

Недавно я обратил свой взгляд на небольшой, но весьма привлекательный OLED микродисплей, который можно вполне успешно применять в своих самоделках, одна беда — известные библиотеки для него поддерживают только латинский шрифт. Ситуация усугубляется тем, что я использую его для подключения к esp32, а не Arduino. Поэтому arduino-библиотеки можно сразу отбросить. Что с этим делать и как дальше жить, об этом мы и поговорим в этой статье.
Честно скажу, этот экранчик мне понравился сразу, как я взял его в руки — особенно когда я увидел его цену, ещё до всяких повышений: цельных 60 р. в розницу (непозволительная роскошь, на грани разорения)!
Сейчас конечно, ситуация несколько грустнее, но не сильно: в пределах «непосильных» 90 с небольшим рублей — он вполне доступен :-)
Но тут, честно говоря, дело совсем даже не в цене, а в том, что он такой маленький и сверхяркий, что руки так и чешутся его где-нибудь применить:

Что касается его разрешения, то оно — 128х32 пикселя. Благодаря своему типу, он обладает весьма высокой яркостью, как я уже говорил, впрочем, как и всё OLED дисплеи — яркость позволяет вполне спокойно смотреть на него и чётко различать индикацию даже в яркий солнечный день (только смартфон никак не может сфокусироваться на такую яркость — что и видно на ролике ниже).
Благодаря интерфейсу I2C, для подключения дисплея к esp32 достаточно только двух пинов (не считая двух пинов питания): Serial Clock (SCL) и Serial Data (SDA).
Некоторое время назад, перепробовав общедоступные решения, я наткнулся на библиотеку вот по этому адресу.Автор разработал решение, которое запустилось у меня на моей esp32 без всяких «танцев с бубном», что и подкупило.
Кроме того, в правовой информации сам автор пишет, что разрешает все возможные модификации и допиливания своей библиотеки, разумеется, если всё это производится не в коммерческих целях (само собой :-) ).
В документации к библиотеке можно найти то, что она предоставляет целый набор разнообразных функций, которые позволяют достаточно гибко работать с ней.
Благодаря, например, этим функциям, можно ярко поморгать всей площадью экрана. Очень интересная функция, особенно исходя из того, что я как раз подумывал использовать нечто подобное в своих самоделках, в частности, в разнообразных робототехнических игрушках — ну знаете, когда у робота моргают глаза, меняется выражение глаз (становится весёлым либо серьёзным и т.д.)
setBrightness(value);Но, опять же, ложка дёгтя в бочке мёда всё же присутствует: поддержки русского языка не предусмотрено. А что если мы её добавим?!
Сразу скажу, что до этого с дисплеями подобного рода мне работать не приходилось, и поэтому это был даже своего рода для меня вызов — смогу или не смогу осилить подобную работу?!
Изучая документацию по функциям этой библиотеки, меня особенно привлекли 2 из них: для рисования линий и для включения какого-либо конкретного пикселя по координатам X Y:
drawLine(x1,y1,x2,y2);
setPixel(x,y);
И я подумал, что зачем выдумывать — будем базироваться на них, в процессе построения своего решения!
То есть, наше решение будет заключаться в том, что мы будем отрисовывать каждую букву для русского шрифта!
Сразу, после того как созрело подобное решение, передо мной в полный рост встала задача раздобыть некий шрифт.
Сначала, в порыве горячки, я даже подумал, что, может быть, имеет смысл нарисовать его самому? Но быстро отбросил это решение, так как представил гигантский объём работы, который на меня свалится в этом случае. Кроме того, не факт, что получится хорошо.
Поэтому я решил загуглить какой-нибудь пиксельный шрифт — то есть шрифт, построенный из отдельных квадратиков.
Окей, шрифт скачан, что дальше? Теперь этот шрифт нужно каким-то образом наложить на матрицу, чтобы представить, как он будет выглядеть в реале. Кроме того, такое наложение позволит нам узнать точные координаты каждого пикселя по X Y, чтобы понимать, какие пиксели необходимо включить для отображения той или иной буквы.Для этих целей мы запускаем свой любимый векторный редактор Corel Draw (лицензионный, кстати! — куплен давным-давно, для одной затеи), в котором отрисовываем из квадратиков матрицу 128х32.
До этого я обратил внимание, что английский шрифт изначальной библиотеки имеет высоту в 7 пикселей, и я решил, что, наверное, будет хорошей идеей, если буквы у меня будут также иметь высоту в 7 пикселей, чтобы иметь возможность использовать цифры из английского шрифта.
Забегая вперёд скажу, что когда я вошёл в азарт, я решил, что нарисую и все остальные цифровые и символьные знаки, которые, как мне кажется, имеют значение для каких-либо ситуаций. Однако, я не включил сюда все возможные варианты символов «на все случаи жизни». Но вы вполне можете отрисовать свои собственные, и добавить их в код!
Ну и, кроме того, надписи подобной высоты, вполне неплохо смотрятся, так как у меня была возможность в этом убедиться на примере английского шрифта.
В целом, после того как алфавит и символы были набросаны на матрицу, это стало выглядеть как-то примерно так (кликабельно):

