

Сложный был год: налоги, катастрофы, бандитизм и стремительное исчезновение малых языков. С последним мириться было нельзя...
Upd. 04.12.2021 — Наш телеграм канал
На территории России проживает большое количество народов, говорящих более чем на 270 языках. Около 150 языков насчитывает менее 1 тысячи носителей, а за последние 20 лет 7 языков уже исчезло.
Этот проект — мои "пять копеек" по поддержке языкового разнообразия. Его цель — помощь исследователям в области машинного перевода, лингвистам, а также энтузиастам, радеющим за свой родной язык. Помогать будем добыванием параллельных корпусов, — своеобразного "топлива", при помощи которого современные модели все успешнее пытаются понять человеческий язык.
Сегодняшние языки — башкирский и чувашский, с популяризаторами которых я в последнее время тесно общался. Сначала я покажу как в принципе извлечь корпус из двух текстов на разных языках. Затем мы столкнемся с тем, что на рассматриваемых языках предобученная модель не тренировалась и попробуем ее дообучить.
Экспериментировать мы будем в среде Colab'а, чтобы любой исследователь при желании смог повторить этот подход для своего языка.
I. Извлекаем параллельный корпус
Для выравнивания двух текстов я написал на python'е библиотеку lingtrain_aligner. Код у нее открыт. Она использует ряд предобученных моделей, можно подключать и свои. Одной из самых удачных мультиязыковых моделей сейчас является LaBSE. Она обучалась на 109 языках. Так как соотношение текстов смещено в сторону популярных языков, то для них качество эмбеддингов (эмбеддингом называют вектор чисел применительно к данным, которые он описывает) будет лучше.
Colab
Попробовать извлечь корпус на нужном языке можно в этом Colab'e. Дальше пройдемся по шагам более подробно.
Установка
Установим библиотеку командой
pip install lingtrain_alignerПосле этого импортируем необходимые модули:
from lingtrain_aligner import splitter, aligner, resolver, metricsНаши тексты (возьмем для примера главу из Гарри Поттера) разобьем на предложения при помощи модуля splitter. Затем создадим файл с данными для выравнивания (sqlite база данных) и загрузим в нее полученные предложения. За это отвечает модуль aligner.
lang_from = "en"
lang_to = "ru"
db_path = "alignment.db"
splitted_from = splitter.split_by_sentences(text1.split('\n'), lang_from)
splitted_to = splitter.split_by_sentences(text2.split('\n'), lang_to)
aligner.fill_db(db_path, lang_from, lang_to, splitted_from, splitted_to)Для учета особенностей грамматики языка (например, особые виды кавычек, отсутствие пробелов и другая лингвистическая экзотика) нужно передать в splitter соответствующие параметры. Выровняем тексты при помощи следующей команды:
aligner.align_db(db_path,
model_name="sentence_transformer_multilingual_labse",
batch_size=200,
window=50,
batch_ids=[],
save_pic=False,
embed_batch_size=5,
normalize_embeddings=True,
show_progress_bar=True,
shift=0)После первичного выравнивания для каждого предложения на английском будет найдено лучшее соответствие на русском. Для поддержки длинных текстов выравнивание идет батчами (отрезками). Между батчами есть нахлест (параметр window). Поток второго текста можно двигать относительно первого (параметр shift). Более подробно о механизме выравнивания можно почитать здесь.
Визуализация
Посмотрим на результат помощи модуля vis_helper:
from lingtrain_aligner import vis_helper
vis_helper.visualize_alignment_by_db(db_path,
output_path="alignment_vis.png",
batch_size=500,
size=(900,900),
lang_name_from=lang_from,
lang_name_to=lang_to,
batch_ids=[],
plt_show=True,
show_info=False)
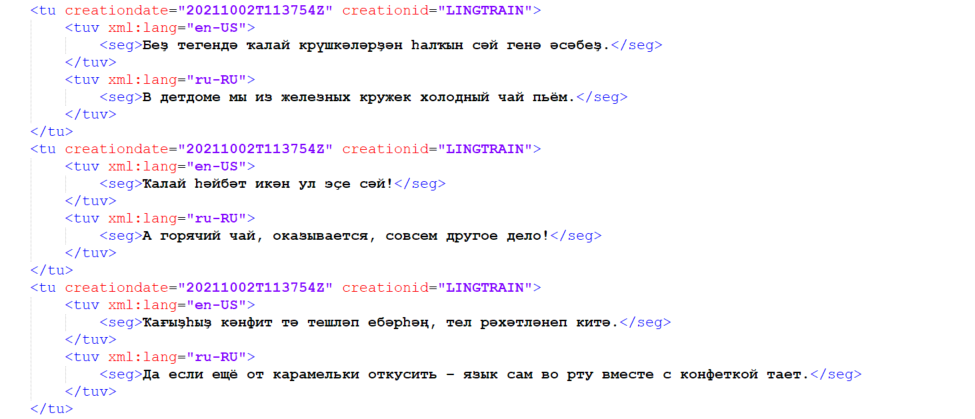
print("score:", metrics.chain_score(db_path))
Метрика
Для оценки выравнивания я придумал метрику, логика которой находится в модуле metrics. Она оценивает насколько связанной получилась цепочка выравнивнивания. Цепочка без разрывов должна иметь score = 1, случайный набор точек будет иметь score = 0.
Разрешение конфликтов
Количество предложений в текстах сильно различается. Это связано как со стилем конкретного переводчика, так и с особенностями конкретного языка (например, есть тенденция перевода сложных русских предложений несколькими на китайском). Чтобы это побороть, нам нужно в определенных местах склеить предложения либо первого текста, либо второго. Этим занимается модуль resolver. Он в несколько проходов разрешает найденные конфликты. Самые большие конфликты должны быть разрешены вручную, для этого есть UI, о нем ниже. В нашем же случае качество первичного выравнивания говорит о том, что все должно быть хорошо. Убедимся в этом, поставив все выпавшие строки на место.
steps = 3
for i in range(steps):
conflicts, rest = resolver.get_all_conflicts(db_path,
min_chain_length=2+i,
max_conflicts_len=6*(i+1),
batch_id=-1)
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
if len(rest) == 0:
breakПосмотрим на визуализацию:

Результат
Картинка красивая, но посмотрим на результат. Из базы можно выгрузить корпуса по отдельности или в формате TMX.
from lingtrain_aligner import saver
output_path="/content"
saver.save_plain_text(db_path, os.path.join(output_path, f"corpora_{lang_from}.txt"), direction="from", batch_ids=[])
saver.save_plain_text(db_path, os.path.join(output_path, f"corpora_{lang_to}.txt"), direction="to", batch_ids=[])
saver.save_tmx(db_path, os.path.join(output_path, f"corpora.tmx"), lang_from, lang_to)Отрывок из corpora.tmx:

