
Писать игровой AI очень интересно и увлекательно - не раз убеждался в этом на личном опыте. Недавно, случайно наткнувшись на код своего старого проекта шахматной программы, решил его немного доработать и выложить на GitHub. А заодно рассказать о том, как он создавался и какие уроки преподал мне в процессе работы.
Начало
Это случилось в 2009 году: я решил написать простую шахматную программу, чтобы попрактиковаться в разработке игрового AI. Сам я не шахматист и даже не сказать что любитель шахмат. Но задача для тренировки вполне подходящая и интересная. Кроме того, играя в шахматы на доске или в программе, мне всегда было любопытно, почему тот или иной ход сильнее другого. Хотелось возможности наглядно видеть всё дерево развития шахматной позиций. Такой фичи в других программах я не встречал - так почему бы не написать самому? Ну а раз уж это тренировка - то придумывать и писать нужно с нуля, а не изучать другие алгоритмы и писать их собственную реализацию. В общем, думаю, дня за три можно управиться и сделать какой-то рабочий вариант.
Первая версия
Обычно шахматные движки используют поиск в глубину с алгоритмом "ветвей и границ" для сужения поиска. Но это не очень-то наглядно, поэтому решено: мы пойдём своим путём - пусть это будет поиск в ширину на фиксированную глубину. Тогда в памяти будет полное дерево поиска, которое можно как-то визуализировать. А также выяснить: а) на какую глубину можно просчитать шахматную игру в рамках имеющихся ресурсов CPU и памяти, б) насколько хорошо или плохо будет играть такой алгоритм?
Надо сказать, что на тот момент у меня был 2-ядерный процессор с 2 или 4 Гб памяти (точно уже не помню), 32-битная винда и 32-битный компилятор Turbo Delphi Explorer. Так что если временем работы ещё можно было как-то пожертвовать, то доступная процессу память была ограничена 2Gb. Про PE flag, расширяющий user memory до 3Gb я тогда не знал. Впрочем, поскольку память кушают и система, и Delphi и другие программы - для шахмат, чтобы не уходить в своп, доступно менее гигабайта.
В результате получилась первая версия игры, состоящая из таких модулей:
UI - основное окно, отрисовка доски с фигурами.
Игровая логика - составление списка возможных ходов, выполнение хода, детекция завершения игры.
AI:оценка - оценочная функция позиции.
AI:перебор - поиск в ширину через очередь.
UI:браузер - окно визуализации дерева поиска, в котором можно наглядно изучать как всё работает.
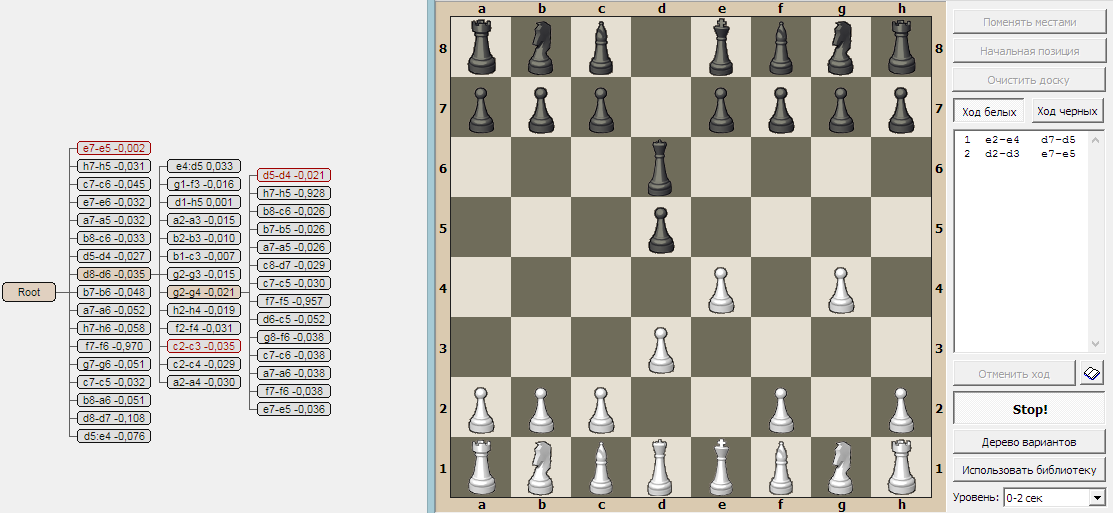
Выяснилось что:
Поиск на глубину 3 полухода работает быстро - меньше секунды, и расходует немного памяти - 5-15 Мб. А вот поиск на глубину 4 полухода работает уже довольно долго и расходует большую часть доступной памяти. В отдельных ситуациях памяти и вовсе не хватает.
