
Airflow — идеальный выбор для конвейеров данных, то есть для оркестрации и планирования ETL. Он широко применяется и популярен для создания конвейеров передачи данных будущего. Он обеспечивает обратное заполнение, управление версиями и происхождение с помощью функциональной абстракции.
Функциональное программирование — это будущее.
Оператор определяет единицу в рабочем процессе, DAG — это набор Задач. Операторы обычно работают независимо, на самом деле они могут работать на совершенно двух разных машинах. Если вы инженер данных и работали с Apache Spark или Apache Drill, вы, вероятно, знаете, что такое DAG! Такая же концепция и у Airflow.
Создавайте конвейеры данных, которые:
Идемпотентны.
Детерминированы.
Не имеют побочных эффектов.
Используют неизменные источники и направления.
Не обновляются, не добавляются.
Модульность и масштабируемость — основная цель функциональных конвейеров данных.
Если вы работали с функциональным программированием с помощью Haskell, Scala, Erlang или Kotlin, вы удивитесь, что это то, что мы делаем в функциональном программировании, и вышеперечисленные пункты относятся к функциональному программированию, да! Вы правы. Функциональное программирование — это мощный инструмент будущего.
Если у вас есть ETL / Data Lake / Streaming Infrastructure как часть платформы разработки данных, у вас должен быть кластер Hadoop / Spark с некоторым дистрибутивом, таким как Hortonworks, MapR, Cloudera и т. д. Поэтому я собираюсь рассказать о том, как вы можете использовать ту же инфраструктуру, где у вас есть Apache Hadoop / Apache Spark Cluster, и вы используете его для создания Airflow Cluster и его масштабирования.
Если у вас много заданий ETL и вы хотите организовать и составить расписание с помощью некоторых инструментов планирования, у вас есть несколько вариантов, например Oozie, Luigi и Airflow. Oozie основан на XML, и мы взяли его 2019 году! :), Luigi чуть не выбросили после того, как Airflow родился на Airbnb.
Почему не используем Luigi с Airflow?
У Airflow есть собственный планировщик, в котором Luigi требует синхронизировать задачи в задании cron.
С Luigi навигация по пользовательскому интерфейсу становится сложной задачей.
В Luigi сложно создавать задачи.
Luigi не масштабируется из-за тесной связи с заданиями Cron.
Повторный запуск процесса в Luigi невозможен.
Luigi не поддерживает распределенное выполнение, так как оно плохо масштабируется.
До появления Airflow я использовал Luigi для поддержки рабочего процесса моделей машинного обучения с помощью Scikit-learn, Numpy, Pandas, Theano и т. д.
В последнем сообщении блога мы обсудили, как настроить мультинодовый кластер Airflow с Celery и RabbitMQ без использования Ambari.
Ага, переходим к главному.
Как настроить мультинодовый кластер Airflow в Hadoop Spark Cluster, чтобы Airflow мог запускать задания Spark/Hive/Hadoop Map Reduce, а также выполнять координацию и планирование.
Давайте сделаем это!
Вы должны использовать airflow-ambari-mpack (пакет управления Apache Airflow для Apache Ambari), я использовал реализацию с открытым исходным кодом от FOSS Contributor https://github.com/miho120/ambari-airflow-mpack, Спасибо за ваш вклад.
Следующие шаги:
Из предыдущего сообщения в блоге вы должны выполнить шаги с 1 по 4, чтобы установить RabbitMQ и другие пакеты.
Как настроить мультинодовый кластер Airflow с помощью Celery и RabbitMQ
- Устанавливаем Apache MPack для Airflow
a. git clone https://github.com/miho120/ambari-mpack.git
b. stop ambari server
c. install the apache mpack for airflow on ambari server
d. start ambari server- Добавляем Airflow Service в Ambari
После успешного выполнения вышеуказанных шагов вы можете открыть интерфейс Ambari
http://<HOST_NAME>:8080Откройте пользовательский интерфейс Ambari (Ambari UI), нажмите Действия -> Добавить службу. (Actions -> Add Service)

HDP Ambari Dashboard
Если шаг 1 выполнен успешно, вы сможете увидеть Airflow как часть службы Ambari.

