
Привет, Хабр!
Я работаю Computer Vision Engineer в Everypixel и сегодня расскажу вам, как мы учили генеративно-состязательную сеть создавать тени на изображении.
Разрабатывать GAN не так трудно, как кажется на первый взгляд. В научном мире существует множество статей и публикаций на тему генеративно-состязательных сетей. В этой статье я покажу вам, как можно реализовать архитектуру нейросети и решение, предложенное в одной из научных статей. В качестве опорной статьи я выбрал ARShadowGAN — публикация о GAN, генерирующей реалистичные тени для нового, вставленного в изображение объекта. Поскольку от оригинальной архитектуры я буду отклоняться, то дальше я буду называть своё решение ARShadowGAN-like.

Вот что вам понадобится:
браузер;
опыт работы с Python;
гугл-аккаунт для того, чтобы работать в среде Google Colaboratory.
Описание генеративно-состязательной сети
Напомню, что генеративно-состязательная сеть состоит из двух сетей:
генератора, создающего изображение из входного шума (у нас генератор будет создавать тень, принимая изображение без тени и маску вставленного объекта);
дискриминатора, различающего настоящее изображение от поддельного, полученного от генератора.
Генератор и дискриминатор работают вместе. Генератор учится всё лучше и лучше генерировать тень, обманывать дискриминатор. Дискриминатор же учится качественно отвечать на вопрос, настоящее ли изображение.
Основная задача — научить генератор создавать качественную тень. Дискриминатор нужен только для более качественного обучения, а в дальнейших этапах (тестирование, инференс, продакшн и т.д.) он участвовать не будет.
Генератор
Генератор ARShadowGAN-like состоит из двух основных блоков: attention и shadow generation (SG).

Одна из фишек для улучшения качества результатов — использование механизма внимания. Карты внимания — это, иначе говоря, маски сегментации, состоящие из нулей (чёрный цвет) и единиц (белый цвет, область интереса).
Attention блок генерирует так называемые карты внимания — карты тех областей изображения, на которые сети нужно обращать больше внимания. Здесь в качестве таких карт будут выступать маска соседних объектов (окклюдеров) и маска падающих от них теней. Так мы будто бы указываем сети, как нужно генерировать тень, она ориентируется, используя в качестве подсказки тени от соседних объектов. Подход очень похож на то, как человек действовал бы в жизни при построении тени вручную, в фотошопе.
Архитектура модуля: U-Net, в котором 4 канала на входе (RGB-изображение без тени и маска вставленного объекта) и 2 канала на выходе (маска окклюдеров и соответствующих им теням).
Shadow generation — самый важный блок в архитектуре всей сети. Его цель: создание 3-канальной маски тени. Он, аналогично attention, имеет U-Net-архитектуру с дополнительным блоком уточнения тени на выходе (refinement). На вход блоку поступает вся известная на данный момент информация: исходное изображение без тени (3 канала), маска вставленного объекта (1 канал) и выход attention блока — маска соседних объектов (1 канал) и маска теней от них (1 канал). Таким образом, на вход модулю приходит 6-канальный тензор. На выходе 3 канала — цветная маска тени для вставленного объекта.
Выход shadow generation попиксельно конкатенируется (складывается) с исходным изображением, в результате чего получается изображение с тенью. Конкатенация также напоминает послойную накладку тени в фотошопе — тень будто вставили поверх исходной картинки.
Дискриминатор
В качестве дискриминатора возьмем дискриминатор от SRGAN. Он привлек своей небольшой, но достаточно мощной архитектурой, а также простотой реализации.
Таким образом, полная схема ARShadowGAN-like будет выглядеть примерно так (да, мелко, но крупным планом отдельные кусочки были показаны выше O):

О датасете
Обучение генеративно-состязательных сетей обычно бывает paired и unpaired.
С парными данными (paired) всё достаточно прозрачно: используется подход обучения с учителем, то есть имеется правильный ответ (ground truth), с которым можно сравнить выход генератора. Для обучения сети составляются пары изображений: исходное изображение — измененное исходное изображение. Нейронная сеть учится генерировать из исходного изображения его модифицированную версию.
Непарное обучение — подход обучения сети без учителя. Зачастую такой подход используется, когда получить парные данные либо невозможно, либо трудно. Например, unpaired обучение часто применяется в задаче Style Transfer— перенос стиля с одного изображения на другое. Здесь вообще неизвестен правильный ответ, именно поэтому происходит обучение без учителя.

