памяти в регистр A.
Вторая штука, которую кодирует опкод, — режим адресации. Он говорит инструкции о том, где ей взять данные. Например, если это режим адресации IMM, то он говорит: возьми данные, которые находятся в ячейке, следующей за текущим программным счетчиком. Мы тоже посмотрим, как работает этот режим и как его можно реализовать на JavaScript.
Такая вот программа. Помимо этих байтиков, все очень похоже на JavaScript, только более низкоуровневое.
Если вспомнить, о чем я рассказывал, может выйти забавный парадокс. Мы, получается, храним программу в памяти, и данные тоже. Можно задать такой вопрос: может ли программа выступать в роли данных? Ответ — да. Мы можем из программы изменить ее же саму в момент выполнения этой программы.
Или другой вопрос: могут ли данные выступать в роли программы? Тоже да. Процессору без разницы. Он просто, как мельница, перемалывает байты, которые ему скармливают и выполняет инструкции. Парадоксальная штука. Если вдуматься, это супернебезопасно. Можно начать выполнять программу, которая является просто данными на стеке и т. д. Но преимущество в том, что это суперпросто. Не надо сложную схемотехнику делать.
Это такая первая великая идея, с которой мы сегодня столкнемся. Называется она архитектурой фон Неймана. Но там на самом деле было много соавторов.
Тут иллюстрируется. Есть программа 1, опкод 169, за ним 10, какие-то данные. Окей. Эту программу можно рассмотреть еще и так: 169 — данные, а 10 — опкод. Это будет легальная программа для 6502. Всю эту программу, опять же, можно рассматривать как данные.
Если у нас есть компилятор, мы можем собрать что-то, положить в этот участок памяти, и будет такая забавная штука.
Давайте посмотрим на первую составляющую нашей программы — инструкции.
6502 предоставляет доступ к 73 инструкциям, среди которых есть арифметика: сложение, вычитание. Нет умножения и деления, извините. Есть битовые операции, они про манипуляции с битами в восьмибитных словах.
Есть прыжки, которые у нас во фронтенде запрещены: оператор jump, который просто переносит программный счетчик к какому-то участку кода. Такое запрещено в программировании, но если вы имеете дело с low level, это единственный способ сделать ветвление. Есть операции для стека и т. д. Они сгруппированы. Да у нас 73 инструкции, но если посмотреть по группам и на то, что они делают, то их на самом деле не так много и они все довольно похожи.
Вернемся к инструкции LDA. Как мы говорили, это «загрузи из памяти значение в регистр A». Вот так суперпросто ее можно реализовать в JavaScript. На входе адрес, который нам поставляет режим адресации. Мы меняем внутри состояние, говорим, что this._a равно прочитанному значению из памяти.
Нам еще нужно установить в статусном регистре два этих битовых поля — нулевой флаг и флаг отрицательного значения. Тут множество всяких побитовых штук. Но если вы будете делать эмулятор, это станет вашей второй натурой — заниматься этими OR, отрицаниями и т. д. Единственное, что тут забавно, — есть такой % 256 во второй ветке. Он отсылает нас, опять же, к природе нашего любимого языка JavaScript, к тому, что у него нет типизированных значений. Значение, которое мы помещаем в Status, может выйти за 256, которые помещаются в один байт. Приходится заниматься такими ухищрениями.
Теперь посмотрим на финальную часть нашего опкода, на режим адресации.
У нас есть 12 режимов адресации. Как мы уже говорили раньше, они позволяют нам доставать и указывать для инструкции, откуда ей взять данные.
Давайте рассмотрим три штучки. Последний — ABS, абсолютный режим адресации, начнем рассматривать с него, извиняюсь за небольшой конфуз. Он делает примерно следующее. Мы на вход ему даем полный адрес, 16 бит. Он нам достает значение из этой ячейки памяти. В ассемблере во второй колонке можно наблюдать, как это выглядит: LDA $ccbb. ccbb — шестнадцатеричное число, обычное число, просто записанное в другой нотации. Если вы здесь чувствуете себя некомфортно, помните, что это просто число.
В третьей колонке можно наблюдать, как это выглядит в машинном коде. Впереди идет опкод — 173, подсвечен синим. А 187 и 204 — это уже данные адреса. Но поскольку мы оперируем с восьмибитными значениями, нам нужно две ячейки памяти, чтобы записать адрес.
Я еще забыл сказать, что опкод выполняется некоторое время на CPU, у него есть определенная стоимость. LDA с абсолютной адресацией выполняются четыре цикла CPU.
