
Модели на основе Трансформера достигли выдающихся результатов в самых разных областях знаний, включая разговорный ИИ, обработку естественного языка, изображений и даже музыки. Главной составляющей любой архитектуры Трансформеров является модуль внимания (attention module), который подсчитывает схожесть для всех пар во входной последовательности. Он, однако, плохо масштабируется с увеличением длины входной последовательности, требуя квадратичного увеличения вычислительного времени для получения всех оценок сходства, а также квадратичного увеличения объема задействованной памяти для построения матрицы для хранения этих оценок.
В приложениях, где требуется расширенное внимание, было предложено несколько быстрых и более компактных прокси, таких как методы кэширования памяти, однако более распространенным решением является использование разреженного внимания (sparse attention). Разреженное внимание сокращает время вычислений и требования к памяти для механизма внимания за счет вычисления только ограниченного числа оценок сходства из последовательности, а не всех возможных пар, в результате чего получается разреженная, а не полная матрица. Эти разреженные вхождения могут быть предложены вручную, найдены с помощью методов оптимизации, выучены или даже рандомизированы, что демонстрируется такими методами, как Разреженные Трансформеры (Sparse Transformers), Longformers, Маршрутизирующие Трансформеры (Routing Transformers), Reformers и Big Bird. Так как разреженные матрицы можно представить еще и графами и ребрами, методы разрежения также мотивированы литературой по графовым нейронным сетям, особенно относительно механизма внимания, изложенным в статье Graph Attention Networks. Такие архитектуры, основанные на разреженности, обычно требуют дополнительных слоев для неявного создания механизма полного внимания.
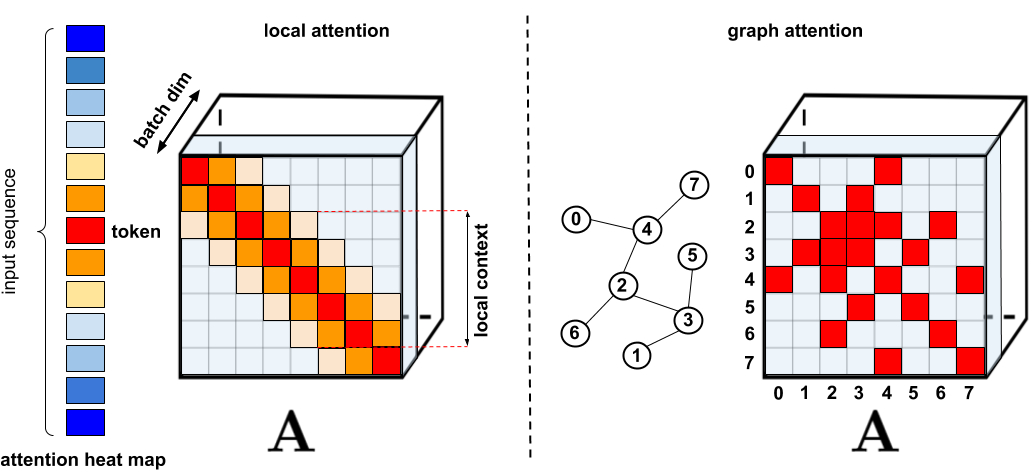
Стандартные методы разрежения. Слева: Пример схемы разреженности, когда токены относятся только к другим ближайшим токенам. Справа: Согласно статьи Graph Attention Networks, токены связаны только со своими соседями в графе, которые должны быть более релевантными, чем другие узлы. См. «Эффективные Трансформеры: обзор» для исчерпывающей классификации различных методов.
К сожалению, методы разреженного внимания могут иметь ряд ограничений. (1) Они требуют эффективных операций умножения разреженных матриц, которые доступны не на всех ускорителях; (2) они обычно не предоставляют строгих теоретических гарантий своей репрезентативной силы; (3) они оптимизированы, в первую очередь, для моделей Трансформера и генеративного предварительного обучения; и (4) они обычно насчитывают больше слоев внимания, чтобы компенсировать разреженные представления, что затрудняет их использование с другими предварительно обученными моделями и требует переобучения и значительного расхода вычислительных ресурсов. Помимо этих недостатков, механизмов разреженного внимания зачастую недостаточно для решения всего спектра проблем, к которым применяются обычные методы внимания, такие как Pointer Networks. Есть также некоторые операции, которые нельзя разредить, например, широко применяемая операция софтмакс (softmax), которая нормализует оценки сходства в механизме внимания и активно используется в рекомендательных системах промышленного масштаба.
