
ВНИМАНИЕ! В статье есть примеры текстов, содержащие мат и грубые выражения. Мы ни в коем случае не хотим оскорбить наших читателей, все подобные тексты приведены лишь в научных целях в качестве примеров токсичности в реальных текстах из Интернета.
Всем привет! Меня зовут Дарина Дементьева, я являюсь аспиранткой в Сколковской лаборатории обработки естественного языка (Skoltech NLP), где занимаюсь исследовательскими проектами совместной лаборатории Skoltech NLP и MTS AI. В рамках работы в совместной лаборатории мы провели серию исследований, посвященных важной социальной проблеме – борьбе с токсичной речью в Интернете или детоксификации текстов.
В этой статье мы расскажем про результаты исследований методов детоксификаций для русского языка. Эта работа была опубликована и презентована на конференции Диалог, а также принята в журнал MDPI. Результаты экспериментов на английском языке приняли для презентации на одной из ведущих конференций в области обработки естественного языка EMNLP. Мы представляем вам краткую выжимку с описанием моделей, постановкой и результатами экспериментов, а в конце вы сможете самостоятельно ̶п̶о̶м̶а̶т̶е̶р̶и̶т̶ь̶с̶я̶ ̶в̶ ̶ч̶а̶т̶е̶ протестировать модели в бою. Теперь – добро пожаловать под кат!
Мотивация
Начнем с того, где вообще может пригодиться детоксификация текстов.
Use Case 1: Подсказка пользователю «на эмоциях».
К сожалению, за долгие годы существования интернет стал местом с большим количеством токсичного и обидного контента. Споры в комментариях часто перерастают в перепалки с грубостями и матами. Поэтому многие социальные сети уже сейчас пытаются бороться с подобным контентом:
— Facebook уже тестирует модели, которые будут обнаруживать разжигание словесных перепалок в группах;
— Instagram представил фичу, которая фильтрует оскорбительный контент;
— VK внедрил фичу, которая взамен матерных слов в сообщении предлагает отправить стикер.
Одним из решений борьбы с токсичным контентом может стать предупреждение пользователя о намерении опубликовать оскорбительный контент и рекомендация более нейтрального детоксифицированного варианта его сообщения.

Use Case 2: Цензор для чатботов.
Уже случалось, что кроме людей источником вопиющей токсичности становились чат-боты. Например, резонансный случай произошел с ботом от Microsoft TayTweet, который от бота, любящего людей, прошел путь до настоящего нациста. Сейчас компании относятся более аккуратно к обучению своих ботов. Чтобы предотвратить такие казусы, здесь также могла бы помочь детоксификация текстов.

Данные
Для русского языка существует несколько непараллельных датасетов для классификации токсичности в текстах. Мы взяли два таких корпуса из соревнований на Kaggle [1, 2], и объединили их в единый RuToxic датасет, состоящий из 163187 сэмплов – 31407 (19%) токсичных и 131780 нетоксичных – из таких социальных сетей как Одноклассники и Пикабу.
Методология
Теперь – о методах. Мы протестировали пару простых бейзлайнов и две более сложные модели – detoxGPT, основанный на предобученной ruGPT модели, и condBERT, который основан на BERT архитектуре. Ниже приводим подробное описание каждого метода.
Бейзлайны
Delete. Этот бейзлайн основан на простой идее, позаимствованной из СМИ: часто можно увидеть, как матерные слова «запикиваются» во время телепередач или закрываются звездочками в статьях. По такому же принципу, мы «скроем» маты – удалим их из сообщения. Для этого мы собрали словарь наиболее встречаемых ругательств (но он, конечно же, не исчерпывающий – очень тяжело соревноваться с богатством русского языка). Токенизируя и приводя к леммам при помощи UDPipe, мы удаляем найденные в словаре токены из поступившего на вход токсичного предложения.
Retrieve. Другой бейзлайн основан на гипотезе, что если взять большой корпус нетоксичных текстов, то в нем можно будет найти нетоксичные предложения, в какой-то мере похожих по содержанию на оригинальное токсичное. Мы взяли предложения из нетоксичной части датасета RuToxic и искали предложение с наименьшим расстоянием по векторным представлениям к токсичному запросу. Для получения векторных представлений текстов мы усредняли векторные предложения слов, полученные из fasttext модели от RusVectores. В качестве расстояния между векторами мы использовали косинусное.
detoxGPT
GPT-2 [3] – это мощная языковая модель, которая может быть адаптирована к широкому кругу seq2seq задач NLP с использованием достаточно небольшого набора обучающих данных. До недавнего времени таких моделей для русского языка не было. Осенью 2020 года для конкурса AI Journey были представлены модели ruGPT3, способные генерировать последовательные и понятные тексты на русском языке. Мы протестировали эти модели для нашей задачи. Для этого мы использовали несколько сценариев:
- zero-shot: модель берется «из коробки» как есть (без дообучения). Входные данные представляют собой токсичное предложение, которое мы хотели бы детоксифицировать, с префиксом «Перефразируй» (рус. Paraphrase) и суффиксом «>>>» для обозначения задачи перефразирования. ruGPT3 уже обучен этой задаче, поэтому сценарий аналогичен выполнению перефразирования.
-
few-shot: модель также берется «из коробки» без изменений. Однако в отличие от предыдущего сценария мы подаем на вход модели префикс, состоящий из параллельного набора данных токсичных и нейтральных предложений, в следующей форме: >>> . Эти примеры должны помочь модели понять, что нам требуется решить задачу детоксификации, а не просто перефразирования. За параллельными предложениями следует снова входное предложение, которое мы хотели бы детоксифицировать, с префиксом «Перефразируй» и суффиксом >>>.

