
Как Netflix добился 80 процентов от всего своего стримингового времени благодаря персонализации

Перевод не дословный. Некоторые куски я дополнила примерами и объяснениями, некоторые перенесла, некоторые удалила, так как они дублировали уже высказанные автором мысли. Оригинал статьи здесь.
Netflix Prize
В 2000 году Netflix представил персонализированные рекомендации фильмов, а в 2006 году запустил Netflix Prize - соревнование по машинному обучению с призовым фондом в 1 миллион долларов. Netflix Prize был открытым соревнованием на лучший алгоритм коллаборативной фильтрации для прогнозирования пользовательских оценок фильмов на основе предыдущих оценок других пользователей. Никакой информации о юзерах или фильмах не было, только айдишники. В то время Netflix использовал Cinematch, свою собственную рек. систему, основанную на линейной регрессии, которая имела среднеквадратичную ошибку (RMSE)=0,9525. В соревновании перед участниками ставилась задача уменьшить этот показатель на 10%. Команда, которая смогла б достичь цели или максимально приблизится к ней через год, получила бы призовой фонд.
Лауреат Progress Prize (международная награда, посвященная следующему поколению новаторов, ежегодно вручаемая одному участнику Global Grad Show) годом позже, в 2007 году, использовал линейную комбинацию матричной факторизации (SVD) и ограниченных машин Больцмана (RBM), достигнув RMSE 0,88. Netflix включил эти алгоритмы в продакшн после некоторой адаптации к исходному коду. Интересно то, что несмотря на то, что некоторые команды достигли RMSE 0,8567 в 2009 году, компания не запустила эти алгоритмы в продакшн из инженерных соображений - слишком много усилий понадобилось бы для незначительного увеличения точности предсказаний. Этот момент применим для всех рекомендательных систем - всегда существует прямая корреляция между сложностью моделей и количеством инженерных усилий по её развёртыванию в проде.
Пару слов о матричной факторизации
Имеем матрицу взаимодействия юзеров с айтемами: каждая строка - юзер, каждый стобец-айтем, на пересечении - результат взаимодействия, в нашем случае пускай это оценки за фильм. Эту матрицу мы раскладываем на матрицу латентных фичей пользователей, где каждая строка - вектор, описывающий юзере и на матрица латентных фичей айтемов, где каждый столбец - вектор, описывающий айтем - это и есть матричная факторизация

Пару слов об ограниченных машинах Больцмана
Restricted Boltzmann machine - вероятностная графовая модель обучения без учителя. Restricted - потому что сеть не полносвязная (вершины графа, находящиеся в одном слое. не соеденены друг с другом), как в обычной машине Больцмана. Веса здесь - вероятности. Скрытый слой представляет латентные фичи данных, проявляющиеся в процессе обучения. Для Нетфлика - видимый слой: видео, которые человек посмотрел. В скрытом слое может крыться, например, описание содержания видео.

Cтриминг - новый способ потребления
*Стриминг — подгрузка данных, которые «скоро потребуются» прямо по ходу процесса показа фильма.
Ещё более важная причина, по которой Нетфликс не внедрил победившие в соревновании модели в том, что был представлен стриминг в 2007. В стриминге объём передаваемых данных резко возрос, поэтому нужно было изменить способ, которым система обрабатывала данные и генерировала рекомендации, алгоритмы должны были стать более быстрыми и легковесными.

