
Интро: почему я написал эту статью
Меня зовут Виктор, я разрабатываю страницу результатов поиска Яндекса. Несмотря на внешнюю простоту, поисковая выдача — сложная штука: на каждый запрос генерируется своя уникальная страница, на которой в зависимости от запроса может присутствовать блок Картинок, Карты, Переводчик, видеоплеер и многие другие компоненты. Все они должны запускаться и работать в памяти обычных бюджетных телефонов, которые использует большинство наших пользователей. Браузерам должно хватать ресурсов, чтобы пользователь не видел вот такого:

На своих серверах мы должны генерировать сотни миллионов уникальных страниц в сутки — это сложнее, чем просто отдавать одни и те же ресурсы. Генерация страницы не должна быть слишком требовательной к памяти сервера.
Разрабатывая проект на JavaScript (TypeScript, ClojureScript или каком-то другом языке, транслируемом в JavaScript), мы привыкли создавать объекты, массивы, строки и вообще писать код, как будто память бесконечна. Это не так. Я расскажу о видах проблем с памятью, о том, какие ограничения мы часто забываем и как их можно преодолеть. В ответ браузеры и пользователи скажут вам спасибо.
- Категории проблем с памятью
-
Ограничения по памяти для разных типов данных
Heap
Buffer, TypedArray
String
Map, Set
Call stack
Типичные задачи, в которых можно наткнуться на ограничения по памяти -
Soft-утечки
Пример из продакшена
Как получаются soft-утечки
Как их обнаружить
Как найти причину
1. Memory Allocation Timeline
2. Техника трёх снапшотов
3. queryObjects
Тренируемся находить утечки -
Hard-утечки
Пример из продакшена
Как бороться -
Нестандартные оптимизации памяти в Node.js
Исходный код
Module._pathCache
Несколько версий пакета в node_modules
require('./data.json') - Заключение
Категории проблем с памятью
JavaScript наряду с Java, C# и Python принадлежит к языкам с автоматической сборкой мусора.
Проблемы с памятью в таких языках можно разделить на три категории:
- Не-утечки: код и данные, которые упираются в ограничения по памяти. Ограничения могут быть либо искусственными — заложенными в язык или среду выполнения, либо естественными — вытекающими из характеристик железа, на котором выполняется код.
- Soft-утечки (мягкие, локальные утечки): что-то мешает сборщику мусора освободить память, например, список содержит в одном из элементов ссылку на давно не нужный объект.
- Hard-утечки (жёсткие, глобальные утечки): память не освобождается, пока браузер или вся операционная система не будут перезапущены.
Важно отличать утечки от неоптимального кода с высоким потреблением памяти: иногда слова «у меня страница течёт» некорректно используются там, где открыто жадное до памяти приложение, но утечки при этом отсутствуют.
Далее я подробно расскажу о каждой из трёх категорий: что она из себя представляет, как её обнаружить, как с ней бороться.
Ограничения по памяти для разных типов данных
Систематизировать свои знания по ограничениям меня побудила эта заметка Романа Дворнова.
Heap
Во многих реализациях языков с автоматической сборкой мусора — хоть и не во всех — для динамического выделения памяти используется куча, она же heap. Например, это языки на основе JVM — Java, Kotlin и так далее. Кучу использует и движок JavaScript V8. Соответственно, размер кучи — самое главное ограничение, с которого надо начинать разбираться.
Компактное и интересное описание того, как в V8 устроена память вообще и куча в частности, можно найти в этой статье. Вот самая ценная картинка оттуда:

В Chrome и других браузерах, основанных на Chromium, текущее состояние хипа можно узнать из performance.memory:
> console.log(performance.memory)
MemoryInfo {totalJSHeapSize: 10000000, usedJSHeapSize: 10000000, jsHeapSizeLimit: 3760000000}- Описание возвращаемого результата на MDN.
- Поддержка в браузерах на сайте Can I use.
С появлением performance.memory в Chrome связана интересная история. Во время роста популярности Gmail в 2010-2012 годах пользователи начали всё чаще жаловаться на высокое потребление памяти браузером. В Google разработчики Gmail пришли к разработчикам Chrome и убедили тех добавить возможность получать из JS информацию о состоянии памяти и усовершенствовать инструменты работы с памятью в DevTools. После этого разработчики Gmail добавили в своё почтовое приложение сбор данных о памяти у клиентов, нашли и исправили несколько утечек. И вообще — в разы уменьшили потребление памяти: примерно в два раза на медиане и в пять раз на 99-й процентили. Кроме исправления уже существующих багов, мониторинг памяти в Gmail помогает оперативно находить и устранять проблемы с памятью в новых версиях приложения и даже баги в сборщике мусора в новых версиях Chrome (обратите внимание, на вертикальной оси отложены не абсолютные значения в мегабайтах, а кратные какой-то базовой величине x):
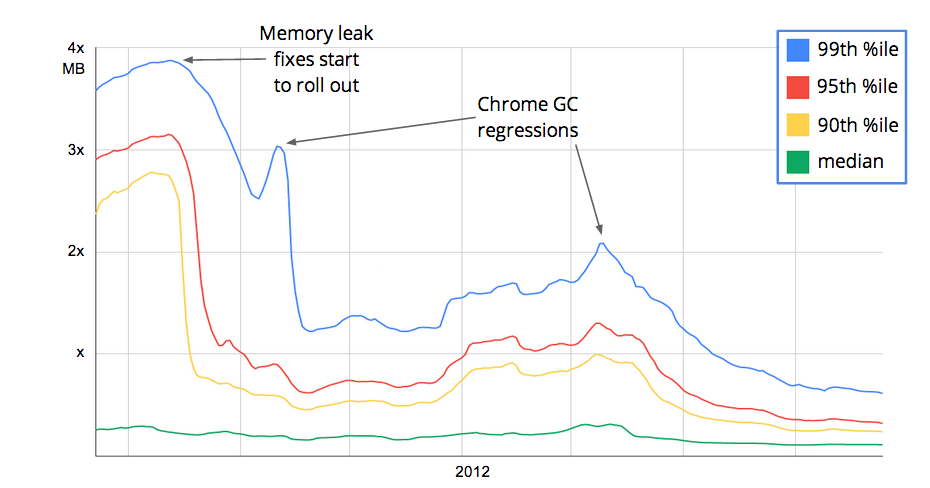
В других браузерах — Firefox, Safari — память устроена аналогично. В Firefox даже есть специальная страница about:memory, на которой можно увидеть детальное состояние памяти и вызвать сборку мусора. Проблема в том, что в этих браузерах неизвестен способ из кода на JS получить состояние хипа. Если у вас есть такая информация — пишите в комментариях.
В Node.js состояние памяти можно узнать вызовом process.memoryUsage():
$ node
Welcome to Node.js v16.8.0.
Type ".help" for more information.
> console.log(process.memoryUsage())
{
rss: 26689536,
heapTotal: 6656000,
heapUsed: 4633936,
external: 893129,
arrayBuffers: 11158
}Документация по process.memoryUsage() находится здесь.
С получением текущего состояния хипа разобрались, теперь к ограничениям. В Chrome и Node.js максимальный размер хипа определяется при старте:
- Если в командной строке указаны параметры, настраивающие размер хипа, то значение берётся оттуда.
- Иначе значение вычисляется в зависимости от архитектуры (32- или 64-битная) и объёма физической памяти.
Насколько мне удалось разобраться, максимальный размер хипа определяется так (если у вас есть дополнения и уточнения — пишите, исправлю):
| Версия | Heap size 32-bit | Heap size 64-bit |
|---|---|---|
| Node.js <= 11 | 700 МБ | 1400 МБ |
| Chrome <= 82, Node.js 12 | Физ. память / 4, но не меньше 128 МБ и не больше 1 ГБ | Физ. память / 2, но не меньше 256 МБ и не больше 2 ГБ |
| Chrome >= 83, Node.js >= 14 | См. выше | См. выше. Если физ. памяти >= 16 ГБ, то максимум увеличен до 4 ГБ |
Подробности о значениях и логике выбора в Node.js можно почитать в этом комментарии к пул-реквесту. Соответствующий код в движке V8: Heap::HeapSizeFromPhysicalMemory, ResourceConstraints::ConfigureDefaults.
Параметры командной строки для V8, управляющие размерами областей хипа:
$ node --v8-options | grep -- -size
…
--min-semi-space-size (min size of a semi-space (in MBytes), the new space consists of two semi-spaces)
--max-semi-space-size (max size of a semi-space (in MBytes), the new space consists of two semi-spaces)
--max-old-space-size (max size of the old space (in Mbytes))
--max-heap-size (max size of the heap (in Mbytes) both max_semi_space_size and max_old_space_size take precedence. All three flags cannot be specified at the same time.)
--initial-heap-size (initial size of the heap (in Mbytes))
--huge-max-old-generation-size (Increase max size of the old space to 4 GB for x64 systems withthe physical memory bigger than 16 GB)
--initial-old-space-size (initial old space size (in Mbytes))
…
--stack-size (default size of stack region v8 is allowed to use (in kBytes))Самый известный и широко используемый из них — это --max-old-space-size, позволяющий увеличить размер Old Space. Например, если на устройстве достаточно физической памяти (пусть будет 32 ГБ) и нашей программе не хватает 4 ГБ, выделенных ей по умолчанию, то мы можем запустить её так:
node --max-old-space-size=8000 index.jsО тонкостях настройки памяти, если Node.js выполняется в контейнере Docker, можно почитать в этой хабрастатье.
