
Рассмотрим, в качестве примера, формулу для вычисления среднего значения. На ней я постараюсь рассказать и показать какие подходы к реализации можно применять и чем они эффективны или не эффективны.

Это сумма всех значений за выбранный период, делённая на период. Иными словами -среднее значение за последние nзначений.
Классический подход
Как ни странно, большинство решений в сети выглядит, как последовательный перебор всех групп размером n (например 4) и вычисление среднего для каждой:
const data = [1, 2, 3, 4, 5, 6, 7, 8, 9];
function sma(data, period) {
const result = [];
for (let i = 0; i <= data.length - period; i++) {
const chunk = data.slice(i, i + period);
const sum = chunk.reduce((acc, num) => acc + num, 0);
result.push(sum / period);
}
return result;
}
console.log(sma(data, 4));
//=> [ '2.50', '3.50', '4.50', '5.50', '6.50', '7.50' ]
//=> ¦ ¦ ¦ ¦ ¦ L-(6+7+8+9)/4
//=> ¦ ¦ ¦ ¦ L-(5+6+7+8)/4
//=> ¦ ¦ ¦ L-(4+5+6+7)/4
//=> ¦ ¦ L-(3+4+5+6)/4
//=> ¦ L-(2+3+4+5)/4
//=> L-(1+2+3+4)/4
Безусловно, это решение работает, но оно очень плохое. Здесь происходит огромное количество повторных вычислений и лишних операций. Разберем весь код по порядку и посмотрим, строка за строкой, что происходит "под капотом".
const result = []Создание массива в JavaScript, выделяет определенную область памяти для хранения данных. Размер массива не определенный и он наполняется по мере работы цикла, в какой-то момент может наступить заполнение выделенной области памяти и модуль управления памятью будет вынужден выделить новоую, более широкую область, затем осуществить перенос в нее диапазона всех значений памяти из предыдущей области, в разных движках это может работать по разному, но в любом случае необходимо, как минимум, выделение новой области памяти. И вот, как выглядит график замера времени на операцию push, в зависимости от длинны массива.
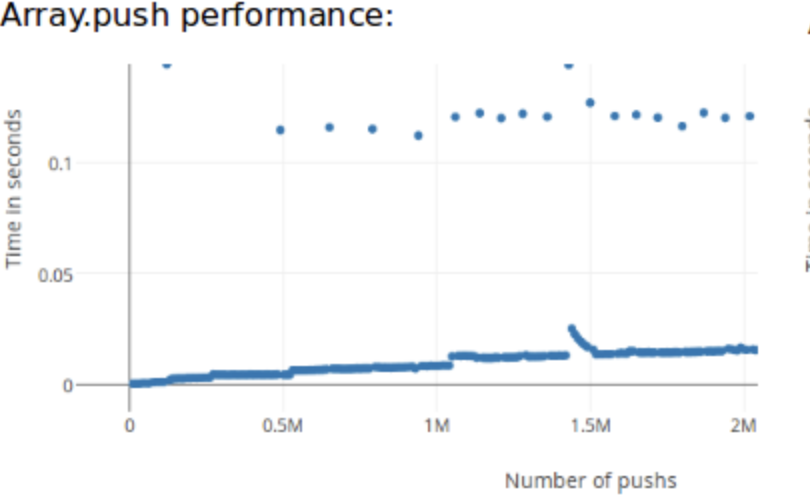
На картинке видны космические, по местным масштабам выбросы. Это происходит по причине тех самых накладных работ в памяти движка на перенос всей области, либо на выделение новой области и связывание со старой.
Из этого можно сделать два вывода:
Для работы с большими массивами лучше использовать создание массива через конструктор как:
new Array(size). Это позволит вам задать размер массива и движок выделит столько памяти, сколько нужно.А зачем тут этот массив вообще. (Позже мы к этому вернемся)
for (let i = 0; i <= data.length - period; i++)Для начала, ремарка про цикл. Я бы не стал так подробно мусолить цикл и перешел бы к следующей части, тк в целом оптимизация цикла не дала бы нужный эффект производительности, но это просто крик души, ода к безграмотности современных разработчиков, щепетильно пишущих бенчмарки налево и направо.
