
Привет, Хабр! Думаю, все здесь в курсе, что данные — это новая нефть. Однако нефть мало чего стоит сама по себе, нужно уметь ее перерабатывать. Если говорить об использовании искусственного интеллекта в радиологии, то самое важное — объективность интерпретации данных.
В теории все звучит достаточно просто: врачи размечают данных, полученная информация загружается в единую базу, нейронные сети сопоставляют сведения и выносят вердикт. Однако на практике разработчики медицинского ИИ сталкиваются с множеством проблем, которые затрудняют процесс интерпретации.
Внедрение программного обеспечения на базе ИИ в здравоохранение — очень сложный процесс. Если делать это неправильно — стартап на верном пути к провалу. В чем заключается сложность и как мы в «Цельсе» с ней героически боремся — читайте под катом.
Недостаток знаний
Внедрением нейронных сетей в здравоохранение занимаются ИТ-специалисты, в частности, дата-сайентисты, которые с помощью математических алгоритмов и программных инструментов проводят анализ данных. Это люди с техническим образованием, которые разбираются в программировании, но при этом не имеют необходимых знаний для расшифровки медицинских снимков.
Незнание предметной области — одна из главных проблем, с которой сталкиваются инженеры при работе с искусственным интеллектом. Чтобы достичь максимального качества модели, дата-сайентист должен анализировать их на ошибки для дальнейшей кластеризации и генерации гипотез. Однако без медицинского образования сделать это проблематично.
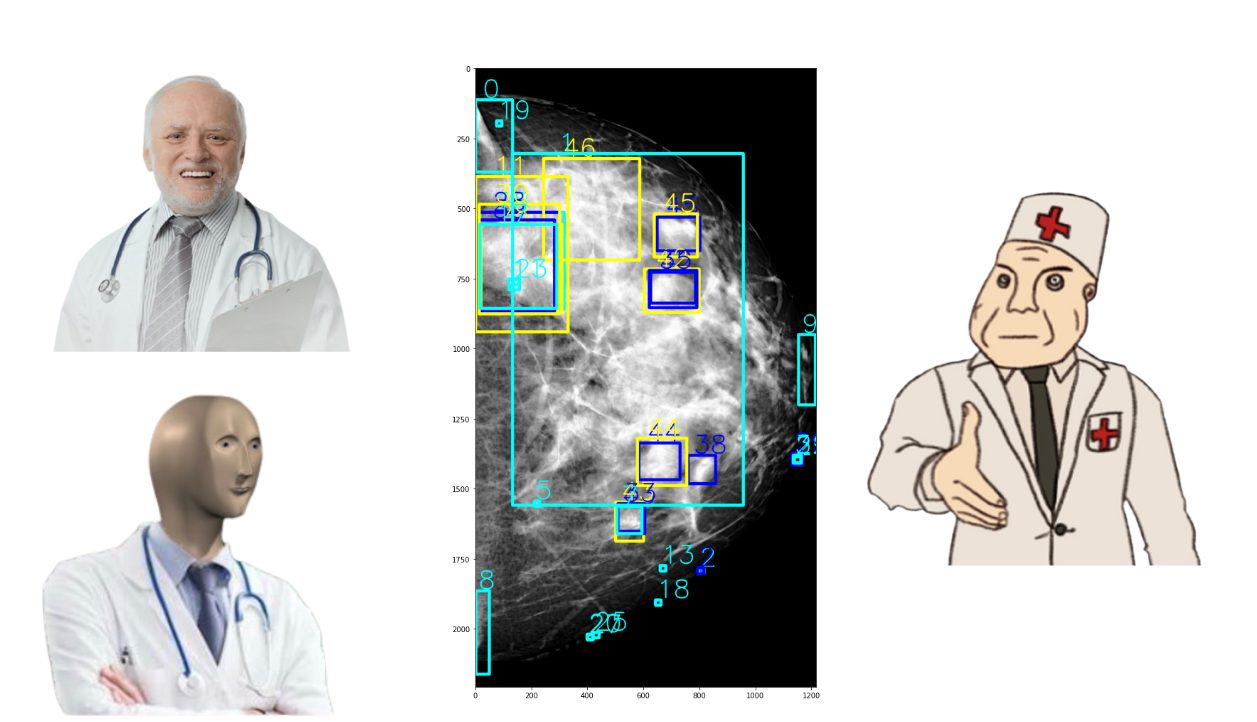
Еще одна проблема, которую могли бы решить специальные знания — грязная разметка. Врач мог бы обнаружить шум визуально, однако инженер, оценивая медицинское изображение, не всегда может определить, где действительно патологический участок, а где присутствует артефакт.
Не стоит забывать про коммуникативные трудности в общении между дата-сайентистами, разметчиками данных и пользователями, дающими обратную связь. Из-за обилия специфических терминов (а порой и профессионального сленга) достичь взаимопонимания может быть нелегко. Для устранения этой проблемы можно прибегнуть к услугам «переводчиков» — специалистов с широкими компетенциями, которые могут понять каждого участника диалога и с каждым найти общий язык.

Вариативность исходных данных
Вторая проблема, которая усложняет интерпретацию данных — вариативность этих данных. Откуда она возникает? В медицинских учреждениях стоит разное оборудование, которое, в соответствии с условиями эксплуатации, по-разному настраивается специалистами. В результате на рентгенографии, проведенной у одного пациента, но на разных аппаратах, цифровые изображения могут очень сильно отличаться.
