

Н. Кобринский, В. Пекелис «Быстрее мысли» — Молодая гвардия, 1959
Когда все вокруг измеряют Гигабайтами, Петабайтами, Зетабайтами и т.д., все компании гордятся своей БигДатой, вспоминать о битах в приличном обществе воспринимается как моветон. Однако и биты иногда бывают полезны. Темой для разговора послужила одна типовая классическая задачка, лежащая в области опросов.
Является продолжением серии предыдущих публикаций.
Постановка задачи
В компании X происходит очередной ребрендинг. Пригласили дорогостоящих спецов, они выкатили на общественное голосование 6 вариантов логотипов. Тут и «стремительная I» и «бесконечно многогранная O» и «гибкая W» и «строгий графит» и «веселый лайм»...
Собрали с сотрудников ответы, каждый должен был написать набор чисел из множества [1; 6], соответствующих понравившимся логотипам. Некоторые были четко уверены и указали только один вариант. Другие занимали различные точки зрения и указали все 6. Третьи выбрали умеренность и указали что-то посерединке.
Получили мы на вход примерно такой набор данных по которому надо выбрать самый популярный логотип.
uid vote
1: id001 6,5,3
2: id002 5,3,4,2,1
3: id003 2,5,4,3
4: id004 1,4
5: id005 2,3,5,1
6: id006 3
7: id007 6,3
8: id008 2,5,6,4,3Задача простая, решается миллионом разных способов. Но попробуем немного добавить в нее разнообразия.
Вариант 1
Классический выпускник DS курсов предложит все это преобразовать в прямоугольную таблицу и потом, возможно путем pivot преобразований, посчитать различные отношения. Засада в неквадратности данных, но это вполне обходимо.
На выходе может получиться примерно такой код:
library(tidyverse)
# эмулируем данные
df <- tibble(
id = 1:3,
answer_1 = rep(1, 3),
answer_2 = rep(2, 3),
answer_3 = c(3, NA, NA),
answer_4 = c(4, NA, 4),
answer_5 = rep(5, 3),
answer_6 = rep(6, 3)
)
df %>%
pivot_longer(-id, names_to = NULL, values_to = "brand_id") %>%
filter(!is.na(brand_id)) %>%
group_by(id) %>%
summarise(
recognized_brands = list(brand_id),
unrecognized_brands = map(recognized_brands, function(x) setdiff(x = 1:6, y= x))
) %>%
unnest_longer(recognized_brands) %>%
unnest_longer(unrecognized_brands) %>%
pivot_longer(-id, names_to = "type", values_to = "brand_id") %>%
filter(!is.na(brand_id)) %>%
distinct() %>%
group_by(brand_id, type) %>%
summarise(N = n()) %>%
pivot_wider(names_from = type, values_from = N, values_fill = 0) %>%
mutate(brand_recognition = recognized_brands / (recognized_brands + unrecognized_brands))Получаем примерно такой ответ:
# A tibble: 6 x 4
# Groups: brand_id [6]
brand_id recognized_brands unrecognized_brands brand_recognition
<dbl> <int> <int> <dbl>
1 1 3 0 1
2 2 3 0 1
3 3 1 2 0.333
4 4 2 1 0.667
5 5 3 0 1
6 6 3 0 1 Неплохо, результат получен. Чего еще хотеть?
Вариант 2
Если нас никак не интересуют показатели в разрезе отдельных сотрудников, то мы можем поступить чуть проще. Свалим все в кучу и в ней же посчитаем.

