
Работая в крупном разработчике и интеграторе решений для маркировки - заметил, что многие участники оборота (т.е. типографии, производители и магазины) не знают об особенностях распознавания маркировки и мало понимания как она распознается, и какие трудности могут быть при ее не правильном нанесении.
Правильность маркировки как раз проверяется ее верификацией на специальных лабораторных приборах - верификаторах 2D кода. О важности верификации для успешной продаже товара на кассе и хочу рассказать.
Немного об эксперименте с маркировкой
Маркировка системы Честный знак - это логическое продолжение цифровизации ритейла. Она позволит сделать продажу товаров прозрачной, и избежать продажи подделки или, того хуже, просрочки. Я намеренно не буду рассказывать о политике и как это все вводится - кому интересно, многие истории гуглятся. Расскажу лишь о технической стороне вопроса - как теперь жить с маркировкой и какие новые термины она нам принесла в жизнь.
Сейчас, на момент января 2022 г. уже вся скоропортящаяся молочная продукция обзавелась кодами DataMatrix GS1, позволяющими заменить штрихкод товара на кассе. Вы можете самостоятельно попробовать "пробить" товар на кассах самообслуживания в Пятерочке, Ашане, ВкусВилл и других супермаркетах - Зачастую, товар без проблем пробьется, как и по обычному штрих-коду EAN-13... Но, иногда он все же не распознается. Вот как с этим быть, как этого избежать - я и хочу рассказать в данной статье.
Распознание Штрих кодов и кодов DataMatrix
Если штрих-код пришел к нам из азбуки Морзе, где ширина линий как раз и означает "длину" импульса для счета - привет аналоговый мир, то 2D DataMarix уже более современен и представляет собой скорее Эксель таблицу с нулями и единицами в графическое исполнение в виде черных и белых квадратов, заключенных между неким постоянным шаблоном, как на Изображение ниже:
")
В чем сложность распознавать? Одна из основных проблем - что мы имеем дело с объектами реального мира, где снять код идеально бинарно - трудно, напечатать его ровно и качественно - трудно, а сохранить его в целости и сохранности от производства до кассы, не испачкав и не стерев по дороге - тоже не тривиальная задача.
Для наглядности, я дошел до ближайшего супермаркета и нашел пару образцов кода, с которым на кассах придется "попотеть":

1ый пример: каплеструйная печать непосредственно на линии. При даже не большой вибрации продукта - сбивается геометрия кода. Разглядеть тут хоть какую-то вменяемую сетку для распознавания кода не так просто. Осложняет все еще и место нанесения, код нанесен на прозрачную крышку, без белой подложки. Его контраст будет не большим - разница между черным и "белым" квадратом (модулем DataMatrix) сетки не велика.

2ой образец - когда код инвертированный. А именно, нанесен с помощью лазерной маркировки. Эта технология выжигает из уже нанесенных черных чернил пигмент, делая модули белыми. Распознается не трудно, нужно лишь инвертировать изображение, как показано далее.

Если программно инвертировать изображение с лазерной маркировки - мы получим весьма качественный код с хорошим контрастом, НО многие OpenSource-распознавалки не умеют самостоятельно инвертировать снимки, необходимо дорабатывать их.

