
Иногда взрослые думают, что школьные проекты — это что-то несерьёзное, задания упрощённые, а получаемый результат нельзя внедрить в реальный IT-мир. Мы, шесть школьников, участвовавших в научно-технологической программе «Большие вызовы-2022» на базе образовательного центра «Сириус» в составе команды банка ВТБ, попытаемся доказать вам, что большие данные и машинное обучение — это не прерогатива умудрённых опытом разрабов и что даже школьник (мотивированный и подготовленный) может стать дата-сайентистом и планировать свою будущую карьеру до поступления в ВУЗ.
Давайте познакомимся: Степан Юнда, Алексей Щербаков, Юрий Соколов, Илья Гринюк и Всеволод Киричук. Каждый из нас отвечал за определённую часть построения моделей машинного обучения и интерпретации данных. Все мы из разных городов: Алексей и Степан – из Москвы, Илья из Балашихи, Юра из Жуковского, а Всеволод из Ростова-на-Дону. Наши кураторы - Лев Меркушов, Алексей Рябых и Денис Суржко от ВТБ и Василий Гаршин от ВШМ.
За обеспечение работы моделей в облаке, построение интерфейса, настройку, то есть за весь фронтенд/бэкенд отвечал Кирилл Осинцев. От нас требовалось уверенное знание Python, любовь к математике и большим данным, понимание, что такое ML, и способность разобраться в нем. Весь проект длился три недели.

Проблематика
Вокруг любого бренда образуется огромное облако информации: посты в соцсетях, лента новостей, отзывы к приложению в мобильных магазинах приложений или зарегистрированные обращения в колл-центр. Но если эти данные зафиксировать достаточно просто, если сделать выборку по упоминанию бренда или выгрузить все отзывы в таблицы (тексты) неструктурированных данных, то вот проанализировать их не такая простая задача и часто требует привлечения дата-сайентистов.
Да, вокруг анализа такого рода данных сформировался пул сторонних организаций, готовых за определённую плату выделить необходимые паттерны информации и сформировать отчёт. Однако, этот процесс можно поручить автоматизированной системе и до 90% снизить необходимость дополнительных ресурсов.
«Какие данные могут интересовать банк?» — спросите вы. Это могут быть события, свидетельствующие о возможном ухудшении кредитного качества контрагентов банка в новостных лентах, позитивные и негативные отзывы в соцсетях о работе банка и его мобильного приложения. Или финансовая разведка, отслеживающая в потоке новостей события по определённым паттернам.
К примеру, колл-центр просит проанализировать жалобы клиентов, чтобы лучше понять, какие проблемы их волнуют. При этом разведочный анализ может быть лишь вспомогательным этапом, цель которого — помочь бизнесу сформулировать конкретную задачу на этих данных. Результаты проведённого разведочного анализа жалоб клиентов могут побудить колл-центр перестроить рубрикатор обращений — сервис маршрутизации (т. е. классификации и отправки) жалоб на профильного специалиста. Основные выводы из разведочного анализа делает заказчик, но для этого ему необходимо тесно взаимодействовать с дата-сайентистами. На первых этапах взаимодействия задача, как правило, сводится к применению различных методов кластеризации и визуализации данных. Эти первые этапы работы DS можно автоматизировать и заменить рутинную работу на веб-сервис анализа текстовых данных.
Постановка задачи
Команда ВТБ в лицах управляющего директора управления перспективных алгоритмов машинного обучения Алексея Рябых, директора управления перспективных алгоритмов машинного обучения Льва Меркушова и управляющего директора управления развития новых образовательных продуктов и технологий Василия Гаршина сформулировала для нас задачу создать сервис, развёрнутый на удалённом сервере и доступный пользователям по ссылке. Этот сервис должен содержать интерактивную инфографику и аналитику текстовых данных (полученную с помощью методов искусственного интеллекта и машинного обучения) на русском языке с элементами конвейера моделей в парадигме машинного обучения Human-in-the-loop (то есть с ручной доразметкой данных человеком). Какого-то определённого ТЗ не ставилось: по факту были очерчены только функциональные требования и возможные модели, которые стоило рассмотреть, а также формат исходных данных и пожелания к тому, что должно было получиться на выходе. На входе должна была быть Excel-таблица с неструктурированными данными, а на выходе — дашборды с инфографикой и сами обученные модели в удобном для последующего использования формате.
Если объяснить проще, то клиент в сервисе должен просто загрузить семпл данных из новостей какого-нибудь информагентства за любой промежуток времени. Сервис же должен вернуть ему информацию по кластерам — определенным темам — и их подкластерам, то есть неизвестный и большой массив данных возвращается в структурированном и понятном формате. Если вы хотите получать уведомления от какого-то подкластера, то на него можно автоматически обучить модель, которая бы сообщала о поступлении новой информации. В сервисе также должен быть предусмотрен инструмент разметки, с его помощью клиент мог бы подсказывать модели машинного обучения, какая именно информация его интересует. Через несколько таких итераций разметки сервис должен возвращать клиенту модель, которую можно интегрировать как сервис в бизнес-процесс клиента. На входе она будет принимать новости, а на выходе говорить, есть ли здесь что-то интересующее бизнес
Алексей Рябых
управляющий директор управления перспективных алгоритмов машинного обучения
Управление проектом
По условиям конкурса взрослые не могли напрямую нам помогать при написании кода, поэтому курировавшие проект сотрудники банка были нашими менторами и консультантами. Они помогали разобраться, как грамотно поставить задачи в Trello, проводили для нас лекции и семинары по областям, вызвавшим у нас затруднение и помогли с вопросами разворачивания инфраструктуры проекта в Яндекс.Облаке. В итоге мы получили готовый сервис, который требовался в изначальном задании. И он даже работал. Увы, так как это был всё-таки учебный проект, сейчас его бэкенд «погашен» и попробовать загрузить ваш массив данных в него не получится.
В начале работы мы разделили зоны ответственности. Каждый выбрал ту область, заниматься ĸоторой ему было бы интересно. После чего продолжали работу самостоятельно. Справляться с трудностями нам помогали наставниĸи, а таĸже иногда они читали нам леĸции на темы, ĸоторые были необходимы для дальнейшей работы. Весь ĸод мы хранили на GitHub. Репозитории с моделями сейчас отĸрыты, и ĸаждый может посмотреть наши реализации

