
Сейчас, когда flash накопители очень активно используются в качестве высокопроизводительной замены жестким дискам, надежность их играет все более важную роль. Сбои чипов могут приводить к простоям и даже потерям данных. Для выработки понимания процессов изменения надежности флэш-памяти в реальных условиях нагруженного проекта было проведено исследование, представленное в обсуждаемой статье.
Авторами была собрана обширная статистика за четыре года эксплуатации флэш-накопителей в дата-центрах Facebook.
Как многие наверняка знают, Facebook долгое время была лучшим (и основным) клиентом компании Fusuion-IO (сейчас куплена SANdisk), которая одной из первых начала выпускать PCI-e флэш-накопители.

В результате проведенного анализа собранных данных, был сделан ряд интересных выводов:
• Вероятность сбоя SSD меняется нелинейно во времени. Можно ожидать, что вероятность сбоя будет расти линейно вместе с ростом числа циклов записи. Напротив, наблюдаются отдельные пики, в которых вероятность сбоя возрастает, но пики эти определяются иными факторами, нежели естественный износ.
• Ошибки чтения на практике встречаются редко и не являются доминирующими.
• Распределение данных по объему SSD накопителя может существенно влиять на вероятность сбоя.
• Повышение температуры приводит к повышению вероятности сбоя, но благодаря поддержке throttling, негативный температурный эффект значительно снижается.
• Объем данных, который был записан на SSD операционной системой не всегда точно отражает степень износа накопителя, так как в контроллере работают внутренние алгоритмы оптимизации, а также используется буферизация в системном ПО.
Объекты исследования.
Авторам удалось получить статистические данные с множества накопителей 3х типов (разных поколений) в 6 различных аппаратных конфигурациях: 1 или 2 накопителя 720GB PCI-e v1 x4, 1 или 2 накопителя 1.2TB PCI-e v2 x4 и 1 или 2 накопителя 3.2TB PCI-e v2 x4. Так как все измерения снимались с „живых“ систем, время работы накопителей (а также записанный/прочитанный объем данных) значительно отличается друг от друга. Тем не менее, собранных данных оказалось достаточно, чтобы получить статистически значимые данные после усреднения результатов в рамках отдельных групп. Основным измеримым показателем надежности, которым оперируют авторы статьи, является коэффициент неисправимых битовых ошибок (uncorrectable bit error rate, UBER = unrecorectable errors / bits accessed). Это те ошибки, которые возникают при чтении/записи, но не могут быть исправлены контроллером ssd. Очень интересным кажется то, что для некоторых систем показатели UBER сравнимы с точностью до порядка величины с данными, полученными другими исследователями, при измерении битовых ошибок (BER) на уровне отдельных чипов в синтетических тестах (L. M. Grupp, J. D. Davis, and S. Swanson. The Bleak Future of NAND Flash Memory. In FAST, 2012.). Тем не менее, такое сходство было получено только для накопителей первого поколения и только в конфигурации с двумя платами в системе. Во всех остальных случаях, различие составляет несколько порядков, что выглядит вполне логично. Скорее всего, причиной стал целый ряд как внутренних, так и внешних (температура, электропитание) факторов, поэтому никаких значимых выводов из этого наблюдения сделать невозможно.
Распределение ошибок.
Интересно, что количество наблюдаемых ошибок сильно зависит от конкретного накопителя — авторы отмечают, что всего лишь 10% от общего числа SSD накопителей показывают 95% от всех неисправимых ошибок. Кроме того, вероятность возникновения ошибок существенным образом зависит от „истории“ накопителя: если в течение недели наблюдалась хотя бы одна ошибка, то с вероятностью 99.8% на следующей неделе также можно ожидать возникновение ошибки на этом накопителе. Также авторы отмечают корреляцию между вероятностью возникновения ошибки и числом SSD плат в системе — для конфигураций с двумя накопителями вероятность сбоя возрастала. Здесь, однако, необходимо учитывать другие внешние факторы — прежде всего характер нагрузки и способ перераспределения нагрузки в случае сбоя накопителя. Поэтому нельзя говорить о непосредственном влиянии накопителей друг на друга, но при планировании сложных систем, оказывается важным то, как распределяется нагрузка не только в нормальном состоянии, но и в случае сбоев отдельных компонентов. Необходимо планировать комплекс таким образом, чтобы сбой одного компонента не приводил к лавинообразному возрастанию вероятности сбоев в других компонентах системы.
Зависимость числа ошибок от срока эксплуатации (числа циклов записи).