Прямо Спортлото какое-то. Куча шаров и 6 цифр.
library(tidyverse)
# подготовим тестовые данные =============
df <- tibble(uid = sprintf("id%03d", 1:100)) %>%
rowwise() %>%
mutate(vote = list(sample(1:6, runif(1, 1, 6)))) %>%
ungroup()
# расчеты
unlist(df$vote) %>%
janitor::tabyl()Получаем ответ в одну строчку
. n percent
1 54 0.1703470
2 55 0.1735016
3 52 0.1640379
4 52 0.1640379
5 52 0.1640379
6 52 0.1640379Вариант 3
Предположим, что нам будет важна исходная таблица по распределению ответов каждого сотрудника в Excel. Т.е. все эти циферки 1..6 надо разнести по 6-ти колонкам. Вариант 1 мы уже имеем с преобразованиями из длинного в широкое и наоборот.
Но есть и другой веселый способ. Используем его, чтобы поговорить про биты и двоичную систему счисления.
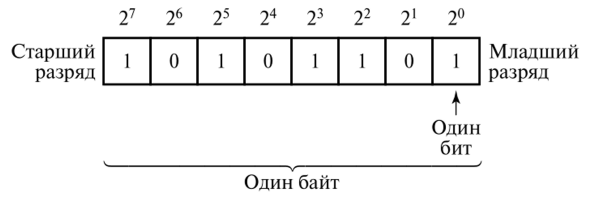
Что есть таблица ответов? По сути, это матрица с 0 и 1, где колонки соответствуют номеру логотипа, а строчки — мнению каждого отдельного сотрудника. Если ответ бинарен, а позиций всего 6, то у нас есть прекрасная возможность использовать двоичное представление чисел для кодирования ответов.
Не будем морочиться с сопоставлением номеров ответов с соответствующими колонками, не будем заниматься сортировкой ответов. За нас все сделает машина.
Просто скомпонуем числа, размещая 1 в тех битах, которые соотв. заполненным номерам. Делаем это с помощью суммы степеней двойки (см. картинку). Дальше можно провести битовые векторизированные вычисления с применением AND по соответствующему разряду, сдвигу вправо или же можем просто преобразовать в матрицу.
library(tidyverse)
library(bitops)
# подготовим тестовые данные =============
df <- tibble(uid = sprintf("id%03d", 1:100)) %>%
rowwise() %>%
mutate(vote = list(sample(1:6, runif(1, 1, 6)))) %>%
ungroup()
# решаем задачу =============
# конструируем битовую маску ответов для каждого человека
res_df <- df %>%
rowwise() %>%
mutate(mask = sum(2^vote),
logo = matrix(
as.logical(bitAnd(mask, c(1, 2, 4, 8, 16, 32))),
nrow = 1)
) %>%
ungroup()
# матрицу преобразуем в целочисленную
mm <- res_df$logo * 1L
sum(mm)
# считаем по колонкам
colMeans(mm)
colSums(mm)Заключение
Грузить и трансформировать Большие Данные — важная и нужная задача. Но если вспоминать про базовые вещи, то иногда задачи можно решать веселее и экономнее. И иногда спускаться из облаков и петабайтов и вспоминать про существование битов.
Предыдущая публикация — «Забираем большие маленькие данные по REST API».
Комментарии (29)

Moskus
18.12.2021 06:33+1По привычке экономить память, использую битовые данные, например, для задания выборочной обработки деталей в групповой оснастке на станке с ЧПУ. Куда проще хранить маску в одной переменной, а в подпрограмме делать сравнения с номером текущей системы координат, чем использовать кучу переменных, как флаги и вычислять в подпрограмме номер флага для проверки.

i_shutov Автор
18.12.2021 08:39+1это вообще крайне удобный метод для тех, кто работает с настоящим железом.
Moskus
18.12.2021 16:51Станки с ЧПУ - занятная ситуация, потому что, с одной стороны, их интерфейс достаточно высокоуровневое устройство, работающее под Windows (не всегда, но часто) и так далее. С другой стороны, в этот интерфейс проброшен прямой доступ к регистрам аппаратного контроллера.

uuuuuuuu
18.12.2021 14:07Так даже в современном Fanuc особо не разгуляешься — количество переменных ограничено.
Moskus
18.12.2021 16:45Ну, всякие обходные способы есть. Например, у того же Haas 6+99 рабочих систем координат, столько мало кто использует, так что часть систем можно под флаги отвести. Но это ощущается, как лёгкое извращение.