Сервис Airflow в Ambari
Вы должны выбрать, на каком узле вы хотите установить веб-сервер, планировщик и воркер. Я бы порекомендовал установить Airflow на веб-сервер, планировщик на master ноде, то есть на узле имени, и на Install Worker на data-нодах.
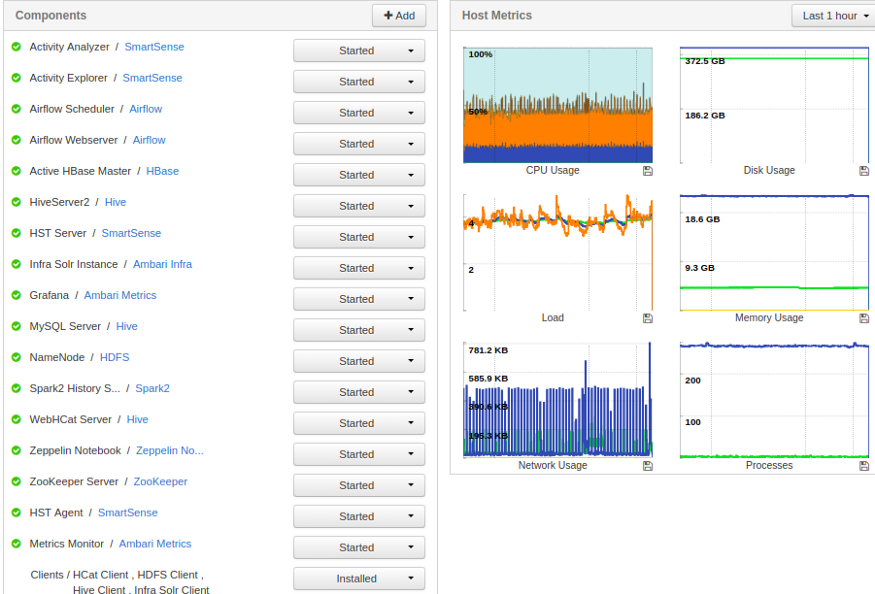
Ambari Master нода / Name нода для Airflow
Как вы можете видеть на изображении выше, веб-сервер Airflow и планировщик Airflow установлены на Name ноде кластера Hadoop / Spark.
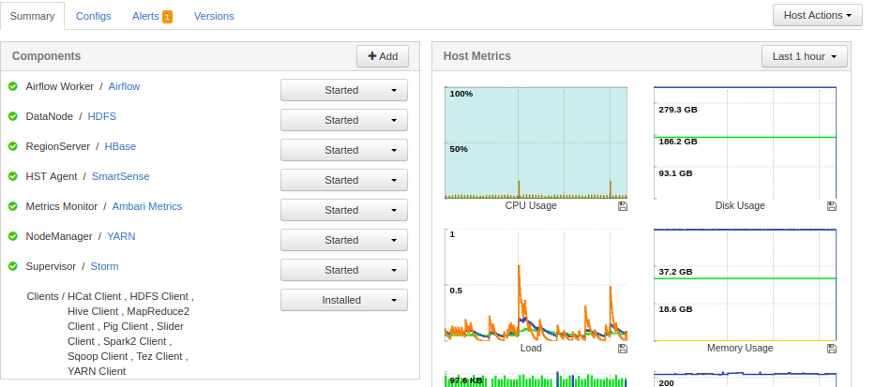
Как вы можете видеть на скриншоте выше, служба Airflow Worker установлена на Data ноде кластера.
В итоге, у меня есть 3 воркер (worker) ноды на трех data нодах.