Перенесемся в 2020 год: Netflix превратился из мейл-сервиса, распространяющего DVD-диски в США, в глобальный стриминговый сервис с 182,8 миллионами подписчиков. Если раньше задача рекомендации была задачей регрессии - предсказать рейтинг фильма для пользователя / кластера пользователей, то сейчас она превратилась в целое множеств задач - задача ранжирования, задача генерации страниц, задача максимизации времени стрима для конкретного пользователя (то есть заставить пользователя провести за просмотром сериальчиков как можно больше времени). Так какие алгоритмы использует Нетфликс? На этот вопрос мы постараемся ответить в статье.
Нетфликс как бизнес
Бизнес-модель Нетфликса - подписка. Проще говоря, чем больше подписчиков / пользователей у Netflix, тем выше его доход. Доход можно рассматривать как функцию трех переменных:
Коэффициент привлечения новых пользователей
Количество отказов от подписки
Скорость, с которой возвращаются старые подписчики (каждый месяц? каждые полгода?)
Насколько важна рекомендательная система для Нетфликса?
80% стримингового времени достигается с помощью рекомендательной системы Netflix. Более того, Netflix постулирует улучшение пользовательского опыта, направленного на удержание клиентов, что, в свою очередь, приводит к экономии на привлечении новых клиентов (по оценкам, 1 млрд долларов на 2016 год).
Рекомендательная система Нетфликса
Как Netflix ранжирует айтемы?
Netflix использует двухуровневую row-based систему ранжирования. Что это значит? Контент ранжируется аж дважды:
В каждом ряду (самые подходящие рекомендации слева)
-
По столбцам вниз (самые подходящие рекомендации сверху)

Каждый ряд собран на основе определенной тематики (например, топ-10 комедий, тренды, ужасы и т.д.) Ряды обычно генерируется одним алгоритмом. Домашняя страница каждого юзера состоит примерно из 40 рядов, в каждом до 75 айтемов, в зависимости от устройства, которое использует пользователь.
Почему ряды?
Так удобнее собирать фидбек - человек листает вниз, пропускает ряд, значит ему не слишком интересны, например, комедии и тренды, человек задерживается - значит заинтересовался, а если листает вправо - то есть двигается по тематике - значит мы его очень заинтересовали.
Какие алгоритмы используются?
Netflix использует различные инструменты ранжирования, тонкости архитектур мы здесь уточнять не будем. Краткое описание этих алгоритмов рассмотрим дальше.
Personalised Video Ranking (PVR) — это алгоритм общего назначения, который обычно создаёт жанровые ряды, выбирая из всего каталога именно то, что идеально подойдёт для пользователя. Он учитывает признаки типа пользовательских фич (пол, возраст, любимые жанры и т.д.) и общую популярность айтема на сайте.

Top-N Video Ranker — Похож на PVR, за исключением того, что он смотрит только на начало рейтингов. Из самых популярных фильмов он выбирает наиболее интересные для пользователя. Он оптимизирован с помощью метрик, которые смотрят на начало рейтингов (например, MAP@K, NDCG).

Trending Now Ranker — этот алгоритм фиксирует временные тренды. “Длительность” тренда варьируется от нескольких минут до нескольких дней. Среди этих трендов выделяют:
События, которые имеют сезонную тенденцию, то есть повторяются (например, День Святого Валентина приводит к росту просмотра романтических фильмов)
-
Разовые события (например, коронавирус или другие катастрофы, вызывающие кратковременную вспышку интереса к документальным фильмам о них)

Пример ряда, сгенерированного Trending Now Ranker
Continue Watching Ranker — Этот алгоритм смотрит на айтемы, которые юзер начал смотреть, но так и не закончил:
Многосерийный контент (например, драматический сериал)
-
Немногосерийный контент, который можно потреблять небольшими порциями (например, фильмы, которые наполовину завершены, сериалы, не зависящие от серии, такие как "Черное зеркало")

Пример ряда, сгенерированного Continue Watching Ranker
Алгоритм вычисляет вероятность того, что юзер продолжит просмотр, используя контекстно-зависимые сигналы (например, время, прошедшее с момента просмотра, момент, на котором пользователь остановился, устройство, на котором пользователь смотрел контент, и т.д.).
Набор просмотренных юзером единиц контента можно рассматривать как последовательностей, чувствительных ко времени. Сегодня я днём я посмотрела первый сезон "Во все тяжкие", вечером -второй, на следующий день начала смотреть курс Стэнфордского универстета по органической химии. Мои просмотры идут последовательно, они - цепочка взаимосвязанных событий. В презентации Джастина Базилико рассказывалось об использовании сети RNN в предсказании последовательностей, чувствительных ко времени, и я предполагаю, что Continue Watching Ranker эту сеть и использует.
Джастин предположил, что Netflix может использовать прошлые сессии конкретного юзера наряду с контекстуальной информацией текущей, чтобы предсказать, какой может быть следующая сессия юзера. Например, в качестве фич можно подавать время и дискретные контекстуальные сигналы и это максимизирует эффективность алгоритма.

