

Введение
В своей статье про обучение на синтетике я затронул такой инструмент как Grad-cam. Grad-CAM один из подходов, позволяющих интерпретировать модель и визуализировать её результаты. Давайте немного поговорим зачем вообще тратить время и ресурсы на визуализацию предсказаний и как это может помочь в будущем!
Если вы уже занимались обучением сверточных нейронных сетей, то наверняка сталкивались с подобной проблемой:
Собрали датасет с котиками (с кем же еще?), начали обучать и получили не самые радужные результаты. Что делать? Ну, естественно, набрать больше котиков!
Обучили еще разок, а результаты никак не изменились, а может даже стали хуже? Что-то явно не так.

О чем это может говорить? В целом..да о чем угодно! Мы можем начать строить и проверять различные гипотезы:
Недостаточное количество нужного класса.
Однотипные экземпляры класса.
Однотипный фон.
Модель обучилась именно на фон.
и так далее и тому подобное..
В случае маленьких моделей и датасета проверка этих гипотез не затратит уйму нашего времени, но как быть, когда на обучение требуются сутки?
Для того, чтобы помочь себе оптимизировать рабочий процесс попробуем разобраться как и что видит наша модель или по другому - какая часть входного изображения активирует тот или иной класс.
CAM-CAM, My lady
Как вы уже могли догадаться - основная идея всех методов в упрощении интерпретируемости моделей.
Для начала, возьмем один из самых простых и надежных методов: Class Activation Maps или коротко CAM.
Представим обычную сверточную сеть: подадим на вход изображение, которое будет проходить через наши сверточные слои, выделяя признаки и на выходе последнего сверточного слоя для каждой карты признаков применим global average pooling (GAP), тем самым усредняя значения в один единственный скаляр и пропустим всю эту красоту через подобие логистической регрессию. Зачем это делать?
Нас интересуют карты признаков, потому что в них содержится информация о пространстве картинки и мы предполагаем, что в картах признаков, полученных после последнего сверточного слоя достаточно информации для классификации.
Теперь нам необходимо обработать их, дабы сделать вывод о том, что за класс перед нами. Для этого мы и используем GAP, а также fully connected layer и softmax, чтобы обучить нашу сеть имитировать полносвязные слои, бывшие в исходной модели.
Теперь, обучив этот слой, мы получим веса, самое время использовать их для взвешивания полученных карт признаков на последнем сверточном слое. Это-то и даст нам возможность понять какой вклад внесла каждая из карт признаков. До GAP слоя мы знали ГДЕ находится тот или иной признак, а теперь мы знаем насколько он важен для определения класса

Математически описать можно следующим образом:
Возьмем карту признаков (что и является функцией), где x и y пиксели, тогда выход из нашего GAP слоя будет выглядеть следующим образом:
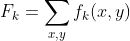
Затем мы берем полученное значение и, чтобы получить предсказание модели перед Softmax, необходимо умножить веса на это самое значение. Таким образом, получаем вот такую формулу:
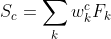
Теперь прогоняем через Softmax, получая вероятность определенного класса:
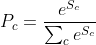
И в конце мы выполняем умножение линейной комбинации весов на полученное значение после GAP:
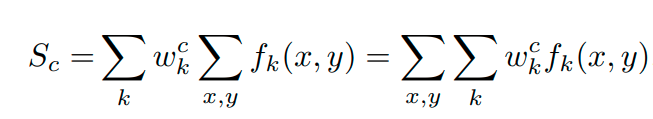
Так как все это представляет из себя линейную комбинацию, поэтому мы можем доработать нашу формулу и получить понимание насколько важна эта карта признаков и то, что в итоге мы рисуем:
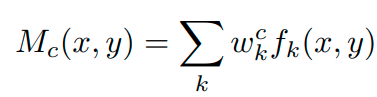
Вот небольшой скрипт для визуализации процесса, ну.. и можно поиграться, насколько это позволит модель на Imagenet.
Не забываем про градиенты
Теперь перейдем к Grad-CAM, а если быть точнее, Gradient-weighted CAM . Мы уже знаем как работает CAM подход, а основная идея Grad-CAM очень схожа: мы хотим использовать информацию, полученную через нашу сверточную сеть, чтобы понять какие части входного изображения были важны для принятия решения о классификации. Основное отличие подхода в том, что Grad-CAM позволяет нам избавиться от линейности в финальной части модели, нам не нужно изначально перестраивать модель и при этом мы все еще можем спокойно визуализировать процесс.
