
http://loafter.github.io/godownloader/
https://github.com/Loafter/godownloader
Вступление
Давным-давно, в году этак 1998, для выхода в интернет я использовал модем на работе у отца. Он его включал вечером после работы и я мог наслаждаться просторами сети интернет на скорости аж 31.2 кбит/c. В то время не было истеричных блогеров, страницы не весили по мегабайту, а в новостных сайтах говорили только правду. Естественно основной интерес представляли ресурсы. Картинки, программы, всякие дополнения к играм, вроде машинок. Как сейчас помню качать через IE было сущим адом. Скачать файл весом больше 500 кб было просто невозможно, древний осел был намного упрямей.
В то время было очень много всяких менеджеров закачек вроде Getright, Go!zilla, Download Accelerator и, конечно, FlashGet. В то время 90% процентов из них были перегружено рекламным говном, лучшим был FlashGet. Он умел бить на части скачиваемый файл и работал шустро. Как сейчас помню версия 1.7 последняя была. Эту версию я в те времена и использовал.
Прошло 15 лет и мне понадобилось скачать большой объем данных через vpn из-за океана.
И что же изменилось за 15 лет?
Да ничего. По прежнему существуют все те же менеджеры с минимальными изменениями. Даже flashget оставил версию 1.7 вместе с новомодной 3.хх.
После того как wxfast download не сумел скачать 50 гигабайтный файл, я решил попробовать написать свой менеджер закачек, который включал бы в себя множество многопоточных заданий с возможностью контроля степени выполнения, остановки в любой момент, а также сохранения состояния загрузок между запусками приложения. Все это отличный вызов для языка GO.
Обертка
С чего начать? Первое что нам необходимо это уметь останавливать закачку и получать информацию о ходе скачивания в любой момент времени. В GO есть легковесные потоки, которые можно использовать у нас в программе. То есть как минимум один поток будет у нас для скачивания, другой для управления процессом (остановка, старт закачки, получение информации о ходе выполнения). Если с процессом получения сведений о загруженных данных проблем не возникает (мы можем получать их по ссылке сквозь потоки), то с процессом останоки закачки все немного сложнее, мы не можем остановить или убить другую goroutine. Но мы можем послать ей сигнал на выход из потока. Собственно так мы и сделаем. Реализуем простую обертку, которая бы позволила создавать произвольные дискретные работы с возможностью паузы и получения информации о состоянии работы.
Для того чтобы, обернуть какую-либо структуру необходимо чтобы она подерживала следующий интерфейс:
type DiscretWork interface {
DoWork() (bool, error)
GetProgress() interface{}
BeforeRun() error
AfterStop() error
}
Сама обертка:
func (mw *MonitoredWorker) wgoroute() {
log.Println("info: work start", mw.GetId())
mw.wgrun.Add(1)
defer func() {
log.Print("info: release work guid ", mw.GetId())
mw.wgrun.Done()
}()
for {
select {
case newState := <-mw.chsig:
if newState == Stopped {
mw.state = newState
log.Println("info: work stopped")
return
}
default:
{
isdone, err := mw.Itw.DoWork()
if err != nil {
log.Println("error: guid", mw.guid, " work failed", err)
mw.state = Failed
return
}
if isdone {
mw.state = Completed
log.Println("info: work done")
return
}
}
}
}
}
func (mw *MonitoredWorker) Start() error {
mw.lc.Lock()
defer mw.lc.Unlock()
if mw.state == Completed {
return errors.New("error: try run completed job")
}
if mw.state == Running {
return errors.New("error: try run runing job")
}
if err := mw.Itw.BeforeRun(); err != nil {
mw.state = Failed
return err
}
mw.chsig = make(chan int, 1)
mw.state = Running
go mw.wgoroute()
return nil
}
После запуска потока, wgoroute(), в цикле функция пошагово выполняет каждую итерацию вызовом метода DoWork(), В случае, если во время выполнения работы произошла ошибка, функция выходит из цикла и завершает поток. Также в цикле осуществляется выборка из канала.
select {
case newState := <-mw.chsig:
if newState == Stopped {
mw.state = newState
log.Println("info: work stopped")
return
}
Если поступило сообщение Stopped, алгоритм выходит из потока и устанавливает соотвествующее состояние.