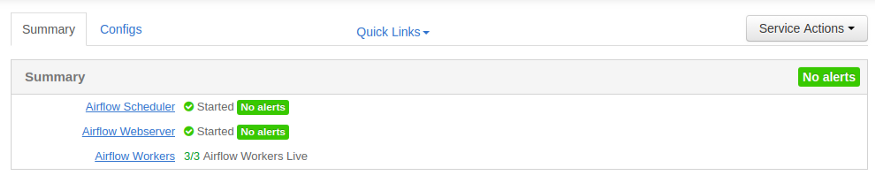
Сервис Airflow в Ambari

Ambari UI: 3 воркера в Airflow
Вы можете добавлять рабочие нода столько, сколько хотите, вы можете добавлять / удалять воркеров, когда захотите. Эта стратегия может масштабироваться по горизонтали + вертикали.
Конфигурация Airflow в Ambari:
Нажмите на Airflow Service, а затем на Config в пользовательском интерфейсе Ambari.

Конфигурация Airflow в Ambari
- Смените Executor
executor = CeleryExecutor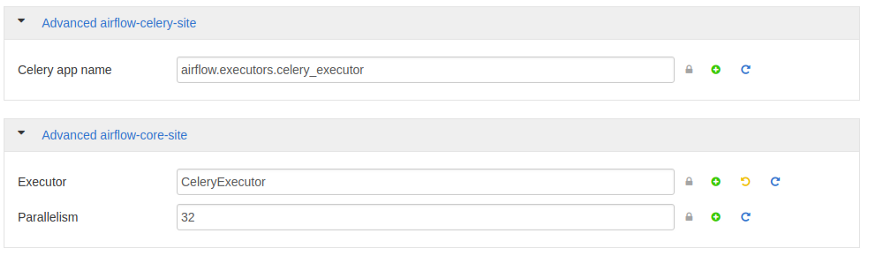
В разделе Advanced airflow-core-site укажите Executor как CeleryExecutor.
- SQL Alchemy Connection
sql_alchemy_conn = postgresql+psycopg2://airflow:airflow@{HOSTNAME}/airflow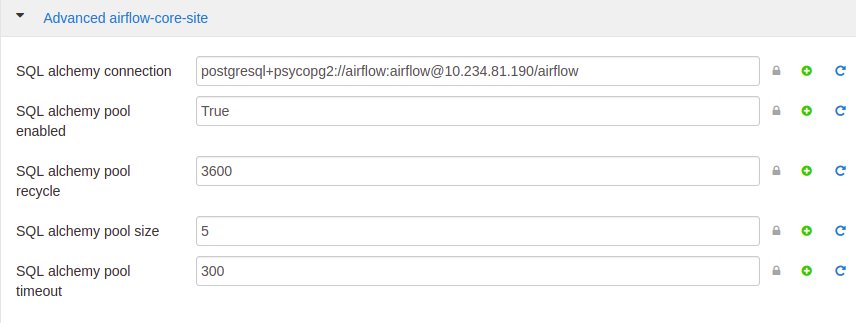
SQL Alchemy Connection
Измените соединение SQL Alchemy на соединение postgresql, пример приведен выше.
- URL-адрес брокера
broker_url= pyamqp://guest:guest@{RabbitMQ-HOSTNAME}:5672/
celery_result_backend = db+postgresql://airflow:airflow@{HOSTNAME}/airflow
URL-адрес брокера и Celery result backend для Airflow
- Прочие
dags_are_paused_at_creation = True
load_examples = False
Конфигурация Airflow-core-site.
После того, как все эти изменения будут внесены в конфигурацию Ambari Airflow, Ambari попросит вас перезапустить все затронутые службы, перезапустите службы и нажмите Service Actions -> InitDB.
Airflow Initdb из Ambari
А затем запустите службу airflow. Теперь у вас должен получиться мультинодовый кластер Airflow.