fine-tuned: модель дообучается на наборе параллельных данных. То есть, на вход модели для обучения подаются примеры по типу >>> . Далее на вход модели подается предложение для детоксификации в том же формате, что и в предыдущих пунктах.
Модель GPT, способную решать задачу переноса стиля с токсичного на нетоксичный, мы назвали кодовым названием detoxGPT. Да, главным недостатком этого метода является параллельный корпус данных – он очень редко существует для задач переноса стиля для текстов. Мы собственноручно разметили 200 предложений, случайно выбранных из датасета RuToxic, сделав для них параллельные детоксифицированные версии. Параллельный датасет получился небольшой, но даже после дообучения на таком корпусе данных из 200 предложений, модель уже может решать поставленную задачу. А собрать такой корпус из нескольких сотен параллельных пар не занимает много времени.
Мы потестировали несколько моделей из семейства ruGPT3: small (125 млн параметров с контекстом 2048), medium (350 млн параметров с контекстом 2048) и large (760 млн параметров с контекстом 2048).
condBERT
BERT (Bidirectional Encoder Representations from Transformers) [4] – это языковая модель, которая была обучена предсказывать пропущенные слова по остальной части предложения. Хотя BERT в основном используется для получения векторных представлений слов или задач маркировки последовательностей и классификации текста, его также можно использовать в сценарии заполнения пробелов в предложении, то есть для извлечения слова в контексте, который был заменен токеном [MASK].
Чтобы сделать BERT пригодным для задачи переноса стиля, нам нужно изменить модель так, чтобы маскирование и замена слов изменяли стиль входного предложения. Это можно сделать с помощью дообучения BERT на корпусах, специфичных для исходного и целевого стилей, чтобы модель запомнила распределения слов в соответствии с нужным стилем, и выполняла нужные замены.
Чтобы модель знала, какие именно токены в предложении считать токсичными и для каких надо искать замену, можно приписать токенам словаря BERT-а оценку токсичности. Для этого мы обучили небольшую модель – логистическую регрессию – и приписали ее коэффициенты к каждому токену словаря, назвав «уровнем токсичности».
Этого шага уже достаточно, чтобы использовать модель для переноса стиля. Но BERT все еще может не очень удачно делать замены, так как изначально модель не обучена на замены [MASK] на нетоксичные токены. Чтобы это исправить, модель можно дополнительно дообучить на корпусе текстов, причем этот корпус может быть непараллельным, как вышеописанный датасет RuToxic.
Модель BERT, которая способна решать задачу замены слов, отвечающих за один стиль в предложении на новый стиль, мы назвали condBERT. Преимущество condBERT по сравнению с методом на основе GPT заключается в том, что он не требует никаких параллельных данных для дообучения. Кроме того, предложение не переписывается полностью, что может быть лучшей стратегией с точки зрения сохранения содержания предложения.
Общая идея работы condBERT изображена на картинке:
Для модели condBERT мы также попробовали пару сценариев:- zero-shot, где BERT был взят из коробки без дополнительного дообучения;
- fine-tuned, где BERT был дообучен на RuToxic датасете для запоминания отношения слов к тому или иному стилю, как было описано выше.
В качестве модели BERT для русского языка мы также попробовали два варианта:- Conversational RuBERT от DeepPavlov;
- Уменьшенная версия мультиязычного BERT для русского языка от Geotrend.
Оценка переноса стиля
Как было сказано ранее, результат переноса стиля должен соответствовать трем критериям: 1) стиль действительно поменялся на требуемый; 2) основной смысл текста сохранен; 3) новое предложение звучит естественно и, в основном, грамматически корректно. Согласно этим критериям мы и подберем соответствующие метрики для оценки работы наших моделей.
Точность переноса стиля
Для того чтобы проверить, изменился ли стиль предложения, мы использовали классификатор токсичности. Для этого мы дообучили RuBERT модель на RuToxic датасете, получив F1 меру 0.83. Да, модель не идеальна, но ее точности достаточно для использования для оценки переноса стиля. Поскольку мы хотим выполнить задачу детоксификации, ожидаем, что результаты моделей будут нетоксичными. Мы вычисляли необходимую точность переноси стиля (Style Transfer Accuracy, STA) на основе этого предположения.
Сохранение контента
Мы подошли к оценке сохранения контента с двух сторон. Сначала мы оценили метрики, основанные на n-граммах:
1) униграмное перекрытие слов (Word Overlap, WO) между токенами исходного предложения Х и результатом Y: ;
;
2) BLEU, которая отображает точность по n-граммам для n от 1 до 4.
Кроме этого, мы посчитали косинусное расстояние (cosine similarity, CS) между векторными представлениями входного и выходного предложения. В качестве векторного представления предложения мы брали среднее значение векторных представлений его токенов, извлеченных с помощью модели fastText из RusVectores.
Качество языка
Для оценки качества языка сгенерированного предложения мы использовали перплексию (perplexity, PPL), полученную из модели ruGPT2Large, которая не участвовала в экспериментах.
Агрегирующая метрика
Чтобы иметь возможность сравнить все модели по какому-то одному числу, мы агрегировали все вышеперечисленные категории метрик в одну общую метрику, которая вычисляется как геометрическое среднее (geometric mean, GM) между STA, CS и 1/PPL:
Результаты
Представляем таблицу с результатами экспериментов:
Здесь красным цветом выделены методы, которые выпали из соревнования из-за слишком плохого сохранения контента. Жирным цветом отмечены лучшие результаты, а жирным и подчеркнутым – самые лучшие в своей категории.
Некоторые результаты получились ожидаемыми. Метод Retrieve очень хорош в плане получения финального нетоксичного стиля в предложении, но по сохранению токенов в предложении он абсолютно провалился. Хотя бывают случаи, когда попадание в контент почти стопроцентное!
Хотя метод Delete далеко не всегда мог простым удалением ругательных слов сменить стиль, он изменяет исходное предложение незначительно, поэтому хорошо сохраняетстя контент. В итоге, результат детоксификации с использованием этого метода может быть вполне приемлемым.
Из detoxGPT модели не все сработали хорошо. Сценарии zero-shot и few-shot не выдавали адекватных результатов для всех моделей, так что из сравнения мы их исключили. Вывод, который здесь можно сделать: стоит дообучать такие большие языковые модели для своей задачи. И, действительно, fine-tuned модели сработали достаточно неплохо, а fine-tuned detoxGPT-large по агрегирующей метрике оказалась самой лучшей. Но так как GPT модели генерируют новое предложение с нуля, то они страдают по метрикам сохранения контента. Кроме того, они могут генерировать длинный хвост с какими-то повторяющимися фразами, не обрывая предложение в нужном месте. Но в тех случаях, когда предложение может быть детоксифицировано не просто удалением мата, а требует полного перефразирования, использование detoxGPT уместно.
Модели condBERT сработали неплохо. Проявилось их преимущество: они меняют токены локально, поэтому получили достаточно высокие метрики по сохранению контента. При этом не всегда замена получается удачной: модели меняют токсичное слово на такой же токсичный синоним, но он совершенно не подходит по контексту или вообще не является спец-символом [UNK].
Заключение
Задача переноса стиля, а тем более детоксификации текстов – это новая область в сфере NLP. До сих пор ученые не пришли к единому мнению о том, как более точно и корректно автоматически оценивать подходы для TST.
Мы провели первые эксперименты по детоксификации текстов для русского языка. Как показывает оценка и как видно из примеров, еще есть необходимость улучшать методы. Иногда достаточно удалить из текста нецензурные слова, а в других – заменить их нетоксичными синонимами. В некоторых случаях детоксификация текстов возможна, если полностью их переформулировать. Наиболее многообещающим направлением для развития можно считать объединение всех представленных стратегий и их применение в зависимости от характера токсичности в конкретных предложениях.
Код моделей detoxGPT, condBERT и код для оценки метрик доступен в нашем репозитории. И, как и обещали, предлагаем поиграться с нашими моделями – доступно демо, можно попытаться обругать бота в Телеграме, а если хотите более низкоуровневый взгляд, то можно запустить демку в колабе.
P.S. В конце хотелось бы выразить благодарность всем сооавторам статьи и коллегам из лаборатории MTS AI-Сколтех, без которых эта работа не была бы реализована. Благодарим Даниила Московского, Варвару Логачеву, Давида Дале, Ольгу Козлову, Никиту Семенова и Александра Панченко.
Комментарии (60)