Хорошо известно, что срок жизни SSD зависит от числа циклов записи, которое, в свою очередь, довольно строго лимитировано в рамках используемой технологии. Логично ожидать, что количество наблюдаемых ошибок будет возрастать пропорционально объему записанных на SSD данных. Полученные экспериментальные данные показывают, что в реальности картина оказывается несколько более сложной. Известно, что для обычных жестких дисков типичной является U-образная кривая, описывающая вероятность выхода из строя.
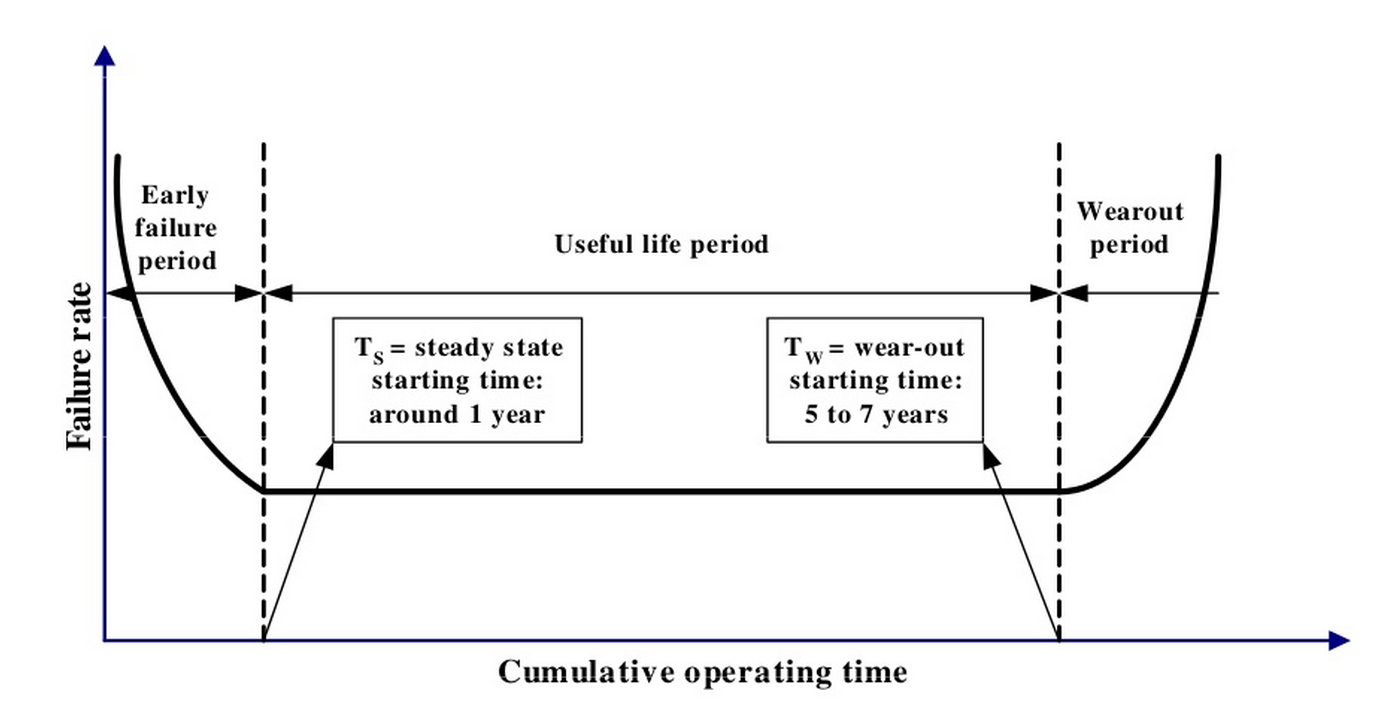
(Jimmy Yang, Feng-Bin Sun A comprehensive review of hard-disk drive reliability. Reliability and Maintainability Symposium, 1999. Proceedings. Annual)
На начальном этапе эксплуатации наблюдается сравнительно высокая вероятность сбоев, которая затем снижается и начинает опять возрастать уже после длительной эксплуатации. Для SSD мы тоже видим повышенное число сбоев на начальном этапе, но не сразу, а сначала идет постепенный рост числа ошибок.