Воспользуемся встроенными в язык средствами тестирования для проверки работы обертки:
package dtest
import (
"errors"
"fmt"
"godownloader/monitor"
"log"
"math/rand"
"testing"
"time"
)
type TestWorkPool struct {
From, id, To int32
}
func (tw TestWorkPool) GetProgress() interface{} {
return tw.From
}
func (tw *TestWorkPool) BeforeRun() error {
log.Println("info: exec before run")
return nil
}
func (tw *TestWorkPool) AfterStop() error {
log.Println("info: after stop")
return nil
}
func (tw *TestWorkPool) DoWork() (bool, error) {
time.Sleep(time.Millisecond * 300)
tw.From += 1
log.Print(tw.From)
if tw.From == tw.To {
fmt.Println("done")
return true, nil
}
if tw.From > tw.To {
return false, errors.New("tw.From > tw.To")
}
return false, nil
}
func TestWorkerPool(t *testing.T) {
wp := monitor.WorkerPool{}
for i := 0; i < 20; i++ {
mw := &monitor.MonitoredWorker{Itw: &TestWorkPool{From: 0, To: 20, id: rand.Int31()}}
wp.AppendWork(mw)
}
wp.StartAll()
time.Sleep(time.Second)
log.Println("------------------Work Started------------------")
log.Println(wp.GetAllProgress())
log.Println("------------------Get All Progress--------------")
time.Sleep(time.Second)
wp.StopAll()
log.Println("------------------Work Stop-------------------")
time.Sleep(time.Second)
wp.StartAll()
time.Sleep(time.Second * 5)
wp.StopAll()
wp.StartAll()
wp.StopAll()
}
Загрузка данных
После того как мы создали рабочую обертку для задач, мы можем приступить к основной функции — загрузки данных по http. Наверное основная проблема протокола http — это низкая скорость при загрузки данных в один поток. Именно поэтому, когда интернет был медленный, появилось столько менеджеров закачек, которые умели разбивать загружаемый файл на фрагменты и загружать их в несколько http-соединений, за счет этого достигался выигрыш в скорости. Естественно наш менеджер закачек не исключение, он также должен уметь забирать файл в несколько потоков. Для нормальной работы данной схемы необходимо чтобы сервер поддерживал докачку.
Со стороны клиента должен быть сформирован запрос у которого есть в заголовке поле Range. Весь запрос в сыром виде выглядит вот так:
GET /PinegrowLinux64.2.2.zip HTTP/1.1
Host: pinegrow.s3.amazonaws.com
User-Agent: Go-http-client/1.1
Range: bytes=34010904-42513630
Первая моя реализация работала крайне медленно. Все дело в том, что на каждую небольшую порцию данных готовился свой запрос, т.е. если необходимо было скачать сегмент от 1 до 2 мегабайтов блоками по 100 кб. это означало, что последовательно было выполнено 10 запросов для каждого блока. Я достаточно быстро понял, что что-то не так.
В программе wireshark я проверил как выполняется закачка другой программой — download master. Правильная схема работы была другая. Если нам нужно скачать 10 сегментов, то сначала готовилось 10 http-запросов на каждый сегмент, а деление на блоки было реализовано последовательным считыванием из блока body в рамках одного http-response.
func (pd *PartialDownloader) BeforeDownload() error {
//create new req
r, err := http.NewRequest("GET", pd.url, nil)
if err != nil {
return err
}
r.Header.Add("Range", "bytes="+strconv.FormatInt(pd.dp.Pos, 10)+"-"+strconv.FormatInt(pd.dp.To, 10))
f,_:=iotools.CreateSafeFile("test")
r.Write(f)
f.Close()
resp, err := pd.client.Do(r)
if err != nil {
log.Printf("error: error download part file%v \n", err)
return err
}
//check response
if resp.StatusCode != 206 {
log.Printf("error: file not found or moved status:", resp.StatusCode)
return errors.New("error: file not found or moved")
}
pd.req = *resp
return nil
}
….