PereslavlFoto
27.10.2021 13:57+5Сама проблема «токсичных текстов» возникла, когда люди решили отказаться от прямолинейности, от искреннего выражения правды.
В школе нас учили (на примере Радищева) никогда не отказываться от «токсичных текстов», а напротив, смело высказывать свои мысли. Вижу, теперь времена иные и правдолюбам больше нет пути.
amarao
27.10.2021 14:06+6Токсичность и прямой текст, это, вообще говоря, совершенно разные вещи. Токсичный текст с большой вероятностью будет полон двойных посланий, противоречий между ними, он будет неконструктивен, обобщающ и оскорбителен.
Сказать - "твоя идея не сработает" - это прямой текст. Текст в первом комментарии в посте - токсичный ответ.
PereslavlFoto
27.10.2021 14:09+1Разумно! Теперь давайте посмотрим на примеры.
1) Если идея не работает, будет лучше сказать — «твоя идея не работает».
2) Если идея чудовищно калечная и будет калечить всех, кто работает над её воплощением, будет ли правильным сказать, что она всего лишь «не работает», и тем самым оставить всю опасность для людей?
Я понимаю вашу мысль о том, что «токсичный текст» полон двойных посланий. Такое нередко случается, если читатели хотят искать двойные послания. Но если автор прямо и откровенно пишет то, что желает сказать, без двойных посланий — тогда его будут обвинять в «токсичном тексте», хотя он всего лишь сообщил правдивые наблюдения.amarao
27.10.2021 14:14+7Достаточно сказать, что реализация этой идеи создаст проблемы в будущем. Ключевой момент: отсутствие переходов на личности и обобщение на неперечислимый класс ("твои идеи всегда" или "ты как всегда").
Повторю, задачей токсичного текста является не передать отношение/мнение к обсуждаемомой теме, а унизить/отвергнуть человека или даже группу людей.
PereslavlFoto
27.10.2021 14:21-2Если спокойно предупредить о проблемах, тогда этого предупреждения никто не услышит. Его просто проигнорируют. Ведь это же опасное предупреждение, будет спокойнее не слышать его.
В вашем примере опытный сотрудник вспомнил, что «Михаил» ещё никогда не предлагал ничего дельного, поэтому имеет причину для обобщения. Уволить «Михаила» нельзя, а принудить его к молчанию — можно.amarao
27.10.2021 14:37+2Это вы себе придумали. Я со стороны эту ситуацию совсем по другому вижу. В целом, если "уволить нельзя", то отвечать токсичностью нельзя тем более, потому что у токсичности есть простое свойство - если её не пресекают, она разрастается.
PereslavlFoto
27.10.2021 15:17-2Да, всё верно. Она разрастается, потому что ничего другого сделать нельзя. Она остаётся единственным (!) способом для того, чтобы заставить всех сотрудинков выполнять ещё больше обязанностей за ещё меньшие деньги.