При глубине поиска в 3 полухода уровень сложности - "младшая школа": компьютер вроде как-то играет, не позволяет "зевнуть" фигуру, не упускает возможность поставить "вилку". Но в то же время допускает грубые ошибки и легко попадается в ловушки. В общем, очень слабый соперник.
При любой глубине поиска, компьютер совершенно не умеет играть в эндшпиле и не понимает что делать, если у противника остался один король.
Таким образом, вырисовались направления дальнейшей работы: углубить поиск, научить позиционной игре а также научить играть в эндшпиле. И многие проблемы можно решить за счёт оценочной функции.
Оценочная функция
Функция оценки позиции - важнейший компонент любого шахматного движка. Где-то она предельно простая и быстрая - учитывает лишь количество фигур и их стоимость, а где-то - сложная и учитывает множество факторов. Поскольку в моём случае количество оцениваемых позиций ограничено объемом памяти, имеет смысл использовать сложную оценочную функцию и заложить в неё как можно больше факторов.
В итоге пришел к примерно такому алгоритму:
Для каждого игрока:
Подсчитать стоимость фигур: конь - 3, ладья - 5 и т.д. Начальная стоимость пешки - 1, но она растёт по мере её продвижения.
Бонус за сделанную рокировку, штраф за потерю возможности рокировки, штраф в миттельшпиле за невыведенные фигуры (коней и ладьи в углах). Штраф за сдвоенные пешки и бонус за захваченные открытые линии.
Определение какие поля находятся под боем и кем. Это медленная операция - основная часть времени выполнения оценочной функции тратится именно здесь. Зато польза от неё колоссальная! Незащищённая фигура под боем на ходу противника - минус фигура. Защищённая - минус разность стоимости фигур. Это позволяет получить эффект углубления поиска на 1-2 уровня.
Если остался один король: штраф за расстояние от центра доски и штраф за расстояние до короля противника. Такая формула в эндшпиле заставляет AI стремиться прижать короля противника к краю доски, т.е. получить позицию, из которой можно найти возможность поставить мат.
Итоговая оценка = (white_rate - black_rate) * (1 + 10 / (white_rate + black_rate)). Эта формула делает разницу более значимой в эндшпиле, заставляя отстающего игрока избегать размена фигур, а ведущего - наоборот, стремиться к размену.
Углубление поиска
Прежде всего, несмотря на доработку оценочной функции, углубление поиска необходимо для ходов со взятием а также шахов. Для этого добавлен новый атрибут узла - вес, который используется вместо глубины. Если дочерний узел порождается обычным ходом - его вес уменьшается на 1, если ходом со взятием - на 0.4, если ходом с шахом - не уменьшается вовсе. Узлы с положительным весом возвращаются в очередь поиска и получают продолжение.
Кроме того, нужно развивать наиболее перспективные направления - ветки с наибольшей оценкой.
В итоге алгоритм получился такой:
На первой стадии строится дерево с базовой глубиной 3 (при этом ветки со взятиями и шахами могут достигать заметно большей глубины).
Оценка дерева алгоритмом минимакс.
Если выполнены критерии принятия решения - выбирается ветка с наилучшей оценкой и алгоритм завершается.
Обрезка дерева: последовательно удаляются ветки с наихудшей оценкой пока не будет свободно достаточно памяти для продолжения поиска.
Переход к следующей стадии: добавляем вес всем листьям дерева и продолжаем поиск. После завершения переходим к п 2.
Критерии принятия решения:
Осталась единственная ветка - выбора нет.