Разрешив конфликты, мы из 344 предложений на английском и 372 на русском получили параллельный корпус из 332 строк. Как было сказано ранее, таким же образом можно выравнивать книги полностью.
Так как художественный перевод подчас граничит с искусством, то некоторые пары все равно нуждаются в дополнительной валидации. Все зависит от конкретного перевода. Кроме того, модель может ошибаться на коротких предложениях и предложениях с большим количеством названий и имен.
Иногда переводчик склонен даже "улучшить" оригинал. Например, в одном из переводов "Властелина колец" можно встретить такое описание:
Тень улыбки промелькнула на бледном, без кровинки, лице Боромира.И оригинал:
Boromir smiled.II. Fine-tuning для нового языка
Вернемся к малым языкам. Модель хоть и хорошая и из коробки "понимает" более ста языков, но с новым будет работать неудовлетворительно. Давайте попробуем.
Colab
Проделанные мной эксперименты и код вы можете посмотреть в этом Colab'e.
Башкирский язык
Попробуем выровнять рассказ "Батя Ялалетдин" Мустая Карима на башкирском и русском языках. Проделаем все те же действия, что и в первой части, получим следующее:

Видим, что качество значительно хуже, хотя и довольно неплохое. С чем это связано? С тем, что LaBSE была обучена в том числе и на небольшом корпусе татарского языка. Эти языки являются родственными и иногда можно получить перевод с одного на другой заменой некоторых букв.
Если мы сейчас запустим механизм разрешения конфликтов, то он, конечно же, отработает. Однако будет значительное количество некорректных разрешений. Так как нас это не устраивает, давайте разбираться как можно модель дообучить и улучшить качество корпуса.
Fine-tuning
Сначала вспомним, как Google изначально тренировал свою модель. Задачей, которую модель оптимизировала, был translation ranking task. Из заданного набора переводов нужно было найти самый корректный (картинка из статьи):

В обертке над моделью, которую я использовал (а это очень популярная и удобная библиотека sentence_transformers) есть набор loss'ов, которые примерно это и делают.
Сначала установим зависимости:
pip install transformers sentencepiece sentence_transformersСделаем импорт и проинициализируем модель:
from sentence_transformers import SentenceTransformer, SentencesDataset, losses
from sentence_transformers.readers import InputExample
from sentence_transformers.evaluation import SentenceEvaluator
from torch.utils.data import DataLoader
model = SentenceTransformer('LaBSE')Дообученную модель можно передать как параметр в методы выравнивания, так мы чуть позже и поступим.
Почитав документацию, я нашел несколько подходящих нам функций ошибок. Это MultipleNegativesRankingLoss, ContrastiveLoss и OnlineContrastiveLoss. В два последних необходимо передвать примеры с меткой 0 или 1. 1 — если пара строк является взаимным переводом и надо сблизить соответствующие вектора, 0 — если надо их растащить. MultipleNegativesRankingLoss работает похожим образом, по коду видно, что в этом лоссе для каждого примера из батча корректные переводы будут приближаться, а все остальные — отдаляться. Автор библиотеки порекомендовал использовать именно его, и в ходе экспериментов он действительно оказался эффективнее других.
Для дообучения нужно привести к необходимому виду свой датасет с парами переводов. Разумеется, перед обучением надо обратить внимание на качество датасета и почистить его. Для башкирского языка я пользовался данными, которые мне предоставили энтузиасты в лице Айгиза Кунафина и Искандера Шакирова. Это открытый русско-башкирский датасет.
train_examples = [InputExample(texts=[x['ba'], x['ru']], label=1) for x in train_dataset]
train_dataset = SentencesDataset(train_examples, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size)
train_loss = losses.MultipleNegativesRankingLoss(model=model)После этого можно обучать модель, делается это просто:
num_epochs = 3
warmup_steps = math.ceil(len(train_dataloader) * 0.1 * num_epochs)
model.fit(train_objectives=[(train_dataloader, train_loss)],
evaluator=evaluator,
epochs=num_epochs,
evaluation_steps=1000,
output_path=model_save_path,
save_best_model=True,
use_amp=True,
warmup_steps=warmup_steps)Так же можно в качестве evaluator'а передать свой класс. Он будет вызываться каждые evaluation_steps шагов, считать вашу метрику и рисовать графики. Я добавил класс ChainScoreEvaluator, который выравнивает и оценивает небольшие отрывки текста на рассматриваемых языках.

Так же надо заметить, что Colab хоть и бесплатный, но может выдавать недостаточно мощные для тренировки карточки. Это сказывается на размере батча и скорости обучения. В итоге я оформил подписку за $10 в месяц (примерно 750 рублей).
Улучшение
Дообучив в течение нескольких дней модель в Colab'e, получился следующий результат:

Такого качества уже хватает, чтобы более уверенно поставить на место выпавшие строки.

Чувашский язык
С чувашским языком все было гораздо сложнее, так как исходное качество было в разы хуже. Язык находится дальше от своих тюркских родственников, которые присутствуют в модели.

За датасет спасибо Александру Антонову, популяризатору чувашского языка. Русско-чувашский параллельный корпус можно найти здесь. В результате экспериментов удалось значительно улучшить качество:
Результат после автоматического разрешения конфликтов:

corpora.tmx

Чтобы вы смогли оценить качество этих моделей, я собрал Colab с их использованием. Преимущество Colab'а в том, что он предоставляет свои GPU, поэтому расчеты идут гораздо быстрее. В этом ноутбуке можно выбирать и другие языки, попробуйте.
Валидация
Отдельно скажу про проверку получившегося корпуса. Чтобы улучшить его качество, можно при помощи этой же модели посчитать расстояние между эмбеддингами (напомню, что это всего лишь вектор чисел соответствующий предложению) и отсечь самые далекие по смыслу пары.
Еще лучше привлечь носителей языка. Так поступили башкирские коллеги, написав бота, который дает на оценку пары предложений. Если владеете башкирским, то подключайтесь.
Обе модели можно попробовать здесь.
UI
Для ручного разрешения больших конфликтов и редактирования корпуса я написал UI. Подробнее о нем я рассказывал здесь, а выглядит он так:
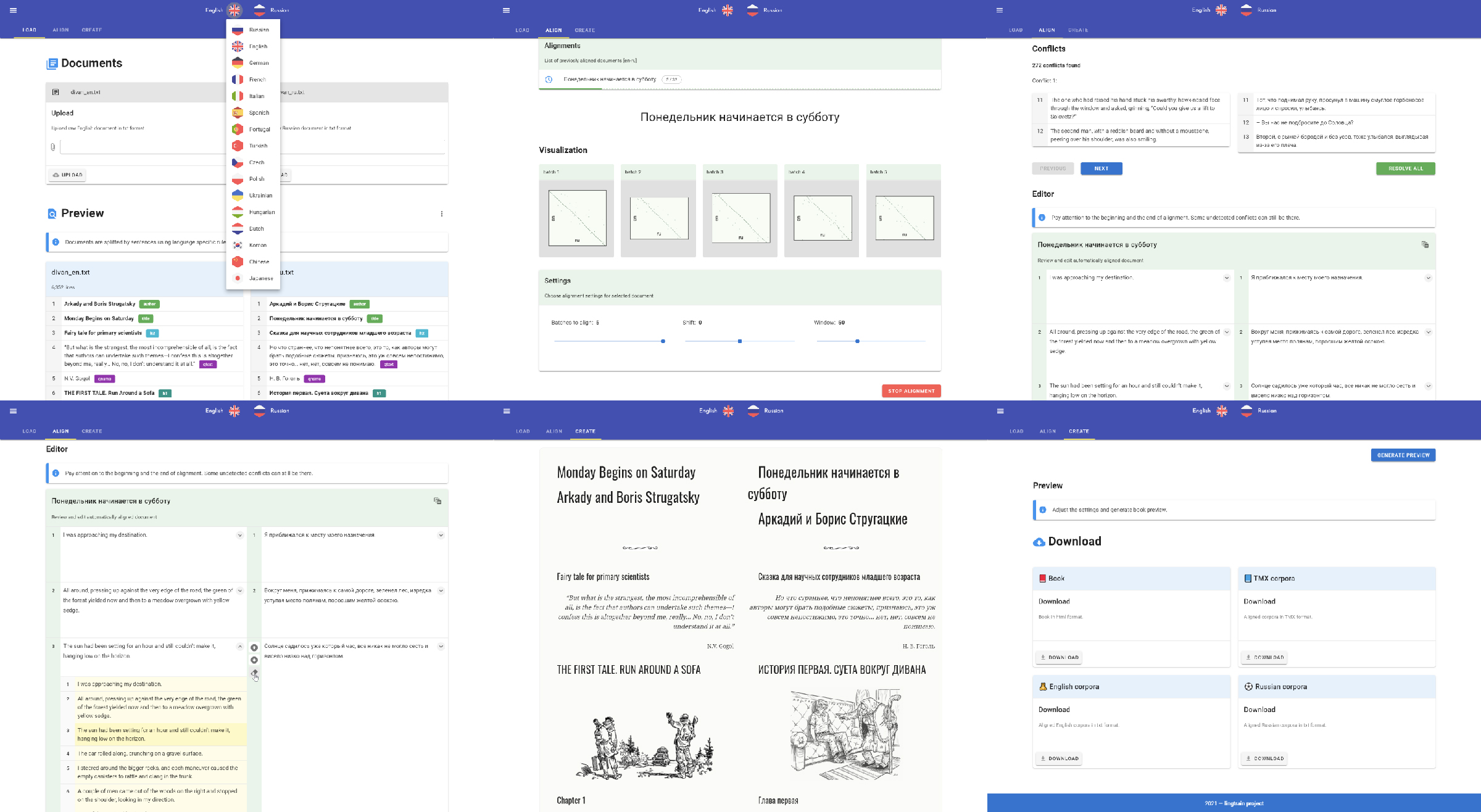
В нем можно не только выравнивать и редактировать корпуса, но и делать из них параллельные книги.
Идеи
Проделанные эксперименты наверняка не являются самыми оптимальными. Качество можно улучшить, если добавить в датасет данные того же стиля, документы на котором необходимо будет выравнивать.
Так же можно использовать тот факт, что родственные языки обладают схожей грамматикой и лексикой с точностью до символов алфавита. Возможно, что при замене, например, кириллических букв на латинские, качество дополнительно возрастет (для того же чувашского). Это тоже предстоит попробовать.
Если у вас какие-то идеи по этому поводу, то буду рад, если поделитесь.
И да, чуть не забыл, — кто угадает, что за языки обозначены на обложке статьи?
Ссылки
Комментарии (90)

AigizK
03.10.2021 16:54+5Сергею большое спасибо, за то что откликнулся и дообучил модель башкирского языка. Вообще мы давно занимаемся выравниванием текста, чтоб улучшить в первую очередь качество машинного перевода. Если раньше этим занимались несколько только человек, так как в ручном режиме выравнивать книги не очень удобно, со смартфона вообще не возможно. То теперь мы предварительно этим алгоритмом находим кандидатов, а потом в телеге люди через смартфон просто проверяют, на сколько перевод правильный. Сейчас к боту телеги подключены более 300 человек. Поэтому если кто то занимается такой же задачей, я думаю и Сергей и я сможем вам помочь.

SergioShpadi
03.10.2021 20:54+16Вполне вероятно, что меня заминусуют, но я все же задам свой вопрос. В чём ценность этих малых языков? Зачем вообще вкладывать силы в их поддержание? Особенно тех ста пятидесяти языков, которые насчитывают менее тысячи носителей?
Со столь малым количеством носителей у языка нет и не может быть никакого культурного пространства. А без культурного пространства язык - это просто кодировка. Можете сравнить объем и количество статей на Википедии почти по любой теме на английском языке и на русском, количество качественных книг по любой теме на Амазоне и на Озоне, и вы увидите насколько культурное пространство русского языка меньше, чем у английского. А количество носителей русского в мире - около 200 млн человек! А вы говорите про чувашский с 1 млн носителей и башкирский с 1.4 миллионами носителей.
В девятнадцатом-двадцатом веке произошел процесс объединения и унификации большинства диалектов каждого из языков - английского, французского, итальянского, немецкого, испанского, русского. Если раньше чуть ли не в каждом городе был свой диалект языка, то с приходом эры развития коммуникаций языки унифицировались и стандартизировались - частично благодаря усилиям государств, частично благодаря естественным процессам. Остались мелкие различия в диалектах вроде "тротуара"-"поребрика" и "подъезда"-"парадной", да и те скорее всего скоро вымрут. Культурное пространство языка в эпоху деревень и слабосвязных городов было разрозненным. В эпоху же, когда все смотрят одни и те же передачи по телевизору и ютубу, читают одни и те же тексты в интернете, культурное пространство языка едино и унифицировано. И это хорошо. По той же логике исчезновение малых языков - это тоже хорошо.
Зачем тратить силы на попытки реанимации трупов? Зачем тратить время на языки, на которых не издаются и не читаются книги, не пишутся и не читаются статьи, на которых даже в быту мало кто разговаривает? Чтобы разжигать националистические чувства малых народностей?

Squoworode
03.10.2021 22:31+4"тротуара"-"поребрика"
Бордюр же.
И сосули с сосисами.
vsviridov
03.10.2021 22:49+7<offtopic>
бордюр и поребрик это два типа укладки.
</offtopic>
tyomitch
04.10.2021 12:22+3https://ic.pics.livejournal.com/tyomitch/13074234/13849/13849_original.jpg -- а это что? Бордебрик?