MentalBlood
27.10.2021 14:14Прямо высказывать негатив просто потому что он у тебя в мыслях — недипломатично. Так можно легко обострить и даже разорвать отношения. Это и есть путь тех, кому особенно ценна корреляция их мыслей с их публичными высказываниями, и он всегда открыт
PereslavlFoto
27.10.2021 14:22+2Если в мыслях негатив — тогда нужно разорвать отношения, чтобы не лукавить и не жить против совести.

svboobnov
28.10.2021 08:10+1Так ведь Радищев призывал говорить прямо потому, что вокруг была обтекаемая дипломатичность. Т. е., прямо в лоб правду могли тебе сказать родители или ближайший друг.
Вообще, думаю, дипломатичность необходима для того, чтобы донести свою мысль до собеседника, поскольку неприятную фразу человек отвергает целиком.
Вот аналогия: смысл == конфета, форма_высказывания == обёртка_конфеты. Если обёртка неприятная, то подавляющее большинство людей даже не притронется к конфете.

hungry_forester
27.10.2021 14:05+6Думается, есть тенденция смешивать в кучу токсичность, хамство и откровенность.
Токсичность в узком смысле - манипулятивность. Впрочем, любое высказывание может служить манипулятивным целям. Ну так, чисто математически рассуждая :)
Ясное дело, что этих роботов тоже пробьют. Но хоть откровенного мата не будет :)