Вариативность обусловлена и тем, как лаборант работает с пациентом и диагностическим оборудованием. Сотрудник рентгенологического кабинета может уложить пациента на платформу по-разному — соответственно, меняется угол обзора, площадь изображения органа. Зачастую на снимках отсутствует участок тканей, необходимых для интерпретации. Это меняет разметку, как следствие, разнится и объективность анализа.
И третий фактор вариативности — сами пациенты. Каждый человек индивидуален, имеет свои анатомические особенности в силу возраста, пола, роста, веса. Это также нужно учитывать при обучении нейронных сетей интерпретации.
Нерелевантные и некачественные данные
В обучающих выборках часто попадаются снимки, на которых присутствуют нерелевантные изображения, а также снимки с артефактами. На качестве обучения нейронных сетей это сказывается неприятным образом, а потому требует проработки.
Разметка данных
Врачи обладают различным опытом, знаниями, практическими умениями. Поэтому один и тот же снимок они могут разметить по-разному. Кроме того, один врач может заметить патологию на ранней стадии, другой не выявит отклонений и пометит пациента как полностью здорового. Соответственно, процесс обучения искусственного интеллекта в данном случае резко усложняется.
В чем причины различной разметки данных?
Субъективность — каждый специалист интерпретирует данные исходя из своей квалификации, опыта, навыков.
Суммационные изображения. Например, исследованию подвергается трехмерный орган, но в результате рентгенографии врач получит двухмерное изображение легких. Это приводит к утрате части информации, необходимой для постановки верного диагноза.
Отсутствие данных о пациенте. Обучение искусственного интеллекта выстраивается на строгих принципах анонимности, поэтому при нанесении разметки врачи не могут ориентироваться на анамнез. Иными словами — работают вне контекста. Это также приводит к расхождениям.
Человеческий фактор. Врачи — обычные люди, которые из-за усталости, невнимательности или по другим причинам могут допустить ошибки, расшифровывая цифровые изображения.
Стоимость работы
Создание действительно качественной базы данных со снимками, на которые наносили разметку компетентные врачи — высокооплачиваемая работа. Анализ одного цифрового изображения обходится в среднем в 1000 рублей. В некоторых случаях, чтобы обеспечить высокую объективность интерпретации снимков, требуется кросс-разметка, в которой принимают участие до 5 врачей одновременно. Это повышает стоимость разметки одного снимка в 5 раз.
Дороговизну обуславливает и то, что до 95% изучаемых снимков — снимки здоровых пациентов. Такие цифровые изображения малоинформативны, так как не позволяют обучить систему искусственного интеллекта распознавать редкие заболевания, но при этом их разметка стоит тех же денег. Все это ставит под вопрос финансовую окупаемость разработок.
Большой объем данных
Медицинские цифровые снимки — это большие данные. Но не в том смысле, который обычно вкладывается в этот термин. Каждый из снимков имеет высокое разрешение — следовательно, под него требуется много памяти, от пары мегабайт до нескольких гигабайт. Уменьшать снимки для экономии облачного пространства нельзя, так как это снижает качество изображения.
Большой объем данных приводит к тому, что:
увеличивается стоимость хранения данных;
снижается скорость работы ИИ;
увеличивается длительность экспериментов.
Методы повышения качества интерпретации данных
Все вышеперечисленное делает проблему качества интерпретации данных в медицине очень острой. Если набор данных будет неполным, недостоверным, неактуальным — высокие цели, которые ставят перед собой разработчики медицинских нейронных сетей, окажутся недостижимыми.
Для решения этой проблемы нет существует «серебряной пули». Однако это не значит, что решения нет вообще. Инженеры компании «Цельс» борются с некачественной интерпретацией данных в трех ключевых направлениях:

Платформа. Разработчики пришли к выводу, что без структурирования данных, получаемых для разметки, достичь объективности невозможно. Поэтому вся информация проходит специфический отбор, проверку качества цифрового изображения в автоматическом режиме c дальнейшим дообучением нейронных сетей. Мы используем Apache Airflow, который позволяет создавать, отслеживать и проводить оркестрацию данных. Важна и разработка дополнительных внутренних продуктов — дашбордов, алертов, метрик. Активное обучение с отсеиванием непригодных снимков позволяет снизить затраты на разметку данных.
Культура и процесс. Принимать участие в работе должны люди различных профессий, из разных команд, которые имеют богатый опыт и разносторонние компетенции. Важно взаимодействие в виде встреч, летучек, мозговых штурмов, основная цель которых — обсуждение проблем, например, с разметкой данных. Для объективности интерпретации данных важно проводить работу с разметчиками — например, писать для них гайдлайны, чтобы стандартизировать процесс разметки.
Дата-тестирование. С этой целью проводится анализ базы данных на полноту информации (проставлены ли теги, отмечены ли на цифровом снимке обязательные элементы), отсутствие пересечений между наборами данных и пр. Работая с разметкой, анализируем снимки на наличие аномалий. Доменные проверки помогают выявить снимки, где присутствует отличие, и отсеять их. Важны на этом этапе и ML-проверки, которые позволяют определить корректность тегов, флип разметки, наличие на изображениях нерелевантных предметов, отсутствие артефактов, обрезанных частей снимков и тому подобное.