
")
Пошел я как-то на курсы по BigData, по рекомендации друзей и мне посчастливилось поучаствовать в соревновании. Не буду рассказывать об обучении на курсе, а расскажу о библиотеке MyMediaLite на .Net и о том, как я ее использовал.
Прелюдие
На носу была завершающая лабораторная работа. В течении всего курса не особо вступал в конкуренцию на лабораторных работах, ближе к концу жизнь заставила побороться — чтобы получить сертификат, надо было зарабатывать баллы. Последняя лекция была не сильно информативная, скорее обзорная и я решил не терять время, параллельно заняться последней лабкой. К сожалению, у меня не было на тот момент, своего кластера с установленным Apache Spark. На учебном кластере, так как все ринулись делать лабораторную, шансов и ресурсов на успех оставалось мало. Мой выбор пал на MyMediaLite на C#.Net. К счастью, был рабочий сервак, не сильно загруженный и выделенный для экспериментов, довольно неплохой, с двумя процами и 16 Gb оперативной памяти.
Условия задачи
Нам были предоставлены следующие данные:
- таблица рейтингов фильмов train.csv (поля userId,movieId,rating,timestamp). На растерзание отдается добрая половина выборки (произвольно отсортированная по movieId и userId), вторая половина остается у супервизора курса, для оценки качества рекомендательной системы
- таблица tags.csv (поля userId,movieId,tag,timestamp) с тэгами к фильмам
- таблица movies.csv (поля movieId,title,genres) с названием фильма и его жанром
- таблица links.csv (поля movieId,imdbId,tmdbId) соответствие идентификатора фильма в базах данных imdb и themoviedb (там можно найти дополнительные характеристики фильмов)
- таблица test.csv (поля userId, movieId и rating) собственно, вторая половина выборки, но без рейтингов.
Необходимо предсказать рейтинги фильмов в таблице test.csv, сформировать результирующий файл, который содержит данные в формате: userId, movieId, rating и залить в чекер. Качество рекомендаций будет оцениваться по RMSE и оно должно быть не хуже (значит не более) 0.9 для зачета. Далее будет идти борьба за лучший результат.
Все файлы данных доступны тут https://goo.gl/iVEbfA
Отличная статья про то, как считать RMSE
Мое решение
Последний вариант кода доступен в гихабе.
Ну кто же в бой идет без разведки? Были получены «разведывательные данные» на перерывах лекций и оказалось, что нам подсунули :) пресловутый movielens 1m, с подмешиванием какого-то другого набора данных. Те, кто уже справился с лабой хвалили SVD++.
Как правило, любое машинное обучение состоит из трех частей:
- Representation
- Evaluation
- Optimization
Я тоже пошел по этому пути и разделил выборку на две части, 70% и 30% соответственно. Вторая часть выборки нужна для проверки точности модели. Был написан самый первый вариант кода, по результатам которого лабораторная работа была успешно сдана. Результат 0.880360573502 на модели BiasedMatrixFactorization. Всю мишуру с тегами и линками отмёл сразу, они могли быть использованы в виде дополнительных фич, для получения лучшего результата. Не стал тратить на это время и это было верным решением, IMHO. Отсутствовавшие в обучающей выборке пользователи тоже были смело проигнорированы, а рейтинги были проставлены неизвестными значениями, которые возвращал класс BiasedMatrixFactorization. Эта была серьезная ошибка, которая стоила мне первого места. На модели SVD++, был получен результат 0.872325203952. Чекер показывал первое место и я со спокойной душой, репетируя речь победителя пошел спать. Но, как говорится, цыплят считают по осени.