Alexey2005
27.10.2021 16:50+6ИМХО, токсичность — это когда комментарий вместо информационной нагрузки несёт эмоциональную. Из вышеприведённого высказывания мы не получаем никакой информации о том, почему же идея так плоха и соответственно никакой обратной связи, его полезность близка к нулю. Зато текст аж трещит по швам от вложенных в него эмоций, которые вызывают ответную эмоциональную реакцию, ещё более мешая сделать непредвзятый вывод.
Поэтому вместо «сарказмометра» и подобных же штук я предлагаю просто замерять степень эмоциональности текста (на это нейронку натренировать куда проще), и чрезмерно насыщенный текст сразу помечать как неприемлемый, поскольку для обмена информацией в рамках производственного процесса эмоции лишь помеха, информационный шум, который только затрудняет восприятие.

Maccimo
27.10.2021 14:20+7важной социальной проблеме – борьбе с токсичной речью в Интернете или детоксификации текстов.
Главное в это социальной проблеме то, что «борцунов с токсичностью» в современном обществе не подвергают остракизму в достаточной мере.
Хочешь бороться с токсичной речью в Интернете — перережь интернет-кабель, запрись в комнате с мягкими стенами и займись детоксификацией своих промытых мозгов. Еду тебе принесут санитары.

Earthsea
27.10.2021 14:24Detoxification
Rewritten:козлина ты козлина .
Сыроват еще детоксификатор. Original, естественно, не буду публиковать.

RMV1983
27.10.2021 15:34+3Меня интересует вот какой правовой аспект: вы предлагаете решение для изменения текста исходного сообщения, написанного человеком. Причём меняете неявно, так что проходящий мимо читатель не сможет понять: это написал исходный автор или нет. Так, вот: что с авторскими правами на исходное сообщение? А на получившееся?
Поскольку вы сами указываете, что смысл текста сохраняется не в 100% случаев, то кто будет отвечать, если изменённое сообщение будет нарушать какой-либо закон? Из-за изменившегося смысла или из-за появления нового варианта прочтения?
Ну и не могу не оставить ссылку, на рассказик, близкий к теме статьи.

cointegrated
27.10.2021 15:50+4Если говорить про права и ответственность за сгенерированный текст, то в посте два случая описаны:
Человек пишет пост, робот предлагает человеку перефразированный текст, человек жмёт "принять новый вариант" либо "оставить как было". В первом случае человек сам согласился с переписанным вариантом текста, и потому и права, и ответственность за этот текст - на нём. Примерно как если бы робот предложил исправить опечатки. Во втором случае перефразированный текст вообще никуда не выкладывается.
Бот намеревается отправить юзеру токсичный текст, но вместо этого отправляет менее токсичный, перефразированный. В этом случае (как и без детоксификации) права и ответственность за текст - на владельце бота.
RMV1983
27.10.2021 16:08+1Эх, хорошо бы, было именно так. Вот только есть у меня опасения, что могут применять как-то иначе. Ведь:
Если человек уже написал токсичный текст, значит он хотел его написать. Да, он может резко передумать, но есть у меня подозрения, что процент будет не особо высоким. Если без дополнительных мер воздействия.
С таким ботом явно что-то не так и его нужно немедленно останавливать, что бы не натворил чего похуже. Как один из тригеров для остановки — норм. Вот только в статье речь не столько про обнаружение, сколько про замену.
Мне, видится, возможное практическое применение несколько иначе. Вот, предположим, есть какой-то воображаемый форум с историей. И там общались давно и свободно, с матами (завуалированными, с ошибками, но угадываемыми) и прочим. Но раз, ввели новый закон: мат нельзя ни в каком виде. И ещё чего-нибудь нельзя.
При доступности описываемого в статье решения, у владельца может возникнуть соблазн: все старые сообщения прогнать через такой алгоритм.
При этом, можно ещё сделать так, что в БД хранятся старые сообщения, а нового пользователя спрашивают: вам показать вежливую версию форума или токсичную?
При этом, первый вариант явно потребует меньше ресурсов на сервере, а второй, лично мне, кажется более предпочтительным (из двух), но он дороже, а значит скорее всего будет большой соблазн выбрать не его.

diogen4212
27.10.2021 21:01-1Более интересно применение данной технологии как расширения в браузере, которое текст любой открытой страницы преобразует в нетоксичный, и чтобы ставить его могли все желающие. В теории это могло бы стать альтернативным путём решения проблемы угнетения меньшинств: кого-то что-то оскорбило, он поставил расширение и всё вместо судебных процессов, культуры отмены и т.д., но это в идеальном мире.