Сразу скажу, что не все символы, которые поддерживают библиотека, показаны на картинке. Полный список поддерживаемых символов вы можете найти в pdf-файле по ссылке.
Дальше началась долгая упорная работа «по перетаскиванию всех букв в левый верхний угол» и внесению координат пикселей, необходимых для включения — в вордовский файл (уже когда вся работа по созданию ПО была завершена — я увидел, что в разметке матрицы есть косяк — отсчёт идёт не с нуля, а с единицы :-). Этот момент в коде поправлен, так что на картинках — не обращайте внимания).
Как я уже говорил, мы будем использовать для своей работы две изначальные функции — для включения отдельного пикселя и для рисования линии. Функция для рисования линии требует координаты X Y начальной точки и конечной точки линии.
После внесения всех символов в вордовский файл это стало выглядеть примерно как-то так:

Здесь данные для передачи в функцию линии показаны чёрным цветом, а для передачи в функцию включения пикселя — выделены красным цветом, просто чтобы не путать.
Ну а дальше начинаем кодить!
Так как каждая буква должна отображаться на новом месте, то необходимо после отображения буквы смещать оффсет — стартовую позицию каждой новой буквы. Так как ширина букв имеет значение в 5 пикселей, то после отображения каждой буквы мы значение смещения увеличиваем на 7 — на ширину буквы + 2 пикселя между ними (это не касается узких символов типа: «.,:|» — там смещение идёт на 3 единицы).
Сначала я хотел все эти оффсеты добавить сразу в вордовский файл, в таблицу, которую уже показывал ранее. Однако подумал, что это будет несколько загромождать ведь код, поэтому решил передавать все эти координаты в отдельные функции, которые и будут добавлять нужные оффсеты. Получилось как-то так (функции длинные, вылезут за поле хабра, посему — вставляю картинками):


После того как заданы оффсеты с корректировками, их необходимо непосредственно отрисовать — а для этого их нужно передать в функцию изначальной библиотеки, которая и занимается отрисовкой.
Автор изначальной библиотеки создал отдельный класс OLED, в котором и имеются все требуемые функции. Поэтому нам приходится передавать объект этого класса в нашу функцию, а уже у этого объекта, в свою очередь, вызывать требуемый функционал.
Так как я изначально представлял себе этот «отрисовщик русского шрифта» в виде некой вызываемой компактной функции, именно так я и сделал:
void RuCharPrinter (String s, int x, int y, OLED &object)
{
//тут код
}
Как можно видеть по этой функции, она на вход принимает строку (что должно быть отображено на экране), а также начальные координаты по X Y, с которых и начинается отображение.
Кроме того, в функцию передаётся по ссылке и объект класса OLED ( чтобы не множить сущности).
Функция содержит достаточно длинную «портянку» кода, который обрабатывает отображение букв, передавая их отдельной подфункции для отрисовки линий или точек. Для примера посмотрим, как выглядит типовая буква, например, буквы а, б, в:
if (temp==176) //буква а
{
lineDrawer (2,1,4,1,x,y, object);
lineDrawer (1,2,1,7,x,y, object);
lineDrawer (5,2,5,7,x,y, object);
lineDrawer (2,4,4,4,x,y, object);
isCharFinded=true;
}
else if (temp==177) //буква б
{
lineDrawer (2,1,5,1,x,y, object);
lineDrawer (1,1,1,7,x,y, object);
lineDrawer (2,3,4,3,x,y, object);
lineDrawer (5,4,5,6,x,y, object);
lineDrawer (2,7,4,7,x,y, object);
isCharFinded=true;
}
else if (temp==178) //буква в
{
lineDrawer (2,1,4,1,x,y, object);
lineDrawer (1,1,1,7,x,y, object);
pixelDrawer (5,2,x,y, object);
lineDrawer (2,3,4,3,x,y, object);
lineDrawer (5,4,5,6,x,y, object);
lineDrawer (2,7,4,7,x,y, object);
isCharFinded=true;
}
//и т.д. — это не конец...
Мы видим, что код получается достаточно компактным и лаконичным.
Что же касается чтения букв из полученной строки, перед их отображением, с этим пришлось поломать голову. Потому что кириллический шрифт для своего хранения использует 2-байтовую кодировку, шрифт идёт в формате UTF-8. То есть, каждая буква кодируется двумя цифрами:

Полную таблицу по кодам для UTF-8 (и не только) вы можете найти вот по этой ссылке.
Возвращаясь к сказанному ранее, можно сказать, что мы просто фильтруем одну из цифр, которая общая почти для всей подборки: 208 или 209. И берём в качестве цифрового кода (по которому мы делаем вывод, какая буква перед нами) только вторую цифру.
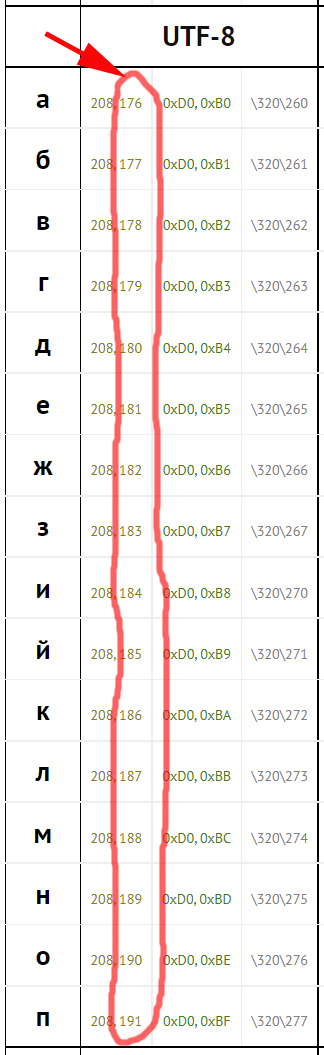
Для этого, в самом начале разбора строки, мы приводим конкретный элемент строки — к цифре. И уже из этого, делаем выводы:
int temp = int (s[i]);
if (temp==176) //буква а
{
//тут код
}
//и т.д.
Ну и ряд других моментов, которые, наверное, будут не настолько интересны широкой аудитории, чтобы о них распространяться…
И потом отладка, отладка, отладка…
И… наступает волнующий момент… Оно дышит!!! :-)

Сразу скажу — на этом фото и на последующих — фото не передаёт яркости и сочности цвета. Кроме того, выглядит полуразмытым (смартфон не может навестись точно, из-за высокой яркости букв). В реале это выглядит чётко, сочно и ярко-зелёно.
И на этом можно было бы и закончить наш рассказ… Но, чего-то не хватает!
А именно — вывода:
Код полностью рабочий, его можно вполне использовать, но больно уж он громоздкий, даже если мы создадим для него отдельную вкладку…Но можно применить гораздо более элегантное решение: а давайте-ка, сделаем из этого кода полноценную подключаемую библиотеку!
В случае со средой Arduino IDE для этого нужно не так уж много, всего лишь необходимо:
- Код функций перенести в файл, который нужно сохранить с расширением .cpp (что расшифровывается как «c plus plus»).
- Название самих функций — в другой файл, который необходимо сохранить с расширением .h ( header — «заголовок»).
- Потом папку с этими двумя файлами необходимо перенести в вашу директорию, где находятся все библиотеки. Например, вот сюда:
C:\Users\USERNAME\Documents\Arduino\libraries
После этого использование кода становится элементарным: мы всего лишь подключаем изначальную библиотеку, подключаем нашу новую библиотеку, и для теста выводим алфавит и символы, которые я набросал в файле Corel Draw:
#include <OLED_I2C.h>
#include <RU_OLED_128x32_library.h>//наша библиотека
OLED myOLED(18, 19); // OLED display pins (SDA, SCL)
boolean b = false;
void setup()
{
if(!myOLED.begin(SSD1306_128X32))
{ while(1); }
Serial.begin (115200);
}
void loop()
{
if (!b)
{
myOLED.clrScr(); //очистка экрана, перед отображением чего то нового
RuCharPrinter ("абвгдежзийклмнопрс", 0, 0, myOLED);
RuCharPrinter ("туфхцчшщъыьэюя.:!?", 0, 13, myOLED);
RuCharPrinter ("0123456789()/#@%|*$", 0, 24, myOLED);
b=true;
}
}После чего мы видим на экране то, что и хотели получить:

Что и требовалось доказать.
Экранчик приветствует всех читателей :-)

