

В целом, конкретно на Хабре наверняка найдётся много специалистов, которые знают, как это сделать. Но вот так получилось, что когда мне показали очень простое и удобное решение, я опросил своих коллег и выяснил, что о нём знает только тот, кто мне рассказал, да и тот уже забыл все детали. Он просто проект выдал и сказал, мол, делай по образу и подобию. И к уже материалам, имеющимся там, пришлось кое-что искать ещё в сети.
В общем, думаю, имеет смысл свести все сведения воедино. Кому интересно – приступаем!
Что следует скачать
Я буду работать под Windows. В сети сказано, что под Линуксом всё будет точно так же, но я не проверял. А под Windows исходно был драйвер WinPcap, а к нему шла библиотека. Гугль говорит, что имена функций на 100% совпадают с таковыми от Линуксовой libpcap. Потом драйвером WinPcap перестали заниматься, даже не было его 64-битной версии. Потом был разработан другой драйвер… Вообще, его имя Npcap, но чтобы не забивать голову лишней информацией, предлагаю более простой путь для поиска:
Просто скачиваем Wireshark и устанавливаем его. Он поставит актуальный драйвер, который по интерфейсу совместим с WinPcap, а значит – будет работать с библиотекой.
Также нам будет нужна библиотека. Мне всё досталось в виде базового проекта, но в целом, скачать нужные файлы можно отсюда: WinPcap · Developer Resources.
Повторю, не надо скачивать оттуда сам драйвер. Он устарел. На сайте всё верно написано. Но это не страшно. Что установится вместе с Wireshark – оно будет совместимо с этой библиотекой. Поэтому спокойно выбираем пункт Download WinPcap 4.1.2 Developer's Pack и скачиваем архив. Нам понадобятся каталоги Include и Lib, содержащиеся внутри него.
Ну всё, теперь наша программная часть готова к бою. У нас установлен Wireshark и примкнувший к нему WinPcap-совместимый драйвер, и есть необходимые заголовочные файлы и библиотеки. Но перед началом опытов мы чуть-чуть настроим аппаратуру на уровне ОС.
Отключаем всё ненужное от сетевого адаптера
Сетевым адаптером могут управлять многие компоненты системы. Если посмотреть на его свойства, мы можем увидеть, какие подсистемы имеют к нему доступ:
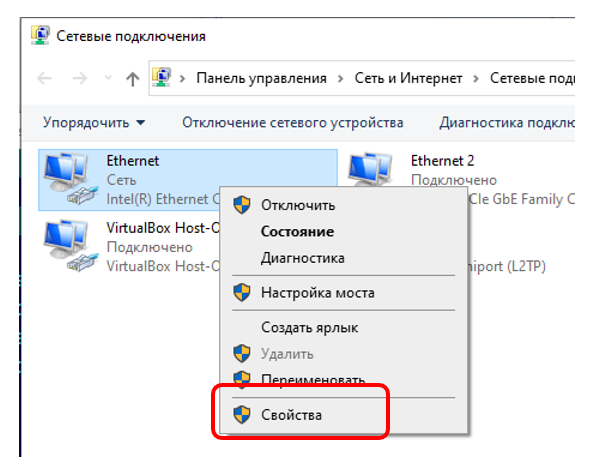
Если прокрутить скроллер, будет ещё куча подсистем, и почти у всех установлены галочки. Для того адаптера, которым мы хотим управлять с высокой предсказуемостью, весь этот зоопарк лучше отключить. Понятно, что это должен быть специально выделенный адаптер. У меня в машине сейчас таких целых два. Когда я отлаживал Ethernet-анализатор, я слал пакеты с одного адаптера на другой, а анализатором ловил их. Сами адаптеры в отечественном Интернет-магазине стоили по 500 рублей, их доставили за день. Понятно, что это были адаптеры по акции, и не каждый день бывают такие цены, но в целом, добавить один-два адаптера к себе в ЭВМ особого труда не составит. Ещё раз обращаю, что я нашёл их в крупном отечественном Интернет-магазине, без привлечения АЛИ Экспресса.
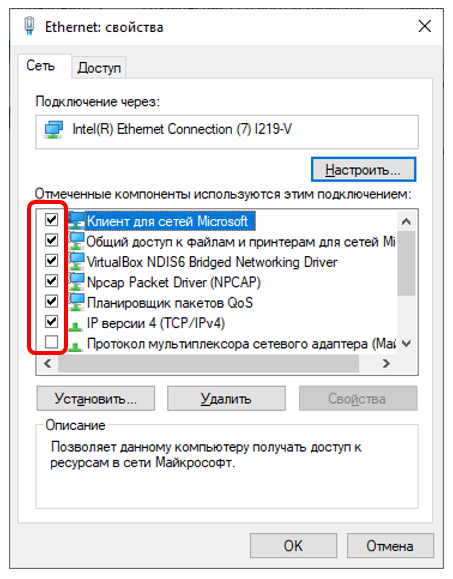
Благодаря выделенному адаптеру, я буду уверен, что никто, кроме меня, ничего туда не пошлёт. Все пакеты будут или сформированы мною, или придут из подконтрольных мне мест. В общем, надо снять все галочки, кроме Pcap-овской. Так как мой Wireshark установил драйвер NPCAP, то галочка должна остаться только для него.
