
Минутка фантастики
Давайте заглянем в параллельный мир на минутку. Допустим, некий товарищ Х составляет некий отчет в некоторую организацию о том, как все изменилось – с процентами, динамикой, распределениями, тестированиями. Допустим, он этот самый отчет сделал – но ему его вернули с неофициальными комментариями «Много формул, ничего не понятно, надо проще» (понятно, почему фантастика – в нашем мире, особенно в госструктурах, это встретишь очень редко).
Но именно в этих случаях и можно применять пакет ggstatsplot.
Краткая идея
Все очень просто – для некоторых задач проверки гипотез в этом пакете реализовано и автоматическое построение графика, и вывод на этом же графике результата теста.
В верхней строчке всегда пишется значение тестовой статистики и р-значение для соответствующей гипотезы. Отлично, что для каждой гипотезы доступны 4 варианта теста: параметрический, непараметрический, робастный (устойчивый к выбросам) и байесовский Дальше строчка продолжается показателем размера эффекта и доверительный интервал размера эффекта. Байесовский тест также выполняется автоматически и информация по нему в строчке внизу.
Порисуем
А вот как это все выглядит на практике (комментарии к коду - это проверяемая гипотеза):
library(AER)
library(ggplot2)
library(ggstatsplot)
library(tidyverse)
data("PSID7682")
data("PSID1976")
# Гипотеза: медиана количества отработанных часов равна 300
gghistostats(data = PSID1976, x = hours, test.value = 300, xlab = "job hours in week", centrality.type = "nonparametric")
Все красиво и доступно - гистограмма значений переменной, линия, изображающая истинную медиану, имя теста - t-критерий Стьюдента, значение критерия - 13.88, р-значение гипотезы, которое позволяет отвергнуть нулевую гипотезу о том, что медиана равна 300.
# Гипотеза: средняя зарплата в группах женатых и неженатых в 1976 году одинакова
ggbetweenstats(PSID7682 %>% filter(year==1976), x = married,y = wage)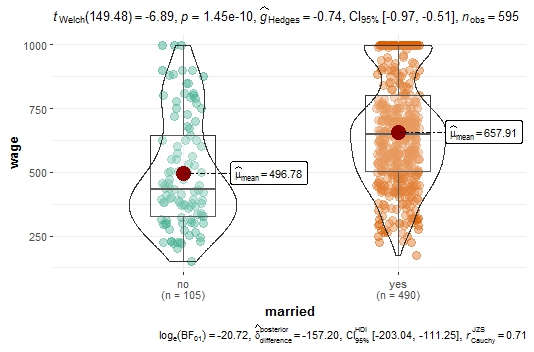