Разберемся как это сделать.
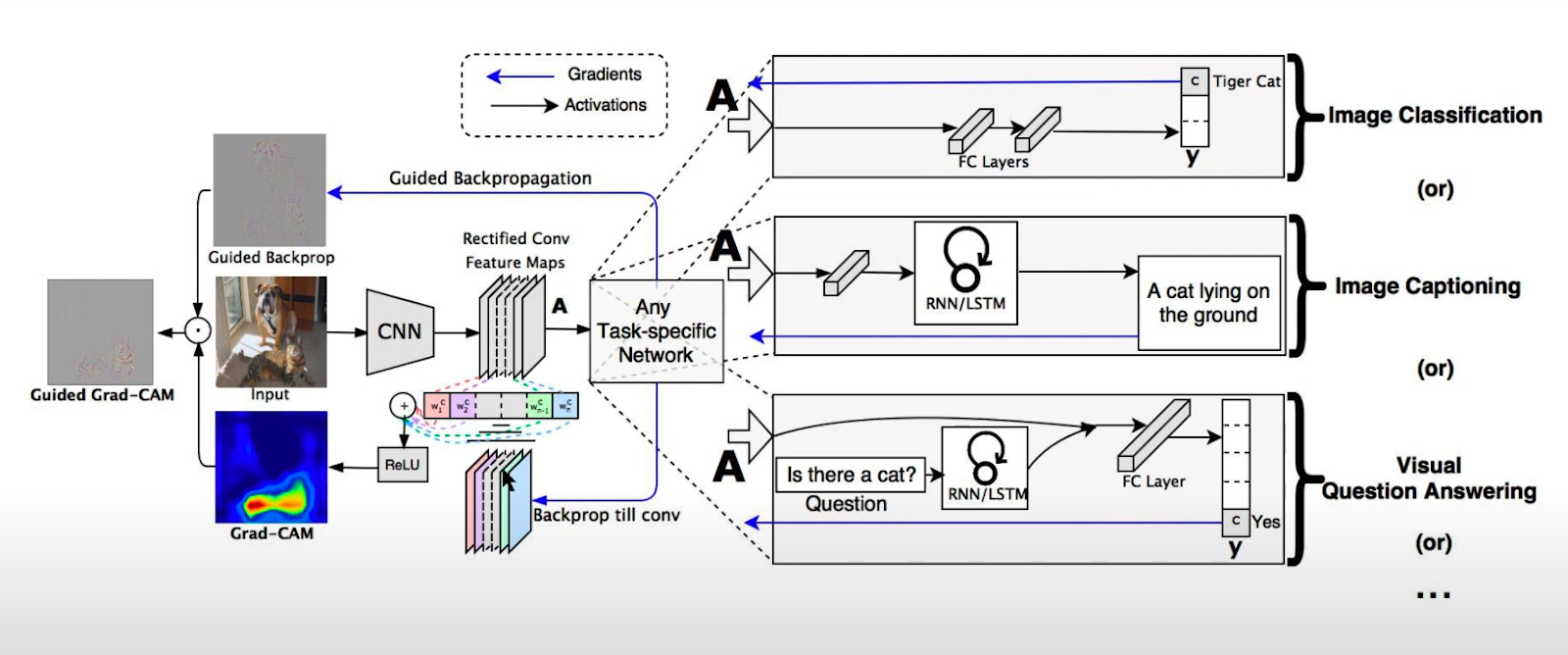
Как и всегда - подадим на вход изображение, все также пройдемся через сверточные слои, все также на выходе получаем карты признаков, в этот момент в реализации CAM нам необходимо изменить архитектуру (добавить GAP,FC,Softmax), в реализации Grad-CAM мы способны сделать что угодно с условием дифференцируемости слоев, чтобы получить градиент. В целом, можно выделить три этапа работы Grad-CAM, давайте разбираться.
Шаг 1: Подсчет градиента
y^c - выходные данные сети для класса С до применения Softmax, озьмем производные от этих данных по отношению к картам признаков:
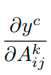
Таким образом мы получим кучу производных (градиент), которые сможем использовать для нахождения интересующих нас весов.