Buffer, TypedArray
Максимальная длина одного буфера или типизированного массива в Node.js ограничена константой. Сама константа добавлена в Node.js v8.2.0, но ограничение существовало и до этого, насколько я знаю.
require('buffer').constants.MAX_LENGTHЗначение константы зависит от версии и разрядности Node.js:
| Версия Node.js | 32-bit | 64-bit |
|---|---|---|
| 8.2.0…13 | 2**30-1 (~1 ГБ) | 2**31-1 (~2 ГБ) |
| 14 | 2**30-1 (~1 ГБ) | 2**32-1 (~4 ГБ) |
| 15…16 | 2**30-1 (~1 ГБ) | 2**32 (4 ГБ) |
Пример кода:
// Node.js v12 64-bit
new Int8Array(2**31-1)
// Int8Array(2147483647)
new Int8Array(2**31)
// Uncaught RangeError: Invalid typed array length: 2147483648
// at new Int8Array (<anonymous>)
new Uint32Array(2**31-1)
// Uint32Array(2147483647)
new Uint32Array(2**31)
// Uncaught RangeError: Invalid typed array length: 2147483648
// at new Uint32Array (<anonymous>)Теперь о браузере Chrome. В исходном коде V8 есть максимальное разрешённое значение длины типизированного массива v8::TypedArray::kMaxLength:
/*
* The largest typed array size that can be constructed using New.
*/
static constexpr size_t kMaxLength =
internal::kApiSystemPointerSize == 4
? internal::kSmiMaxValue // 2147483647 (но это не точно)
: static_cast<size_t>(uint64_t{1} << 32); // 4294967296К сожалению, v8::TypedArray::kMaxLength никак не прочитать из JS. Единственное, что я смог найти: в Node.js начиная с 14 версии значения JSArrayBuffer::kMaxByteLength и JSTypedArray::kMaxLength (оно равно v8::TypedArray::kMaxLength) доступны при включённой опции --allow-natives-syntax в виде функций %ArrayBufferMaxByteLength() и %TypedArrayMaxLength():
$ nvm use v16 && node --allow-natives-syntax
Welcome to Node.js v16.8.0.
Type ".help" for more information.
> %ArrayBufferMaxByteLength()
9007199254740991
> %TypedArrayMaxLength()
4294967296
> .exit
$ nvm use v14 && node --allow-natives-syntax
Welcome to Node.js v14.17.5.
Type ".help" for more information.
> %ArrayBufferMaxByteLength()
9007199254740991
> %TypedArrayMaxLength()
4294967295
> .exit
$ nvm use v12 && node --allow-natives-syntax
Welcome to Node.js v12.18.1.
Type ".help" for more information.
> %ArrayBufferMaxByteLength()
%ArrayBufferMaxByteLength()
^
Uncaught SyntaxError: ArrayBufferMaxByteLength is not defined
> %TypedArrayMaxLength()
%TypedArrayMaxLength()
^
Uncaught SyntaxError: TypedArrayMaxLength is not defined
> .exitНо вернёмся к браузеру Chrome. При попытке создать типизированный массив с длиной, превышающей v8::TypedArray::kMaxLength, браузер выбросит ошибку:
> new Int8Array(2**33)
Uncaught RangeError: Invalid typed array length: 8589934592Если длина будет меньше максимальной, но массив не поместится в память, браузер выбросит ошибку с другим сообщением:
> new Int8Array(2**32)
Uncaught RangeError: Array buffer allocation failedВ браузере Firefox максимальный объём типизированного массива в байтах maxByteLength() вычисляется как равный максимальному размеру внутреннего буфера ArrayBufferObject::maxBufferByteLength(). В 64-битной архитектуре с поддержкой больших буферов он равен 8 ГБ, в остальных случаях — 2 ГБ (2147483647, константа INT32_MAX). Максимальная разрешённая длина массива рассчитывается как maxByteLength() / BYTES_PER_ELEMENT, причём эти расчёты разбросаны по всему коду, например здесь и здесь. Как и в Chrome, эти значения недоступны из JS.
При невозможности создать типизированный массив желаемой длины N можно увидеть такие сообщения об ошибке (обратите внимание, что в Node.js и Chrome число N может попасть в сообщение, и это может помешать группировке и подсчёту однотипных ошибок):
| Платформа | Сообщение |
|---|---|
| Node.js | RangeError: Invalid typed array length: N |
| Chrome | RangeError: Invalid typed array length: N |
| Chrome | RangeError: Array buffer allocation failed |
| Safari | Error: Out of memory |
| Firefox | RangeError: invalid array length |
С помощью этого и этого скрипта я определил максимальные достижимые размеры Int8Array и Int32Array:
| Версия | Макс. длина Int8Array
|
Макс. длина Int32Array
|
|---|---|---|
| Chrome 99…102 MacOS и Windows | 2_145_386_496 (2**31-2_097_152, ~2 ГБ) | 536_346_624 (2**29-524_288, ~512 МБ) |
| Chrome 99 Android | 1_073_741_823 (2**30-1, ~1 ГБ) | 334_082_048 |
| Safari 13 MacOS | 2_147_483_647 (2**31-1, ~2 ГБ) | 536_870_911 (2**29-1, ~512 МБ) |
| Firefox 96…100 MacOS и Windows | 8_589_934_592 (2**33, 8 ГБ) | 2_147_483_648 (2**31, 2 ГБ) |
Для всех браузеров кроме Chrome Android максимальная длина Int32Array в четыре раза меньше длины Int8Array (Int8 — это один байт, Int32 — четыре байта, поэтому элементов Int32 в той же памяти может поместиться в четыре раза меньше, чем элементов Int8). В Chrome Android я, скорее всего, столкнулся с нехваткой физической памяти телефона.
String
Длина строки находится в поле length. В Node.js максимальное значение length ограничено константой.
require('buffer').constants.MAX_STRING_LENGTHОбратите внимание, что это не количество букв в строке, а именно число в поле length (в строгой формулировке — количество UTF-16 code units). Разные буквы и символы могут состоять из одного или двух code units:
console.log('Z'.length); // 1
console.log('Я'.length); // 1
console.log('????'.length); // 2Как один code point (для того же смайлика) превращается в два code unit, можно прочитать в спецификации ES2016.
В браузерах тоже есть ограничения на максимальную длину строки. Конкретные значения я определил с помощью такого скрипта и свёл в таблицу:
| Версия | string.length |
|---|---|
| Node.js 12 | 1_073_741_799 (2**30-25, ~1 ГБ) |
| Node.js 16 | 536_870_888 (2**29-24, ~512 МБ) |
| Chrome 94…101 MacOS и Windows | 536_870_888 (2**29-24, ~512 МБ) |
| Chrome 94 Android | Определить не удалось, примерно на 250 мегабайтах на моём телефоне падает вкладка или весь браузер |
| Safari 13 | 2_147_483_647 (2**31-1, ~2 ГБ) |
| Firefox <= 64 | 268_435_455 (2**28-1, ~256 МБ) |
| Firefox >= 65 | 1_073_741_822 (2**30-2, ~1 ГБ) |
| Спецификация ES2016 | 9_007_199_254_740_991 (2**53-1) |
Два важных момента:
- В Node.js 16 максимальная длина строки уменьшилась в два раза по сравнению с предыдущими версиями — это надо учитывать при обновлении Node.js.
- Спецификация ES2016 явно ограничивает длину строки числом, совпадающим с Number.MAX_SAFE_INTEGER.
При превышении допустимой длины строки Node.js и браузеры выдают такие сообщения об ошибке:
| Платформа | Сообщение |
|---|---|
| Node.js, Chrome | RangeError: Invalid string length |
| Safari | Error: Out of memory |
| Firefox | InternalError: allocation size overflow |
Map, Set
В V8 (а следовательно, и в использующих его Node.js и Chrome) есть жёсткое ограничение на количество ключей в Map и Set. При превышении выбрасывается ошибка. В Node.js её текст довольно забавный — см. далее в таблице.
Браузер Firefox в текущей версии захардкоженных лимитов не имеет. При добавлении новых данных в Map и Set он начинает всё сильнее тормозить, потом при первом запуске всё-таки выбрасывает ошибку «out of memory». При повторном запуске кода в том же окне он ещё сильнее тормозит, и ошибки дождаться практически невозможно. Кстати, «out of memory» — это не объект класса Error со стеком, который обычно бросается как-то так...
throw new Error("out of memory");… а простая строка, которую в JavaScript можно бросить вместо объекта ошибки:
throw "out of memory";То есть из такой перехваченной ошибки получить стек и прийти по нему к проблемному месту не получится — поле stack у строки в принципе отсутствует.
Браузер Safari ведёт себя похоже на Firefox — тоже не имеет лимитов, тоже при добавлении данных в Map и Set начинает всё сильнее тормозить, и получить ошибку я так ни разу и не смог.
Доступных из JS констант для максимального количества ключей я нигде не нашёл, значения определял с помощью скрипта:
| Версия | Количество ключей в Map и Set |
|---|---|
| Node.js 12…16 | 16_777_216 (2**24) |
| Chrome 94…101 MacOS и Windows | 16_777_216 (2**24) |
| Chrome 101 Android | 16_777_216 (2**24) |
| Safari 13 | >15_000_000 (сильно тормозит) |
| Firefox 92…96 MacOS и Windows | >131_000_000 (сильно тормозит) |
При превышении допустимого количества ключей в Node.js и Chrome и при исчерпании памяти в Firefox можно увидеть такие сообщения об ошибке:
| Платформа | Сообщение |
|---|---|
| Node.js | RangeError: Value undefined out of range for undefined options property undefined |
| Chrome | RangeError: Map maximum size exceeded |
| Chrome | RangeError: Set maximum size exceeded |
| Safari | (сильно тормозит, не дождался ошибки) |
| Firefox | out of memory |
Call stack
Глубина стека вызовов (максимальное количество вложенных вызовов функций, которое можно сделать) сейчас ни в одной среде выполнения жёстко не зафиксирована и зависит от разных факторов:
- Она быстро уменьшается с добавлением в вызываемые функции параметров и локальных переменных — они занимают дополнительное место в стеке. Например, в Chrome при добавлении в каждую вызываемую функцию четырёх локальных переменных или четырёх параметров с числами small int глубина стека уменьшается примерно с 13 000 примерно до 9000 (конкретные результаты плавают в диапазоне ±10% от версии к версии и от запуска к запуску).