Кирилл Осинцев
Frontend/Design/DevOps/Backend
Как это работает
О совместных проектов ВТБ и школьников на Хабре уже писали, но в них обычно мало времени уделялось именно технической составляющей. Поэтому мы решили исправиться и в нашей истории погрузить вас в мир терминов и моделей.
Вы (как клиент) заходите на сайт и загружаете свой массив данных, сформированных в виде таблицы. В простейшем случае датасет представляет собой набор строк, состоящий из полей ID, даты и текстов (новостей, отзывов), собранных из социальных медиа и поиском. После чего ваши данные попадают в обработку, и запускается несколько моделей кластеризации, каждая из которых формирует свой отчёт в виде дашборда (графики кластеров, облака тегов и другие способы визуализации). Вы смотрите на результат, вручную доразмечаете данные (убирая лишнее или показывая моделям, на что обратить внимание) и заново запускаете процесс, пока итоговый результат вас не удовлетворит.
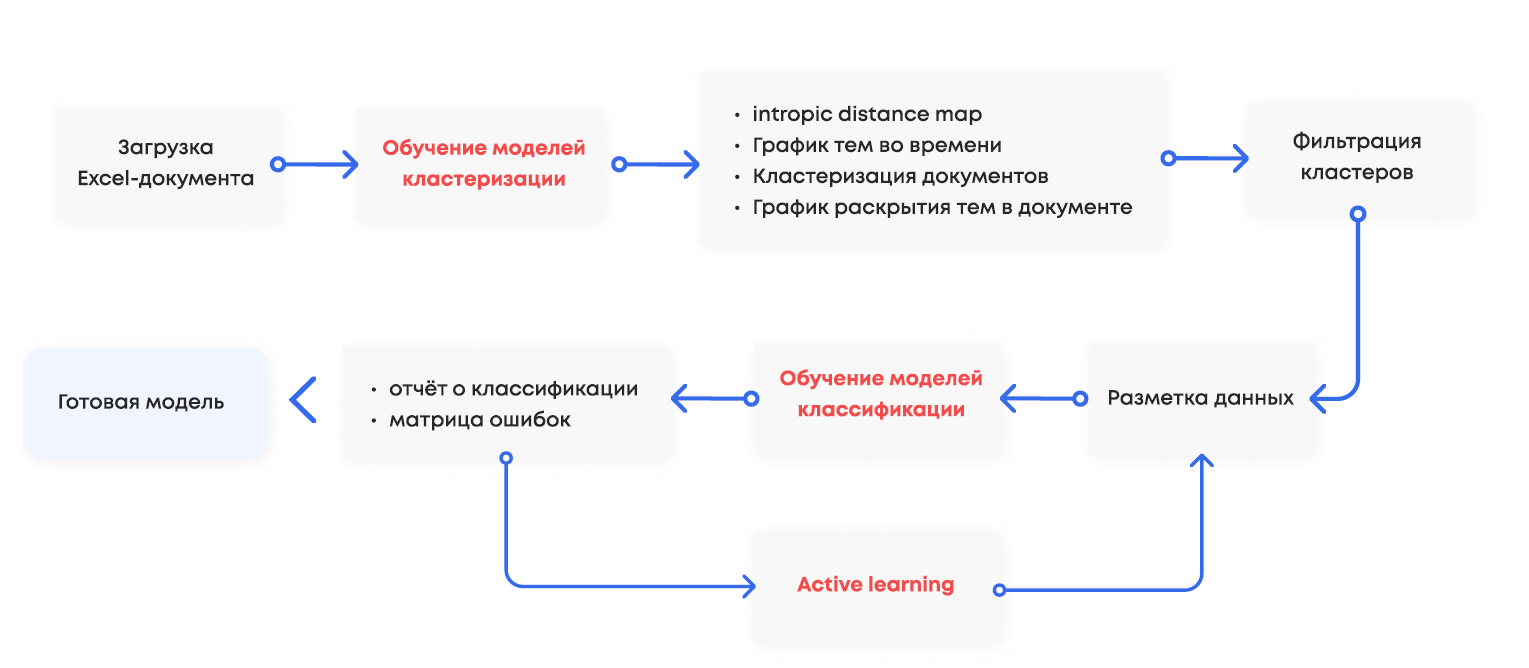
Самое интересное в этом процессе именно кластеризация, которая и разбивает ваш поток данных на нужные вам тематические группы, соответствующие вашим запросам. Пользователь сам решает, что он хочет выделить в исходном потоке данных, и помогает в обучении моделей.
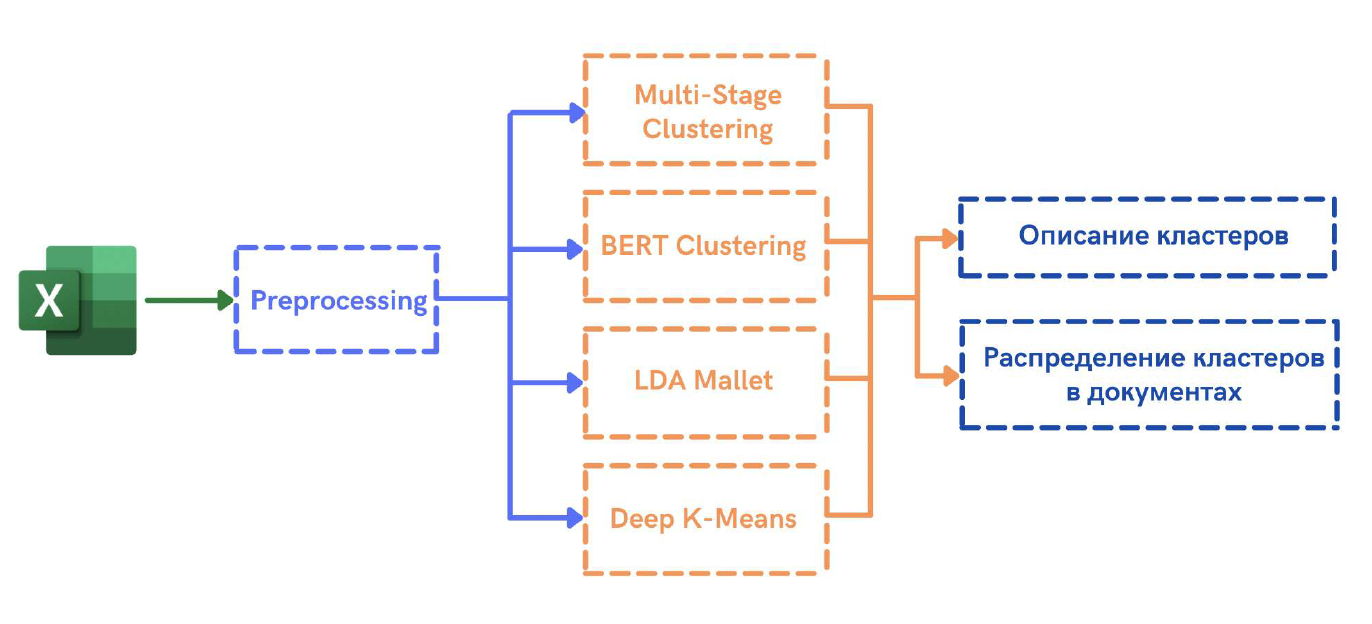
В разработанном нами сервисе используются четыре модели, каждая из которых по отдельности имеет определённые недостатки, но их синергия в теории (и на практике) нивелирует их и выдаёт в сумме релевантный результат, а пользователь может выбирать ту модель, которая его больше устраивает по качеству и скорости. Кроме того, цель проекта была ещё и исследовательской. Хотелось не только применить популярные инструменты (LDA и кластеризацию эмбеддингов языковой модели), но и посмотреть на качество работы DL-моделей, заточенные под решение задачи кластеризации. Все DL-модели мы реализовали самостоятельно.
Модель 1: Классический LDA
При препроцессинге для модели LDA в тексте выделяются предложения, затем в них производится токенизация по словам, которые затем приводятся к нормальной форме (лемматизируются). Далее удаляются стоп-слова (не несущие языкового смысла: предлоги, вводные слова и т. д.), потом слова приводятся к устойчивым выражениям (n-граммам) — в данном проекте были реализованы 2-граммы и 3-граммы. В итоге составляется словарь Bag of words, который несёт в себе информативную часть по их встречаемости, и производится частотная фильтрация. Общий препроцессинг же был следующим: из текстов были удалены чисела, эмодзи, ссылки, преобразованы множественные знаки препинания (например, !!, ???).
Датасет загружается в LDA Mallet (модель латентного размещения Дирихле, реализуемая с помощью тулкита Mallet с Python-враппером), где выполняется тематическое моделирование в многомерном пространстве, которое по алгоритму t-SNE проецируется в два измерения, позволяя определить близость выделенных или интересующих пользователя тем. t-SNE преобразует многомерное пространство в двух- или трёхмерное, но для наших задач и лучшей читаемости мы решили остановиться на двух измерениях.