Готовим проект
В последнее время, я всё делаю с использованием Qt. Поэтому я скопировал в каталог со своим проектом папки Include и Lib из архива WpdPack_4_1_2.zip. Далее, я дописал в файл проекта такие строки:
DEFINES += HAVE_SNPRINTF
DEFINES += HAVE_VSNPRINTF
INCLUDEPATH += WinPCap/Include
LIBS += $$PWD/WinPCap/Lib/x64/wpcap.lib
LIBS += $$PWD/WinPCap/Lib/x64/Packet.lib
LIBS += -lIphlpapi
LIBS += -lWs2_32В коде я использую такие заголовочные файлы:
#include "pcap-int.h"
#include "Packet32.h"
#include "iphlpapi.h"
#include "Win32-Extensions.h"
Получаем список устройств
Чтобы открыть устройство «сетевой адаптер», надо выяснить его имя. Для этого имеются функция pcap_findalldevs(). Выделенную ею память надо будет освободить при помощи функции pcap_freealldevs().
Я покажу кусок кода, который не просто заполняет список в Qt-шном виджете, но ещё и устанавливает маркер на тот его элемент, который был запомнен при предыдущем открытии. Ну, чтобы не требовалось выбирать карту каждый раз.
settings.beginGroup( "DefaultCards" );
QString defaultSource = settings.value("Source",QVariant("Nothing")).toString();
QString defaultDestination = settings.value("Destination",QVariant("Nothing")).toString();
settings.endGroup();
pcap_if_t *alldevs;
char errbuf[PCAP_ERRBUF_SIZE];
if (pcap_findalldevs(&alldevs, errbuf) != -1)
{
int i = 0;
for(pcap_if_t *d = alldevs; d != NULL; d = d->next)
{
ui->m_listEthCardNames->insertRow(i);
QTableWidgetItem* newItem = new QTableWidgetItem (d->description);
ui->m_listEthCardNames->setItem(i,0,newItem);
newItem = new QTableWidgetItem (d->name);
ui->m_listEthCardNames->setItem(i,1,newItem);
if (newItem->text()==defaultSource)
{
ui->m_listEthCardNames->selectRow(i);
}
i += 1;
}
pcap_freealldevs(alldevs);
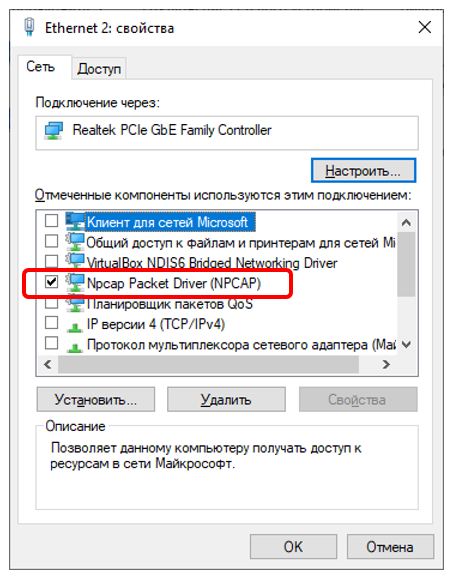
}В итоге, получаем что-то такое в списке:
Открываем устройство
Сам процесс открытия устройства прост и понятен. Необходимо и достаточно вызвать функцию pcap_open_live(). Пример вызова функции:
m_hCardSource = pcap_open_live(srcItem->text().toLatin1(), 65536, 1, -1, errbuf);Здесь есть одна магическая константа – единица. На самом деле, это не что иное, как:
#define PCAP_OPENFLAG_PROMISCUOUS 1
Но я так и не смог найти способа правильного включения заголовочного файла, содержащего эту константу. Мало того, мне этот пример приехал тоже с магическим числом. Так что, похоже, не я первый.
Но не всё так просто, как хотелось бы. Адаптер недостаточно просто открыть. При самостоятельном формировании пакетов нам будет нужен его MAC-адрес. А когда я гонял данные с одного адаптера на другой – MAC-адреса обоих. Большинство примеров, которые я нашёл, при той схеме, которую я выбрал, не сработают. Они хороши, когда плата обслуживается кучей сетевых сервисов. Нет сервиса – нет возможности запросить у него MAC-адрес. А у меня все галки сняты. В результате массового опроса Гугля, был выстрадан следующий путь.
Сначала открываем карту при помощи уже известной функции:
int srcRow = ui->m_listEthCardNames->currentRow();
if (srcRow <0)
{
QMessageBox::critical(this,"Error","Please, select a Source Card");
return;
}
char errbuf[PCAP_ERRBUF_SIZE];
QString srcDescription = ui->m_listEthCardNames->item(srcRow,0)->text();
QTableWidgetItem* srcItem = ui->m_listEthCardNames->item(srcRow,1);
m_hCardSource = pcap_open_live(srcItem->text().toLatin1(), 65536, 1, -1, errbuf);
if (m_hCardSource == 0)
{
QMessageBox::critical(this,"Open Source Adapter Error",errbuf);
return;
}А теперь – открываем адаптер на другом уровне. Там можно посылать системные запросы, в том числе, запрос на MAC-адрес. После чего адаптер того уровня можно закрыть.
PPACKET_OID_DATA pOidData;
CHAR pAddr[512];
ZeroMemory(pAddr, sizeof(pAddr));
pOidData = (PPACKET_OID_DATA) pAddr;
pOidData->Oid = OID_802_3_CURRENT_ADDRESS;
pOidData->Length = 6;
LPADAPTER pADP = PacketOpenAdapter((PCHAR)(srcItem->text().toLatin1().constData()));
if(PacketRequest(pADP, FALSE, pOidData))
{
memcpy(m_macSource, pOidData->Data, 6);
}
PacketCloseAdapter(pADP);Ну, и дальше я сохраняю идентификатор адаптера в файле конфигурации, чтобы при следующем входе в программу в списке был выбран именно он:
QSettings settings( "YolkaPlay.conf", QSettings::IniFormat );
settings.beginGroup( "DefaultCards" );
settings.setValue( "Source", srcItem->text() );
settings.endGroup();Вот теперь мы не просто открыли адаптер, но ещё и узнали его MAC-адрес, поэтому готовы к ручному формированию пакетов.
