
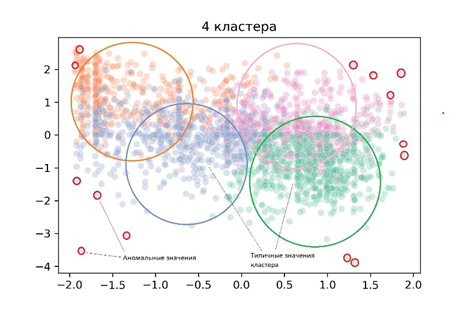
Поиск аномалий и выявление подозрительных операций широко применяется в клиентской аналитике, банковском аудите и других видах бизнес аналитики. Суть данной методики заключается в анализе больших объемов данных и выявлении поставщиков, клиентов, транзакций или иных активностей с крайне нетипичным поведением. Часто, такие аномалии являются индикатором мошенничества или поводом для более детального анализа подобных бизнес активностей.

Выявлять нетипичное поведение или аномальные значения признаков можно разными путями. При наличие данных за прошедшие периоды, размеченные как fraud/not fraud, можно использовать модели классификаторы для выявления подозрительных операций в настоящем. Я же рассмотрю случай, когда размеченных должным образом данных нет и анализ нужно проводить с чистого листа. Данная методика была применена для анализа поставщиков программного обеспечения и компьютерной техники на предмет выявления компаний с аномальным, не характерным для подобных контрагентов поведением.
Поведение разных поставщиков в некоторых случаях различается кардинально. Так, транзакции по таким поставщикам программного* обеспечения как Microsoft могут исчисляться в сотнях миллионов рублей, в то время как местный поставщик недорогой
компьютерной периферии может осуществлять небольшие поставки на незначительные
суммы. Поэтому, первым шагом анализа является группировка поставщиков со схожим
поведением в кластеры. Каждый кластер объединяет поставщиков с близкими
показателями по суммам поставок, частоте оплат, а также длительности отношений
с банком. Далее, я рассчитываю центроид каждого кластера и расстояние между
центром кластера и каждым конкретным значением признака или переменной в
кластере. Чем ближе значение признака находится к центру кластера, тем более
типичным это значение является для данного кластера и наоборот, значения,
максимально удаленные от центра, являются аномальными и могут расцениваться как
подозрительные. Затем, я устанавливаю пороговые значения рассчитанных
расстояний (97 процентилей), в пределах которых значения переменных являются
типичными или нормальными для поставщиков конкретного кластера. В заключении, я
помечаю значения переменных, которые превысили установленные пороговые значения
как аномальные (схема 1).
Кластеризация, выявление аномалий и разметка данных с использованием алгоритма K-means
Датасет содержит код поставщика и четыре признака, которые описывают каждого из них.
«Дней_с_последней_оплаты» - метрика, показывающая, когда последний раз была сделка с поставщиком;
«Частота» - метрика, показывающая количество сделок за рассматриваемый период;
«Сумма» - метрика, показывающая сумму всех сделок с поставщиком;
«Длительность_отношений_в_днях» - метрика, показывающая длительность отношений с поставщиком.
Первым шагом необходимо подготовить данные для модели. Для этого необходимо улучшить распределение данных (boxcox метод) и нормализовать их чтобы mean и std были одинаковыми для всех признаков (StandardScaler).
# преобразую переменные используя boxcox метод
def boxcox_df(x):
x_boxcox, _ = stats.boxcox(x)
return x_boxcox
rfm_data_boxcox = rfm_data.apply(boxcox_df, axis=0)
# нормализую данные используя StandardScaler()
scaler = StandardScaler()
scaler.fit(rfm_data_boxcox)
rfm_norm = scaler.transform(rfm_data_boxcox)
rfm_norm = pd.DataFrame(rfm_norm, index = rfm_data_boxcox.index, columns = rfm_data_boxcox.columns)Рассчитываю оптимальное количество кластеров используя Elbow criterion метод. Точка, в которой падение графика становится незначительным, показывает оптимальное количество кластеров.
# Рассчитываю оптимальное количество кластеров используя Elbow criterion метод
sse = {}
for k in range(1, 11):
kmeans=KMeans(n_clusters = k, random_state=42)
kmeans.fit(rfm_norm)
sse[k] = kmeans.inertia_
sns.pointplot(x = list(sse.keys()), y=list(sse.values()))
plt.show()Оптимальным количеством кластеров является 4. Далее, я строю модель с четырьмя кластерами и визуализирую кластеры используя heatmap и snake plot. Snake plot показывает различия между кластерами по признакам. Heatmap показывает средние значения признаков в каждом кластере, а также размер кластеров.