3ий образец мне не удалось найти в торговых сетях, но такая проблема также присутствует - это нанесение кода маркировки без соблюдения "Тихой зоны". Тихая зона - особая граница возле DataMatrix кода, с рекомендованной толщиной от 3-х модулей кода, такая зона обеспечивает поиск и надежное считывание фиксированного шаблона кода. В этой области не должно быть ничего, кроме белого или, в случае инверсного кода, черного фона.
Если вам интересна внутренняя сторона распознавания кода, рекомендую прочитать статью.
Я же продолжу про особенности распознавания: Перед вами пара кодов, имеющих свои особенности распознавания. На кассе встроенная в сканер или саму кассу камера (а 2D коды распознает зачастую именно смарт камера или смарт-модуль, на AliExpress можно найти отдельно модули именно для распознавания маркировки, которые и ставятся в некоторые кассы) делает снимок нашего кода, и честно пытается превратить его в строку символов, и в этом есть особенностей, трудностей и тонкостей:
-
Чем подсветить датаматрикс, чтобы его лучше увидела камера?
Это строго регламентировано ГОСТом, необходимо либо красной подсветкой, либо белой.
Но так как эпоха 1D штрих кодов не закончилась - а они требуют красного света, то зачастую красную подсветку и используют.
Как ни странно, допускается ИК (инфракрасная) подсветка и с ней распознавание работает все несколько надежнее. Парадокс в том, что многие цветные чернила в ИК диапазоне становятся не видимыми, и сканер видит только черную краску на белом фоне, найти код становится легче. Такой вот аппаратный фильтр изображения.
-
Разрешение съемки
Для съемки Хорошего кода необходимо иметь разрешение минимум 3 пикселя на модуль кода. В случае с искаженным изображением - требования возрастают, так как алгоритмам нужно большее разрешение для восстановления искаженной геометрии кода.
-
Условия съемки
Направленный точечный свет в сканер кассы может значительно испортить надежность распознавания кода из-за бликов и пересвета, несмотря на применяемые поляризационные фильтры
Солнечный свет, попадающий на сканер и товар, также может повлиять на распознавание кассой маркировки
-
Пред обработка кадра
Если есть доступ к связке железо + ПО, и оно не является единым модулем, то зачастую его можно настроить или даже перепрошить, добавив свои требования. Так можно реализовать то же инвертирование изображения для лазерной маркировки.
-
Алгоритм распознавания
Тут кто что использовал - тот и молодец. Есть пара OpenSource алгоритмов, требующих хороший снимок на вход.
Есть готовые модули распознавания кодов, выдающие сразу строку в com порт.
И вот с такими особенностями маркировки сталкивается Ритейл сейчас при выбытии товаров на кассах.
Чем же облегчает жизнь кассира верификация кодов на производстве?
Верификация позволяет убедиться в том, что произведенный продукт отвечает всем требованиям к маркировке и гарантированно будет распознаваться даже модулем с Aliexpress. Тем самым производитель будет уверен, что магазин ему не вернет товар, кассир сможет его пробить, а сам производитель не "упадет" своей репутацией в глазах покупателя из-за плохой маркировки.
Как она происходит:
Верификация может быть как 100% поточной, непосредственно на линии производства, так и выборочной - в лаборатории на специальном девайсе - Верификаторе. Стандарт оценки кода, как и требования к верификатору описаны в ГОСТ 15415-2012 и ГОСТ 16022-2008.
Основной задачей верификатора является не распознать код, а дотошно проверить его структуру, и происходить это по 7и параметрам:
контраст символа
модуляция
запас по коэффициенту отражения
повреждение фиксированных шаблонов
осевая неоднородность
неоднородность сетки
неиспользованное исправление ошибок
Каждый из этих параметров имеет буквенную величину, называемую Грейдами, ABCDF, где А - самая высокая оценка, F - самая низкая. Коды начиная с "троечников" - с оценки "С", маркировка уверенно распознаются всем оборудованием на кассах, складах и т.д. Все что ниже - могут иметь проблемы.
Пример поточной верификации на Типографии в один ручей:
Параметры верификации и что они нам могут сказать о коде
Контраст символа
Если контраст кода не достаточный, алгоритм может "не заметить" фиксированные шаблоны кода и код может не найтись, даже несмотря на автояркость в модулях и камерах. Поэтому, блеклый код или напечатанный на цветном фоне (например, бежевом) и уж тем более на прозрачном может стать проблемой на кассе.
Модуляция
Чтобы преобразовать матрицу черных и белых модулей в таблицу нулей и единиц необходимо использовать фильтрацию изображения для его разложения на черное и белое. Кто хоть раз запускал OpenCV - точно знает параметр Threshold, или Порог чувствительности, все модули, которые Ниже (темнее) этого порога - становятся "черными" Единицами в двоичном коде таблицы, а те модули, что Выше (светлее) порога - "белыми" Нулями.

Этот параметр показывает нам на сколько идеально напечатан каждый модуль кода. Если модуляция будет низкой - некоторые модули скорее всего не распознаются. Но небольшие повреждения кода не так страшны - у кода есть запас прочности.
Запас по коэффициенту отражения
Близкая по смыслу к контрасту величина, но проверяется не весь код целиком, а каждый модуль в отдельности относительно черного (0) и белого (255) значения в 8и битном изображение.
Показывает, может ли небольшая потертость кода стать причиной его не распознавания, если запас не большой - то даже грязь или термоусадочная пленка будет способна испортить распознавание кода.
Повреждение фиксированных шаблонов
Фиксированные шаблоны уже показывал ранее в статье, по ним алгоритм находит сам код, состоит из двух частей: так называемых L линий - они показывают ориентацию кода, и двух пунктирных линий - по ним в последующем строится сетка для распознавания точек (модулей) DataMatrix.

Фиксированный шаблон - один из самых важных параметров кода, если он нарушен, алгоритмы могут попросту не найти код на изображение.
Осевая неоднородность
Если код будет не квадратным - а DataMatrix должен быть всегда квадратным. Это может также пагубно повлияет на его нахождение на снимке и распознавание.

