
Представляю в блоге ЛАНИТ вторую часть моего пересказа статьи “A Survey of Transformers”, в которой приведены основные модификации архитектуры стандартного трансформера, придуманные за два года после ее появления. В первой части мы кратко вспомнили, из каких основных элементов и принципов состоит трансформер, и прошлись по различным схемам, меняющим или дополняющим механизм многоголового внимания. Целью большинства этих схем являлось преодоление квадратичной зависимости сложности вычислений от длины последовательности токенов, подающихся на вход. В этой части мы коснемся модификаций других элементов архитектуры, которые уже направлены или на улучшение способности сети извлекать больше информации из токенов, или применяются на большую длину последовательности, разделяя ее на сегменты.

Позиционные эмбеддинги
В обычном трансформере используются позиционные эмбеддинги на основе sin и cos как функций от позиции токена (t) и от позиции числа внутри вектора эмбеддинга (i):

Другой расхожий подход для кодирования позиций токенов - обучаемые эмбеддинги. Существует и комбинация этих подходов (Wang et al. https://openreview.net/forum?id=onxoVA9FxMw), при котором предлагается использовать тригонометрический функции, но ωi учить, а не задавать самостоятельно. Также авторы указывают на возможную проблему с утерей информации о позициях токенов на верхних слоях, для чего во многих работах эти эмбеддинги добавляются на всех слоях.
Относительные позиционные эмбеддинги
Отдельная ветка работ посвящена замене абсолютных позиционных эмбеддигов относительными, обосновывая это тем, что знание токенов об относительной позиции друг друга важнее, чем знание абсолютных позиций.
Так Shaw et al. (https://aclanthology.org/N18-2074/) предлагают добавлять обучаемые относительные эмбеддинги к ключам. Понятно, что таких относительных эмбеддингов будет l2 где l - длина последовательности, поэтому предлагается ограничивать применение таковых расстоянием между токенами равным K:
для
Здесь rij - эмбеддинг относительного положения токенов i и j.
В трансформере InDIGO K=3 https://transacl.org/ojs/index.php/tacl/article/view/1732). В Music Transformer (https://openreview.net/forum?id=rJe4ShAcF7) проведена некоторая работа по уменьшению нагрузки на памяти этого механизма. В T5 (https://arxiv.org/abs/1910.10683) этот алгоритм немного упрощен - в нем rij является числом, а не вектором. Авторы Transformer-XL (https://aclanthology.org/P19-1285/) оставили обычные позиционные эмбеддинги, но используют их для расчета матрицы внимания:
Здесь R как раз и является обычной матрицей позиционных эмбеддингов, а u1;u2 обучаемые векторы размерности ключей/запросов.
В DeBERTa (https://arxiv.org/abs/2006.03654) авторы считают позиционные эмбеддинги схожим с Shaw et al. (https://aclanthology.org/N18-2074/) образом, но применяют как в Transformer-XL:
Отдельная интересная концепция реализована в TUPE (Transformer with Untied positional encoding: https://arxiv.org/abs/2006.15595). В нем предлагается для расчета весов внимания брать позиционные эмбеддинги напрямую и также скалярно перемножать их преобразованные к своим собственным ключам/запросам, как мы это делаем с эмбеддингами токенов, но через отдельные матрицы:

Также еще предлагается добавлять обучаемое число относительного положения токенов bj-i
Авторы Roformer (https://arxiv.org/abs/2104.09864) выдумали еще более изощренный способ кодирования положения токенов: они вводят обучаемые параметры углов поворота пар координат. Так, на mθ1 поворачивают первые две координаты, а на mθ2 - вторые две и т.д. Получается d/2 углов поворота. А m - это номер токена. Для d=2 авторы приводят следующую визуализацию:
)")
Эта операция соответствует умножению ключей и запросов на матрицу R:
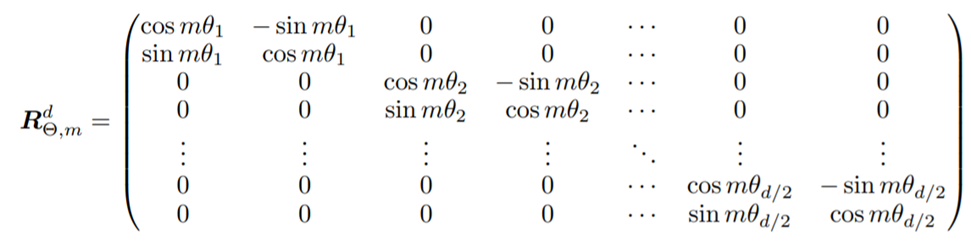
Если при чтении у вас возник резонный вопрос, а почему бы не кодировать эмбеддинги другой сеткой, которая умеет учитывать последовательность токенов, то спешу вас порадовать: и такое есть - реализовано, например, в R-Transformer (https://arxiv.org/abs/1907.05572) через RNN, которые, пробегаясь по последовательности, дают эмбеддинги, которые далее уже подаются на вход трансформеру. Важно понимать, что если пропустить последовательность через обычную RNN, то, во-первых, рано или поздно она все-таки начнет забывать первые токены, а во-вторых, первые токены будут нести скудную информацию. Частично это решается через двунаправленную RNN, но авторы пошли по другому пути: local RNN. Они паддят (дополняют) последовательность каким-то количеством специальных токенов и используют RNN в окне, доставая лишь результат применения последней ячейки.
Теперь уже возникает резонный вопрос: “А почему бы не через свертки?” И тут уже люди постарались и сделали Conditional Position Encoding (https://arxiv.org/abs/2102.10882). Авторы получают эмбеддинги для Vision Transformer, прогоняя сверточную сеть по изначальному изображению, а потом уже формируя из этого токены.

Нормализация
Не обошли исследователи и вопрос нормализации. В первую очередь в обзорной статье рассматриваются работы по переносу layer нормализации в рамках архитектуры в другое место. Так, обычное положение этого элемента архитектуры - между residual блоками, обозначаемое как post-LN, предлагается заменить pre-LN, при котором она находится внутри residual-блока перед многоголовым вниманием и перед позиционным полносвязным слоем.

Замечают, что концепция post-LN требует тонкой игры со скоростью обучения (learning rate) в начале обучения, но, с другой стороны, после того, как обучение стабилизируется, обгоняет pre-LN по метрикам. Liu et al. считают, что проблема в нестабильном обучении post-LN заключается в большой зависимости от residual-слоев в начале, и они предлагают специальный подход Admin (Adaptive model initialization) для стабилизации обучения на ранних стадиях.
Предлагаются и различные замены layer-нормализации. Так, Xu et al. (https://proceedings.neurips.cc/paper/2019/hash/2f4fe03d77724a7217006e5d16728874-Abstract.html) указывают на то, что обучаемые параметры нормализации не обучаются как нужно и предлагают вместо них использовать гиперпараметры, нормализируя по следующим формулам:
где C,k - гиперпарметры. μ, σ - соответственно среднее и стандартное отклонение x.
Nguyen и Salazar (https://arxiv.org/abs/1910.05895) предлагают вообще заменить нормализацию через среднее и стандартное отклонение делением на l2 норму и умножением на обучаемый параметр (g):
Многие задаются вопросом, почему в трансформерах используется Layer-нормализация, а не более распространенная нормализация по батчам. Авторы обзора приводят статью Shen et al., в которой обсуждается, почему нормализация по батчам плохо работает в трансформерах на текстовых данных, и приходят к ответу, что это из-за нестабильности статистик в рамках батча. Они предлагают PowerNorm:
В их подходе нормировка происходит на экспоненциально взвешенное скользящее квадратичное среднее.
γ; β - обучаемые параметры, как и в обычной батч-нормализации.
Авторы ReZero (https://arxiv.org/abs/2003.04887) решили, что нет нормализации - нет проблем, и просто вокруг каждого слоя делают обучаемую residual-связку.
Позиционная полносвязная сетка
В этой части архитектуры основная часть экспериментов затрагивает функции активации вместо ReLU. Различные авторы пробовали swish (x*sigmoid(β*x)), GELU (gaussian error linear unit), GLU (gate linear unit).
Некоторые авторы пытаются заменить полносвязную сетку на другой слой. Так Lample et al. (https://proceedings.neurips.cc/paper/2019/hash/9d8df73a3cfbf3c5b47bc9b50f214aff-Abstract.html) вводят механизм под названием Learnable product key memories, напоминающий внутреннее внимание, работа которого построена следующим образом.
При помощи отдельного слоя (полносвязного + батч нормализация) получаем запросы (query).
Откуда-то берем ключи и значения (полагаю, тоже полносвязным слоем аналогично работе внутреннего внимания).
Выбираем top-k ключей для каждого запроса по скалярному произведению (при этом векторы ключей делятся пополам по принципу product quantization для масштабирования/ускорения).
Получаем веса аналогично внутреннему вниманию через softmax от скалярного произведения запросов и ключей из top-k.
Суммируем для каждого запроса результат.
Другие же предпринимают попытки заменить FFN на mixture of experts. Организован этот слой следующим образом.
 для каждого токена")
Каждый эксперт при этом представляет собой отдельный полносвязный слой или слои, а gating network - обучаемую нейросеть, которая учится взвешивать ответы экспертов, выбирая из них некоторый топ. Для обучения вводится дополнительная функция ошибки, которая способствует выбору разнообразных экспертов. Различия в реализациях касаются, например, того, как и сколько выбирать экспертов. Авторы Gshard (https://arxiv.org/abs/2006.16668) выбирают двух, в Switch Transformer (https://arxiv.org/abs/2101.03961) - одного, а Yang et al. (https://arxiv.org/abs/2105.15082) предлагают делить экспертов на группы и выбирать топ-1 из каждой группы.
Наконец, у некоторых авторов возникли идеи вообще убрать FFN слой, что, как утверждается, не драматически сказывается на результате.
Общие архитектурные изменения
Много освещаемых в обзоре работ меняют не конкретный элемент архитектуры, а парадигму работы или же дополняют ее. Авторы обзора в первую очередь приводят работы, нацеленные на снижение числа параметров.
В Lite Transformer (https://openreview.net/forum?id=ByeMPlHKPH) авторы предлагают делить эмбеддинги токенов пополам (именно эмбеддинг, а не последовательность) и одну половину отправлять в обычное многоголовое внимание в глобальной разреженной реализации для отслеживания дальних взаимодействий между токенами. Вторую же часть - отправлять на сверточные слои для установления локальных взаимодействий.


