

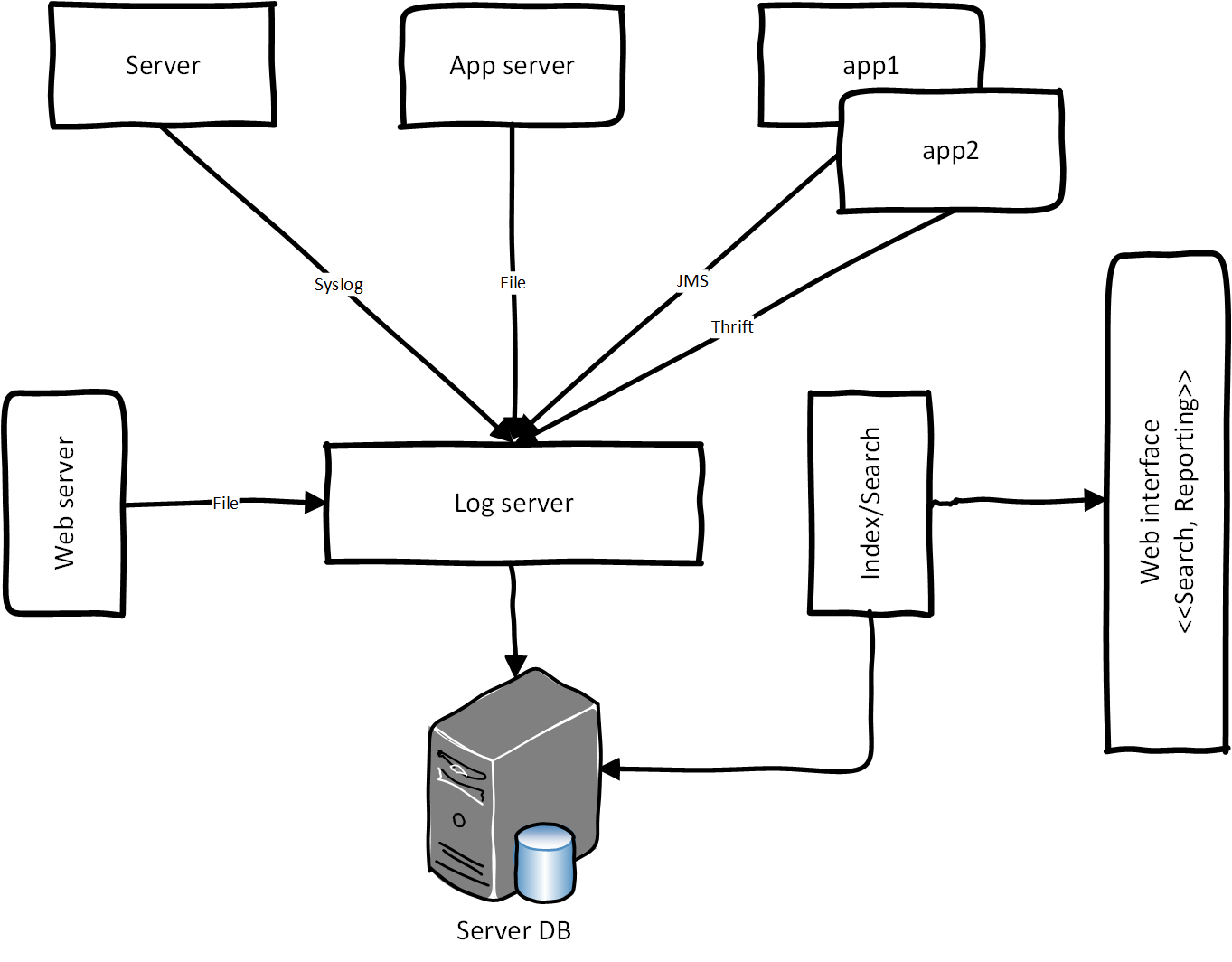
В 2011 году в одном из флагманских проектов Электронного правительства РФ мы столкнулись с проблемой проектирования централизованной системы логирования (протоколирования). ЦСЛ – это логирование для обработки прикладных и системных логов (событий) в едином хранилище. Прикладные логи из сервер-приложения (обращения гражданам к сервису через портал госуслуг), лог балансировки, нагрузки и шина интеграции протоколируют логи через лог сервера, попадают в хранилище, после этого данные индексируется и агрегируются для отчётности. Для формирования отчётности мы использовали систему BI. Ниже — концептуальная архитектура ЦСЛ:
Ситуация усложняется, когда участвуют разные legacy гетерогенные системы со своим хранилищем и системой логирования. Одна из таких систем — СМЭВ (Система межведомственного электронного взаимодействия, архитектура 2011 г.). Она содержит два типа шин интеграции Oracle: WSM и Oracle OSB. Oracle WSM всегда протоколирует сообщения в виде BLOB в собственной схеме БД. Также OSB логирует сообщения в своей схеме, а у других ПО свой подход к логированию. Теперь представьте, что вся эта система устанавливается в нескольких регионах РФ. Данные реплицируется из других ЦОДов в федеральный ЦОД для обработки и агрегаций. После консолидации и агрегации результирующие данные попадают в отчёты через систему BI. В иллюстрации ниже приведена высокоуровневая архитектура СМЭВ 2.0:
