

Исторически так сложилось, что LINQ взыскал сомнительную репутацию за его слабую производительность. LINQ медленный, аллоцирует память, сложно читается, поэтому обычно его используют как инструмент запросов к БД и то, зачастую сложные запросы легче написать на SQL. Даже на собеседованиях джунов просят не использовать LINQ в алгоритмах.
"Я знавал одного разраба, который мог написать запрос абсолютно любой сложности на LINQ, но если надо было что-либо в нём поменять, он писал всё заново" - мой тимлид из EPAM...
Но что если я скажу вам, что с .Net7 всё начнёт меняться. Если вы не были заняты последний год чисткой беклога не поднимая головы, то наверное слышали про новые фичи в .Net6 которые капитально облегчат жизнь разработчикам.
Zip() теперь может совмещать 3 коллекции, ElementAt() теперь может принимать оператор индекса "^" чтобы отсчитывать с конца коллекции, Take() теперь принимает диапазон индексов list.Take(2..6). Также появились новые методы TryGetNonEnumeratedCount(), чтобы не проходиться по коллекции для получения Count, MinBy(), MaxBy(), AvarageBy(), название которых говорит само за себя и новый метод Chunk(), дробящий коллекцию\массив на равные части.
.Net7 же берётся за классические методы и творит с ними чудеса, пока-что особое внимание получили только 4 метода:
.Min()
.Max()
.Average()
.Sum()
И раньше, чтобы выиграть несколько наносекунд на крупных проектах, люди иногда писали собственные методы, что-то на подобии такого
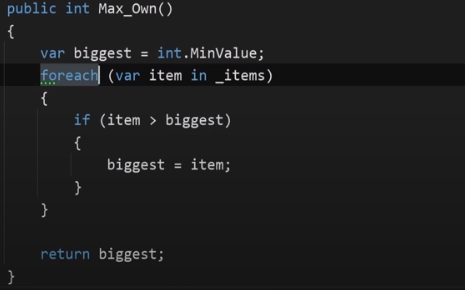
И результат был, но не капитальный. Память всё равно выделялась и написание таких методов раздувало проект.

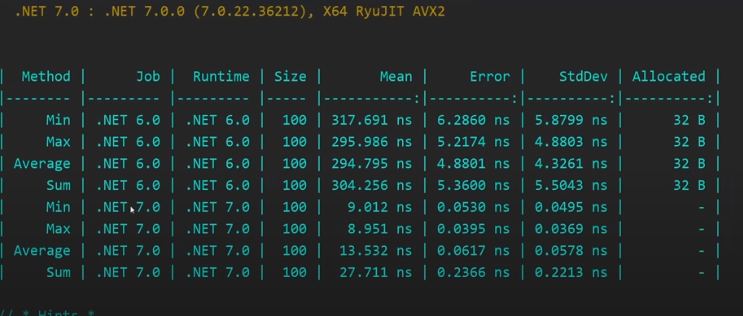
Теперь посмотрим на бенчмарк по одной дженерик коллекции но в разных версиях фреймворка. Net6 и Net7 RC1, все те методы, получившие изменения.

Если мы посмотрим на время выполнения этих методов, то глаза начинают перемещаться на лоб, такого прироста обычно вменяемые люди не ожидают, не говоря уже о том, что в данном случае и память не аллоцируется вовсе!
Надо разобраться. Быть того не может.
Берём для примера реализацию Min() из .Net6, в принципе она не менялась давно.
Для тех кто внезапно не видел реализацию этого метода, вот кодище:

Впринципе всё ожидаемо и ясно как белый день, метод расширения с классической реализацией, даже до конца можно не показывать...
А вот когда мы смотрим реализацию на .Net7, начинается интересное. Тут многое по другому.

Мы не сразу переходим в блок кода, мы видим лямбду на метод MinInteger() куда передаётся коллекция, и уже в нём начинается буст производительности.
Это стало возможным поскольку в методы добавили дополнительное условие:

Сначала мы пытаемся получить из источника структуру Span<T>. Кто не в курсе, что она делает, советую почитать или посмотреть, объяснять её устройство крайне долго, в двух словах - обьект Span представляет непрерывную область памяти и храниться в стеке а не в хипе.
Если же мы не можем получить Span из источника, то всё идёт по старой схеме. Цикл с поэлементным поиском, как и в старых версиях фреймворка.
Если же же да, то условие запускает новый блок кода с векторизацией поиска:

Когда нам удаётся получить Span<T> из источника, запускается поиск с помощью вектора Vector<T> .