В трансформере DeLight (https://arxiv.org/abs/2008.00623) вместо блока трансформера ставят DeLight-блок из трех составляющих: специальная DeLight-трансформация с увеличением размерности эмбеддингов (как в position-wise FFN), одна self-attention-голова, position-wise FFN с уменьшением размерности. Получившуюся сеть можно строить значительно глубже обычного трансформера при том же числе параметров.
Усиление связи между блоками
Авторы Transparent Attention (https://aclanthology.org/D18-1338/) предлагают вместо того, чтобы подавать в специальный cross-блок внимания декодера выход только с последнего слоя энкодера, формировать взвешенную сумму выходов всех слоев. Веса для каждого слоя при этом являются обучающимися. В Feedback Transformer (https://openreview.net/forum?id=OCm0rwa1lx1) указывают на проблему, что в авторегрессионном режиме, при котором добавляется по одному новому токену в последовательность, каждый слой получает информацию о предыдущих токенах только с нижних слоев, хотя для этих токенов присутствует информация на всех слоях. Авторы этого трансформера предлагают взвешивать результат со всех слоев также с помощью обучаемых весов.
Разделяй и властвуй
Некоторые авторы иным образом подходят к решению ограничений на длину последовательности. Авторы обзора обобщают эти наработки до двух подходов: рекуррентный трансформер и иерархический, и сначала описывают работы, посвященные первому.
В Transformer-XL длинный текст делят на сегменты, и выход с каждого сегмента подают на вход этой же сети при обработке следующего, и так на каждом слое:
Здесь
- эмбеддинги сегмента τ на l-1 слое, SG - функция, обозначающая непротекаемость градиента - обратное распространение не идет на предыдущий сегмент. Таким образом, эмбеддинги токенов, которые используются для расчета ключей и значений, берутся конкатенацией эмбеддингов предыдущего слоя этого сегмента и предыдущего.
В Compressive transformer (https://openreview.net/forum?id=SylKikSYDH) пошли дальше - его авторы сделали подход, при котором учитывается информация не только от предыдущего сегмента, а от всех предыдущих сегментов, используя для этого какую-либо операцию сжатия, например, пулинг или свертку. Аналогично Transformer-XL-градиент от основной функции ошибки в эту операцию не распространяется, поэтому авторы предлагают обучать свертку с помощью внутренней отдельной функции ошибки на восстановление как в автоэнкодере. В Memformer (https://arxiv.org/abs/2010.06891) информацию от предыдущих прогонов используют не в виде отдельного токена, а в кросс-внимании для расчета ключей и значений.