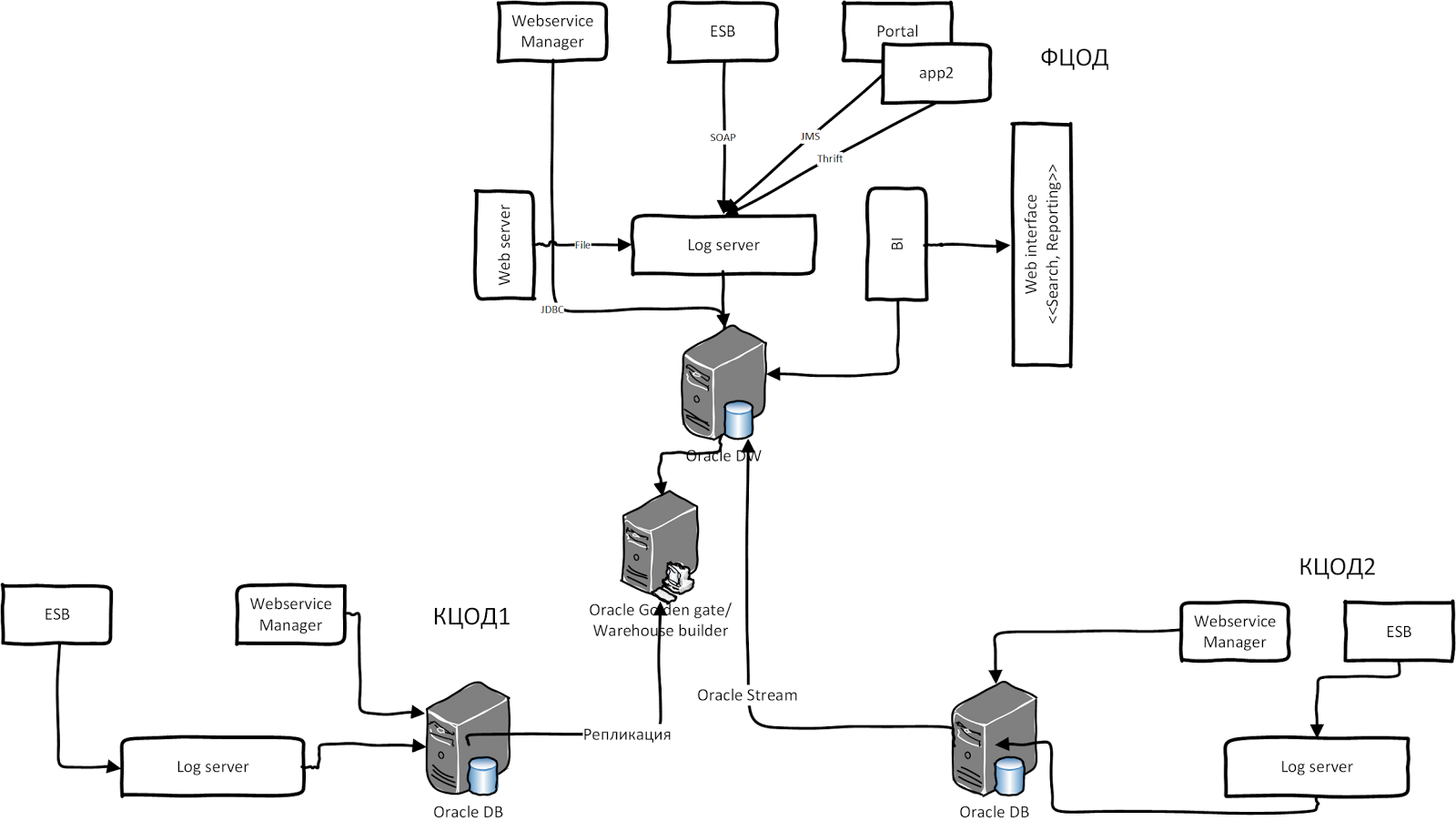
У этой системы был ряд недостатков:
- Плохая масштабируемость: первой проблемой стала динамика роста регистраций и использование сервисов во всех органах власти. В начале 2011 года было зарегистрировано всего 4 000 сервисов, а уже во втором квартале 2013 года – более 10 000. В каждом ЦОДе были зарегистрированы примерно по 1 000 soap-сервисов в шине интеграции, а в федеральном ЦОДе — около 2 000 сервисов. Таким образом, потребность в сервисе выросла почти в 6 раз: на федеральном уровне количество логов достигало 21 млн в день, а по всей России – примерно 41 млн записей, в час-пик RPS (Request per second) — 1375. Конечно, по сравнению с высокой нагрузочной системой это крохотные цифры. Весь процесс обработки данных и отчётности реализован на основе PL/SQL, т.е. обработка сообщения и консолидация данных были реализованы на PL/SQL, которая не была достаточно производительной. После большого апдейта мы могли разобрать 450 тысяч сообщений за 110 минут, когда нам на вход поступало несколько миллионов сообщений в день.