Тут уже можно понять, зачем нужно столько режимов адресации. Рассмотрим следующий режим адресации, ZP0. Это режим адресации по нулевой странице. А нулевая страница — это первые 256 байт, размещенные в памяти. Это адреса от нуля до 255.
В ассемблере, опять же, LDA *10. Что этот режим адресации делает? Он говорит: сходи в нулевую страницу, вот в эти первые 256 байт, с таким-то смещением. в данном случае 10, и возьми оттуда значение. Тут мы уже замечаем существенное различие между режимами адресации.
В случае с абсолютной адресацией нам потребовалось, во-первых, три байта, чтобы записать такую программу. Во-вторых, нам потребовалось четыре цикла CPU. А в режиме адресации ZP0 потребовалось всего три цикла CPU и два байта. Но да, мы потеряли гибкость. То есть мы можем помещать свои данные только в первую страницу, вот эту.
Финальный режим адресации IMM говорит: возьми данные из ячейки, следующей за опкодом. Эта LDA #10 в ассемблере такое делает. И получается, программа выглядит как [169, 10]. Она уже требует два цикла CPU. Но тут понятно, что мы тоже теряем гибкость, и нам нужно, чтобы опкод был рядом с данными.
Реализовать это в JavaScript проще простого. Вот пример кода. Есть адрес. Это IMM адресация, которая как раз берет из программного счетчика данные. Мы просто говорим, что наш адрес — это программный счетчик, и увеличиваем его на один, чтобы при следующем выполнении программы он уже перескочил на следующую команду.
Вот такая забавная штука. Мы теперь умеем читать машинный код как фронтендеры. И даже умеем смотреть, что там в ассемблере написано.
Мы уже в принципе знаем все, что нужно. Есть программа, она состоит из байт. Каждый байт — опкод, каждый опкод — инструкция и т. д. Посмотрим, как выполняется наша программа. А выполняется она как раз в этих циклах CPU.
Как такой код можно сделать? Пример. Нам нужно считать опкод из программного счетчика, потом просто его увеличить на один. Теперь нам нужно этот опкод как раз декодировать в инструкцию и в режим адресации. Если подумать, опкод — это простое число, 169. А в байте у нас всего 256 чисел. Мы можем сделать массив на 256 значений. Каждый элемент этого массива просто будет отсылать нас к тому, какую инструкцию надо использовать, какой нужен режим адресации и сколько циклов это займет. То есть это суперпросто. И массив у меня лежит как раз в состоянии процессора.
Дальше мы просто выполняем функцию режима адресации на 36 строке, которая дает нам адрес, и скармливаем его инструкции.
Что нам нужно сделать финально, так это разобраться с циклами. opcodeResolver возвращает количество циклов, мы их записываем в переменную remainingCycles. На каждый цикл процессора мы смотрим: если осталось ноль циклов, то можем выполнить следующую команду, если больше нуля — мы просто уменьшаем его на один. И все, суперпросто. Так выполняется программа на 6502.
Но как мы уже говорили, программа может находиться в разных участках памяти, в разных соотношениях и т. д. Как вообще процессору понять, откуда начать выполнять эту программу. Нам нужен такой int main из мира C.
На самом деле, все просто. У процессора есть процедура сброса его состояния. В этой процедуре мы берем адрес начальной команды из адреса 0xfffxc. 0xfffxc — опять шестнадцатеричное число. Если чувствуете себя не комфортно, забейте, это обычное число. Так они в JavaScript пишутся, через 0x.
Нам нужно считать два байта адреса, адрес 16 бит. Мы считаем младшие байты из этого адреса, старшие байты из следующего за ним адреса. И потом складываем это дело такой магией битовых операций. Кроме того, сброс состояния процессора сбрасывает еще значение в регистрах — регистр A, X, Y, указатель на стек, статус. Сброс занимает восемь циклов. Такая вот штука.
Мы теперь уже все, на самом деле, знаем. Честно скажу: для меня было отчасти сложно все это написать, потому что я вообще не понимал, как это тестировать. Мы пишем целый компьютер, который может выполнять любую когда-либо созданную для него программу. Как понять, что мы двигаемся правильно?
Есть супергениальный и замечательный способ! Берем два CPU. Первый — тот, который мы делаем, второй — эталонный CPU, мы точно знаем, что он работает хорошо. Например, есть эмулятор для NES, nintendulator, который считается таким эталоном CPU.