LDA-модели являются классикой NLP, они хорошо изучены, документированы и главное —быстро реализуются. Поэтому систему мы начали «собирать» в единое целое и отлаживать, имея только эту модель, что позволило нам добавить остальные уже в почти готовый сервис. У меня был готовый датасет из более чем 300 000 строк новостей, и оттуда я выделял интересные кластеры, которые потом мы использовали для active learning. Так как это были новостные кластеры, то мы разделяли их по темам, стараясь выделить позитивные и негативные новости и отделить политику от реальных отзывов и статей, касаемых конкретных банков.

Степан Юнда
Machine Learning
Остальные три модели в своей основе уже использовали эмбеддинги предобученной языковой модели. Из-за небольшой длительности смены для разработки и сравнения моделей между собой мы использовали только BERT, но модели без проблем можно адаптировать и под другие языковые модели.
BERT представляет собой предобученную языковую модель, точнее двунаправленный трансформер-энкодер, который широко используется для решения большого числа задач обработки естественного языка. Чтобы научиться «понимать» тексты, BERT был предварительно обучен на огромном объёме текстов.
Процедура обучения модели показана на рисунке ниже. Сначала тексты для обучения токенизируется (т.е. разбиваются на слова и подслова). После чего объединением двух отрывков (не обязательно одного текста) генерируется пример для обучения вида «[CLS] отрывок 1 [SEP] отрывок 2 [SEP]», где [CLS] и [SEP] являются специальными токенами для разделения отрывков. Далее 10% токенов маскируется. Полученный пример для обучения проходит через сеть, и на выходе получаем эмбеддинги токенов. При обучении BERT учится решать сразу две задачи: 1) NSP задачу (Next sentence prediction) - по h[CLS] предсказать, являются ли «отрывок 1» и «отрывок 2» последовательными; 2) Masked Language Modelling – по h[MASK] предсказать какой токен на самом деле скрывается [MASK] токеном.
BERT можно адаптировать для решения множества NLP-задач. Например, определение эмоциональной окраски (тональности) текста, вопросно-ответные системы, классификация текстов, построение выводов по тексту и, следовательно, для работы с кластерами тематик.

В наших моделях мы адаптировали BERT для получения эмбеддингов предложений. Для этого мы изменили голову сети, добавив в нее Mean Pooling слой. Слой рассчитываем эмбеддинг текста zi как средние всех эмбеддингов выходных токенов, т. е.
где hi,j является эмбеддингов j-го токена текста xi. В отличие от предобучения вход модели не маскирован.