- Второй сильно повлиявший фактор – это репликация данных между ЦОД, которая проводилась через разные гетерогенные инструменты: WHB, Oracle Goldengate, Oracle Stream. Если канал связи по каким-то причинам отсутствовал, их приходилось запускать повторно, чтобы избежать ошибок.
- Масштабирование Oracle RAC: также при увеличении роста потребности в сервисе, необходимо было масштабировать БД, что было очень дорого и сложно.
- Дорогостоящие лицензии на ПО Oracle.
Все эти причины сподвигли нас пересмотреть нашу архитектуру и перейти на NoSQL. После небольшого обсуждения и сравнительного анализа мы решили использовать хранилище Cassandra. Её плюсы были очевидными:
- Автоматическая репликация данных между датацентрами;
- Шардинг данных «из коробки»;
- Линейное масштабирование кластера Cassandra;
- Отсутствие единой точки отказа;
- модель данных на основе Google Big Table;
- СПО (open source).
В итоге у нас получилось следующая концептуальная архитектура на базе Cassandra:
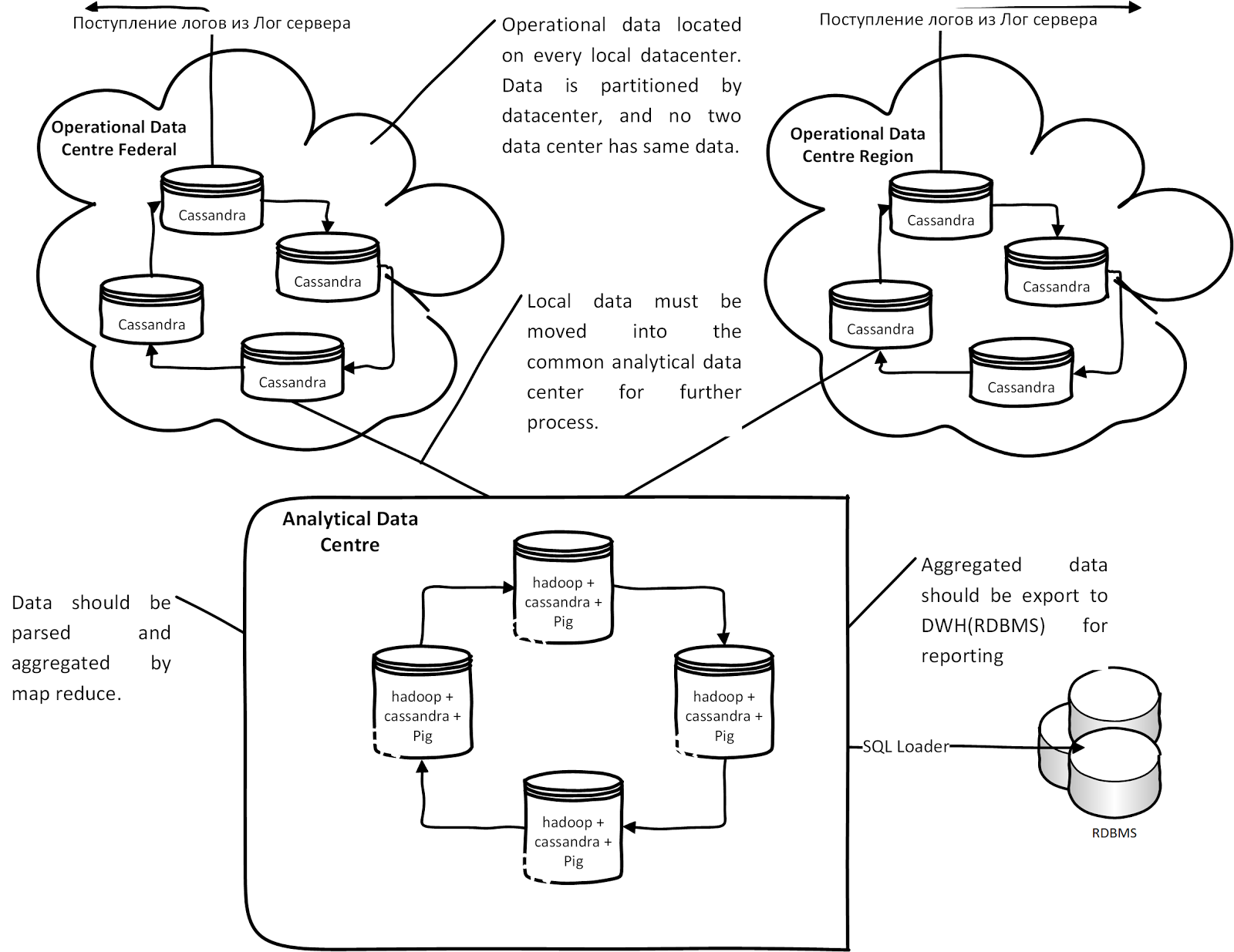
Каждый лог-сервер региона или ЦоД пишет протоколы в своём узле кластера Cassandra. Данные автоматически реплицируются в аналитическом центре для анализа. После анализа и обработки данных в Hadoop Map Reduce данные выгружаются через SQL loader для отчётности в Oracle. Если по каким-то причинам канал связи между аналитическими центрами и ЦоД отсутствует, данные накапливаются (Hinted hands of) в каждом операционном узле Cassandra и при появлении связи, данные из ЦоД попадают в аналитические узлы.
