

Привет! Меня зовут Олег, я руководитель направления по метаданным в департаменте по работе с данными розничной сети «Магнит». Мы занимаемся всем, что связано с понятностью данных, развитием инструментов и сервисов, которые помогают бизнес-пользователям быстрее найти и получить нужные данные в корпоративной платформе, сориентироваться в нюансах их использования и происхождения.
Всё описанное ниже — наш практический опыт: решение конкретных задач и болей. Инструмент, о котором я расскажу, получил массу позитивных отзывов коллег, и что самое главное — им регулярно пользуются. Поэтому, собственно, мы и решили о нём рассказать.
Инструменты, которые сейчас на вооружении — это база знаний, виртуальный помощник (чат-бот, работающий в веб-интерфейсах и корпоративном мессенджере), веб-приложение для записи/редактирования бизнес-метаданных в хранилище и, собственно, Каталог витрин КХД, о котором я и расскажу подробнее в этой статье. Всё это создает, как мы любим выражаться, нулевую линию поддержки – систему самообслуживания пользователя, которая помогает сориентироваться в data-сервисах. В итоге это экономит время пользователя и трудозатраты команды, занимающейся развитием и сопровождением платформы данных.
Если тема вам близка, и вы дочитали до этого момента, то прежде, чем продолжить и рассказать какие кейсы мы решали, хотелось бы познакомить вас с масштабами платформы данных в компании.
Мы строим КХД более 12 лет, и у нас накопилось очень много данных.

В том числе, и в корпоративном хранилище данных (КХД), к которому мы прикрутили самописный каталог.