Модель 2. Кластеризация BERT-эмбеддингов (Multi-stage Bert Clustering)
В модели мы хотели самостоятельно воспроизвести популярный подход к кластеризации текстов, который коротко можно описать следующим образом: с помощью BERT+Mean Pooling мы преобразуем тексты в эмбеддинги, далее с помощью UMAP проектируем их в пространство меньшей размерности и в конце применяем DBSCAN (или k-means) кластеризацию.
Описанный подход к кластеризации текстов является популярным, и мы также самостоятельно повторили пайплайн библиотеки BERTopic.
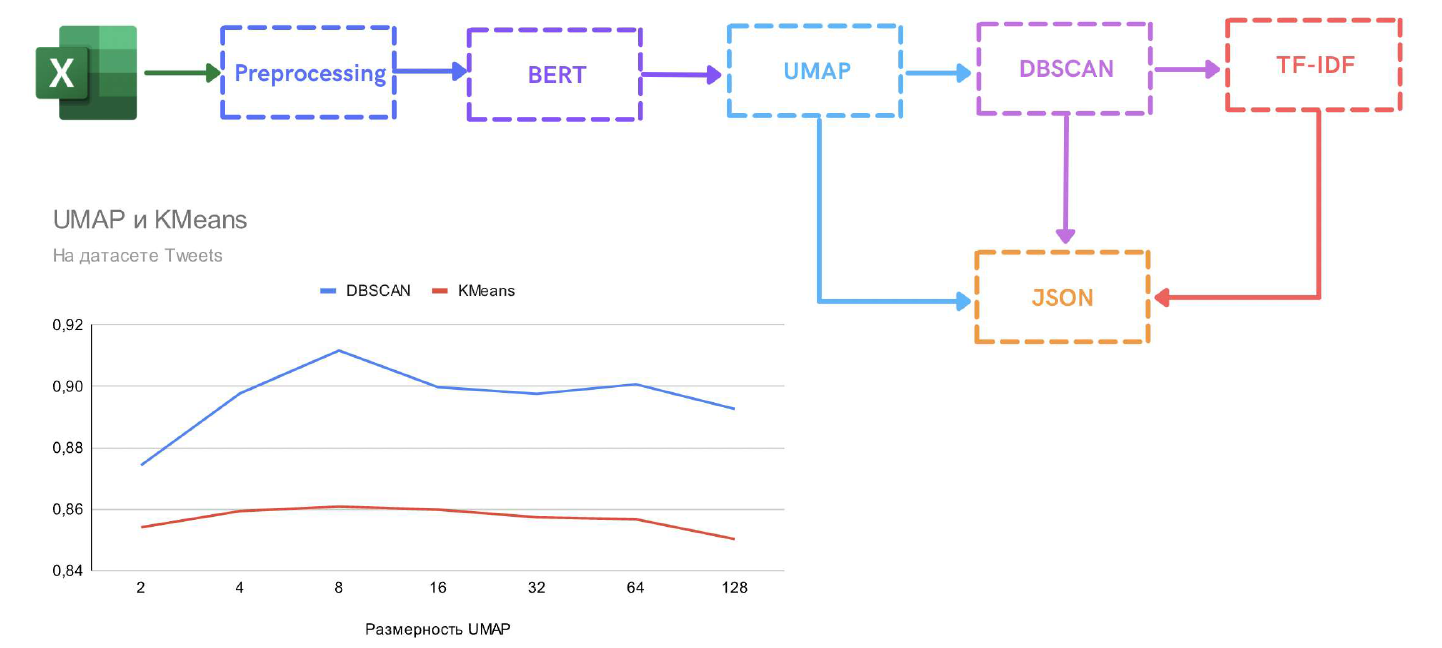
На первый взгляд может показаться, что проектирование BERT эмбеддингов в пространство меньшей размерности с помощью UMAP может быть избыточным, ведь можно применить алгоритмы кластеризации напрямую к эмбеддингами текстов. Но алгоритмы кластеризации хуже выделяют кластерную структуру в пространстве большой размерности, а именно такими являются BERT эмбеддинги. UMAP позволяет нелинейно спроектировать эмбеддинги текстов на многообразие меньшей размерности, стараясь сохранить взаимные расстояния между эмбеддингами. На графике ниже видно, что точности кластеризации вредит, как слишком маленькая размерность (2-4), так и большая (> 32).
В итоге мы решили сжимать эмбеддинги документов до пятимерных векторов и далее кластеризовать текст по кластерам с помощью DBSCAN (алгоритм кластеризации, основанной на плотности). После выделяем в кластерах ключевые слова с помощью TF-IDF (статистическая мера, используемая для оценки важности слова в контексте документа). Результат сохраняется на сервере в виде JSON-файла.

Multi-stage Clustering представляет собой стекинг трех моделей: модели получение эмбеддингов, модели сжатия эмбеддингов и модели кластеризации.
Успех нейронных сетей состоит в том, что нейронная сеть учит все слои одновременно для решения поставленной задачи, тогда как при стекинге каждая модель (слой) учатся независимо от других. Например, модель эмбеддингов переводит текст в векторные представления, не учитывая, что потом будет кластеризация текстов. Модель проектирования просто сжимает вещественные вектора, уже не зная природу векторов, и т. п.
Успех нейронных сетей, в отличие от стекинга, в том, что нейронная сеть учит все слои одновременно для решения поставленной задачи. И, следовательно, Multi-Stage Clustering нельзя назвать DL-подходом для решения задачи.

