
Мы в «ЛАНИТ — Би Пи Эм» занимаемся построением BPM-решений и автоматизацией бизнес-процессов. Обычно после выпуска первой версии развитие процессов не останавливается и заказчик хочет их улучшать: заменять ручные расчеты на автоматические, убирать ненужные шаги и обращения к устаревшим системам и т. п.
Автоматизированные процессы часто являются отражением реального мира и могут выполняться долго: дни, месяцы или годы. Что делать при выпуске новой версии с теми процессами, что были запущены на старой версии, но не успели завершиться? Их нужно довести до конца по старой версии или мигрировать на середину новой версии и довести уже по ней?
В этой статье я расскажу о проблемах (очевидных и не очень) обновления запущенных ранее процессов и про то, почему обычные подходы к миграции данных не работают в процессных системах на базе BPMN, и приведу несколько инструментов и идей, проверенных нами в реальных проектах на Camunda Platform и Pega Platform. Статья направлена на мидлов и старших разработчиков.

В чём корень проблем?
Возьмём простейший BPMN-процесс с одним ручным шагом, к которому во второй версии добавили возможность альтернативного действия:

При изменении процесса, особенно если мы ничего не удаляем и не изменяем, а только добавляем элементы, интуитивно кажется, что «закон обратной силы не имеет», и старые процессы могут идти по старой версии. Предположим, что BPM-продукт, на котором построено наше решение, так и работает — запоминает версию запущенного процесса. Предположим также, что ручные шаги выполняются в веб-приложении — и у него вышла новая версия, где на форме задачи появилась кнопка «Отклонить». Что же произойдёт, когда пользователь откроет задачу из старого процесса и нажмёт на эту новую кнопку? Наше решение попробует выполнить альтернативное действие на старом процессе, где его нет, что приведёт к ошибке.
Можно было бы потребовать от BPM-продукта, чтобы он переводил все процессы на новую версию автоматически. Рассмотрим этот вариант на примере процесса, в котором в новой версии часть ручных действий была заменена автоматическим выполнением:

Что произойдет в старых процессах, которые ожидали обработки на момент выпуска новой версии? После автоматического перевода на новую версию наше решение будет считать, что шаг с автоматической обработкой уже пройден, и шаг с ручной обработкой выполнит только свою половину работы, как положено по новой версии процесса. В результате мы получим «тихую» ошибку в виде не полностью выполненного процесса, поскольку никто не запустил автоматическую обработку «задним числом».
Стоит ещё учесть, что изменения в процессе могут быть и более драматическими:

В общем случае можно считать, что новая и старая версии — это два разных процесса. Чтобы перейти из одного процесса в другой, нужно описать логику перехода — это описание называется миграцией.
Существует ещё вариант с одновременной поддержкой нескольких версий процесса, но он требует поддержания адаптеров для каждой версии в разных компонентах решения (веб-приложение, бизнес-логика). По нашему опыту, это дорогостоящий и хрупкий вариант, поэтому мы не будем его рассматривать в этой статье.
Итак, мы познакомились с причинами проблем и наметили ключевую цель — после выпуска новой версии решения все процессы должны мигрировать на самую последнюю версию. Вопрос — как этого добиться?
Нужно просто описать миграции в SQL!
Те, кто знаком с подходом Evolutionary Database Design, скажут: «Состояние процесса — это же обычные данные в реляционной БД. Нужно описать миграцию как SQL-скрипт и опубликовать его в репозитории для инструмента типа Flyway / Liquibase».
Для тех, кто не знаком с этим подходом, расскажу в двух словах:
Изменения в структуре БД описываются как инкрементные SQL-скрипты от предыдущего состояния структуры к желаемому.
Помимо DDL скрипты могут содержать DML и даже запуск процедур для выполнения миграции данных.
Скриптам присваивается порядковый номер (например, числовой префикс в названии файла скрипта), и они сохраняются в репозиторий вместе с исходным кодом.