DaneSoul
04.10.2021 14:40+1А вот на правой картинке он поребрик по все длине, включая ту часть где он вровень с плиткой, или только на участке с травой? ;-)

youngmysteriouslight
03.10.2021 22:51+4Хоть я тоже не понимаю, зачем искусственно неносителем пытаться воскресить неродной язык, именно на Ваши вопросы я вижу ответы.
Вы, кажется, исходите из того, что единственная цель языка — это создать канал для общения между людьми. Аналогия: вот есть локальная сеть, где узлы могут общаться между собой и ресурсы распространяются только внутри, а есть Интернет — единое пространство имён и адресов. При таком подходе Вы правы, нужно одно пространство.
В языке есть либо какие-то собственные уникальные свойства/возможности, либо сопряженные с определённой культурой, либо внешние по отношению к языку. Собственные свойства языка могут быть интересными, даже если на языке не говорит уже или ещё никто; это определённо повод над развитием этого языка работать. Например, в русском люди умеют двигаться; в английском люди двигаются менее осмысленно; с другой стороны, в английском есть система времён, а в русском она поломанная и убогая.
Если язык является предлогом (маркером, идентификатором) к культурному пространству: аналогиям, образам, идеям, взглядам, догматам, традиции, — то унификация невозможно ни в пространстве, ни во времени даже для одного языка (например, русский русских в Америке и в России, в современной, в СССР и в царской). Даже разные поколения и разные субкультуры оперируют разными образами. Вы говорите, что
В эпоху же, когда все смотрят одни и те же передачи по телевизору и ютубу, читают одни и те же тексты в интернете, культурное пространство языка едино и унифицировано. И это хорошо.
но это, во-первых, не так, люди читают то, что им интересно, а во-вторых, пространство не едино (вспомним хотя бы феномен падонкаффского языка). К тому же, я не считаю, что унификация — это всегда хорошо. Хотя я согласен с Вами, что логика применимо к малым языкам должна быть такой же, как в этом вопросе.
Так вот, с этой точки зрения ценность умирающего языка определяется глубиной (не количество, а качеством) умирающей культуры. Реанимировать язык без культуры? Зачем? Например, на хабре читаешь некоторые посты — написаны по-английски, хотя русскими буквами, русскими словами и с падежами. Язык как кодировка, да. А у других переводчиков люди двигаются и сотрудники без экспертизы.
Из внеязыковых свойств Вы отметили распространённость. Это не делает сам язык хорошим, сколько говорит о носителях и современном состоянии общества. Непопулярность не должна приниматься во внимание при оценке самого языка. Это всё равно, что сказать N-е лет назад, что никакая TypeScript не нужна, потому что все знают JavaScript; или сейчас сказать, что git — это хорошая система контроля версия, потому что она всеми поддерживается и все её знают, никакая другая нам не нужна. Хотя распространённость — это показатель, да.

VIPDC
04.10.2021 09:37+3Распестрённый язык живёт и развивается, совершенствуется, эволюционирует. Малые языки существуют, влачат существование.
Хороший пример Мальта. Да есть Мальтийский язык. Но даже местные на слабо разговаривают да и не все. Что бы поступить в госуниверситет Мальты надо сдать экзамены по нему, в итоге молодежь просто имея шенген уезжает на учёбу в Европу. Можно заставлять учить язык, но в итоге самые лучшие проголосуют ногами.
SergioShpadi
04.10.2021 10:02+6Сравнение с языками и инструментами программирования не совсем верное. Новые языки и инструменты призваны проще решить задачи, которые трудно решить на других языках. Естественные же языки в принципе решают одну и ту же задачу - передать информацию от человека к человеку.
Кроме того из-за простоты смены языка программирования по сравнению с естественным языком, процесс естественного отбора среди языков программирования идет гораздо быстрее. Основных языков осталось не так уж и много: JavaScript, Python, Java, PHP, C, C++, C#, Swift, Kotlin, Rust, Go и небольшое количество менее популярных вроде Scala, Haskell.
Кроме того, существует гипотеза лингвистической относительности Сепира-Уорфа, из верности которой следует, что передача сложной информации на английском языке будет гораздо качественнее, чем на чувашском.
Так вот, с этой точки зрения ценность умирающего языка определяется глубиной умирающей культуры
Какая глубина культуры может быть у малых языков? Они ведь умерли не просто так, а именно потому что не имели культуры, а поглотившая их цивилизация с другим языком её имела.
Я как-то был на фестивале местной культуры в мордовском селе в Пензенской области. Из культуры там были только красно-цветастые платья, которые в реальной жизни никто не носит, частушки на мордовском, которые в реальной жизни никто не поет, и пирожки с картошкой, не имеющие вообще никакой связи с мордовской культурой как таковой. Никаких всемирно известных произведений литературы уровня Достоевского, картин уровня Васнецова, никаких музыкальных произведений уровня Чайковского и никакого кино уровня Тарковского там не было, нет и никогда не будет.
Богатая культурная среда существует только у имперских языков, которые когда-то где-то были lingua franca - английского, французского, немецкого, итальянского, испанского, русского, китайского, арабского. Культура - это продукт жизнедеятельности городской цивилизации, а не деревенской. У малых деревенских народов культуры быть не может, ей неоткуда там появиться. До сих пор во всем мире чувствуется культурное влияние двух величайших цивилизаций античности - греческой и римской, и соответственно их языков - древнегреческого и латыни. Никакого влияния чувашской культуры мир не ощущает, да и о её существовании понятия не имеет.
Единственным исключением из правила, как мне кажется, является иврит и еврейская культура. Израиль никогда не был империей, а в период с II по XX век вообще не существовал. Иврит в это время был исключительно языком коммуникации между еврейскими диаспорами разных стран, на котором даже сами евреи не говорили в быту. Но тем не менее из-за популярности христианства древне-еврейская культура и язык сильно повлияли на европейскую культуры.

terentjew-alexey
04.10.2021 13:46-5Тот, кто знает, что он ничего не знает, знает больше того, кто не знает, что он ничего не знает.

INSTE
04.10.2021 15:16+1Ну таки Сычков писал многое в мордовских деревнях, да и Степан Эрзя тоже в целом существовал в международном масштабе (это я так, привел навскидку первое что вспомнил).

Ritan
04.10.2021 17:25+1Например, в русском люди умеют двигаться; в английском люди двигаются менее осмысленно
Беглое гугление не дало никаких результатов, а сам я не очень понимаю о чём здесь речь.
DaneSoul
04.10.2021 22:22+3Речь о большой вариативности и гибкости глаголов движения в русском языке:
ЕХАТЬ: приехать, уехать, заехать, переехать, подъехать…
И таких глаголов целый набор, каждая форма меняет смысл или нюансы смысла.
Это сильно впечатляет изучающих русский язык иностранцев.
Однако, я бы отметил, что большинство этих смыслов передается и в английском языке, но вместо изменения формы слова как в русском, там используются предлоги, формирующие с глаголом устойчивые выражения.Ritan
05.10.2021 16:15+1Теперь понятно, спасибо. Но ведь это действительно нельзя записать в значимые различия. Просто разные способы словообразования( синтетические/аналитические языки)

rumbleblowingaggregate
05.10.2021 00:38+1Видимо, имеется в виду однонаправленные и разнонаправленные глаголы движения в русском языке. Идти/ходить, вести/водить, поплавать/поплыть и тому подобные пары.