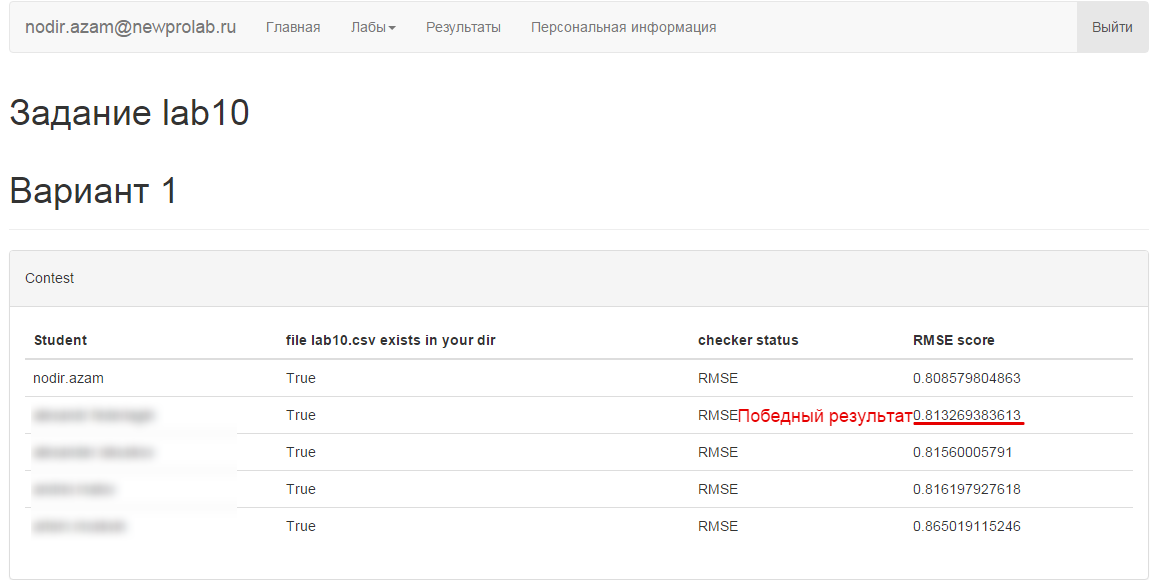
Итоги соревнования
Буду краток, победное место переходило из рук в руки несколько раз. В итоге, на момент дедлайна мой товарищ получил первое место, а я — второе. Мы, программеры — упрямый народ, удалось все-таки выжать лучший результат на BiasedMatrixFactorization. Увы после дедлайна.
Альтернативное решение
Мой товарищ wenk, получивший первое место, любезно согласился предоставить свой код. Его решение было реализовано на кластере с Apache Spark, используя ALS из scikit-learn.
# coding: utf-8
# In[1]:
import os
import sys
os.environ["PYSPARK_SUBMIT_ARGS"]=' --driver-memory 5g --packages com.databricks:spark-csv_2.10:1.1.0 pyspark-shell'
sys.path.insert(0, os.environ.get('SPARK_HOME', None) + "/python")
import py4j
from pyspark import SparkContext,SparkConf,SQLContext
conf = (SparkConf().setMaster("spark://bd-m:7077")
.setAppName("lab09")
.set("spark.executor.memory", "50g")
.set("spark.driver.maxResultSize","5g")
.set("spark.driver.memory","2g")
.set("spark.cores.max", "26"))
sc = SparkContext(conf=conf)
sqlCtx = SQLContext(sc)
# In[2]:
ratings_src=sc.textFile('/lab10/train.csv',26)
ratings=ratings_src.map(lambda r: r.split(",")).filter(lambda x: x[0]!='userId').map(lambda x: (int(x[0]),int(x[1]),float(x[2])))
ratings.take(5)
# In[3]:
test_src=sc.textFile('/lab10/test.csv',26)
test=test_src.map(lambda r: r.split(",")).filter(lambda x: x[0]!='userId').map(lambda x: (int(x[0]),int(x[1])))
test.take(5)
# In[4]:
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel
from pyspark.mllib.recommendation import Rating
rat = ratings.map(lambda r: Rating(int(r[0]),int(r[1]),float(r[2])))
rat.cache()
rat.first()
# In[14]:
training,validation,testing = rat.randomSplit([0.6,0.2,0.2])
# In[15]:
print training.count()
print validation.count()
print testing.count()
# In[16]:
training.cache()
validation.cache()
# In[17]:
import math
def evaluate_model(model, dataset):
testdata = dataset.map(lambda x: (x[0],x[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = dataset.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).reduce(lambda x, y: x + y) / ratesAndPreds.count()
RMSE = math.sqrt(MSE)
return {'MSE':MSE, 'RMSE':RMSE}
# In[12]:
rank=20
numIterations=30
# In[28]:
model = ALS.train(training, rank, numIterations)
# In[ ]:
numIterations=30
lambda_=0.085
ps = []
for rank in range(25,500,25):
model = ALS.train(training, rank, numIterations,lambda_)
metrics = evaluate_model(model, validation)
print("Rank = " + str(rank) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE']))
ps.append((rank,metrics['RMSE']))
# In[10]:
ls = []
rank=2
numIterations = 30
for lambda_ in [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]:
model = ALS.train(training, rank, numIterations, lambda_)
metrics = evaluate_model(model, validation)
print("Lambda = " + str(lambda_) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE']))
