

Всем привет. Я Игорь, тимлид в команде, которая занимается системой лояльности в CSI. Расскажу, как работают и устроены системы лояльности в ритейле, о том, как мы создали новую архитектуру системы Set Loyalty, что применяем из фреймворков и инструментов.
Мало кто представляет, что такое современные системы лояльности в крупном федеральном ритейле. Это десятки миллионов анкет, миллиарды чековых транзакций в год, сотни RPS (request per second) из разных каналов покупки — от кассы до мобильного приложения с требованием отклика до секунды. И все это с деплоем на серверах заказчика и необходимостью максимальной доступности, так как любой сбой приводит к очень большим убыткам.
Из чего состоит система лояльности в ритейле
Наша компания занимается разработкой фронт-офисных систем для ритейла. Именно с работой нашего софта сталкивается покупатель в магазине: иногда лично, а иногда через кассира. Направление, в котором работаю я, занимается разработкой того, что принято называть «системой лояльности покупателей» — это скидки, купоны, персональные предложения, бонусы и все то, что мотивирует покупателя возвращаться, быть лояльным определенной торговой сети. Система лояльности сейчас есть почти в каждом магазине, за исключением дискаунтеров или совсем небольших несетевых магазинов. Там она тоже есть, но другого уровня.

Специальная тетрадь, куда вносят лояльных покупателей :)
Система лояльности покупателей – это специализированная ИТ-система, готовый набор инструментов и механик, платформа для построения и запуска ритейлером программы лояльности в своих магазинах. Отдельные модули (процессинги) лояльности отвечают за работу с конкретными блоками данных. Сегодня практически у любого сетевого ритейлера в арсенале (в разных системах модули называются по-разному, здесь я в качестве примера привожу названия из нашей экосистемы):
Физические/электронные карты постоянного покупателя и анкеты клиентов сети — ядро и основа программы лояльности. Данные содержатся в модуле «CRM: Покупатели».
На основании анкетных данных и истории покупок по разным признакам формируются сегменты покупателей, и им предоставляются свои преференции и персональные предложения (модуль «Сегменты»).
Запускать купоны, бонусы, всевозможные акции и скидки позволяют модули управления рекламными акциями («Бонусы», «Купоны»). Каждая из механик должна работать в рамках всей сети, иметь свои настройки, условия и ограничения — поэтому существуют также сервисы счетчиков и ограничений.
Всё это дополняется системой информирования (модуль «Коммуникации») через sms, мессенджеры, почту и мобильные приложения — это тоже часть системы лояльности, хоть и вспомогательная.
Что происходит на кассе
Итак, у клиента установлен кассовый софт, например, Set Retail и система лояльности (в нашем случае Set Loyalty). Как выглядит типичный сценарий на кассе — добавляются товары, осуществляется проверка на возраст (если требуется), нажимается кнопка «Расчет». Дальше начинается магия:

Применение дисконтной карты покупателя — вот отправная точка для начала работы системы лояльности Set Loyalty:
Происходит авторизация через поиск дисконтной карты или номер телефона покупателя в базе данных «CRM: Покупатели».
В процессе авторизации отправляются запросы в базы данных «Сегментов», «Бонусов».
В результате на момент расчета на кассе есть вся необходимая информация: анкета покупателя, сегменты, в которые попал покупатель, его бонусный счет.
Теперь можно добавить купон и повторить весь цикл.
На основе чека и данных, полученных от системы лояльности, покупателю предоставляются скидки на товары — как универсальные для всех обладателей дисконтных карт, так и уникальные: для сегмента покупателей и даже персональные для конкретного покупателя.
Примерно так же рассчитываются условия покупки во всех каналах покупки: в интернет-магазине, на кассах для самостоятельной покупки. И все это должно работать максимально быстро, чтобы покупатель даже не заметил задержки в обслуживании.
Как мы к этому пришли
Изначально в Set Retail был (и есть) отдельный встроенный модуль лояльности с гигантским числом механик: акций и скидок — они считаются непосредственно на кассе. Эти акции и скидки могут заводиться даже и в ERP-системе и спускаться в нужный магазин через центральный офис, но в конце концов попадают именно на кассу — конечную точку продажи и расчета акций и скидок. Информация о результатах применения акций на кассах «поднимается» назад на магазины, а потом в центральный офис. В итоге обмен данным происходит по такой схеме.