func (pd *PartialDownloader) DownloadSergment() (bool, error) {
//write flush data to disk
buffer := make([]byte, FlushDiskSize, FlushDiskSize)
count, err := pd.req.Body.Read(buffer)
if (err != nil) && (err.Error() != "EOF") {
pd.req.Body.Close()
pd.file.Sync()
return true, err
}
//log.Printf("returned from server %v bytes", count)
if pd.dp.Pos+int64(count) > pd.dp.To {
count = int(pd.dp.To - pd.dp.Pos)
log.Printf("warning: server return to much for me i give only %v bytes", count)
}
realc, err := pd.file.WriteAt(buffer[:count], pd.dp.Pos)
if err != nil {
pd.file.Sync()
pd.req.Body.Close()
return true, err
}
pd.dp.Pos = pd.dp.Pos + int64(realc)
pd.messureSpeed(realc)
//log.Printf("writed %v pos %v to %v", realc, pd.dp.Pos, pd.dp.To)
if pd.dp.Pos == pd.dp.To {
//ok download part complete normal
pd.file.Sync()
pd.req.Body.Close()
pd.dp.Speed = 0
log.Printf("info: download complete normal")
return true, nil
}
//not full download next segment
return false, nil
}
Обернув класс загрузчика в интерефейс DiscretWork из предыдущей части заметки мы можем попробовать протестировать его работу:
func TestDownload(t *testing.T) {
dl, err := httpclient.CreateDownloader("http://pinegrow.s3.amazonaws.com/PinegrowLinux64.2.2.zip", "PinegrowLinux64.2.2.zip", 7)
if err != nil {
t.Error("failed: can't create downloader")
}
errs := dl.StartAll()
if len(errs)>0 {
t.Error("failed: can't start downloader")
}
…..wait for finish download
}
Интерфейс
Уже достаточно долгое время все свои сервисы на go я делаю по одной схеме. Как правило, web-интерейс через который пользователь взаимодействует с json-сервисом посредствам http-запросов. Такая схема работы дает ряд преимуществ перед традиционными графическими интерейсами перечисленными ниже.
- Возможность в автоматическом режиме добавлять новые закачки;
- Нет привязки к определенной операционной системе, достаточно только браузера.
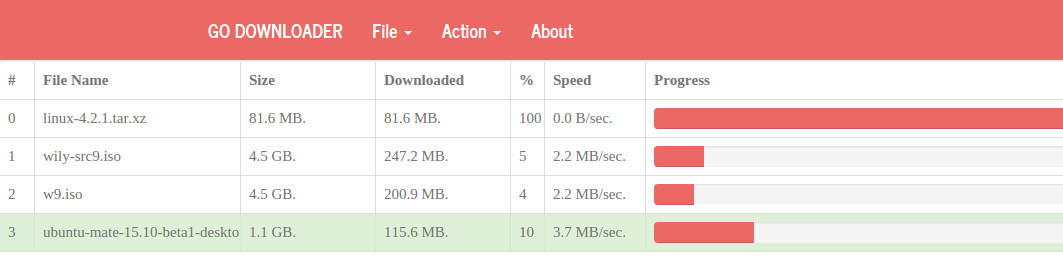
Обновление интерфейса осуществляется каждые 500 милисекунд. В качестве источника данных для таблицы закачек используется псевдо-файл localhost/progress.json. Если его открыть в браузере, откроются динамически обновляемые json-данные. В качестве компонента таблицы используется jgrid. Благодаря его простоте код занимает совсем немного места.
function UpdateTable() {
$("#jqGrid")
.jqGrid({
url: 'http://localhost:9981/progress.json',
mtype: "GET",
ajaxSubgridOptions: {
async: false
},
styleUI: 'Bootstrap',
datatype: "json",
colModel: [{
label: '#',
name: 'Id',
key: true,
width: 5
},
…..
{
label: 'Speed',
name: 'Speed',
width: 15,
formatter: FormatByte
}, {
label: 'Progress',
name: 'Progress',
formatter: FormatProgressBar
}],
viewrecords: true,
rowNum: 20,
pager: "#jqGridPager"
});
}
Завершение сервиса и сохранение настроек
Есть ещё интересная особенность сервиса о которой я бы хотел рассказать. Это то, как завершается веб-сервис. Дело в том, что в момент запуска http-сервиса, программа зависает на функции start и виснет пока мы не завершим приложение. Но в Go есть возможность подписаться на сигналы посылаемые операционной системой. Таким образом мы можем перехватить момент, когда наш процесс завершается, даже если мы это делаем через команду kill и выполняем какие-либо завершающие действия. К примеру, это сохранение настроек и текущий прогресс закачек.
c := make(chan os.Signal, 1)
signal.Notify(c, os.Interrupt)
signal.Notify(c, syscall.SIGTERM)
go func() {
<-c
func() {
gdownsrv.StopAllTask()
log.Println("info: save setting ", gdownsrv.SaveSettings(getSetPath()))
}()
os.Exit(1)
}()
Существуют много расширений стандартной реализации http-сервиса go позволяющих выполнить какие-либо действия после завершения сервиса. На мой взгляд описанный выше способ наиболее прост и надежен, данный способ работает даже если мы убивает сервис.