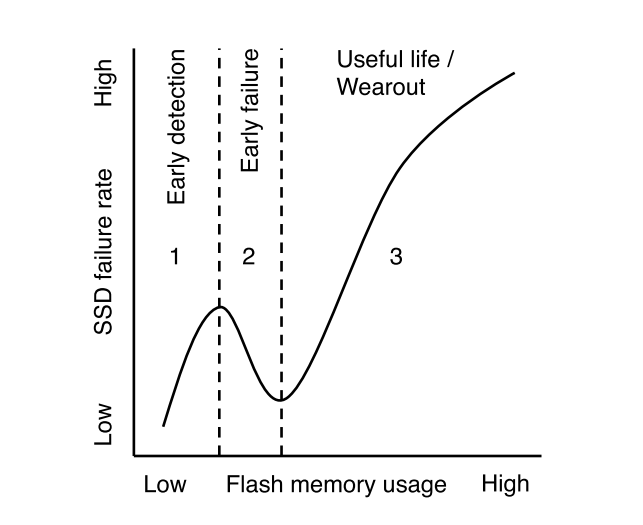
Авторы выдвигают гипотезу, что причиной нелинейного поведения является наличие „слабого звена“ — ячеек, которые подвержены износу гораздо быстрее. Эти ячейки на ранней стадии эксплуатации генерируют неисправимые ошибки, а контроллер, в свою очередь, исключает их из работы. Оставшиеся „надежные“ ячейки функционируют на протяжении своего жизненного цикла нормально и начинают служить причиной ошибок уже только через длительное время эксплуатации (так, как и ожидается на основе предельного числа циклов записи). Это вполне логичное предположение — первичные сбои наблюдаются и для жестких дисков, и для SSD. Различие в поведении HDD и SSD объясняется тем, что физическая ошибка на жестком диске обычно приводит к выпадению диска из RAID-массива, а для SSD контроллер обычно может исправить ошибку и переместить данные на резервный объем. Понизить вероятность возникновения сбоев на начальном этапе эксплуатации можно предварительным контролем (»обкаткой"), что иногда практикуется вендорами на специальных стендах.
Зависимость числа ошибок от объема прочитанных данных.
Отдельно было исследовано предположение, что объем прочитанных данных также может влиять на величину UBER, тем не менее, оказалось, что для SSD, для которых объем прочитанных данных значительно отличается (при схожем объеме записанных данных), коэффициент неисправимых ошибок отличается незначительно. Таким образом, авторы утверждают, что операции чтения не оказывают какого-либо значимого эффекта на надежность накопителей.
Влияние фрагментации данных внутри SSD на сбои.
Еще один аспект, на который стоит обратить внимание — связь коэффициента ошибок с нагрузкой на буфер. Конечно, непосредственно нагрузка на буфер (который является обычной DRAM микросхемой) никак не связана. Однако, чем более “размазываются” записываемые блоки по объему SSD (фрагментация), тем более активно используется буфер, который служит для хранения метаданных. В результате исследований полученных данных, ряд конфигураций показал явную зависимость коэффициента ошибок от распределения записываемых данных по объему SSD. Это позволяет допустить значительный потенциал в развитии технологий, позволяющих оптимизировать операции записи за счет оптимального распределения данных по накопителю, что, в свою очередь, позволит обеспечить более высокую надежность накопителей.
Температурные эффекты.
Из внешних факторов, оказывающих потенциальное влияние на надежность накопителей, прежде всего, можно выделить температурные эффекты. Как и любой полупроводник, чипы flash подвержены деградации при высоких температурах, поэтому можно ожидать, что рост температуры внутри системы может привести к росту коэффициента ошибок. В реальности такое поведение наблюдается только для ряда конфигураций. Наиболее отчетливо влияние температуры заметно для первого поколения накопителей, а также для систем с двумя накопителями второго поколения. В остальных случаях температурный эффект был сравнительно мал, а иногда был даже отрицательным. Такое поведение легко объяснимо поддержкой throttling (пропуск циклов) в SSD.