При этом ритейлеры хотели в своих программах лояльности использовать новые возможности, например, персональные скидки.
При текущем подходе это потребовало бы наличия на каждой кассе всех персональных скидок, так как покупатель может подойти на любую кассу. Результат применения акции должен подняться в центральный офис и загрузиться на оставшиеся сервера и кассы — так, чтобы другие кассы смогли учесть уже примененные персональные скидки и актуализировать данные по клиенту. А это — сотни миллионов действующих предложений, состояние которых должно быть актуально в любой момент времени в любом месте покупки. Аналогично с данными бонусных счетов, одноразовыми купонами — данных становилось слишком много. Возникла необходимость писать сервисы для процессинга всех необходимых данных.
Решение
Решено — делаем новые процессинги лояльности. Называем продукт Set Loyalty.

Используем в центральном сервере лояльности множество микросервисов, которые можно масштабировать (запускать несколько экземпляров одного типа). Этим убрана проблема точек отказа: если что-то случится с одним сервисом, это не заблокирует работу остальных. Для управления развертыванием выбрали Nomad (почему именно он — написано в статье моего коллеги), к нему добавили Consul для хранения настроек и Service Discovery, в качестве прокси для маршрутизации traefik. Все три компонента: nomad, consul, traefik взаимодействуют друг с другом без нареканий.
С выбором фреймворка для написания сервисов экспериментировать не стали, запланировали писать с помощью фреймворка Spring Boot, что позволило быстро стартовать и написать первые сервисы. В качестве базы данных взяли PostgreSQL и Patroni для него как автоматический failover.