Крайне информативный график - можно визуально сравнить распределения, квантили, отмечены средние ... ну и гипотеза о равенстве средних тут тоже отвергается. Есть и модификация для большого количества групп:
# Гипотеза: средняя зарплата в разные года одинакова
ggdotplotstats(data = Base3 <- PSID7682[,c(12,13)],x = wage,y = year,type = "robust")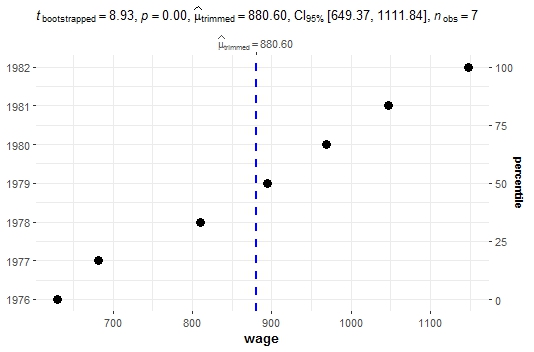
Собственно, точками показано изменение зарплаты в разные года. С помощью type = "robust" была задана необходимость использования теста, устойчивого к выбросам. Посмотрим еще на графики:
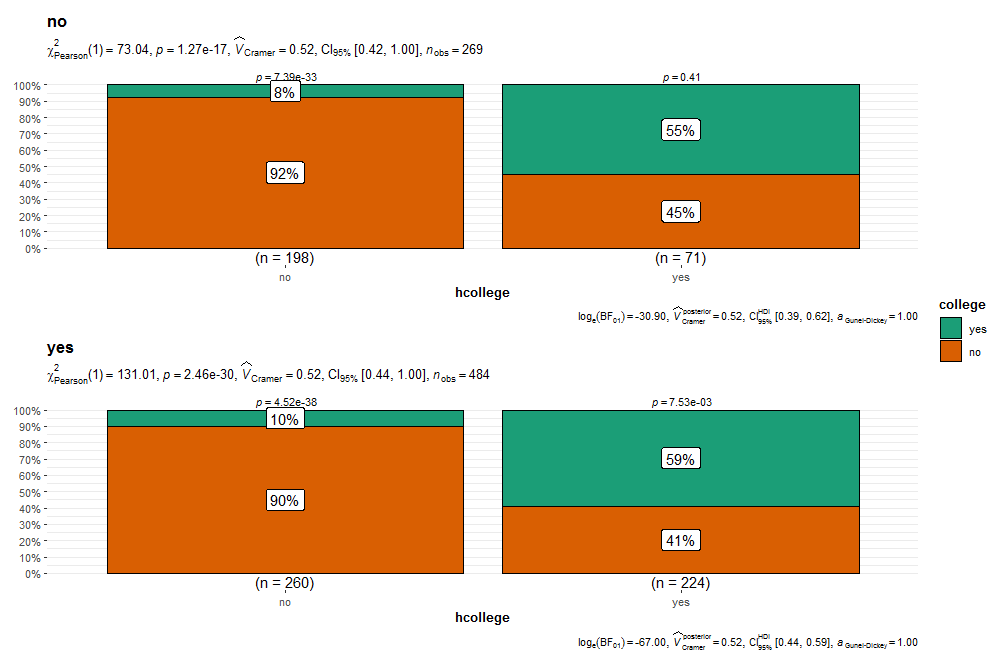
# Гипотеза: среди живущих и неживущих в городе пропорции закончивших / незакончивших колледж одинакова
ggbarstats(PSID1976, x = college, y = city)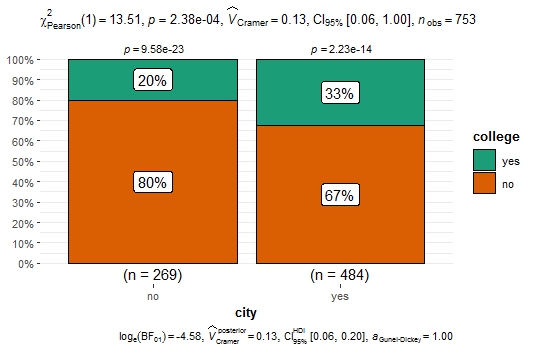
Это шикарный способ визуализации теста 2 на 2 категориальных данных на равенство пропорций. Тест хи-квадрат показывает, что нулевую гипотезу о равенстве пропорций можно отвергнуть.
Из простого также можно отметить круговые диаграммы:
# Гипотеза: истинная пропорция тех, кто учился / не учился в колледже: 50 на 50
ggpiestats(PSID1976, x = college)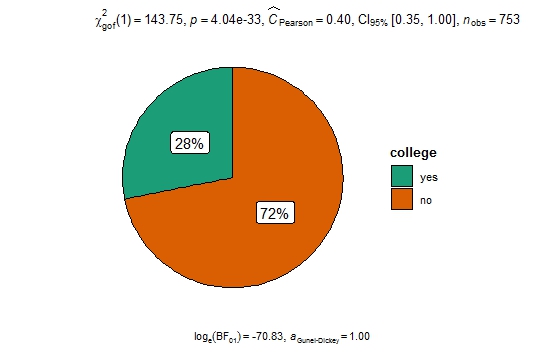
Есть возможность вывести и точечный график в показателями значимости корреляции:
# Гипотеза: корреляция между количеством отработанных часов и заработной платой нулевая
ggscatterstats(data = PSID1976,x = hours,y = wage,
point.args = list(size = 1.5, alpha = 0.4, stroke = 0, na.rm = TRUE),
smooth.line.args = list(size = 1, color = "blue", method = "lm", formula = y ~ x, na.rm = TRUE))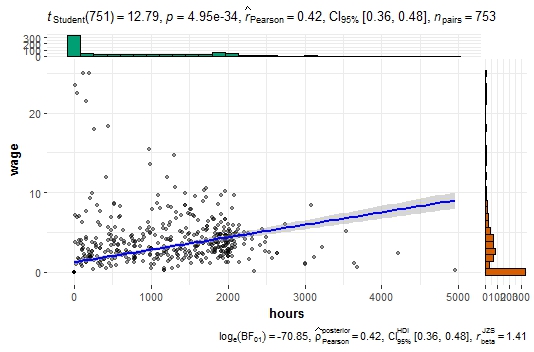
Возможности модификации элементов графика тоже большие - можно задать и параметры гистограммы, и параметры точек, и параметры линии. Гипотеза о нулевой корреляции также отвергается.