Формируем пакеты
Если честно, теория процесса формирования пакетов не относится к теме статьи. Я просто поискал в сети функции заполнения попроще. В том примере, который будет приложен в конце, я вызываю функцию void Dialog::CreatePacket().
В ней, среди прочего, есть такие строки:
unsigned short UDPChecksum = CalculateUDPChecksum(packet);
memcpy((void*)(packet.m_pData+40),(void*)&UDPChecksum,2);
unsigned short IPChecksum = htons(CalculateIPChecksum(packet));
memcpy((void*)(packet.m_pData+24),(void*)&IPChecksum,2);Эти строки очень полезны не только при ручном формировании пакетов. Я брал штатные пакеты от обычных программ, которые наловил WireShark. Дальше пытался хоть подставить их в Verilog модель, хоть послать через PCap драйвер. Ethernet устройство упорно их игнорировало. Оказывается, WireShark отображает дамп уходящих пакетов без контрольных сумм UDP заголовка.
Вот я вижу два абсолютно идентичных пакета, пойманных WireSharkом. Один ушёл из PCap драйвера, второй — через сокеты. Никаких различий! Но устройство ловит только тот, что послан через сокеты. Снимаю дамп на стороне устройства — в PCap версии контрольная сумма отсутствует… Потому что она отсутствовала и в WireShark дампе. В общем, эти строчки помогут вам довести до ума пакеты, которые были сформированы другими программами и отловлены Wiresharkом.
Шлём пакеты по одному
Для посылки одиночных пакетов следует использовать функцию pcap_sendpacket().
Вот пример формирования и отсылки одиночного пакета:
void Dialog::on_m_btnSendPkt_clicked()
{
addrAndPort sourceParams;
sourceParams.mac = m_macSource;
sourceParams.ip = inet_addr("10.0.0.2");
sourceParams.port = 12345;
static const uint8_t fakeDestMac [6]={0x01,0x02,0x03,0x04,0x05,0x06};
addrAndPort destParams;
destParams.mac = (uint8_t*) fakeDestMac;
destParams.ip = inet_addr("10.0.0.3");
destParams.port = 12345;
static const int dataSize = 0x22;
udpData udpData;
udpData.SetUserSize(dataSize);
for (int i=0;i<dataSize;i++)
{
udpData.m_pUserData[i] = (uint8_t)(i + ((~i)<<4));
}
// Well. Data is filled, now we can add extra information
CreatePacket(sourceParams,destParams,udpData);
pcap_sendpacket(m_hCardSource,udpData.m_pData,udpData.m_totalDataSize);
}Скоро мы узнаем, почему этой функцией не стоит пользоваться, если планируется посылка пачки пакетов. Но для одиночных – вполне себе полезная функция, так как она принимает в качестве аргументов указатель на данные и их длину, не требуя заполнять какие-то сложные структуры.
Принимаем пакеты
Есть несколько разных подходов к приёму пакетов. Так как мне в том проекте, где я впервые использовал libpcap, надо было ловить задержку от посылки пакета с одной карты до приёма на другой, я вынес этот функционал в отдельный поток. Для этого пришлось добавить такой простенький класс:
class CReceiverThread : public QThread
{
public:
Dialog* m_pDialog;
// QThread interface
protected:
void run();
};На всякий случай, потоковая функция запускается с повышенным приоритетом (поэтому в том проекте у меня иногда получалось, что пакет приходил раньше, чем завершалось выполнение функции его передачи).
m_rcvThread.m_pDialog = this;
m_rcvThread.start(QThread::HighestPriority);
Когда работа завершена, надо не забыть остановить принимающий поток, ведь следующий тест может потребовать запуска принимающего потока с другой логикой. Сейчас я просто жду в передающей функции секунду после посылки последнего пакета, а затем — взвожу флаг для принимающего потока, что он может завершаться. Ну, и жду сигнала о том, что завершение действительно произошло. Для тестового приложения этого достаточно:
// For finish receive process
Sleep (1000);
QApplication::restoreOverrideCursor();
if (m_rcvThread.isRunning())
{
m_rcvThread.requestInterruption();
}
while (m_rcvThread.isRunning())
{
QThread::msleep(10);
}Теперь – самое интересное. Внутри потока самое главное – это вызов функции pcap_next_ex(). В случае успешного завершения, она вернёт заголовок (в котором имеются длина и временная метка), а также блок данных. Полученные данные я сохраняю в связном списке. Главное его достоинство – при добавлении данных, он не перестраивается. А то доводилось мне заниматься оптимизацией одной программы, где автор массово добавлял данные в тогда ещё CByteArray, и она работала 40 минут. После замены динамического массива на связный список время работы уменьшилось до минуты… А после сборки не в Debug, а в Release конфигурации – до нескольких секунд. С тех пор я люблю связные списки для вещей, размер которых заранее не известен. А сколько лишних данных может прийти из сети – предсказать невозможно. Итак, потоковая функция выглядит так:
void CReceiverThread::run()
{
while (!isInterruptionRequested())
{
pcap_pkthdr *header;
const u_char * pData;
int res = pcap_next_ex(m_pDialog->m_hCardSource, &header, &pData);
if (res == 1)
{
if (header->len != header->caplen)
{
volatile int stop = 0;
(void) stop;
}
receivedPacket* pPkt = new receivedPacket(header->len);
m_pDialog->m_receivedPackets.push_back(pPkt);
pPkt->SetTimeStamp(m_pDialog->m_timer.nsecsElapsed());
memcpy (pPkt->GetHdrPtr(),header,sizeof(pcap_pkthdr));
memcpy (pPkt->GetData(),pData,header->caplen);
}
}
}Забавный факт, связанный с функцией приёма
Кстати о невозможности предсказать объём приходящих данных. Пока я слал данные с одного адаптера на другой, я не обращал внимания на то, что функция приёма отловит не только приходящие пакеты, но и исходящие. Там для исходящего адаптера просто не шёл приём, вот я и не видел, что пакеты кто-то отлавливает.я. Ну, там всё работало так:
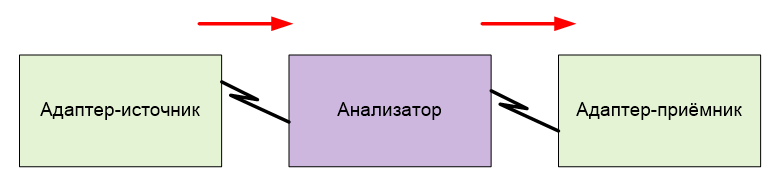
В текущем проекте у меня на проводе сидит устройство, которое модифицирует (инвертирует) пакеты и шлёт их назад.