Стек ПО
- Cassandra 1.1.5
- Hadoop 1.0.3
- Apache pig 0.1.11
- AzKaban
Модель данных и их обработки
Модель данных — Column Family, состоящая из столбцов и значений. Все столбцы (column) статичные, потому что Pig не умел работать с динамическими столбцами: таким образом, у нас хранится полезная нагрузка soap payload в столбце. Через Hadoop Map Reduce проводится разбор сообщения, и результат сохраняется в таблице Cassandra для построения агрегата. После этого в результирующих метаданных запускается Reduce для построения разных агрегатов. Агрегированные данные экспортируется через Oracle SQL Loader из Hadoop HDFS в Oracle DB.
Производительность
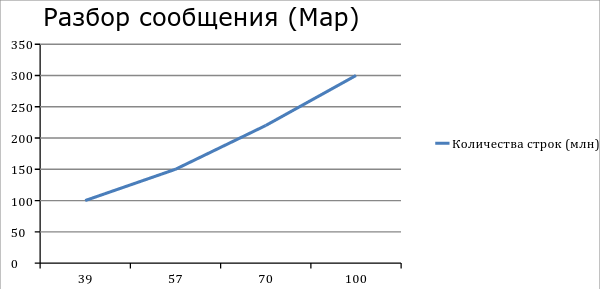
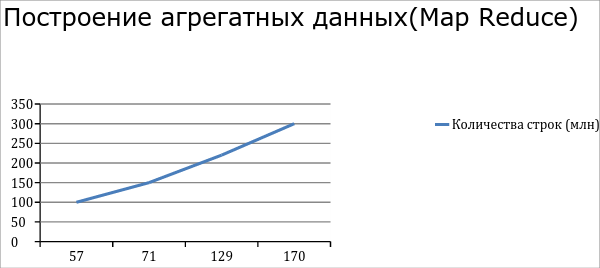
После настройки (fine tuning) Hadoop мы получили такие производительности. Разбор 300 млн строк из Cassandra занимает примерно 100 минут. Построение агрегата на 300 млн записей занимает в среднем 170 мин. Pig cкрипт агрегата данных в нашем случае содержит 3 крупных операторов join, поэтому появляется ещё 3 временных map.
Итоги
При переходе очень важно понять data-модель и причину перехода. Реляционные базы данных до сих пор лидируют среди хранилищ данных, при помощи реляционной модели можно реализовать почти все домен-модели: например, мы перенесли только не транзакционные данные (прикладные и системные логи). Cassandra нам помогла решить проблему с репликацией между data-центрами, а Hadoop решил вопрос производительности обработки данных.
Ссылки:
Комментарии (54)

astronom
30.09.2015 17:05Т.е. рост практически линейный? Получается, если будет 3 млрд строк, то за сутки не уложиться? А Вы производите агрегацию в одном месте или в дата-центрах на местах, и уже агрегаты доставляете в центр? Агрегируется все или каждая 100-я или 1000-я строка лога (если это не лог фин. операций, к примеру, то не всегда нужно агрегировать все строки).

shamim
30.09.2015 21:49Да рост был линейный, за 3 млрд строк надо было бы еще hadoop data node добавлять. Да мы провели агрегацию в одном месте (федеральном цоде). Данные были не транзакционные и агрегировал суточные данные

AndryX
30.09.2015 18:29+3Есть опыт интеграции в СМЭВ. Это сущий ад, который не заканчивается уже 9 месяцев ради 3х простых сервисов. Боюсь никакие улучшения системы логирования вам не помогут.

lair
30.09.2015 18:30Правильнее сказать «не помогли» — впереди СМЭВ 3, с другой идеологией и от другого разработчика.
shamim
30.09.2015 21:52весь страна ждет, уже 2ой год.