- Она зависит от способа вызова функции (
fn(),fn.call(),fn.apply()). В комментарии к старому багрепорту в Firefox отмечалось, что в одной особенно неудачной ночной сборке Firefox под Linux при использованииfn.call()вместоfn()глубина стека уменьшалась примерно с 7000-40 000 всего до 500. В первом приближении можно считать, что во всех браузерахfn.call()занимает больше памяти на стеке, чем простой вызов функцииfn(). - В Firefox она может меняться в ходе прогрева вызываемого кода. Сначала (в режиме интерпретации) потребление стека сильнее и максимальная глубина, соответственно, меньше. Потом (после компиляции и оптимизации) потребление стека уменьшается, как отмечено в комментарии). Это важно при первом открытии страницы — Firefox видит код в первый раз, выполняет его в режиме интерпретации, глубина стека минимальна, и можно получить сложновоспроизводимый баг.
При превышении допустимой вложенности вызовов Node.js и браузеры выдают такие сообщения об ошибке:
| Платформа | Сообщение |
|---|---|
| Node.js, Chrome | RangeError: Maximum call stack size exceeded |
| Safari | RangeError: Maximum call stack size exceeded |
| Firefox | InternalError: too much recursion |
Значения глубины стека я определил с помощью такого скрипта и, округлив (повторю, что они меняются от запуска к запуску), свёл в таблицу:
| Браузер |
fn() без параметров |
fn(a, b, c, d, e) |
fn.call(this) без параметров |
fn.call(this, a, b, c, d, e) |
|---|---|---|---|---|
| Node.js 12 MacOS 10.15 | 15 700 | 7000 | 14 000 | 6300 |
| Node.js 16 MacOS 10.15 | 14 000 | 6600 | 12 600 | 6000 |
| Chrome 97 Android | 24 500 | 11 600 | 22 100 | 10 500 |
| Chrome 96 и 97 MacOS 10.15 | 13 900 | 6600 | 12 500 | 6000 |
| Chrome 96 и 97 Windows 10 | 13 900 | 6600 | 12 500 | 6000 |
| Safari 13 MacOS | 36 000 | 25 000 | 28 000 | 23 000 |
| Safari 15 iOS | 7900 | 5500 | 6200 | 5000 |
| Firefox 96 MacOS 10.15 (непрогретый код) | 25 100 | 11 500 | 18 400 | 12 100 |
| Firefox 96 MacOS 10.15 (прогретый код) | 39 400 | 23 600 | 29 600 | 19 700 |
| Firefox 96 Windows 10 (непрогретый код) | 26 500 | 10 100 | 9700 | 8700 |
| Firefox 96 Windows 10 (прогретый код) | 39 400 | 23 600 | 29 500 | 19 700 |
Конкретные значения не так важны, важнее увидеть порядок чисел и понять, что счёт допустимой вложенности сколько-нибудь сложных вызовов идёт всего лишь на тысячи. С другой стороны, исходя из багрепортов (вроде вышеупомянутого в Firefox) видим, что некоторые современные сайты и SPA уже имеют максимальную вложенность вызовов больше 500.
Максимальную вложенность вызовов можно оценить. Предположим, что при написании приложения X на фреймворке Y максимальная вложенность компонентов составит N. Например, легко представить десятикратную вложенность компонентов: приложение > страница > шапка > выпадающее меню > попап > список опций > опция > вложенное меню > попап > сообщение о версии приложения. Также предположим, что создание и рендер одного компонента во фреймворке Y требуют M вложенных вызовов. Тогда потребуется N*M вложенных вызовов. В качестве упражнения предлагаю читателям Хабра самостоятельно найти конкретные значения N и M для своих приложений и фреймворков.
Получается, что сейчас в типичных случаях у нас есть как минимум десятикратный запас по глубине стека, но какая-либо проблема (например, неудачная сборка или инсталляция браузера, недостаток памяти на устройстве или слишком сложный код) может легко съесть этот запас. Приведу пример из личного опыта. На одном из моих прошлых мест работы в службу поддержки обратился пользователь, который не мог запустить наше SPA в Internet Explorer. Я начал разбираться, в логах увидел ошибку переполнения стека, измерил глубину стека в браузере пользователя — она была всего лишь около 270 (причину установить не удалось, помогло универсальное средство — переустановка Windows). Пример из другого проекта: ошибки переполнения стека на телефонах логируются в два раза чаще, чем на десктопах. В основном это касается бюджетных или не самых новых моделей вроде Huawei Y5 Lite, Huawei Honor 6A, Samsung Galaxy J2, Samsung Galaxy J5, Alcatel 1 5033D, BQ BQ-5035, BQ BQ-5514 и тому подобных.
Раз уж упомянул про максимальную вложенность компонентов, то позволю себе небольшой офтопик: размеры дерева компонентов (максимальная ширина, максимальная и медианная глубина, суммарное количество компонентов) неплохо подходят для оценки сложности приложения, а такие же размеры DOM-дерева документа в браузере годятся для оценки сложности вёрстки страницы.
Типичные задачи, в которых можно наткнуться на ограничения по памяти
Список, конечно же, не полон. Свои примеры можете присылать в комментариях.
-
Чтение файла в Node.js в память целиком. Налагаемые при этом ограничения:
- размер свободной памяти,
- максимальный размер структуры, в которую читаем файл (
BufferилиString).
В процессе эксплуатации кода рано или поздно кто-то попытается прочитать слишком большой файл.
Как с этим бороться: использовать потоки и/или обрабатывать данные частями (пакетами, чанками).
-
Работа с JSON при помощи
JSON.stringify()иJSON.parse(), то есть преобразование объекта в строку и обратно, или, как ещё говорят, сериализация и десериализация. Налагаемые ограничения:- размер свободной памяти (исходные данные и результат должны одновременно в ней умещаться),
- максимальная длина строки (например, в Node.js 16 не получится вместить в строку 600 МБ данных).
Как и в предыдущем пункте, рано или поздно кто-то попытается обработать слишком большой объём данных.
Как с этим бороться: использовать пакеты @discoveryjs/json-ext, json-stream-stringify, big-json.
Именно такая проблема была в Webpack 4 при использовании
webpack-cliверсий 4.2.0 и ниже — когда проект становился слишком большим, внезапно становилось невозможно получить граф зависимостей и информацию о сборке (файлstats.json). Код записи файлаfs.writeFileSync(dest, JSON.stringify(stats.toJson(…)))упирался в ограничение на максимальную длину строки, получаемой послеJSON.stringify(). Проблема исправлена вwebpack-cli@4.3.0в этом пул-реквесте.
-
Сериализация объекта со множеством ссылок на один и тот же вложенный объект.
const parentObj = {value: 'long string'}; const items = [ {parent: parentObj, data: 1}, {parent: parentObj, data: 2}, {parent: parentObj, data: 3} ];Массив
itemsсодержит в каждом элементе в полеparentссылку на один и тот же объектparentObj, и на сервере достаточно эффективно хранится в памяти: всеparentссылаются на один и тот жеparentObj, то есть память расходуется на один объектparentObjиitems.lengthссылок на него. При сериализации для передачи клиенту наступает «взрыв»: в каждом элементе массива повторяется строка сериализованного объектаparentObj:JSON.stringify(items); // '[{"parent":{"value":"long string"},"data":1},{"parent":{"value":"long string"},"data":2},{"parent":{"value":"long string"},"data":3}]'Довольно просто наткнуться на такую проблему при использовании серверного и клиентского рендеринга вместе: одни и те же компоненты применяются и на сервере, и на клиенте. На сервере рендерим начальное состояние страницы, клиенту отдаём и разметку, и сериализованные данные, клиент производит гидрацию и далее по необходимости ререндерит компоненты.
Как с этим бороться:
- запомнить этот пример и избегать аналогичных ситуаций при написании кода,
- в изоморфном коде (который выполняется и на сервере, и на клиенте) использовать нормализованные данные,
- при отправке клиенту данных для гидрации и ответов на AJAX сделать мониторинг размера отправляемого JSON — это позволит избежать неприятных сюрпризов в будущем (после введения такого мониторинга в нашем проекте мы увидели, что на некоторые AJAX-запросы отправляются JSON в десятки мегабайт).
-
Обработка очень больших массивов с помощью
map(function(element, index, array) { /* … */ })и аналогичных операций. Исходный массив передаётся в параметреarrayв итератор, следовательно, он должен существовать до последней итерации и сборщик мусора ничего не может с ним сделать. При обработке очень больших массивов мы должны учитывать, что и исходный массив, и результат должны одновременно умещаться в памяти. Чтобы уменьшить потребление памяти, можно написать код так, чтобы все операции изменяли элементы в исходном массиве:const array = [/* очень много данных */]; for (let i = 0; i < array.length; i++) { // результат пишем в тот же элемент массива array[i] = processElement(array[i], i); }Сюда же можно отнести использование операторов spread
const array2 = [...array]и restconst [a0, a1, ...array2] = array— в какой-то момент исходный массивarrayи массивarray2существуют в памяти одновременно.Как с этим бороться: самое главное — внимательно и не спеша дочитать статью и понять, что проблема есть только при обработке очень, очень больших массивов. Не надо срочно переписывать половину проекта. Не надо писать в Твиттере, что «map() сжирает в два раза больше памяти, чем старый добрый цикл for(;;)». Не надо избегать использования
map,filter,reduceи всех остальных методов работы с массивами. Надо просто запомнить, что когда придётся обрабатывать действительно большой объём данных, можно использовать следующие приёмы:- обрабатывать данные in-place, то есть перезаписывать элементы исходного массива,
- обрабатывать данные частями (пакетами),
- вместо цепочек
.map().filter().reduce()обрабатывать данные в один проход, - чтобы не объединять вручную весь код из такой цепочки вызовов, можно использовать ленивые коллекции из Lodash или трансдьюсеры из Ramda.