Отдельно стоит сказать про корреляционную матрицу. Она тоже крайне хороша:
ggcorrmat(data = PSID1976[,c(2,5,7,14,17)])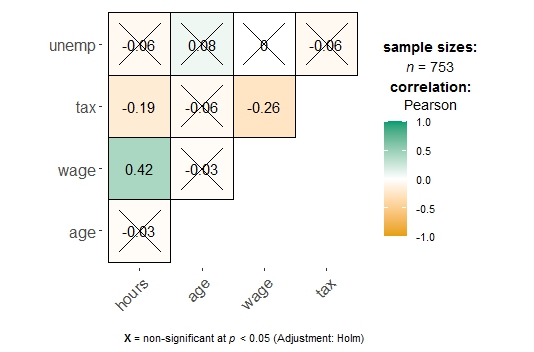
Незначимые корреляции сразу зачеркиваются.
Однако это еще не все. Пакет эксклюзивен возможностью построения группы графиков, что позволяет отразить результаты тестов для разных групп данных. Примеры ниже:
# Проверка гипотезы о равенстве средней зарплаты в группе женатых и неженатых в 1976 году для разных отраслей (yes - работа в промышленности, no - нет)
grouped_ggbetweenstats(
data = Base1, x = married,y = wage, plot.type = "violin",
grouping.var = industry,
output = "plot")
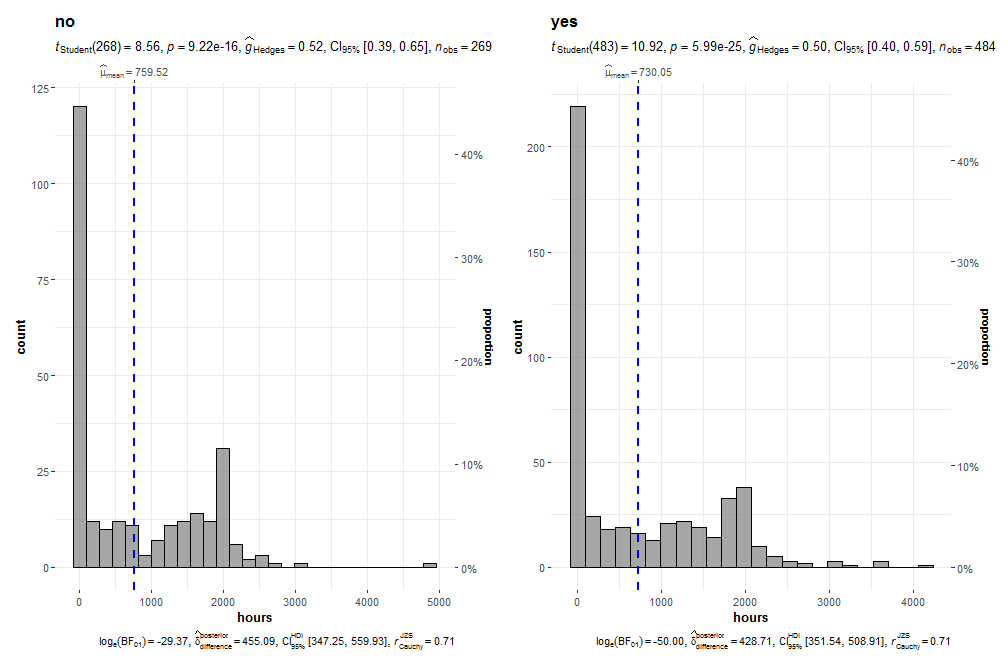
# Проверка гипотезы о равенстве среднего количества отработанных часов 300-м для тех, кто живет и не живет в городе
grouped_gghistostats(data = PSID1976,
x = hours, test.value = 300,
grouping.var = city)