sanitar
30.09.2015 22:30Да дождалась же уже, но что толку — те же яйца, только в профиль теперь с ActiveMQ внутри.
shamim
01.10.2015 10:58в СМЭВ 3 концепция другая же — асинхронная взаимодействия

Stas911
01.10.2015 21:39То есть посылаешь запрос, получаешь ack и тишину и ждешь, пока обед кончится? :)
shamim
01.10.2015 22:15по моему 2 моделей
1) опрос (poll) — когда периодический приходишь к СМЭВ за ответ с номером
2) push — когда при обращение к СМЭВ передаешь еще url сервиса для получения ответа, СМЭВ сам вызывает сервис клиента когда ответ получен от поставщика
shamim
30.09.2015 21:50Может поделитесь какие у вас были сложности с интеграцию?
AndryX
01.10.2015 00:22Задача простая — реализовать средство идентификации пользователей электронного кошелька. Для этого были найдены три сервиса: SID0003450 (ИНН), SID0003822 (СНИЛС), SID0003418 (Проверка паспорта через ФМС).
Так вот, сначала ждешь ключи N времени (месяца полтора). Пока ты их ждешь ничего, конечно же, сделать нельзя потому что сервер на котором лежала документация был не доступен 2 недели. (Кажется было в Марте.) Потом качаешь доку в DOC формате, в которая хоть и в архиве, но именно в нее закинуты файлы с примерами, без которых работать сложно. Когда у тебя Mac, то процесс извлечения файлов заключается в нахождении друга с Windows и просьбой его все оттуда выковырять.
А когда ключи приходят делаешь два простых сервиса, а потом оказывается что есть отдельные ключи на один из сервисов (ФМС). По этому сервису нас перенаправляет поддержка со СМЭВа в ФМС, ФМС потом к людям, которые писали им софт (какого?), последние отфутболивают обратно, где нам больше не отвечают 4 месяца.
Это только та часть проблем, которую я помню. Даже не говорю о необходимости ставить CryptoPro и мучиться потом с ним. В основном бюрократия, но и технических «странностей» у вас хватает.lair
01.10.2015 00:31Меня вот всегда потрясало, что — несмотря на системы логирования, аудит, вот это вот всё — любое общение с ТП СМЭВ все равно начиналось с «пришлите трейс запроса/ответа». И отдельно — «контрольные примеры» во всех РП.
shamim
01.10.2015 10:55Служба эксплуатации тогда еще не было готов пользоваться CQL запросами чтобы вытащить данные из Cassandra таблицы, поэтому часто для оперативной работы спрашивали «пришлите трейс запроса/ответа»
lair
01.10.2015 11:06К сожалению, в моем опыте это было не «часто для оперативной работы», а всегда. Иными словами тикет в ТП не открывали без запроса/ответа. Нам пришлось сделать свою систему сквозного логирования, чтобы решить эту проблему.
Служба эксплуатации тогда еще не было готов пользоваться CQL запросами чтобы вытащить данные из Cassandra таблицы
Удивительно, что в задании не был изначально заложен интерфейс.shamim
01.10.2015 11:13сначала в плане было заложен интерфейс, только компания datastax когда решил выпустить IDE под названием Datastax DevCenter, было принято решения ждать и применять его.
shamim
01.10.2015 10:57если это начале 2011 года, да было организационная проблема.
>>> Это только та часть проблем, которую я помню. Даже не говорю о необходимости ставить CryptoPro и мучиться потом с ним.
по моему эту жалобу относится к CryptoPro а не к СМЭВ

VolCh
30.09.2015 20:33-1Все эти причины сподвигли нас пересмотреть нашу архитектуру и перейти на NoSQL.
Почему именно NoSQL, а не другая SQL СУБД?shamim
30.09.2015 21:22Из за репликация данных между ЦОД, система работал в 7 регионах страны и часто было свой каналов между ЦоД, У Cassnadra из коробки есть возможности хранить данный в локальных узлах и при появление канал связи Cassandra может передавать и синхронизировать данные между узлами кластера (hinted handhof). А также масштабируемость системы было критично.

Ilirium
01.10.2015 06:50-3Вот это картинка! Супер! В пост защёл только чтобы восхититься и написать комент.
Alexins
01.10.2015 09:31-1Хоть убей, не пойму, при чем здесь NoSQL.
Появилась связь между узлами большого кластера. NoSQL база перераспределила данные на разные узлы кластера.
Совсем не факт, что данные одного центра обработки данных будут находится на узлах данного центра, а не утекут безвозвратно в другой центр данных. При потере связи, текущий центр теряет часть своих данных.
Мой старый блог «Apache CXF и ЭЦП для SOAP сообщений СМЭВ».shamim
01.10.2015 10:53+1>>> Совсем не факт, что данные одного центра обработки данных будут находится на узлах данного центра, а не утекут безвозвратно в другой центр данных
Речь идет о Cassandra Replication
вот вам 2 пример
create keyspace p00skimKS
with strategy_class='NetworkTopologyStrategy'
and strategy_options:p00smevDC = 0 and strategy_options:p00skimDC = 1;
— create keyspace p00smev_archKS
with strategy_class='NetworkTopologyStrategy'
and strategy_options:p00smevDC = 1 and strategy_options:p00skimDC = 0;
на первом примере данные не когда не будет реплицироваться в дата центре p00smevDC, а на втором примере нет. Есть хорошая документация в cassandra planet www.datastax.com/dev/blog/multi-datacenter-replication (раздел Geographical Location Scenario)
>>> Мой старый блог «Apache CXF и ЭЦП для SOAP сообщений СМЭВ».