Video-Video Similarity Ranker -он же “Потому что ты посмотрел вот это” (because you watched)
Этот content-based алгоритм. Мы берём айтем, который посмотрел пользователь и вычисляем похожие айтемы с помощью матрицы сходства между элементами и возвращаем наиболее похожие айтемы. В отличие от других алгоритмов, этот не является персонализированным, поскольку никакие другие личные фичи не используются. Персонализация применяется дальше - в том, как именно мы отобразим похожие айтемы на страничке с рекомендациями (об этом далее).
Пару слов о content-based подходе
Content-based подход - обучение классификатора определять, что нравится тому или иному пользователю, на основе фич айтемов, с которыми он взаимодейтствовал (фильмов, которые он посмотрел). Например, обучении подаются признаки фильмов, на выходе получаем вектор фильма, который этот конкретный пользователь мог бы посмотреть следующим.

Процесс генерации рядов
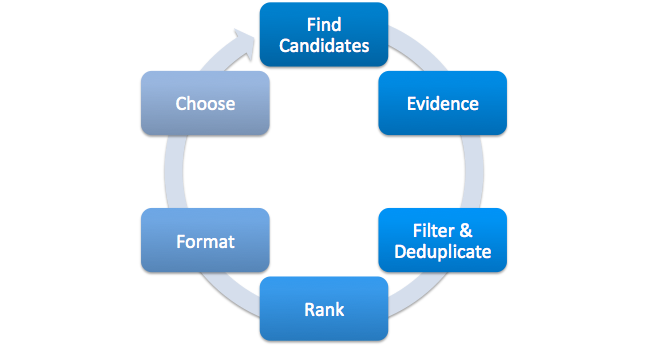
Каждый из вышеперечисленных алгоритмов проходит через процесс генерации строк, показанный на изображении ниже. Например, если PVR видит, что пользователь поставил “Дневнику памяти” 10 звёзд , он найдёт ещё романтические фильмы, которые могут пользователю понравится и в то же время соберёт обоснования - почему именно такой ряд был сгенерирован (Вы недавно посмотрели “дневник памяти”, в данном случае). Насколько я понимаю, алгоритм сбора обоснований включен во все алгоритмы ранжирования, упомянутые выше, для более тщательного ранжирования элементов списка (см. Ниже изображение рабочего процесса модели Netflix).
Найти айтемы-кандидаты
Найти обоснования
Отфильтровать и удалить дубликаты - например, не будем рекомендовать фильмы 18+ детскому аккаунту.
Отранжировать
Выбрать
Алгоритм cбора обоснований использует всю информацию, которую Netflix показывает в верхнем левом углу страницы, включая предсказанный рейтинг, который был таргетом соревнования Netflix. Также алгоритм смотрит на метаданные, такие как описание фильма, награды или актёрский состав, даже картинки с постеров Нетфликс использует для усиления рекомендаций.
(с) из статьи The Netflix Recommender System: Algorithms, Business Value, and Innovation

Каждый из пяти алгоритмов проходит через один и тот же процесс генерации рядов.
Генерация страниц