Изображение взято здесь.
Вернемся к нашей задаче генерации теней. Авторы ARShadowGAN используют парные данные для обучения своей сети. Парами здесь являются изображение без тени — соответствующее ему изображение с тенью.
Как же собрать такой датасет?
Вариантов здесь достаточно много, приведу некоторые из них:
Можно попробовать собрать такой набор данных вручную — отснять датасет. Нужно зафиксировать сцену, параметры камеры и т.д., после чего занулять тени в исходной сцене (например, с помощью регулирования света) и получать снимки без тени и с тенью. Такой подход очень трудоемок и затратен.
Альтернативным подходом я вижу сбор датасета из других изображений с тенями. Логика такая: возьмем изображение с тенью и тень удалим. Отсюда вытекает другая, не менее лёгкая задача — Image Inpainting — восстановление вырезанных мест в изображении, либо опять же ручная работа в фотошопе. Кроме того, сеть может легко переобучиться на таком датасете, поскольку могут обнаружиться артефакты, которые не видны человеческому глазу, но заметны на более глубоком семантическом уровне.
Еще один способ — сбор синтетического датасета с помощью 3D. Авторы ARShadowGAN пошли по этому пути и собрали ShadowAR-dataset. Идея следующая: сперва авторы выбрали несколько 3D-моделей из известной библиотеки ShapeNet, затем эти модели фиксировались в правильном положении относительно сцены. Далее запускался рендер этих объектов на прозрачном фоне с включенным источником освещения и выключенным — с тенью и без тени. После этого рендеры выбранных объектов просто вставлялись на 2D-изображения сцен без дополнительных обработок. Так получили пары: исходное изображение без тени (noshadow) и ground truth изображение с тенью (shadow). Подробнее о сборе ShadowAR-dataset можно почитать в оригинальной статье.
Итак, пары изображений noshadow и shadow у нас есть. Откуда берутся маски?
Напомню, что масок у нас три: маска вставленного объекта, маска соседних объектов (окклюдеров) и маска теней от них. Маска вставленного объекта легко получаются после рендера объекта на прозрачном фоне. Прозрачный фон заливается черным цветом, все остальные области, относящиеся к нашему объекту, — белым. Маски же соседних объектов и теней от них были получены авторами ARShadowGAN с помощью привлечения человеческой разметки (краудсорсинга).

Функции потерь и метрики
Attention
В этом месте отклонимся от статьи — возьмем функцию потерь для решения задачи сегментации.
Генерацию карт внимания (масок) можно рассматривать как классическую задачу сегментации изображений. В качестве функции потерь возьмем Dice Loss. Она хорошо устойчива по отношению к несбалансированным данным.
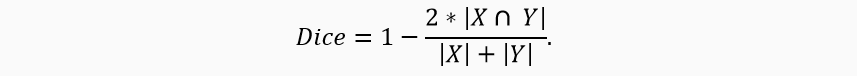
В качестве метрики возьмем IoU (Intersection over Union).
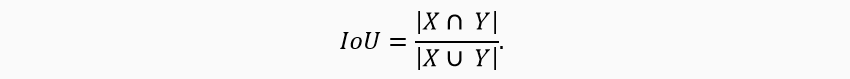
Подробнее о Dice Loss и IoU можно посмотреть здесь.
Shadow generation
Функцию потерь для блока генерации возьмем подобной той, что приведена в оригинальной статье. Она будет состоять из взвешенной суммы трёх функций потерь: L2, Lper и Ladv:
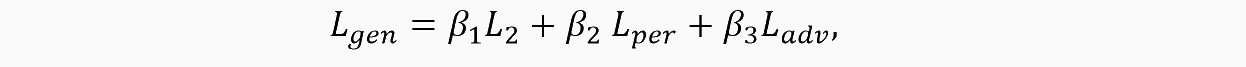
L2 будет оценивать расстояние от ground truth изображения до сгенерированных (до и после refinement-блока, обозначенного как R).

Lper (perceptual loss) — функция потерь, вычисляющая расстояние между картами признаков сети VGG16 при прогоне через неё изображений. Разница считается стандартным MSE между ground truth изображением с тенью и сгенерированными изображениями — до и после refinement-блока соответственно.