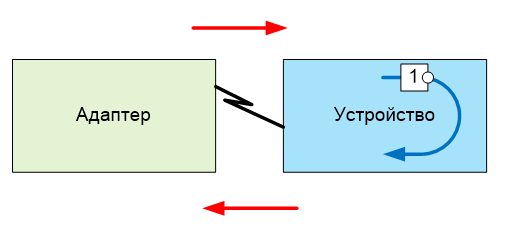
И вот тут-то я обратил внимание, что читающий поток улавливает вдвое больше пакетов, чем я ожидаю. Проверил – точно. Ловятся и исходящие, и входящие. Проверил на версии с двумя платами: там — кто отсылает, ловит копии отосланных; кто принимает, ловит принятые. Так что дело именно в логике.
В общем, не пугайтесь, когда функция pcap_next_ex() будет принимать копии отосланного. Давайте я поясню суть сказанного на рисунке
Первый практический опыт использования
Давайте разбавим сухую теорию практикой. В настоящее время я адаптирую «прошивку» для работы с гигабитным Ethernetом к ПЛИС Lattice. И вот убеждаемся мы, что уровень PHY работает корректно, пора переходить к MAC. А он не работает! И что делать? Вытаскиваем наружу линию за линией, смотрим на них осциллографом, выясняем, что возникает ошибка CRC в поле FCS. Что дальше?
А дальше начинается веселье. Расчётное значение CRC зависит от дикого числа параметров. Когда сбой может идти откуда угодно, ничего не получится найти. Желательно оставить для начала что-то одно. И вот тут нам на помощь приходит возможность формировать абсолютно любой пакет данных. Просто берём и шлём пакет из одних нулей. В этом случае выходное значение зависит только от внутреннего регистра сдвига. Напомню, как вообще считается CRC (я возьму первый попавшийся рисунок, без привязки к именно нашей разрядности и именно нашему полиному):

То есть, в алгоритме имеется регистр сдвига и однобитовое входное значение. В параллельных алгоритмах добавляется некоторое количество логики, которая позволяет учитывать за один такт не один входной бит, а много. Но сколько бы их ни было, а будет выполняться операция XOR. Нулевое входное слово не будет вносить никаких изменений в том, что бегает по регистру сдвига. А значит, мы будем проверять только этот регистр и его обратные связи. Исправен – перейдём дальше. Нет – будем чинить его. Поэтому желательно для начала на вход подавать именно нули. Но пакет, ушедший через сокеты, будет содержать заголовок! При работе через Pcap-драйвер мы вполне можем послать пакет с заголовком из одних нулей! Это же замечательно!
А на отладочные линии, идущие из ПЛИС на анализатор, выведем и линии, соответствующие регистру сдвига. Как же я привык к хорошему! В Квартусе я бы воспользовался SignalTAPом, в Vivado – ILA. А тут надо выводить сигналы на настоящие контакты и подключать настоящий анализатор! Но так или иначе. Берём и подключаем. Вернее, сначала убеждаемся, что на входы блока приходят одни нули, если через Pcap послан пакет из одних нулей… Ну, то есть, система ничего не добавила по пути… Этот рисунок я публиковать не буду, поверьте на слово. А вот регистр – покажу. Анализатор у меня 16-битный, так что из данных я вывел только младший байт.