Погуглив "Самый быстрый способ итерации в JavaScript" не трудно наткнуться на кучу разных бенчмарков, которые написаны не правильно. Почему не правильно? .
В теории самый самый быстрый способ итерации в JavaScript -while(i > 0) , но все тесты в лучшем случае предлагают такой вариант условия остановки: while(i++) , в котором добавляется дополнительная нагрузка в виде приведения типа числа из Number в Boolean. Даже такой вариант выхода из цикла не совсем правильный: while(i < length) потому, что сравнение с 0 является одной из самых быстрых операций и отличается от сравнения с любыми другими видами чисел.
Бытует мнение, что это миф, однако это не так. Доказательство очень простое, взглянем как процессор обрабатывает сравнение с 0 и с 1
// Сравнение с 0
Frame size 8
30 S> 0xc24390c03a6 @ 0 : 0c 01 LdaSmi [1]
0xc24390c03a8 @ 2 : 26 fb Star r0
38 S> 0xc24390c03aa @ 4 : 0b LdaZero
44 E> 0xc24390c03ab @ 5 : 6a fb 00 TestGreaterThan r0, [0]
0xc24390c03ae @ 8 : 9a 02 JumpIfFalse [2] (0xc24390c03b0 @ 10)
0xc24390c03b0 @ 10 : 0d LdaUndefined
52 S> 0xc24390c03b1 @ 11 : aa Return // Сравнение с 1
Frame size 8
30 S> 0x1ae5f0003a6 @ 0 : 0c 01 LdaSmi [1]
0x1ae5f0003a8 @ 2 : 26 fb Star r0
38 S> 0x1ae5f0003aa @ 4 : 0c 64 LdaSmi [100]
44 E> 0x1ae5f0003ac @ 6 : 6a fb 00 TestGreaterThan r0, [0]
0x1ae5f0003af @ 9 : 9a 02 JumpIfFalse [2] (0x1ae5f0003b1 @ 11)
0x1ae5f0003b1 @ 11 : 0d LdaUndefined
54 S> 0x1ae5f0003b2 @ 12 : aa Return Обратите внимание на 5ую строку. Там используется сравнение LdaZero. Которое вежливо отмечено вторым в порядке быстродействия самими разработчиками v8.
Выводы:
Сравнение с нулем или нет - разница есть!
Не верьте бенчмаркам, если они написаны не правильно
Все эти вычисления можно сделать без цикла, об этом позже.
const chunk = data.slice(i, i + period);Теперь очередь этой строки. Оператор sliceсоздает новый массив, для которого выделяется память, заполняет его данными из предыдущего массива (иммутабильно) и присваивается в переменную chunk. Это с ума сойти сколько операций на пустом месте. И тут все можно описать столь же подробно, но я не стану, потому что больше нет сил разбираться в рубрике "По колено в коде" (Олды тут?). Выше, я все обещал позже рассказать о том, как сделать эти вычисления эффективнее. Приступим!
Потоковая обработка
В основе идеи потоковой обработки, лежит архитектура последовательных вычислений, с последующим переиспользованием (по возможности) результатов предыдущих вычислений. Такой подход хорош всегда и везде (где он применим), он применяется в парсинге текста, вычислениях, поисках в математических абстракциях и прочее.
Реализация вычислений SMA в этом подходе выглядит так:
export class SMA {
constructor(period) {
this.period = period;
this.arr = [];
this.sum = 0;
this.filled = false;
}
nextValue(value) {
this.filled = this.filled || this.arr.length === this.period;
this.arr.push(value);
if (this.filled) {
this.sum -= this.arr.shift();
this.sum += value;
return this.sum / this.period;
}
this.sum += value;
}
}
const data = [1, 2, 3, 4, 5, 6, 7, 8, 9];
const sma = new SMA(4);
for(let i = 0; i < data.length; i++) {
console.log(sma.nextValue(data[i]));
}Преимущества подхода в сравнении с классической реализацией:
Массив фиксированной длинны, который заполняется значениями и очищается при переполнении, поддерживая константную размерность. Тем самым позволяет не хранить в памяти лишнюю информацию.