Armitage1986
28.10.2021 04:51Проблема ведь не в том, что человека что-то оскорбило, а в том, что "да как эта скотина посмела, счас вот я ей...!! ".
svboobnov
28.10.2021 07:49+1>>... кого-то что-то оскорбило,...
Оскорблённый всегда найдёт, чем оскорбиться. В школьном чате йуные снежинки оскрбляются от того, что им прямо и честно, без ругательств, указывают на фактические ошибки. Они вообще оскорбляются, если их не обожают.
В ту пору, когда я работал учителем, удивлялся такому отношению к мнениям окружающих.

apapacy
27.10.2021 18:25Если говорить про права и ответственность остаётся только добавить расчёт индекса токсичности и внедрить сертификат не токсичности и здравствуй новый мир.
Alexey2005
27.10.2021 22:23+2Проблема решается очень просто: пишем к этому детоксификатору парный ему токсификатор, который делает прямо противоположное — увеличивает степень токсичности текста до исходной.
После чего все желающие ставят эту связку в качестве расширения браузера. В итоге все посты попадают в соцсеть в этаком «кодированном» детоксифицированном виде, а те, кто согласен на токсичность, при чтении их декодируют и видят так, как и задумано.
В итоге люди спокойно кроют идиотов матом, а SJW остаются с носом, потому что в соцсети всё чинно-мирно, ничего токсичного не просачивается и ни к чему придраться не выходит.
Эта же технология может использоваться и в политических целях. Если в какой-то стране запрещено допустим оскорблять Отца Нации, то создаём связку из двух нейронок: одна превращает всю хулу на Мудрого Вождя в славословие и дифирамбы, а другая — наоборот. После чего с нашей стороны в сеть попадают только восторженные посты, к которым не придерётся даже самый въедливый «патриот».
johnfound
28.10.2021 01:19+4Только есть маленькая деталь:
tox(detox(x) != detox(tox(x)) != xsvboobnov
28.10.2021 07:37+1Вы заблуждаетесь: вот уже лет 300, а то и более, россияне живут в двоемыслии, и легко кодируют язвительный текст в то, что пройдёт цензуру (а цензоры тогда были живые, не машины) , и декодируют при чтении.
Вот представьте себе, что я прокомментировал Ваш коммент таким: "Продукт Вашего межушного ганглия просто восхитителен!!!".
apapacy
28.10.2021 09:53Советская цензура так ушла в аллюзии что стала пропускать откровенную антисоветчину. Например золотой теленок. Там если читать сейчас все открытым тек том пишется. Или же ставший бестселлером сборник Фазиля Искандера Сандро из Чегема. Там если кто не читал фабула такая что в молодости Сандро Чегемский убил русского солдата на посту который перднул в его присутствии за что получил в подарок бинокль от принца Ольденбургского и с этим биноклем потом не расставался до времен позднего застоя. Я собственно тогда только понял прочитав в детстве что СССР делится на национальности.

Gutt
27.10.2021 16:23Маты могут быть в зале для боулдеринга, но не в сообщении. Это из той же серии, что и штан вместо штанов или трус вместо трусов.
apapacy
28.10.2021 11:08Да Вы правы. Сейчас мало кто хорошо знает русскую речь. Это не маты а матюки. Хотя у Маяковского тоже было:
Чтоб суше пяткам - Пол кроется , извините за выражение , пробковым матом.А вто в словаре Броггауза-Ефрона...

johnfound
27.10.2021 17:29+1важной социальной проблеме – борьбе с токсичной речью в Интернете или детоксификации текстов.
А кто и где сказал, что борьба с токсичной речью (что бы это ни значило) является важная социальная проблема?
Как раз наоборот – токсичная речь, это важный социальный регулятор, один из заместителей прямого насилия. Вы считаете что лучше было бы иметь прямое насилие вместо токсичные комментарии? Флаг вам в руки, как говориться, но потом не говорите что "это не так было задумано".