Flux
03.10.2021 23:09+1https://github.com/una-language/una-language — ваше?
В чём ценность этого малого языка? Зачем вообще вкладывать силы в его поддержание? 531 коммит в язык который с близкой к единице вероятностью никогда и никем не будет использован в проде. Что будет если сравнить сообщество этого языка и какого-то захудалого бейсика, не говоря уже про мейнстримные питоны/плюсы/жсы?Совершенно согласен с тем что языки-трупы не нужны, но неплохо бы самому соответствовать своим стандартам.
SergioShpadi
04.10.2021 09:21+8Ни в чем)
Это был интересный пет-проект по созданию языка с LISP-подобным синтаксисом на платформе JavaScript с добавлением значимой интендации а-ля Python. Проект принес мне море удовольствия, и я узнал много нового про внутреннее устройство JavaScript.
После завершения этого проекта я не вкладываю в него никаких сил. Его ценность для внешнего мира примерно нулевая. Для меня как творца он бесценен как мое лучшее произведение программистского искусства.

kryvichh
04.10.2021 03:51+4Язык - важная часть культуры народа. Нет языка - исчезает его культура - исчезает народ. Вы возразите: "а зачем нам все эти народы? Пусть будет один народ с одной культурой и унифицированным, математически выверенным языком." Кроме прочего, такому народу зашло бы всемирное правительство, им проще управлять, ставить перед ним великие цели и контролировать их исполнение... Чувствуете, как в этих рассуждениях мы движемся к антиутопии?

major-general_Kusanagi
04.10.2021 08:45+2А как быть тем разным народам у которых одинаковые языки? Например, на Балканах в бывшей Югославии такое часто встречается.

iberisoft
04.10.2021 10:44+1Говорящие на одном языке сербы и хорваты отличаются друг от друга вероисповеданием и историей в большей степени, чем русские и украинцы, имеющие разный язык. Так что не один язык все решает, хотя его фактор очень важен.
tyomitch
04.10.2021 12:47+1Сами югославы (не все, но существенная часть) считают, что у них разные языки.
kryvichh
05.10.2021 21:20+1Языки, как и культура народов в целом, развиваются по принципу биологических систем. Сиамские близнецы - это один организм или два? В биологии принято считать что два, даже если у них одно сердце на двоих.
Вообще, многие вещи из биологии применимы к человеческим языкам и культуре. Эволюция, естественный отбор, мутации, изоляция, биоразнообразие - вот это вот всё. Это говорит нам о том, что даже если в какой-то момент у цивилизации останется только один язык и культура, например, в результате катастрофы или геноцида, со временем они всё равно будут разделятся на диалекты, мутировать, отмирать и возрождаться. В противном случае это будет уже не человеческая и даже не земная цивилизация, какой мы её знаем.

anti4ek
04.10.2021 10:38+1"Нет языка - исчезает его культура - исчезает народ"
Самый наглядный пример - Австрия. Языка нет, а народ и культура - есть.

averkij Автор
05.10.2021 12:34+1У австрийцев язык, скажем, есть. Надо другой пример.
anti4ek
07.10.2021 08:30Нет, "Государственный язык — немецкий".
tyomitch
07.10.2021 09:58И что с того?
В Ирландии государственный язык ирландский, но на нём разговаривают 1.7% ирландцев, остальные -- на английском. В Беларуси на белорусском тоже разговаривает меньшинство (около четверти).
anti4ek
11.10.2021 08:48Опять мимо.
Как говорит немецкая вики, "это родной язык около 88,6% от австрийских граждан".
Т.е., повторюсь, нагляднейшая демонстрация того, что языка нет, а народ и культура есть.
tyomitch
11.10.2021 11:29Ну надо же, а на https://de.wikipedia.org/wiki/Bairisch написано "gesprochen werden die bairischen Dialekte hier von insgesamt etwa 12 Millionen Menschen im <...> größten Teil der Republik Österreich (ohne Vorarlberg)"
Расскажете, что родной язык для австрийцев хохдойч, а потом их переучивают на байриш? Ну-ну.
anti4ek
11.10.2021 12:20Т.е. вас не смутило слово "диалект"?
Язык - немецкий. Да, есть австрийский диалект немецкого языка. Но язык остаётся.
tyomitch
11.10.2021 14:01Т.е. вас не смутило, что в самом начале этой викистатьи написано "Die bairische Dialektgruppe wird von der Internationalen Organisation für Normung als eigenständige Einzelsprache klassifiziert"?
Слово Dialekte (это мн.ч.) в предыдущей цитате относится к диалектам именно баварского языка.
anti4ek
11.10.2021 16:58Нет, не смутило. "Официальный язык – немецкий. Имеющий достаточно характерное местное произношение и множество идиоматических оборотов, повседневный австрийский заметно отличается от "хохдойч" (литературного немецкого). Австрийские диалекты близки к баварскому Германии и немецкому Швейцарии, при этом локальные говоры прослеживаются практически повсеместно. Во многих районах присутствует свой характерный сленг, часто малопонятный даже соседям, но в общении местные жители все же стараются придерживаться "стандартного" языка. По разным оценкам его постоянно используют от 85 до 88% населения, но понимают практически все."(с)инет
Т.е. язык государственный немецкий, разговаривают на немецком, при этом присутствуют диалекты.
P.S. По моему скромному наблюдению, устойчивое нежелание признавать феномен Австрии, часто относится к области политических убеждений, совершенно не связанных с проблемой собственно языка.
tyomitch
11.10.2021 21:38Значит, сначала вы ссылались на неназванную статью девики, а когда оказалось, что в девики написано не это — то её авторитет сразу затмевает какой-то неназванный русский ресурс?
Устойчивое нежелание признавать байриш языком, даже когда международные организации признали — к какой области относится?
averkij Автор
11.10.2021 12:04Вас, наверное, смущает слово «немецкий». Типа раз не «австрийский», то нет своего языка.
DaneSoul
04.10.2021 14:55+1Язык — важная часть культуры народа. Нет языка — исчезает его культура — исчезает народ.
В США проживают представители сотен народов, которые повседневно общаются на едином английском языке и которые на этом языке совместно построили одну из самых влиятельных экономик мира и культуру (кино, игры, музыка и т.д.), которая понятна и любима практически во всем мире.

mikleh
04.10.2021 16:41+2Кроме прочего, такому народу зашло бы всемирное правительство, им проще управлять, ставить перед ним великие цели и контролировать их исполнение… Чувствуете, как в этих рассуждениях мы движемся к антиутопии?
Ну лично я чувствую, как в этих рассуждениях мы движемся к лучшему будущему, до которого человечество когда-нибудь все же дорастет.kryvichh
05.10.2021 21:11+1Слишком рискованно. Всемирное правительство будет единой точкой отказа для человеческой цивилизации.

ksr123
05.10.2021 00:55Понятие "народ" в современном мире очень размытое. С учетом ассимиляции, которая есть у всех народов.