Саму библиотеку вы можете скачать вот по этой ссылке, и использовать, модифицировать — абсолютно свободно.
Успехов в создании собственных самоделок!
P.S. Для своей работы моя библиотека требует инсталляцию изначальной библиотеки (так как является надстройкой над ней), поэтому её тоже необходимо установить, пройдя вот по этой ссылке.
Теоретически можно было пойти ещё дальше и встроить поддержку русского языка — прямо в изначальную библиотеку. Но я так делать не стал, чтобы несколько разделить своё решение и библиотеку-основу. А вот вы можете попробовать. Заодно и малость прокачаете свой скилл ;-)

Комментарии (21)

YDR
16.05.2022 12:13+13(теперь я знаю, что такое векторный велосипед из костылей...)
В чипе для этого дисплея есть команда отправки двоичных данных непосредственно с помещением их в видеопамять. Она предназначена как раз для вывода символов и других растров. Вот ее и нужно использовать. А битовые картинки символов ("знакогенератор") нужно просто помещать в отдельную область памяти.
Я бы понял, если бы хотелось получить произвольную масштабируемость, и не нужна была бы скорость отображения...
Вывод символа - если хочется - можно сделать свой, пусть и с поддержкой utf-8.
ESP32 тоже может в Ардуино, кстати.
Своеобразный подход.

DAN_SEA Автор
16.05.2022 12:27+5Господа, в самом начале я написал - что просто воспользовался имеющейся библиотекой-основой и, опираясь на её возможности - создал своё решение. Но, разумеется всегда можно пойти и "глубжее" и сделать правильней :-)
В любом случае, выложил свое полностью готовое (и работающее!) решение. Буду рад видеть ваш более продуманный и эффективный вариант ;-)

FGV
16.05.2022 12:29+1
daggert
17.05.2022 12:49Вам не кажется что это чуток другое? А точней вообще другое. Еще точней совсем другая весовая категория никак не сравнимая с oled i2c.
FGV
17.05.2022 14:29Это смотря какой размер экрана и что надо отображать на нем. Для 128*32 может и жирновато будет, но чую что будет меньше жрать памяти и шустрее работать чем реализованное в статье.
daggert
18.05.2022 16:44В этой библиотеке 16-битка минимумом и 180 килобайт флешки и весьма-весьма неплохой жор оперативки (:
Эта либа более для больших экранов, от 512.FGV
18.05.2022 17:18...180 килобайт флешки и весьма-весьма неплохой жор оперативки (:
Для esp32 с ее мегабайтными флэшками это фигня.
Эта либа более для больших экранов, от 512.
Соглашусь что для 128*16 она жирновата. Про 512 - несогласен, как пример - T-Wath (экран 240*240): https://github.com/Xinyuan-LilyGO/TTGO_TWatch_Library

iliasam
16.05.2022 14:36+6Я не поленился, скачал библиотеку-основу "OLED_I2C".
В ней есть поддержка работы с текстом, растровые шрифты лежат в файле "DefaultFonts.c".
Каждая буква кодируется 5 байтами (по байту на вертикальную линию символа).
Нужно было только добавить туда русские шрифты.
Пример массива: http://arduino.ru/forum/pesochnitsa-razdel-dlya-novichkov/dorabotka-biblioteki-russkogo-shrifta
Возможно, нужно немного подправить функцию "OLED::_print_char".Есть и другие библиотеки уже с поддержкой русского: https://github.com/GyverLibs/GyverOLED - там тоже можно таблицу символов посмотреть: https://github.com/GyverLibs/GyverOLED/blob/main/src/charMap.h

vladcod
16.05.2022 14:48+4void LCD_Chr(u8 ch, u8 invers) { u8 i; lcd_buff_idx=y_cur * 128 + x_cur * 6; if ((ch >= 0x20)&&(ch <= 0x7F)) ch -= 32; else if (ch>=0xC0) ch-=96; else ch = 95; for (i=0;i<5;i++) { if(invers) lcd_buff[lcd_buff_idx++] = ~(font[ch][i]); else lcd_buff[lcd_buff_idx++] = font[ch][i]; } ... } const u8 font [][5] = // { { 0x00, 0x00, 0x00, 0x00, 0x00 }, // 0x20 32 ... { 0x06, 0x09, 0x09, 0x06, 0x00 }, // ~ 0x7E 126 { 0x1C, 0x3E, 0x7C, 0x3E, 0x1C }, // 0x7F 127 { 0x7C, 0x12, 0x11, 0x12, 0x7C }, // А 0xC0 192 { 0x7F, 0x49, 0x49, 0x49, 0x31 }, // Б 0xC1 193 ... { 0x7C, 0x10, 0x38, 0x44, 0x38 }, // ю 0xFE 254 { 0x48, 0x54, 0x34, 0x14, 0x7C } // я 0xFF 255 };Надеюсь, идея понятна.