причем тут это не очень понял ))Alexins
01.10.2015 13:23-1Пример интересный.
Первый пример — p00skimKS. Вы запрещаете перетекание данных в другой дата центр.
Второй пример — p00smev_archKS. Вы запрещаете распределять в текущем дата центре и разрешаете отдавать в другой дата центр.
Из двух примеров получается как минимум дубликат своих данных в двух разделах. Допустим, нам места на диске не жалко. Но у нас несколько внешних дата центров и для каждого надо подготовить свой набор данных, которые надо отдать. Получаем картину из кучи N+1 разделов.
N — количество внешних дата центров. +1 — это текущий дата центр. И первый из N — это общий (федеральный) центр.
Может я и не прав. Не проще ли реализовать аналог почтового сервера, или MQ сервера, с указанием адресатов доставки? Затрат на распределение данных по разным разделам меньше.
Можно заменить SMTP или MQ сервер на FTP сервер. Выкладывать данные для других центров на ftp обменник. И принимаемый дата центр сам решает проблему, как обрабатывать эти данные. То есть, не завязаны на использование одного ПО.
Далее, технология MapReduce. Да, это модно и потому, круто. Но почему графика не в виде логарифма, а в виде прямой линии? По мне, всё дело в этой технологии. Хотим добиться увеличения скорости за счет обработки данных текущего узла кластера. Но на поверку получаем обратный эффект. Каждый узел имеет часть данных другого узла. Другими словами, при 3-х уровневой репликации данных, мы получаем полных 3 прохода обработки одних и тех же данных. Проще было бы получить поток не повторяющихся данных. И этот поток нарезать на кучу потоков в одном узле и на несколько узлов.
0x0FFF
01.10.2015 13:41+1График никакого отношения к MapReduce не имеет. Он лишь показывает, что используемый алгоритм обработки данных линейно зависит от количества входных данных. Тут не важно, работает ли он на кластере или на одной машине.
Почему 3 прохода обработки? При записи данных в HDFS вы действительно записываете данные 3 раза на 3 разных машинах, но делается это не последовательно, а параллельно. При чтении вычитывается только одна копия и чаще всего локальная для обработчика, другие копии хранятся для отказоустойчивости и speculative executionAlexins
01.10.2015 16:12-2Линейная зависимость обработки данных от количества обрабатываемых данных, это главная проблема.
Если бы была экспонента, было бы очень плохо. А вот логарифм — это то, к чему надо стремиться.
То есть, затраты растут гораздо ниже, чем объем данных. Я по оси X представляю объем данных, а по оси Y объем затрат или время обработки.
Для этого нужно отказываться от последовательной обработки данных.
Пример. У вас на машине 4 ядра.
1) Последовательно берем данные, обрабатываем, отправляем куда-то.
2) Если это не конец данных, возвращаемся к первому пункту.
Итого: у нас занято 1 ядро, а 3 простаивает.
Это не эффективно. Надо организовывать очередь из задач обработки и определять набор обработчиков. Так мы загрузим все 4 ядра и тем самым увеличим скорость обработки данных. У нас уже не получится линейного графика. Он будет больше напоминать логарифмическую кривую. При этом, части получения исходных данных и отправки результата, могут остаться последовательными.
На самом деле, на 4-х ядрах можно использовать несколько десятков обработчиков (потоков).
Ну ни как не получается у меня прямой линии. Что я делаю не так?
Честно, в статье так и сказано. У нас был Oracle и он работал быстро. И вот однажды нам его стало не хватать. Мы решили поставить вместо одного Oracle кучу NoSQL машин. О чудо, система стала быстрее работать. Но чуда нет. Производительность системы растет линейно. Нам нужно поставить еще несколько физически/виртуальных машин.
>> У этой системы был ряд недостатков:
>> Плохая массштабируемость: первой проблемой стала динамика роста регистраций и использование сервисов во всех органах власти.
Вы сократили время обработки одного запроса, но с задачей увеличения производительности не справились.
>> После настройки (fine tuning) Hadoop мы получили такие производительности. Разбор 300 млн строк из Cassandra занимает примерно 100 минут. Построение агрегата на 300 млн записей занимает в среднем 170 мин.