В принципе, это, наверное, все, что я хотел донести для читателей.
Не знаю, на сколько актуальным получился менеджер закачек для других, но дистрибутивы и образы виртуальных машин я уже качаю при помощи своего менеджера закачек.
Но контрольные суммы периодически все же проверяю.
Скачать релиз под Mac, Windows, Linux: http://loafter.github.io/godownloader/
Git:https://github.com/Loafter/godownloader
Комментарии (38)

schroeder
29.09.2015 21:29+2а можно подсунуть этой проге несколько зеркал на файл? Это была бы классная фича, если ссылка динамическая и живет например всего один день, а закачка по каким либо причинам прервалась(например комп выключили).
Mopper
29.09.2015 22:29+1Такую возможность я не предусматривал. Но в файле настроек который хранится в вашей домашней дирректории (.godownload) вы можете подредактировать список закачек и сделать две закачки указывающие на один файл в который нужно писать, но с разными адресами и разными дипазонами данных. Это конечно не рабочее решение, а попробовать как вы выразились подсунуть.

encyclopedist
29.09.2015 22:16+2b означает «бит»
B означает «байт»
В вашей программе вы похоже имели ввиду байты, а не биты.
Self_Perfection
29.09.2015 23:53+2Это не всё. Ещё и скорость прочему-то в единицах количества информации, а не собственно скорости. Вероятно там должно быть Mb/sec, а не Mb. А может быть даже и MB/sec, в случае скорости гораздо сложнее угадать мегабиты/сек или мегабайты/сек на самом деле имел ввиду автор.
Указывание почти случайного набора символов — поразительно распространённая ошибка. Казалось бы не орфография, ошибка в единицах измерения кардинально меняет смысл текста. Не понимаю, почему люди за собой не проверяют.
Darthman
30.09.2015 13:06+1<Зануда_мод_он>
Еще возможно автор имел ввиду MiB, поскольку MB = 1 000 000байт, а не 1 048 576, как многие полагают. Если уж совсем придираться.
lexore
29.09.2015 23:32+9Могу порекомендовать первым делать слать HEAD запрос.
Узнаете и размер файла в «Content-Length», и возможность докачки в «Accept-Ranges».
xiWera
30.09.2015 12:19Зачем? В первом ответе на GET итак все это содержится.
lexore
30.09.2015 13:17Чтобы узнать правильный размер и указать его в Range в первом «качающем» запросе.
После вот этой уязвимости на веб серверах могут быть настройки, отбрасывающие запросы с некорректным range.xiWera
30.09.2015 13:32Не нужно всё это. Вы предлагаете лишний запрос и ничего взамен.
Варианты.
1)мы качаем с самого начала
не важно поддерживается что-то сервером или нет — мы получим в ответ на GET всё что нужно, никакой range указывать не нужно.
2) мы качаем не с самого начала
в ответе сервера мы получим достаточно информации о том, с какого места на самом деле мы продолжаем качать.lexore
30.09.2015 13:33> в ответе сервера мы получим достаточно информации о том, с какого места на самом деле мы продолжаем качать.
Вот тут поподробнее, пожалуйстаxiWera
02.10.2015 02:09+1Всё то что вы ожидаете получить в HEAD придёт и в GET.
Пришел только размер без range или вообще без размера и диапазона? значит качаем с нулевого байта
Пришел рэнж — ну сами понимаете.
HEAD нужен только если вы не собираетесь качать, а вам нужно, например, кэши посбрасывать, или статистику пособирать.
gurinderu
30.09.2015 14:51+2Обновление интерфейса осуществляется каждые 500 милисекунд.
Почему бы не заюзать Websockets и делать push с сервера?

Alexufo
30.09.2015 14:54Кстати, в догонку из готового
Крупноват exe но все равно утилита хорошая
aria2.sourceforge.net/manual/ru/html/aria2c.html

reimax
30.09.2015 14:54ubuntu, отредактировал юзера и группу, выполнил sh /home/rei/download/godownload/Ubuntu/install.sh
cp: не удалось выполнить stat для «./godownload»: Нет такого файла или каталога

Ivan_83
30.09.2015 16:15+1«основная проблема протокола http — это низкая скорость при загрузки данных в один поток» — Фигня!