Чтобы решить эти проблемы, авторы представляют Performer, архитектуру Трансформера с механизмом внимания, которая масштабируется линейно. Это позволяет ускорить обучение, делая возможным обработку более длинных последовательностей, что требуется для некоторых наборов изображений, таких как ImageNet64, и наборов текстовых данных, таких как PG-19. Performer использует эффективный (линейный) фреймворк обобщенного внимания, который позволяет применять широкий класс механизмов внимания, основанных на различных мерах (ядрах) сходства. Фреймворк реализован на основе нового алгоритма быстрого внимания с положительными ортогональными случайными признаками (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), который обеспечивает масштабируемую низкодисперсную и несмещенную оценку механизмов внимания. Последние могут быть выражены посредством случайных разложений карты признаков (в частности, обычного софтмакс-внимания). Мы получаем надежные гарантии точности для этого метода при сохранении линейной пространственной и временной сложности, что также может быть применено к отдельным операциям софтмакс.
Обобщенное внимание
В исходном механизме внимания входные значения запроса и ключа, соответствующие строкам и столбцам матрицы, перемножаются и проходят через функцию софтмакс для формирования матрицы внимания, в которой хранятся оценки сходства. Обратите внимание, что в этом методе нельзя разложить произведение ключ-запрос обратно на исходные значения запроса и ключа после передачи его в нелинейную операцию софтмакс. Однако можно разложить матрицу внимания обратно на произведение случайных нелинейных функций исходных запросов и ключей, известных как случайные признаки, что позволяет более эффективно кодировать информацию о сходстве.
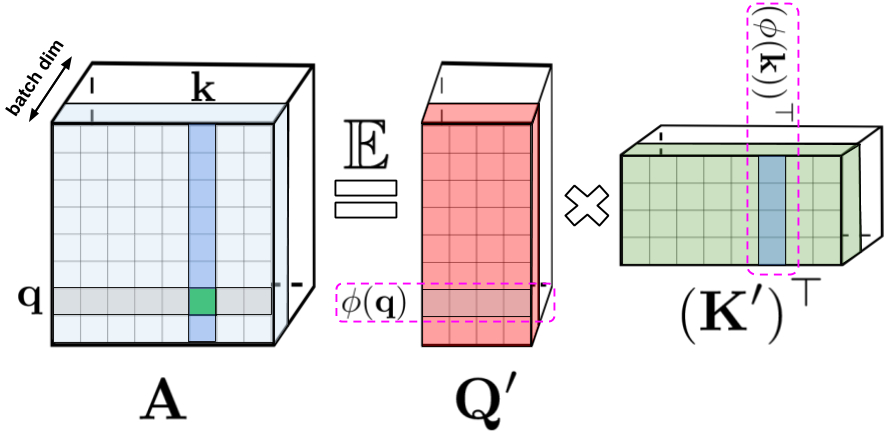
В левой части равенства: стандартная матрица внимания, которая содержит все оценки сходства для каждой пары записей, сформированных операцией софтмакс над запросом и ключами, обозначенными q и k. В правой части: стандартную матрицу внимания можно аппроксимировать с помощью случайных матриц более низкого ранга Q' и K' со строками, кодирующими потенциальные случайные нелинейные функции исходных запросов/ключей. Для обычного софтмакс-внимания преобразование очень компактно и включает экспоненциальную функцию, а также случайные гауссовские проекции.
Простое софтмакс-внимание можно рассматривать как частный случай подобных нелинейных функций, определяемых экспоненциальными функциями и гауссовскими проекциями. Стоит отметить, что можно рассуждать также и обратным образом, реализуя сначала более общие нелинейные функции, имплицитно определяя другие типы мер сходства (ядер) в произведении ключа и запроса. Авторы рассматривают это как обобщенное внимание, основываясь на более ранней работе о ядерных методах. Хотя для большинства ядер закрытых формул не существует, описанный авторами механизм все же можно применить, поскольку он не полагается на них.