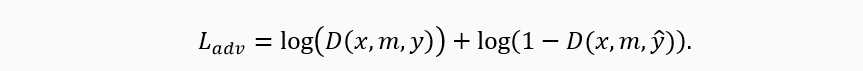
Ladv — стандартный adversarial лосс, который учитывает соревновательный момент между генератором и дискриминатором. Здесь D(.) — вероятность принадлежности к классу «настоящее изображение». В ходе обучения генератор пытается минимизировать Ladv, в то время как дискриминатор, наоборот, — пытается его максимизировать.
Подготовка
Установка необходимых модулей
Для реализации ARShadowGAN-like будет использоваться библиотека глубокого обучения для Python — pytorch.
Используемые библиотеки: что для чего?
Работу начнём с установки необходимых модулей:
segmentation-models-pytorch — для импорта U-Net архитектуры;
albumentations — для аугментаций;
piq — для импорта необходимой функции потерь;
matplotlib — для отрисовки изображений внутри ноутбуков;
numpy — для работы с массивами;
opencv-python — для работы с изображениями;
tensorboard — для визуализации графиков обучения;
torch — для нейронных сетей и глубокого обучения;
torchvision — для импорта моделей, для глубокого обучения;
tqdm — для progress bar визуализации.
pip install segmentation-models-pytorch==0.1.0
pip install albumentations==0.5.1
pip install piq==0.5.1
pip install matplotlib==3.2.1
pip install numpy==1.18.4
pip install opencv-python>=3.4.5.20
pip install tensorboard==2.2.1
pip install torch>=1.5.0
pip install torchvision>=0.6.0
pip install tqdm>=4.41.1Датасет
Датасет: структура, скачивание, распаковка
Для обучения и тестирования я буду использовать готовый датасет. В нём данные уже разбиты на train и test выборки. Скачаем и распакуем его.
unzip shadow_ar_dataset.zipСтруктура папок в наборе данных следующая.
Каждая из выборок содержит 5 папок с изображениями:
- noshadow (изображения без теней);
- shadow (изображения с тенями);
- mask (маски вставленных объектов);
- robject (соседние объекты или окклюдеры);
- rshadow (тени от соседних объектов).
dataset
+-- train
¦ +-- noshadow -- example1.png, ...
¦ +-- shadow ---- example1.png, ...
¦ +-- mask ------ example1.png, ...
¦ +-- robject --- example1.png, ...
¦ L-- rshadow --- example1.png, ...
L-- test
+-- noshadow -- example2.png, ...
+-- shadow ---- example2.png, ...
+-- mask ------ example2.png, ...
+-- robject --- example2.png, ...
L-- rshadow --- example2.png, ...Вы можете не использовать готовый набор данных, а подготовить свой датасет с аналогичной файловой структурой.
Итак, подготовим класс ARDataset для обработки изображений и выдачи i-ой порции данных по запросу.
Импорт библиотек
import os
import os.path as osp
import cv2
import random
import numpy as np
import albumentations as albu
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable
from piq import ContentLoss
import segmentation_models_pytorch as smpДалее определим сам класс. Основная функция в классе — __getitem__() . Она возвращает i-ое изображение и соответствующую ему маску по запросу.
Класс ARDataset
class ARDataset(Dataset):
def __init__(self, dataset_path, augmentation=None, augmentation_images=None, preprocessing=None, is_train=True, ):
""" Инициализация параметров датасета
dataset_path - путь до папки train или test
augmentation - аугментации, применяемые как к изображениям, так и
к маскам
augmentation_images - аугментации, применяемые только к
изображениям
preprocessing - предобработка изображений
is_train - флаг [True - режим обучения / False - режим предсказания]
"""
noshadow_path = os.path.join(dataset_path, 'noshadow')
mask_path = os.path.join(dataset_path, 'mask')
# соберём пути до файлов
self.noshadow_paths = []; self.mask_paths = [];
self.rshadow_paths = []; self.robject_paths = [];
self.shadow_paths = [];
if is_train:
rshadow_path = osp.join(dataset_path, 'rshadow')
robject_path = osp.join(dataset_path, 'robject')
shadow_path = osp.join(dataset_path, 'shadow')
files_names_list = sorted(os.listdir(noshadow_path))
for file_name in files_names_list:
self.noshadow_paths.append(osp.join(noshadow_path, file_name))
self.mask_paths.append(osp.join(mask_path, file_name))
if is_train:
self.rshadow_paths.append(osp.join(rshadow_path, file_name))
self.robject_paths.append(osp.join(robject_path, file_name))
self.shadow_paths.append(osp.join(shadow_path, file_name))
self.augmentation = augmentation
self.augmentation_images = augmentation_images
self.preprocessing = preprocessing
self.is_train = is_train
def __getitem__(self, i):
""" Получение i-го набора из датасета.