Если начать полностью объяснять процесс векторизации то это займет ещё пару тройку мониторов (Ссылка на полное описание процесса векторизации в конце этой статьи.). Поэтому опишем "грубо говоря":
Дополнительное условие проверяет, является ли длинна битов нашего полученного Span такой же или больше чем Vector с тем же переданным типом, но умноженным на 2. Это позволяет нам искать не по значению, а по длинам кусков битов нашей непрерывной области памяти, и затем сравнивать только значения совпавших длин с нужным результатом. В итоге мы сокращаем поиск в десятки, а может и в сотни раз так как шанс того, что элементы массива или коллекции будут повально занимать такое же пространство, что и наше желаемое значение, крайне мал.
Также условие IsHardwareAccelerated проверяет возможно ли ускорение процесса со стороны железа. Чтобы вернулось true мы должны быть на х64 платформе, а также в Release моде.

Однако если даже мы в Debug то уже в рантайме параметр вроде как всё равно измениться на true и векторизация сработает.
Так что вот, Microsoft не сидит на месте и я надеюсь что и в дальнейшем они будут радовать нас увеличением производительности и в других методах/библиотеках. Вместо концовки добавлю только скрин бенча по массиву, чтобы глаз ещё раз порадовался.
Почитать про векторизацию можно тут
Структура Vector<T>
Скрин бенчмарка и объяснение работы Span<T> на YouTuve каналe Nick Chapsas
2022. Платон Звонков, начинающий разработчик.
Комментарии (23)

mbobka
06.11.2022 19:45+2Это не оригинальный пост, а перевод видео с канала Nick Chapsas. Все скриншоты взяты оттуда.

ArkadiyShuvaev
06.11.2022 19:57+6Автор-то, молодец, на самом деле. Нашел новую нишу. Перевод популярных Youtube каналов с проф. тематикой.


Sektor2350
06.11.2022 22:48+11Linq сложно читается... what?

SadOcean
08.11.2022 00:15Да нет, все верно.
Linq (или например реактивные расширения) очень плотные, обладают специфической логикой и не очень добры к инструментам пояснения, типа нейминга.
Например можно добавить GroupBy(itemsGroup => Condition(itemsGrout)), но логический смысл группировки будет раскрыт хуже, чем если бы мы писали в обычном процедурном стиле с временными переменными.
Bronx
08.11.2022 13:29-1А если написать прощё:
.GroupBy(Condition), то смысл будет ещё хуже понятен?SadOcean
08.11.2022 17:35Это был условный пример.
Конечно если обернуть в понятное имя - конкретно тут будет неплохо.
А если в неудачное - то станет даже хуже (нельзя посмотреть условие на месте, нужно идти в метод)


KReal
07.11.2022 01:36+9Исторически так сложилось, что LINQ взыскал сомнительную репутацию за его слабую производительность. LINQ медленный, аллоцирует память, сложно читается, поэтому обычно его используют как инструмент запросов к БД и то, зачастую сложные запросы легче написать на SQL. Даже на собеседованиях джунов просят не использовать LINQ в алгоритмах.
Вот честно, первый раз слышу такие претензии. Что касается «медленный и аллоцирует память» — ну если делать lazy цепочки над IEnumerable ничего там аллоцироваться не будет и медленно работать тоже. По поводу сложно читается — во всех наших командах мы как раз можем пренебречь потерями в производительности ради декларативности Linq, которая плюс-минус понятна всем. Про базу данных — ну наверное, если можно писать запросы на Linq (в EF или где там еще), то база это позволяет, а если нужен перфоманс — то велком в plain SQL или прости господи процедуры и иже с ними.
Вот про джунов согласен — понятное дело, что если на собеседовании просят, например, отсортировать коллекцию, то .Sort() это слишком толстый лайфхак)
Raneddo
07.11.2022 13:54То есть на собеседовании вы просите джуна отсортировать массив? А каким алгоритмом? Если пузырьком, то это вообще бесполезно. Максимум, надо знать О нотацию и основную идею алгоритма. А если вы просите написать qsort, то это вообще нонсенс. Даже Яндекс (и всё, что выше за границей) не просят писать алгоритмы сложнее бинарного поиска, там задачи на подумать. Возможно, у вас компания, которая занимается оптимизацией алгоритмов сортировки, тогда я могу понять такой вопрос, иначе он бесполезен
KReal
08.11.2022 02:13+1Ну наверное любым. В интересах собеседуемого предложить разные варианты. Если не qsort, то слиянием, почему нет. Но мне кажется, вы уводите в сторону — я отвечал на «джунов не просят использовать LINQ на собеседованиях». Практическую пользу от линка на собесе я сходу узреть не могу)