PKav
18.12.2021 12:18+1В программировании микроконтроллеров и вообще цифровой электронике отдельные биты используются везде и всюду. И я считаю это очень правильным подходом, которым следовало бы оперировать везде, т.к. обработка, передача и хранение данных, закодированных таким образом может осуществляться гораздо дешевле во всех смыслах этого слова. И если программисты серверных и десктопных приложений на это не способны и везде городят какие-то огромные конструкции из кучи абстракций, то за что же им тогда платят такие огромные деньги?

SamaRazor
18.12.2021 12:27+1За то что они решают проблемы бизнеса в срок, а не через 10 лет, наверное.
PKav
18.12.2021 12:29+2Думаю, за такие деньги и с опытом можно сделать и в срок, и оптимально.

Tsimur_S
18.12.2021 12:39Думаю, за такие деньги и с опытом можно сделать и в срок, и оптимально.
Людей делающих в срок и оптимально не хватает, причем не только в программировании а вообще везде. Как дальше поступать, закрывать бизнес?
i_shutov Автор
18.12.2021 13:08при условии что решают.
статистика индустрии показывает почти всегда обратное -- давайте уж честно.
Гартнер, так тот отчет свой писал, что около 70% проектов с бигдатой оказались прожиганием денег.
samsergey
18.12.2021 15:26+1Но ведь именно для этой задачи, в которой надо просто выделить наиболее часто втречающийся элемент выборки, использование бинарной арифметики -- это абстракция, причем неочевидная и строящаяся на предположнении о том, что анализируемые данные вписываются в байт или слово. Эффективность этого решения (на Питоне) будет заметной только для миллионов подобных анкет, а подднржка этой абстрации при небольшом изменении методов опроса (добавлении веса, например) приведет к существенному перестроению и логики и используемых данных. Так что абстракции в программировании неизбежны, и больше платят за те, которые делают работу програмииста более предметно-ориентированной.
i_shutov Автор
18.12.2021 15:53+1Эта задача -- просто повод поговорить про иные методы. Если в руках только молоток, то кругом одни гвозди. У специалиста же будет целый авто инструментов. Мы же бенчмарки здесь не гоняем... ну и тут же можно было бы про разрежённые матрицы побеседовать, но это был бы перебор.

Kelbon
18.12.2021 20:45+1обработка битов медленнее обработки байтов. Так что нет, это не быстрее. А платят разработчикам серверных и прочих приложений за качественный код, который потом можно редактировать, а не копаться в битах и разбираться почему после изменения sizeof структурки всё упало
i_shutov Автор
18.12.2021 23:00тут вроде как тема DS затрагивается. у разработчиков ПО другие приоритеты и другие задачи. Работа с битами может быть такой же быстрой -- логическое И/ИЛИ над словом и маской -- примерно такая же операция в конвейере ALU. Но даже не в этом суть. Еще раз повторю, задача -- как предложение посмотреть вокруг себя. Допускаю, что тем, кто на ассемблере не писал, все это кажется странным и ненужным...
Кстати, насколько давно доводилось видеть качественный код приложения? Не какой-либо отдельной функции отдельного разработчика, а именно приложения? Какого-нибудь?

orekh
18.12.2021 13:06+2Вопрос по входным данным. Каждый голосующий подает бюллетень с массивом ответов. Что значит позиция ответа? По мнению голосующего: те ответы, что стоят в начале массива более предпочтительны, чем те что в конце; или равнозначны?
i_shutov Автор
18.12.2021 13:07+1задача самая простая -- равнозначны.
можно считать, что это голосование за паб для отмечания корп. нового года :)
zaiats_2k
19.12.2021 13:51С пабами всё совсем не просто. В этом я на прошлой неделе устроил дебош и меня туда теперь не пускают. А в том пиво разбавляют. А в третьем - скользкие ступеньки, но не все об этом знают, потому что зимой ещё не заходили туда.
i_shutov Автор
19.12.2021 14:02Все неважно.
С новогодними пабами все предельно просто -- наступает точка невозврата.
В определенный момент остается два варианта -- либо прекращаем строить сложные модели, есть друг другу мозг и хватаем то, что еще пока осталось, либо просто никуда не идем.
И это замечательно, поскольку без внешнего меча очень часто все превращается в бесконечную жвачку.