Soft-утечки
Есть два признака, что в коде возникла именно soft-утечка:
- Потребление памяти постепенно растёт. Это главный признак: код без утечки освобождает всю память, которую забрал, а код с утечкой — нет. Рост памяти может быть замаскирован работой остального кода, но при должном навыке его можно заметить — всегда есть какой-то минимум, ниже которого объём используемой памяти не сможет упасть даже после сборки мусора, и этот минимум будет расти. Для тренировки можете намеренно создать утечку и посмотреть, как это отражается на графиках состояния памяти.
- Утечка действует, только пока живёт приложение. Если обновить вкладку браузера или перезапустить node — память вернётся. Это принципиальное отличие soft-утечек от hard-утечек, про которые я расскажу немного позже.
Пример из продакшена
20 апреля 2020 года в релиз одного из наших проектов попал код с утечкой памяти в Node.js. Утечка была не настолько сильной, чтобы код успевал съесть всю память и упасть на машинах разработчиков или во время тестирования релиза, и стала заметна только на боевых серверах. Она проявилась на трёх графиках.
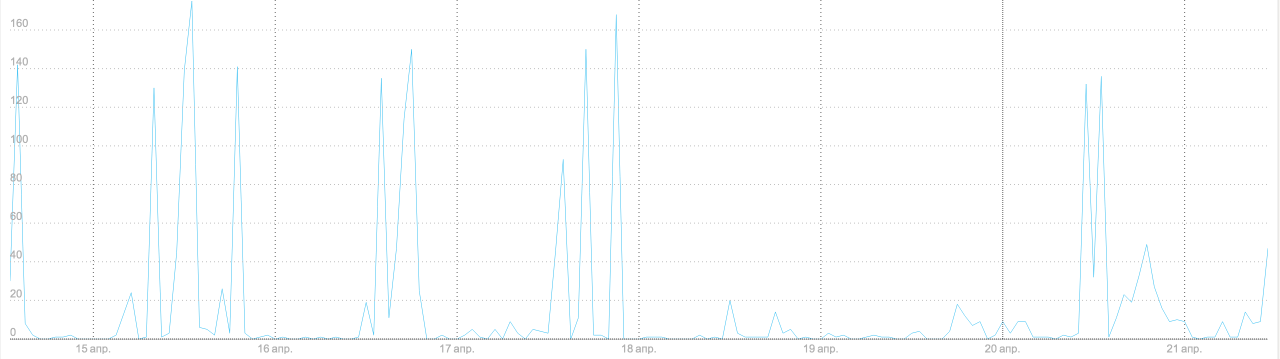
График 1. Количество аварийных завершений Node.js в час
Первым делом дежурные обратили внимание на то, что выросла частота падений Node.js. Падения неизбежно были и раньше, но только в периоды пиковой нагрузки (если экземпляр node не успевает обработать запрос за фиксированный промежуток времени — мы его принудительно перезапускаем) и на особенно тяжёлых запросах (в основном боты, которые парсят выдачу Яндекса, запрашивая по 50-100 документов на страницу), а теперь экземпляры Node.js стали падать и перезапускаться даже ночью, когда частота запросов минимальна.
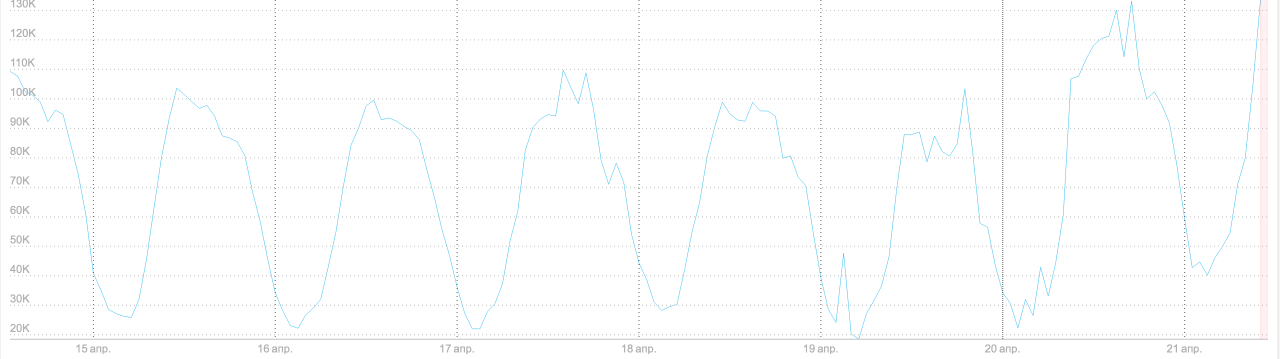
График 2. Количество минорных сборок мусора (minor GC) в час
Из этого графика видно, что минорные сборки мусора стали чаще. Minor GC происходит, когда заканчивается память в young space — той части кучи, куда попадают свежесозданные объекты. График говорит, что появились какие-то проблемы с памятью, но не позволяет определить причину (рост потребления памяти или утечка).

График 3. Использование кучи (process.memoryUsage().heapUsed) на всех серверах Node.js, 95-я процентиль, в мегабайтах
Из третьего графика стало ясно, что дело именно в утечке, а не в новом коде, которому просто надо больше памяти. Здесь видны и суточные колебания в зависимости от приходящих пользователей (люди обычно работают днём и спят ночью), и еженедельные (на выходных характер запросов меняется — люди в основном отдыхают, смотрят видео, заказывают доставку еды...), и колебания из-за рестартов отдельных серверов. Это осложняет анализ, но если обратить внимание на локальные минимумы по ночам, становится видно, что в ночь на 21 число локальный минимум стал заметно выше и короче по времени. То есть часть использованной памяти не освободилась, несмотря на сборку мусора. Именно это — признак утечки памяти.
Как получаются soft-утечки
Очень коротко: причина в несовпадении сроков жизни объектов.
Если подробнее, то причина в том, что долгоживущий объект ссылается на короткоживущие (следовательно, сборщик мусора не может их удалить). Эту формулировку можно разбить на два варианта:
- Неожиданно долгоживущий объект ссылается на короткоживущие объекты.
- Долгоживущий объект неожиданно ссылается на короткоживущие объекты.
Вот конкретные механизмы возникновения утечек, о которых я знаю:
- Неожиданная ссылка на объект из глобальных переменных (
windowв браузере,globalв Node.js) — как прямая, так и через несколько вложенных объектов. - Ссылка на объект из неожиданно долгоживущего колбэка (
setInterval, обработчики событий и тому подобное). Если не остановитьsetInterval, его колбэк останется в памяти со всеми объектами, на которые он ссылается. Если не отписаться от события — аналогично, обработчик события со всеми объектами останется в памяти. Типичный пример: обработчики событийDOMContentLoadedиload. Эти события в процессе открытия страницы наступают только один раз, но немногие разработчики от них потом отписываются. - Неожиданная ссылка из замыкания. Если функция ссылается на объект в замыкании, и в этом же замыкании лежит большой объект, который самой функцией не используется, он всё равно может остаться в памяти. Вот пример утечки из фреймворка Meteor. Больше о замыканиях можно прочитать здесь.
- Неожиданная ссылка в кэше или мемоизаторе. Это одна из основных проблем программирования (напомню, всего их две: выбор имён, очистка кэша и ошибка на единицу). Если вы добавляете кэш или мемоизацию — сразу же продумайте, как ограничить их максимальный размер и в какой момент они будут чиститься. Немного сложнее, если эти возможности «из коробки» предоставляет используемый фреймворк: в процессе его изучения такие тонкости можно упустить, на тестовых проектах уровня «Hello, world!» утечки чаще всего не успевают проявиться, и в результате с проблемами можно впервые столкнуться только на серьёзном проекте. Так как проблема существует довольно давно, действия по её устранению хорошо известны: контроль размера кэша, использование WeakMap и WeakSet, выбор подходящего алгоритма кэширования (почитайте статьи на Хабре и в Википедии).
Как их обнаружить
В продакшене надо собирать данные о памяти клиентов и серверов. Напомню, что в Chrome это можно сделать с помощью performance.memory, а в Node.js — с помощью process.memoryUsage(). По собранным данным можно и нужно строить графики, и очень желательно настроить автоматические алерты, чтобы дежурные получали сигнал при неожиданном росте потребления памяти.
Есть хорошее правило: чем раньше обнаружишь ошибку — тем проще найти причину. Оно применимо и в нашем случае: часть утечек можно обнаружить и быстро устранить ещё до выкатывания релиза.
Если у вас есть А/Б-тестирование, то собираемые данные о памяти должны присутствовать в его результатах (да и другие технические метрики тоже неплохо показывать — например, Core Web Vitals). Это позволит найти и починить утечку ещё на стадии эксперимента. Дополнительный бонус: при А/Б-тестировании легко понять, какой код включался в эксперименте и отсутствовал в контрольной группе, то есть область поиска в коде сильно сужается.
Ещё один этап, на котором можно найти утечку, — тестирование релиза. Для клиентского кода можно написать на Puppeteer тесты для поиска утечек. Основная идея в том, что в Chrome DevTools (а следовательно, и в Puppeteer) есть команда queryObjects() — она возвращает количество объектов, которые живы (на них кто-то ссылается) и принадлежат заданному классу. Если в тестируемом коде есть утечка — количество живых объектов будет расти. Тесты выглядят так.
При тестировании релиза серверный код тоже можно и нужно автоматически проверять на отсутствие утечек:
- Запускаем два сервера, один — контрольный с последним уже опубликованным релизом, второй — с тестируемым релизом.
- Отправляем параллельно на оба сервера достаточно большое количество запросов (одновременно один и тот же запрос отправляем и на контрольный, и на тестируемый сервер).
- Строим графики потребления памяти обоими серверами (используем уже существующий механизм мониторинга памяти).
- Если графики достаточно сильно расходятся — роняем тест.
Чтобы понять, работает ли такой тест вообще, определить нужное количество запросов и настроить пороги для падения теста, лучше всего искусственно добавить в код утечку и отработать все детали на ней. Если тест получится достаточно быстрым и надёжным — можно его запускать на каждом пул-реквесте, а не только в релизе.