# Проверка гипотезы о равенстве пропорции уровня образования жены среди мужчин разного уровня образования для тех, кто живет и не живет в городе
grouped_ggbarstats(data = PSID1976,
x = college,
y = hcollege,
grouping.var = city,
plotgrid.args = list(nrow = 2))
# Проверка гипотезы о равенстве пропорций живущих и не живущих в городе для людей с разным уровнем образования
grouped_ggpiestats(
data=PSID1976, x = city,
grouping.var = college)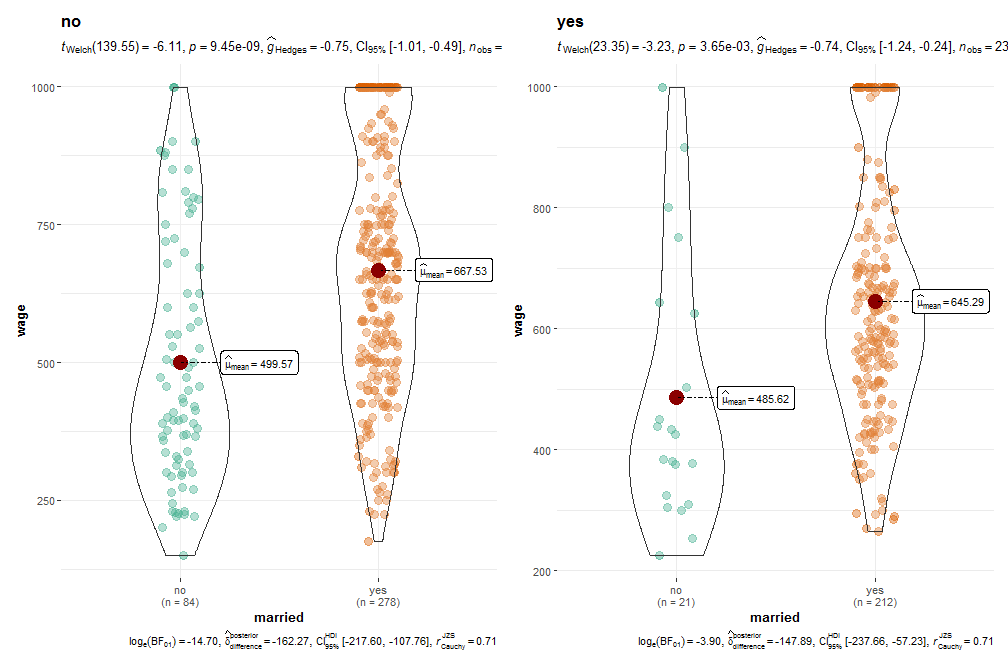
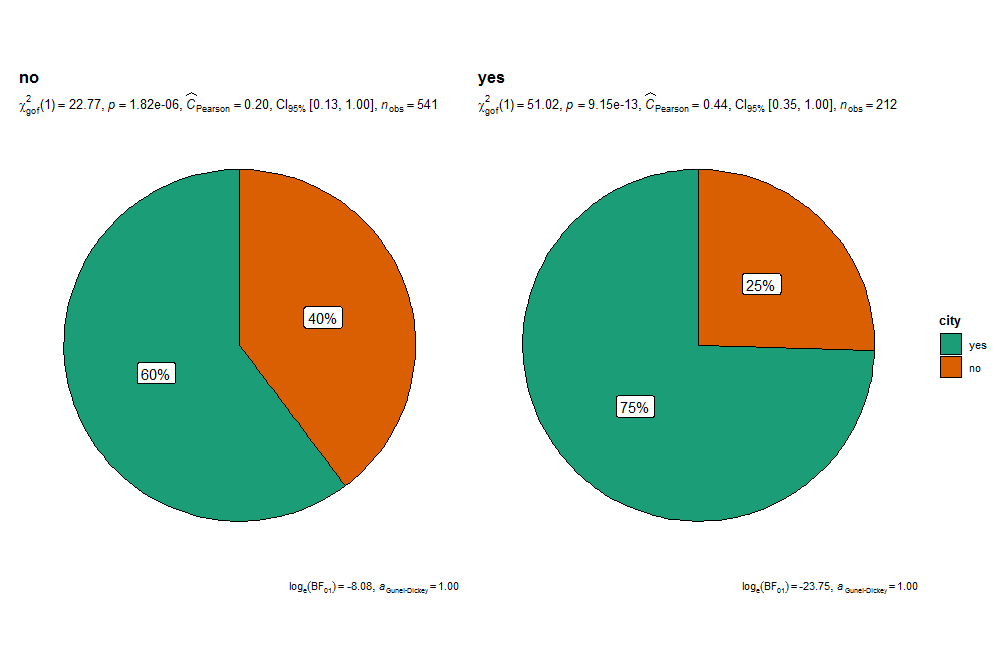
Отдельно стоит упомянуть про визуализацию уравнений регрессии. Есть очень интересный способ визуализации доверительных интервалов и статистик коэффициентов регрессии:
# Визуализация значений и параметров регрессионных коэффициентов
mod <- lm(formula = I(log(wage)) ~ weeks*education+industry , data = Base1)
ggcoefstats(mod, output = "plot")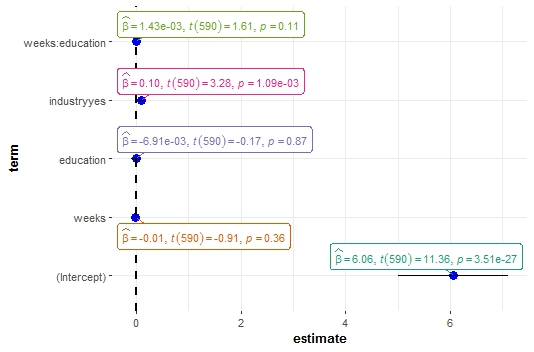
Значение коэффициента, визуализация размаха, результаты проверки гипотезы о равенстве данного показателя нулю - все видно.