Кое-что из Чек-листа для проверки служб для мультинодового кластера Airflow:
- Очереди RabbitMQ должны быть запущены:
- Подключения RabbitMQ должны быть активными:

- Каналы RabbitMQ должны быть запущены:

- Отображение Celery Flower
Celery Flower — это веб-инструмент для мониторинга и управления кластерами Celery. Номер порта по умолчанию — 5555.

Вы также можете видеть здесь, что 3 рабочих находятся в сети, и вы можете отслеживать одну единицу «задачи» Celery здесь.
Обратите внимание, что вы также можете запустить «Celery Flower», веб-интерфейс, созданный поверх Celery, для наблюдения за своими рабочими. Вы можете использовать команду быстрого доступа airflow flower, чтобы запустить веб-сервер Flower.
nohup airflow flower >> /var/local/airflow/logs/flower.logs &Мы закончили установку и настройку мультинодовый кластер Airflow на Ambari HDP Hadoop / Spark Cluster.
Я столкнулся с некоторыми проблемами, о которых я расскажу ниже.
Проблемы и трудности при настройке Multi-Node Airflow Cluster
Последней статьей, которую я написал об Apache Airflow, была «Установка и настройка Multi-Node Airflow Cluster с HDP Ambari и Celery для конвейеров данных». Вопрос был в том, прошло ли все гладко или возникли проблемы. Да, были некоторые проблемы.
В этой статье я расскажу о тех проблемах, с которыми я столкнулся в своем путешествии по настройке Multi-Node Airflow Cluster.
Проблема 1. После изменения LocalExecutor на CeleryExecutor группа доступности базы данных находилась в режиме выполнения, но на самом деле ни одна из задач не запускалась.
Worker не смог связаться с Scheduler с помощью Celery.
Ошибка:
AttributeError: ‘DisabledBackend’ object has no attribute ‘_get_task_meta_for’
Apr 10 21:03:52 charlie-prod airflow_control.sh: [2019–04–10 21:03:51,962] {celery_executor.py:112} ERROR — Error syncing the celery executor, ignoring it:
Apr 10 21:03:52 charlie-prod airflow_control.sh: [2019–04–10 21:03:51,962] {celery_executor.py:113} ERROR — ‘DisabledBackend’ object has no attribute ‘_get_task_meta_for’Я начал изучать код Airflow в той же строке, где возникла ошибка, но не понимал, что происходит. Но причина была ясна. Celery не могла публиковать сообщения или подписываться на них и не имела возможности участвовать в канале связи.
Решение:
Установленная версия Celery была 3.3.5 (которая слишком старая и несовместима с Airflow 1.10 (текущая установленная версия).
pip install --upgrade celery
3.3.5 => 4.3Проблема 2: после запуска DAG на CeleryExecutor DAG завершился с какой-то странной ошибкой, по крайней мере, для меня.