Доступ к ним бизнес-пользователи получают через конечные представления — витрины данных. Когда их более 5000, естественно, задача поиска превращается в серьёзный квест; а вопрос понимания и доверия к найденному — ещё более чувствительной темой. Подобного рода проблемы в enterprise масштабах решаются внедрением зрелого проприетарного (чаще всего) или не менее зрелого open-source (при должном опыте внедряющей команды) софта класса Data Governance: Business Glossary и/ или Data Catalog, а в идеале ещё и в связке с решением Data Quality. Сразу скажу, что первый вариант — это целевая история и для нас, в которую мы идём достаточно основательно и аккуратно. Внедрение enterprise-решения требует серьёзных инвестиций (софт, инфраструктура, внутренняя и внешняя команды) и времени. Но решать бизнес-задачи нужно здесь и сейчас. Вот мы и решили попробовать сделать лучше (понятнее для пользователей) уже сейчас. Обкатать решения существующих бизнес-кейсов, пообщаться с пользователями, наработать опыт, чтобы учесть его при внедрении целевого решения.
А что сделали-то?
В начале года взяли всё, что было в нашем распоряжении: КХД на Teradata, базу знаний на Confluence и, конечно же, волю, опыт и hard skills команды и разработали автоматически обновляемый Каталог витрин КХД с пользовательским интерфейсом Confluence. С точки зрения техники, решение можно разбить на три части: бэкенд с метаданными (они у нас сейчас берутся с Teradata, ETL Informatica, а в ближайшем будущем Postgre – вынесем всё в единое место), фронтенд на Confluence, макет которого собирается стандартными макросами (их набор зависит от вашей версии, у нас 7.12.5) и Python-магия, которая берёт данные из бэкенда и наполняет контентом подготовленные макеты под админской учёткой.
Как работает Каталог витрин КХД?
Стартовая страница для поиска необходимых витрин выглядит так. Скрин сделан на примере бизнес-кейса, где пользователь ищет что-то про праздник, а точнее витрины, поля которых содержат информацию о праздничных днях.
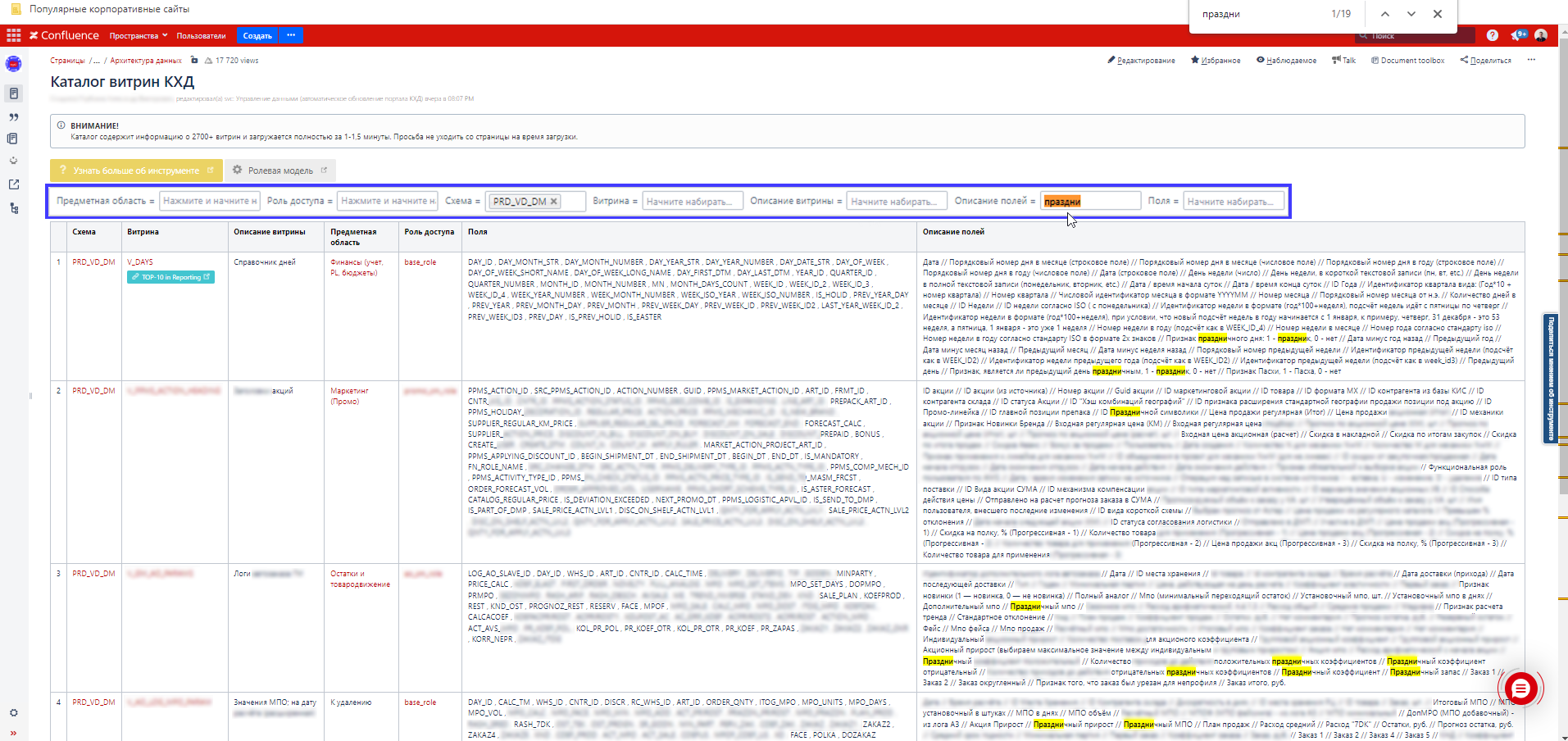
Она представляет из себя плоскую таблицу, в которую публикуются наиболее востребованные пользователями метаданные для витрин хранилища: схема (список), наименование (текст), описание витрины (текст), предметная область (список, где-то в других компаниях это бизнес-домен), роль доступа (список), поля (текст) и описание этих полей (текст). Сама таблица обёрнута в макросы «Фильтр таблиц» и «Table Plus». Такая конструкция обеспечивает мгновенный поиск по полям таблицы. Нюанс только в том, что в зависимости от объёма таблицы, загрузка страницы может занять некоторое время. В нашем случае это до 1,5 минут. Но дальнейшее удобство инструмента покрывает время ожидания. Чтобы не смущать пользователей бесконечным скроллингом, сделали вывод по 25 строк, остальное — как страницы поисковой выдачи.

