
Я часто слышу от пробующих работать с Rust системных программистов жалобы на мьютексы и особенно на Rust Mutex API. Жалобы обычно выглядят так:
- Они не хотят, чтобы мьютекс содержал данные, только блокировку.
- Они не хотят управлять «защитным» значением, разблокирующим мьютекс при сбросе, в частности, они просто хотят вызывать операцию
unlock, потому что им кажется, что это более явное действие.
Такие изменения превратили бы Rust mutex API в эквивалент C/Posix mutex API. Однажды я даже видел, как один разработчик пытался использовать
Mutex<()> и разные хитрости, чтобы его имитировать.Однако у такого стремления есть проблема: эти два аспекта
Mutex неразрывно связаны друг с другом, а также с гарантиями безопасности Rust в целом — изменение одного из них или обоих откроет возможности для возникновения незаметных багов и повреждений из-за гонок данных.Использование API мьютексов в стиле C, состоящего из набора косвенно защищаемых данных и из функций
lock и unlock было бы опрометчивым в Rust, потому что это позволяет безопасному коду легко вносить ошибки, нарушающие безопасность памяти и вызывающие гонки данных.Прозвучит спорно, но я утверждаю, что это справедливо и для C. Просто в Rust это более очевидно, поскольку Rust тщательно разделяет понятия «безопасного» кода, в который невозможно внести подобные ошибки, и «небезопасного» кода, в который можно вносить такие ошибки. В C такого разделения нет, и в результате этого использующий мьютексы код на C может тривиальным образом создавать серьёзные баги, которые потенциально можно подвергать эксплойтам.
В этом посте я разберу типичный C mutex API, сравню его с типичным Rust mutex API, и расскажу о том, что произойдёт, если мы изменим Rust API так, чтобы он напоминал C.
Мьютексы в C
(Примечание: когда я говорю «C», мои комментарии также относятся и к различным вариантам C, в том числе и к C++, который, по сути, использует то же устройство мьютексов.)
В C есть широкий выбор API мьютексов, в основном потому, что стандартный API был утверждён только в 2011 году. В этом посте я буду использовать стандартные мьютексы C11, потому что они просты и доступны, однако это описание столь же применимо, например, и к
pthreads.В этом посте мы будем считать, что C mutex API состоит из двух основных операций:
lock и unlock. [Я не буду рассматривать создание и разрушение мьютексов, вещи наподобие trylock, атрибуты мьютексов, различия между рекурсивными и нерекурсивными мьютексами, и т. д. Ничто из перечисленного не относится к моим рассуждениям.]// Блокирует мьютекс, пока он не освобождается.
int mtx_lock(mtx_t *mutex);
// Разблокирует мьютекс.
int mtx_unlock(mtx_t *mutex);В этих функциях используется обычный стандарт C — возвращается
int со значением 0, обозначающий успех, а всё остальное означает неудачу.Когда коду нужно получить безопасный доступ к данным, которые могут использоваться в нескольких потоках, он вызывает
mtx_lock. Затем он выполняет доступ к данным, а в конце вызывает mtx_unlock. Вот простой пример, в котором эти операции используются для обработки глобального счётчика, инкремент которого можно выполнять из нескольких потоков:mtx_t *the_mutex;
int the_counter;
// Код инициализации the_mutex пропущен.
int increment_the_counter() {
int r = mtx_lock(the_mutex);
if (r != 0) return r;
// При заблокированном мьютексе мы можем безопасно работать со счётчиком.
the_counter++;
return mtx_unlock(the_mutex);
}
// Обратите внимание, что эта функция передаётся в "out-параметр", *value_out,
// потому что возвращаемое значение обозначает успех/неудачу.
int read_the_counter(int *value_out) {
int r = mtx_lock(the_mutex);
if (r != 0) return r;
// При заблокированном мьютексе мы можем безопасно считывать счётчик.
*value_out = the_counter;
return mtx_unlock(the_mutex);
}В более сложных случаях система может использовать более «мелкие» мьютексы, хранящиеся в структурах данных вместе с защищаемыми ими данными, например:
struct SomeData {
mtx_t *mutex;
int the_data;
};Чтобы определить, какие данные должны защищаться каким мьютексом, программисты на C обычно используют стандарты из документации, например, этот из документации Chromium по мьютексам:
У каждой общей переменной/поля должен быть комментарий, указывающий, какой мьютекс её защищает:int accesses_; // количество доступов (охраняемых mu_)
или комментарий, объясняющий, почему мьютекс не требуется:int table_size_; // количество элементов в таблице (readonly после init)
Каждый мьютекс должен иметь комментарий, указывающий, какие переменные, а также какие неочевидные инварианты он защищает:Lock mu_; // защищает accesses_, list_, count_ // инвариант: count_ == количество элементов в связном списке list_
Можно считать соответствующие комментарии рядом с переменными и мьютексами аналогом совпадающих типов аргументов и параметров процедур; избыточность может быть очень полезной для дальнейшей поддержки кода.