Apr 11 14:13:13 charlie-prod airflow_control.sh: return load(BytesIO(s))
Apr 11 14:13:13 charlie-prod airflow_control.sh: TypeError: Required argument ‘object’ (pos 1) not found
Apr 11 14:13:13 charlie-prod airflow_control.sh: [2019–04–11 14:13:13,847: ERROR/ForkPoolWorker-6285] Pool process <celery.concurrency.asynpool.Worker object at 0x7f3a88b7b250> error: TypeError(“Required argument ‘object’ (pos 1) not found”,)
Apr 11 14:13:13 charlie-prod airflow_control.sh: Traceback (most recent call last):
Apr 11 14:13:13 charlie-prod airflow_control.sh: File “/usr/lib64/python2.7/site-packages/billiard/pool.py”, line 289, in __call__
Apr 11 14:13:13 charlie-prod airflow_control.sh: sys.exit(self.workloop(pid=pid))
Apr 11 14:13:13 charlie-prod airflow_control.sh: File “/usr/lib64/python2.7/site-packages/billiard/pool.py”, line 347, in workloop
Apr 11 14:13:13 charlie-prod airflow_control.sh: req = wait_for_job()
Apr 11 14:13:13 charlie-prod airflow_control.sh: File “/usr/lib64/python2.7/site-packages/billiard/pool.py”, line 447, in receive
Apr 11 14:13:13 charlie-prod airflow_control.sh: ready, req = _receive(1.0)
Apr 11 14:13:13 charlie-prod airflow_control.sh: File “/usr/lib64/python2.7/site-packages/billiard/pool.py”, line 419, in _recv
Apr 11 14:13:13 charlie-prod airflow_control.sh: return True, loads(get_payload())
Apr 11 14:13:13 charlie-prod airflow_control.sh: File “/usr/lib64/python2.7/site-packages/billiard/common.py”, line 101, in pickle_loads
Apr 11 14:13:13 charlie-prod airflow_control.sh: return load(BytesIO(s))
Apr 11 14:13:13 charlie-prod airflow_control.sh: TypeError: Required argument ‘object’ (pos 1) not foundРешение:
Я не смог ничего понять об этой ошибке.
Я изучил блог о airflow на китайском языке: https://blog.csdn.net/u013492463/article/details/80881260
Я ничего не понял, но, по крайней мере, получил небольшое представление о том, что может быть причиной этой ошибки.
Более ранняя настройка:
broker_url= amqp://guest:guest@{RabbitMQ-HOSTNAME}:5672/Я понимаю, что pyamqp был бы лучшим выбором, так как многие люди использовали его, и более ранняя статья в некоторой степени давала такое же разрешение.
amqp:// — это псевдоним, который использует librabbitmq, если он доступен, или py-amqp, если его нет.
Вы должны использовать pyamqp:// или librabbitmq://, если хотите точно указать, какой протокол передачи данных использовать. Протокол передачи данных pyamqp: // использует библиотеку amqp (http://github.com/celery/py-amqp)
Позднее произвел установку с разрешением:
broker_url= pyamqp://guest:guest@{RabbitMQ-HOSTNAME}:5672/изменение amqp на pyamqp устранило указанную выше ошибку.
Установка:
pip install pyamqpПроблема 3: сбой подключения SQL Alchemy
Более ранняя конфигурация:
SQL alchemy connection
sql_alchemy_conn = postgresql://airflow:airflow@{HOST_NAME}:5432/airflowРешение:
Более поздняя конфигурация:
sql_alchemy_conn = postgresql+psycopg2://airflow:airflow@{HOSTNAME}/airflowДля psycopg2 вам необходимо установить pip wheel.
Установите адаптер PostGreSQL: psycopg2
Psycopg — это адаптер PostgreSQL для языка программирования Python.
Проблема 4: HDP версия 2.6.2 с Ambari, установка Worker Installation при сбое нескольких хостов.
После успешной установки веб-сервера и планировщика на главном узле, то есть на узле имени, целью было установить Celery worker на всех узлах данных, чтобы группы DAG могли работать параллельно и масштабироваться по горизонтали и вертикали.
Но Амбари дал дурацкие выражения :) с ошибкой ниже.
by ‘SSLError(SSLError(“bad handshake: SysCallError(104, ‘ECONNRESET’)”,),)’: /simple/apache-airflow/
Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by ‘SSLError(SSLError(“bad handshake: SysCallError(104, ‘ECONNRESET’)”,),)’: /simple/apache-airflow/
Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by ‘SSLError(SSLError(“bad handshake: SysCallError(104, ‘ECONNRESET’)”,),)’: /simple/apache-airflow/
Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by ‘SSLError(SSLError(“bad handshake: SysCallError(104, ‘ECONNRESET’)”,),)’: /simple/apache-airflow/
Could not fetch URL https://pypi.org/simple/apache-airflow/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host=’pypi.org’, port=443): Max retries exceeded with url: /simple/apache-airflow/ (Caused by SSLError(SSLError(“bad handshake: SysCallError(104, ‘ECONNRESET’)”,),)) — skippingРешение:
Это означает, что pip не может загрузить и установить wheel на машину, когда я пытался установить worker на узле с помощью пользовательского интерфейса Ambari. Однако с помощью команд терминала я смог запустить те же команды для установки wheel’s of pip.