Мы для страницы результатов поиска сначала использовали 70 000 запросов, сейчас остановились на 50 000. Анализируем полный размер кучи heapTotal, но графики для rss, heapUsed и external тоже строим и иногда на них смотрим. Тест занимает примерно 45-55 минут. Для пул-реквеста это слишком долго, поэтому автоматически тест запускается только при сборке релиза, но при необходимости в любом пул-реквесте его можно запустить вручную. Приведу примеры получившихся графиков. Красным цветом нарисован heapTotal для серверного кода, собранного из пул-реквеста, синим цветом — для основной ветки репозитория.

Пример 1. Обычный пул-реквест
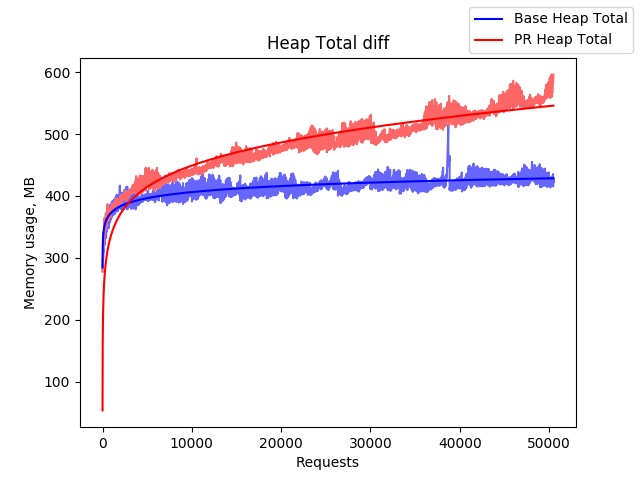
Пример 2. Пул-реквест с утечкой памяти
На втором примере хорошо видно: несмотря на колебания, красный график неуклонно ползёт вверх и не собирается останавливаться.
Как найти причину
Установить, что где-то в коде есть утечка, — лишь половина дела. Дальше надо понять, где конкретно она находится и каков механизм её возникновения. Проще всего это сделать, воспроизведя утечку, найдя в Chrome DevTools оставшийся в памяти объект и отследив путь от объекта до кода, который его создал.
Для серверного кода способ не меняется — его тоже можно отлаживать в Chrome DevTools. Для этого надо при запуске node указать опцию --inspect (подробное описание есть в документации по Node.js и статье Пола Айриша):
node --inspect <ваш_скрипт>.jsЯ знаю три способа, как в Chrome DevTools найти утекающие объекты.
1. Поиск утечек с помощью Memory Allocation Timeline
Memory Allocation Timeline — инструмент в Chrome DevTools, который записывает выделение памяти под объекты и её освобождение. Он хорошо визуализирует, какие участки памяти остаются неосвобождёнными — именно в них и могут находиться утечки (а могут и не находиться). Инструмент применим при поиске утечек, которые можно воспроизвести в течение нескольких минут — именно на столько DevTools хватает ресурсов, чтобы записывать информацию о работе с памятью.
Документация немного устарела (инструмент переименован и перемещён в другую вкладку, внешний вид сильно изменился), но для понимания сути происходящего её всё равно полезно прочитать.
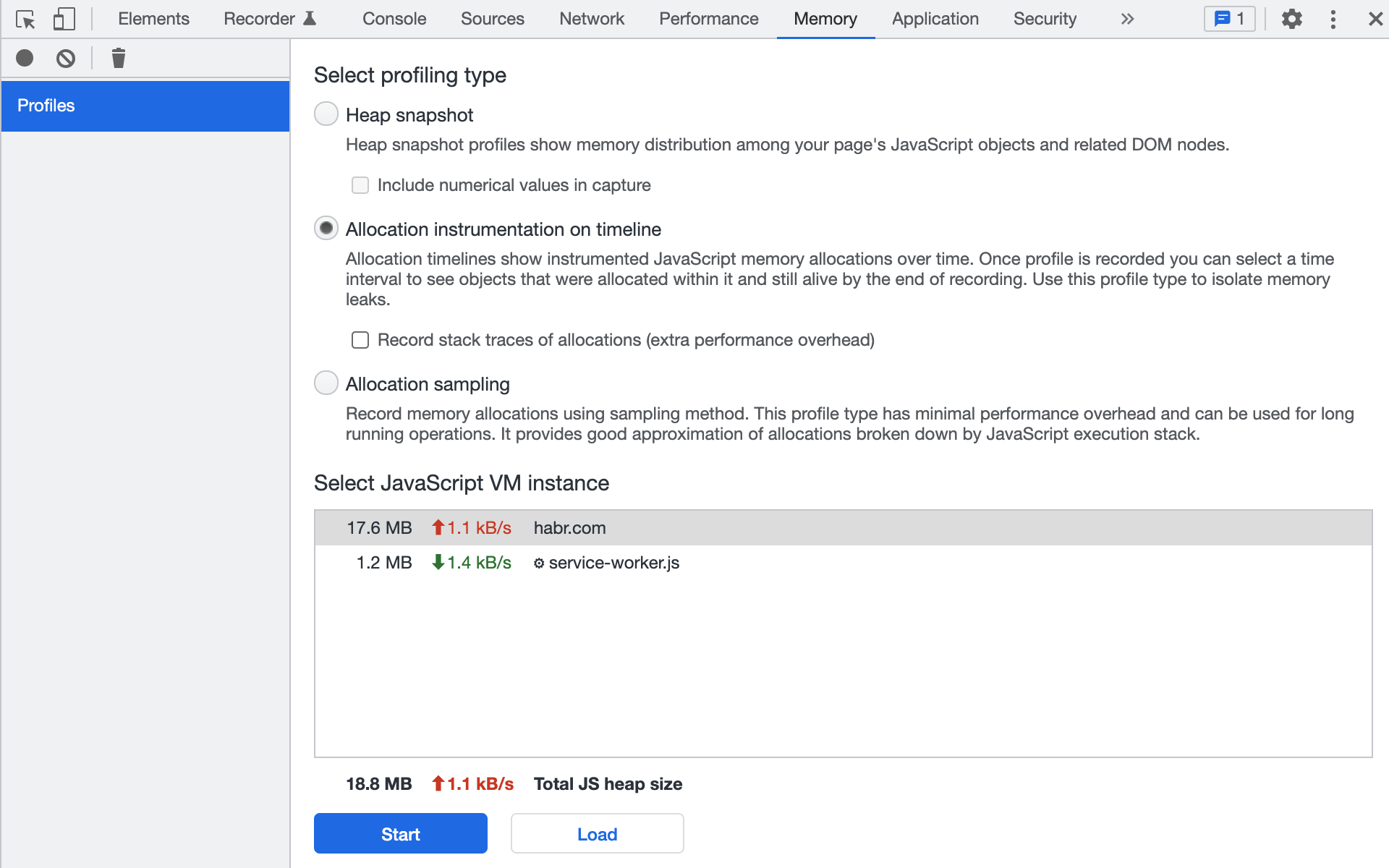
Как пользоваться инструментом (актуальная для Chrome 97 инструкция):
- Открываем в Chrome страницу, на которой собираемся искать утечку.
- Открываем Chrome DevTools.
- Открываем вкладку Memory (раньше была вкладка Profiles).
-
Выбираем Allocation instrumentation on timeline (на скриншоте — внешний вид в Chrome 97).
- Прогреваем страницу: несколько раз совершаем действия, которые, по нашему подозрению, приводят к утечке.
- Включаем запись кнопкой Start.
- «Под запись» несколько раз повторяем те же действия.
-
Вертикальные полоски («палочки») на таймлайне — это память, которая в тот момент времени потребовалась каким-то объектам. Серый цвет — память уже освобождена, синий цвет — до сих пор занята. Полоска может быть частично синей, это значит, что часть памяти ещё используется.
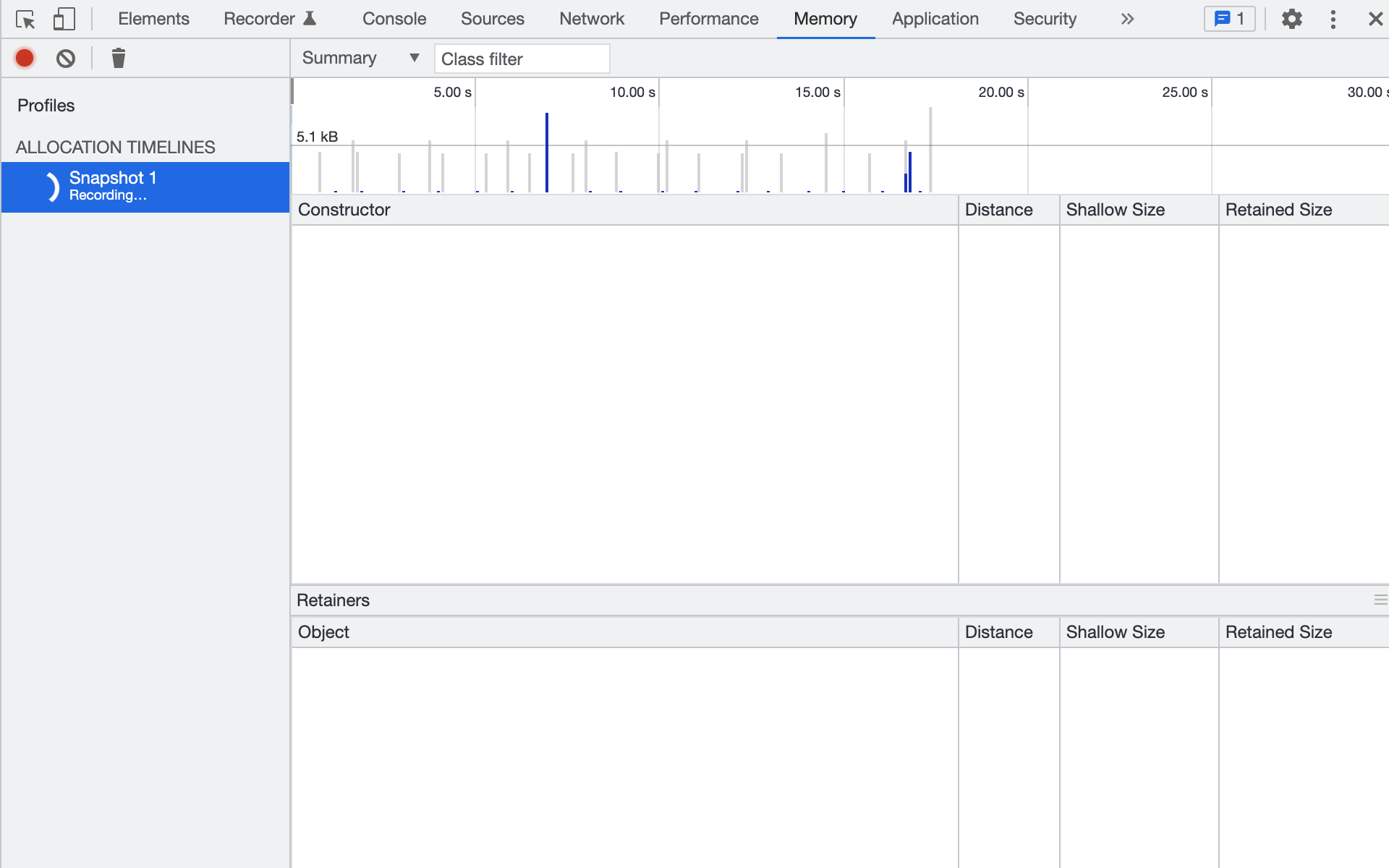
- Останавливаем запись круглой красной кнопкой в верхнем левом углу.