Hadoop — это ваш MapReduce. А вы мне, «График никакого отношения к MapReduce не имеет».0x0FFF
01.10.2015 16:36+1У вас есть процессор. Максимально он может выполнить X инструкций в секунду, чем больше ядер тем больше X. У вас есть входные данные в количестве Y записей. Если на обработку каждой записи тратится C операций процессора, то на этом процессоре максимум вы сможете обработать Y*C/X операций в секунду. Не важно, 20 или 20000 потоков у вас, процессор быстрее не станет и выполнять больше X операций он не сможет физически. Итого Runtime = Y*C/X. Увеличив Y в 2 раза получим Runtime = 2*Y*C/X, что в два раза больше. Если у нас не один процессор, а 1000, это не изменит картины. Будет время выполнения Y*C/(1000*X) и 2*Y*C/(1000*X), то есть при росте количества данных в 2 раза все равно производительность упадет в 2 раза.
Это называется асимптотическая сложность алгоритма O(N). К таким алгоритмам и относится чаще всего алгоритм парсинга логов — вы не сможете получить меньше O(N), т.к. вам нужно как минимум один раз прочитать каждую строчку входных данных. Я не отрицаю, есть алгоритмы сложностью меньше O(N), допустим тот же поиск в сбалансированном дереве с характеристикой O(logN), или даже на дереве ван Эмде Боаса со сложностью O(log(logN)), но все алгоритмы с sublinear complexity не являются не алгоритмами обработки данных, а алгоритмами поиска.
Да, и не «вы» — система-то в общем не моя, я скорее сам критикую их архитектуру.Alexins
01.10.2015 23:24-1Вопрос не по теме. Вы практик или теоретик?
Генрих Форд придумал конвеер, тем самым повысив производительность труда на производстве.
Теперь дело за малым, повторно открыть гениальное открытие или сделать гениальное закрытие.
Получением исходных данных занимается один процесс. Второй, из переменной X не занимается тем же самым. Он делает совсем другую работу. И если эта работа требует больше затрат, читай тактов процессора, тогда можно организовать несколько потоков обработки данных от первого процесса.
Текстовые записи в журналах не однородны. Их так же можно разнести на группы обработчиков.
Получаем, что однородные данные будут обрабатываться за одинаковое количество шагов.
Поскольку данные не однородные, мы получаем разное количество шагов для каждой строки журнала.
Ваша математика рассыпалась на кучу условий если.
Скажу больше. Если в журнале все строки однородные, это уже не журнал, а суть поток однородных данных. И только в этом случае Ваши формулы становятся детерминированными и верными. И даже в этом случае можно применить конвеерную обработку данных.
Применение алгоритмов O(logN) на одном или нескольких участков конвеера даст прирост производительности. Вам понадобится гораздо меньшее количество процессов (автоматов) на этом участке. Высвободившийся ресурс можно задействовать на более тяжелом участке.
Решаем задачу Генриха Форда. Один мастер собирает 1 машину за 1 неделю. 50 мастеров за неделю соберут 50 машин. Маловато. Но для производства 100 машин надо построить еще один цех и нанять еще 50 мастеров. Продолжать?0x0FFF
02.10.2015 10:07Не буду критиковать ваши замечания. Просто приведите пример алгоритма обработки данных, скорость работы которого зависит от объема входных данных сублинейно (допустим, по тому же логарифму)
shamim
01.10.2015 16:58Тут похоже нужно пояснить не которые моменты, я вечером попробую расписать по подробнее

dunmaksim
01.10.2015 14:12+1Общее впечатление от статьи: «Ребят, мы тут узнали, что существует NoSQL, и решили её внедрить! Но сейчас нам дальше рассказывать некогда, пора домашку делать.»
shamim
01.10.2015 14:25У комания AT Consulting есть подписанный договор NDA как исполнитель, который не позволяет детализировать все моменты. Если у вас есть конкретный вопрос, буду рад отвечать.
dunmaksim
01.10.2015 15:22Почему SOAP, а не JSON?
shamim
01.10.2015 15:37SOAP являлся defacto стандартом для взаимодействия через СМЭВ с поставщиками услуг.
dunmaksim
01.10.2015 16:51Кто решил, что для СМЭВ нужно использовать SOAP, и почему его, а не какой-нибудь другой протокол или формат обмена данными?
shamim
01.10.2015 16:56по приказу Министерства связи и массовых коммуникаций Российской Федерации от 27 декабря 2010 г. № 190 «Об утверждении технических требований к взаимодействию информационных систем в единой системе межведомственного электронного взаимодействия»
с приказом можно ознакомится по ссылке
smev.gosuslugi.ru/portal/api/files/get/424dunmaksim
01.10.2015 17:01Ага, ясно, там люди до сих пор тексты в Lexicon for DOS набирают, видимо.
shamim
01.10.2015 17:19вы это зря )) у soap есть некоторые большие преимущества, это wsdl описания сервиса (которые еще применяется для создания stub) и валидация сообщения(я про wadl знаю) а также готовые разных стандартов от w3c и oasis. Такие стандарты очень важно для egovernance.
lair
01.10.2015 17:27+1К wsdl-описаниям сервисов неплохо бы прилагать административный ресурс, который бы следил за тем, что (а) описания соответствуют сервисам и (б) в схеме сообщений в самом интересном месте не стоит
<xs:any/>. А то вроде и есть схема, а вроде и толку от нее ноль. А если учесть, что добрая половина данных в СМЭВ передавалась в виде вложений, то преимущества строгой типизации падали еще больше.