Yoshida et al. (https://arxiv.org/abs/2008.07027) пошли дальше и придумали, как добавлять рекуррентность для уже обученных моделей. Предлагается после прогона трансформера на одном сегменте получать некоторый эмбеддинг этого сегмента и пропускать его через многослойный перцептрон, который делает из него вектор длиной d - дополнительный токен, который вместе со следующей последовательностью попадает на вход при прогоне этой же архитектуры на следующем сегменте.


И хотя этот предобученный трансформер такого типа токенов никогда не видел, многослойный перцептрон научится делать такие эмбеддинги, которые уменьшали бы функцию ошибки. Вектор z при этом формируется как взвешенная сумма (используется софтмакс от обучаемых параметров) от выходов всех слоев.
В иерархических трансформерах, как правило, используются эмбеддинги более детальной структуры информации для формирования эмбеддингов более обобщенных. Например, Miculicich et al. (https://aclanthology.org/D18-1325/) в задаче машинного перевода предлагают агрегировать эмбеддинги предыдущих предложений, формируя по эмбеддингу на предложение, и добавлять их к последовательности для формирования пар “ключ-значение” в механизме внимания.
 для машинного перевода через нейронные сети (NMT)")
В HIBERT (https://aclanthology.org/P19-1499/) авторы предлагают прогонять сначала трансформер на предложениях, а потом эмбеддинг каждого предложения (берут <EOS> токен) через еще один трансформер. В работе Lui и Lapata (https://aclanthology.org/P19-1500/) агрегация информация с более детальных элементов (токенов) происходит за счет внутреннего внимания с глобальным обучаемым вектором запроса. В Hi-Transformer (https://arxiv.org/abs/2106.01040) авторы используют эмбеддинги предложений для того, чтобы через еще один трансформер над ними сформировать эмбеддинг документа, который подают в качестве отдельного токена в трансформер над токенами, для того чтобы получить эмбеддинги токенов с учетом информации о документе в целом.

В TENER (https://arxiv.org/abs/1911.04474) используют трансформер над символами и потом агрегируют для получения эмбеддингов слов. Наконец, подход Transformer in Transformer (https://arxiv.org/abs/2103.00112) предлагает эмбеддинги больших патчей изображений получать с использованием эмбеддингов на выходе трансформера над более маленькими патчами, составляющими большой.

Архитектура трансформера за несколько лет, прошедших со своего появления, стала использоваться почти во всех областях: обработке естественного языка, компьютерном зрении, прогнозировании временных рядов, рекомендательных системах. Каждой области присущи свои сложности, которые требовали адаптации этой архитектуры, улучшение ее производительности или уменьшение нагрузки на память. Многие из них приведены выше. И уже после выхода обзорной статьи, о которой идет речь в моем посте, появлялись новые модели, в основе которых лежит архитектура трансформера, которые привносят что-то новое: Perceiver, Retro, Swin Transformer. Они, в том числе, используют некоторые из наработок своих коллег, которые отражены в моем посте. Также, надеюсь, он поможет вам расширить сознание и выйти за пределы BERT или GPT-3 и начать использовать что-то более оптимальное.
kitaisky
Это все конечно интересно, но на практике упирается в то, какую архитектуру выберут и предобучат большие дяди, и после этого будут использовать для решения своих задач все остальные.
vladbalv Автор
не совсем согласен. многие из этих моделей есть в transformers в huggingface - их можно брать, самостоятельно обучать или дообучать. или например подсмотреть код и реализовать аналогичную архитектуру, но не из 10 слоев, а из 3, и тогда намного проще ее будет обучить
некоторые обучают маленькие берты (см. rubert-tiny) даже на google colab :)
kitaisky
Именно что "самостоятельно" обучать - основная проблема таки как раз в этом. Про дистилляцию -возможно, но таки опять же тут сетку нужно учить с нуля. Возмьжно небольшие сетки на такой архитектуре могут хорошо подходить для решения кааих-то задач, не связанных с языковым моделязыковым моделированием, гдк нужны гигантские объемы данных - я бы с удовольствием почитал о применении указанных выше архитектур к каким-нибудь табличкам, рядам и прочему.