Скрипты упаковываются в приложение и выполняются по порядку при старте приложения специальным служебным инструментом, который анализирует, какие скрипты уже были применены к этой БД.
Состояние процесса действительно представляет собой несколько строк в таблицах БД, а развитие BPMN-схемы процесса похоже на развитие структуры БД. Нюанс с состоянием процесса в том, что это не непосредственная часть вашего решения, а часть используемого BPM-продукта, его инкапсулированный компонент, вторгаться в который не совсем корректно с точки зрения проектирования. Перечислю конкретные практические минусы:
Состояние процесса состоит из точек, где остановился процесс, переменных, подпроцессов и др. — это достаточно сложный набор данных, поэтому скрипты будет тяжело писать и поддерживать.
В некоторых продуктах может применяться объектная сериализация переменных или всего состояние процесса, формат будет не обязательно общеупотребимым текстовым типа JSON, в худшем случае это может быть проприетарный бинарный формат.
При обновлении версии самого BPM-продукта в вашем решении формат хранения состояния процессов в нём может поменяться.
Получается, что сам подход выглядит применимым, но вот инструмент и способ описания миграций нам не подходят.
Тогда как описывать миграции?
Если работа с состоянием процесса напрямую на уровне БД исключается, нужно обратиться к тем средствам, которые предоставляет и рекомендует BPM-продукт.
Хорошие BPM-продукты предоставляют API, которое при описании миграций позволяет:
Изменять текущие точки остановки процесса: создавать новые, превращать их в другие точки остановки, удалять.
Запускать и останавливать подпроцессы.
Запускать шаги, которые необходимо выполнить «задним числом», например, вычисления и вызовы других систем.
Изменять переменные процесса.
Язык и детали этого API сильно зависят от BPM-продукта, иногда несколько вышеописанных задач решается одной операцией в API. Некоторые задачи миграции решаются API для выполнения прикладных действий над процессом, например: выполнение задачи, получение сообщения.
Можно выделить несколько паттернов для описания миграций, которые применимы в разных BPM-продуктах.
Паттерн Legacy Branch
Этот паттерн применим, когда новая версия не должна иметь обратной силы и запущенные процессы должны выполниться по старой версии.
")
Механизм работы:
Старый шаг / ветка остаются на новой схеме процесса наряду с актуальными шагами.
В старый шаг нет путей для входа, т.е. в него не могут прийти новые процессы.
Если нужно, отдельные шаги этой старой ветки могут быть скорректированы / удалены по сравнению с изначальным старым вариантом, чтобы корректно интегрироваться в новую версию.
Плюсы:
Крайне прост в использовании.
Реализуем практически в любом BPM-продукте.
Минусы:
Схема процесса замусоривается старыми версиями, которые можно удалить только, когда на всех стендах завершатся старые процессы.
В других компонентах решения (веб-приложение, API) необходимо также оставить поддержку старых версий.
Паттерн Migration Island
Этот паттерн применим, когда происходят изменения внутри процесса / подпроцесса: удаляется шаг, изменяется тип шага, шаг заменяется на подпроцесс. Отдельно стоит отметить применимость для ситуации, когда появляется обязательный шаг, который нужно выполнить «задним числом».
")
Механизм работы:
Шаг, на котором остановился процесс, остается на схеме процесса, но без путей для входа, т.е. в него не могут прийти новые процессы.
После него, если необходимо, добавляется ветка с дополнительными шагами для миграции.
Заканчивается старый шаг / ветка переходом на тот шаг нового процесса, который является новой точки остановки.
В описании миграции старый шаг процесса программно завершается, что запускает выполнение дополнительных шагов и переход в нужную точку остановки.
Похож на Legacy Branch, но ключевое отличие в том, что старая ветка выполняется во время миграции, а не в прикладном сценарии.
Плюсы:
Можно реализовать почти любые преобразования в процессе и дополнительные шаги.
Логика миграции проста и наглядна.
Реализуем практически в любом BPM-продукте.
В других компонентах решения (веб-приложение, API) не нужно оставлять поддержку старых версий.