Хотя в этом разделе я стараюсь никого не судить, не могу промолчать о последнем абзаце. Есть важное различие между типами аргументов процедур и комментариями про область действия мьютексов: типы аргументов процедур проверяются компилятором. Эта аналогия ближе к тому, чтобы объявить все параметры как
void * и указывать их реальные типы в комментариях, а потом ждать, что пользователи будут всегда правильно реализовывать приведение типов и порядок.Впрочем, я отклонился от темы. Давайте теперь для сравнения рассмотрим Rust.
Мьютексы в Rust
В модуле
std::sync стандартной библиотеки Rust есть тип Mutex. Его API отличается от API в C тремя аспектами:-
Mutexсодержит охраняемые им данные: полное имя типаMutex<T>, гдеTозначает выбираемый вами охраняемый тип. - Операция
lockвозвращает «защитное» значение. - Операция
unlockдоступна только для защитного значения, а не для самогоMutex. (Операцияunlockтакже оказываетсяdrop, что мы подробнее рассмотрим это ниже.)
В bare-metal-средах
no_std, где я обычно работаю, у нас есть собственные типы Mutex, но они выглядят почти так же, как и Mutex из стандартной библиотеки, и на то есть причины, о которых вы узнаете в этом посте.Упрощённая версия Rust API выглядит так:
// Мьютекс, охраняющий некие данные типа T.
struct Mutex<T> {
// содержимое пропущено
}
impl<T> Mutex<T> {
// Создаёт мьютекс, инициализирует его охраняемые данные.
pub fn new(contents: T) -> Self { ... }
// Блокирует мьютекс. После получения блокировки
// возвращает MutexGuard, содержащий ссылку
// на охраняемые данные.
pub fn lock(&self) -> MutexGuard<'_, T> { ... }
}
// Результат блокировки мьютекса с временем жизни'a,
// охраняющего данные типа T. Обратите внимание, что он не реализует
// Copy или Clone, поэтому его нельзя дублировать.
struct MutexGuard<'a, T> {
// содержимое пропущено
}(В этом упрощённом API я не рассматриваю концепцию под названием «lock poisoning», потому что она не относится к нашей теме.)
А вот пример нашего API инкрементов счётчика, переписанный с использованием мьютекса Rust:
// Rust-версия не использует глобальных переменных, потому что
// это потребует небезопасности.
struct Counter {
mutex: Mutex<usize>,
}
fn increment_the_counter(ctr: &Counter) {
let guard = ctr.mutex.lock();
*guard += 1;
// Также можно выразить это как
// *ctr.mutex.lock() += 1;
// если вам нужна краткость.
}
fn read_the_counter(ctr: &Counter) -> usize {
let guard = ctr.mutex.lock();
*guard
}Подобный API обычно описывается так: тип
MutexGuard является умным указателем, обеспечивающим доступ к содержимому мьютекса типа T, но только пока существует сама защита. Когда она сбрасывается явным образом или выходит за область своего действия, доступ завершается и мьютекс разблокируется.Но можно посмотреть на это и иначе:
MutexGuard — это токен, доказывающий, что мьютекс был заблокирован.- Так как мы не можем создать
MutexGuardникак, кроме как операциейMutex::lock, наличиеMutexGuardдемонстрирует, чтоlockбыла вызвана. [Под этим я подразумеваю, что этого никак нельзя сделать в безопасном Rust, и нельзя легко сделать это случайно в небезопасном Rust. Разумеется, в небезопасном Rust можно отклониться от курса и разрушить любой инвариант языка, но я всё-таки пытаюсь создавать ПО, устойчивое к ошибкам, сделанным добросовестными программистами. Если вы подозреваете, что с вашей кодовой базой будут работать злонамеренные коварные программисты, то стоит отключить небезопасный Rust атрибутом#![forbid(unsafe_code)]. А потом, возможно, пересмотреть свой подход к найму персонала.] - Так как
Mutexпо определению не может выдать больше, чем одинMutexGuard, второй вызовlockпри существованииMutexGuardбудет заблокирован, пока не будет разрушен первый, а самMutexGuardне может быть дублирован — наличиеMutexGuardдемонстрирует уникальный доступ к данным, охраняемым мьютексом. А это в условиях Rust означает, что из него можно получить&mut T. - Поскольку параметр времени жизни
'aв определенииMutexGuardпривязывается к времени жизни самогоMutex, то при вызовеlockкомпилятор не позволит сброситьMutex, всё ещё имеющийMutexGuard, предотвращая его превращение в повисший указатель.