Одна из веток имеет оценку существенно более высокую чем у остальных - выбираем её.
Истекло время на ход - выбираем ветку с наилучшей оценкой.
Кэширование
В процессе работы больше всего времени тратится на оценочную функцию. Но бывает, что в ходе поиска одни и те же позиции встречаются несколько раз: в одно и то же состояние можно прийти различными путями. Возникает мысль: почему бы не кэшировать результат оценочной функции?
Всё просто: нужно вычислить хэш от позиции и если в кэше уже есть оценка с таким хэшем - использовать её вместо вычисления. А если нет - вычислить и сохранить в кэше оценок. Основная проблема - нужна достаточно качественная и быстрая хэш-функция. После множества экспериментов получилось написать приемлемую функцию, вычисляющую 64-битный хэш. Общее количество возможных шахматных позиций значительно больше 264, но количество позиций, оцениваемых в ходе партии значительно меньше 232, поэтому более-менее качественная хэш-функция должна свести вероятность хэш-коллизий к минимуму.
Процент "попаданий" в кэш в ходе игры получился в районе 30-45%, но в эндшпиле достигает 80-90%, что даёт ускорение почти в 5-10 раз, а следовательно позволяет увеличить глубину поиска. Неплохой выигрыш!
Что получилось?
Я добавил библиотеку дебютов, и в таком состоянии программа играла уже довольно неплохо - примерно на уровне 2-го разряда, а может и чуть сильнее. Результат, в принципе, достойный - можно остановиться. Хотя были вполне очевидны недостатки и направления развития:
AI работает в один поток - ресурс CPU задействован не полностью.
А что если предоставить больше памяти?
AI думает только во время своего хода. Почему бы не использовать время соперника для просчёта наиболее вероятных продолжений?
Главная слабость: детерминированность. Каждый ход рассматривается как отдельная задача, каждая позиция приводит к детерминированному решению. Достаточно выиграть один раз, чтобы запомнить последовательность ходов, которая всегда приведёт к победе. А играть с таким соперником неинтересно.
Однако, к этому времени код проекта уже достаточно "замусорился" и требовал рефакторинга. Поскольку на него и так уже было потрачено много времени, я решил его забросить.
Дальнейшее развитие
Недавно наткнувшись на этот заброшенный проект, решил всё-таки привести его код в порядок и доработать. Доработки сделал такие:
Многопоточность: сейчас у меня уже 8-поточный, а не 2-поточный CPU, поэтому многопоточный вариант даёт серьёзную прибавку в скорости.
64-битный режим: кроме возможности использовать больше памяти, было любопытно, будет ли алгоритм работать быстрее на архитектуре x64. Как ни странно, оказалось что нет! Хотя отдельные функции на x64 работают быстрее, в целом версия x86 оказалась на 5-10% быстрее. Возможно 64-битный компилятор Delphi не очень хорош, не знаю.
Больше памяти: даже в 32-битном режиме за счёт PE-флага расширения адресного пространства доступной памяти стало больше. Однако практика показала, что больше 1 Гб памяти все-равно не нужно - разве что для хранения "обрезанных" ветвей дерева. К усилению игры увеличение памяти не приводит.
Непрерывность поиска: теперь дерево поиска не создаётся с нуля каждый ход, а создаётся лишь в начале партии. Когда делается ход - неактуальные ветви дерева обрезаются а поиск продолжается с того состояния, которое было. В том числе и во время хода соперника - идёт проработка перспективных продолжений, поэтому когда соперник сделает ход, поиск продолжится не с нуля. Быть может и вовсе получится сразу же сделать ход. Момент времени, когда игрок сделает ход - это фактор случайности, который делает игру недетерминированной. Теперь уже нельзя запомнить выигрышную последовательность ходов.
Оценка дерева. Ввёл новый атрибут узла - качество оценки. Качество равно сумме качества всех прямых потомков, умноженное на коэффициент затухания. Т.е. качество оценки показывает проработанность ветки.