Обычное решение для этой ошибки было запущено с аргументом доверенного пользователя или с изменением репозитория, из которого pypi загружает wheel.
pip install --trusted-host pypi.python.org --trusted-host pypi.org --trusted-host files.pythonhosted.org --upgrade --ignore-installed apache-airflow[celery]==1.10.0' returned 1. Collecting apache-airflow[celery]==1.10.0Пробовал сделать, что указал выше, но снова не удалось. Появился стек других ошибок, но с аналогичным значением.
resource_management.core.exceptions.ExecutionFailed: Execution of ‘export SLUGIFY_USES_TEXT_UNIDECODE=yes && pip install — trusted-host pypi.python.org — trusted-host pypi.org — trusted-host files.pythonhosted.org — upgrade — ignore-installed apache-airflow[celery]==1.10.0’ returned 1. Collecting apache-airflow[celery]==1.10.0
Retrying (Retry(total=4, connect=None, read=None, redirect=None)) after connection broken by ‘ProtocolError(‘Connection aborted.’, error(104, ‘Connection reset by peer’))’: /simple/apache-airflow/
Retrying (Retry(total=3, connect=None, read=None, redirect=None)) after connection broken by ‘ProtocolError(‘Connection aborted.’, error(104, ‘Connection reset by peer’))’: /simple/apache-airflow/
Retrying (Retry(total=2, connect=None, read=None, redirect=None)) after connection broken by ‘ProtocolError(‘Connection aborted.’, error(104, ‘Connection reset by peer’))’: /simple/apache-airflow/
Retrying (Retry(total=1, connect=None, read=None, redirect=None)) after connection broken by ‘ProtocolError(‘Connection aborted.’, error(104, ‘Connection reset by peer’))’: /simple/apache-airflow/
Retrying (Retry(total=0, connect=None, read=None, redirect=None)) after connection broken by ‘ProtocolError(‘Connection aborted.’, error(104, ‘Connection reset by peer’))’: /simple/apache-airflow/
Could not find a version that satisfies the requirement apache-airflow[celery]==1.10.0 (from versions: )
No matching distribution found for apache-airflow[celery]==1.10.0
You are using pip version 8.1.2, however version 19.0.3 is available.
You should consider upgrading via the ‘pip install — upgrade pip’ command.Я обновил pip, но безуспешно.
Наконец я понял, Hack не может быть разрешением, которое сработало, — это команды, которые я установил в celery и все необходимые wheel pip, которые перечислены здесь.
Но все же он выдал ту же ошибку. Но когда эти колеса были установлены, это не игнорировалось. Согласно коду https://github.com/miho120/ambari-airflow-mpack/blob/e1c9ca004adaa3320e35ab7baa7fdb9b9695b635/airflow-service-mpack/common-services/AIRFLOW/1.10.0/package/scripts/airflow_worker_control.py
В кластере я вручную закомментировал эти строки временно (позже отменил изменения после успешной установки воркера) и добавил воркера из Ambari, который работал как шарм :), и этот хак сделал мой день.
После установки worker на другом узле вам может потребоваться перезапуск службы airflowиз Ambari. Вы можете узнать больше из моей предыдущей статьи в блоге; Настройка Multi-Node Airflow Cluster с HDP Ambari и Celery для конвейеров данных

loltrol
Так вроде бы Ambari мертво и доживает свой саппорт, после слияния с hortonworks и cloudera?
chemtech Автор
А где-нибудь про это прочитать можно?