Volkerball
04.10.2021 07:27+2объединения и унификации большинства диалектов каждого из языков - английского, французского, итальянского, немецкого, испанского
Появились литературные языки, которые преподаются в школах, типа хохдойч, но местные диалекты и по ныне вполне здравствуют, зачастую являются предметом гордости(или некоторого стыда) и части местной культуры. А человек такое существо, что ему важно чувство принадлежности к какой-то группе, и по возможности группе поменьше. Ну и диалект или язык помогает ему в этом.
На фоне других языков как раз становится заметно, что русскому языку очень сильно не повезло в части сохранения диалектов и говоров. Как бы не скатиться в лингвистический детерминизм, но возможно ли уничтожение диалектов внесло свой вклад в неразвитость и неухоженность российский регионов? Унифицированный язык это как советские микрорайоны - вроде бы как всё общее, а вроде и бы ничейное, нет чувства принадлежности. Да и даже в условиях России людям интереснее ездить в самобытные города со своей культурой и языком, нежели чем в безликий советский Новосибирск, к примеру.
P.S. Жителям НСКа: «В очередь, сукины дети, в очередь!»
AigizK
04.10.2021 09:46+1Интересная точка зрения. Это как жить в многоэтажке и требовать, чтоб ЖЭУ убирались и жить в частном доме и наводить порядок самому, так как чувствуешь ответственность.
DaneSoul
04.10.2021 15:00Унифицированный язык это как советские микрорайоны — вроде бы как всё общее, а вроде и бы ничейное, нет чувства принадлежности.
ИМХО, чувство принадлежности психологически связано с чувством собственничества и следовательно не возможно без чувства индивидуальности. А Советская власть отчаянно боролась с индивидуализмом в пользу «коллективизации» на всех уровнях и никакое языковое разнообразие бы тут ничем не помогло.
Yser
04.10.2021 08:42Я дополню ваши вопросы контекстом:
Зачем иметь национальность в стране, которая является федерацией только де-юре, а де-факто есть титульная нация с титульным же языком?
Зачем вообще иметь какие-то другие языки, если ЭГЕ сдается только на русском?
Зачем все вышепречисленное, если в Яндексу термин "россияне" имеет 13 млн упоминаний, а "русские" 91 млн.
П.С. и да, вы крайне мало, я бы даже сказал - ничего, не знаете о диалектах того же немецкого и их использовании.
Iisus2007
04.10.2021 08:42+4Мне кажется, что меня тоже заминисуют, ну ладно Думается мне, что это политический момент.
В последние 10 лет очень много НКО внезапно "озаботились" малыми языками в РФ. Под это дело вкачиваются большие средства. Цель ясна - заложить бомбу в мягкое подбрюшье РФ - Поволжье и потом подорвать. На Украине в далёких 90х всё так же начиналось. Технологии мягкой силы уже отработаны))
Причем так забавно слушать "малых" националистов. У них злой Путин навязывает им русский. В то же время молодежь мегаполисов РФ уже говорит на суржике руинглиша. Как бы нелогично, но люди ищут злодея, не понимая, что как вы верно заметили это мировая тенденция. И русского когда-то не станет. Мир придёт к 6ти мировым языкам. Это правильно.
Вместо замыкания на своем микрорегионе проще выучить русский, используемый на бСССР, английский - на весь мир и какой-нить язык программирования. Всё. Вот молодежь и "голосует ногами".
etoropov
04.10.2021 16:38+1Да, политический момент, к сожалению. "Язык - это диалект с армией и флотом". По описанным вами же причинам, французы в свое время боролись за единый французский (то есть, Парижский диалект), а испанцы - за единый испанский. Чем сильно подсократили численность говорящих на баскском, например. А баскский - вообще уникальный язык в Европе.
Короче, ужасно жаль, что малые языки попадают под раздачу в этой нашей политике. Насколько было бы круче, если бы государства гордились тем, какая у них богатая культура: 100 языков и 100500 диалектов.
AigizK
04.10.2021 09:28+13Ответа на вопрос "зачем нужны языки малочисленных народов?" у меня нет. Но относительно ваших доводов могу написать свои соображения.
1. В чём ценность этих малых языков?
Ценность для кого, для остальных? А почему должна быть ценность? Почему народ просто не может жить сам по себе? Говоря вашим же языком, можно утверждать: зачем нам старики, они уже ничего не производят, а государство им выплачивает просто так деньги.
2. Со столь малым количеством носителей у языка нет и не может быть никакого культурного пространства.
Если говорить про башкир, то нас больше миллиона и есть своя республика, сопоставимая по размерам с некоторыми странами. Культура у народа есть, она не утеряна, причем человек может не знать или плохо знать свой родной язык, но при этом культура эта его окружает и на него влияет.
3. Можете сравнить объем и количество статей на Википедии почти по любой теме на английском языке и на русском, количество качественных книг по любой теме на Амазоне и на Озоне, и вы увидите насколько культурное пространство русского языка меньше, чем у английского. А количество носителей русского в мире - около 200 млн человек! А вы говорите про чувашский с 1 млн носителей и башкирский с 1.4 миллионами носителей.
Всякие Википедии, книги на сайтах - это не показатель. Для примера русских 200млн, а статей всего 1,7млн, то есть 1 статья на 100 человек. А башкир 1,4млн, а статей в Вики 58тыс, т.е. 1 статья на 24 человека. Получается у башкир на человека выходит в 4 раза больше статей, но это же не означает что культура у башкира выше в 4 раза.
Вообще основная идея, из за чего я этим занимаюсь, как раз помочь оцифровать язык. Это включает в себя распознавание языка(STT), синтез речи(TTS), машинные переводы, языковые модели. Вот когда все это будет,
вот тогда и поговоримпоявятся дополнительные возможности по сохранению языка. Простой пример: дети сейчас с детства смотрят ютюб блогеров. Как правило это русскоговорящие блогеры. Кто мешает перевести их и озвучить на родном языке? У Яндекса же получилось ???? На самом деле инструменты, которые позволят это сделать, они все ближе и доступнее.А вы говорите про чувашский с 1 млн носителей и башкирский с 1.4 миллионами носителей.
Как русские могут понять славянские языки, так и башкиры понимают тюркские языки. А носителей тюркских языков более 180млн, почти сопоставимы с русскими. Так что здесь у нас даже появляется преимущество перед русскими, так как живя в РФ мы знаем и русский.
В девятнадцатом-двадцатом веке произошел процесс объединения и унификации большинства диалектов каждого из языков
Да, даже сейчас в РФ есть "силы", которые направлены на то, чтоб оставить только русский язык на территории РФ. Но не знаю почему, но в области машинного обучения в последнее время очень много работ направлено на сохранение языков малочисленных народов. Проявляется это в создание мультиязычных языковых моделей(BERT от гугла, есть аналоги у ФБ, даже Сбер что то анонсировал, но пока не выпустил), мультиязычных переводчиков(это направление вообще активно развивается, сам участвую в проекте, где переводят с тюркских языков на русский и английский). Поэтому можно предположить, что маятник теперь двигается в другую сторону. Пока в РФ это не чувствуется, но кто знает, что будет через 10 лет.
В теории может получиться так, что если твой язык оцифрован, то тебе не надо будет изучать другие языки совсем. Новые модели машинного перевода голоса в голос могут произвести революцию. А может Илон Маск доработает свой чип, тогда даже сложно представить, какие возможности откроются.
Зачем тратить силы на попытки реанимации трупов? Зачем тратить время на языки, на которых не издаются и не читаются книги, не пишутся и не читаются статьи, на которых даже в быту мало кто разговаривает? Чтобы разжигать националистические чувства малых народностей?
Можно тут привести пример с языками программирования, что их много и почему то программисты все еще не перешли на один язык(Esperanto#).
А можно еще сказать так: вот так получилось, что сейчас есть такие языки. Какие то исчезли, какие то нет, а некоторые еще и сопротивляются. Почему? Я не знаю. Но я же в свободное от работы времени трачу свои силы. И таких как я много. Значит этот язык еще не труп, а старается всеми силами выжить. И я очень благодарен @averkij за этот проект, @snakers4 за то что сделал для нашего языка синтезатор речи. Никакого отношения к башкирскому языку они не имеют, но зачем то нам помогают. Бесплатно. И не только нашему языку.
major-general_Kusanagi
04.10.2021 09:52+2В чём ценность этих малых языков?
Говорящие с ветром?
А ещё всяким археологам и лингвистам полезно при расшифровке найденных надписей.averkij Автор
12.10.2021 11:09+1Слышал еще байку про неграмотных радистов во время войны, которые передавали слова с ошибками и это тоже усложняло дешифровку, если данные перехватывали.
BigElectricCat
04.10.2021 10:08-2"подъезда"-"парадной"подъезд — место на границе дома, куда привозят инвентарь, расходные материалы, еду. Характеризуется удобным подъездом большого транспорта и удобным доступом в подсобные помещения.
парадное — место на границе дома, где хозяин дома торжественно встречает гостей.
PS: Про поребрик и бордюр вам уже нарисовали, а то что вы привыкли жить в гробах, не говорит о том, что остальные забыли что и для чего нужно.
major-general_Kusanagi
04.10.2021 10:13+1В городе, где я живу есть пара старых домов, где есть и парадная и подъезд. В парадную — вход с фасада, а в подъезд — вход со двора. Большинство же жилых домов, давно уже не имеет парадную, а только подъезд.