i - индекс
Возвращает:
image - изображение с нормализацией для attention блока
mask - маска с нормализацией для attention блока
image1 - изображение с нормализацией для shadow generation блока
mask1 - маска с нормализацией для shadow generaion блока
"""
# исходное изображение
image = cv2.imread(self.noshadow_paths[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# маска вставленного объекта
mask = cv2.imread(self.mask_paths[i], 0)
if self.is_train:
# маска соседних объектов
robject_mask = cv2.imread(self.robject_paths[i], 0)
# маска теней от соседних объектов
rshadow_mask = cv2.imread(self.rshadow_paths[i], 0)
# результирующее изображение
res_image = cv2.imread(self.shadow_paths[i])
res_image = cv2.cvtColor(res_image, cv2.COLOR_BGR2RGB)
# применяем аугментации отдельно к изображениям
if self.augmentation_images:
sample = self.augmentation_images(
image=image,
image1=res_image
)
image = sample['image']
res_image = sample['image1']
# соберём маски в одну переменную для применения аугментаций
mask = np.stack([robject_mask, rshadow_mask, mask], axis=-1)
mask = mask.astype('float')
# аналогично с изображениями
image = np.concatenate([image, res_image], axis=2)
image = image.astype('float')
# применяем аугментации
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# нормализация масок
mask[mask >= 128] = 255; mask[mask < 128] = 0
# нормализация для shadow generation блока
image1, mask1 = image.astype(np.float) / 127.5 - 1.0, mask.astype(np.float) / 127.5 - 1.0
# нормализация для attention блока
image, mask = image.astype(np.float) / 255.0, mask.astype(np.float) / 255.0
# применяем препроцессинг
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
sample = self.preprocessing(image=image1, mask=mask1)
image1, mask1 = sample['image'], sample['mask']
return image, mask, image1, mask1
def __len__(self):
""" Возвращает длину датасета"""
return len(self.noshadow_paths)Объявим аугментации и функции для обработки данных. Аугментации будем брать из репозитория albumentations.
Аугментации и предобработка
def get_training_augmentation():
""" Аугментации для всех изображений, тренировочная выборка. """
train_transform = [
albu.Resize(256,256),
albu.HorizontalFlip(p=0.5),
albu.Rotate(p=0.3, limit=(-10, 10), interpolation=3, border_mode=2),
]
return albu.Compose(train_transform)
def get_validation_augmentation():
""" Аугментации для всех изображений, валидационная / тестовая выборка """
test_transform = [
albu.Resize(256,256),
]
return albu.Compose(test_transform)
def get_image_augmentation():
""" Аугментации только для изображений (не для масок). """
image_transform = [
albu.OneOf([
albu.Blur(p=0.2, blur_limit=(3, 5)),
albu.GaussNoise(p=0.2, var_limit=(10.0, 50.0)),
albu.ISONoise(p=0.2, intensity=(0.1, 0.5), color_shift=(0.01, 0.05)),
albu.ImageCompression(p=0.2, quality_lower=90, quality_upper=100, compression_type=0),
albu.MultiplicativeNoise(p=0.2, multiplier=(0.9, 1.1), per_channel=True, elementwise=True),
], p=1),
albu.OneOf([
albu.HueSaturationValue(p=0.2, hue_shift_limit=(-10, 10), sat_shift_limit=(-10, 10), val_shift_limit=(-10, 10)),
albu.RandomBrightness(p=0.3, limit=(-0.1, 0.1)),
albu.RandomGamma(p=0.3, gamma_limit=(80, 100), eps=1e-07),
albu.ToGray(p=0.1),
albu.ToSepia(p=0.1),
], p=1)
]
return albu.Compose(image_transform, additional_targets={
'image1': 'image',
'image2': 'image'
})
def get_preprocessing():
""" Препроцессинг """
_transform = [
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
def to_tensor(x, **kwargs):
""" Приводит изображение в формат: [channels, width, height] """
return x.transpose(2, 0, 1).astype('float32')Обучение
Объявим датасеты и даталоадеры для загрузки данных и определим устройство, на котором сеть будет обучаться.