Углубление поиска. Качество оценки вместе с самой оценкой учитывается при выборе веток для углубления поиска. Чем выше оценка и чем ниже её качество - тем выше приоритет такой ветки для её развития. Потому что мало смысла до посинения развивать и так хорошо проработанную ветку с максимальной оценкой, которая уже вряд ли существенно изменится, когда она сравнивается со слабо проработанными ветками, чья оценка может значительно измениться.
База оценок и самообучение. В процессе игры какие-то позиции детально прорабатываются и получают оценку с высоким качеством. Почему бы не сохранять такие оценки для использования в других партиях? Это ещё одна фича, которая делает игру недетерминированной.
В результате этих доработок AI стал сильнее, и вполне уверенно обыгрывает старую версию игры. Я провел несколько партий против AI на chess.com и выяснил, что уровень моей программы примерно соответствует рейтингу 1800-1900. Прогресс есть, и это хорошо!
Программирование игрового AI - занятие чертовски затягивающее: всегда хочется добиться большего. И хотя у меня по прежнему есть масса идей для дальнейшего развития, наступает момент, когда надо остановиться. Думаю, он наступил. Однако если кто-либо желает - может взять мой код, побаловаться, поэкспериментировать, что-нибудь реализовать. Благо, сейчас Delphi доступен каждому благодаря бесплатной Community Edition, не говоря уже про бесплатный Free Pascal и Lazarus. Код проекта (а также скомпилированный exe-шник) можно взять тут (для компиляции понадобится также кое что из https://github.com/Cooler2/ApusGameEngine). Спасибо всем, кто дочитал.
VaalKIA
Я сам писал шахматную программу, поэтому не удержался от пары комментариев:
1. Про поиск в ширину автор пишет полную чушь, дерево, в принципе не надо хранить, если у вас список ходов из позиции детерминирован, то важен только текущий путь и оценки, для механизма отсечения.
2. Автор искажает факты, только начиная с ключевого пункта "(при этом ветки со взятиями и шахами могут достигать заметно большей глубины)" из раздела «Углубление поиска» его программа, действительно смогла играть, до этого она могла просчитвать мат в пределах видимости, но ни о какой игре речь не шла.
Поясню дополнительно: если рассматривать любую позицию, то почти всегда возможно взятие вашей фигуры, если не ваш ход или вы можете взять достаточно весомую фигуру противника, а расплата, которая наступет дальше, находится за горизонтом события, поэтому программа, просчитывающая на определённую глубину не может В ПРИНЦИПЕ адекватно оценивать никакую позицию, все оценки — коту под хвост, она постоянно будет приписывать либо вычитать сильную фигуру, чего не будет случаться в реальности.
Статья выглядит довольно ладной, но, сдаётся мне, что автор нифига не писал (особенно, учитывая отсылки к дерменизму: вы можете просчитать на нужную глубину, только имея безлимит по времени, имея же временной лимит, вы просто обязаны реализовать просчёт во время обдумывания хода соперником и ни о каком детерминизме речь уже не идёт), просто посмотрел движки, пособирал инфу и выложил нам компиляцию того, что надо сделать.
P.S. Ну и тот, кто действительно писал движёк, знает чем отличается минимакс, от альфа-бета, про который в статье даже не упоминается. Исходники не смотрел, вроде бы в ТурбоВижн 19xx лохматого года идёт движёк шахмат, для общего развития.
Шахматный движок в 328 байт: в целом, ценность шахматного кода преувеличина
Спасибо за статью о Дельфи/Lazarus.
Cooler2 Автор
А как его визуализировать, если не хранить?
А код на гитхабе, видимо, сам-собой возник? :-)
VaalKIA
Вы же не отображаете всё дерево, а только путь, даже если оно интерактивно, показать прощёлкнутую ветку — никаких проблем нет, это несколько деятков позиций.
Не собираюсь вникать в то, откуда взялся код и насколько он оригинален.
Cooler2 Автор
Ну надо где-то брать оценки для отображаемой ветки. Пускай позиций отображается немного, но их оценка формируется из большого количества листьев. Может быть с альфа-бетой посчитать их "на лету" было бы достаточно быстро, не знаю. Я выбрал простой вариант.