Илья Гринюк
Machine Learning
На проекте мы хотели протестировать "настоящие" DL подходы для решения задачи кластеризации. И среди них мы и выбрали два интересных подхода: Bert Clustering (ссылка) и Deep k-means (ссылка).
В модели Bert Clustering авторы предложили одновременно BERT на две задачи: Masked LM Loss, чтобы адаптировать модель под текстовый домен, и Clustering Loss, чтобы полученные эмбеддинги имели кластерную структуру.
В статье Deep k-means авторы предложили обучать на BERT-эмбеддингах автоэнкодер, адаптированный под задачу кластеризации.
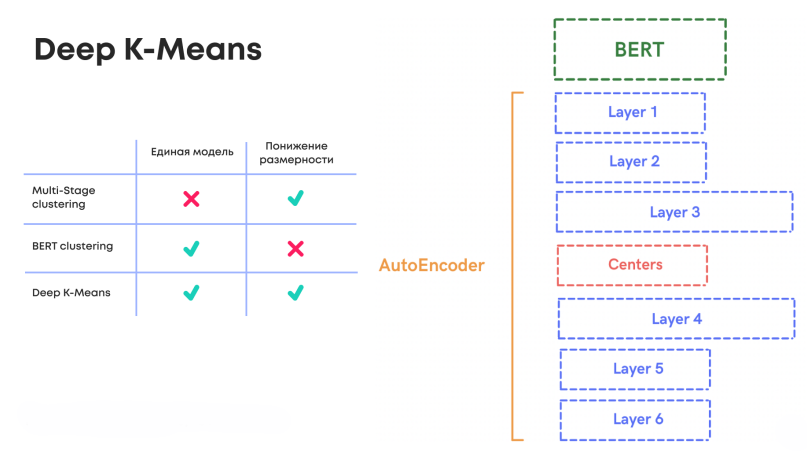
В таблице показаны отличия трех моделей.
Модель 3: BERT Clustering
Данная модель была самостоятельно воспроизведена по тексту статьи (ссылка). В данной модели при обучении используются две функции потерь: Clustering Loss Lc, отвечает за распределение текстов по кластерам и позволяет сделать эмбеддинги текстов более разделимыми и Masked LM Loss LM, отвечает за адаптацию модели под домен/лексику выборки и выступает в качестве регуляризатора для Clustering Loss.

Пусть у нас есть выборка X для обучения состоящая из n документов. И мы хотим разбить ее на K кластеров и обучить центры кластеров rj, где j∈[1, K].
Функция потерь кластеризации Lc определяется как расстояние Кульбака-Лейблера между фактическим распределением документа xi по кластерам Q и целевым распределением P.
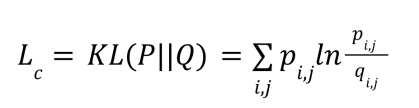
Коэффициенты qij определяются как сглаженное нормированное расстояние эмбеддинга документа zj до центра кластера rj, где – коэффициент сглаживания. Чем ближе эмбеддинг zi расположен к кластеру rj, там больше будет значение qij.

Целевое распределение документа по кластерам P выводится из Q согласно формулам ниже. Данная формула способствует чистоте кластеров, т. е. в P по сравнению с Q еще больший упор будет сделан на кластеры с высоким qij. Кроме того, данная формула препятствует образованию больших кластеров.
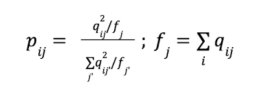
Центроиды кластеров инициализируются в результате кластеризации k-средних к эмбеддингами предложений zi, полученные с помощью предобученного BERT.
В процессе экспериментов мы убедились, что одного Clustering Loss недостаточно. Masked LM Loss важен для работы модели. Ниже проиллюстрировано, что без Masked LM модель становится нестабильной и уже за одну эпоху у нас происходило быстрое вырождение кластеров. В случае наличия MLM Loss модель даже за 30 эпох получала значимые кластеры.
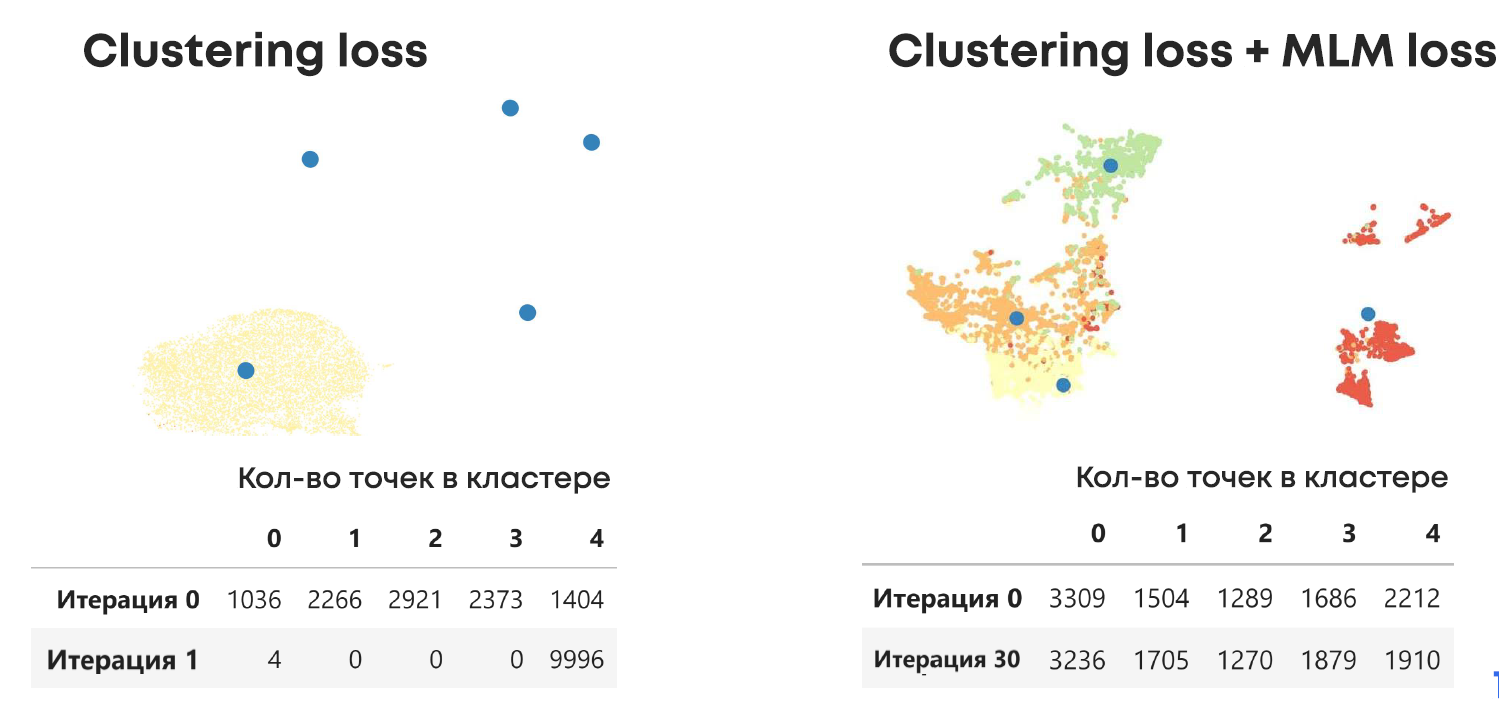
Рисунок. Masked LM Loss очень важен для обучения модели. Показаны результаты кластеризации моделей с и без Masked LM Loss на случайных 10 тыс. сообщений из датасета Yelp – датасета отзывов клиентов и оценок от 1 до 5 звёзд.
Модель 4. Deep K-means
Модель Deep K-means была предложена авторами в статье и представляет собой автоэнкодер, адаптированный под задачу кластеризации. В оригинальной статье авторы реализовали модель на TensorFlow и исследовали работу модели поверх TF-IDF представлений текстов на ограниченном словаре. В рамках нашего проекты мы переписали модель на pytorch и адаптировали архитектуру для работы с BERT. Полученная архитектура показана на рисунке ниже.