Вариации Rust mutex API и их проблемы
Как говорилось в начале поста, я слышу две основные жалобы на Rust mutex API.
- Мне не нравится, что охраняемые мьютексом данные находятся внутри мьютекса.
- Мне не нравится использовать защитное значение для отслеживания блокировки мьютекса (обычно подразумевают, что должна быть доступна функция
unlock).
Давайте попробуем реализовать эти вариации!
Перемещаем охраняемые данные из мьютекса
Начнём с этого. Просто не будем ничего помещать в мьютекс, и будем хранить какие-то охраняемые данные, как сделали бы это в C:
struct SomeData {
mutex: Mutex<()>,
the_data: i32,
}(Если вы давно работаете с Rust и знакомы с понятием «interior mutability» (внутренняя мутабельность), то можете увидеть проблему в этом определении, но давайте без спойлеров.)
Когда мы это делаем, то сразу же отказываемся от одной вещи: помощи по мьютексам от компилятора. Теперь мы можем свободно работать с
the_data без блокировки мьютекса. Наверно, на этом этапе мы бы добавили комментарии как в Chromium, объясняющие, как правильно работать со структурой SomeData.Но это значит, что любой, кто работает с этим API и не прочитал комментарий (или неправильно его понял) может создавать гонки данных, точно так же, как и на C. Ведь так?
Как ни удивительно, но это не так, эту структуру нельзя использовать для создания гонок данных в безопасном Rust, даже если вы напишете подобный код:
fn use_the_data_wrong(data: &SomeData) -> i32 {
// Я плохой человек и буду получать доступ к охраняемым данным без блокировки
data.the_data
}Это действительно похоже на эталонную гонку данных, и код компилируется без проблем, однако оказывается, что это не гонка данных, потому что при этом изменении мы кое-что потеряли: возможность обновления
SomeData из нескольких потоков.Мы можем использовать
SomeData между потоками, потому что SomeData автоматически реализует Sync. Sync — это стандартный типаж (trait) Rust, обозначающий, что нечто можно безопасно использовать между потоками — его имя подразумевает, что передаваемый элемент выполняет некую синхронизацию. Sync автоматически определяется для типов, соответствующих базовым критериям, один из которых заключается в том, что всё их содержимое тоже должно быть Sync, что в данном случае истинно.Однако общее использование между потоками не означает изменения, и если
the_data по сути остаётся постоянной, больше нет гонки данных, вызываемой её считыванием без блокировки. [В данном посте мы предполагаем, что если работаем с многоядерным процессором со слабой моделью памяти, то реализованы соответствующие барьеры. Есть вероятность, что вам нужно беспокоиться об этом, только если вы знаете, что это значит.]i32 — это простой машинный тип, который имеет атомарный аналог AtomicI32 (из std::sync::atomic). Этот тип является Sync и предоставляет атомарные операции для обновления его из нескольких потоков, однако на этом этапе вам, вероятно, не понадобится мьютекс! Иными словами, AtomicI32 обеспечивает внутреннюю мутабельность – его API позволяет изменять содержимое, даже если у вас есть только разделяемая ссылка на него.Если охраняемые данные сложнее, чем integer, допустим, это набор из integer и указателей, и вам нужно сохранять их внутреннее постоянство, то атомарного аналога у них не будет, поэтому если мы захотим изменять их через разделяемую ссылку, то нужно поместить их в какой-то контейнер, с тщательно управляемым доступом, чтобы он был
Sync, даже несмотря на то, что его содержимое изменяемо.Например, контейнер типа
std::sync::Mutex.Но в этом разделе мы не хотим помещать общие данные внутрь потокобезопасных контейнеров наподобие
Mutex, поэтому давайте думать дальше.На самом деле, есть ещё один способ.
Можно аккуратно инкапсулировать
SomeData в модуль, сделав его поля приватными, чтобы код за пределами модуля не мог ссылаться на the_data напрямую. Можно даже создать функции для работы с SomeData, которые будут правильно обрабатывать мьютекс. На самом деле, логично было бы перестать мучать Mutex<()> и перейти на AtomicBool.// Предполагается, что мы находимся в модуле, отдельном от клиентского кода.
use std::sync::{AtomicBool, Ordering};
// Struct является pub; поля не являются pub.
pub struct SomeData {
locked: AtomicBool,
the_data: i32,
}
pub fn try_read_data(d: &SomeData) -> Option<i32> {
if d.locked.swap(true, Ordering::Acquire) {
// мы уже были заблокированы!
