
Привет Хабр! В блоге на нашем сайте мы регулярно публикуем статьи про данные и всё, что с ними связано. Некоторые материалы оттуда публикуем и здесь.
Как компании узнают, кто из дата-сайентистов круче, когда нанимают их на работу? Как показать свой талант и стать известным в сообществе? На основе чего формируется рейтинг, исходя из которого вас потом могут нанять на престижную позицию? Рассказываем про самую известную состязательную платформу, возможности и правила ее игры, а еще раскрываем список лучших участников из России.

Дата-сайенс — по определению всё-таки наука. Поэтому, чтобы оценивать разработчиков и аналитиков долгое время применялся и применяется распространенный среди ученых индекс Хирша. Он помогает по числу публикаций и их цитируемости понять, насколько востребованы научные работы — а значит и их автор.
Но часто компании держат информацию о своих сотрудниках и их работе в тайне. Особенно тщательно скрывают дата-сайентистов в России, где наблюдается огромный дефицит кадров в этой области.
В ответ на спрос стала расти популярность соревновательных платформ для разработчиков. Самый известный сервис — Kaggle (произносится: «кэджл»), который принадлежит Google. Его используют студенты, а профессиональные разработчики рассказывают, как прокачать свой рейтинг. Применяемые там решения задают моду в среде дата-сайентистов, а компании в России и в мире обращают внимание на место в рейтингах Kaggle при найме на работу.
Kaggle полностью бесплатен, и любой пользователь может организовать конкурс по исследованию данных или участвовать в уже существующем. В системе размещены наборы открытых данных, а также предоставляются облачные инструменты для их обработки и машинного обучения. Еще есть возможность учиться и раздел для размещения вакансий, где отобрать лучших кандидатов тоже помогут конкурсы.
Одна из интересных фич Kaggle, благодаря которой он стал настолько популярен в среде дата-сайенс, — система рейтинга.
Пользователи могут зарабатывать очки и улучшать свой рейтинг в четырех разных категориях:
Продвижение в каждой из категорий не зависит от остальных. В них доступны разные уровни достижений:
Медали присваиваются за отличный результат на соревнованиях, популярный программный код или полезный набор данных и остаются навсегда. В то же время баллы со временем теряют свою ценность, что позволяет общему рейтингу оставаться актуальным.
Больше всего в Kaggle зарегистрировано пользователей из Индии и США. Россияне занимают в общем рейтинге стран стабильное пятое место — между Китаем и Японией. Первое место в общем рейтинге соревнований по дата сайенс занимает Гуаншо Сю (Guanshuo Xu) — дата-сайентист из Нью-Йорка. За пять лет он набрал более 255 тысяч очков в Kaggle-соревнованиях (это абсолютный рекорд).
Гуаншо закончил бакалавриат по специальности «Электротехника и электроника» в университете Тунцзи в Шанхае, а после поступил в магистратуру университета Нью-Джерси. С 2010 года он занимался задачами по распознаванию изображений и алгоритмами машинного обучения, в 2017 году впервые стал грандмастером в Kaggle, а с 2019 года работает на позиции Data Scientist в H2O.ai (алгоритмами этой компании пользуются Cisco, Intel и PayPal).
Для составления списка лучших практикующих дата-сайентистов России мы использовали данные участников Kaggle-соревнований, у которых указана личная информация.
 Самый сильный из участвующих в Kaggle-соревнованиях российский разработчик Дмитрий Гордеев (dott) тоже работает в H2O.ai. Он зарегистрировался в Kaggle восемь лет назад, и на сегодня у него 114 тысяч очков.
Самый сильный из участвующих в Kaggle-соревнованиях российский разработчик Дмитрий Гордеев (dott) тоже работает в H2O.ai. Он зарегистрировался в Kaggle восемь лет назад, и на сегодня у него 114 тысяч очков.