Но еще больше возможностей представляет пакет ggpmisc.
Можно задать и вывести уравнение регрессии со статистикой:
library(ggpmisc)
formula <- y ~ poly(x, 3, raw = TRUE)
ggplot(Base2, aes(x=hours, y=wage)) +
geom_point() +
stat_poly_line(formula = formula) +
stat_poly_eq(aes(label = paste(after_stat(eq.label), "*\" with \"*",
after_stat(rr.label), "*\", \"*",
after_stat(f.value.label), "*\", and \"*",
after_stat(p.value.label), "*\".\"",
sep = "")),
formula = formula, size = 3)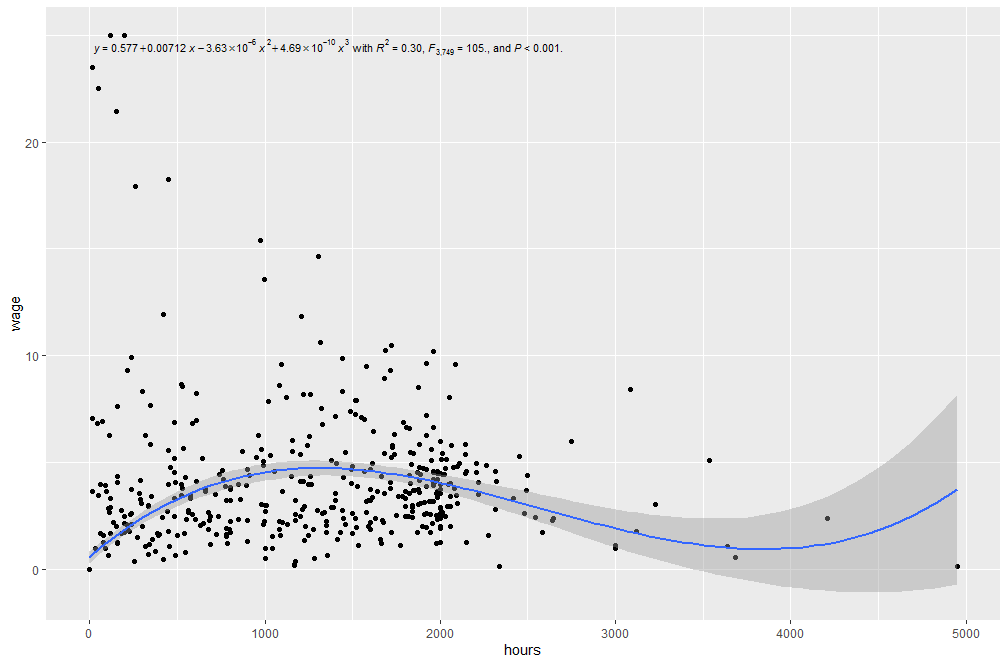
Или можно просто вывести классическую табличку с коэффициентами на график:
formula <- y ~ x + I(x^2) + I(x^3)
ggplot(Base2, aes(x=hours, y=wage)) +
geom_point() +
geom_smooth(method = "lm", formula = formula) +
stat_fit_tb(method = "lm",
method.args = list(formula = formula),
tb.vars = c(Parameter = "term",
Estimate = "estimate",
"s.e." = "std.error",
"italic(t)" = "statistic",
"italic(P)" = "p.value"),
label.y = "top", label.x = "right",
parse = TRUE)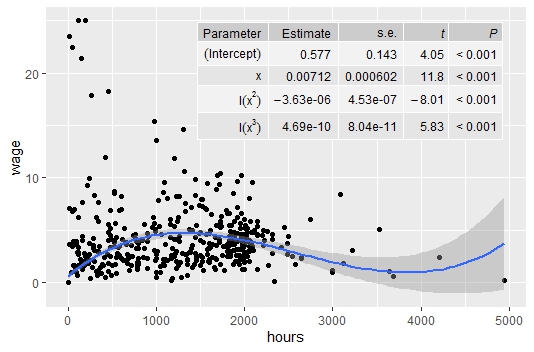
Выглядит все очень лаконично, емко и точно может быть использовано для подготовки разного рода отчетов и выступлений.