Alexins
01.10.2015 18:18-1>> Статья оставляет впечатление недосказанности:
Во-первых, зачем для сервиса накопления и анализа логов Cassandra?
За это ставят плюсы.
>> Линейная зависимость обработки данных от количества обрабатываемых данных, это главная проблема.
За это ставят минусы.
Ставьте еще.
Как только идет неудобная тема, сразу минус.
Мое мнение, попытка авторов проекта была интересная в плане самообучения. Но совсем провальная в плане производительности. Не удивлюсь, если следующая версия этой системы будет от другого производителя.
И честно, тут проблема не в том, используется ли реляционная база данных или нет.
Сумели переложить задачу с одной машины на несколько — «круто», «зачет», «так держать», «дай пять».
Производительность системы тает по линейному закону, а может, даже по экспоненте — полный провал.
Первый график после 57 идет вверх гораздо быстрее — плохо.
Второй график после 71 идет вверх гораздо быстрее — плохо.
Минусы надо ставить автору такой производительности, а не тому, кто вздумал критиковать.
grossws
01.10.2015 18:30Как только идет неудобная тема, сразу минус
Не люблю нытиков, так что сразу минус.Alexins
01.10.2015 19:16А по теме ничего путного сказать не смог.
Я что-ли графики показал на всеобщее обозрение?
Там производительность падает. Мне как-то до этого проекта совсем нет дела. Это так, Вам, к сведению,
0x0FFF
Статья оставляет впечатление недосказанности:
shamim
Договор NDA с заказчикам не позволяет все детализировать, я все таки попробую отвечать на ваше все вопросы:
>>> Во-первых, зачем для сервиса накопления и анализа логов Cassandra? Почему нельзя было взять тот же Flume и спокойно грузить данные в HDFS, а там их с тем же успехом обрабатывать в MR?
Из за репликация данных между ЦОД, система работал в 7 регионах страны и часто было свой каналов между ЦоД, У Cassnadra из коробки есть возможности хранить данный в локальных узлах и при появление канал связи Cassandra может передавать и синхронизировать данные между узлами кластера (hinted handhof). Если через flume тогда необходимо было хранить все эти данные в Oracle ExaData, серверные диски было довольно дорогие, нам еще бы нужно было вычислить промижуточные данные во время свой канал связи между ЦОД.
>>> Картинки исходной и целевой архитектуры не имеют общих компонент, сложно понять куда именно (и как) вы подключили Cassandra
Cassandra установлись в каждом регионе, стратегия NetworkTopologyStrategy, репликация между дата центрами.
>>> 300млн записей за 100 минут — какого рода обработка проводится? Мой ноутбук может спокойно распарсить 300млн строк лога за 7-8 минут на одном ядре. Обработка очень сложная с подтягиванием данных из внешних систем?
в основном группировка данных, большее 9 groupBy а также во время reduce в обновили данных в Cassandra таблицу
>>> Показатели производительности без указания характеристик кластера смотрятся немного странно
Cassandra сервер: 4 CPU, 8 Gb Ram, virtual machine
Hadoop data node: 6 cpu, 16 Gb RAM, virtual machine
>>> На графиках не подписаны оси и что где меряется непонятно
оси X — время в минутах
оси Y — количества строк в таблице
0x0FFF
С появлением в картинке Exadata и разворачиванием Cassandra+Hadoop на виртуальных машинах ситуация начинается проясняться. Я не в курсе истории, но скорее всего она выглядела приблизительно так:
Если серьезно:
shamim
Если сейчас поставили задачи для решения таких проблем, я бы проектировал его по другому.
>>> По производительности — на скромном кластере в 20 нод агрегация не 300 миллионов, а 300 миллиардов записей лога делается за <30 минут
проблема было еще с Cassandra и Pig (data flow). У cassandra еще не было готово выборки данных через where clause. Pig в любой обработки подтянул все данные (хоть это млрд)и после этого pig начал фильтрации обработки.
0x0FFF
Понятно. Но Flume умел то, что я говорю, еще в 2012 году. Cassandra изначально тут использовать не надо было, т.к. это система совсем для другой задачи. Hive с partitioning вполне мог справиться, опять же уже в 2012-м. Тот же Hive+Tez доступен с февраля 2013-го и пользоваться им проще, чем Pig
Stas911
Hadoop крутится в виртуалке? Вроде везде пишут, что никаких прослоек и виртуализаций если хотите производительность
UPD: Прочитал выше, если виртуалки — это все, что было, тогда, видимо, выбора было не много.
shamim
да virtual machine на VMWare. Проблемп было в СХД, он был медленный и общий для Cassandra и Hadoop. Поэтому производительности анализ данных у нас не так высоко было