Насколько можно судить, авторы первыми показали, что любую матрицу внимания можно эффективно аппроксимировать в последующих низкоуровневых применениях Трансформера с использованием случайных признаков. Новым механизмом, позволяющим это сделать, является использование положительных случайных признаков, то есть положительных нелинейных функций исходных запросов и ключей, которые оказываются критически важными для предотвращения нестабильности во время обучения и обеспечивают более точное приближение к обычному механизму софтмакс-внимания.
Навстречу FAVOR+: быстрое внимание за счет матричной ассоциативности
Описанная выше декомпозиция позволяет хранить неявную матрицу внимания с линейной, а не квадратичной сложностью по памяти. Используя это разложение, можно также получить линейное время работы механизма внимания. В то время как исходный механизм умножает сохраненную матрицу внимания на входное значение для получения окончательного результата, после разложения матрицы внимания можно переставить матричные умножения, чтобы аппроксимировать результат обычного механизма внимания без явного построения матрицы внимания квадратичного размера. В конечном итоге, это приводит к FAVOR+.
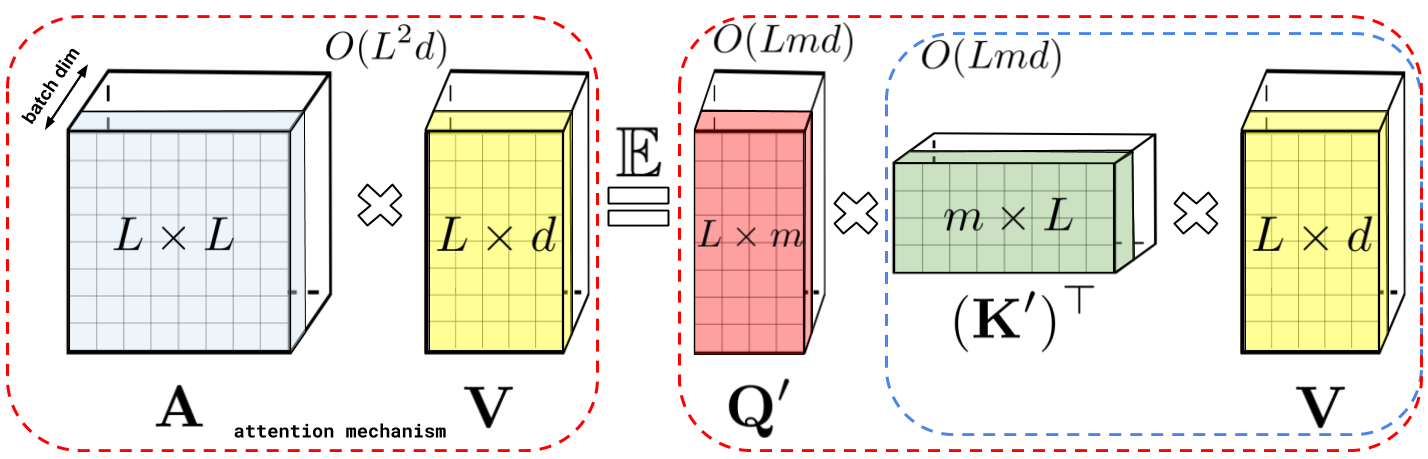
Слева: вычисление стандартного модуля внимания, где окончательный желаемый результат вычисляется путем выполнения матричного умножения матрицы внимания A на тензор значений V. Справа: путем разделения матриц Q' и K', используемых при разложении A более низкого ранга, и проведения матричных умножений в порядке, указанном пунктирными прямоугольниками, мы получаем линейный механизм внимания, никогда явно не конструируя A или ее приближение.