ls.append((lambda_,metrics['RMSE']))
# In[23]:
ls = []
rank=250
numIterations = 30
for lambda_ in [0.085]:
model = ALS.train(training, rank, numIterations, lambda_)
metrics = evaluate_model(model, validation)
print("Lambda = " + str(lambda_) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE']))
ls.append((lambda_,metrics['RMSE']))
#Lambda = 0.1 MSE = 0.751080178965 RMSE = 0.866648821014
#Lambda = 0.075 MSE = 0.750219897276 RMSE = 0.866152352232
#Lambda = 0.07 MSE = 0.750033337876 RMSE = 0.866044651202
#Lambda = 0.08 MSE = 0.749335888762 RMSE = 0.865641894066
#Lambda = 0.09 MSE = 0.749929174577 RMSE = 0.865984511742
#rank 200 Lambda = 0.085 MSE = 0.709501168484 RMSE = 0.842318923261
get_ipython().run_cell_magic(u'time', u'', u'rank=400\nnumIterations=30\nlambda_=0.085\nmodel = ALS.train(rat, rank, numIterations,lambda_)\npredictions = model.predictAll(test).map(lambda r: (r[0], r[1], r[2]))')
# In[7]:
te=test.collect()
base=sorted(te,key=lambda x: x[0]*1000000+x[1])
# In[8]:
pred=predictions.collect()
# In[9]:
t_=predictions.map(lambda x: (x[0], {x[1]:x[2]})).reduceByKey(lambda a,b: dict(a.items()+b.items())).collect()
t={}
for i in t_:
t[i[0]]=i[1]
s="userId,movieId,rating\r\n"
for i in base:
if t.has_key(i[0]):
u=t[i[0]]
if u.has_key(i[1]):
s+=str(i[0])+","+str(i[1])+","+str(u[i[1]])+"\r\n"
else:
s+=str(i[0])+","+str(i[1])+",3.67671059005\r\n"
else:
s+=str(i[0])+","+str(i[1])+",3.67671059005\r\n"
# In[12]:
text_file = open("lab10.csv", "w")
text_file.write(s)
text_file.close()
Мой опыт
Для себя отметил некоторые факты:
- Всегда надо внимательно изучать данные, не «забивать на пропуски», а стараться заполнять их близкими значениями. Например, средний рейтинг по выборке вместо пустых значений, существенно улучшил результат
- Округление результата (рейтинга) снизило точность предсказания, нежели длинный хвост
- Лучший вариант был рассчитан на всей выборке, без валидации. Был использован метод DoCrossValidation
- В идеале надо было построить график зависимости параметров (количества итераций и т.п) и результата RMSE. Двигаться к победе не в слепую, а зряче
- Apache Spark дает выигрыш по времени вычисления, так как оно идет на нескольких машинах. Если критично время — используйте спарк
- MyMediaLite вполне себе достойная библиотека, для небольших, не критичных по времени вычисления задач. Может себя оправдать, когда невыгодно поднимать кластер со спарком
Ах, если бы я знал все это раньше, стал бы победителем… Признателен за ваше мнение и советы друзья, сильно не пинайте…
Комментарии (9)


EvilsInterrupt
02.10.2015 11:53+1К картинке приложен вопрос «Попробуй выбери, какая из них лучше? :)». Конечно же вторая, если считать справа налево ;)



GrigoryPerepechko
Хм, и зачем это я зашел сюда…
Stepanow
Рекомендую четвёртую слева
Godless
И 6ю!
avorsa
дайте две! )