Минусы:
Схема процесса замусоривается деталями миграции, особенно, если в одной версии несколько таких «островов».
В аудите процесса будет запись о фиктивном выполнении старого шага.
Паттерн Migration Ticket
Если в новой версии процесса много шагов с одинаковым способом миграции или происходят структурные изменения в дереве подпроцессов, например, целый подпроцесс теряет актуальность, то можно использовать этот паттерн.
")
Механизм работы:
Изменяемый шаг, набор шагов или подпроцесс остаётся на схеме процесса, но без путей для входа, т.е. в него не могут прийти новые процессы.
На нужном уровне иерархии подпроцессов добавляется обработка события — обычно это Signal / Message Boundary Event.
После него, если необходимо, добавляется ветка с дополнительными шагами для миграции.
Заканчивается старый шаг / ветка возвращением на нужный шаг нового процесса.
В описании миграции программно отправляется событие во все/определённые процессы, что отменяет выполнение любых изменяемых шагов и запускает выполнение ветки миграции.
Похож на Migration Island и на обработку ошибок типа try/catch.
Плюсы:
Позволяет запускать и останавливать подпроцессы.
Минусы:
Требует какого-то механизма событий в BPM-продукте.
Схема процесса замусоривается шагами миграции.
Что можно забыть при описании миграции?
Некоторые ошибки при описании миграций не приведут к немедленному сбою во время миграции, а оставят процессы в неконсистентном состоянии, что приведет к ошибкам при дальнейшем продвижении по процессу — это самый неприятный вид ошибок. Несколько примеров:
Не учесть асинхронные ответы, которые придут из других систем после исчезновения шага.
Не обновить переменные процесса или другие данные, сопровождающие процесс.
Не выполнить обязательные шаги «задним числом», например, не заполнить данные расчета, которые должны быть получены на добавленном в начало процесса шаге
Не запустить подпроцесс, который теперь обязательно должен сопровождать основной процесс.
Миграцию описали, можем выпускать?
Прежде чем выпускать новую версию процесса, нужно решить ещё один вопрос, который проще всего объяснить на примере.
Допустим, вы разрабатываете версию 3 процесса, при этом на промышленном стенде установлена версия 1, на тестовом — версия 2. Версия 2 вполне может никогда не добраться до прома, но она уже установлена на другой стенд, который нельзя откатить к версии 1. Каким образом следует описывать миграции — мигрировать инкрементами с версии 1 на 2, а с 2 на 3, или сразу полностью с версии 1 на 3?
Полные миграции требуют меньше времени на выполнение, но сложно предугадать, с какой на какую версию может потребоваться мигрировать. Инкрементные миграции повторяют проверенный подход эволюционного развития схемы БД, но требуют последовательного выполнения нескольких миграций для каждого процесса. Выбор зависит от специфики решений, для нас хорошо подошёл инкрементный подход.
Кто будет запускать миграции?
Для запуска миграций можно использовать следующие способы:
Ops Team вручную определяет процессы, необходимые миграции и применяет их.
Ops Team вручную запускает только фазу миграции, а определение процессов, список миграций и их применение выполняется автоматически.
Все шаги, включая запуск фазы миграции, выполняются автоматически.
По нашему опыту, чем меньше будет ручных шагов, тем лучше, но более автоматизированные способы требуют более продвинутого инструмента. Далее мы обсудим подход в реализации полностью автоматизированного способа.
Как лучше выполнять миграции?
Детали запуска и выполнения миграций зависят от BPM-продукта: какие средства администрирования он использует, доступен ли в нём планировщик, поддерживает ли он явно версионность процессов и т. д. Постараемся выделить общеупотребимые идеи.
Самый простой вариант автоматической реализации:
Запустить фазу миграции при старте приложения (listener или аналоги).
Синхронно сформировать список процессов и требуемых миграций.
Синхронно применить все миграции.
Продолжить старт приложения.
Этот способ очень популярен в тех решениях, что мы видели, и мы рекомендуем использовать его, пока позволяют масштабы.