Вышеприведенный анализ актуален для так называемого двунаправленного внимания, то есть некаузального внимания, при котором отсутствует понятие прошлого и будущего. Для однонаправленного (каузального) внимания, когда токены не связаны с другими токенами, появляющимися позже во входной последовательности, авторы немного изменяют подход, чтобы использовать вычисления префиксной суммы, которые сохраняют только промежуточные итоги матричных вычислений, но не явную нижнюю треугольную часть обычной матрицы внимания.
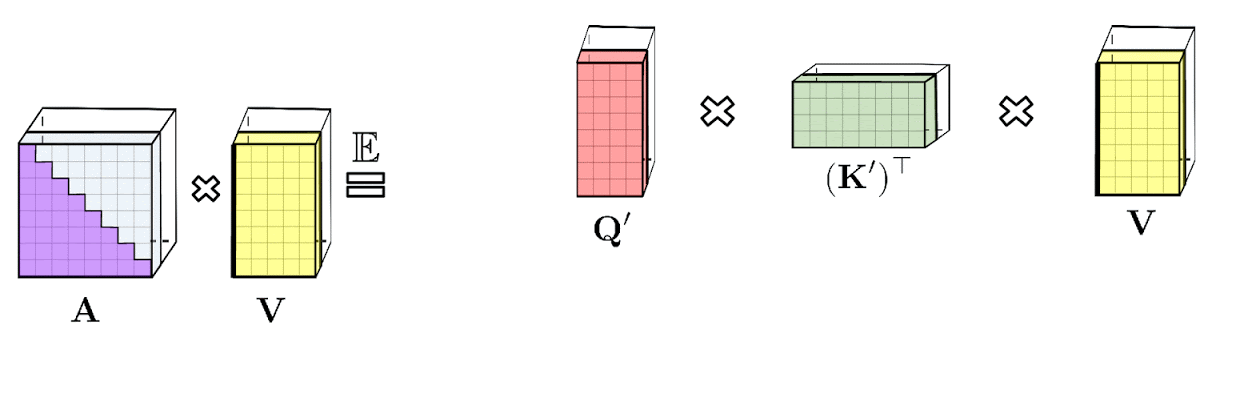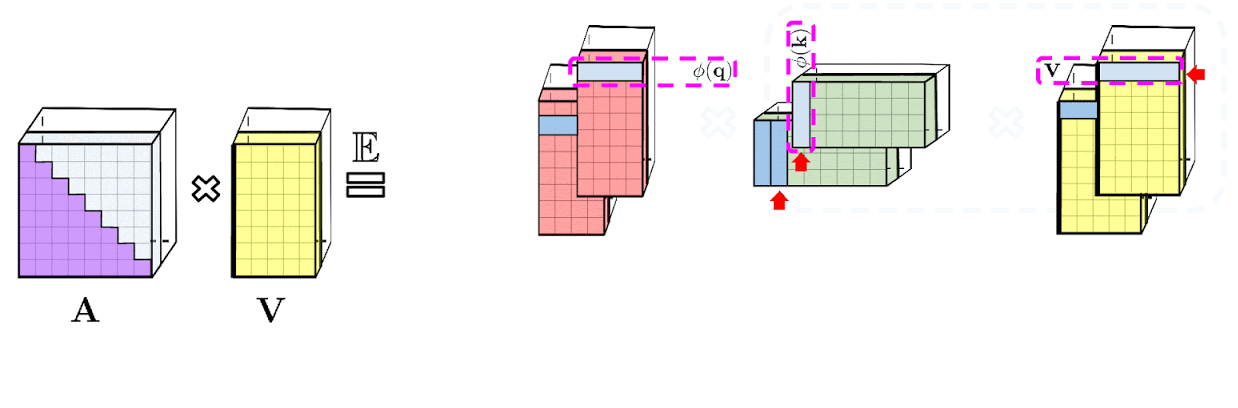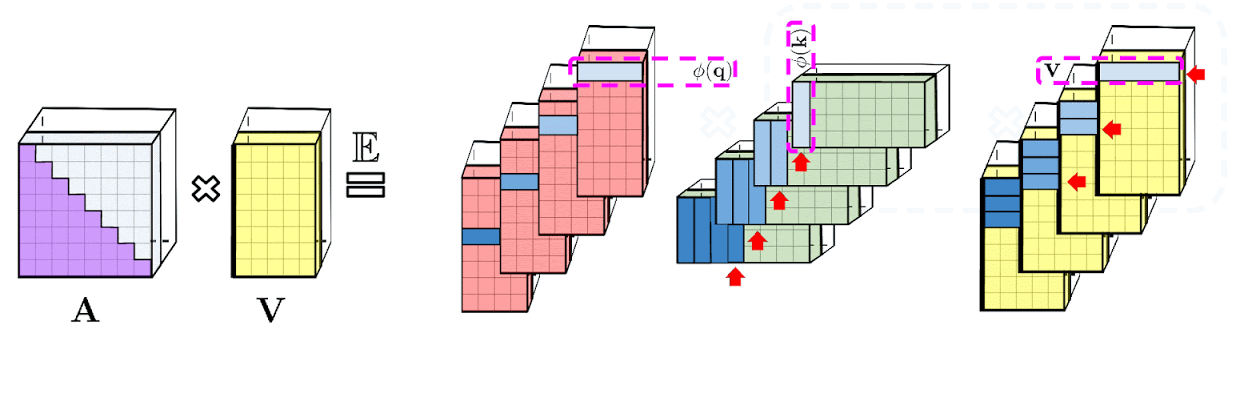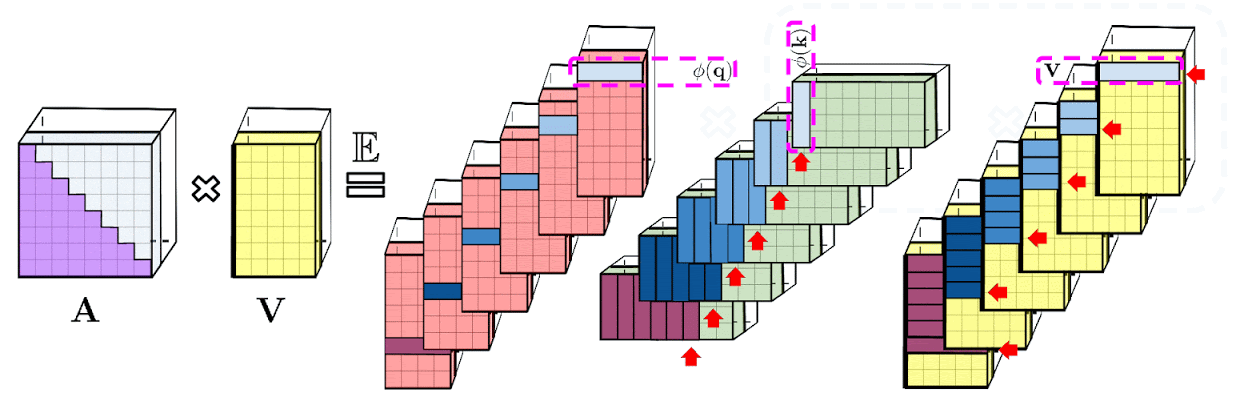
Слева: стандартное однонаправленное внимание требует маскирования матрицы внимания, чтобы получить ее нижнюю треугольную часть. Справа: несмещенное приближение в левой части равенства может быть получено с помощью механизма префиксной суммы, где сумма префиксов внешних произведений случайных карт признаков для ключей и векторов значений строится на лету и умножается слева на вектор случайных признаков запроса для получения новой строки в результирующей матрице.
Свойства
Сначала авторы сравнивают пространственную и временную сложность Performer и показывают, что ускорение внимания и сокращение памяти эмпирически почти оптимальны, то есть очень близки к тому, чтобы вообще не использовать механизм внимания в модели.