yulai-b
04.10.2021 10:19+4Как носитель башкирского языка, поддерживаю обеими руками.
Совершенно ни к чему иметь множество кодов для выражения одного и того же смысла.

almaz1c
04.10.2021 10:55С подобной логикой любой язык, кроме английского и, наверное, китайского можно вычеркнуть из списка живых. Все равно ведь
русский/французский/немецкий/какой-угодно язык прирастает за счет англицизмов. Кринж, хайп, доктор, директор, камрад, детектор, машина, генератор, чатиться, лайкать, свайпать и т д....
terentjew-alexey
04.10.2021 11:12+1Не желаю Вас не коим образом обидеть, но, простите, Ваши вопросы говорят о скудности знаний и поверхностном мышлении.
Прочитайте первую попавшуюся поэзию. Как бы ее прочитали вслух? Что передает та или иная интонация? Вы можете запрограммировать или обучить машину чувствам?
А лингвистикой Вы занимались? Вы чувствовали момент озарения от того, когда понимали суть слова, не поверхностный слой (информационный), а нечто глубже, что-то что идет из глубин времени, времени когда формировалось то или иное определение, смысл, или же двойной, тройной подтекст, что уловим лишь носителю языка?
То же и с языками, неважно какими. Язык это живой организм, который живет и развивается вместе с его носителями. И в нем есть то, что можно назвать душой (материалистам привет), то чего не закодируешь в 0 и 1.
И если учесть мною выше сказанное, то Ваша аналогия с трупами, вообще оскорбительна и непозволительна, если еще можно возможно взывать к совести.
Newbilius
04.10.2021 11:53+7Язык это живой организм, который живет и развивается вместе с его носителями.
Ваша аналогия с трупами, вообще оскорбительна и непозволительна
Ну ведь и вы же называете язык "ЖИВЫМ организмом". Следовательно, как и любой другой организм, язык смертен. Выражение "мёртвый язык" не спроста существует. А значит и слово "труп" к подобному языку вполне применимо. В чём оскорбление?
И если продолжать аналогию с живым организмом, то исчезающие языки ещё не мертвы. Они скорее подобны живому, но сильно больному существу, подключенному к системе искусственного жизнеобеспечения. И, если продолжать аналогии, мы можем в дискуссии прийти к очень непростому вопросу об эвтаназии...
Только вот беда - все эти аналогии только удаляют нас от обсуждения вопроса целесообразности поддержки исчезающих языков ;-)
terentjew-alexey
04.10.2021 12:50+1Я с Вами отчасти согласен.
Оскорблением я считаю потребительское отношение к поднятому вопросу, и попытка обобщения.
Как может судить и предлагать к обсуждению вопрос о необходимости, о целесообразности и смысле существования того или иного объекта, человек не относящийся к делу.
По аналогии: чиновники и реальные дела на месте, люди дела и обсуждение ими геополитики.
По этому и считаю, что обобщение, решение за других, это неуважительно отношение.
Целесообразность и смысл тех или иных мероприятий - дело личное, с учетом интересов окружающих. Не нам это решать.

agmt
04.10.2021 12:28+1Как бы ее прочитали вслух? Что передает та или иная интонация?
А где автор статьи занимается интонацией/произношением?terentjew-alexey
04.10.2021 13:05Вопрос в комментарии поставлен про целесообразность языка. То что это культура конкретного народа, как будто никого не интересует.
Пример с поэзией приведен для указания на глубину культурного слоя и его значения в сознании народа. Автор же занимается тем, что ему интересно и что он считает важным и может помочь, в общем случае народу, а не языку.
tyomitch
04.10.2021 12:28+4А зачем защищать вымирающих животных? В чём ценность последней сотни диких амурских тигров, зачем вкладывать столько сил в их защиту от браконьеров?
terentjew-alexey
04.10.2021 13:08+1Каждый сам за себя определяет ценность того или иного явления. Вам так не кажется?
Если Вы не смогли себе ответить на данный вопрос, это не значит что другие для себя не ответили.

FedorovDimulya
04.10.2021 16:53Как минимум-разнообразие и богатство некое, после того, как исчезнет последний представитель вида/носитель языка- все, конец, больше никогда этого не будет

mao_zvezdun
04.10.2021 12:32+1В чём ценность этих малых языков?
Ценность малых языков в том, что они есть. Ценность мёртвых языков в том, что они были. Это материал лингвистам для исследований, и чем материала больше (сохранилось) тем интереснее в этом разбираться.