С ростом приложения у этого варианта начинаются проблемы с масштабированием:
Определение списка процессов и миграций занимает значительное время.
Применение миграций занимает значительное время.
Применение миграций требуется балансировать по кластеру.
Логично переводить синхронные шаги в асинхронное выполнение через планировщик. При этом необходимо учитывать нюансы:
Миграции должны применяться после того, как приложение и BPMN-продукт запустились.
Запуск фазы миграции, формирование списка процессов и требуемых миграций необходимо выполнить ровно один раз, нужен кластерный планировщик.
Задачи применения миграций можно распределять между узлами кластера через кластерный планировщик.
Необходимо балансировать по узлам кластера нагрузку выполнения миграций и прикладную нагрузку, возможно, следует выделить несколько узлов исключительно под миграции.
Необходимо предусмотреть стратегию обработки ошибок на каждом из шагов.
Самая неприятная сложность асинхронного выполнения миграций — это потенциальная недоступность процессов. В промежутке между запуском приложения и завершением миграций для отдельно взятого процесса (пока процесс ожидает миграции в планировщике) попытка работать с ним в приложении может привести к ошибкам и неконсистентным данным. Может потребоваться реализовать специальную обработку входящих запросов к таким процессам: отказ с ошибкой, постановка в очередь и т. п.
Как итог мы рекомендуем использовать следующую стратегию: выполнять миграции синхронно, пока их скорость позволяет, и не открывать доступ к процессам до их завершения. Только после исчерпания возможностей синхронного выполнения переходить к более сложному асинхронному выполнению, при этом придётся решить проблему недоступности процессов.
Заключение
Запущенные процессы обновляются во время своей жизни, как и другие структуры данных в наших решениях. Чаще всего BPM-продукт не может самостоятельно определить, как выполнить эти обновления, и команде необходимо описать правила для миграции.
Миграция запущенных ранее BPM-процессов — нетривиальная задача, которая при этом не очень хорошо покрывается в популярных BPM-продуктах, даже коммерческих. Команде стоит посвятить время получению экспертизы в этом вопросе, изучить ресурсы о выбранном BPM-продукте. Постепенно в команде можно накапливать удачные подходы и готовые компоненты, чтобы снизить сложность и стоимость решения задачи миграции.
Надеюсь, статья поможет вам понять основные проблемы и пути решения задач, связанных с миграцией процессов. Буду благодарен за вопросы и дополнения в комментариях.
Комментарии (9)

ultrinfaern
29.11.2021 19:04+2Почему у всс все варианты - нарисовать в новой схеме какие-то шаги миграции.
Почему бы не написать вообще внешний мигратор, у которого будет таблица : старый шаг, новый шаг, код который нужно выполнить, включая и модификацию переменных процесса. Единственная проблема здесь, если без ручного вмешательства миграция невозможна, нет данных. Ну по крайней мере можно выбрать хоть какой-то шаг с минимумо потерь.

oefimov Автор
30.11.2021 14:23Спасибо за дополнение, это вполне валидный вариант миграции. Некоторые BPM-продукты даже имеют поддержку подобных миграций, например, у Camunda есть Cockpit.
Есть ограничение -- ни Camunda, ни Pega не предоставляют API, чтобы мигрировать шаг с изменением его типа: ручной в автоматический, автоматический в подпроцесс и другие комбинации. Для решения этой проблемы мы применяем варианты с шагами миграции на схеме -- например, паттерн Migration Island.
ultrinfaern
30.11.2021 15:09Спасибо. Я в камунде только мельком читал про миграцию, и о таких ограничениях не знал.
Как вариант, при миграции, если это не ручной шаг, пинать процесс дальше, срывая например время ожидания, или генерируя событие, чтобы перейти в то состояние которое легко мигрировать.
С другой стороны, если полезть напрямую в базу, конечно ограничений нет. :)

Alex_BBB
30.11.2021 12:53Спасибо за статью. Небольшое дополнение.