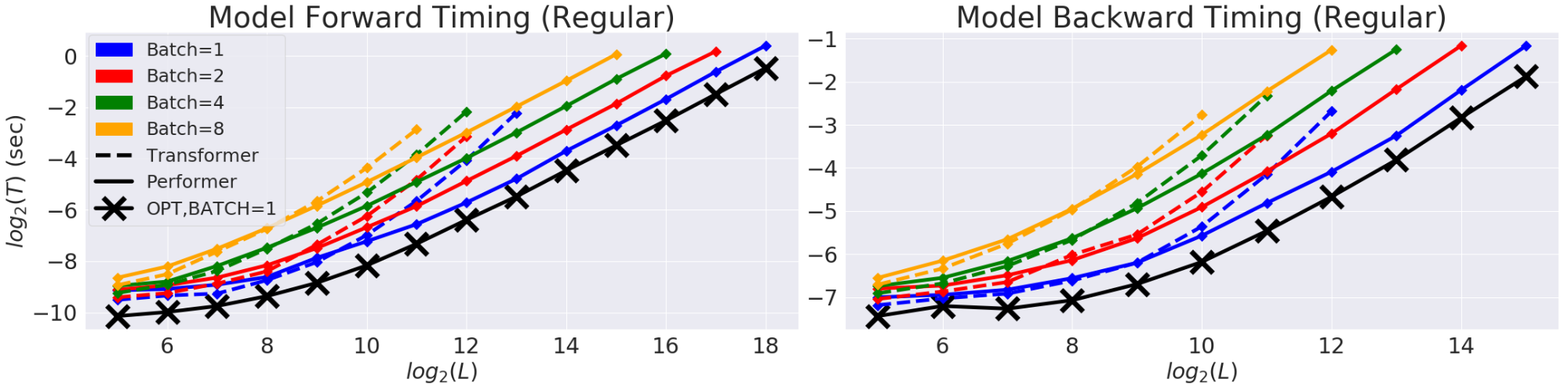
Двунаправленная синхронизация для обычной модели на основе Трансформера в логарифмическом графике со временем (T) и длиной (L). Линии заканчиваются на пределе памяти GPU. Черная линия (X) обозначает максимально возможное сжатие памяти и ускорение при использовании «фиктивного» блока внимания, который, по существу, обходит вычисления внимания и демонстрирует максимально возможную эффективность модели. Модель Performer почти способна достичь этой оптимальной производительности в компоненте внимания.
Авторы также показывают, что Performer, используя несмещенное софтмакс-приближение, обратно совместима с предварительно обученными моделями Трансформера после небольшой тонкой настройки, которая потенциально может снизить вычислительные затраты за счет повышения скорости инференса без необходимости полностью переобучать ранее существовавшие модели.
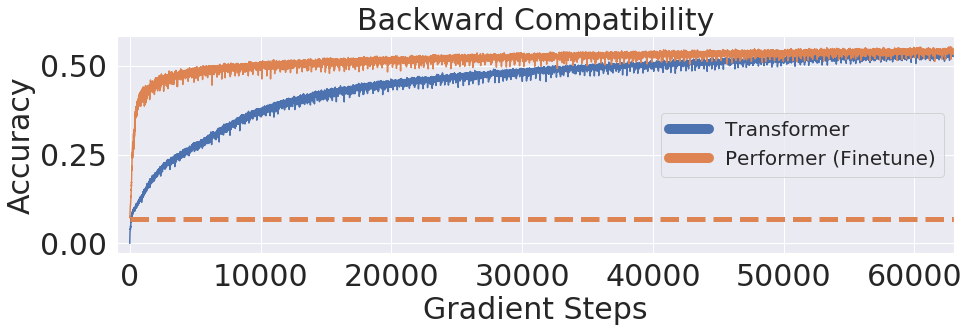
Используя набор данных One Billion Word Benchmark (LM1B), авторы перенесли исходные предварительно обученные веса модели Трансформера в модель Performer, которая дает начальную ненулевую точность 0.07 (пунктирная оранжевая линия). Однако после тонкой настройки Performer быстро восстанавливает точность за небольшую часть исходного количества шагов градиента.
Пример использования: моделирование белков
Белки — это большие молекулы со сложной трехмерной структурой и определенными функциями, которые необходимы для жизни. Как и слова, белки задаются линейными последовательностями, где каждый символ является одним из 20 аминокислотных строительных блоков. Применение Трансформеров к большим неразмеченным корпусам белковых последовательностей (например, UniRef) позволяет получить модели, которые можно использовать для точных прогнозов относительно свернутой функциональной макромолекулы. Performer-ReLU (который использует внимание на основе ReLU, экземпляр обобщенного внимания, который отличается от софтмакса) хорошо работает при моделировании данных последовательности белков, в то время как Performer-Softmax сходится по показателю точности (accuracy) с Трансформером, как и было предсказано теоретическими результатами авторов.