ABOMETP
27.10.2021 17:34+2напоминает старый анекдот про опытную машинистку, что печатала текст письма командира части под диктовку, только этой нейросети далеко до той машинистки

janatem
27.10.2021 18:14+1<…> вот уже много лет идет разработка кибернетического редактора. Ученые – писателям. В порядке помощи. Собственно, сам робот-редактор уже создан, и теперь его на наших рукописях только дрессируют. И вот когда эта машина вступит в строй, вот тут нам всем будет конец, потому что она не только грамматические ошибки будет исправлять и стиль править, она, дяденьки, подтекст на два метра под текстом будет углядывать. Она, дяденьки, сразу определит, кто есть кто и почему. <…> Робот-редактор, оказывается, был только зарею новой эры. Это машина громоздкая, стационарная, дорогая. А вот на подходе уже, если хотите знать, дяденьки, специальные пишущие машинки, пока еще только для нас, прозаиков. На этих машинках установлены электронные цензурные ограничители. Представляете? Печатаешь ты двумя пальцами «жопа», а на бумаге выходит: «окорока», «пятая точка», «афедрон» и уж в самом крайнем случае «ж» с тремя точками.
Написано, между прочим, в 1980-х.
Sergey-Aleksandrovich
27.10.2021 20:58+3Предлагаю вместе пофантазировать о прекрасном де-токсифицированном отдаленном будущем, в котором любая изложенная "мысль" (коментарий/сообщение любого пользователя на любом сайте/блоге, в соцсети, месенджере, субтитрах, видеозаписи, аудиозвонке и т.д.) автоматически исправляется/модерируются (в контексте нашей фантазии не важно это подсказка с целью "образумить" или автоматическое исправление) "искуственным интеллектом", приводя "высказанную" мысль до "нейтральной эмоциональной окраски"...
...а потом эти люди встречаются в реальной жизни

spinmozg
27.10.2021 22:41+2Давайте рассмотрим абсолютно фантастический вариант. Например, вместо условного токсичного "Навальный - молодец" будет "Осуждаю! И правильно, что сидит!", да ведь? Это же снимет градус токсичности? Ведь что такое токсичность? Нет однозначного определения, значит, можно применять это по своему усмотрению... А потом закрепить чье-то усмотрение законодательно. Исключительно в интересах граждан, конечно...
svboobnov
28.10.2021 07:27+1Хм, есть очень простой пример неуловимого мата:
*Идёт диктант по русскому языку*
Учительница: Пишите, дети: "В углу скребёт мышь."
Вовочка: Марьванна, а кто такой "скр"?
svboobnov
28.10.2021 08:44+1А вот пример именно язвительности:
*на форуме обсуждают монаду IO в Хаскеле*
АА: Да чо вы паритесь? Пишите просто "WriteLn('превет' #13#10) ;" и оно напечатается!
ББ: Ваше мнение очень ценно для нас; пожалуйста, перезвоните позже...
ВВ: А Вы уже сделали домашнюю работу по русскому?
Подобные насмешливые ответы не перехватываются (пока?) фильтрами и язвят вполне чувствительно.



sherem
28.10.2021 16:08+2Позабавила замена "идиот" на "уважаемый". Фраза прочиталась с интонациями Яковлева в фильме Кин-дза-дза. Только он использовал "родной". Похоже, что на Плюке эти технологии были интегририваны в переводчик :)
maffi44maffi44
28.10.2021 16:08В этом крестовом походе к новому миру без зла и насилия, участники этого похода забыли для кого все делается.
В подобных сервисах совершенно вымывается ценность субъектности пользователя.
Ведь сообщение, в контексте общения между людьми, ценно не само по себе, а в контексте того, что его высказал некий субъект, которого мы выспринимаем как равного (в контексте общения между субъектами).
В данном случае сообщение от субъекта подменяется сообщением от объекта (нейронки), тем самым ценность его нивилируется. Люди достаточно быстро это поймут и не будут пользоваться такими сервисами, потому что не будут видеть для этого причины (если только не захотят поговорить с нейронкой).
Не стоит думать, что вы лучше знаете как жить (говорить, общаться, выражать мысли, действовть и т. д.) другим людям.
Lecort
28.10.2021 17:33Прикольно ... Чел написал статью, а ее обсуждение посвящено первому комментарию... )))) А как быть с проблемой грамотности написания текстов в интернете? Щас она упала ниже плинтуса... Хрен с ними, с матами и токсичностью... Имхо, не самая главная беда... Люди перестали грамотно писать. И гордятся этим.
johnfound
28.10.2021 17:49Имхо, не самая главная беда… Люди перестали грамотно писать. И гордятся этим.
Ну-у-у, тогда надо делать нейронки, исправляющие ошибки. Нет? Я бы использовал с удовольствием. А если и падежи может чинить, то и заплатил бы. :P
ilialin
29.10.2021 09:20А термины «взрыв» и «просрали все полимеры» в выражения «хлопок» и «отрицательный рост» — это тоже вы исправляете?