-
После этого курсором выделяем интересующий нас отрезок времени — DevTools покажет, какие объекты из этого отрезка до сих пор живы. Объекты группируются по типам (конструкторам).
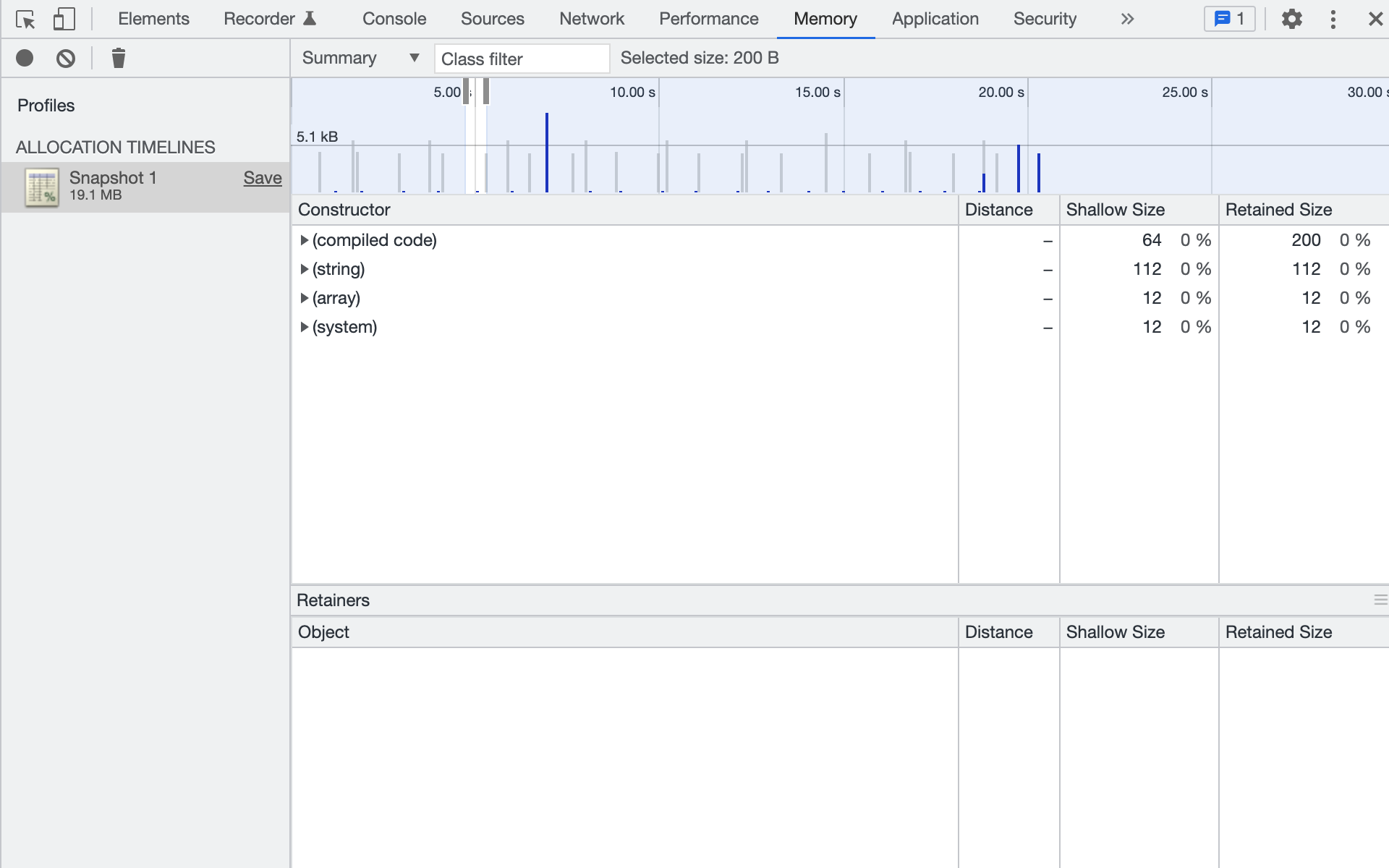
Почти все названия в круглых скобках — (compiled code), (array), (system), как на скриншоте — можно игнорировать. Это внутренние типы движка V8, наших утечек там нет. Исключений, пожалуй, всего два:
-
(string)— примитивный тип строки. Если строки за время записи заняли очень большой объём памяти (колонки Shallow Size и Retained Size), то их нужно проанализировать. -
(closure)— замыкание. Возникает, когда создаётся новая функция. Они обычно занимают мало памяти, но если создаётся много замыканий с одной и той же функцией внутри, то их тоже нужно проанализировать.
Дальше анализируем объекты в памяти, ищем те, которых там быть не должно. Это сложный процесс, который сам по себе достоин отдельной статьи, поэтому здесь я углубляться не буду. Некоторые интересные детали можно узнать из видео:
Полезно потренироваться в использовании Memory allocation timeline на простых примерах с утечками и без них — к этому вопросу я вернусь дальше в статье.
2. Поиск утечек с помощью техники трёх снапшотов
Инструменты Chrome DevTools, кроме непрерывной записи аллокаций, умеют делать одиночные снимки состояния памяти (heap snapshot, далее — просто снапшоты) и сравнивать их между собой.
Memory Allocation Timeline, как я уже упоминал, может записать только несколько минут работы с вашим кодом, а снапшоты памяти можно делать хоть с интервалом в час. Поэтому техника трёх снапшотов незаменима при поиске редко возникающих и сложно воспроизводимых утечек, которые нельзя получить за одну-две минуты.
Кроме того, техника особенно хорошо работает со страницами и приложениями, в которых пользователь после каких-то действий регулярно возвращается к исходному состоянию (на странице Facebook — к фиду новостей, в Gmail — к списку писем и так далее).
Итак, пошаговая инструкция:
- Прогреваем страницу. Выполняем несколько раз действия, которые, по нашему подозрению, приводят к утечке. Прогрев должен загрузить динамические импорты, выполнить memo и lazy, создать долгосрочные объекты, чтобы в дальнейшем это не мешало анализу.
-
Делаем первый снапшот памяти.
- Совершаем действия, которые, по нашему подозрению, приводят к утечке (например, открываем попап), потом возвращаемся к исходному состоянию из пункта 1 (закрываем попап). Можно проделать это не единожды, а круглое число раз, например, десять.
- Делаем второй снапшот.
- Повторяем действия из пункта 3 (открываем-закрываем попап). Здесь число повторений уже не играет роли, достаточно одного-двух раз.
- Делаем третий снапшот.
-
Показываем в третьем снапшоте только те объекты, которые были созданы между первым и вторым снапшотом (Objects allocated between Snapshot 1 and Snapshot 2). Это очень важный момент, в котором часто ошибаются, поэтому повторю ещё раз: в третьем снапшоте смотрим только объекты, созданные между первым и вторым снапшотами.
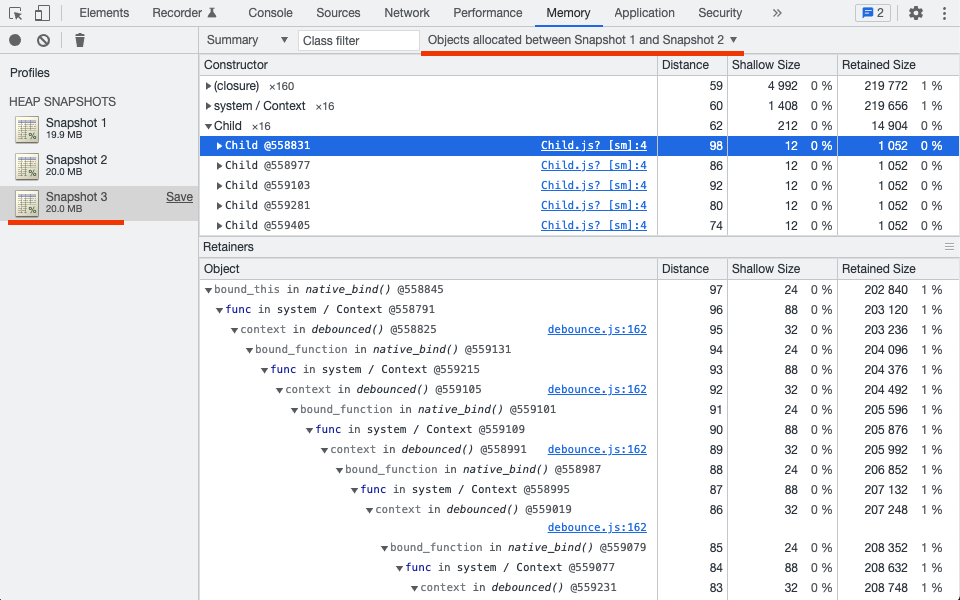
Таким образом мы значительно уменьшаем количество объектов для проверки на утечку. Исключаются:
- объекты, созданные до первого снапшота (долгоживущие, постоянно нужные),
- объекты, созданные после второго снапшота (живые в момент снятия третьего снапшота),
- большинство объектов, созданных между первым и вторым снапшотами — в пункте 5 инструкции все они были заменены более актуальными, даже если в коде есть мемоизация.