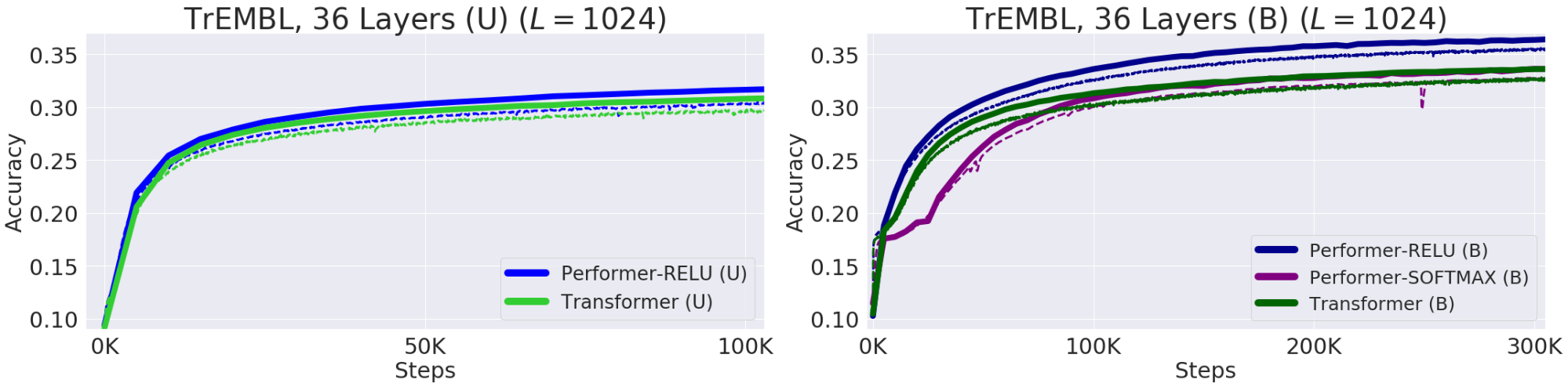
Эффективность моделирования белковых последовательностей. Набор для обучения (Train) — пунктир, набор для валидации (Validation) – сплошная линия, однонаправленный — (U), двунаправленный — (B). Авторы используют параметры модели с 36 слоями из ProGen (2019) для всех прогонов, в каждом из которых используется 16x16 TPU-v2. Размеры батчей были максимизированы для каждого запуска с учетом соответствующих вычислительных ограничений.
Ниже представлена визуализация модели Protein Performer, обученной с использованием механизма приближенного внимания на основе ReLU. Использование Performer для оценки сходства между аминокислотами позволяет восстановить структуру, аналогичную хорошо известным матрицам замен, полученным путем анализа шаблонов эволюционных замен в тщательно подобранных соответствиях последовательностей. В более общем плане авторы обнаружили, что локальные и глобальные шаблоны внимания соответствуют моделям Трансформера, обученным на данных о белках. Приближение неразреженного внимания Performer'а может улавливать глобальные взаимодействия между множеством белковых последовательностей. В качестве доказательства концепции авторы обучили модели на длинных конкатенированных последовательностях белков, что превысило бы допустимый объем памяти обычной модели Трансформера, но не Performer из-за его компактности.