В общем рейтинге Kaggle он занимает девятое место. В 2010 году Дмитрий закончил МГУ, занимаясь там распознаванием изображений и data mining. Работая с 2008 года в группе моделирования розничных рисков в банке, он вырос до директора подразделения и переехал в Австрию в 2013 году. В 2014 году прошел курс по дата-сайенс на Coursera, а уже в 2020-м присоединился к команде в H2O.ai.
 На втором месте среди российских дата-сайентистов в рейтинге соревнований Kaggle — Артур Кузин (n01z3) — он занимает 28-е место в общем рейтинге Kaggle, имея больше 71 тысячи очков.
На втором месте среди российских дата-сайентистов в рейтинге соревнований Kaggle — Артур Кузин (n01z3) — он занимает 28-е место в общем рейтинге Kaggle, имея больше 71 тысячи очков.
Артур закончил Московский физико-технический институт в 2011 году и занимался исследовательской аналитикой с 2008 по 2016 год. После этого он устроился в «Авито» на позицию Data Scientist, а последние несколько лет руководит командой по Computer Vision в X5 Retail Group. У Артура несколько публикаций по физике и патент на устройство для калибровки просвечивающих электронных микроскопов.
 Третье место в общем рейтинге соревнований Kaggle среди россиян занимает Артем Кулаков (Art) — в общем рейтинге у него 29-е место и 71 тысяча очков Kaggle, которые он заработал за два года участия в соревнованиях. Артем учится в ВШЭ по специальности Computer Science и уже успел поработать на позиции Data Analyst в «Тинькофф Банке» и «Мегафоне». Сейчас Артем занимается фрилансом и специализируется на задачах Computer Vision и NLP.
Третье место в общем рейтинге соревнований Kaggle среди россиян занимает Артем Кулаков (Art) — в общем рейтинге у него 29-е место и 71 тысяча очков Kaggle, которые он заработал за два года участия в соревнованиях. Артем учится в ВШЭ по специальности Computer Science и уже успел поработать на позиции Data Analyst в «Тинькофф Банке» и «Мегафоне». Сейчас Артем занимается фрилансом и специализируется на задачах Computer Vision и NLP.
 На четвертом месте Роман Соловьев (ZFTurbo) — у него 69 тысяч очков и 31-е место в общем рейтинге соревнований Kaggle. Роман — ведущий научный сотрудник Института проблем проектирования в микроэлектронике РАН.
На четвертом месте Роман Соловьев (ZFTurbo) — у него 69 тысяч очков и 31-е место в общем рейтинге соревнований Kaggle. Роман — ведущий научный сотрудник Института проблем проектирования в микроэлектронике РАН.
 На пятом месте Илья Ларченко (ilialar), занимающий сейчас 37-е место в общем рейтинге Kaggle с 65 тысячами очков. Илья окончил МФТИ в 2014 году, а затем работал аналитиком и разработчиком. С 2017 года он руководил командой дата сайентистов в компании DOC+, а в 2020 году переехал в Таиланд, где работает на позиции Data Science Manager в компании Agoda.
На пятом месте Илья Ларченко (ilialar), занимающий сейчас 37-е место в общем рейтинге Kaggle с 65 тысячами очков. Илья окончил МФТИ в 2014 году, а затем работал аналитиком и разработчиком. С 2017 года он руководил командой дата сайентистов в компании DOC+, а в 2020 году переехал в Таиланд, где работает на позиции Data Science Manager в компании Agoda.
Небольшой элемент геймификации, позволяющий пользователям зарабатывать баллы и медали в соревнованиях Kaggle, изменил правила игры в вопросах найма.
Пример лучших дата-сайентистов из России показывает: образование и опыт работы с данными не столь важны для построения успешной карьеры. Например, Артем Кулаков еще учится в университете, а принимать участие в соревнованиях на Kaggle начал всего два года назад. Сейчас он — в списке лучших дата-сайентистов России и работает на фрилансе. Гуаншо Сю закончил бакалавриат по специальности «Электротехника и электроника», а сейчас работает в H2O.ai — лидере open source решений в дата-сайенс.