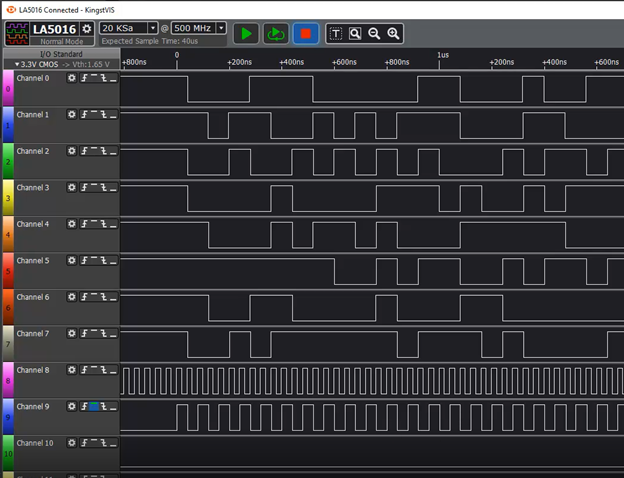
Я не нашёл, как в этой программе объединить биты в байт. Но посчитав пальцем, мы видим, что сначала там идёт 0xff, затем – 0x72, затем – 0x20. Дальше – не интересно. Потому что, взяв программную реализацию CRC и прогнав через неё все нули, мы получим последовательность для младшего байта 0xFF, 0x72, 0x00. Но и это ещё не всё! Если взять Верилоговский текст генератора CRC из этого проекта и прогнать его через ModelSim, мы получим в младших байтах всё те же 0xFF, 0x72, 0x00:

Пока я сделал вывод, что код для расчета CRC использует такой сложный синтаксис, что OpenSource компилятор Yosys неверно его синтезировал. Причём дело именно в логике. Даже для скорости 10 Мбит в секунду (тактовая частота будет 2,5 МГц), результат будет полностью идентичен. Взяв более простой исходник, мы получили работающий код. Там данные, пойманные логическим анализатором, совпадают с полученными хоть программным путём, хоть ModelSimом:
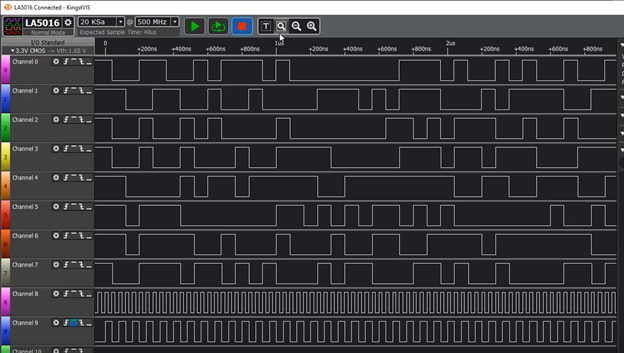
Правда, в найденном на замену исходнике пришлось перевернуть с ног на голову все биты в байте. Просто сначала я добился верной последовательности вот на этой диаграмме, потом – подал последовательность 0x01, 0x00, 0x00, 0x00… и увидел, что регистр сдвига ловит то, что вообще-то было бы при входе последовательности 0x80, 0x00, 0x00,0x00…Перевернул биты – всё стало хорошо. Если бы я не мог управлять потоком с точностью до байта, включая заголовок — искать врага пришлось бы дольше. Как бы я выкручивался, если бы пришлось посылать данные через обычные сокеты, ума не приложу! Использование Pcap-драйвера — просто находка для последовательного поиска врага!
Проблема передачи большого количества одиночных пакетов
Итак. Полученные знания уже позволяют нам проводить функциональное тестирование сетевых вещей. Но тестирование скоростных характеристик и устойчивости – увы, так не провести. Делаем простой пример. Передаём десять тысяч пакетов, каждый размером в килобайт.
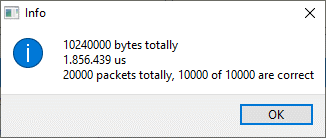
10 мегабайт за 1.8 секунды. Это… Ну пусть 5 мегабайт в секунду. На гигабитной скорости (10 бит в байте) это 50 мегабит в секунду. Как-то медленно!
Но так как на принимающей стороне стоит ПЛИС, я могу вывести линии шины AXIStream (это почти как AVALON_ST, про которую я писал в куче статей, но только с небольшими особенностями) и посмотреть, как пакеты передаются, при помощи анализатора. Запускаем.
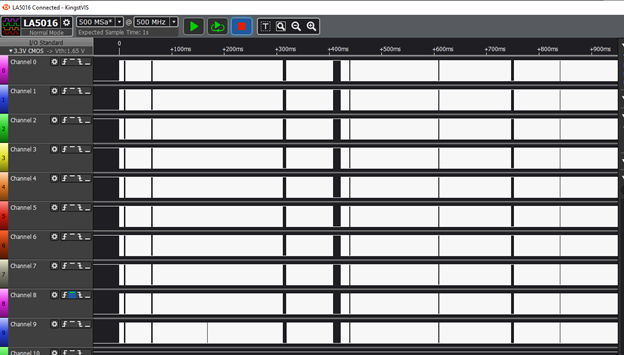
Уже тут видны паузы вплоть до 15 миллисекунд. Если чуть увеличить масштаб, увидим, что расстояния между пакетами равно примерно 200 микросекунд. Я покажу только линию строба. Когда она в единице, идёт перекачка данных по шине AXIStream, когда в нуле – шина простаивает:

Но мы видим, что шина дольше простаивает, чем работает. Это связано с тем, что система ради каждого пакета проваливается с пользовательского уровня на уровень ядра, а потом – возвращается на пользовательский уровень. Это очень дорогая операция. Чтобы устранить эту проблему, в библиотеке libpcap есть механизм, когда мы готовим очередь, а затем – единожды проваливаемся на уровень ядра. Давайте разберёмся, как он работает.
Передача с помощью очередей
Насколько мне удалось понять, функция передачи при помощи очередей была придумана специально для того, чтобы посылать ранее пойманные последовательности. По крайней мере, все найденные примеры именно читают последовательности из файла с ранее пойманными данными и посылают их. Собственно, нам надо сделать четыре шага:
- Зарезервировать память для очереди при помощи функции pcap_sendqueue_alloc(). Памяти должно быть достаточно для размещения всех данных и необходимого количества структур pcap_pkthdr (а необходимо их будет столько, сколько пакетов попадёт в очередь).
- Поместить в очередь все пакеты при помощи многократного вызова функции pcap_sendqueue_queue().
- Отправить всё содержимое оптом при помощи функции pcap_sendqueue_transmit(). У этой функции есть очень интересный аргумент — sync. Можно сказать, чтобы она слала пакеты с максимально возможной скоростью, а можно поручить брать время отсылки каждого пакета из поля ts, заполняемого на предыдущем шаге. С высокой вероятностью, sync придётся взводить. У меня просто иначе переполнялась очередь на стороне ПЛИС. Чтобы всё стало хорошо, для гигабита я делал расстояния между пакетами равным 10 микросекунд, для ста мегабит – 220 микросекунд.
- Освободить память, занятую очередью, при помощи функции pcap_sendqueue_destroy().