Датасеты, даталоадеры, девайс
# число изображений, прогоняемых через нейросеть за один раз
batch_size = 8
dataset_path = '/path/to/your/dataset'
train_path = osp.join(dataset_path, 'train')
test_path = osp.join(dataset_path, 'test')
# объявим датасеты
train_dataset = ARDataset(train_path, augmentation=get_training_augmentation(), preprocessing=get_preprocessing(),)
valid_dataset = ARDataset(test_path, augmentation=get_validation_augmentation(), preprocessing=get_preprocessing(),)
# объявим даталоадеры
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)Определим устройство, на котором будем учить сеть:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')Будем учить attention и shadow generation блоки по отдельности.
Обучение attention блока
В качестве модели attention блока возьмём U-Net. Архитектуру импортируем из репозитория segmentation_models.pytorch. Для повышения качества работы сети заменим стандартную кодирующую часть U-Net на сеть-классификатор resnet34.
Поскольку на вход attention блок принимает изображение без тени и маску вставленного объекта, то заменим первый сверточный слой в модели: на вход модулю поступает 4-канальный тензор (3 цветных канала + 1 черно-белый).
# объявим модель Unet с 2 классами на выходе - 2 маски (соседние объекты и их тени)
model = smp.Unet(encoder_name='resnet34', classes=2, activation='sigmoid',)
# заменим в модели первый сверточный слой - на входе должно быть 4 канала
model.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)Объявим функцию потерь, метрику и оптимизатор.
loss = smp.utils.losses.DiceLoss()
metric = smp.utils.metrics.IoU(threshold=0.5)
optimizer = torch.optim.Adam([dict(params=model.parameters(), lr=1e-4),])Создадим функцию для обучения attention блока. Обучение стандартное, состоит из трех циклов: цикла по эпохам, тренировочного цикла по батчам и валидационного цикла по батчам.
На каждой итерации по даталоадеру выполняется прямой прогон данных через модель и получение предсказаний. Далее вычисляются функции потерь и метрики, после чего выполняется обратный проход алгоритма обучения (обратное распространение ошибки), происходит обновление весов.
Функция для обучения attention и её вызов
def train(n_epoch, train_loader, valid_loader, model_path, model, loss, metric, optimizer, device):
""" Функция обучения сети.
n_epoch -- число эпох
train_loader -- даталоадер для тренировочной выборки
valid_loader -- даталоадер для валидационной выборки
model_path -- путь для сохранения модели
model -- предварительно объявленная модель
loss -- функция потерь
metric -- метрика
optimizer -- оптимизатор
device -- определенный torch.device
"""
model.to(device)
max_score = 0
total_train_steps = len(train_loader)
total_valid_steps = len(valid_loader)
# запускаем цикл обучения
print('Start training!')
for epoch in range(n_epoch):
# переведём модель в режим тренировки
model.train()
train_loss = 0.0
train_metric = 0.0
# тренировочный цикл по батчам
for data in train_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# прогоним через модель
model_input = torch.cat((noshadow_image, mask), axis=1)
model_output = model(model_input)
# сравним выход модели с ground truth данными
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
train_metric += metric(ground_truth, model_output).item()
optimizer.zero_grad()
loss_result.backward()
optimizer.step()
train_loss += loss_result.item()
# переведём модель в eval-режим
model.eval()
valid_loss = 0.0
valid_metric = 0.0
# валидационный цикл по батчам
for data in valid_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# прогоним через модель
model_input = torch.cat((noshadow_image, mask), axis=1)
with torch.no_grad():
model_output = model(model_input)
# сравним выход модели с ground truth данными
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
valid_metric += metric(ground_truth, model_output).item()
valid_loss += loss_result.item()
train_loss = train_loss / total_train_steps
train_metric = train_metric / total_train_steps
valid_loss = valid_loss / total_valid_steps
valid_metric = valid_metric / total_valid_steps
print(f'\nEpoch {epoch}, train_loss: {train_loss}, train_metric: {train_metric}, valid_loss: {valid_loss}, valid_metric: {valid_metric}')
# если получили новый максимум по точности - сохраняем модель
if max_score < valid_metric:
max_score = valid_metric
torch.save(model.state_dict(), model_path)
print('Model saved!')
# вызовем функцию:
# число эпох
n_epoch = 10
# путь для сохранения модели
model_path = '/path/for/model/saving'
train(n_epoch=n_epoch,
train_loader=train_loader,
valid_loader=valid_loader,
model_path=model_path,
model=model,
loss=loss,
metric=metric,
optimizer=optimizer,
device=device)После того, как обучение attention блока закончено, приступим к основной части сети.
