
Введение
Иногда возникает необходимость быстро сделать кастомную модель для детекции, но разбираться в специфике компьютерного зрения и зоопарке моделей нет времени. Так появился краткий обзор проблемы детекции, и пошаговый туториал для обучения и инференса модели YOLOv5 в сервисе Google Colab.
Архитектура
YOLOv5 относится к архитектуре One-Stage detector - подход, который предсказывает координаты определённого количества bounding box'ов с результатами классификации и вероятности нахождения объекта, и в дальнейшем корректируя их местоположение. В целом такую архитектуру можно представить в следующем виде:

Сеть скейлит исходное изображение в несколько feature map'ов с использованием skip-connection и прочих архитектурных фишек. Полученные карты признаков приводятся в одно разрешение с помощью апсемплинга и конкатенируются. Затем предсказываются классы и bounding box'ы для объектов, далее для каждого объекта выбирается самый вероятный bounding box с помощью Non-Maximum Suppression. Подробнее можно почитать на Medium. Да, статья на Medium про YOLOv4, но отличие v5 только в том, что v5 реализована на pytorch.
Реализация
За основу взят репозиторий ultralytics.
Установка
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txtСтруктура датасета
/dataset
--/images
--/train
--/valid
--/labels
--/train
--/valid
--dataset.yamlФайлы изображений и меток разделены по разным папкам, в корне лежит файл конфигурации yaml, который имеет следующий формат:
train: ../dataset/images/train/
val: ../dataset/images/valid/
nc: 1 # количество классов
names: ['class_0'] # имена классовРазметка
Разметка осуществляется в следующем формате:
Label_ID_1 X_CENTER_NORM Y_CENTER_NORM WIDTH_NORM HEIGHT_NORM
Для каждого изображения <image_name>.jpg создается файл <image_name>.txt с разметкой.
Значения для каждого bounding box'а вычисляются следующим образом:
X_CENTER_NORM = X_CENTER_ABS/IMAGE_WIDTH
Y_CENTER_NORM = Y_CENTER_ABS/IMAGE_HEIGHT
WIDTH_NORM = WIDTH_OF_LABEL_ABS/IMAGE_WIDTH
HEIGHT_NORM = HEIGHT_OF_LABEL_ABS/IMAGE_HEIGHTДля разметки можно использовать программу LabelImg.
Обучение
Обучение производится с помощью скрипта train.py с ключами:
--data, путь к датасету
--img, разрешение картинки
--epochs, количество эпох - рекомендуется 300-500
--cfg, конфиг размера s/m/l
--weights, стартовые веса
Существуют и другие настройки, о них можно почитать на странице проекта.
После обучения можно сохранить лучшую модель, которая расположена в ../yolov5/runs/train/exp/weights/best.pt
Инференс
Запустить модель можно несколькими способами:
Скрипта
detect.pyуказав веса модели и файл для детекцииTorch Hub:
model_path = '/content/yolov5.pt'
yolo_path = '/content/yolov5'
model = torch.hub.load(yolo_path, 'custom', path=model_path, source='local')
img_path = 'content/test.jpg'
results = model([img_path])Кастомная функция
predictна основеdetect.py, которую можно найти в репозитории.
from predict import predict
pred_list = predict(
weights=weights,
source=image,
imgsz=[1280, 1280]
)Результаты
Пример распознавания:

Видно, что есть и пропуски, и ошибки распознавания, но сетка училась на сотне примеров из поисковой выдачи гугла, так что с ростом количества данных должно расти и качество предсказания.
Заключение
Код для запуска и пример датасета доступен в репозитории на github. Исправления и дополнения приветствуются.
Комментарии (10)

maxood
13.09.2021 16:03Позвольте полюбопытствовать, почему yolov5? Под "v5" нет никакого смысла, кроме маркетинга. Почему не "v4", который настоящий?

kitaisky Автор
13.09.2021 16:18В тексте я указал, что отличие v5 только в реализации на pytorch. В названии использую v5 по названию авторского репозитория.