Deosis
07.11.2022 07:37+3Также появились новые методы TryGetNonEnumeratedCount(), чтобы не проходиться по коллекции для получения Count
Пример дичайшего легаси. А все потому, что программисты использовали count для выполнения побочных эффектов. И теперь нельзя ускорить этот метод, не сломав кучу пользовательского кода.

Popou
08.11.2022 11:32Прошу прощения, а для чего ещё может использоваться Count?

mayorovp
08.11.2022 13:13Для подсчёта количества, как бы.
Popou
08.11.2022 13:15Да нет, я не об этом, автор коментария говорит о побочных эффекта. Мне вот стали интересны именно они.
mayorovp
08.11.2022 13:24+3Ну вот смотрите:
var hashSet = new HashSet<Foo>(); foos.Count(hashSet.Add);Это ещё более-менее (скорее менее, чем более) нормальный способ, ведь подсчитать число удовлетворяющих предикату объектов невозможно без выполнения этого предиката. Но иногда делали и вот так:
var list = new List<Bar>(); foos.Select(foo => { list.Add(foo.Bar); return foo; }).Count();Вот это уже абсолютно ненормальный способ, ведь селектор тут вообще исполнять никто не обязан. Но нет, были те кто считал это отличной заменой циклу foreach, ведь они совершенно точно знали, что внутри Count есть именно такой цикл! А теперь уже Microsoft не могут этот цикл убрать из Count…

alexhott
07.11.2022 08:18Вы не любите кошек? Да вы просто их готовить не умеете.
Перед тем как чего-то написать ан LINQ я довольно долго писал и оптимизировал SQL запросы. По началу пришлось смотреть что в итоге LINQ отправляет серверу и от чего это зависит, оказалось что можно таки выйти на любой оптимальный SQL запрос используя синтаксис LINQ, и мне уже не хотелось писать внутри шарпового кода голые SQL.
ptr128
07.11.2022 11:38Может Вы путаете LINQ (ORM) с Linq2DB (типизированный SQL)?
alexhott
07.11.2022 13:28Ну конкретно мой комментарий конечно относится к работе с БД, а не просто с любыми коллекциями в памяти, да и в статье вроде как LINQ в контексте рядом с SQL. Хотя вот так сразу не вспомню сценария когда коллекция рождалась бы не из БД и с ней нужно было какие-то операции с большим объемом провернуть.

baklajan
07.11.2022 15:19+1Много же примеров Linq2: XML, CSV и т.д.
Да и само понятие большое тоже растяжимое думаю, в каком-то кейсе 1000 штук много, в каком-то сотни миллионов не очень много.
ptr128
07.11.2022 18:17Так я об этом и спросил. Если Linq сначала делает SELECT, предоставляя доступ к данным коду на клиенте, а потом INSERT ... VALUES или SqlBulkCopy, то Linq2DB ориентирована на [WITH ...] INSERT/MERGE ... FROM, когда клиенту данные могут вообще не пересылаться.
Парадигма разная. Первая - ORM, а вторая - синтаксический сахар для написания SQL в C# и берущая на себя проблемы различия синтаксиса в разных СУБД.
mayorovp
Оптимизация прикольная, но как-то не очень интересная. В реальном коде Min на массиве напрямую вызываться, скорее всего, не будет — между ними будут хотя бы Select и Where.
Вот если бы они общий случай ускорить умудрились...
a-tk
Для этого надо сначала научиться инлайнить лямбды.