Шаг 2: Подсчет весов усреднением градиентов
Эти веса (в некоторых работах это называют альфа-значения) получаются в результате объединения global average pooling и этих производных:
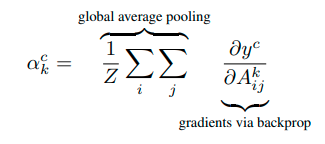
Шаг 3: Подсчет Grad-CAM Heatmap
Теперь мы можем пропустить через ReLU (получив, таким образом, только положительные значения, так как нас интересуют только те значения, что вносят какой-то вклад) линейную комбинацию весов и карты признаков и это как раз то, что мы ищем:
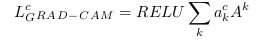
Увеличиваем размерность для соответствия с входным изображением и вуаля!
Здесь вы также можете попробовать GradCAM.
Путеводная звезда
Перед финальным Guided Grad-Cam, думаю, стоит рассказать о Guided Backpropagation.
Основная идея - мы пренебрегаем всеми отрицательными градиентами и фокусируемся только на положительных градиентах (почти мотивационная цитата).
Итак, чуть подробней: подаем на вход сверточной сети изображение, получаем карты признаков. При прямом распространении, после сверточных слоев мы проходим через ReLU и, таким образом, любой отрицательный выход фиксируется как 0.
А теперь мы просто берем и делаем ровно тоже самое, но с градиентом, таким образом, при backpropagation мы возвращаем только те градиенты, которые соответствуют неотрицательным элементам, а отрицательные мы зануляем.
Благодаря такому подходу мы можем дать себе ответ на вопрос - что видит наша модель и нас абсолютно не интересует, чего она не видит.

И по традиции, ссылка на код.
Всё лучшее - вместе!
Ну и финальное на сегодня: Guided Gradient-weighted CAM.
Как можно догадаться из названия - это просто совокупность Guided backpropagation и Grad-CAM.
Поэтому,думаю, много писать тут нет смысла, давайте просто покажу код, да и сравним полученные результаты по всем подходам.

Проблемы, шеф!
Grad-CAM очень популярный метод для интерпретирования моделей и создания heatmap для конкретных классов на основе входных изображений. Однако, у этого подхода наблюдаются значительная проблема: из-за шага усреднения градиента мы можем получить некорректный heatmap с выделенными нерелевантными областями.
Но эта проблема ничто в сравнении с проблемами связанными с Guided подходами. В статье проводились проверки самых популярных подходов для визуализации. Возьмем два теста:
Тест 1:
Если мы хотим (а мы хотим) использовать heatmap для того, чтобы определять как именно наша модель делает прогнозы, то мы расчитываем, что полученный heatmap связан с параметрами, которые модель получила в процессе обучения. Исходя из этого, мы можем сделать проверку работоспособности - возьмем рандомные веса и если это ломает наш итоговый heatmap, то все хорошо, так и должно быть. И вот, что предоставляют нам эксперименты из статьи:
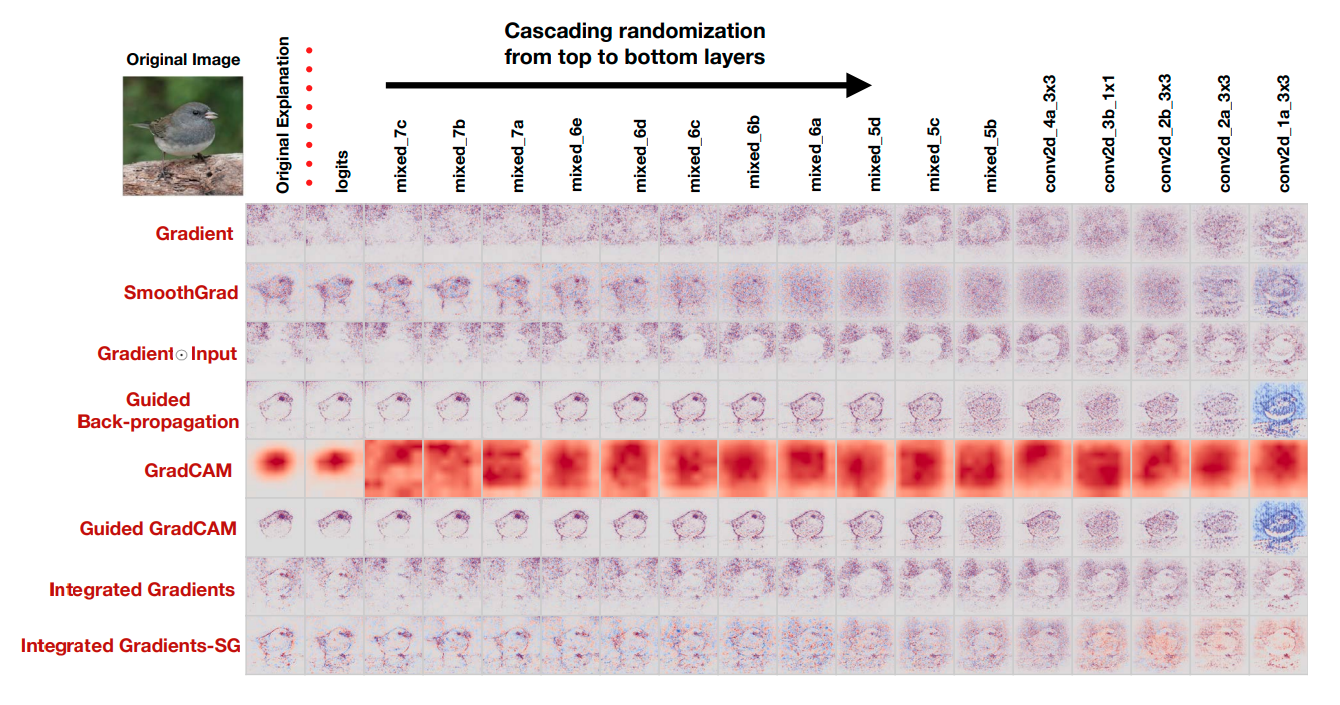
Как мы видим, guided подходы практически никак не изменились, что подает тревожные звоночки. Но давайте пройдем еще один тест.
Тест 2:
Второй тест поинтересней в своей идеи:
Давайте перепутаем все метки - изображение кота будет помечено как собака, мяч как банан и так далее (на что хватит фантазии, но лучше просто использовать случайное распределение). Зачем это делать? В целом, затем же, что и в первом тесте - если подход визуализации не будет чувствителен к рандомизации меток, тогда этот подход не в состоянии объяснить механизмы, которые показывают зависимость экземпляра и метки. Другими словами, если мы подаем на вход изображение кошечки, получаем heatmap, на котором области интереса будут определяться на этой самой кошечке, но метка (label) у нас была собачка - это говорит о том, что подход не работоспособен. Пример теста из статьи:
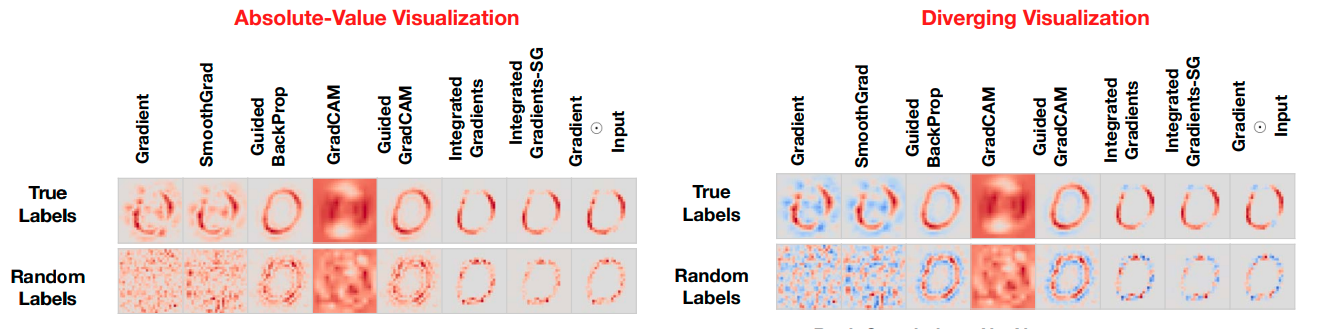
Выводы
Получаем довольно интересные выводы о том, что подходы, связанные с Guided вариацией не дают нам надежных объяснений о том, как работает наша модель, а лишь функционируют как дететкор границ. Исходя из этого, лучше использовать CAM и Grad-CAM подходы, однако, и у них есть свои недостатки, которые, впрочем, были исправлены в дальнейших исследованиях, о которых я расскажу в следующей статье!
dronperminov
Самое печальное в методах, основанных на градиентах, то, что они объясняют только значения градиентов. Корреляцию между объяснимостью работы сети и значениями градиентов в хэтмапах, несомненно, можно увидеть, но никак нельзя взаимозаменять эти два понятия, к сожалению.
Кажется, что истинное объяснение может дать только математическая функция, которую реализует сеть, но толку от такого объяснения на порядок меньше, чем от градиентов.