VMarkelov
06.10.2021 22:47+1Относительная ценность малых языков есть, например, в том, что они могут содержать полезную информацию об окружающей среде. Люди, жившие в какой-то области со своим языком могут иметь в языке вещи, которые отсутствуют в "имперских" языках и тем самым можно потерять часть информации. Понятное дело, что эту информацию, в теории, можно снова найти, но это время и не всегда кому-то надо. Хотя, это больше голос "за" ради сохранения малых языков, а не их возрождения.
Подробности о возможной потере важной информации можно почерпнуть тут: https://www.pnas.org/content/118/24/e2103683118




AlePil
03.10.2021 22:55+3В девятнадцатом-двадцатом веке произошел процесс объединения и унификации большинства диалектов каждого из языков - английского, французского, итальянского...
эммм... нет. я не могу сказать про русский, но в итальянском и французском точно нет. Более того, в итальянских последнее время есть устойчивый тренд на развитие диалектов и на придания им статуса отдельных языков (неаполитанский как пример).

etoropov
04.10.2021 16:50Его цель — помощь исследователям в области машинного перевода, лингвистам, а также энтузиастам, радеющим за свой родной язык. Помогать будем добыванием параллельных корпусов, — своеобразного "топлива", при помощи которого современные модели все успешнее пытаются понять человеческий язык.
А можно побольше контекста проекта, пожалуйста. Чем полезно иметь параллельные корпусы для сохранения языка? Я так понял, что эти методики работают, если язык имеет большой набор печатных материалов? Какие еще IT-проекты могут быть полезны / чем можно помочь этому проекту не-носителям языка?
AigizK
04.10.2021 19:17+1И да, и нет.
Когда у вас много книжек переведенных на другой язык, у вас по сути есть готовый корпус параллельных предложений. От 1млн предложений можно получить более менее приемлемый машинный перевод. В этом смысле языкам, у которых нет книжек или были, но допустим алфавит поменяли и теперь надо из одного алфавита перевести на другой, а заняться этим некому, не повезло.
Но с другой стороны сейчас выяснили, что вроде бы у языков есть что то общее. И когда обучают языковую модель для одного языка, потом можно использовать эту модель(или предыдущие слои этой модели) и дотренировать на корпусе другого языка. И это работает.
В случае с языками из одного семейства это вообще хорошо работает. Например мы обучали мультиязычный перевод с тюркских на англ и рус. Использовали корпус башкирского-русского в размере 500K+, еще какие то другие и якутский где то 9K. Понятно что с 9K машинный переводчик не сделаешь. Но из за того что в корпусе, которую мы использовали были и другие языки, качество перевода с якутского на русский был почти на том же уровне, что и с башкирского на русский.
Чем могут помочь не ночители. Как правило созданием инструментов. Например у нас есть корпус аудио+текст на сайте CommonVoice. Это 5Gb, 247 часов аудио(https://commonvoice.mozilla.org/ba/datasets). Можно на основе него создать модель распознавания речи.
Или можно используя монокорпус башкирского языка и создать спелчекер, суммаризацию текста и т.п.

le2
05.10.2021 05:53+3В игре Civilization V — Аттила — предводитель гуннов, говорит на современном чувашском языке (посмотрите видео). Это не очень научно, но это ближайший язык.
Городское население Чехии 200 лет говорило на немецком. Потом с распадом Австро-Венгрии язык реанимировали буквально за три года и использовали для во внутриэлитных войнах, как сейчас сами-знаете-где. Вы против чешского языка?
Немецкий язык — синтетика высоколобых интеллектуалов. Ему триста лет и часть немцев впервые его учит в школе, потому до сих пор в семьях говорят на швабских и прочих диалектах. Про большинство прочих языков такое же можно сказать. Англичане не могут читать Шекспира в подлиннике. Посмотрите советские фильмы 30х годов, как актеры говорят? Они говорят не на родном языке, а вызубрили фонетически по-бумажке, типа «я вас боюс» — отстутствуют мягкие знаки и прочие необычности — тогда государство формировало стандарт для радио, а потом для Первого канала ТВ.
Из полезного применения чувашского-башкирского (помимо права человека) — культурное, экономическое взаимодействие с тюркоязычными странами (200 млн людей). Им гораздо легче выучить родственный язык. Наверное также полезно спецслужбам для подготовки шпионов.averkij Автор
05.10.2021 10:08Про немецкие и прочие диалекты согласен. Знаю, что в Германии есть переводчики с нижненемецкого (Niederdeutsch) на обычный (Hochdeutsch). За факт про Цивилизацию — спасибо.
tyomitch
05.10.2021 15:21+1Наверное, стоит отметить, что Niederdeutsch -- потомок древнесаксонского и относится (вместе с английским) к другой подгруппе германских языков, нежели Hochdeutsch. И заодно -- что диалекты на большей части территорий Германии, Австрии и Швейцарии не имеют отношения к Niederdeutsch, но от официального языка своих стран (Hochdeutsch) отличаются столь же сильно.
.png")
https://commons.wikimedia.org/wiki/File:Deutsch-Niederländischer_Sprachraum_(nach_Werner_König).png

Foduch
11.10.2021 13:22+1Посмотрел на ютубе озвучку Аттилы, да он говорит на чувашском, но ударения на столько неправильно расставили, что даже я как носитель не с первого раза понял все фразы. Так что важен не только текстовый перевод, но и постановка ударений.
.png")
{kind=link}

CyaN
05.10.2021 09:57Чувашский язык сам по себе интересен. Например, тем, что там нет слова "да". Да и диалектов минимум 3 существует. В общем, малым языком его назвать - некорректно, все-таки, 5-й по численности народ в России.
Малые языки - это, например, чукотский, эвенкийский, etc. Вот для них сохранение языка действительно актуально.
tyomitch
05.10.2021 14:58В общем, малым языком его назвать - некорректно, все-таки, 5-й по численности народ в России.
По результатам переписи 2010, по числу владеющих им россиян (0.73%) чувашский уступает русскому, английскому, татарскому, немецкому, чеченскому, башкирскому и украинскому.
averkij Автор
06.10.2021 10:53Когда жил в Якутии, то якутский язык тоже не смог бы назвать малым. Он там живее всех живых и мирно сосуществует с русским. А сейчас смотрю, в масштабах страны действительно малый язык, даже поизучать захотелось.
nikolay_karelin
Дообучение тоже было на Colab?
averkij Автор
Да, все там делал. Он отваливается периодически, но в целом довольно удобно (когда другого варианта все равно нет).
TiesP
kaggle.com
averkij Автор
Ну это тот же Colab. Я имел в виду, когда своей карты нет.
TiesP
Не то же самое, ведь он не «отваливается»)… просто там ограничение на кол-во часов GPU в неделю. Чтобы быть точным — на kaggle проработает больше времени непрерывно, чем на colab (по моим ощущениям)
averkij Автор
Тут согласен. С другой стороны, на колабе v100 и a100 выпадают на самой платной подписке.