Обучение shadow generation блока
В качестве модели shadow generation блока аналогично возьмём U-Net, только в качестве кодировщика возьмем сеть полегче — resnet18.
Поскольку на вход shadow generation блок принимает изображение без тени и 3 маски (маску вставленного объекта, маску соседних объектов и маску теней от них), заменим первый сверточный слой в модели: на вход модулю поступает 6-канальный тензор (3 цветных канала + 3 черно-белых).
После U-Net добавим в конце 4 refinement-блока. Один такой блок состоит из последовательности: BatchNorm2d, ReLU и Conv2d.
Объявим класс генератор.
Класс генератор
class Generator_with_Refin(nn.Module):
def __init__(self, encoder):
""" Инициализация генератора."""
super(Generator_with_Refin, self).__init__()
self.generator = smp.Unet(
encoder_name=encoder,
classes=1,
activation='identity',
)
self.generator.encoder.conv1 = nn.Conv2d(6, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
self.generator.segmentation_head = nn.Identity()
self.SG_head = nn.Conv2d(in_channels=16, out_channels=3, kernel_size=3, stride=1, padding=1)
self.refinement = torch.nn.Sequential()
for i in range(4):
self.refinement.add_module(f'refinement{3*i+1}', nn.BatchNorm2d(16))
self.refinement.add_module(f'refinement{3*i+2}', nn.ReLU())
refinement3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1)
self.refinement.add_module(f'refinement{3*i+3}', refinement3)
self.output1 = nn.Conv2d(in_channels=16, out_channels=3, kernel_size=3, stride=1, padding=1)
def forward(self, x):
""" Прямой проход данных через сеть."""
x = self.generator(x)
out1 = self.SG_head(x)
x = self.refinement(x)
x = self.output1(x)
return out1, xОбъявим класс дискриминатор.
Класс дискриминатор
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)Объявим объекты моделей генератора и дискриминатора, а также функции потерь и оптимизатор для генератора и дискриминатора.
Генератор, дискриминатор, функции потерь, оптимизаторы
generator = Generator_with_Refin('resnet18')
discriminator = Discriminator(input_shape=(3,256,256))
l2loss = nn.MSELoss()
perloss = ContentLoss(feature_extractor="vgg16", layers=("relu3_3", ))
GANloss = nn.MSELoss()
optimizer_G = torch.optim.Adam([dict(params=generator.parameters(), lr=1e-4),])
optimizer_D = torch.optim.Adam([dict(params=discriminator.parameters(), lr=1e-6),])Всё готово для обучения, определим функцию для обучения SG блока. Её вызов будет аналогичен вызову функции обучения attention.
Функция для обучения SG блока
def train(generator, discriminator, device, n_epoch, optimizer_G, optimizer_D, train_loader, valid_loader, scheduler, losses, models_paths, bettas, writer):
"""Функция для обучения SG-блока
generator: модель-генератор
discriminator: модель-дискриминатор
device: torch-device для обучения
n_epoch: количество эпох
optimizer_G: оптимизатор для модели-генератора
optimizer_D: оптимизатор для модели-дискриминатора
train_loader: даталоадер для тренировочной выборки
valid_loader: даталоадер для валидационной выборки
scheduler: шедуллер для изменения скорости обучения
losses: список функций потерь
models_paths: список путей для сохранения моделей
bettas: список коэффициентов для функций потерь
writer: tensorboard writer
"""
# перенесем модели на ГПУ
generator.to(device)
discriminator.to(device)
# для валидационного минимума
val_common_min = np.inf
print('Запускаем обучение!')