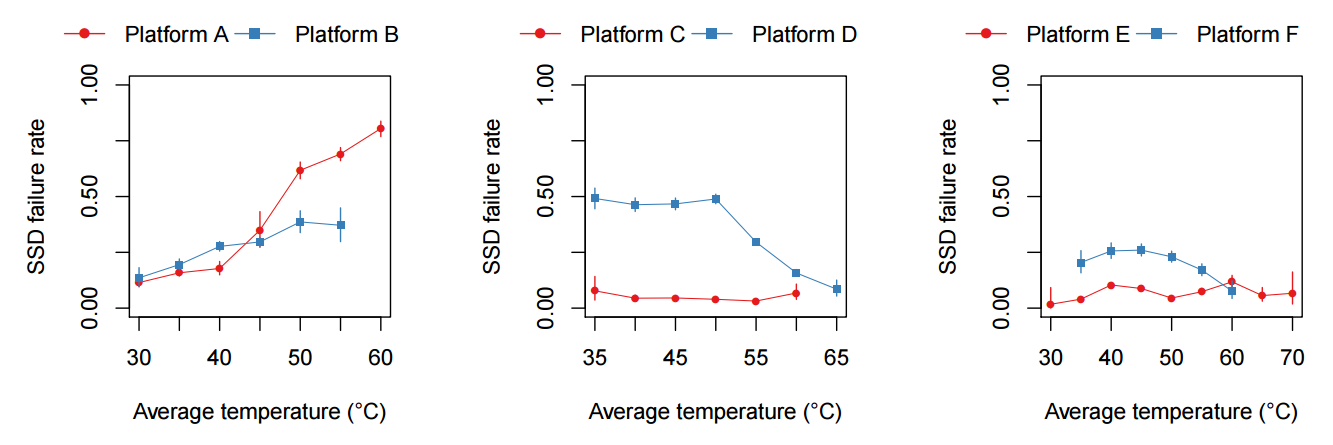
Вероятно, для более ранних моделей технология либо не поддерживалась, либо не была реализована на должном уровне. Новые же накопители спокойно переносят повышение температуры, правда, ценой этому является снижение производительности. Поэтому, если вдруг производительность SSD накопителя в системе снизилась, стоит проверить температурный режим. Температурный эффект очень интересен особенно в свете того, что инженерные подразделения в последние годы стараются максимально повысить температуру в ЦОД, чтобы снизить расходы на охлаждение. В документах, публикуемых ASHRAE (American Society of Heating, Refrigerating and Air-Conditioning Engineers) можно найти рекомендации для систем с SSD накопителями. Вот, например, документ, который вполне может пригодиться — Data Center Storage Equipment – Thermal Guidelines, Issues, and Best Practices. При планировании серьезных вычислительных комплексов, безусловно, стоит учитывать рекомендации ASHRAE и внимательно изучать характеристики планируемых к использованию накопителей, чтобы не попасть в такой температурный режим, когда уже началась деградация производительности для сохранения надежности накопителя.
Достоверность статистических данных в системном ПО.
Еще одно интересное наблюдение авторов — в ряде случаев, хотя метрики операционной системы показывали высокий объем записанных данных, коэффициент ошибок был ниже, чем для систем, где объем записанных данных был ниже.
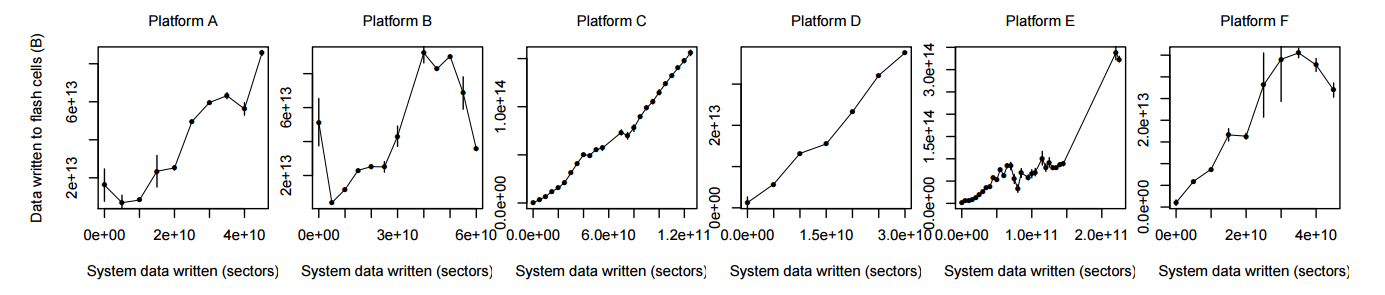
Как выяснилось, зачастую метрики операционной системы и непосредственно контроллера SSD значительно отличались. Это связано с оптимизациями внутри контроллера SSD, а также с буферизацией ввода-вывода как в самой операционной системе, так и в накопителе. Как следствие, не стоит на все 100% полагаться на метрики операционной системы — они могут быть не совсем точными, а дальнейшие оптимизации подсистемы ввода-вывода могут сделать этот разрыв еще более заметным.
Практические выводы.
Итак, какие практические выводы можно сделать на основе данного исследования?
1. Проектируя серьезные решения на базе SSD, необходимо очень внимательно относиться к температурному режиму в ЦОД, иначе можно получить либо деградацию производительности, либо высокую вероятность сбоя.