Берем определенную тестовую программу, выполняем ее на эталонном CPU и на каждую команду записываем состояние процессора в лог состояний. Потом берем эту программу и выполняем ее на нашем CPU. И каждое состояние после каждой команды сравниваем с этим логом. Суперидея!
Конечно, нам эталон CPU не нужен. Нам просто нужен лог выполнения программы. Этот лог можно найти на Nesdev. На самом деле, эмулятор процессора можно написать, не знаю, за пару дней на выходных — это прямо суперштука!
И все. Берем лог, сравниваем состояние, и у нас получается интерактивный тест. Выполняем первую команду, она у нас не реализована в процессоре, который мы разрабатываем. Мы ее реализовываем, переходим к следующей строке лога и опять же реализовываем. Супероперативно! Позволяет двигаться быстро.
Архитектура NES
Теперь у нас есть CPU, который, по сути, сердце нашего компьютера. И мы можем посмотреть, из чего состоит архитектура самой NES и как делаются такие сложные составные компьютерные системы. Потому что, если подумать, ну есть CPU, есть память. Мы можем значения получать, записывать и т. д.
Но в NES, в любой телевизионной приставке есть еще экран, звуковые устройства и т. д. Нам нужно учиться работать с периферией. Для этого даже не нужно узнавать ничего нового, достаточно концепции нашей шины. Это, наверное, вторая такая гениальная идея, гениальное открытие, которое я для себя сделал в процессе написания эмулятора.
Давайте представим, что мы возьмем нашу память, в которой было 64 килобайта, и разобьем ее на два диапазона по 32 килобайта. В младшем диапазоне будет находиться некое устройство, которое представляет собой массив лампочек, как на картинке с этим табло.
Скажем, что при записи в этот младший 32-килобайтный диапазон лампочка будет зажигаться либо тухнуть. Если мы записываем туда значение 1, лампочка зажигается, если 0 — тухнуть. При этом мы можем считать значение и понять состояние системы, понять, какая картинка выведена на этот экран.
Опять же, в старший диапазон адресов мы ставим обычную память, в которой находится программа, потому что нам нужно, чтобы при процедуре сброса в старшем диапазоне был адрес.
Это на самом деле супергениальная идея. Чтобы взаимодействовать с периферией, не нужны дополнительные команды и т. д. Мы просто пишем в старую добрую память, как раньше. Но при этом память уже может представлять собой дополнительные устройства.
Теперь мы уже полностью готовы рассмотреть архитектуру NES. У нас есть CPU и его шина, как обычно. Есть два дополнительных килобайта памяти. Есть APU — устройство вывода звука. К сожалению, сейчас мы его не рассмотрим, но там тоже все суперкруто. И есть картридж. Он помещен в верхний диапазон и поставляет данные о программе. Еще он поставляет данные графики, сейчас рассмотрим. Последняя штука, которая есть на шине CPU, — это PPU, picture processing unit, такая протовидеокарта. Если вы хотели научиться работать с видеокартами, мы сейчас даже узнаем, как реализовать одну.
У PPU тоже есть своя шина, на которую смещаются таблицы имен, палитры и графические данные. Но графические данные поставляет картридж. И еще есть память объекта. Вот такая архитектура.
Давайте посмотрим, что такое картридж. Это намного более крутая идея, чем компакт-диск, если учесть, что она из прошлого.
Чем же она крута? Слева мы можем видеть картридж американского региона, знаменитую игру Zelda, если кто не играл — поиграйте, супер. И если мы разберем этот картридж, то обнаружим в нем микросхемы. Там нет лазерного диска и т. д. Обычно эти микросхемы просто содержат некие данные. Также картридж напрямую врезается в нашу компьютерную систему, в шину CPU и PPU. Это позволяет делать удивительные вещи, расширять пользовательский опыт.
На борту картриджа есть mapper, он заправляет трансляцией адресов. Предположим, у нас большая игра. Но в NES есть всего 32 килобайта памяти, которые она может адресовать под программу. А игра, предположим, 128 килобайт. mapper может на лету, во время выполнения программы, подменить определенный диапазон памяти на совершенно новые данные. Мы можем сказать в программе: загрузи нам уровень 2, и память напрямую, почти что мгновенно подменится.