Начните с простых задач сегодня — и кто знает, быть может, через год или два вы сможете оказаться в рейтинге лучших дата сайентистов и двигать прогресс вперед, реализуя технологии исследований ВИЧ, модели прогнозирования загруженности магистралей и многое другое. Главное — иметь желание развиваться в области Data Science и как можно больше практиковаться.

Как компании узнают, кто из дата-сайентистов круче, когда нанимают их на работу? Как показать свой талант и стать известным в сообществе? На основе чего формируется рейтинг, исходя из которого вас потом могут нанять на престижную позицию? Рассказываем про самую известную состязательную платформу, возможности и правила ее игры, а еще раскрываем список лучших участников из России.
Дата-сайенс — по определению всё-таки наука. Поэтому, чтобы оценивать разработчиков и аналитиков долгое время применялся и применяется распространенный среди ученых индекс Хирша. Он помогает по числу публикаций и их цитируемости понять, насколько востребованы научные работы — а значит и их автор.
Индекс Хирша h равен числу статей, на каждую из которых сослались не менее h раз. То есть, чтобы его рассчитать, берут все статьи ученого, которые цитировали его коллеги, расставляют в порядке уменьшения числа ссылок на них, присваивая им номера. После этого находят последнюю статью, чей номер не превосходит число ее цитирований. Этот номер и есть индекс Хирша.Сложно? Вроде не очень, а уж настоящим дата-сайентистам понятно сразу — вот только для оценки их работы не слишком подходит. Ведь результат их работы куда чаще — код, а не научный текст. К тому же дата-сайентисты востребованы на рынке, а рынку важнее примеры алгоритмов, чем достижения в науке.
Но часто компании держат информацию о своих сотрудниках и их работе в тайне. Особенно тщательно скрывают дата-сайентистов в России, где наблюдается огромный дефицит кадров в этой области.
В ответ на спрос стала расти популярность соревновательных платформ для разработчиков. Самый известный сервис — Kaggle (произносится: «кэджл»), который принадлежит Google. Его используют студенты, а профессиональные разработчики рассказывают, как прокачать свой рейтинг. Применяемые там решения задают моду в среде дата-сайентистов, а компании в России и в мире обращают внимание на место в рейтингах Kaggle при найме на работу.
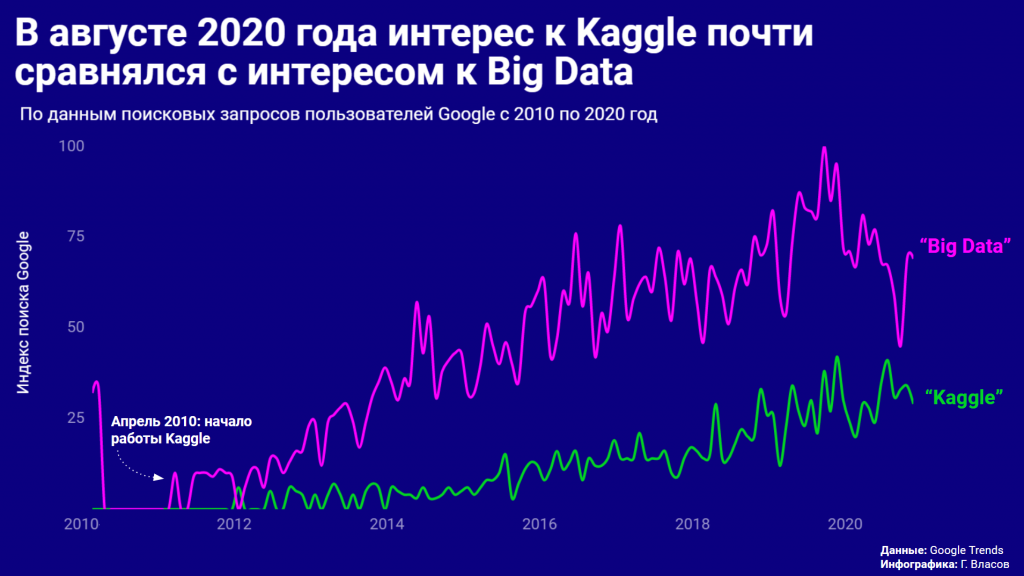
В 2017 году в Kaggle было зарегистрировано больше миллиона пользователей, а в августе 2020 года пользователи из России гуглили сервис почти так же часто, как словосочетание «?Big Data»?:
Kaggle полностью бесплатен, и любой пользователь может организовать конкурс по исследованию данных или участвовать в уже существующем. В системе размещены наборы открытых данных, а также предоставляются облачные инструменты для их обработки и машинного обучения. Еще есть возможность учиться и раздел для размещения вакансий, где отобрать лучших кандидатов тоже помогут конкурсы.