Ключевая идея техники трёх снапшотов: при отсутствии утечки все объекты, созданные между первым и вторым снапшотами (в пункте 3), должны освободиться в пункте 5 и исчезнуть из третьего снапшота.
При анализе обращаем внимание на количество объектов, равное или кратное количеству повторений в пункте 3 (количество объектов видно в колонке Constructor). Посмотрим на примере из скриншота: если мы проделали действие c утечкой 16 раз и видим «Child x16», «system / Context x16», «(closure) x160» — можем предположить, что на каждое наше действие создаётся и остаётся в памяти по одному экземпляру класса Child и по 10 замыканий (closure).
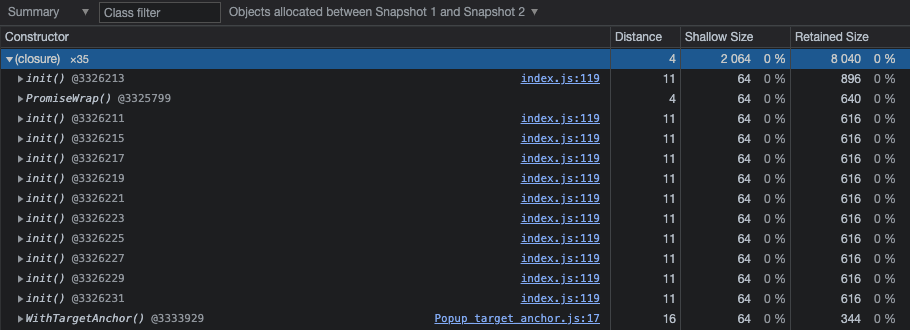
Названия в круглых скобках вроде (compiled code) (я уже упоминал про них выше по тексту) игнорируем, кроме (string) и (closure). В (closure) смотрим, для каких именно функций создаются замыкания: если там повторяется одна и та же функция, то в этом месте может быть утечка. Пример: на скриншоте ниже между первым и вторым снапшотами создано и осталось в памяти 11 замыканий для одной и той же функции init(), расположенной в 119-й строке файла index.js. Это очень похоже на утечку. В этом примере дальнейшим шагом будет определение, кто создаёт эти замыкания и как они удерживаются в памяти.
3. Поиск утечек с помощью queryObjects
Я уже упоминал, что в Chrome DevTools есть команда queryObjects(), которая возвращает количество живых объектов заданного класса (с заданным конструктором).
Этой командой можно проверить, накапливаются ли в памяти объекты, и уточнить, какие именно:
> queryObjects(Object)
Array(54700)
> queryObjects(Object)
Array(54892)
> queryObjects(Object)
Array(55080) // количество всех объектов в памяти растёт
> queryObjects(Function)
Array(34232)
> queryObjects(Function)
Array(34302)
> queryObjects(Function)
Array(34347) // количество функций растёт
> queryObjects(HTMLElement)
Array(79)
> queryObjects(HTMLElement)
Array(79)
> queryObjects(HTMLElement)
Array(79) // количество DOM-элементов не меняетсяЭто скорее вспомогательный приём. Он работает только из DevTools (и из инструментов, которые умеют в Chrome DevTools Protocol), требует явного указания класса объектов (соответствующий класс должен быть в глобальной области видимости) — зато позволяет быстро проверить конкретные сценарии утечек (накапливаются ли в памяти функции или ссылки на detached DOM-элементы) и тут же проинспектировать соответствующие объекты.
Тренируемся находить утечки
На чём тренироваться:
- Вот песочница, в которой есть утечка. Ответ можно подсмотреть на гитхабе в этом комментарии.
- В этой статье есть примеры кода для имитации утечки в браузере. Можно вставлять их на простейшую страницу, открывать в Chrome и тренироваться.
- В этой и этой статьях вы найдёте примеры кода с утечкой для Node.js.
Дальше можно объединиться с коллегой по проекту: он добавляет утечку в вашу ветку кода в репозитории, вы — в его ветку, и каждый ищет утечку у себя в ветке, не заглядывая в коммиты.
Также полезно поисследовать код без утечек, чтобы понимать, как в Chrome DevTools выглядит «здоровое» приложение.
Ещё раз приведу ссылки на статью и видео от разработчиков Google про утечки в Gmail — там хорошо и понятно рассказано о мониторинге памяти, поиске и устранении утечек. Могут оказаться полезными старые, но всё ещё годные статьи: эта и эта. Перевод хорошей статьи про soft-утечки есть на Хабре.
Hard-утечки
Ещё раз повторю главное отличие hard-утечек от soft-утечек: чтобы освободить утёкшую память, надо перезапустить приложение (браузер или Node.js) или даже перезагрузить операционную систему.
Пример из продакшена
У меня есть только один довольно старый пример, который заодно проливает свет на такую же старую загадку, когда-то мучившую верстальщиков.
Много лет назад был такой браузер: Internet Explorer 7. Одна из проблем IE7 была связана с масштабированием (интерполяцией) больших изображений — при уменьшении картинка очень сильно портилась визуально. Особенно это касалось чертежей и рисунков, в которых всегда много тонких чётких линий.
В принципе это было исправимо. В CSS браузера было проприетарное свойство -ms-interpolation-mode, управляющее режимом интерполяции. Оно имело два значения: bicubic (бикубическая интерполяция изображения) и nearest-neighbor (интерполяция по соседним пикселям), и значением по умолчанию служило именно nearest-neighbor. Достаточно было дописать в CSS:
img {
-ms-interpolation-mode: bicubic;
}И уменьшенные картинки начинали выглядеть намного лучше без заметного влияния на быстродействие.
Единственный вопрос, который возникал у многих в то время: ну почему разработчики IE7, реализовав качественный и достаточно быстрый алгоритм масштабирования, не включили его по умолчанию?!

На возможный ответ натолкнулись мои коллеги, когда разрабатывали просмотрщик отсканированных документов для одного крупного заказчика, у которого были в основном компьютеры с IE7. Они, конечно же, натолкнулись на очень некрасивое масштабирование отсканированных чертежей и схем формата A0, быстро нашли, что проблему можно исправить с помощью вышеуказанного фрагмента CSS, потроллили разработчиков IE7, которые не включили -ms-interpolation-mode: bicubic по умолчанию, зарелизили новую версию просмотрщика...
… и начали получать багрепорты от заказчика: браузер тормозит, компьютеры к концу дня становятся колом, работать невозможно и так далее. Перезагрузка Windows помогала, но постепенно всё опять начинало тормозить. Когда коллегам удалось воспроизвести проблему на машине у себя в офисе и увидеть в диспетчере задач, что у IE7 при листании документов в просмотрщике растёт потребление памяти, — стало понятно, что дело в утечке. При этом обновление страницы как раз не помогало — память освобождалась только при закрытии всего браузера целиком (возможно, достаточно было закрыть вкладку с просмотрщиком — это было давно, я уже не помню). Перебрав все попавшие в релиз изменения, они обнаружили, что при удалении из CSS правила про -ms-interpolation-mode или при замене на -ms-interpolation-mode: nearest-neighbor утечка пропадает.
Только тогда стало понятно, почему разработчики браузера реализовали бикубическую интерполяцию, но не включили её в IE7 по умолчанию. Скорее всего, они не успели к релизу починить утечку и просто отключили приводящее к утечке поведение.
Как бороться
К сожалению, здесь мало что можно сделать:
- Самое главное — понять, что проблема с памятью именно в hard-утечке.
- Определить, где именно она происходит (в расширении браузера, в самом браузере, в ОС, где-то ещё) и какие конкретно версии софта подвержены утечке. Сообщить о проблеме разработчикам софта.
- Если можем контролировать версии софта и есть не подверженные утечке версии — обновиться/откатиться на версию без утечки.
- На сервере, если не можем сменить версию софта или ждём исправленной версии, временно помогут запланированные рестарты в наименее загруженное время суток.
- Сложнее всего разобраться с утечками в ОС клиента, в браузере или в браузерном расширении — фронтенд не управляет версиями браузера и операционной системы. Можно разве что показать пользователю сообщение, что в его версии браузера/ОС есть утечка памяти, и предложить сменить их на аналоги.
Нестандартные оптимизации памяти в Node.js
Вот я и добрался до самого нетривиального. Нестандартные оптимизации могут пригодиться в ситуации, когда остальные возможности исчерпаны, но на серверах с Node.js надо освободить ещё немного памяти.
Node.js выделяет память на довольно неожиданные вещи, которые либо вообще не нужны, либо легко оптимизируются. Дальше я расскажу об оптимизациях, которые обнаружил сам.
Исходный код
Когда Node.js выполняет загрузку модуля через require или import, исходный код этого модуля в виде строки читается в память и остаётся там до самого конца.
В одном большом проекте мы собрали весь серверный код в три бандла:
- сам код проекта,
- наши библиотеки,
- стандартные сторонние библиотеки (Lodash и так далее).
После этого легко увидеть, что строки с исходным кодом занимают около 28 МБ памяти:

То есть комментарии, отступы, обёртки function (exports, require, module, __filename, __dirname) вокруг CommonJS-модулей — всё это занимает память сервера. А исходный код в процессе работы практически никогда и никому не нужен.