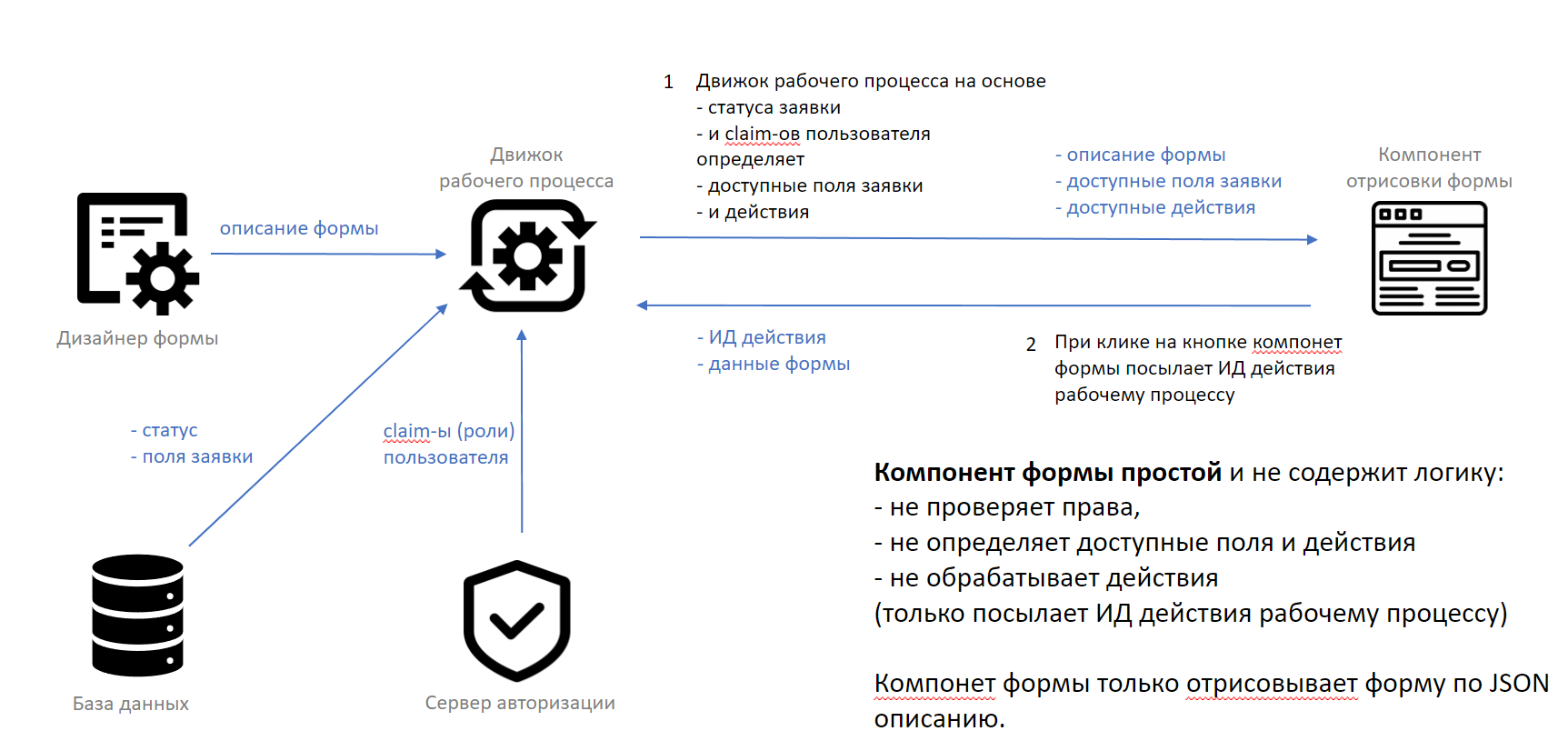
Предположим также, что ручные шаги выполняются в веб-приложении — и у него вышла новая версия, где на форме задачи появилась кнопка «Отклонить». Что же произойдёт, когда пользователь откроет задачу из старого процесса и нажмёт на эту новую кнопку? Наше решение попробует выполнить альтернативное действие на старом процессе, где его нет, что приведёт к ошибке.