None
} else {
// мы заблокировали "мьютекс" и можем безопасно выполнять считывание.
let result = d.the_data;
d.locked.store(false, Ordering::Release);
Some(result)
}
}Но мы по-прежнему не получили возможность обновления
the_data при помощи разделяемой ссылки, &SomeData — это всё, что у нас будет, когда мы сделаем его общим для потоков.Так получается потому, что на самом деле
Mutex играет две роли от лица охраняемых им данных: да, он обеспечивает синхронизацию, но также обеспечивает и внутреннюю мутабельность, позволяя записывать данные через разделённую ссылку. Иными словами, это и блокировка, и контейнер наподобие Cell или RefCell.Однако, и
Cell, и RefCell не являются Sync (потому что им не хватает потокобезопасной блокировки Mutex), поэтому мы не можем использовать один из этих типов для оборачивания the_data, или мы полностью потеряем возможность общего использования её между потоками.Вместо этого нам придётся спуститься на уровень ниже и использовать тип, который используется внутри
Cell, RefCell и Mutex, а именно UnsafeCell. Как понятно из имени, мы будем увеличивать объём небезопасного кода.// Предполагается, что мы находимся в модуле, отдельном от клиентского кода.
use std::cell::UnsafeCell;
use std::sync::{AtomicBool, Ordering};
// Struct является pub; поля не являются pub.
pub struct SomeData {
locked: AtomicBool,
the_data: UnsafeCell<i32>,
}
pub fn try_read_data(d: &SomeData) -> Option<i32> {
if d.locked.swap(true, Ordering::Acquire) {
// мы уже были заблокированы!
None
} else {
// мы заблокировали "мьютекс"!
// Безопасность: это небезопасно, потому что разыменует
// сырой указатель, возвращённый UnsafeCell::get. Чтобы код был
// безопасным, нам нужно знать, что указатель валиден, что
// нам гарантирует UnsafeCell, и что создаваемая нами ссылка
// не создаёт альтернативных точек входали и гонок, в чём мы уверены, наверно?
// ведь блокировка есть?
let result = unsafe {
*d.the_data.get()
};
d.locked.store(false, Ordering::Release);
Some(result)
}
}
pub fn try_write_data(d: &SomeData, new_val: i32) -> bool {
if d.locked.swap(true, Ordering::Acquire) {
// мы уже заблокированы!
false
} else {
// мы заблокировали "мьютекс"!
// Безопасность: см. обоснование в try_read_data.
unsafe {
*d.the_data.get() = new_val;
}
d.locked.store(false, Ordering::Release);
true
}
}
// Объявляем компилятору, что мы уверены, что это теперь
// можно использовать между потоками.
unsafe impl Sync for SomeData {}Нам пришлось добавить
unsafe impl для Sync. Это сообщает компилятору, что мы удовлетворяем критериям, чтобы обрабатывать данные как Sync …без проверок. Это единственный способ реализации Sync вручную, потому что все проверяемые способы реализации Sync происходят автоматически.Благодаря этому изменению мы можем обновлять данные, используемые между потоками. Мы приближаемся к тому, что хотели реализовать.
Однако в то же время мы заново реализовали бОльшую часть
Mutex… и при этом не очень качественно. То, что мы сделали, эквивалентно Mutex, но:- Поддерживает только один вид охраняемых данных, поэтому если нам понадобится второй, то придётся переписывать всё это снова.
- Не может дать ссылку на охраняемые данные, поэтому все обновления должны реализовываться в этом модуле и выполняться по значению.
- Не поддерживает блокировку мьютексов, потому что для их блокировки обычно требуется поддержка ОС, а мы решили писать её самостоятельно.
Давайте попробуем решить первые две, добавив операцию
try_lock, создающую ссылку, и сделав тип обобщённым:struct SharedData<T> {
owned: AtomicBool,
contents: UnsafeCell<T>,
}
impl<T> SharedData<T> {
pub fn try_lock(&self) -> Option<&mut T> {
if self.owned.swap(true, Ordering::Acquire) {
// уже заблокировано
None
} else {
// мы победили!