AlexeyAB
15.09.2021 18:26+1Несколько полезных ссылок:
Pytorch-YOLOv4 (Python):
Darknet (C/C++) cfg/weights - https://github.com/AlexeyAB/darknet#pre-trained-models
Pytorch-YOLOR (Python): https://github.com/WongKinYiu/yolor
nVidia Transfer Learning Toolkit (training and detection) for YOLOv4: https://docs.nvidia.com/metropolis/TLT/tlt-user-guide/text/object_detection/yolo_v4.html
OpenCV-dnn for yolov4.cfg/weights and yolov4-tiny.cfg/weights (Python): https://colab.research.google.com/gist/AlexeyAB/90d2203cda30e85030374cb91192ef81/opencv-python-cuda.ipynb
Сравнение на Microsoft COCO dataset:
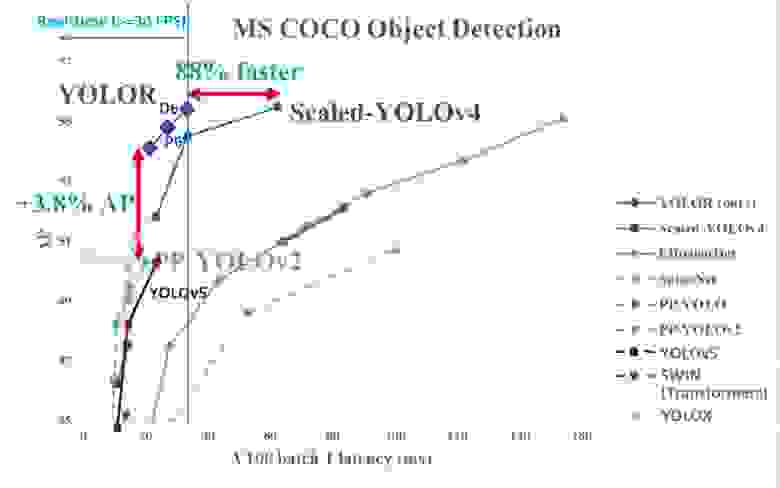
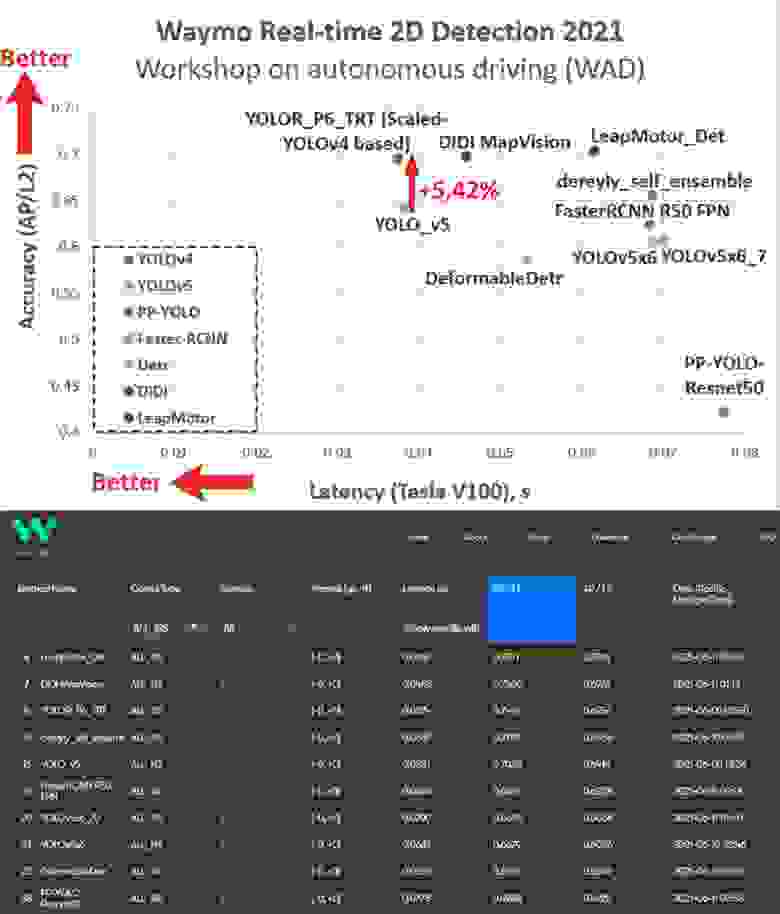
Сравнение на Waymo open dataset 2D (беспилотные авто): https://waymo.com/open/challenges/2021/real-time-2d-prediction/#



VPryadchenko
13.09.2021 16:31А при чем тут Colab?
В смысле, зачем делать на нем акцент в КДПВ и введении, если далее по тексту нет ни ссылок, ни туториалов конкретно касательно колаба, ни вообще чего бы то ни было релевантного?kitaisky Автор
13.09.2021 16:33По ссылке на репозиторий можно одной кнопкой запустить трэйн и инференс в колабе.

fuwiak
Вы уже запускали эту модель продакшене? Есть ли разница в качестве сравнивая со старыми вариантами YOLO?
kitaisky Автор
На проде крутится сейчас в качестве MVP, с другими yolo не сравнивал, но таких сравнений полно в интернете.
fuwiak
Я спрашивал про ваш опыт, другие benchmark смогу сам и найти.