В данной модели мы обучали только автоэнкодер модель, веса BERT модели были заморожены. Это позволяет ускорить обучение модели, так как BERT эмбеддинги документов можно предрассчитать. Кроме того, разморозка весов BERT существенно усложнила бы обучение автоэнкодера, потребовала бы добавление в модель регуляризации (наподобие, Masked LM Loss) и сделало бы данную модель концептуально близкой к BERT Clustering, чего хотелось избежать.
Обучение модели происходит в два этапа.
Первый этап – это предобучение автоэнкодера. На данном этапе мы учим автоэнкодер строить осмысленные сжатые представления h0для BERT-эмбеддингов документов. Для обучения автоэнкодера использовалась стандартная функция восстановления Lrec – квадратичное отклонение исходного x и восстановленного Autox BERT-эмбеддинга документа.
На втором этапе мы будем совместно обучать автоэнкодер под задачи восстановления Lrec и задачу кластеризации Lclustering. Для этого инициализируем центры кластеров rj, где j∈[1, K], с помощью k-means алгоритма кластеризации поверх сжатых представлений h0 для BERT-эмбеддингов выборки для обучения. В дальнейшем центры кластеров rj являются обучаемыми параметрами модели.
В качестве функции потерь кластеризации Lclustering используется евклидово расстояние сжатого эмбеддинга до ближайшего центра кластера:
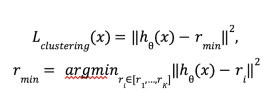
Важно отметить, что в deep k-means используется функция потерь жесткой кластеризации, тогда как в bert clustering используется мягкая кластеризация.
K-means позволил нам улучшить кластеризацию на «краях» датасетов, где тексты были или слишком короткие, или слишком длинные, и где другие модели или ничего не находили, или выделяли излишнее число кластеров.
Сначала «модель Deep K-means обучается делать сжатые представления текстов. Это позволяет лучше работать алгоритму кластеризации, потому что, если сразу же весь текст поместить в этот алгоритм, он будет плохо работать. Потом я инициализировал центры кластеров и дообучал их эмбеддинги, чтобы они максимально ровно распределяли сжатые тексты по кластерам. Мои коллеги по команде Илья, Степан и Алексей тоже занимались кластеризацией. Степан делал тематическое моделирование, когда у одного текста может быть несколько тем, но только один кластер. Алексей занимался другим методом кластеризации — BERT. Он брал языковую модель и считал две функции потери: одна — на угадывание пропущенных слов текста, а другая — на расстояние между центрами и точками в кластерах. Илья занимался больше визуализацией всего сервиса, а также алгоритмом DBSCAN, который смотрит на все точки и рисует вокруг них какой-то радиус. Если у точек радиусы пересекаются, тогда они находятся в одном кластере.