for epoch in range(n_epoch):
# переводим модели в режим обучения
generator.train()
discriminator.train()
# списки для значений функций потерь
train_l2_loss = []; train_per_loss = []; train_common_loss = [];
train_D_loss = []; valid_l2_loss = []; valid_per_loss = [];
valid_common_loss = [];
print('Цикл по батчам (пакетам):')
for batch_i, data in enumerate(tqdm(train_loader)):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# подготовим входной тензор для модели
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
# ------------ учим генератор -------------------------------------
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# Adversarial ground truths
valid = Variable(torch.cuda.FloatTensor(np.ones((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(torch.cuda.FloatTensor(np.zeros((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
# вычисляем функции потерь
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor2)
gan_loss = losses[2](discriminator(result_nn_tensor2), valid)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss + bettas[2] * gan_loss
optimizer_G.zero_grad()
common_loss.backward()
optimizer_G.step()
# ------------ учим дискриминатор ---------------------------------
optimizer_D.zero_grad()
loss_real = losses[2](discriminator(shadow_image), valid)
loss_fake = losses[2](discriminator(result_nn_tensor2.detach()), fake)
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# ------------------------------------------------------------------
train_l2_loss.append((bettas[0] * l2_loss).item())
train_per_loss.append((bettas[1] * per_loss).item())
train_D_loss.append((bettas[2] * loss_D).item())
train_common_loss.append(common_loss.item())
# переводим generator в eval-режим
generator.eval()
# валидация
for batch_i, data in enumerate(valid_loader):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# подготовим вход в для модели
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
with torch.no_grad():
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_result_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# вычисляем функции потерь
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor2)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss
valid_per_loss.append((bettas[1] * per_loss).item())
valid_l2_loss.append((bettas[0] * l2_loss).item())
valid_common_loss.append(common_loss.item())
# усредняем значения функций потерь
tr_l2_loss = np.mean(train_l2_loss)
val_l2_loss = np.mean(valid_l2_loss)
tr_per_loss = np.mean(train_per_loss)
val_per_loss = np.mean(valid_per_loss)
tr_common_loss = np.mean(train_common_loss)
val_common_loss = np.mean(valid_common_loss)
tr_D_loss = np.mean(train_D_loss)
# добавляем результаты в tensorboard
writer.add_scalar('tr_l2_loss', tr_l2_loss, epoch)
writer.add_scalar('val_l2_loss', val_l2_loss, epoch)
writer.add_scalar('tr_per_loss', tr_per_loss, epoch)
writer.add_scalar('val_per_loss', val_per_loss, epoch)
writer.add_scalar('tr_common_loss', tr_common_loss, epoch)
writer.add_scalar('val_common_loss', val_common_loss, epoch)
writer.add_scalar('tr_D_loss', tr_D_loss, epoch)
# печатаем информацию
print(f'\nEpoch {epoch}, tr_common loss: {tr_common_loss:.4f}, val_common loss: {val_common_loss:.4f}, D_loss {tr_D_loss:.4f}')
if val_common_loss <= val_common_min:
# сохраняем лучшую модель
torch.save(generator.state_dict(), models_paths[0])
torch.save(discriminator.state_dict(), models_paths[1])
val_common_min = val_common_loss
print(f'Model saved!')
# делаем шаг шедуллера
scheduler.step(val_common_loss)Процесс обучения

Графики, общая информация
Для обучения я использовал видеокарту GTX 1080Ti на сервере hostkey. В процессе я отслеживал изменение функций потерь по построенным графикам с помощью утилиты tensorboard. Ниже, на рисунках, представлены графики обучения на тренировочной и валидационной выборке.

Особенно полезен второй рисунок, поскольку валидационная выборка не участвует в процессе обучения генератора и является независимой. По графикам обучения видно, что выход на плато произошел в районе 200-250-й эпохи. Здесь можно было уже тормозить обучение генератора, поскольку монотонность у функции потерь отсутствует.
Однако полезно также смотреть на графики обучения в логарифмической шкале — она более наглядно показывает монотонность графика. По графику логарифма валидационной функции потерь видим, что обучение в районе 200-250-й эпохи останавливать рановато, можно было сделать это позже, на 400-й эпохе.

Для наглядности эксперимента периодически происходило сохранение предсказанной картинки (см. гифку визуализации процесса обучения выше).
Некоторые трудности
В процессе обучения пришлось решить достаточно простую проблему — неправильное взвешивание функций потерь.
Поскольку наша окончательная функция потерь состоит из взвешенной суммы других лосс-функций, вклад каждой из них в общую сумму нужно регулировать по отдельности путём задания коэффициентов для них. Оптимальный вариант — взять коэффициенты, предложенные в оригинальной статье.
При неправильной балансировке лосс-функций мы можем получить неудовлетворительные результаты, например, если для L2 задать слишком сильный вклад, то обучение нейронной сети может и вовсе застопориться. L2 достаточно быстро сходится, но при этом совсем убирать её из общей суммы тоже нежелательно — выходная тень будет получаться менее реалистичной, менее консистентной по цвету и прозрачности.
На картинке слева — ground truth изображение, справа — сгенерированное изображение.
Инференс
Для предсказания и тестирования объединим модели attention и SG в один класс ARShadowGAN.