Обратите внимание, что на третьем шаге уйти данные уйдут, но из очереди никуда не исчезнут. Я поначалу пробовал после окончания отсылки добавлять в неё новые пакеты для следующей пачки. Оказалось, что в следующий раз поедут и те, что уже были в ней, и новые. Так что первое, что приходит на ум — отправленную очередь можно разрушить, освободив память при помощи функции pcap_sendqueue_destroy(), после чего — снова создать новую, перейдя к шагу 1.
Также у меня возникла странная проблема, которую я объехал на серой козе. У меня же стояла задача проверять сторону ПЛИС, а не оптимизировать сторону ПК. Дело в том, что, если посылаем 100 пакетов подряд, они отлично доходят, а принимающий поток ловит и их копии, и все ответы от устройства. 1000 пакетов – десяток-другой ответов не доходят (теряются по пути туда или обратно – не разбирался). При пачке их десяти тысяч пакетов, терялась пара тысяч. Я не понял, что к чему. Я просто шлю пачками по 100 пакетов. Скорость при этом для моих задач приемлемая, потери равны нулю. Устойчивость «прошивки» ПЛИС всё равно подтверждается.
Итак, вот как выглядит передача очередями с учётом всего вышесказанного:
bool bSleepBetween = ui->m_cbSleepBetween->isChecked();
int delta = 10;
if (bSleepBetween)
{
delta = 220;
}
…
for (int i=0;i<m_nSendPktCnt;i+=100)
{
pcap_send_queue *squeue = pcap_sendqueue_alloc (10 * 1024 * 1024);
pcap_pkthdr hdr;
memset (&hdr,0,sizeof(hdr));
for (int j=0;((j<100) && (i+j < m_nSendPktCnt));j++)
{
hdr.caplen = m_dataForSend[i+j].m_totalDataSize;
hdr.len = m_dataForSend[i+j].m_totalDataSize;
hdr.ts.tv_usec += delta;
if (hdr.ts.tv_usec > 1000000)
{
hdr.ts.tv_usec %= 1000000;
hdr.ts.tv_sec += 1;
}
pcap_sendqueue_queue (squeue,&hdr,m_dataForSend[i+j].m_pData);
}
pcap_sendqueue_transmit(m_hCardSource, squeue, 1);
/* free the send queue */
pcap_sendqueue_destroy(squeue);
}
Тестовый прогон с очередью
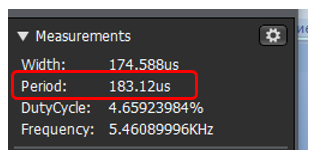
Сравните времянку с той, которая была выше. Она снята в том же масштабе!
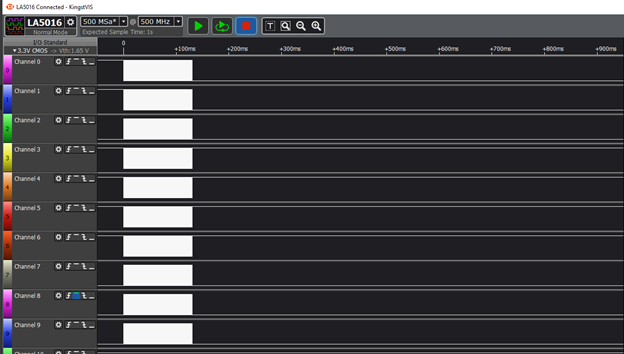
Внушает? Собственно, вот результаты замеров (10 мегабайт за 135 миллисекунд):
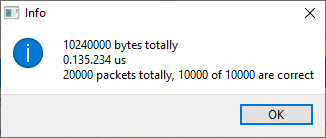
Примерно 75 мегабайт в секунду. То есть, 750 мегабит. Не гигабит, кончено… Просто если увеличить масштаб, мы увидим, что между каждой сотней пакетов всё равно есть те самые паузы по 200-300 мкс:
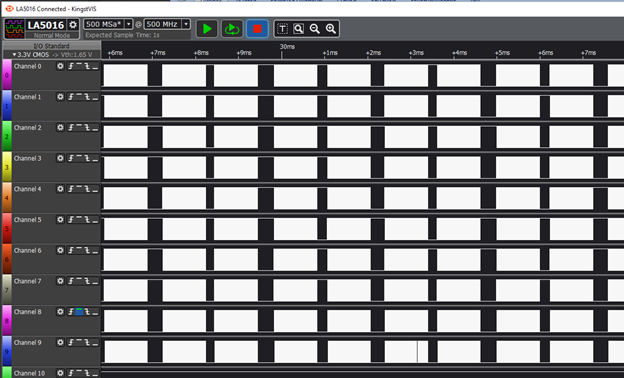
Но зато внутри блока мы видим вот такое соотношение работы и простоев:

Почти всё время единица, то есть, идёт передача данных по AXIStream! Пачка из сотни таких вещей не убивает «прошивку» в ПЛИС, а сотен уходит много, значит, начерно всё более-менее устойчиво. Так как я просто внедряю чужую Open Source разработку, этого достаточно, чтобы понять, что внедрено всё более-менее верно.
Что дальше
UDP – это хорошо, но как быть с более сложными протоколами? Тот пример, который мне выдали в качестве основы, обеспечивал высокоуровневые протоколы с помощью библиотеки LwIP. Так что никто не запрещает идти и этим путём. Но мне как-то было грустно думать, сколько времени я потрачу на освоение этой библиотеки и устранение проблем с нею, когда мне нужны не просто UDP-пакеты, а скорее даже UDP-подобные пакеты. Но кому надо – имейте в виду. Совершенно не обязательно мучиться. Можно просто взять LwIP.