Каталог витрин КХД по расписанию обновляется каждый вечер. Витрины ранжируются перед публикацией: сверху показываются наиболее популярные витрины, к которым за последний месяц обращались чаще всего или больше всего уникальных пользователей. Расчёт таких операционных метаданных решили делать раз в неделю (по субботам), чтобы сильно не грузить хранилище.
Итого: пользователь спрашивает, а каталог мгновенно отвечает, подкидывая наиболее популярные объекты, т. е. витрины, которым доверяет бОльшая часть пользователей и которые соответствуют критериям поиска. Если у вас нет критериев для поиска или вы новичок в компании, просто зайдите в Каталог и сразу поймёте, какие данные (факты или справочники) считаются основными – они вверху. Конечно, скриншотить стартовую страницу Каталога с такими сущностями мы не можем – поверьте на слово ????
Больше всего пользователям зашла возможность поиска витрин по полям, где они могут вбить наименование поля (и разобраться в логической модели: например, в какой витрине хранится расшифровка ключевого поля) или описание поля, куда можно вбить наименование показателя/бизнес-термина. Единственный недостаток — на странице не подсвечиваются введённые фильтры поиска – CTRL+F вам в помощь.
Кстати, кто использует тот или иной data catalog, попробуйте решить этот кейс из коробки своего решения ????
Каталог витрин КХД в нашей компании — это единая точка входа для поиска необходимых данных. Он помогает каждый день как новичкам в рамках их онбординга, так и опытным пользователя КХД. Но пользователям зачастую мало знать об объекте основные метаданные, представленные в Каталоге, нужна возможность узнать подробнее о структуре полей, происхождении данных в витрине и опыте использования витрины коллегами. Чтобы решить это задачу, мы реализовали паспорта витрин (карточка витрины, если по-простому). А если заглядывать дальше, то и для каждой промышленной процедуры и потока данных тоже есть паспорта, но они заслуживают отдельной статьи.
Что можно найти в паспортах витрин?
Эволюционным путём мы пришли от разделения экрана на три зоны к трём вкладкам: «Поля», «Происхождение данных» и «Использование». Ниже будет подсвечено содержимое для каждой из них. К слову, сами вкладки сделаны макросам Confluence: Horizontal Navigation Bar и Horizontal Navigation Bar Page.
Ключевой момент заключается в том, что контент паспортов витрин (как и паспортов других объектов) генерируется автоматически и не изменяется пользователями вручную в Confluence. У пользователей есть только возможность поставить оценки, прокомментировать, добавить страницу в избранное для отслеживания изменений.
Ниже — содержимое первой вкладки витрины, которую мы нашли в каталоге.

На что обратить внимание?
Наименование страницы, соответствующее схеме и объекту (витрине).
Бизнес-описание витрины — зелёным жирным текстом.
Кнопка с предметной областью, которая отправит вас на страницу этой предметной области в отдельной вкладке.
Ещё одна кнопка, показывающая, что витрина входит в ТОП-10 в отчётности (действительно, без календаря никуда).
Содержимое самой вкладке, где в формате таблицы представлены поля, описание полей и тип данных полей.
На примере попала ещё кнопка UPI. Применительно к нашему стеку это означает unique primary index (такие у нас ещё есть и для просто PI, и для полей партиционирования). Если обратить внимание, то в правом верхнем углу таблицы можно одним кликом скачать таблицу с полями.
Немного засветим конструкцию макросов в режиме ручного редактирования страницы.

Идём дальше — вкладка «Происхождение данных». Рассмотрим её на примере другой более показательной витрины.

Здесь вы найдёте ссылки на схему и реестр требований (другими словами — техническое задание), сможете узнать, есть ли охлаждённые данные (тут наша специфика использования Teradata и Hadoop). С помощью «раскрывашек» сможете посмотреть скрипт витрины, источник, указанный в скрипте и подробнее изучить физические таблицы-источники для этой витрины: размер, количество строк, дату последнего обновления, факт репликации между серверами (тоже наша специфика), процедуры и потоки, которые задействованы в формировании таблицы с данными. Для процедур подсвечены функции, которые они выполняют. Процедуры и потоки кликабельны и ведут в их паспорта.
Далее перейдём к последней вкладке «Использование» и вернёмся к витрине «Справочник дней».

Эта вкладка показывает, кто и где использует витрину:
кнопками подсвечены сервера (наша специфика);
категория информации согласно стандартам информационной безопасности (их тоже пользователь сможет почитать при желании);
роль доступа, которую пользователю нужно получить, чтобы начать работать с объектом;
раскрывашки с информацией об использовании витрины в аналитической отчётности и других объектах КХД (их можно развернуть и получить ссылки на описание этих объектов);
оценки пользователей (каталог же всё-таки);
статистика витрины (цифры, на основании которых витрины ранжируются в каталоге) — можно посмотреть, кто использует витрину чаще всего на нужном вам сервере),
примечание;
обращения пользователей (тут наша интеграция с Jira) — судя по всему, кто-то когда-то уже задавал вопросы по этой витрине команде сопровождения).
О наших пользователях
Всего в экосистему каталога входит порядка 9 000 автоматически обновляемых страниц, включая паспорта витрин, процедур, потоков, страниц для схем и самого каталога витрин.
На всех страницах прикручен чат-бот (о нём расскажем в следующий раз) и сборщик задач (стандартная фича в Jira — с помощью неё собираем обратную связь пользователей, которая сразу летит как задача нам).
Напомню, что мы запустили инструмент и начали его «продавать» пользователям в начале 2022 года. А вот и статистика использования:

Тратить много сил на продвижение инструмента не пришлось. После запуска мы провели ряд коммуникаций на пользователей КХД, организовали воркшоп и далее уже работали с обратной связью. Каждый месяц мы рассказывали пользователям о новых фичах и продолжаем это делать сейчас.
А где же мы берём метаданные?
Про фронт сказали, про «Python-магию» не расскажем. А где же мы берём сам контент (бизнес-метаданные)? Это важная составляющая, и у нас она исторически отлажена и контролируется на регулярной основе. Речь о внесении аналитиками/ разработчиками в рамках производственного процесса информации по описанию витрин, полей витрин, категории информации, предметной области, рекомендованной роли. Для всего есть места хранения и место в бизнес-процессе, когда оно валидируется и записывается в хранилище. Теперь с таким количеством пользователей коллеги чувствуют бОльшую ответственность за качество и полноту этого контента. Остальное (например, тип поля или обращения) собирается автоматически из технических и операционных метаданных хранилища.
А что по затратам?
Каталог витрин КХД за свои 10 месяцев пережил много апгрейдов с точки зрения фичей, визуального оформления и полноты метаданных. В этом огромная заслуга большого количества пользователей, команд развития КХД, их вовлечённости и обратной связи. В названии статьи, как вы помните, мы гордо заявляем про минимальны затраты. Так каковы же они? Не назовём затраченные человекодни или деньги, но скажем, что реализация самой идеи на старте и базовых её механик (генерация паспортов витрин и формирование каталога) — результат факультативной работы одного аналитика и одного инженера в пределах месяца.
Заключение
В будущем все наработки Каталога витрин КХД переедут в целевой инструмент. А пока у нас есть понимание, что Каталог будет служить компании ещё около года, и мы продолжаем добавлять новую функциональность, общаться с пользователями и решать их кейсы. Например, сейчас работаем над потребностью указывать систему-источник для физических таблиц, из которых строятся витрины. В нашем ETL-инструменте есть IP машин, из которых он тянет данные, осталось только дать им понятное наименование и поделиться ссылкой на существующие описания систем.
С учетом полученного опыта наша команда и бизнес-пользователи теперь будут более требовательны к целевой платформе управления данными. Придётся очень постараться, чтобы научить её некоторым фичам, о которых мы поведали в этой статье????
Upsarin01
Я так и не понял смысла загрузки информации о всех 2700 витрин на стартовую страницу, и в чем заключается удобство? Тратить 1.5 минуты на это? А если через мобильник и связь плохая?
Не думаю что обычный быстрый поиск или группировка этих витрин по понятным категориям - сильно бы нагрузила проект....
om_8 Автор
Удобство заключается в скорости поиска и возможности комбинировать использование конкретных фильтров (например, описание витрины и описание поля витрины) - результат отдает мгновенно и этот результат подан в правильной плоскости без "шумов" от других страниц пространства (в спейсе еще много страниц с технической документацией). Поэтому мы помимо стандартного ("обычного быстрого поиска") Confluence, сделали еще стартовую страницу. Кроме скорости поиска, у нас там прикручен алгоритм, который поднимает вверх наиболее востребованные витрины + в саму таблицу на стартовой страницы выведены основные метаданные на наш взгляд, которые удобно воспринимать в табличном виде.
1,5 минуты - это пороговое значение, превысить которое получается в очень редких случаях. Обычно с среднестатистическим интернетом пользователи укладываются в 30 сек. Жалоб по этой теме не поступает уже давно. На старте инициативы было 3,5-5 минут - это конечно была беда; потом оптимизировали.
Витрины (паспорта витрин) также сгруппированы:
1. Физически привязаны к разным страницам-родителям, которые равны Схемам в хранилище. Таких родителей ~ 25.
2. Размечены (связаны) по предметным областям, а для каждой предметной области тоже есть страница с описанием и списком витрин, входящих в нее.
т.е., если пользователь более погруженный в структуру КХД или архитектуру данных в целом, и знает, что ищет, то может переходить по таким разделам.