Плюс там есть забавные штуки. Например, mapper может поставлять чипы, которые расширяют звуковые дорожки, добавляют новые и т. д. Если вы играли в Castlevania, послушайте, как звучит Castlevania японского региона. Там дополнительный звук, звучит совершенно по-другому. При этом все выполняется на одном и том же железе. То есть эта идея больше сродни той, когда вы видеокарту купили, воткнули в компьютер, и у вас появилась дополнительная функциональность. Тут то же самое. Это супер. Но мы застряли с компакт-дисками.
Перейдем к финальной части — рассмотрим, как же работает это устройство вывода картинок. Потому что если вы хотите сделать эмулятор, программа-минимум — сделать процессор и вот эту штуку, чтобы смотреть, как картинки и видеоигры выглядят.
Начнем с самой верхнеуровневой сущности — самой картинки. Она состоит из двух планов. Есть передний план, на котором размещаются более динамические сущности, и задний, где размещаются более статичные сущности вроде сцены.
Здесь можно посмотреть разбиение. Слева — та же знаменитая игра Castlevania, поэтому все наше путешествие в PPU произойдет с Саймоном Бельмонтом. Будем вместе с ним рассматривать, как все устроено.
Тут фон, колонны и т. д. Мы видим, что они рисуются на заднем фоне, но при этом все персонажи — сам Саймон (слева, коричневый) и призраки — рисуются уже на переднем плане. То есть передний план существует для более динамичных сущностей, а задний — для более статичных.
Картинка на растровом дисплее состоит из пикселей. Пиксели — это просто цветные точки. Как минимум нам нужны цвета. В NES есть системная палитра. Она состоит из 64 цветов, это, к сожалению, все цвета, которые NES способна воспроизводить. Но мы не можем взять любой цвет из палитры. Для пользовательских палитр есть определенный диапазон в памяти, который, в свою очередь, тоже разбит на два таких поддиапазона.
Есть диапазон заднего и переднего плана. Каждый диапазон разбит на четыре палитры по четыре цвета. Например, задний план, нулевая палитра состоит из белого, синего, красного цветов. А четвертый цвет в каждой палитре всегда отсылает к прозрачному цвету, что позволяет нам делать прозрачный пиксель.
Этот диапазон с палитрами размещен уже не на шине CPU, а на шине PPU. Давайте посмотрим, как мы можем писать туда данные, потому что мы не имеем доступа к шине PPU через шину CPU.
Тут мы опять возвращаемся к идее memory mapped I/O. Есть адрес 0x2006 и 0x2007, это шестнадцатеричные адреса, но это просто цифры. И записываем мы так. Поскольку у нас адрес 16-битный, в регистр адреса ox2006 мы записываем адрес в два подхода по восемь бит и потом уже можем записать наши данные через адрес 0x2007. Такая забавная штука. То есть на самом деле нам надо выполнить три операции, чтобы как минимум записать что-то в палитру.
Отлично. У нас есть палитра, но нам нужны структуры. Цвета это всегда хорошо, но растровые картинки имеют определенную структуру.
Для графики есть две таблицы по четыре килобайта, которые содержат тайлы. И вся эта память представляет своего рода атлас. Раньше, когда все пользовались растровым изображением, то делали большой атлас, из которого потом через background-image по координатам выбирали нужные картинки. Здесь такая же идея.
В каждой таблице есть по 256 тайлов. Опять же забавная нумерология: именно 256 позволяет указывать один байт, 256 различных значений. То есть за один байт мы можем указать любой тайл, который нам нужен. Получаются две таблицы. Одна таблица для фонов, другая для переднего плана.
Посмотрим, как эти тайлики хранятся. Здесь тоже забавная штука. Вспомним, что у нас в палитре четыре цвета. Снова нумерология: в байте восемь бит, а тайл — восемь на восемь. Получается, одним байтом мы можем представить полоску тайла, где каждый бит будет отвечать за какой-то цвет. А восемью байтами мы можем представить полноценный тайл восемь на восемь.
Но тут есть одна проблема. Как мы говорили, один бит отвечает за цвет, но может представить всего два значения. Тайлы хранятся в двух плоскостях. Есть плоскость старшего и младшего бита. Чтобы получить финальный цвет, мы комбинируем данные из обеих плоскостей.
Можно рассмотреть — здесь, например, буква «Я», нижняя часть, там стоит цифра «3», которая получается так: берем плоскость младшего и старшего бита и получаем двоичное число 11, которое будет равно десятичному 3. Такая забавная структура данных.
Задний план
Теперь мы наконец-то можем отобразить задний план!