# строю модель с 4 кластерами
kmeans = KMeans(n_clusters=4, random_state=1)
kmeans.fit(rfm_norm)
# вывожу лейблы кластеров
cluster_labels_4 = kmeans.labels_
# добавляю колонку 'Кластеры' в датасет с оригинальными данными
rfm_data_k4 = rfm_data.assign(Кластер = cluster_labels_4)
# рассчитываю средние значения переменных и размер каждого кластера
rfm_data_k4_grouped = rfm_data_k4.groupby('Кластер').agg(
{'Дней_с_последней_оплаты':'mean', 'Частота':'mean',
'Сумма_общая_тыс_руб':'mean', 'Длительность_отношений_в_днях':['mean', 'count']})
# добавляю колонку 'Кластер'
rfm_norm_clusters = rfm_norm.assign(Кластер = cluster_labels_4)
Snake plot (справа) показывает, что наши четыре кластера различаются по всем четырем признакам и я могу интуитивно определить их экономический смысл и озаглавить. Так, кластер=0 показывает поставщиков, с которыми давно не было никаких отношений, а частота оплат и суммы контрактов по ним были не значительные. И наоборот, кластер=1 группирует действующих поставщиков с большими суммами и частотой оплат. Heatmap (слева) показывает средние значения признаков в каждом кластере в реальных единицах (рублях, днях, количествах поставок). Последний столбец демонстрирует количество поставщиков в каждом кластере. Оба графика говорят о том, что поставщики корректно разбиты на группы, которые значительно отличаются между собой.
Далее, я определяю аномальные значения переменных. Пороговое значение аномальных данных - 97 процентилей. Размечаю данные: 1-fraud, 0-not fraud:
# сохраняю центроид кластера
x_cluster_centers = kmeans.cluster_centers_
# рассчитываю расстояния от центра кластера до каждого значения переменных
dist = kmeans.transform(rfm_norm)
# помечаю аномальные значения как 1 и нормальные значения как 0 на основе рассчитанных расстояний
km_y_pred = np.array(dist)
km_y_pred[dist>=np.percentile(dist, 97)] = 1
km_y_pred[dist<np.percentile(dist, 97)] = 0
# создаю DF
fraud_data = pd.DataFrame(km_y_pred, index = rfm_norm.index, columns = rfm_norm.columns)
fraud_data = fraud_data.assign(Fraud_score = fraud_data.sum(axis=1))
# изолирую нормализованные данные с аномальными значениями
fraud_data_fraud = fraud_data[(fraud_data['Дней_с_последней_оплаты']==1)
|(fraud_data['Частота']==1)
|(fraud_data['Сумма_общая_тыс_руб']==1)
|(fraud_data['Длительность_отношений_в_днях']==1)]
rfm_norm_fraud = rfm_norm_clusters[rfm_norm_clusters.index.isin(fraud_data_fraud.index)]
rfm_norm_not_fraud = rfm_norm_clusters[~rfm_norm_clusters.index.isin(fraud_data_fraud.index)]
Рассчитываю количество поставщиков с аномальным поведением:
# рассчитываю количество поставщиков, по которым 2 и более аномальных значения данных
fraudulent = fraud_data_fraud[(fraud_data_fraud['Fraud_score']>=2)
&(fraud_data_fraud['Сумма_общая_тыс_руб']==1)]
print('Количество поставщиков с аномальным поведением (1 и более аномалий): ', len(fraud_data_fraud))
print('Количество поставщиков с аномальным поведением (2 и более аномалии): ', fraudulent.shape[0])
Количество поставщиков с аномальным поведением (1 и более аномалий): 263
Количество поставщиков с аномальным поведением (2 и более аномалии): 22Заключение
В статье рассмотрена методика выявления аномалий и разметки данных при анализе поставщиков программного обеспечения и компьютерной техники. Анализ выявил 263 компании с не типичным поведением. Данная методика не позволяет с уверенностью сказать, что все сделки по этим компаниям являются мошенническими. Я лишь могу утверждать, что эти компании имели аномальное, не типичное поведение по отношению к компаниям со схожими характеристиками. Поэтому, хорошей практикой является обсуждение и корректировка результатов исследования со специалистом по fraud анализу который обладает более глубокой экспертизой в данной области.
Также, выявлены 22 компании, по которым зафиксировано 2 и более аномалии. По этим контрагентам целесообразно провести более детальную проверку с анализом договоров и фактической деятельности.
Размеченные подобным образом данные можно использовать в построении моделей-классификаторов для выявления аномальных операций в текущей деятельности компании.
sunnybear
97 перцентиль откуда взялся? Это ведь самое тонкое место в аномалиях - определить границу, до которой все ещё нормально
NewTechAudit Автор
Статистический анализ данных на этапе формирования фичей, а также анализ полученных кластеров даст ответ на вопрос в каких интервалах находятся экстремальные значения признаков. Кроме того, общение со специалистом по fraud анализу может прояснить ситуацию
Ananiev_Genrih
Как-то опасно все это прибито гвоздями. Дрейф данных (data drift) и привет...
Так же вызывает недоумение использование kmeans для поиска аномалий - видимо индусы в своих многочисленных статьях формируют тренды)))
Автор видимо не в курсе - какие ограничения есть у kmeans и насколько сами аномалии аффектят на него в процессе его работы. Это как искать аномалии по 2-м/3-м сигмам в одномерном пространстве забыв как аффектят аномалии на саму среднеарифметическую в процессе расчета. Хотя бы предварительно ознакомились с более робастными алгоритмами, например.
Статью смело можно сжать в несколько строк production-ready кода более уместными алгоритмами (например этим) , вызвав его хоть из R хоть из питона.
NewTechAudit Автор
Kmeans вполне рабочий алгоритм для текущей аналитики, простой и понятный. У DBSCAN свои недостатки, например, computational cost