Класс ARShadowGAN, объединяющий attention и shadow generation блоки
class ARShadowGAN(nn.Module):
def __init__(self, model_path_attention, model_path_SG, encoder_att='resnet34', encoder_SG='resnet18', device='cuda:0'):
super(ARShadowGAN, self).__init__()
self.device = torch.device(device)
self.model_att = smp.Unet(
classes=2,
encoder_name=encoder_att,
activation='sigmoid'
)
self.model_att.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7,7), stride=(2,2), padding=(3,3), bias=False)
self.model_att.load_state_dict(torch.load(model_path_attention))
self.model_att.to(device)
self.model_SG = Generator_with_Refin(encoder_SG)
self.model_SG.load_state_dict(torch.load(model_path_SG))
self.model_SG.to(device)
def forward(self, tensor_att, tensor_SG):
self.model_att.eval()
with torch.no_grad():
robject_rshadow_tensor = self.model_att(tensor_att)
robject_rshadow_np = robject_rshadow_tensor.cpu().numpy()
robject_rshadow_np[robject_rshadow_np >= 0.5] = 1
robject_rshadow_np[robject_rshadow_np < 0.5] = 0
robject_rshadow_np = 2 * (robject_rshadow_np - 0.5)
robject_rshadow_tensor = torch.cuda.FloatTensor(robject_rshadow_np)
tensor_SG = torch.cat((tensor_SG, robject_rshadow_tensor), axis=1)
self.model_SG.eval()
with torch.no_grad():
output_mask1, output_mask2 = self.model_SG(tensor_SG)
result = torch.add(tensor_SG[:,:3, ...], output_mask2)
return result, output_mask2Далее приведём сам код инференса.
Инференс
# укажем пути до данных и чекпоинтов
dataset_path = '/content/arshadowgan/uploaded'
result_path = '/content/arshadowgan/uploaded/shadow'
path_att = '/content/drive/MyDrive/ARShadowGAN-like/attention.pth'
path_SG = '/content/drive/MyDrive/ARShadowGAN-like/SG_generator.pth'
# объявим датасет и даталоадер
dataset = ARDataset(dataset_path, augmentation=get_validation_augmentation(256), preprocessing=get_preprocessing(), is_train=False)
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
# определим устройство
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# объявим полную модель
model = ARShadowGAN(
encoder_att='resnet34',
encoder_SG='resnet18',
model_path_attention=path_att,
model_path_SG=path_SG,
device=device
)
# переведем ее в режим тестирования
model.eval()
# предсказание
for i, data in enumerate(dataloader):
tensor_att = torch.cat((data[0][:, :3], torch.unsqueeze(data[1][:, -1], axis=1)), axis=1).to(device)
tensor_SG = torch.cat((data[2][:, :3], torch.unsqueeze(data[3][:, -1], axis=1)), axis=1).to(device)
with torch.no_grad():
result, shadow_mask = model(tensor_att, tensor_SG)
shadow_mask = np.uint8(127.5*shadow_mask[0].cpu().numpy().transpose((1,2,0)) + 1.0)
output_image = np.uint8(127.5 * (result.cpu().numpy()[0].transpose(1,2,0) + 1.0))
cv2.imwrite(osp.join(result_path, 'test.png'), output_image)
print('Результат сохранен: ' + result_path + '/test.png')
Заключение
В данной статье рассмотрена генеративно-состязательная сеть на примере решения одной из амбициозных и непростых задач на стыке Augmented Reality и Computer Vision. В целом полученная модель умеет генерировать тени, пусть и не всегда идеально.
Отмечу, что GAN — это не единственный способ генерации тени, существуют и другие подходы, в которых, например, используются техники 3D-реконструкции объекта, дифференцированный рендеринг и т.п.
Весь приведенный код — в репозитории, примеры запуска — в Google Colab ноутбуке.

P.S. Буду рад открытой дискуссии, каким-либо замечаниям и предложениям.
Спасибо за внимание!



DjPhoeniX
Результат впечатляет, но возник вопрос — если сеть работает в AR-контексте (то-есть 3D-рендер есть "по умолчанию") — почему бы не ограничить сеть выводом "light estimation" и настраивать параметры рендера так, чтобы тень отрисовывал движок? Этим методом "за компанию" решается сомнительная реалистичность в размытии тени.
artyomnaz Автор
Согласен, с реалистичностью возникают сложности. В том числе из-за отсутствия хороших метрик для оценки качества изображений (кроме FID).