VMarkelov
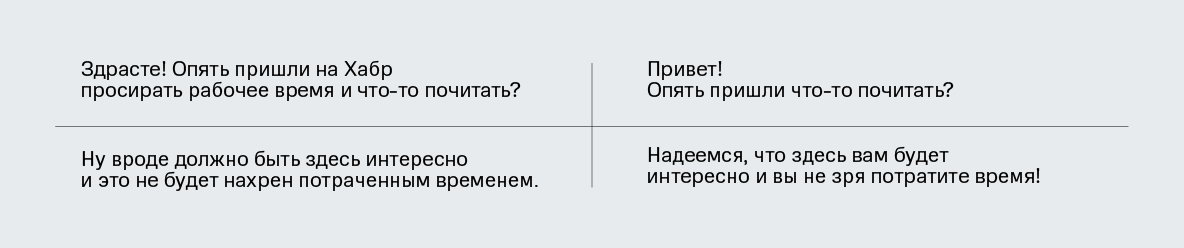
31.10.2021 22:18+1Автоматическая замена "Ты что, идиот, сам прочитать не можешь?" на "Ты что, уважаемый, сам прочитать не можешь?" будет хорошо смотреться разве что в начале. Со временем все привыкнут к тому, что "уважаемый" - это всегда какое-то ругательство и станут обижаться даже на безобидного "уважаемого".
Есть хорошая юмореска на эту тему: https://lex-kravetski.livejournal.com/151979.html
Старая, но до сих пор злободневная.
amarao
Мишенька, я рад, что ты сюда пришёл с своей, несомненно, в очередной раз, гениальной идеей. Но мы же взрослые люди и всё понимаем, так что, может быть, просто сэкономим занятому полезными вещами дяде чуть-чуть времени и ты просто поиграешь в песочнице?
MentalBlood
Мда. Понимать сарказм примерно так же сложно, как понимать юмор, а до нормального понимания юмора нейронкам еще далеко. Наверное потому что для шуток очень важен контекст, который к тому же далек от того, что непосредственно в тексте шутки
amarao
Это не юмор, и это не сарказм, и не шутка, это чистой воды токсичность.
Сам текст - вольный пересказ одного прелюбопытного сообщения, которое я недавно наблюдал в рабочем чате.
Я постарался сохранить все признаки токсичности: обращение к коллеге со снисходительно-ласкательной интонацией, обобщение неудачности текущего решения на человека (не "это плохо", а "у тебя всегда плохо"), слабо завуалированное оскорбление, немотивированный отказ.
PereslavlFoto
В этой ситуации фраза из чата означает вот что:
Я видел такие ситуации. Там «Михаилы» не заслуживали мотивации, поэтому всегда получали отказ без мотивации, разве что иногда с насмешкой от руководителя и от других «Михаилов».
amarao
Конкретно в том чате, откуда я это брал, один человек писал человеку из другого отдела, причём, зная обоих, я сильно на стороне "Михаила", потому что автор текста просто не хотел, чтобы на его вотчину кто-то заходил с автоматизацией, а вместо этого ему писали бы тикеты, у которых был бы "next business day" время выполнения.
PereslavlFoto
Обычное дело! Опытный специалист видит в новых рацпредложениях большое число неустранимых недостатков, которые возникают, потому что автор рацпредложения не знаком с темой, по которой вносит своё рацпредложение.
Именно поэтому ещё в советское время рационализаторов и изобретателей нигде не любили. Ради экономии, ради «рационализации» они, как правило, губили давно налаженный технологический процесс. Потому-то рационалиаторов всюду боятся.
MentalBlood
Вот же: "я рад", "несомненно… гениальной идеей". Вот песочница и вообще стиль второго предложения уже не сарказм, а просто унижение. Кстати, пожалуй даже унижение/оскорбление нейронкам тут будет увидеть непросто, разве что по стилю
PereslavlFoto
В данном примере сотрудник не накопил опыта, не предлагает дельных решений, не приносит прибыли, не нравится начальству, отвлекает людей от работы. Однако нет формальной причины для его увольнения. Придётся бороться с ним через риторику.
amarao
В данном примере "Михаил" в одиночку вытащил систему автоматизации нереального размера, имеет в группе поддержки несколько десятков весьма опытных и авторитетных сотрудников, но ему отвечает "вахтёр" из соседнего отдела, которому это принесёт изменения и чуть-чуть сократит права по "вахтёрству". Тру стори.
PereslavlFoto
Если всё это правда, тогда «Михаил» уже давно понял, что в чат писать не надо. А надо писать учредителю, владельцу бизнеса.
venanen
Каким бы не был Михаил - такое общение недопустимо в технологичной бизнес-среде