VaalKIA
С оценками — возможно, но в реальности, важен просчитыаемый путь и оценка, в динамике. Вот как это выглядело в классике (Super Chess 3.5, ZX Spectrum 1984г):

Cooler2 Автор
Осмелюсь предположить, что код с поиском в ширину — достаточно уникален. Кто ж станет такое писать. Зато он позволяет прочувствовать как именно играет AI с полным перебором на фиксированную глубину. Если бы его не написал — это осталось бы загадкой :)
Кстати, первый коммит в репозитории — как-раз старая версия, которая играет детерминированно и думает только на своём ходу. В этом нетрудно убедиться.
VaalKIA
Все, в частности — я. Поиск в ширину, это первое понимание того, как вообще может работать выбор в дереве лучшего значения (когда они «лучшие» существуют все одновременно и уровнем ниже происходит естественный выбор), далее приходит понимание того, что всё дерево не нужно
Cooler2 Автор
Хм, тогда непонятно в чём суть претензии, что я начал с поиска в ширину, если все с этого начинают :-)
VaalKIA
Суть претензии в логических и временных несостыковках, вашего повествования, а не в фактах по отдельности. А так же неразборчивость в существенных и несущественных деталях. Ну это типа, как, сейчас мы нарисуем сову.
P.S.
— Скажите, а правда, что Кац выиграл в лотерею миллион?
— Правда. Но не Кац, а Рабинович. Не в лотерею, а в карты. Не миллион, а сто рублей. И не выиграл, а проиграл.
Cooler2 Автор
В Turbo Vision не видел, но видел OWL Chess — довольно хорошая программа на Borland Pascal под Win 3.1 Исходники доступны. Но задача изначально стояла написать с нуля, а не изучать другие движки. Изучение чужих движков практически не даёт опыта решения задач, возникающих в процессе работы над AI других игр.
dkdkdk
Создание игровой программы — это чертовски интересный процесс.
Мы с отцом пилили программу по русским шашкам «Магистр» примерно с 1992 ?по 2003 год.
И кстати, что интересно, последняя самая сильная версия была тоже на Delphi (генератор ходов правда был на встроенном в Delphi ASMе).
К 2003 году у нас уже была практически полная 7-я фигурная база окончаний (за исключением всякой экзотики типа 6 против 1).
Потом мне уже стало как-то неинтересно и я забил, а отец до сих пор пытается полностью решить такую разновидность шашек как «поддавки».
В шашках дерево перебора намного меньше из-за того что количество ходов из каждой позиции намного меньше чем в шахматах. Однако существуют и свои сложности, например взятие дамкой часто требует долгого рекурсивного перебора. А также само появление дамок на доске сильно увеличивает количество возможных ходов, поэтому в отличие от шахматных программ переход в эндшпиль нисколько не уменьшает дерево, а только увеличивает его.
Также оказалось, что многие шахматные «эвристики» невозможно применить в шашках из-за того что накладные расходы на работу эвристик оказываются больше чем полученный результат (именно потому что количество ходов из каждой позиции меньше). Также оказалось что для шашек можно придумать свои собственные эвристики которые в принципе невозможны в шахматах.
Вспоминаю те годы с большой теплотой, наверное это был мой самый интересный проект в программировании за 30 лет.
ne555
Это серъезная проблема (общая проблема велосипедостроения, не «в боевых условиях» или без опыта на теор.данных).
pdima
Текущие подходы уже и не используют такие тактические приемы, alphazero/muzero и подобные подходы похоже работают лучше.
ne555
Пиар.
pdima
Пиар для Гугла конечно, они же не в бизнесе шахматных движков, но модель которая [само]обучалась только очень небольшое время без баз и десятилетиями отточенных тактических приемов и даже не заточенная на шахматы, как минимум сравнима с другими SOTA программами.
Cooler2 Автор
Захват центра — через небольшой бонус за количество полей под боем, за 7 горизонталь тоже.
Но тут есть проблема: вся эта куча параметров — как их определить: на глаз, по ощущениям?