Это даже не проблема tcp, за скорость передачи отвечает Сongestion Control (откуда передаётся) алгоритм и ещё пачка опций при tcp способствуют.
Даже размеры буферов сокетов влияют.
Притом, что есть и неоднозначные опции, вроде DelayACK: для локалок / маленького RTT лучше включать, ибо снижает нагрузку на проц, а для большого RTT лучше отключать, чтобы передающая сторона по быстрее получала подтверждения.
Сongestion Control:
htcp — для RTT в пределах 100 и не очень больших потерь, для локалок вообще идеально
hybla — когда RTT > 70 и есть потери. Он медленее стартует в начале, но ощутимо устойчивее к потерям во время работы — те не роняет скорость при потерях, а постепенно снижает.
илиноис — тут кто то его нахваливает, но стартует он медленно, чем мне и не нравится.
А в былые годы использовали вегас, илинойс, вествуд и может какой то ещё мусор.
Когда я тестил всё это то вегас вообще больше 500 кб/сек не пропускал, притом что мне нужно было передать HD поток, битрейта там минимум в двое больше.
Нынче в линухах кубик по дефлту, во фре ньюрено, в винде своя хреновина.
К тому же, во времена 98 винды не уверен что там были реализованы многие важные для скорости опции, такие как rfc1323, SACK, rfc3390, delayed_ack.
Про потери на диалапе вообще лучше не вспоминать, особенно когда связь настолько ухудшалась что модем производил пересогасование скорости на более низкую.
Вот как то так: большие потери на линиях и несовершенство СС алгоритмов, вкупе с отсутствием опций и отсутствием тюнигов ОС с обоих сторон и приводило к печальным скоростям.
С другой стороны, слишком много параллельных потоков закачки тоже плохо — вырастает служебный трафик, что приводит к уменьшению полезной пропускной способности, те качать в 4 потока при диалапе было выгоднее, чем в 8-16 и более.
Аналогично цифры масштабировать и для ADSL, где в торренте после 16-32 пиров скорость закачки падала, хотя утилизация канала оставалась максимальной. (128 килобит)
В современном мире админы вебсерверов не стали умнее, просто дефолты в ОС стали чуть лучше, и в линиях потерь меньше, пропускная способность выросла, от того многопоточная закачка практически умерла.
Olej
30.09.2015 19:11-1С другой стороны, слишком много параллельных потоков закачки тоже плохо — вырастает служебный трафик, что приводит к уменьшению полезной пропускной способности
1. А почему должен возрасти служебный трафик, можно подробнее?
2. Статья о реализации на Go, а в Go потоки — это не совсем потоки… или даже совсем не потоки.Mopper
30.09.2015 21:03+2Все правильно он написал. Но на прикладном уровне что имеем то и имеем.
Отвечу на ваши вопросы:
1. Поясню на примере: Вот где больше топлива потратится если 100 человек на одном автобусе перевезти или в 5 газелях. Естестсвенно в пробке быстрее газели проедут, но без пробки одинаково, но бензина потратится больше 5 газелями.
2. Вы наверное путаете потоки выполнения и потоки скачивания, одно это параллельные нити выполнения программы, а другое tcp-ip соединения.
Ivan_83
08.10.2015 22:541. Потому что скорее всего уменьшаются окна передачи потому что скорость на каждое отдельное соединение падает, это приводит к тому что чаще ходят ACK и служебка от сервера.
2. Я вообще воздержался от высказываний по поводу GO, самой идеи и нюансов реализации, всё сказанное относится исключительно к сетям / передаче данных по сетям.
2 glagola:
Бойтесь своих желаний, они могут сбытся.
Браузер слишком тяжеловесная вещь, притом слишком не поворотливая.
Ещё браузер вечно между безопасностью и удобством балансирует, соответственно то что без проблем делается в программе в браузере нужно через жопу делать, и то если получится.
Вот взять хотя бы speedtest vs iperf / btest: спидтест глючная херня, а iperf / btest вполне себе инструменты, хотя вроде как и то и другое замеряет скорость.
Отдельно заслуживает внимание частота обновления информации (и цена за это), скорость реакции на действия и прочее.