Проблема с множеством каналов связей решается, с одной стороны, концентрацией информации на стороне лояльности, то есть мы не спускаем на кассу данные, которые можно не спускать, касса запрашивает их по необходимости. С другой стороны, там, где это осталось необходимо, асинхронные данные (в частности, чеки) получаем, используя такую хорошо масштабируемую систему, как Kafka.
Все интеграции (взаимодействия между сервисами, запросы с касс) стали делать через JSON, синхронный обмен сообщениями в стиле REST, ранее использовали различные реализации RPC поверх HTTP, в частности SOAP — тут пришлось перестраивать мышление при создании API сервисов. В итоге получилось так:
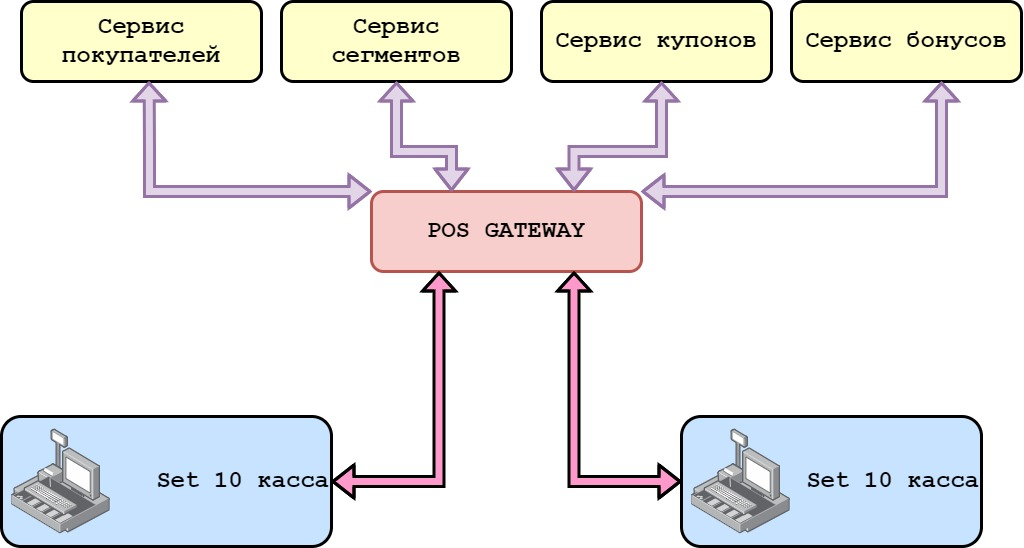
Теперь касса запрашивает всю необходимую информацию для работы с покупателем в POS Gateway (шаблон микросервисной архитектуры API Gateway), который осуществлял агрегацию информации из всех сервисов. Тут нашлось применение реактивному программированию, задействовали WebFlux.
Что теперь происходит на кассе. При применении дисконтной карты сначала опросить необходимо сервис «CRM: Покупатели». Получаем анкету покупателя вместе с уникальным идентификатором покупателя, используя который делаем запросы в сервисы сегментов, купонов, бонусов и т.п. Естественно, ответ для кассы можно сформировать быстрее, если запросы по идентификатору покупателя делать параллельно. WebFlux позволяет удобно выполнять параллельные запросы и производить их агрегацию.
Сервис «CRM: Покупатели» отвечает за хранение анкет покупателей и дисконтных карт. Он получился наиболее комплексным сервисом, явно без приставки микро-, так как туда попали сущности, которые либо нельзя было разделить, либо сделать это было сложно. Также «CRM: Покупатели» должны поддерживать множество интеграций (помимо касс): со стойками самообслуживания, CRM-системы клиентов, личным кабинетом покупателей и т.п.
В итоге получилась гибкая и масштабируемая система: у каждой торговой сети может быть своё подмножество сервисов (например, сети не нужны бонусы) — модулей лояльности. Можно менять количество инстансов сервисов и БД, группировать БД разных доменов как на одном хосте, либо делить на множество, использовать реплики и иным образом менять систему под потребности бизнеса: в зависимости от величины аудитории покупателей. Такой подход позволяет адаптировать решение: для крупной сети — это одна инфраструктура и требования к высокой доступности, для средней — другие, поменьше и подешевле.
Разработка API сервисов
Как я писал, были определенные трудности с переходом от RPC к REST принципу построения API сервисов. При использовании Spring MVC используют два подхода: либо пишут контроллеры, классы DTO, добавляют к ним swagger-аннотации и генерируют спеку, либо наоборот: сначала пишут спеку, а потом генерируют контроллеры с DTO (также известен как API First).
Так вот, в нашем случае более продуктивным оказался именно второй подход:
1. Он позволяет сразу получать аккуратно написанный документ, который можно передать для сторонних интеграций (которые могут быть написаны совсем не на Java).
2. Такой документ можно использовать еще до начала разработки сервиса, параллелить работу.
3. Меньше кода в репозитории, так как большая часть генерируется во время компиляции.
4. Что немаловажно, позволяет сразу «думать» категориями REST: ресурс, GET POST PUT, вместо натягивания названий методов на HTTP-пути.
Тестирование
В начале мы продолжали использовать обычный подход при написании тестов: брали каждый класс, будь то контроллер, сервис или DAO, внешние зависимости класса закрывали через Mockito (с embedded БД работали только DAO), класс покрывали тестами.
Но такой подход имеет ряд проблем:
Каждый такой тест на класс полагается на определенное поведение классов, от которых он зависит, это поведение может меняться, но тест продолжит работать.
Любой рефакторинг требует переписывания огромного количества тестов, хотя поведение сервиса в целом не менялось.
Распространена ситуация, когда вроде бы все тесты написаны, но сервис в целом не работает из-за каких-то очень простых ошибок.
В новом решении удачной находкой оказалось использовании mockMVC (end2end) тестов: поднимаются все Spring-бины, используется реальная embedded БД и Kafka, тесты сводятся к REST-запросам и чтению из Kafka, интеграции с другими сервисами закрываются через Mockito. Такие тесты сложнее писать, но они эффективно покрывают основную часть кода сервиса, взяв за основу подобный тест легко воспроизвести почти любой найденный на проде дефект. Таким образом, разработчик делает акцент на end2end тестах основных сценариев, иначе говоря, mockMvc-тесты пишутся на основе спеки в первую очередь, далее тестами покрываются уже отдельные сервисы, слой dao и прочее, как бы сверху вниз.
В заключение
Внедрить новые подходы и технологии нас мотивировали потребности рынка. Решение оказалось востребованным и позволило удовлетворить не только потребности торговых сетей и покупателей, но и нас как разработчиков, которые хотят всегда попробовать что-то новое.
Мы полностью довольны результатом и выбранной архитектурой решения, уверены, что справимся с требованиями даже самых крупных федеральных сетей. Сервисы показывают стабильно высокую доступность и скорость отклика, измеряемую в миллисекундах даже в часы пиковой загрузки RPS.
Ниже — пример из grafana одного из наших клиентов с клиентской базой более 30 миллионов покупателей. Технические службы наших клиентов сами при желании наблюдают за показателями «здоровья» своей программы лояльности.

Статья получилась обзорной, если возникнет интерес к конкретным пунктам — буду рад ответить в комментариях.