Как это работает
Одна из интересных фич Kaggle, благодаря которой он стал настолько популярен в среде дата-сайенс, — система рейтинга.
Пользователи могут зарабатывать очки и улучшать свой рейтинг в четырех разных категориях:
- Соревнования. В одиночку или командой вы решаете задачи по машинному обучению. Соревнования очень разнообразны: от простой и понятной задачи по предсказанию количества выживших на «Титанике» до оценки эффективности игроков защиты при игре в пас от NFL Big Data Bowl 2021.
- Программный код. Делитесь своим кодом с сообществом, запуская его в Kaggle Notebooks — облачной вычислительной среде.
- Наборы данных. Вы можете помогать другим дата-сайентистам, выкладывая новые данные для совместного использования.
- Обсуждения. Обсуждайте задачи и делитесь лучшими решениями, а также оценивайте посты других пользователей.
Продвижение в каждой из категорий не зависит от остальных. В них доступны разные уровни достижений:
- Новичок. Вам достаточно зарегистрироваться.
- Участник. Вы заполнили профиль и пообщались с сообществом, а также использовали все возможности платформы:
— Запустили один скрипт.
— Поучаствовали в одном соревновании.
— Написали один комментарий.
— Отдали один голос кому-то из участников.
- Эксперт. Вы выполнили значительный объем работ в Kaggle в одной или нескольких областях знаний и заработали бронзовые медали. Для каждой из категорий необходимо разное количество медалей, а после получения достижения вы попадете в рейтинг Kaggle соответствующей категории.
- Мастер. Чтобы получить этот уровень, нужно продемонстрировать превосходство в одной или нескольких категориях знаний на Kaggle и получить серебряные или золотые медали в зависимости от категорий. Мастера в категории «Соревнования» имеют право участвовать в эксклюзивных состязаниях, недоступных другим категориям.
- Грандмастер. Вы постоянно демонстрируете выдающиеся показатели и получаете золотые медали. Вы лучший из лучших.
Медали присваиваются за отличный результат на соревнованиях, популярный программный код или полезный набор данных и остаются навсегда. В то же время баллы со временем теряют свою ценность, что позволяет общему рейтингу оставаться актуальным.
Кто на первом месте?
Больше всего в Kaggle зарегистрировано пользователей из Индии и США. Россияне занимают в общем рейтинге стран стабильное пятое место — между Китаем и Японией. Первое место в общем рейтинге соревнований по дата сайенс занимает Гуаншо Сю (Guanshuo Xu) — дата-сайентист из Нью-Йорка. За пять лет он набрал более 255 тысяч очков в Kaggle-соревнованиях (это абсолютный рекорд).
Гуаншо закончил бакалавриат по специальности «Электротехника и электроника» в университете Тунцзи в Шанхае, а после поступил в магистратуру университета Нью-Джерси. С 2010 года он занимался задачами по распознаванию изображений и алгоритмами машинного обучения, в 2017 году впервые стал грандмастером в Kaggle, а с 2019 года работает на позиции Data Scientist в H2O.ai (алгоритмами этой компании пользуются Cisco, Intel и PayPal).