Это работает пока AI играет на таком уровне, что очевидно где решение правильное, а где — ошибка. А дальше уже нужны другие методы типа генетической оптимизации. В шахматах это нелегко, из-за того, что партии длятся долго и провести миллион партий для оптимизации параметров — дело затратное.
da-nie
Я вот думаю свой движок попробовать на GPU распараллелить. Только надо придумать как. Наверное, стоит каждый переход на уровень вниз запустить как поток на GPU. Но тогда большая часть из них нифига не отсечётся — ведь отсечение происходит на запускающем уровне выше по результатам возврата из веток ниже. Надо подумать.
А как вы подключили туда движок? У вас UCI поддерживается?
Я свой на Arena запускал для тестирования.
HemulGM
GPU сильно уступает в математических вычислениях. Эффективно будет только, если создать на GPU сотни и сотни потоков
da-nie
А я и собираюсь создать на пару миллионов потоков. :) Вопрос только в том, чем их загрузить.
Возможно, будет иметь смысл на первых нескольких полуходах собрать базу ходов и все их отправить уже дальше считаться на GPU. Потом посмотреть, что вернёт GPU и выбрать лучший ход из этих миллионов.
HemulGM
Возможно, стоит хранить большую часть данных в памяти GPU. Тогда, думаю, легче будет распараллелить
da-nie
А там хранить-то особо нечего. :) Всё ж рекурсивное.
mustitz
Хэш позиций, отсортированные ходы для них. Вообще получаем батч позиций, где нужно сгенерировать ходы. Генерим. Получаем батч позиций для оценки. Оцениваем. Загрузить в общем-то не проблема, у тебя уже на 3–4 полуходе будут достаточные батчи.
da-nie
Там всего сотня мегабайт уйдёт на это всё.
mustitz
На что уйдёт? Если исходить из скорости генерации миллион позицию в секунду (а это примерно одно ядро CPU) и 100 байт на позицию, то сотня мегабайт в секунду и будет уходить. А на GPU мы хотим ещё получить boost, значит будет быстрее.
Тут проблема в общем хеше позиций. Не видно, как эффективно использовать приватную память, а с глобальной скорость будет падать…
da-nie
На кэш уйдёт.
Ничего подобного. 64 бита зобрист-ключ и 4 байта оценка позиции для данного ключа. Всё.
Не будет. ;) Кэш общий.
mustitz
А сортированный список ходов? Это очень важно с точки зрения перфоманса. А оценка позиции нам в общем-то и не сильно нужна.
da-nie
Этот список ходов для текущей позиции на доске. Он весьма мал.
HemulGM
Я к тому, что для миллиона потоков в GPU нужно снизить кол-во обращений в ОЗУ, иначе профита не будет
da-nie
В ОЗУ процессора или видеокарты? Первое, насколько я помню CUDA (а помню так себе), вообще невозможно — поток GPU не умеет работать с ОЗУ процессора.
HemulGM
В ОЗУ кончено не видеокарты. Суть в чем, алгоритм твой будет хранить всё в ОЗУ и ты собираешься отдавать GPU работу, но во время работы нужно обращаться к тому, что хранишь.
Я предлагаю тебе использовать по полной ОЗУ видеокарты в программе. И тогда потоки в GPU будут эффективнее, т.к. ты сможешь себя не ограничивать там и отдавать потокам более значимую работу.
В противном случае, ты будешь отдавать мелкую работу миллионам потоков, т.к. им просто напросто не с чем работать, т.к. да, из CUDA нельзя получить доступ к «внешней» ОЗУ.
da-nie
Нет. Каждый поток на GPU будет независим от остальных и просчитывает всю свою ветку со всеми частями, как если бы игра началась с его позиции. Что касается кэша, то им вообще можно пожертвовать (при миллионе потоков — легко). В этом случае расход памяти вообще околонулевой, а коллизий нет вообще.
Проблема только в том, что этот миллион потоков отвечает всего нескольким дополнительным полуходам. Стоит ли овчинка выделки, вот вопрос.
mustitz
Это совсем грустно и неэффективно. И без кэша… Ты понимаешь, зачем нужен кэш? Альфа-бета перебор очень зависим от порядка просмотра ходов. Если у нас порядок ходов от самого плохого к лучшему, нам надо просмотреть все позиции на заданной глубине (экспоненциальный взрыв). Если у нас порядок ходов от лучшего к худшему, то большая часть вариантов отсекается, и у нас что-то вроде логарифма.