Для него есть таблица имен. У нас их две штуки, каждая по 960 байт, каждый байт отсылает нас к определенному тайлу. То есть в предыдущей таблице указывается идентификатор тайла. Если мы представим эти 960 байт как матрицу, получится экран 32 на 30 тайлов. Разрешение NES у нас будет 256 пикселей на 240 пикселей.
Отлично. Мы можем записать туда тайлы. Но как вы могли заметить, тайлы не указывают палитру, с которой они должны отображаться. Мы можем разные тайлы отображать с разными палитрами, и нам тоже нужно где-то хранить эту информацию. К сожалению, у нас всего 64 байта на одну таблицу имен для хранения информации о палитре.
И тут возникает проблема. Если мы разобьем таблицу дальше, чтобы там было всего 64 значения, то получим квадраты четыре на четыре тайла, которые выглядят, как такой красный квадратик. Это просто огромная порция экрана. Она была бы подчинена одной палитре, если бы не одно но.
Как мы помним, в подпалитре есть четыре палитры, и нам нужно всего два бита для указания нужной. Каждый этот байт из 64-х копирует информацию о палитре для сетки четыре на четыре. Но эта сетка еще разбивается на такие подсетки два на два. Конечно, тут есть ограничение: сетка два на два тайла привязана к одной палитре. Таковы ограничения в мире отображения фонов на Nintendo. Забавный факт, но в целом играм он не особо мешает.
Еще есть скролинг. Если вспомнить, например, «Марио» или Castlevania, то мы знаем: если в этих играх герой двигается направо, то мир как бы раскрывается вдоль экрана. Это сделано за счет скролинга.
Вспомним, что у нас есть две таблицы имен, которые уже кодируют два экрана. И когда наш герой движется, мы как бы дозаполняем данные в таблицу имен, которые следуют далее. Мы прямо на лету, когда наш герой движется, дозаполняем таблицу имен. Получается, мы можем указать, с какого тайла в таблице имен нам нужно начать отображать данные, и будем их разворачивать по полоскам. Весь фокус скролинга — чтение из двух таблиц имен.
То есть если мы выходим за одну таблицу имен по горизонтали, то начинаем автоматически читать из другой и т. д. И не забываем, опять же, заполнять данные.
Кстати, скролинг в то время был довольно большой штукой. Первые свершения Джона Кармака были как раз на поприще скролинга. Посмотрите эту историю, довольно забавно.
Передний план
И передний план. На первом плане, как мы говорили, есть динамические сущности, и хранятся они в памяти объектов и атрибутов.
Там есть 256 байт, в которые мы можем записать 64 объекта, четыре байта на объект. Каждый объект кодирует X и Y, это смещение по пикселям на экране. Плюс адрес тайла и атрибуты. Мы можем указать приоритет перед фоном, видите внизу картинку? Можем указать палитру. Приоритет перед фоном говорит PPU, что фон должен быть отрисован поверх спрайта. Это позволяет нам поместить Саймона за статую.
Еще мы можем сделать ориентацию, развернуть мимо какой-либо оси, например, горизонтальной, вертикальной, как буковку «Я» на картинке. Записываем мы примерно так же, как и палитру: через адрес 0x2003, 0x2004.
Наконец, финал. Как же мы отображаем объекты переднего плана?
Картинка разворачивается по линиям, которые называются сканлайны, это телевизионный термин. Перед каждым сканлайном мы просто берем восемь спрайтов из памяти объектов и атрибутов. Не больше восьми, поддерживаются только восемь. Есть и такое ограничение. Мы просто их построчно отображаем, как тут, например. На текущем сканлайне желтым мы отображаем облачко, солнышко и сердечко в полосочке. А смайлик не отображаем. Но он все равно радуется.
Посмотрите суперканал One Lone Coder. Там есть сам процесс программирования, в частности — программирования эмулятора NES. А на Nesdev собрана вся информация по эмуляции — из чего она состоит и т. д. Финальная ссылка — код моего эмулятора. Посмотрите, если интересно. Написано на TypeScript.
Спасибо. Надеюсь, вам понравилось.




Fregl
Очень много вырезано из контекста. Мне эта тема интересна, но материал подан не достаточно подробно, да ещё в стиле как для маленьких детишек.
chams Автор
К сожалению за 45 минут всего рассказать не получилось (особенно жалко про звук). Очень советую вот эту серию видео www.youtube.com/watch?v=nViZg02IMQo&list=PLrOv9FMX8xJHqMvSGB_9G9nZZ_4IgteYf (по ней я делал свой эмулятор).