Есть вариант когда доступность кнопок описывается в рабочем процессе. Веб-приложение только рисует кнопки полученные от рабочего процесса.
Тогда описанной выше проблемы не будет: задачи новой версии рабочего процесса будут иметь кнопку, для старых задач кнопки не будет. Конечно это не отменяет необходимости миграции если нужно и старые задачи перевести на новый процесс.
Самореклама:
видео прототипа движка рабочих процессов с генерацией кнопок (4 мин)
https://vimeo.com/632994077online демо конструктора форм
https://alexeyboiko.github.io/FormDesignerDemo/презентация
https://1drv.ms/p/s!AtucE3yK2YmNg0OdNt0FmTKnKfZZ?e=zGmp4oultrinfaern
30.11.2021 15:02Как я понял, у вас весь процесс завязан на одной форме. И в зависимости от текущего шага вы или показываете поле или нет.
Все движки BPM работают по-другому. В процессе есть точка - ручное вмешательство. Вот для этой точки и рисуется форма. И проблемы с полями нет - так как иначе вы бы вообще не увидели данную форму, ели бы она вам не пришла по процессу. Плюс для каждой точки рисуется своя форма, сложной логики что показывать а что нет здесь нет - показывается вся форма.
Alex_BBB
30.11.2021 15:29Как я понял, у вас весь процесс завязан на одной форме.
Нет, форм можно сделать сколько угодно. Движок выбирает форму (а точнее описание формы) в зависимости от текущего пользователя и статуса объекта (заявки/задачи). Так же выбираются и доступные действия (кнопки): от текущего пользователя и статуса.
oefimov Автор
30.11.2021 15:33+1Спасибо за предложенный вариант. Конечно, кнопки -- это лишь пример, измениться может и состав отображаемых / вводимых данных на форме.
Поэтому в общем случае этот вариант требует передачи BPM-продуктом, помимо данных формы, её полного метаописания, достаточного для генерации экранной формы универсальным интерпретатором метаязыка. В этом случае в каждую версию процесса заложены метаописания каждого шага, что позволяет корректно отображать формы старых версий процесса.
К сожалению, сам подход с отрисовкой форм по метаописанию, по нашему опыту, годится только для прототипирования и простейших приложений. В решениях, над которыми мы работаем, этот подход не справляется с требованиями к современным UI/UX. Попытки наращивать функциональность метаязыка приводят, в конечном итоге, к изобретению аналогов HTML/CSS/JS. Более перспективной альтернативой мне видится отрисовка на фронте экранной формы с учётом версии процесса, а не только идентификатора шага.
Но, в любом случае, ещё остаётся проблема с шагами других типов -- например, заполнением / разбором интеграционных сообщений в автоматических шагах. Здесь по-прежнему потребуются адаптеры для разных версий.
Alex_BBB
30.11.2021 16:22+1Попытки наращивать функциональность метаязыка приводят, в конечном итоге, к изобретению аналогов HTML/CSS/JS
Это точно. С конструкторами форм нужно знать меру. Думаю что конструктор должен уметь
задавать проверку полей по regex
скрывать/показывать поля в зависимости от значения других полей
настраивать связанные выпадающие списки
Все остальное в конструктор не пихать. С таким набором функций конструктором еще можно пользоваться.
Однако, ограничение конструкторов не означает что они нигде не применимы. Для многих задач конструкторов хватит. Взять хотя бы SharePoint - там вообще можно только местами поля менять.
В прототипе (давал ссылку выше) для случаев когда конструктора не хватает предлагается реализовать самодельные контролы (индивидуально под заказчика). И вставлять эти самодельные контролы в формы, так же как и предустановленные контролы, через дизайнер.
Концепция “сделай рабочий процесс без программистов” немного страдает, но в целом полезность движка рабочий процессов сохраняется: настройка статусов и переходов, обработчики команд, доступность форм/полей, история рабочего процесса, логирование и проч.
Keeper1
И где тут про гидралисков?