Поэтому движок обычно считает на глубину N, сохраняет как можно больше нод в хеше вместе с порядком ходов от лучшего к худшему. А потом считает на глубину N+1 при этом максимально использует результаты, полученные на глубине N (в первую очередь смотрим ход, которым был лучшим на глубине N).
Наверное, будет лучше смотреть в направлении методов MCTS, они лучше отвечают архитектуре GPU
da-nie
Прочти мою статью про шахматный движок и увидишь, как всё это на самом деле работает и почему всё не так, как ты полагаешь. И именно поэтому отключив кэш сильной просадки скорости не будет. Late Move Reduction сокращает варианты гораздо (ГОРАЗДО!) эффективнее любого кэша. А кэш это так, чуток быстродействия добавить.
mustitz
Возможно, но в любом случае Stockfish достаточно неплохо ест память, и есть рекомендация выделять 1G per thread. Что он хранит?
da-nie
Он там хранит кэш. Польза от кэша, разумеется, есть. Просто она не так велика, как кажется (там общее количество позиций таково, что попадание в кэш не так уж часто, но оно есть).
mustitz
Тут интересно APU заюзать, там вроде CPU и GPU разделяют память.
Cooler2 Автор
Никак — вводил ходы вручную.
da-nie
А у вас там ошибок в программе нет?
А то что-то странное творится:
Пешка пошла с h2 в h4. Потом слон с e6 на h3.
А потом я вижу отсутствие пешки на h4! Слон её съел? А каким волшебством?
Также непонятно, почему выбрав ход чёрных и запустив AI игра начинается с хода чёрных! Но я-то жду, что AI походит белыми. Как в таком случае играть чёрными?
Ну и ещё долго думает и отлично кушает память. :)
Ну и сообщение о сбое тоже наблюдал один раз. :)
Cooler2 Автор
Дык взятие на проходе.
AI играет той стороной, которая вверху. Если перевернуть доску — он будет играть белыми.
А ошибки, конечно, есть. Код после доработок сырой. И по-хорошему надо ещё разок отрефакторить и оттестировать. Но это выльется в ещё пару дней работы, результат которой лично для меня никакой ценности уже не составит.
da-nie
Слоном?! :O
Cooler2 Автор
О как, не знал! :(
tenzink
Чтобы подобные проблемы отлавливать можно реализовать для своего движка perft и сравнить с известными данными: www.chessprogramming.org/Perft_Results
mustitz
1. От программирования шахмат меня отталкивает то, что это паханное-перепаханное поле.
2. Всё-таки более классический путь написать UCI движок, и использовать логи. И тебе сразу же доступны много разных GUI + соперников-программ. Визизуализация дереве как идея мне не очень нравиться: выводи все линии, и если ты хочешь получить более делальный анализ, проанализируй ещё раз на меньшей глубине.
3. До многопоточности я бы всё-таки больше занялся генератором ходов и прочей оптимизацией. Хранение позиции в массиве не самая хорошая идея, ну хотя бы тогда использовать 0x88 для генерации ходов. А сейчас, особенно с ассемблерной инструкцией PEXT, наверное биторды впереди планеты всей. В один поток сколько позиций генериться в секунду?
4. Ну и вместо минимакса, который используется очень часто, я бы всё-таки посмотрел в сторону MCTS, всё-таки хоть что-то да новое…
Ну а так да, велосипед… Который другим бы, наверное, не рекомендовал изучать… Слишком уж много не очень удачных решений, которые надо будет переделывать для развития.
Cooler2 Автор
Согласен, я тоже не рекомендую его изучать — рекомендую писать своё. В программировании, как и в математике, самому решать задачи полезнее, чем изучать чужие решения.
За 0x88 отдельное спасибо :) У меня положение на поле как раз хранится в виде 0bYYYYXXXX.
Tesla2018
Есть довольно интересное видео на эту тему:
www.youtube.com/watch?v=U4ogK0MIzqk