Заключение
Мы освоили методику работы с сетью не через штатные сокеты операционной системы, а через ручное формирование и отправку пакетов. По ходу статьи мы рассмотрели два случая, где рассмотренный механизм является крайне необходимым. При необходимости, систему можно дополнить высокоуровневыми протоколами при помощи библиотеки LwIP (технология в статье не рассмотрена).
Проект, в котором все описанные технологии применены на практике, можно найти здесь: Grovety/Test-Colorlight-Ethernet: Qt project to test functionality of verilog-ethernet project on Colorlight 5A-75B board (github.com)
Социологический опрос
При разработке предыдущего блока статей я столкнулся с тем, что тема оказалась мало кому интересна. Поэтому теперь боязно начинать что-то большое, не выяснив, а нужно ли это общественности. С этой статьёй всё просто. Я уверен, что буду показывать её коллегам по мере возникновения задач у них. Плюс я уже один раз вспоминал, что к чему, когда делал тестовый проект для проверки «прошивки». Так что я сам же через год буду её читать.
Но работа с сетью на уровне пакетов – малая часть интересных вещей, которые удалось узнать, работая над проектом. Мы освоили работу с ПЛИС Lattice. Само по себе это особого интереса не представляет. Ну ПЛИС и ПЛИС, ещё один производитель, чего там интересного? А интересно там то, что разработка ведётся при помощи самых настоящих Open Source средств разработки. Оказывается, уже есть и такие! Но при использовании этих средств нужно иметь в виду кучку нюансов. Их можно было бы рассмотреть.
Но и это ещё не всё. Так получилось, что меня удручает долгая работа с инструментами для Линукса. Но оказывается, те самые Open Source средства можно собрать даже под Windows. Не в эмуляции Линукса под Windows, а просто под Windows. Опять же, сам процесс сборки кажется мне поучительным. Он расширяет кругозор по внедрению других разработок.
Также заказчик подкинул нам марку макетных плат, которые непонятно по какой причине стоят достаточно дёшево. Очень дёшево. Но продаются достаточно давно, чтобы списать это на простой демпинг. Себе я уже взял три штуки от жадности, хоть есть там и нюансы. Про них тоже можно было бы поговорить.
В общем, можно было бы рассмотреть всё это дело в виде нескольких статей. Но будет ли это интересно? Если нет, то лучше не тратить время на написание, а потратить его на что-то другое.
Комментарии (14)

Almighty_Goose
28.10.2021 00:40Смотрю на все эти пляски с бубнами и понимаю, что под Linux писать гораздо проще. Можно даже не использовать libpcap, а сразу открывать пакетный сокет (man 7 packet).
Лет 15 назад в моей работе, когда был выбор использовать дальше libpcap, с новой версией которого перестала работать программа после обновления морально устаревшего дистрибутива Linux, мой выбор всё же пал именно на пакетный сокет, т.к. развесистая функциональность pcap была не нужна. Фактически, задача стояла только принимать пакеты одинакового размера и извлекать массивы данных по заданному смещению. Сам формат пакетов не был стандартным протоколом (не только не TCP/UDP, но даже не IP), потому что разработчик железки пожалел ресурсы ПЛИС. Подтверждение получения пакета (ACK) передавалось через другую аппаратуру с гарантированной доставкой.
Для ускорения можно использовать packet mmap, до чего у меня руки не дошли, т.к. всё замечательно работало и без него.

myxo
28.10.2021 01:55О да, на линуксе с этим обстоит куда приятнее. Вообще на винде тоже есть raw sockets, но они как-то сильно обрезаны (как говорят, для безопасности). Самая проблема там - очень ограниченная возможность устанавливать фильтрацию трафика в ядре. По крайней мере у меня в свое время так и не получилось фильтровать udp broadcast по порту, все в юзерленд сваливалось.

EasyLy Автор
28.10.2021 04:02Тут кроме самого функционала, как я отметил, очень важно, что когда все галки сняты - к адаптеру никто не полезет. Их просто не пустит система. Если же поставить буквально одну галку IPv4, то тут же начинают лезть всяческие пакеты от различных протоколов в больших количествах.
В реальной жизни это не так страшно. Но во время отладки, особенно когда на том конце подключён логический анализатор с не самой развитой системой фильтрации (а при работе с ПЛИС Lattice под Open Source средствами разработки особого выбора нет) - все эти пакеты портят жизнь.
При таком же подходе, получил сетевушку в монопольный доступ и отлаживай всё, контролируя каждый пакет в кабеле. Даже ARP пакеты - только вручную. Чтобы проверить поведение отлаживаемой системы при разных сценариях. Собственно, сейчас мне предстоит чинить реализацию этого ARP, так как при требуемой частоте 125 МГц, штатное (по мнению Заказчика) решение с Гитхаба даёт на требуемой ПЛИС параметр FMax = 64 МГц, и критические цепи относятся как раз к ARP. Эту подсистему придётся сильно перепахивать.
Вот когда будет отлажено - тогда уже можно выпускать всё в реальный мир, с кучей левого трафика и автоматической работой с той же ARP.
Almighty_Goose
28.10.2021 15:04С пронырливыми сервисами, лезущими куда не попадя, проблема и на Linux есть. Можно резать трафик используя фаервол на сервере или аппаратным фаерволом на openwrt.
С ARP - для своих некоммерческих проектов его можно просто не имплементировать: что Window, что Linux позволяют задать соответствие MAC-IP консольной магией "arp -s ip mac".
На Linux поинтереснее. Есть такое понятие как Gratuitous ARP - когда устройство при включении или периодически рассылает всем свой ARP-ответ, хотя его никто не спрашивал. Естественно, на этом можно построить атаку, перехватив чужой IP на свой MAC. Почему, собственно, gratuitous ARP не используется. Однако, в настройках sysctl для ядра Linux можно разрешить gratuitous ARP для своих интерфейсов.