Неоднородность сетки
Распознавание 2D кода построено на наложение на него сетки по центрам модулей, в последующем именно центры каждого квадрата (модуля) преобразовываются в двоичный код. Область преобразования называется аппертурой, и варьируется от 0.8 до 0.6 от размера модуля.
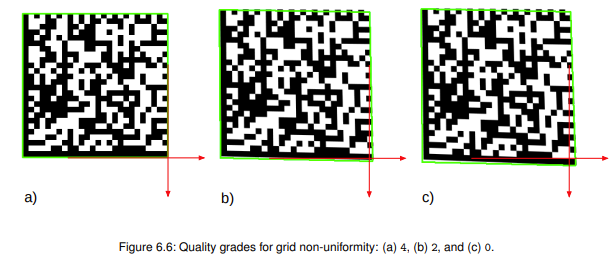
Если сетка имеет значительные искажения, а ровно и сам код не квадрат - это значительно усложняет алгоритм распознавания такого кода, не каждая OpenSoure библиотека имеет алгоритмы для корректировки искажений. Из-за искажения кода вы можете получить NoRead на кассе. Товар невозможно будет приобрести, даже если он будет полностью годным к употреблению.
Неиспользованное исправление ошибок
DataMatrixк код - это не просто набор двоичного кода по ASCII таблице, иначе бы потеря одного модуля ломала все распознавание кода.
Для обеспечения надежности хранящейся информации применяется алгоритм Рида-Соломона. Он обеспечивает максимальную безопасность кода DataMatrix: даже поврежденный на 25% код может быть прочитан без каких-либо трудностей.
Комментарии (19)

vbifkol
05.01.2022 21:27+1Интересно, разработчики этого чуда осознают, что миллионы кассиров проклинают их по сто раз в день? Не, понятно конечно что наше дело - техническое, но надо же понимать что если сказали жечь евреев, то надо из этой конторы валить, а не придумывать замечательные способы растопки.

andersong
07.01.2022 20:00Перед тем, как маркировку проклянут миллионы кассиров, ее проклянут айтишники, интеграторы, работники типографий, наладчики оборудования, операторы, кладовщики и еще очень много народу. И в конечном счете за эту бессмысленную выдумку платит конечный потребитель, который в очередной раз удивится подорожанию продуктов - мы с вами.



victor_2004
05.01.2022 23:56+1Опечаток реально много и это печалит :-(
Забыли указать еще один типичный случай нарушения ГОСТ-а. Это отсутствие "зоны тишины" вокруг кода. В идеале не менее трех точек кода.
Дизайнеры дизайнерят этикетку, впихивают в нее рамочки и в угол рамочки помещают датаматрикс. Если датаматрикс будет слишком близко к рамочке, то возможны проблемы со считыванием.
Такую же проблему можно словить и на 1D кодах, если рамка слишком близко расположена к началу кода.

avsolovyev Автор
06.01.2022 16:18+1Здравствуйте! Спасибо большое за интерес и исправления, я обязательно отредактирую статью. Извините за ошибки - писал в поезде и не заметил их.
Нас счет "зоны тишины" - да, встречал такую ошибку на некоторых типографиях. Попробую найти вживую и добавить в статью, спасибо!

androidt1c
06.01.2022 13:57+1На практике проблема лежит больше не в технической плоскости, а в подходе производителей: "берите, что дают". Когда код откровенно плохой (для этого не нужна верификация, достаточно глазами посмотреть) или содержит некорректные символы, а производитель говорит: "всех устраивает, только вам не нравится".
victor_2004
06.01.2022 18:20Это в том числе это связано с тем, что нет единых утвержденных методик проверки. Приложение от чз схавало? Тогда чего вы придираетесь?
А то, что приложение от чз хавало откровенно кривые коды - это приходилось доказывать с ГОСТ-ами и верификаторами.
Akina
Впервые вижу на Хабре статью, в которой ТАКОЕ количество и откровенных ошибок, и опечаток (я надеюсь, что всё же опечаток).
Это что, намеренная демонстрация неуважения к своим потенциальным читателям?
Gengenid
Это ужас какой-то.
Совсем недавно тут @Exosphere рассказывал сказки, как тщательно они из песочницы статьи отбирают
https://habr.com/ru/company/habr/blog/589587/
Botvinkin
Судя по тому, что у автора фамилия в профиле написана с опечаткой, дело тут не в неуважении. Либо это какая-то странная форма неуважения вообще ко всем, включая самого себя.
Wesha
С телефона статью набирал, видимо. Какая-то новая мода — всё с телефона делать.
FDA847
Обычно принято в личку автору писать про ошибки и опечатки. А комментарии уже для обсуждения самого материала статьи.
Wesha
Для этого на хабре есть Ctrl-Enter функциональность, если Вы не в курсе.
DistortNeo
Если ошибок 2-3 штуки, то я так и делаю. Здесь же я насчитал минимум 20 ошибок, и я считаю это недопустимым для читателя.
P.S. А сам материал статьи интересный.
Boomburum
Всякое бывает :) Поправил что нашёл.
buratino
невозможно обсуждать, то что невозможно прочесть... ужыс-ужыс...
У нас в местечковых пабликах народ меньше ошибок делает в постах, написанных с бодуна левой пяткой
avsolovyev Автор
Здравствуйте! Спасибо большое за интерес и исправления, я обязательно отредактирую статью. Извините за ошибки - писал в поезде и не заметил их.