// безопасность: этот &mut уникален, потому что мы выиграли любые
// потенциальные гонки, задав флаг при помощи атомарного swap.
unsafe { &mut *self.contents.get() }
}
}
}
unsafe impl<T: Send> Sync for SharedData<T> {}Это уже выглядит похожим на стандартный тип
Mutex, только с меньшим списком возможностей. В частности, здесь нет возможности unlock.Mutex-подобный элемент, который невозможно разблокировать, всё равно может быть полезным — это базис для того, что я называю First-Mover Allocator Pattern, в котором почти полностью используется приведённый выше код. Однако это совсем не Mutex. На этом этапе у нас есть два варианта. Можно реализовать разблокировку при помощи защитного типа, то есть, по сути воссоздать std::sync::Mutex, или попасть в ловушку, описанную в предыдущем разделе.Разблокировка небезопасна
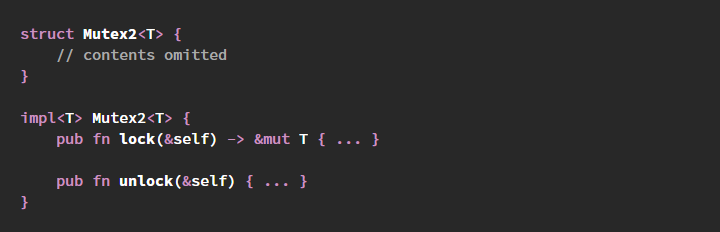
Что если мы удалим
MutexGuard из стандартного Mutex и вместо него создадим операцию unlock, как в C?Вот набросок того, как это может выглядеть, если мы оставим охраняемые данные внутри мьютекса (и таким образом избежим проблем, описанных в предыдущем разделе):
struct Mutex2<T> {
// содержимое пропущено
}
impl<T> Mutex2<T> {
pub fn lock(&self) -> &mut T { ... }
pub fn unlock(&self) { ... }
}Вместо возврата какого-нибудь сложного типа
MutexGuard для управления ресурсами мы просто возвращаем исключающую ссылку на охраняемые данные &mut T.В этом API, как и в C, вполне допускается вызывать
unlock в любой момент, когда у вас есть доступ к Mutex2. В свою очередь, это означает, что нет способа гарантировать, что мы используем ссылку на охраняемые данные только до разблокировки:let guarded_data = mutex.lock();
guarded_data.do_stuff();
mutex.unlock();
guarded_data.do_stuff(); // ой-ёй, по-прежнему в области действияА ещё это значит, что мы создали инструмент для создания ссылок на
&mut, которые являются альтернативными точками входа, что является ещё одним способом нарушения безопасности памяти:let guarded_data = mutex.lock();
mutex.unlock();
let guarded_data2 = mutex.lock();
*guarded_data = *guarded_data2; // ой-ёй, создаются псевдонимыПо сути, неконтролируемая
unlock теряет способность понимать, остаются ли доступными какие-то ссылки на охраняемые данные, и даёт безопасному коду возможность провоцировать произвольные гонки данных. Именно это мы стремимся предотвратить при помощи мьютекса.В Rust можно создать операцию
unlock над мьютексом в стиле C, но она должна быть unsafe, потому что вызывающий код должен гарантировать то, что не может гарантировать компилятор, например, сопоставление unlock и lock, а также то, что ссылки на охраняемые данные не утекут за пределы unlock.Однако для представленного выше наброска
Mutex2 это, по сути, означает, что мьютекс бесполезен для безопасного кода — основная часть кода, использующая мьютекс, вероятно, захочет его разблокировать! И мы вернулись к проблеме, описанной в предыдущем разделе.Чтобы исправить это, нам нужно сделать
unlock безопасной, а чтобы она была безопасной, нам нужно каким-то образом ограничить доступ к unlock, за исключением ровно одного вызова unlock после блокировки мьютекса и после уничтожения всех ссылок на охраняемые данные. Простейший способ гарантировать то, что одна операция будет доступна только после другой операции — сделать так, чтобы первая операция возвращала некий токен, который нужно передать второй операции. То есть вызов lock должен как-то сгенерировать токен, который вызывающий код должен обменять на возможность вызвать unlock, и не более одного раза. В Rust это можно сделать, создав тип, который нельзя копировать или клонировать, примерно так:struct Mutex2<T> { ... }
impl<T> Mutex2<T> {
// Создаёт токен _и_ ссылку на охраняемые данные.
pub fn lock(&self) -> (UnlockToken, &mut T) { ... }
pub fn unlock(&self, token: UnlockToken) { ... }
}
// Обратите внимание, что это не Copy или Clone, поэтому нельзя дублировать.