Впрочем, ARP очень простой протокол, не понимаю как для него сфитировалось 64МГц Fmax. Вот, для DHCP я бы однозначно сказал "верю".
EasyLy Автор
28.10.2021 19:44Пока только могу сказать, что там у автора идёт две ОЗУшины ARP кэша, потом - куча логики и только потом результат защёлкивается. Кое-что уже удалось конвейеризировать, уже FMax не 64, а 83 МГц. Завтра продолжим разбираться, что можно сделать. На данный момент, я не понимаю, как имеющаяся ветка вносит нынешнюю задержку. Возможно, это вообще транспортная задержка, возникающая при разводке.
EasyLy Автор
21.11.2021 21:51Впрочем, ARP очень простой протокол, не понимаю как для него сфитировалось 64МГц Fmax. Вот, для DHCP я бы однозначно сказал "верю".
Всё, разогнал. Теперь могу вкратце сказать, кто был виноват в том конкретном случае, помимо задержек от ОЗУ. Многобитные функции. 48 битное сравнение MAC, 32 битное сравнение IP с текущим, а также с FFFFFFFF для бродкаста. А ещё и с наложением маски подсети... Всё пришлось конвейеризировать.
Штатный опенсорсный проект собирает 48 и 32 битное значение MAC и IP соответственно, потом - сравнивает. Чтобы разогнать - по мере прихода байтов сравниваем. Потом - просто операцию "И" над шестью или четырьмя битами результатов побайтного сравнения выполняем.
Но это ещё не всё. У ARP таймауты есть. 2 секунды для ретрейнов и 30 для последней попытки. Они задавались в тиках 125 мегагерцового таймера. Итого у автора использовался 36 битный счётчик. Пришлось разбить его на три. Один генерит мегагерцовые тики, второй - килогерцовые, третий уже в миллисекундах таймауты отсчитывает. При такой разрядности каждого счётчика, быстродействие выходит в приемлемый диапазон
Ну, и прочие подобные уменьшения разрядности. Латтис и Yosys/NextPNR иначе не позволяют официальное решение найти. При этом проект с плохим FMax по факту работал. Но без гарантий.
Almighty_Goose
22.11.2021 22:1464MHz*2=128MHz, т.е. даже вполовину уменьшив сложность комбинаторной функции в боттлнеке, можно уместиться в 125МГц. Что вы успешно и проделали.
Хорошая работа, поздравляю!
Опенсорсную реализацию ARP, скорее всего, делали на Altera или Xilinx, там достаточно просто выбрать чип с соответствующим speed grade. Не знаю как обстоит дело со speed grade в Lattice, всё-таки их традиционно считают более энергоэффективными и дешевыми, чем производительными. А я больше работаю с Altera.
В отчете Fmax всегда пессимистичный. Реальный Fmax чаще выше, даже при минимальном охлаждении чипа. Ну и среднее качество чипов FPGA выше минимума. Потому в штучных экземплярах еще можно рассчитывать на удачу, а в массовых образцах нет.
Но это все довольно банальные и очевидные факторы.

VBKesha
28.10.2021 00:47+1В общем, можно было бы рассмотреть всё это дело в виде нескольких статей. Но будет ли это интересно?
Мне было бы интересно.

shuhray
28.10.2021 18:55Можно поставить Nmap, там есть библиотека для сырых (raw) пакетов, а писать скрипты придётся на Lua (язык простой и приятный, Wireshark его тоже поддерживает).
EasyLy Автор
28.10.2021 19:51Мне его пришлось поставить, чтобы запускать ncat, так как исходный проект для ПЛИС рекомендует вести тестирование с помощью netcat. Гугль сказал, чтобы я под Windows использовал ncat и не мучился.
Я точно не изучал, как там всё устроено, но при установке NMap, он предлагает поставить всё тот же NPap. Так что не удивлюсь, если он через этот же драйвер всё и реализует. Но и не поручусь.
shuhray
28.10.2021 20:55Конечно, через него же, но там удобные библиотеки для разных сетевых протоколов (для сырых пакетов, опять же, обёртка WinPcap, но гораздо проще писать на Lua, чем на С++).
EasyLy Автор
29.10.2021 02:06В 2006-м внедряли мы в систему для газоанализатора поддержку LUA. И потом переписывали плюсовые алгоритмы, сделанные на первом этапе, на этот скрипт. Обработка ошибок стала занимать 2/3 кода и загромождать пространство так, что основной алгоритм стало не видно. Может, с тех пор что-то и поменялось, но мой опыт говорит, что вряд ли "гораздо проще на нём писать". Скорее, кто к чему привык.
myxo
Npcap хорош, но у него есть фатальный недостаток — он платный, если использовать на более чем 5 устройствах. Я с болью предвижу момент когда WinPcap перестанет работать и придется велосипедить свой драйвер.
Поделюсь своим (откровенно говоря небольшим) опытом. Сама библиотека pcap действительно работает более менее одинаково на винде и линуксе, разве что в WinPCap есть дополнительные функции с приставкой _ex, которых в libpcap нету.
Но там есть нюансы (как я понимаю на уровне ниже, в реализации сетевого стека). Например функция для чтения pcap_next_ex на винде разблокируется, после прохождения таймаута, заданного в pcap_open_live. В линуксе это не так, она не разблокируется пока на pcap девайс не придет хотя бы один пакет в текущем окне ожидания (справедливости ради, в документации указано, что таймаут не гарантирует разблокировку, но все равно неожиданно). Много функционала я не писал, но подозреваю, что подобных нюансов ещё куча.
EasyLy Автор
Ну, тут главное - знать, что "так вообще можно было". А там - каждый под свои задачи найдёт что-то.
Огромное спасибо за дополнение!