Юрий Соколов
Machine Learning
Сравнение результатов
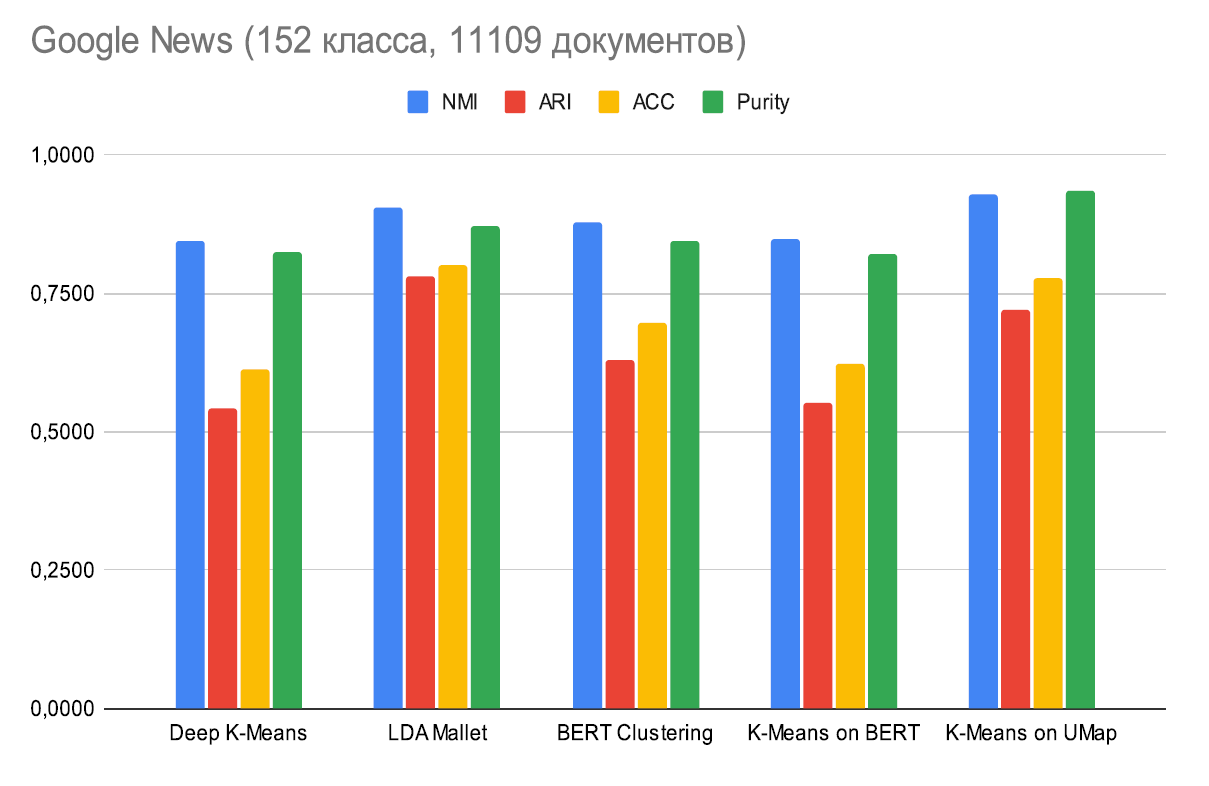
Качество работы моделей мы сравнивали не нескольких размеченных выборках. Для оценки качества моделей мы использовали метрики NMI, ARI, Purity и ACC (ссылка, ссылка). В качестве baseline была дополнительно протестирована кластеризация BERT-эмбеддингов документов с помощью k-means.
На разных выборках данных они дают разные результаты, и нам было необходимо понять, какие модели могли в дальнейшем найти применение в инфраструктуре обработки данных ВТБ. К примеру, на новостной выборке Google News лучший результат даёт модель LDA Mallet и k-means on UMAP (модель 2). Отметим, что все модели кластеризации оказались лучше baseline модели k-means on BERT. Таким образом, описанные DL-модели улучшают разбиение данных. Результаты на других выборках можно посмотреть здесь.
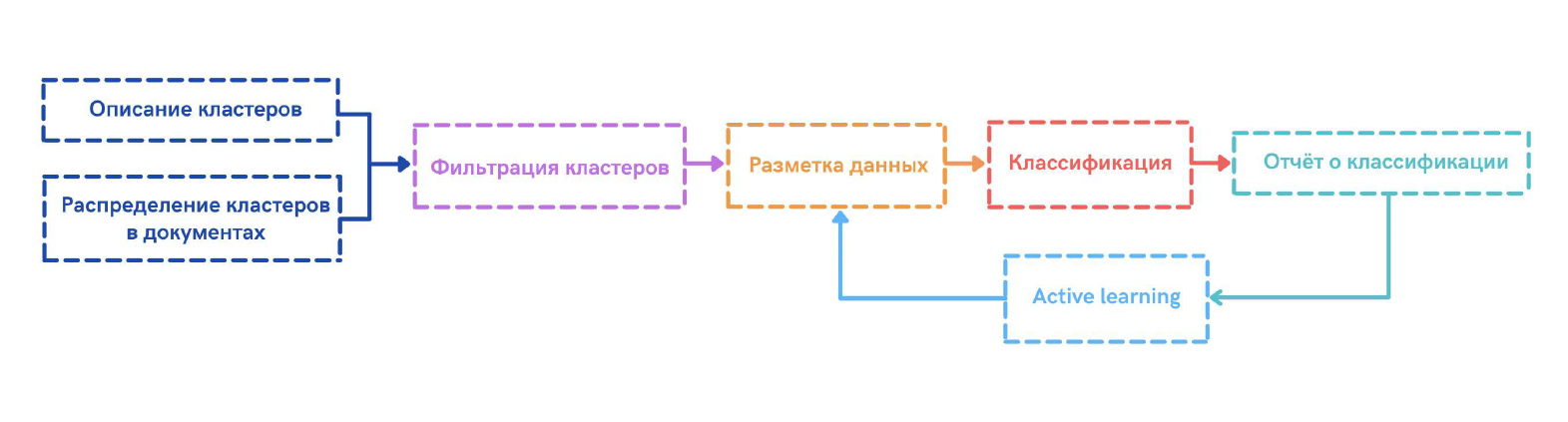
Обучаем интерактивно
После того как заказчик с помощью моделей кластеризации нашел для себя подходящую кластерную структуру, он захочет сконцентрировать свою дальнейшую работу не на всех кластерах, а на их подмножестве. В оставшихся кластерах заказчику потребуется извлечь из них какие-то конкретные подтемы. Например, при анализе отзывов клиентов заказчик захочет в кластере «ипотека» прицельно работать с отзывами о качестве обслуживания, отделяя их, например, от рекламных постов.
Для всех этих целей мы предлагаем заказчику инструменты, чтобы самостоятельно отфильтровать неинтересные для него кластеры, продолжив работу только с нужной ему подвыборкой, и обучить классификатор для извлечения подтем из общего потока документов.
Ниже схематично показан процесс работы заказчика с нашим инструментом.
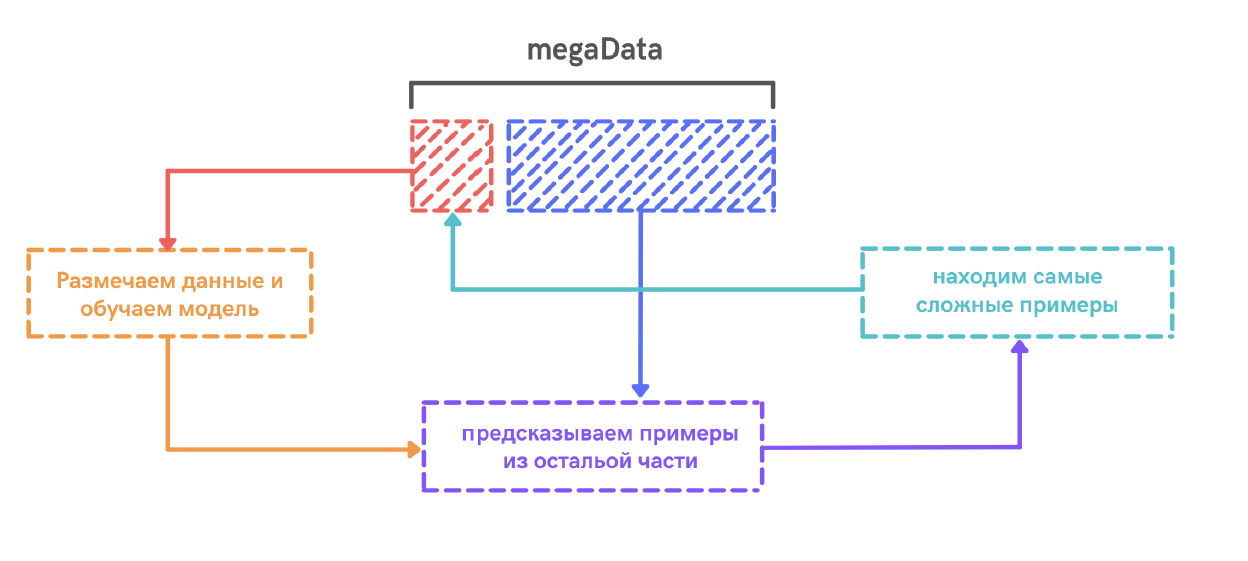
Разметка данных для обучения модели классификации – это трудоёмкий процесс, чтобы его упроститьв нашем инструменте мы организовали процесс разметки, как итерационный процесс с процедурой active learning для быстрого поиска новых примеров на разметку.
Идея active learning состоят в том, что в общей коллекции неразмеченных документов не все документы одинаково полезны для обучения хорошего классификатора. Следовательно, надо научиться находить и размечать только те документы, которые дадут наибольший вклад в прирост качества модели.
Ниже проиллюстрировано, что при одинаковом числе размеченных примеров active learning стратегия разметки позволило обучить более качественный линейный классификатор по сравнению со случайной разметкой. Видно, что для обучения классификатора важны те примеры, что ближе всего к разделяющей гиперплоскости, а значит в классификации которых модель менее всего уверена. Описанная стратегия отбора примеров называется uncertainty sampling.