Для качалки/торрент клиента обновления раз в 1-10 сек это ОК, а вот если более интенсивно взаимодействовать нужно то уже всё начинает лагать и тормозить.glagola
10.10.2015 15:39В данной статье автор просто обновлял данные каждые n секунд, хотя можно было бы и websocket'ы использовать, тогда был бы чистый realtime (медленнее на константу, чем если бы это была обычная программа с графическим интерфейсом, из-за обработки пакетов в сетевом стеке).
По поводу speedtest'a, iperf, btest и прочих, я видимо не очень хорошо объяснил, демон реализующий логику программы крутится на тойже машине, что и открывают браузер (хотя это и не обязательно). Браузер в данном случае как Xorg, он просто позволяет представить данные графически, а элементы управления позволяют передать управляющее воздействие в демон, чтобы тот выполнил какое-то действие.
glagola
30.09.2015 17:56У меня есть мечта, чтобы все программы работали именно по такой схеме как у вас: вычислительная часть — сервис, а визуальная — браузер. Тогда вычислительную часть будет легче сделать кроссплатформенной, а визуальную за счет JS-ных фреймворков (EmberJs, AngularJs и т.д.), CSS, HTML, а так же WebSocket'ов намного более динамичной, живой, красивой.
Mopper
30.09.2015 20:49Ну я не знаю как других новых языках (rust, scala....). Но мне кажется, что go реализовывался с прицелом на подобного рода интерфейсы. Он уже из коробки имеет http-сервер и json-парсинг и тд.
Когда go только появился, я очень растроился так как не нашел визуального toolkit для него, кнопочки и окошки не поделаешь. Потом понял что не так уж он и нужен. Хотя если появится я точно не растроюсь)

Olej
30.09.2015 19:29Уже достаточно долгое время все свои сервисы на go я делаю по одной схеме. Как правило, web-интерейс через который пользователь взаимодействует с json-сервисом посредствам http-запросов. Такая схема работы дает ряд преимуществ перед традиционными графическими интерейсами
Очень хотелось бы об этой технике почитать (обсудить) подробнее.
Отдельной статьёй (это в порядке дружественной подсказки автору) и на примере простого и компактного приложения, которое легко обозреть… в 10 минут.
Потому что все составляющие компоненты известны и понятны, но интересно бы посмотреть как автор их увязывает в комплекс.Mopper
30.09.2015 20:42Ну вот смотрите я тут об этом писал на примере «Диспечера задач для linux» и «Dicom-клиента».
habrahabr.ru/post/247727
habrahabr.ru/post/254581
Я бы наверное написал отдельную микростатью, но тут просто схема работы (Интерфейс отдельно <->логика отдельно). Не думаю что она достойна отдельной статии.
У меня был мысль реализовать визуальную-библиотеку-конструктор, которая связывала событийной моделью веб-интерфейс и обработчики событий который уже на GO.
Что то на подобие визуального редактора как у Visual studio. OnClick() OnMove() и тд.
Но чето я прикинул что опыта маловато. Надоже как-то компилировать текст разметки в исходный код go.Olej
30.09.2015 23:22У меня был мысль реализовать визуальную-библиотеку-конструктор, которая связывала событийной моделью веб-интерфейс и обработчики событий который уже на GO.
Интересно это применительно не только к Go, но и к любому другому языку программирования.
Что то на подобие визуального редактора как у Visual studio.
Какой ужас! o-:

exelens
Ещё был ReGet и если я правильно помню Флешгет появился после него.
SOLON7
Помнится Reget была самой крутой, пока не появился рекламный DM.
Aquahawk
ReGet Delux!
nik_vr
Это была единственная программа, на которую я купил лицензию в студенческие года. На Dialup'e от Кировэлектросвязи образца начала 2000-х оно того стоило.
Alexufo
У меня денег не было )) Я помню, что просил разработчика trashreg сделать мне лоадер, который сам нажимает кнопку «продолжить» ориентируясь по расстоянию белых пикселей в кнопках загрузочного экрана. Тогда я был горд своей идеей )
nik_vr
Я со стипендии покупал :)
Хотя лоадер тоже делать доводилось. Для Windows Commander (тогда он ещё так назывался). Делал в небезызвестной в то время программе InqSoft Sign of Misery.
Alexufo
Cо Станиславом, автором «InqSoft» тоже знаком немного :-) Писал о нем
habrahabr.ru/post/158381
KReal
Ох, вспомнил как две недели качал Ultima Online по ночам со скоростью 19,2 )))