struct UnlockToken { ... }Это может сработать, но это решает только одну часть проблемы, потому что код, вызвавший
lock, всё равно намеренно или случайно может использовать &mut T после передачи его UnlockToken.Это также создаёт новую проблему: что если мы передадим
UnlockToken, сгенерированный одним мьютексом, другому мьютексу? Это позволит нам разблокировать мьютекс в неожиданное время, что возвращает нас к гонкам данных. Мы могли бы добавить в UnlockToken информацию о том, от какого мьютекса он взят (возможно, указатель?), а затем создать панику, если пользователь перепутает свои токены. Это предотвратит возможность гонок данных, однако перемещает ошибку в среду выполнения (паника), что неприятно.Поместив указатель на мьютекс внутрь
UnlockToken, мы можем избавиться от вероятности ошибок среды выполнения, переместив операцию unlock. Если мы поместим операцию unlock в токен, то получим:struct Mutex2<T> { ... }
impl<T> Mutex2<T> {
// Создаёт токен _и_ ссылку на охраняемые данные.
pub fn lock(&self) -> (UnlockToken, &mut T) { ... }
}
// Обратите внимание, что это не Copy или Clone, поэтому нельзя дублировать.
struct UnlockToken { ... }
impl UnlockToken {
// Это ненадёжно, см. ниже.
pub fn unlock(self) { ... }
}Обратите внимание, что
UnlockToken::unlock берёт self по значению, то есть использует self – это удовлетворяет требованию того, что разблокировку можно выполнять один раз на токен. Так как идентификатор разблокируемого мьютекса подразумевается из токена, невозможно использовать токен одного мьютекса для разблокировки другого. Это удовлетворяет второму требованию.Однако мы получили новую проблему: теперь, когда
unlock можно вызывать только в UnlockToken, что произойдёт, если пользователь просто сбросит токен? В наивной реализации мьютекс останется заблокированным навечно. Это не нарушает принцип безопасности Rust созданием гонки данных и тому подобного, но будет создавать баги. Вероятно, нам потребуется реализовать Drop для UnlockToken, чтобы можно было обнаруживать эту ситуацию. Это можно сделать двумя очевидными способами:- Написать
Dropimpl, создающую панику. - Написать
Dropimpl, разблокирующую мьютекс.
Создающая панику
Drop impl приводит к возможности новой ошибки среды выполнения. Это поднимает вопрос о том, будет ли случайный сброс токена обозначать баг. Если это баг, паника вполне разумна, чтобы защитить программу от влияния бага. Если нет, то паника просто устанавливает капкан, в который может попасть пользователь.Как может выглядеть случайный сброс токена в созданном нами наброске API? Самый компактный способ будет выглядеть так:
let (_, guarded_data) = mutex.lock();
guarded_data.do_stuff();Присваивание токену wildcard pattern
_ означает, что он будет сброшен сразу же, поэтому доступ к охраняемым данным во второй строке происходит с разблокированным мьютексом. Паника, если токен будет сброшен, предотвратит доступ (и условия гонки), но… только в этом случае.Но не в этом:
let (token, guarded_data) = mutex.lock();
token.unlock();
guarded_data.do_stuff(); // ой-ёй, по-прежнему в области действияЗдесь паника не возникает, однако создаётся гонка данных.
Я хочу донести мысль о том, что вопрос о том, нужно ли паниковать при сбросе токена, только отвлекает нас — сработает любое из решений (хотя лично мне не нравится добавлять ненужные паники и я бы выбрал вариант разблокировки при сбросе). Но ни одного из решений не достаточно, чтобы сделать
unlock безопасной!Чтобы это исправить, нам нужно гарантировать, что время жизни токена разблокировки и время жизни ссылки на охраняемые данные точно совпадало, чтобы ссылка не жила дольше, чем токен разблокировки. Проще всего это сделать, не рассматривая их как отдельные значения, а объединить их. Примерно так:
struct Mutex2<T> { ... }
impl<T> Mutex2<T> {
// Создаёт комбинированные токен и ссылку.
pub fn lock(&self) -> MutexGuard<'_, T> { ... }
}
// Обратите внимание, что это не Copy или Clone, поэтому нельзя дублировать.
struct MutexGuard<'a, T> { ... }
impl<T> Drop for MutexGuard<'a, T> {
// ... код разблокировки мьютекса размещается здесь
}
// Deref обеспечивает возможность доступа к охраняемым данным, пока жив MutexGuard.
impl<T> Deref for MutexGuard<'a, T> {
type Target = T;
fn deref(&self) -> &Self::Target { ... }
}
// ... также понадобится DerefMut, который здесь опущен для краткости.На этом этапе мы воссоздали API
std::sync::Mutex. Это удобно решает все проблемы, с которыми мы столкнулись в этом разделе:- Невозможно разблокировать мьютекс, сначала его не заблокировав, поскольку для разблокировки потребуется наличие
MutexGuard. - Блокировка мьютекса даёт нам право разблокировать его только один раз, поскольку
MutexGuardнельзя дублировать. - Сразу же после разблокировки мьютекса доступ к охраняемым данным становится невозможным, что предотвращает гонки данных, поскольку для разблокировки
MutexGuardдолжен выйти за область действия, а именно с помощьюMutexGuardмы получали доступ к охраняемым данным.