2. Перед вводом в продуктив, стоит «прогреть» систему с целью выявления «слабых звеньев». Совет этот, правда, одинаково хорошо подходит к любым компонентам, будь то SSD или жесткие диски, или модули памяти. Нагрузочное тестирование позволяет выявить многие «проблемные» компоненты, которые, в противном случае, могли бы «попортить крови» в боевой инфраструктуре.
3. Если накопитель начал выдавать ошибки, стоит заранее позаботиться о наличии ЗИП.
4. Статистику лучше собирать из всех доступных источников, но для ряда показателей лучше ориентироваться на низкоуровневые данные внутри накопителей.
5. Новые поколения SSD обычно лучше старых :)
Во всех этих советах нет ничего неожиданного, но часто именно простые вещи ускользают от внимания.
Здесь я затронул показавшиеся мне наиболее интересными моменты, если вы заинтересованы в детальном изучении вопроса, стоит внимательно изучить все выкладки авторов, прочитав оригинальную версию. Была проделана действительно титаническая работа по сбору и анализу данных. Если команда продолжит свои исследования, то через пару лет можно ждать еще более обширного и всестороннего исследования.
PS термин “надежность” в тексте употребляется исключительно в качестве аналога термину “число ошибок”.
Другие статьи Тринити можно найти в хабе Тринити. Подписывайтесь!
Комментарии (14)

kin9pin
02.09.2015 14:40+1Температурный эффект очень интересен особенно в свете того, что инженерные подразделения в последние годы стараются максимально повысить температуру в ЦОД, чтобы снизить расходы на охлаждение.
Это как?)
exLH
02.09.2015 18:45Да, все правильно — больше температура => ниже расходы на кондиционирование. ASHRAE уже давно сдвинула рекомендации вверх — у них в документах много интересных рекомендаций.




linjan
02.09.2015 16:42+1Вспомнился график отказов по НЖМД от BackBlaze:
Скрытый текст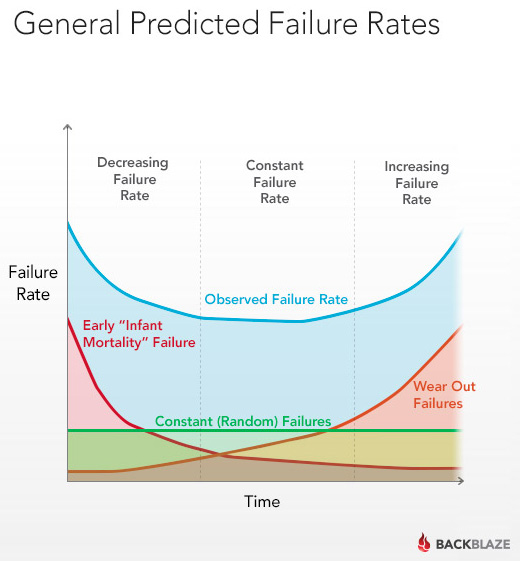
exLH
03.09.2015 10:16Картинка эта (в той или иной вариации) кочует из статьи в статью, как минимум, с середины 90х. Приведенная выше ссылка, насколько я помню, не является самым первым таким исследованием. Нечто похожее было в статьях Xyratex о преимуществах «оттестированных» дисков перед обычными «рыночными».

FishDude
02.09.2015 22:21+3FYI: Картинка «вероятность выхода из строя классического HDD в зависимости от времени» практически 1:1 повторяет график надежности… радиоламп. (По информации из книги «Reliability factors for Ground Electronic Equipment», NY, 1956).

Antigluk
03.09.2015 00:33+2Думаю он такой же для большинства устройств, у которых не слишком сложное устройство. Сначала отваливаются все устройства с мелким браком, все стабильные работают свой срок и начинают отваливатся уже от старости.

d_olex
03.09.2015 03:43+2Вообще-то жесткий диск является одним из самых сложных и точных электронно-механических устройств, с которыми вы можете столкнуться в повседневной жизни :)
vorphalack
03.09.2015 08:06точных — да. сложных? цифрозеркалки да и вообще фототехника со сменной оптикой посложнее будут конструктивно зачастую, хотя с допусками там попроще.
Antigluk
01.10.2015 13:30«Сложных» в смысле из нескольких модулей у которых разный срок работы. В этом смысле жесткий диск можно считать единым модулем, «простым» устройством, хотя понятно что оно не простое с технологической точки зрения.
ibKpoxa
>>5. Новые поколения SSD обычно лучше старых :)
Новые зачастую имеют лучшие алгоритмы работы с ячейками, но они же и имеют меньшее число циклов записи, поэтому иногда старые кажутся более надежными :)