lamerok
16.05.2022 15:09if (temp==176) //буква а
{
lineDrawer (2,1,4,1,x,y, object);
lineDrawer (1,2,1,7,x,y, object);
lineDrawer (5,2,5,7,x,y, object);
lineDrawer (2,4,4,4,x,y, object);Если вы знаете как все буковки рисуются, вы можете нарисовать их на этапе компиляции в буфер ПЗУ. А потом просто из этого буфера переправить данные в буфер отрисовки. Тогда, скорость отрисовки резко увеличится, поскольку львиная часть работы будет сделана на этапе компиляции и вам не нужен будет внешний генератор.


dlinyj
16.05.2022 14:51+4Как хорошо, что написана такая статья. Вообще, хабр сова торт, в комментариях можно узнать много хороших решений.
В своё время тоже писал большую библиотеку работы с дисплеем.


sav13
16.05.2022 17:03+7одна беда — известные библиотеки для него поддерживают только латинский шрифт. Ситуация усугубляется тем, что я использую его для подключения к esp32, а не Arduino. Поэтому arduino-библиотеки можно сразу отбросить. Что с этим делать и как дальше жить, об этом мы и поговорим в этой статье.
Прежде чем самоотверженно бросаться на создание велосипеда, лучше немного погуглить )))
К Adafruit GFX и U8Glib нормально подключаются русские шрифты
Обе эти библиотеки поддерживают кучу архитектур, в том числе и ESP32

roofcat
16.05.2022 18:43+1Возможно, я ошибаюсь, но, по-моему, в Esphome для oled displays на базе контроллера 1306 (и не только) реализована возможность трансформации и загрузки произвольного TTF фонта в память дисплея. на таком малыше я не экспериментировал, но на большем размере все работало.

ColdHam
17.05.2022 00:59+4Я конечно вообще не разу не кунг-фу программист микроконтроллеров, но на гитхабе тысячи библиотек для работы с этими дисплеями на любой вкус. Все они так или иначе обслуживают рисование линий кружочков и прочих примитивов, но шрифты - это всегда просто static массив пикселей, который грузится в буфер и пачкой отправляется в экран (i2c, spi не важно). Архитектура микроконтроллера тоже не существенна - заменяется 2 функции - отправка байта и отправка массива в соответствии с выбранным МК. Рисование букв линиями - свежо, новаторски. Но в основном затратно)

madcatdev
17.05.2022 02:48+1Чтобы не мучаться в Corel, для создания таких шрифтов есть программа LCD Vision, она кстати умеет импортировать системные шрифты, и генерировать набор символов в виде массива байт.
Символы лучше хранить в виде массива байт, в вашем случае это выйдет (5*7)/8 = 5 байт на символ. При отрисовке просто передаете эти данные в видеопамять дисплея, предварительно выбрав область видеопамяти.
UTF-8 не лучшее решение, лучше взять кодировку ANSI.

SlavaS80
17.05.2022 08:48За марку дисплея благодарю, за реализацию - присоединяюсь к критике по поводу решения отрисовывать на растровом дисплее русский текст с матрицей ?х8 (как я понимаю, у Вас шрифт с разной шириной в пикселях).
Ваше решение имеет смысл при использовании масштабируемых шрифтов (привет тем, кто помнит BGI шрифты) или при отрисовке шрифтов большого размера.
В случае использования растрового шрифта Вам бы хватило максимум 7 байт на букву (буква Щ кодируется матрицей 6 на 8 пикселей, плюс 1 байт на ширину).
Желаю Вам творческих успехов и становления как высококлассного программиста, в том числе встраиваемых решений.

bat654321
17.05.2022 09:46+4Международная конференция хирургов. Доклад русских:
- Мы научились делать операцию по удалению гланд. В зале свист, возмущение,
дескать что там гланды, все умеем.
- Через анальный проход...
- О-оооо, зачем через анус?
- А у нас все через жопу делается.
FGV
Нда, полный звиздец. Никогда так не делайте. В данном случае рисование линий и установка/сброс пикселей - лишняя трата ресурсов.
Если уж надо строку напечатать - разбейте ее на буквы-спрайты и лейте их через i2c напрямую в память экрана, или сначала рисуйте в памяти/буфере потом через dma шлите в экран (благо 128*32 много места в озу не занимает).