Поскольку мы выполняем явные вызовы
unlock или полагаемся на Drop, то сработает любое решение, если вы очень аккуратно пишете unlock. Например, есть операция unlock, предложенная для добавления в стандартную библиотеку. Она выглядит так:impl Mutex<T> {
pub fn unlock(guard: MutexGuard<'_, T>) {
// Здесь ничего не пропущено --
// функция на самом деле пустая!
}
}Да, это пустая функция. Она просто переносит
MutexGuard функцию по значению, а затем сбрасывает его. (Точно так же реализована std::mem::drop, если вам любопытно.) Это безопасно потому, что управление доступом к охраняемым данным по-прежнему обеспечивается MutexGuard и разблокировка мьютекса по-прежнему является косвенной в MutexGuard. Обратите внимание, что функция не имеет параметра &self, задающего Mutex; это значит, что она вызывается так:let guard = mutex.lock();
guard.do_stuff();
Mutex::unlock(guard);Надеюсь, из этого раздела вам стало понятно, что любая явная операция разблокировки в безопасном Rust, по сути, обязана выглядеть так. (И, вероятно, являться синонимом
drop.)Лично я предпочитаю при необходимости явного задания области действия мьютекса использовать такой паттерн:
{
let guard = mutex.lock();
guard.do_stuff();
}
// guard больше недоступен за областью действия.Заключение
Если вкратце, то вы можете создавать в Rust API мьютексов в стиле C, но при этом вы отказываетесь от большинства гарантий безопасности Rust, потому что его можно использовать для тривиального создания багов гонок данных и/или смешения исключающих ссылок, поэтому API почти полностью должен быть
unsafe. И использовать его нужно крайне аккуратно. Наверно, с большим количеством комментариев.Однако комментарии не являются стратегией реализации concurrency.
Если вы надеетесь на то, что программист всегда читает, понимает и запоминает документацию, а потом всегда делает всё правильно, то вы получите баги.
Один из показателей, которые я использую при проведении аудита безопасности кода — я ищу большие блоки документации или стандартов кодинга с подробными паттернами документирования, например как тот, который я процитировал из документации Chromium. Они почти всегда являются показателем того, что близлежащий API имеет глубокие изъяны и его можно использовать для внесения ошибок.
Теперь, когда мы понимаем, почему Rust API имеет именно такую структуру, стоит задаться вопросом: почему C mutex API структурирован так, что его сложно использовать и легко использовать неверно, почему он требует подробных комментариев или даже статического анализа для правильной реализации? И всё это несмотря на то, что стандартный API был спроектирован примерно в 2010 году, когда многоядерные процессоры уже были широко распространены.
Этот вопрос одновременно и справедлив, и несправедлив. В C (и C++) отсутствуют важные фичи языка, из-за чего невозможно реализовать API в стиле Rust с теми же гарантиями — отсутствует явно задаваемое время жизни, нет эквивалента
Sync, отсутствует «move-семантика» для обеспечения того, что значения завершают своё существование в контролируемые моменты (как это происходит с MutexGuard). Поэтому неразумно ожидать, что стандарт C позволит определить безопасный API мьютексов.Зато вполне разумно использовать инструменты получше.
Комментарии (14)

Bromles
08.04.2022 15:28+2Возникает интересный вопрос: а если нам надо свопнуть два значения с помощью мьютексов, как это нормально реализовать в Расте? Ну то есть через мьютексы в Си или локи в Жаве можно просто объявить кусок кода однопоточным и сделать там, что угодно
Но в расте, получается, придется делать по мьютексу на каждую используемую переменную. А если это не своп и их не 2, а больше? Оптимизационная проблема получается
С этим языком знаком плохо, поэтому буду рад, если подскажете, как это можно сделать лучше
Но на данный момент ничего лучше следующего не приходит на ум, а это не очень:use std::mem; use std::sync::Mutex; struct Data1 { m_x: Mutex<usize>, } struct Data2 { m_y: Mutex<usize>, } fn swap(src: Data1, dest: Data2) { let mut lock_src = src.m_x.lock().unwrap(); let mut lock_dest = dest.m_y.lock().unwrap(); mem::swap(&mut *lock_src, &mut *lock_dest); println!("was 5 now {}", (*lock_src)); println!("was 10 now {}", (*lock_dest)); } fn main() { let data1 = Data1 { m_x: Mutex::new(5) }; let data2 = Data2 { m_y: Mutex::new(10) }; swap(data1, data2); }
lgorSL
08.04.2022 16:59+1Конкретно в вашем примере можно сделать один мьютекс для структуры, которая содержит и Data1 и Data2. (Сори, нельзя, невнимательно прочитал код)
Но в общем случае для N мьютексов интересно - в с++ есть std::lock(...), в который можно передать произвольное количество мьютексов и не бояться дедлока, мьютексы будут захвачены в каком-то порядке. Интересно, можно ли так в расте, или в нём программист должен сам запомнить, что мьютекс А всегда должен захватываться не позже мьютекса Б?