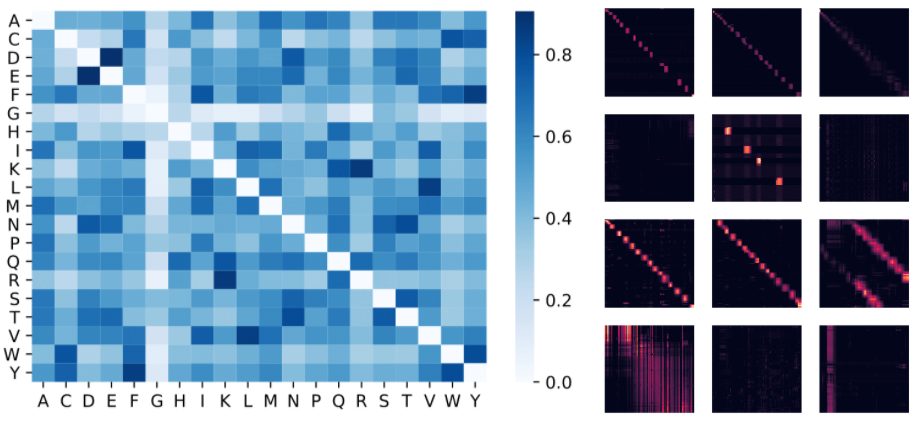
Слева: матрица сходства аминокислот, оцененная по весам внимания. Модель распознает очень похожие пары аминокислот, такие как (D, E) и (F, Y), несмотря на доступ только к последовательностям белков без предварительной информации о биохимии. Справа: матрицы внимания из 4 слоев (строк) и 3 выбранных «голов» (столбцов) для белка BPT1_BOVIN, показывающие локальные и глобальные шаблоны внимания.
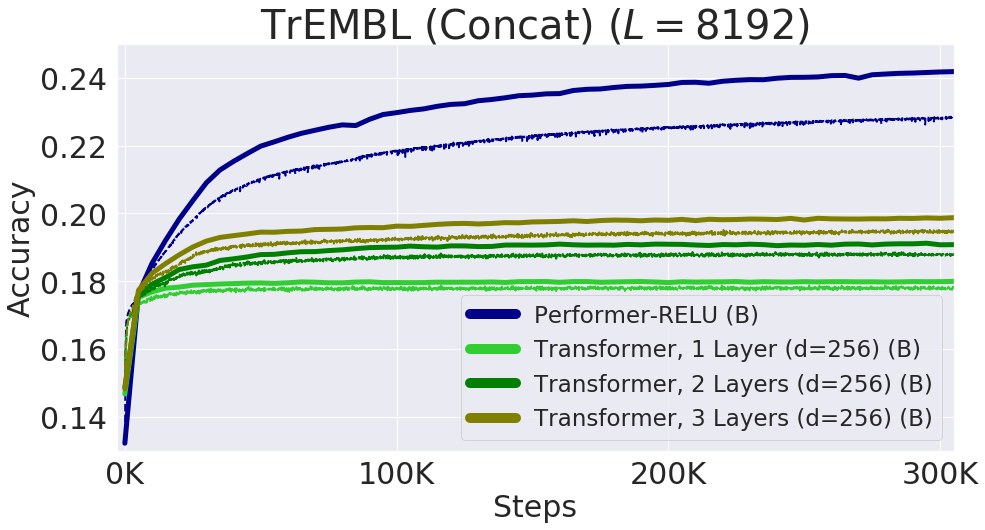
Качество на последовательностях длиной до 8192, полученных путем конкатенации отдельных белковых последовательностей. Чтобы поместиться в память TPU, размер модели Трансформера (количество слоев и размерность эмбеддингов) был уменьшен.
Вывод
Работа авторов вносит вклад в недавние усилия по созданию методов, основанных на неразреженности и ядерных интерпретациях Трансформеров. Метод авторов совместим с другими техниками, такими как обратимые слои, и авторы даже интегрировали FAVOR с кодом Reformer. Авторы предоставляют ссылки на статью, код Performer'а и код для языкового моделирования белковых последовательностей. Авторы полагают, что их исследование открывает совершенно новый взгляд на внимание, архитектуры Трансформера и даже ядерные методы.
Авторы
- Авторы оригинала — Krzysztof Choromanski, Lucy Colwell
- Перевод — Смирнова Екатерина
- Редактирование и вёрстка — Шкарин Сергей
DaniyarM
А что за внимание с ReLU? Показано, что оно лучше, но не слова о том, что это.
Kouki_RUS Автор
Авторы в данной статье на этом не акцентировали внимание. Более подробно про внимание с ReLU можно прочитать в исходной работе:
arxiv.org/abs/2009.14794