Лучшие дата-сайентисты из России по версии Kaggle
Для составления списка лучших практикующих дата-сайентистов России мы использовали данные участников Kaggle-соревнований, у которых указана личная информация.
Самый сильный из участвующих в Kaggle-соревнованиях российский разработчик Дмитрий Гордеев (dott) тоже работает в H2O.ai. Он зарегистрировался в Kaggle восемь лет назад, и на сегодня у него 114 тысяч очков.В общем рейтинге Kaggle он занимает девятое место. В 2010 году Дмитрий закончил МГУ, занимаясь там распознаванием изображений и data mining. Работая с 2008 года в группе моделирования розничных рисков в банке, он вырос до директора подразделения и переехал в Австрию в 2013 году. В 2014 году прошел курс по дата-сайенс на Coursera, а уже в 2020-м присоединился к команде в H2O.ai.
На втором месте среди российских дата-сайентистов в рейтинге соревнований Kaggle — Артур Кузин (n01z3) — он занимает 28-е место в общем рейтинге Kaggle, имея больше 71 тысячи очков. Артур закончил Московский физико-технический институт в 2011 году и занимался исследовательской аналитикой с 2008 по 2016 год. После этого он устроился в «Авито» на позицию Data Scientist, а последние несколько лет руководит командой по Computer Vision в X5 Retail Group. У Артура несколько публикаций по физике и патент на устройство для калибровки просвечивающих электронных микроскопов.
Третье место в общем рейтинге соревнований Kaggle среди россиян занимает Артем Кулаков (Art) — в общем рейтинге у него 29-е место и 71 тысяча очков Kaggle, которые он заработал за два года участия в соревнованиях. Артем учится в ВШЭ по специальности Computer Science и уже успел поработать на позиции Data Analyst в «Тинькофф Банке» и «Мегафоне». Сейчас Артем занимается фрилансом и специализируется на задачах Computer Vision и NLP. На четвертом месте Роман Соловьев (ZFTurbo) — у него 69 тысяч очков и 31-е место в общем рейтинге соревнований Kaggle. Роман — ведущий научный сотрудник Института проблем проектирования в микроэлектронике РАН. На пятом месте Илья Ларченко (ilialar), занимающий сейчас 37-е место в общем рейтинге Kaggle с 65 тысячами очков. Илья окончил МФТИ в 2014 году, а затем работал аналитиком и разработчиком. С 2017 года он руководил командой дата сайентистов в компании DOC+, а в 2020 году переехал в Таиланд, где работает на позиции Data Science Manager в компании Agoda. Небольшой элемент геймификации, позволяющий пользователям зарабатывать баллы и медали в соревнованиях Kaggle, изменил правила игры в вопросах найма.
Пример лучших дата-сайентистов из России показывает: образование и опыт работы с данными не столь важны для построения успешной карьеры. Например, Артем Кулаков еще учится в университете, а принимать участие в соревнованиях на Kaggle начал всего два года назад. Сейчас он — в списке лучших дата-сайентистов России и работает на фрилансе. Гуаншо Сю закончил бакалавриат по специальности «Электротехника и электроника», а сейчас работает в H2O.ai — лидере open source решений в дата-сайенс.
Начните с простых задач сегодня — и кто знает, быть может, через год или два вы сможете оказаться в рейтинге лучших дата сайентистов и двигать прогресс вперед, реализуя технологии исследований ВИЧ, модели прогнозирования загруженности магистралей и многое другое. Главное — иметь желание развиваться в области Data Science и как можно больше практиковаться.
Eще курсы
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Machine Learning
- Профессия Этичный хакер
- Разработчик игр на Unity
- Курс по JavaScript
- Профессия Веб-разработчик
- Профессия Java-разработчик
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Сколько зарабатывает дата-сайентист: обзор зарплат и вакансий в 2020
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в 2020
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Machine Learning и Computer Vision в добывающей промышленности
neurocore
Статья ради статьи. Ну хватит.
Ilha
Статья ради рекламы. Никогда не хватит.