Повторное использование вычислений, позволяет вообще отказаться от итераций по какому-либо массиву, мы просто записываем сумму всех входящих значений, и вычитаем сумму уходящих значений (при переполнении массива)
Но проблемные места все же есть:
Проблема 1 - это постоянное условие проверки переполненности массива, даже оптимизированное в this.filled, все еще вызвыается в холостую на каждую итерацию.
Проблема 2 -Мы все еще вынуждены хранить массив длинной 4 и постоянно выполнять операции shift и push , и если push нам не так страшен, то shift, вызывает последовательное смещение индексов, что дорого.
В остальном, даже в таком виде это решение будет работать быстрее в разы, чем классический подход.
Решаем проблему под номером один. Для этого при заполнении массива переопределим метод
this.nextValue = (value: number) => {
this.sum += value;
this.arr.push(value);
this.sum -= this.arr.shift();
return this.sum / this.period;
};Это позволит избежать в дальнейших расчетах дополнительных проверок на заполненность массива. Такой "лайфхак" имеет мелкое негативное воздействие на так называемые Shape структуры браузера, которые применяются для оптимизации доступа к свойствам объекта в реальном режиме времени. Прочитать про это можно здесь. Однако это воздействие будет разовым и на дальнейших вычисления не скажется. Такой подход дает в итоге даст значительное ускорение.
Мы сегодня с вами разобрали два подхода к вычислениям среднего значения, но это все легко переносится и на любые другие вычисления, поддающиеся потоковому анализу. Я постарался сделать статью интересной затронув глубинный уровень языка и работу с памятью.
SMA и многие другие аналитические функции (технические индикаторы) можно найти в моем репозитории.
Домашнее задание
В статье решается только одна из двух проблем потоковой реализации. Можно ли избавиться от проблемы номер два? Пишите ваши предложения в комментариях.




lair
Кольцевой буфер же.
BusinessDuck Автор
Вы правы, но не совсем. Текущая реализация это и есть кольцевой буффер. Вопрос в том, как сделать ее быстрее, а именно без использования shift операции. Либо же вообще отказаться от такого подхода и каким-то другим образом хранить числа для атомарных перерасчетов суммы.
lair
Нет. В кольцевом буфере не делается shift/push, а двигается указатель.
BusinessDuck Автор
Указатель в массиве на 0й элемент вы имеете в виду? Если нет, приведите пример реализации абстрактно или на JS
lair
Да.
BusinessDuck Автор
Это один из хороших вариантов решения проблемы. Спасибо. И как и любой "ускоряющий" механизм, дает нагрузку на память. (К сожалению не смог найти картинку где диаграммами показано что увеличение производительности чаще всего приводит к увеличению потребляемой памяти)
lair
В каком месте, если у вас всегда выделено одно и то же количество памяти, и вам ничего не надо (де)аллоцировать?
Он, наоборот, требует одной-двух "лишних" операций (сложение по модулю), но на фоне операций с выделением памяти это обычно мелочи по стоимости.
BusinessDuck Автор
На JS нельзя сдвинуть указатель на первый элемент массива напрямую, придется записывать в массив все поступающие значения и отдельно хранить индекс "начала" и сдвигать его при добавлении элемента. Получается в памяти будут вообще все данные.
А написание структуры, которая отличается от стандартного массива и реализует какую-то более продвинутую логику, сопряжено с использованием `new` оператора, что убьет производительность.
netricks
В классическом кольцевом буфере сдвигают не данные а индекс последнего элемента. При этом данные никуда не сшифтятся. Новый элемент кладётся на место изгнанного.
lair
Мне кажется, вы немного не понимаете, как работает кольцевой буфер. Рассмотрим пример размером 4, последние записанные элементы 18, 22, 64, 3. Мы где-то в середине работы, буфер давно и прочно заполнен (это чтобы не рассматривать edge case в начале).
Никаких выделений памяти.
BusinessDuck Автор
Все, понял, индекс цикличный просто. Супер :)
0xd34df00d
Модуль там не нужен, достаточно if и однократного вычитания длины буфера, для достаточно больших буферов это будет практически незаметно.
А для размеров, равных степени двойки, можно просто делать and с нужной битовой маской.
lair
Вполне возможно, что там есть место для оптимизации, я не большой специалист.