Мы провели минимальную минификацию — убрали только отступы и комментарии, не трогая переводы строк, имена методов и переменных, чтобы стектрейсы ошибок остались понятными и полезными. Основной бандл «похудел» с 23 до 15 МБ.
Пул-реквест с таким минифицированным серверным кодом показал заметное уменьшение потребления памяти:

Module._pathCache
Node.js при загрузке модулей строит полный (абсолютный) путь к файлу из относительного, который указывается в require() и import. Построение полного пути — довольно медленный процесс, а одни и те же модули могут грузиться много раз из разных мест в коде. Для ускорения пути запоминаются в кэше с логичным названием Module._pathCache.
Код кэширования:
Пути на сервере могут быть очень длинными, а модулей может быть очень много, поэтому кэш порой разрастается до десятков мегабайт:

После старта и прогрева сервера, когда все модули уже загружены в память, этот кэш становится бесполезен. Его можно очистить следующим кодом:
Object.keys(Module._pathCache)
.forEach(key => delete Module._pathCache[key]);Это безопасно — при отсутствии пути в кэше получим только замедление, если понадобится загрузить какой-нибудь модуль ещё раз.
Несколько версий пакета в node_modules
Если в node_modules оказывается несколько версий пакета (например, lodash@4.17.21 и lodash@4.17.15 одновременно, или вообще пять разных версий Moment.js с его гигантскими наборами данных для локалей и таймзон), то для каждой версии будет тратиться память на вышеперечисленные пункты. Устранение дублей поможет её сэкономить.
Чтобы найти дубли, я пользуюсь двумя инструментами:
- Стандартный npm find-dupes — самый распространённый, но менее полезный.
- Пакет dependencies-tree-builder.
Я использую dependencies-tree-builder в таком скрипте:
const chalk = require('chalk');
const buildTreeAsync = require('dependencies-tree-builder');
/**
* Максимально допустимое число разных версий пакетов, попадающих в сборку.
* Возможны разные валидные комбинации, например 12 версий одного пакета
* или 4 пакета, каждый трёх разных версий.
*
* @type {number}
*/
const MAX_COUNT_OF_DUPLICATED_PACKAGES = 12;
async function check({log}) {
const packageJson = require('./package.json');
let tree;
try {
tree = await buildTreeAsync(packageJson);
} catch (e) {
// При ошибке чистим кэш и пробуем снова
// Код в catch можно будет удалить после https://github.com/itwillwork/dependencies-tree-builder/pull/4
const fs = require('fs');
const path = require('path');
const CACHE_FILE = path.resolve(__dirname, './node_modules/dependencies-tree-builder/.packages.cache.json');
log(chalk.gray('Чистим кэш ' + CACHE_FILE));
fs.unlinkSync(CACHE_FILE);
const PackageCollector = require('dependencies-tree-builder/src/package_collector');
PackageCollector._cacheInstance = {};
// Пробуем снова
tree = await buildTreeAsync(packageJson);
}
const packages = Object.entries(tree.scoupe)
.filter(([, versions]) => Object.keys(versions).length > 1);
const countOfDuplicates = packages
.reduce((count, [, versions]) => count + Object.keys(versions).length, 0);
const pl = new Intl.PluralRules('ru');
const packagePlural = {one: 'пакет', few: 'пакета', many: 'пакетов'};
const versionPlural = {one: 'версия', few: 'версии', many: 'версий'};
if (countOfDuplicates <= MAX_COUNT_OF_DUPLICATED_PACKAGES) {
log(chalk.gray(
`В package.json есть ${packages.length} ${packagePlural[pl.select(packages.length)]} с несколькими версиями ` +
`(всего ${countOfDuplicates} ${versionPlural[pl.select(countOfDuplicates)]})`
));
return;
}
log(chalk.red.bold(
`В package.json есть ${packages.length} ${packagePlural[pl.select(packages.length)]} с несколькими версиями ` +
`(всего ${countOfDuplicates} ${versionPlural[pl.select(countOfDuplicates)]}):`
));
for (const [packageName, versions] of packages) {
log(chalk.blue(packageName) + ' ' + Object.keys(versions).join(', '));
Object.entries(versions).forEach(([version, {usages}]) => {
usages = usages.map(usage => (usage.length > 1) ? usage.slice(1).join('->') : usage[0]);
log(' ' + chalk.green(version) + ': ' + usages.join(', '));
});
}
}
check(console);Скрипт считает количество дублей и показывает, кто именно использует разные версии одного и того же пакета.
Найденные дубли можно убрать несколькими способами:
- Через npm dedupe.
- Вручную добавить в package.json пакет подходящей версии. Например, если у одного пакета указана точная версия транзитивной зависимости
"lodash": "4.17.15", а у другого указан диапазон версий"lodash": "^4.17.0", то мы можем заставить npm использовать и там и там одну версию, добавив явную зависимость"lodash": "4.17.15". - Через yarn resolutions.
- Через настройку
aliasв webpack.config.js, если код собирается через webpack.
require('./data.json')
В Node.js есть штатная возможность читать файлы JSON как CommonJS-модули через require():
const data = require('./data.json');Плюс такого подхода — простота и краткость. Но есть и два минуса:
- Node.js создаёт объект
Module, который занимает примерно в полтора раза больше памяти, чем исходный файл JSON. То есть для файлаdata.jsonразмером 10 МБ будет израсходовано около 15 МБ оперативной памяти. - Созданный модуль остаётся в кэше модулей на всё время работы Node.js, даже если данные больше не нужны.
Если на сервере надо читать большие JSON'ы (или много мелких), то можно уменьшить потребление памяти, переписав их загрузку:
// Плохо:
const data = require('./data.json');
// Лучше:
const data = JSON.parse(fs.readFileSync('./data.json', 'utf-8'));
// Для больших JSON'ов так ещё лучше:
const {parseChunked} = require('@discoveryjs/json-ext');
const data = await parseChunked(fs.createReadStream('data.json'));Заключение
Я бы хотел, чтобы эта статья помогла вам:
- писать хороший код,
- правильно работать с кэшами и мемоизацией,
- уверенно решать проблемы с лишним потреблением памяти и утечками,
- мониторить память сервера и клиентов в пул-реквесте, релизе, продакшене (раньше обнаружишь проблему — быстрее найдёшь причину),
- знать, что делать в крайних случаях, чтобы выиграть немного времени и памяти.
Комментарии (11)

Sergey_Kovalenko
02.06.2022 14:38Подскажите, как вы сделали ссылки внуть текта в вашем оглавлении. Я пишу цикл статей и преродически ссылаюсь из одной на какое-нибудь место повествования внутри другой. Было бы удобно не отпралять читателя ко всей статье целиком искать в ней нужный параграф, а передать ссылку непосредственно на сам параграф.

Leono
02.06.2022 15:13+2в том месте, на которое хочется сослаться, надо поставить якорь (на Хабре лучше отдельной строкой):
<anchor>1</anchor>Sergey_Kovalenko
02.06.2022 15:51Я так понимаю, что вместо "1" должен быть тест ссылки, который подсвечивается голубым? Надо поэкспериментировать, думаю дальше я смогу нагуглить, если что спрошу у вас через личные сообщения.
Большьшое спасибо!

speshuric
02.06.2022 16:32+3Монументально и гора ссылок на почитать.
Бросилось в глаза, насколько разное сейчас оборудование в эксплуатации. Есть и сервера с ТБ памяти, и ворстейшены с 64-256 ГБ, и десктопы с 16-128 ГБ , и ноутбуки 8-32 ГБ и телефонопланшеты с 2-8 ГБ - 3 порядка разницы - и V8/браузеру приходится работать на всём зоопарке: что для одного устройства копейки, то для другого всё устройство.
И еще ситуация с 32-битными ограничениями на размер непрерывного объекта в JS/Java/.Net начинает напоминать ограничения в 65536 байт в 1993-1994-1995 года: и памяти уже на порядки больше, но большинство сред исполнения не готовы работать с бОльшими массивами (хотя уже общая память давно больше).

Format-X22
02.06.2022 19:26Прям статья под мой сегодняшний день. Переписывал код с axios на встроенный в ноду https уменьшив потребление памяти вдвое. В моём случае с 4Гб до 2Гб. Да - мне приходит неприлично много данных. И похоже сверхпопулярный axios имеет дырку что удваивает потребляемую память.

SiSya
02.06.2022 21:37+2Можно конкретнее?
Format-X22
03.06.2022 13:00+2Да, можно было бы конкретнее.
Я написал большой-большой коммент, там было 3 примера кода, под спойлерами, аккуратненько. Там были выкладки с цифрами сколько чего, где и как, как код вел себя до загрузки данных, как было после, что было с памятью потом. И всё красиво и расчудесно. А потом я решил добавить последний код - и в этот момент редактор завис, вкладка померла.... и постирала всё, абсолютно всё что я писал, без возможности вернуть. Второй раз я это писать не буду, со всеми вопросами - к автору этого ущербного редактора комментов.

SiSya
Благодарю за статью. Полагаю, по большому счету, статья для разработчиков на ванильном js, т.к. у фреймворков под капотом крайне много своих особенностей и можно успеть уйти на пенсию, пока развернешь весь стректрейс.
Вообще, на сегодняшний день некоторую долю проблем с производительностью и памятью решает следование основным принципам верной работы с ссылочными типами и их замыканием. Про глобальные переменные и var я уже почти не слышу.
И то хорошо.
jehy
Да нет, те же принципы отлично работают и для большого энтерпрайз приложения на TS и каком-нибудь фреймворке. Лишняя ссылка, плохая мемоизация, неудачная версия зависимости - и потекли. И надо успеть отладить не до пенсии, а за день. Так что я прямо активно пользовался много чем из описанного автором, в том числе техникой трёх снепшотов, которая, к слову, работает и для серверной разработки.