После того, как алгоритмы генерируют ряды-кандидаты, внутри каждого из которых ранжирование уже произведено, нужно решить, какую из этих 10 000 строк отображать.
Исторически сложилось так, что Netflix использует подход, основанный на решающих правилах, в котором ряды конкурируют за экранное пространство. Задача отображения рядов направлена не только на точность рекомендаций, но и на их
разнообразие. Например, любителю романтических фильмов можно порекомендовать такой набор рядов - “Лучшие ромкомы этого лета”, “Фильмы о любви, которые смотрели ваши родители”, “Пары, которые сохранили свою любовь несмотря ни на что”. Точность этих рекомендаций будет довольно высока, но они не разнообразны. Даже самому заядлому любителю фильмов о любви такие подборки быстро наскучат, поэтому в рекомендации нужно добавлять что-то ещё - что-то, что может быть более рискованным выбором, но всё ещё может понравится пользователю. Такой подход реализовывают в себе в частности алгоритмы “одноруких бандитов”.
стабильность. Не должно быть такого, что для одного и того же пользователя мы сегодня рекомендуем боевивики и ужасы, а завтра - подростковые сериалы (даже если он действительно любит и то и другое). Или же нелогично рекомендовать пользователям, история просмотров которых различается всего на 1 фильм из 100, совершенно разные фильмы. Рекомендации не должны шарахаться из стороны в сторону. Также стабильность необходима, если, например, пользователи некоторое время взаимодействовали с Netflix, привыкли определенным образом перемещаться по странице - например, обычно мы показываем сверху пользователю исторические драмы, а комедии в самом низу. Если в поведении пользователя ничего резко не изменилось, нет причин внезапно менять ранжирование рядов.
Аппаратные возможности — какое устройство используется для просмотра. Какие строки / столбцы видны с первого взгляда, а какие — при прокрутке.
Мы хотим предсказать, что пользователи хотят сейчас посмотреть, при этим учитывая, что они могут хотеть продолжить просмотр недосмотренного контента. Ещё мы хотим подчеркнуть объём своего каталога, показав что-то свеженькое. Хотим попытаться уловить тренды происходящие в регионе участника.
Как бэйзлайн подход, основанный на решающих и правилах может работать довольно хорошо, потому что можно просто собрать несколько наборов критериев, обязательных для выполнения и прогонять рекомендации через них. С другой стороны большое количество таких правил естественным образом привело Netflix к локальному оптимуму с точки зрения обеспечения качественного взаимодействия с пользователями.
Так что же с проблемой ранжирования рядов?
Row-based подход использует уже существующие рекомендации и применяет к ним learning-to-rank подход → ставит оценки рядам и ранжирует их на основе этих оценок. Этот подход может быть относительно быстрым, но ему не хватает разнообразия. Пользователь может увидеть страницу, полную строк, которая в целом соответствует его интересам, но по ряда может быть очень похожей (вспоминаем любителя романтики). Как же нам тогда подключить разнообразие?
Stage-wise подход так же считает скор для ряда, но теперь это делается не для всех рядов одновременно, а последовательно друг за другом. Если ряд выбирается в подборку, то скор для всех следующих рядов пересчитывается — например, если мы уже выбрали ряд, содержащий хорроры, скор всех других рядов, близких к хоррорам, уменьшится. Это жадный алгоритм.
Мы могли бы улучшить его, если бы при расчёта скора для ряда мы бы учитывали k ближайших рядов. Однако ни один из этих подходов не приведет к достижению глобального оптимума.
ML подход, который использует Netflix, пытается создать функцию подсчета рейтинга путем обучения модели — используя историческую информацию о том, какие страницы уже генерировались для пользователей и учитывая то, что с этих страниц пользователи действительно видели, как они с отображаемым контентом взаимодействовали и что они смотрели.
Конечно, существует множество других фич, которые можно использовать для ранжирования, и способов, которыми можно отображать ряды. Можно просто аггрегировать все метаданные контента в эмбеддинг, например. Независимо от того, какие фичи используются для генерации страницы, основная цель - создать гипотетические страницы и посмотреть, с какими элементами пользователь взаимодействовал бы. Затем мы оцениваем сгенерированные страницы с использованием метрик, таких как Precision@m-by-n и Recall@m-by-n (они являются адаптицией метрик Precision@k и Recall@k только работают в двумерном пространстве - не вектор, а матрица, не просто ряд, а вертикаль и горизонталь.).