RolexStrider
18.12.2021 20:05+1И в гига и в пета и в зеттабайтах найдется место битам. Возьмем к примеру современные СУБД, хотя бы MS SQL. Есть поле (для простоты) типа tinyint. Может хранить значения 0...255. Надеюсь ясно, что это 8 бит. Но! при условии что оно объявлено как NOT NULL. Значит NULL - это 256-е значение. Но вот в 8 бит (в байт) оно уже не помещается. Нужен хотя бы еще один бит, котроый был бы признаком того, что в этом поле - NULL. Но при этом введение такого бита напрочь сломает всё выравнивание данных по границе байтов.
Поэтому (в MSSQL, и скорее всего в большинстве СУБД) NULL-ы хранят отдельно от данных (но недалеко), в "bitmap"-ах. То есть в массиве бит, каждый из которых говорит о том, NULL или не-NULL в соответствующем ему значению в "реальной" таблице.
И любая операция над полем, допускающим NULL (даже тупо сравнение, т.к. NULL не равен ничему, включая NULL), помимо обращения к данным основной таблицы обязательно требует обращение к этому bitmap-у. И это не самая простая операция.
Так что при проектировании схемы БД - везде где только можно - объявляйте поля как NOT NULL.
Биты рулят.i_shutov Автор
18.12.2021 22:53Спасибо, отличную тему затронули. Далеко не все об этом даже задумываются. Altinity в каком-то из видео рассказывают, что один из первых тезисов, который доводят при обучении CH -- не использовать NULL везде, где это возможно.

Filipp42
19.12.2021 00:41О! Не думал, что кто-нибудь вспомнит "Быстрые мысли".
i_shutov Автор
19.12.2021 08:20А почему бы и нет? Послевоенные книги по естественным наукам очень хорошо читать. Экстренное воспитание тысяч инженеров было жизненно необходимо. Материал подавали без всяких "очевидно" и небрежностей. Четко, ясно, доходчивым языком.
И справочники весьма качественные. Кстати, и книги по радиоэлектронике тоже хороши. Пусть на лампах, но принципы на пальцах показывают.
Кто думает, что память на ферритовых кольцах в прошлом? Можно заглянуть в военную технику, чтобы понять что это заблуждение.
Filipp42
19.12.2021 15:44Да, жалко, сейчас таких не пишут. Быстрые мысли хорошо было бы переиздать. Да и не только их.
Volrath
20.12.2021 11:11+1Только сейчас увидел, что моё решение из чата стало примером для "типичного выпускника DS курсов"))
Так приходит слава. Спасибо, Илья)
i_shutov Автор
20.12.2021 11:12+1Это было дано с большим уважением и без каких-либо купюр. Это действительно типовой подход, никаких тайных мыслей.
Но этим подходом могут пользоваться и матерые спецы. Только у последних спектр инструментов куда шире и не ограничивается только этим вариантом.
lxsmkv
Так тройка встречается чаще всего, вот и ответ.
i_shutov Автор
Где именно встречается? В генераторе случайных чисел? О чем вообще речь? Метод пристального взгляда?
i_shutov Автор
А, Вы решили, что первые восемь строчек месть задача? Оригинально. Но это совсем не так, это просто фрагмент, какой-то срез. Не знаю, зачем все понимать в худших трактовках? Тем более, что дальше по тексту видно, чтотданнвх куда больше, да и не в этом вообще суть.