Xop
08.04.2022 17:01+3Эмм, так когда вы объявляете кусок кода в джаве однопоточным вы разве не должны передать туда некий объект, который и играет роль мутекса? И в любом случае у вас всегда будет либо два мутекса (по одному на значение) и свопы медленнее, чем хотелось бы, либо общий мутекс на оба значение и быстрые свопы (но потенциально лишние блокировки, когда нужен доступ только у одному значению).
Bromles
08.04.2022 17:51Вы говорите про synchronized, который синхронизирует по объекту. А я говорю про реализации интерфейса Lock из пакета java.util.concurrent.locks. Например ReentrantLock
Вот пример с аналогичным для Сишных мьютексов кодом на Джаве
class CommonResource { int x = 0; } public class Main { public static void main(String[] args) { CommonResource resource = new CommonResource(); Lock locker = new ReentrantLock(); for (int i = 1; i < 6; i++) { Thread t = new Thread(() -> { locker.lock(); try { resource.x = 1; for (int j = 1; j < 5; j++) { System.out.printf("%s %d %n", Thread.currentThread().getName(), resource.x); resource.x++; Thread.sleep(100); } } catch (InterruptedException ex) { ex.printStackTrace(); } finally { locker.unlock(); } }); t.setName("Thread " + i); t.start(); } } }
mayorovp
08.04.2022 18:56+4Ну так тут ReentrantLock роль мьютекса и исполняет. Никаких отличий от других языков программирования.

Cheater
08.04.2022 17:12+2Имхо не надо делать мьютекс частью структуры данных (т.к. средства синхронизации, всякие guard-ы и т.д. это всё для Data1, Data2 внешние сущности), и надо закрывать мьютексом 1 раз пару значений:
use std::mem; use std::sync::Mutex; struct Data1 { m_x: usize } struct Data2 { m_y: usize } fn swap(src: &mut (&mut Data1, &mut Data2)) { mem::swap(&mut src.0.m_x, &mut src.1.m_y); } fn main() { let mut data1 = Data1 { m_x: 5 }; let mut data2 = Data2 { m_y: 10 }; let mutex = Mutex::new((&mut data1, &mut data2)); swap(&mut mutex.lock().unwrap()); println!("was 5 now {}", data1.m_x); println!("was 10 now {}", data2.m_y); }Bromles
08.04.2022 17:56+1Вы использовали тупль, который тут хорошо подходит, да. Но если переменных больше 2? Если надо работать с переменными, которые по смысле не объединить в одну структуру?
Cheater
08.04.2022 18:52+5Потокобезопасная обработка 2, 3, 4, любого небольшого числа объектов разных типов делается через создание n-элементного кортежа из ссылок на нужные объекты и затем закрытие кортежа мьютексом. Колхоз, но должно работать. В чём состоит более общая задача мне не ясно

mrbald
09.04.2022 10:29Так данные не делаются частью, а просто оборачиваются. На плюсах такое тоже легко закодировать, но обычно называют “synchronized” и не считается базовым строительным блоком.

lorc
08.04.2022 19:27+8Задача не совсем понятна.
У вас есть значение которое потенциально может изменяться в нескольких потоках. Значит вам нужен мютекс, который вы будете брать каждый раз когда обращаетесь к значению.
Если у вас два значения, значит либо:- У вас один мютекс который вы берете каждый раз когда обращаетесь к любому значению.
- У вас два мютекса, каждый охраняет свое значение.
Так будет и в Яве, и в Си, и в Расте.

Amomum
08.04.2022 21:51+1С удовольствием использую в С++ библиотеку https://github.com/LouisCharlesC/safe, которая реализует аналогичный API.

KreisNv
09.04.2022 23:09-1Вопрос, а какую задачу решали? Не в первый раз вижу оверинжениринг на пустом месте
lorc
09.04.2022 23:37+5Так вроде ж написали: гарантировать правильное использование мютексов на уровне языка. Если код скомпилировался, значит мютексы используется правильно и гарантируют потокобезопасность.
MikeLP
Спасибо за хорошую статью.