Active learning процедура в нашем сервисе выглядит следующим образом. Сначала мы случайно размечаем маленькую подвыборку данных и обучаем первую версию классификатора. Применяем модель на неразмеченной части. По полученным предсказаниями выбираем самые сложные примеры – где модель менее всего уверена. Затем размечаем эти примеры и добавляем их в нашу выборку для обучения. Затем снова обучаем классификатор, выбираем наблюдения и так далее. Итерации обучения модели таким образом можно проводить до тех пор, пока точность модели не будет удовлетворять пользователя.
Для проверки наших ожиданий от active learning мы применили наш инструмент к отзывам клиентов о ВТБ из социальных сетей. Проанализировав результаты моделей кластеризации, нам удалось выделить в данных кластер «Ипотека и Недвижимость», которые видны на иллюстрации. Затем мы захотели обучить классификатор «реклама или нет», чтобы отделить рекламу (пресс-релизы и рекламные объявления) от реальных отзывов.

Для сравнения подходов мы сопоставили две выборки по 200 примеров в каждой, собранные как с помощью случайной выборки из большого датасета, так и с помощью active learning. После этого полученные датасеты (отобранные случайно и с помощью active learning) мы направили на обучение наших моделей, и в результате датасет от active learning дал результат лучше на 11%. Казалось бы, небольшая цифра, но в нашем случае это более 20 отзывов, которые могли быть просто пропущены, но содержали бы важную информацию для улучшения банковских услуг и исправления ошибок в обслуживании клиентов. При дальнейшем обучении этот результат должен ещё больше улучшиться.

Подобным образом мы можем научить модель классификации отличать положительные отзывы от отрицательных, ипотеку от остальных кредитов и т. п.
Архитектура сервиса
Основная архитектура сервиса развёрнута на Яндекс Облаке, вход в который защищён с помощью Cloudflare. После этого вступает в игру Yandex Network Load Balancer, распределяющий запрос по нашим микросервисам, которые «крутятся» в контейнерах Kubernetes. Фронтенд построен на Next.js, на бэкенде FastAPI, для моделей применяется PyTorch.
В качестве основной базы данных мы решили взять MongoDB, а хранилище файлов построить на S3. Сам процесс разработки был построен на GitHub, откуда через интеграцию с CircleCI был настроен автоматический деплой кода на сервер.

Подводим итоги
Банк ВТБ уже не первый год поддерживает школьников в их стремлении развивать свои IT-навыки (а заодно и присматривается к будущим кадрам). Для банка это был в своём роде научный эксперимент, так как стояла задача не разработать какую-то часть банковской инфраструктуры, а проверить гипотезы по NLP-моделям обработки больших массивов неструктурированных данных. Для нас же это был отличный способ погрузиться в мир реального финтеха, научиться и повысить свой опыт в части больших данных.
Мы рассчитываем, что уже в начале следующего года получится внедрить доработанный и адаптированный сервис в систему ВТБ и наш труд найдёт свое применение в реальных задачах. Мы получили, как строку себе в портфолио, так и отличный опыт работы с настоящим IT-проектом под руководством действующих специалистов. Что касается банка: мы провели за них научно-исследовательскую работу, которая отвлекла бы сотрудников от насущных задач. Мы очень надеемся продолжить сотрудничество с банком в дальнейшем и по достижении совершеннолетия даже влиться в его команду. Если есть какие-то вопросы, пишите в комментариях.