Холодный запуск, деплой и Большие данные
Проблема холодного старта
Старая как мир проблема холодного старта не обходит Netflix стороной. Исторически Нетфликс справляется с ней так - нового пользователя просят заполнить небольший опросник, чтоб запустить персональные рекомендации. Если пропустить этот шаг, алгоритм рекомендаций будет показывать различные популярные айтемы.
Кроме того, во время периода Covid-19, был создан Netflix Party — расширение Chrome для совместного просмотра фильмов на разных устройствах. На мой взгляд, это оказывает огромное влияние на решение проблемы холодного старта, так как вероятнее всего данные, которые необходимы этому расширению для работы, отправляется на обработку в Нетфликс.

То есть Netflix раньше работал на вас, как на одного юзера — по крайней мере собирать информацию он мог только об одном юзере. Я могу смотреть сериал дома с компаний друзей, но Нетфликс об этом понятия не имел. С помощью Netflix Party Netflix можно создать граф того, с кем вы взаимодействовали, и потенциально выполнить коллаборативную фильтрацию, чтобы предоставлять более точные рекомендации новым пользователям. Например, у меня есть друг Марк, у которого нет аккаунта на Нетфликсе. У меня аккаунт есть. Я использовала Netflix Party, чтоб посмотреть с Марком пару боевиков на выходных. Марк решил зарегестрироваться на Нетфликсе. Алгоритм видит, что юзер, который регестрируется под почтой mark@gmail.com уже смотрел со мной, зарегестрированным юзером Нетфликс, два боевика. Это не только значит то, что Марк потенциально любит боевики, но и то, что мы с ним - друзья, а значит вероятно любим похожие кино. И вот уже Марку можно рекомендовать персонализированно, хотя он только что зарегестрировался.
A/B тесты
Известно, что когда мы оцениваем модель рекомендаций вне прода - оффлайн, и когда мы собираем реальные показатели модели, работающей в проде - можно натолькнуться на ощутимую разницу. Конечно, офлайн оценка помогает нам понять, работает ли модель, но нет никакой гарантии, что она приведёт к фактическому улучшению пользовательского опыта (например, общее время просмотра). Таким образом, команда Netflix внедрила невероятный и эффективный процесс A / B-тестирования, чтобы быстро тестировать новые алгоритмы.
A / B-тестирование само по себе является искусством, поскольку необходимо учитывать множество переменных — как выбрать контрольную и тестовую группу, как определить, является ли A / B-тест статистически значимым, опеределить размер групп, какие метрики использовать при A /B-тестировании и многое другое.
По сути, офлайн валидация помогает Нетфликсу решить какие модели можно запускать в A/B тесты. Вы можете прочитать больше об экспериментах Netflix по A / B тестированию здесь.
Дальше можно поговорить об архитектуре рекомендательной системы Нетфликс, совмещающей офлайн, онлайн и ниарлайн вычисления. Статью об этом я уже переводила для Хабра.

Заключение
Нетфликс не зря самый крупный стриминговый сервис в мире. Рекомендательная система Нетфлика учитывает огромное количество факторов и использует множество алгоритмов для генерации рекомендаций. Такая система требует усилия большого количества инженеров, однако в целом простая рекомендательная система может включать в себя всего один алгоритм, и всё ещё быть неплохой. Нетфликс показывает дата-саинтистом, как может быть, а мы в свою очередь можем ориентироваться на его подходы, чтоб строить рекомендательные системы под свои задачи.
slavanikolsky
Netflix ещё может простить подписку оплаченную до конца года.
https://habr.com/ru/news/t/660667/
Matshishkapeu
Они ещё выдают штраф в несколько баксов за каждый логин не из своего дома. Начали проверять эту фичу на самых зажратых и богатых юзерах - в Чили и Перу.
Aleksandr-JS-Developer
Дизлайк отписка