
Привет, Хабр! Меня зовут Влад, я frontend-разработчик в SimbirSoft.
Я часто задумывался, почему на проектах, где используется Node.js (в частности Nuxt.js и Next.js — фреймворки на базе Vue и React), мы каждый раз, словно по шаблону дополнительно используем еще одну прослойку бэка — PHP, Java, C# или другой язык программирования, к примеру, «неродной» JavaScript. И тогда я с головой погрузился в анализ ситуации по работе с популярными системами управления базами данных (СУБД), файлами, изображениями и другими естественными потребностями современного проекта.
Для чего было это анализировать? Причин было несколько, в основном я искал:
более интересную альтернативу реализации клиент-серверного приложения;
быстрый способ сборки MVP, а также сайтов с немудреной структурой базы данных (БД) — лендингов, CMS;
наиболее дешевый вариант реализации сайтов, упомянутых в предыдущем пункте;
способ превратить frontend-разработчиков в самодостаточную команду (тут могут быть «плюшки», например, в скорости набора команды, а менее раздутый бюджет — это уже следствие);
метод расширения кругозора специалистов из мира frontend. В данном случае я оперирую своим личным убеждением, что любой разработчик — это прежде всего инженер. А потому смежные области, например, умение работать с репозиторием, деплоить проект на сервере, тестировать приложение и даже обладать базовыми знаниями в области хранения данных, — однозначно должны входить в багаж умений такого специалиста.

JavaScript + Node.js + ORM
Всем известно, что при создании клиент-серверной архитектуры используется паттерн, согласно которому клиентское web-приложение (в нашем случае — JavaScript-приложение) «клянчит» данные у backend-приложения, предоставляющего API и реализующее посредством моделей логику доступа к данным. Кажется, в этой архитектуре все гладко, но! Везде на проектах, где я честно трудился, backend было принято реализовывать на «неродной» платформе, например, PHP (Laravel, Codeigniter), Java, C#.
В итоге, добавляя в этот стек Nuxt.js/Next.js (js-фреймворки для Vue и React), помимо необходимости дважды описывать модели данных (или иногда обычные DTO) и сервисы/контроллеры для backend- и frontend-приложения, мы получаем бессмысленную и беспощадную цепочку запросов: backend на Node.js → браузер → backend на иной платформе → БД. Возникает вопрос: «Зачем?!».
А все потому, что до сих пор не набрало популярность (как правило, из-за страха перед новой, неизученной технологией) использование в качестве бэка Node.js — родной серверной реализации на JavaScript. Node.js прекрасно работает с разнообразными СУБД. Более того, для него существует немало ORM, позволяющих абстрагироваться от тонкостей реализации той или иной СУБД и работать с данными БД как с коллекцией объектов. Но даже если вы рядовой frontend-разработчик, то с принципами работы СУБД, а также встроенным языком все же лучше ознакомиться — это добавит в вашу жизнь красок и расширит ваш кругозор.
В идеале для продуктовой разработки архитектуры БД лучше привлечь отдельного специалиста, поскольку эта сфера достаточно широка, она требует постоянного внимания, и охватить ее полностью, совмещая работу на frontend, не получится.
Но, конечно, не все хорошо владеют Node.js и Express, а потому я не просто так упомянул те фреймворки со встроенным Node.js: Nuxt.js (Vue), Next.js (React). Прелесть этих фреймворков заключается в том, что код мы пишем один раз, а выполняется он как на серверной стороне, так и на клиентской. И поднимать вручную web-сервер на «ноде» тоже не нужно. Теперь приправляем это блюдо нашей ORM и — готово!
Для Nuxt.js можно использовать Prisma ORM, а для Next.js — Sequelize ORM. Упомянутые ORM поддерживают все популярные СУБД (например, MySQL, PostgreSQL, MongoDB, SQLite) и основные подходы для работы с API: REST, GraphQL, gRPC. Далее я постараюсь в общих чертах описать этот подход. Уточню, что я ни в коем случае не собираюсь перепечатывать официальную документацию, а лишь делюсь своим личным опытом построения архитектуры с использованием Prisma ORM.
Понимание и возможности ORM (Prisma)
ORM (Object-Relational Mapping) — объектно-реляционное отображение, суть которого заключается в связывании структуры БД с объектно-ориентированной концепцией языка программирования.
Приведу пример структуры таблицы пользователя:
create table "User"
(
"userId" serial not null
constraint user_pk
primary key,
"userEmail" varchar(255),
"userPassword" varchar(255),
"userName" varchar(255),
"userSurname" varchar(255)
);
create unique index user_useremail_uindex on "User" ("userEmail");Это пример запроса, создающего таблицу User в БД на языке SQL. Как видим, такое представление совершенно не ложится на концепцию такого языка как JavaScript. Поэтому наша Prisma ORM позволяет описать нам ту же таблицу следующим образом:
model User {
userId Int @id(map: "user_pk") @default(autoincrement())
userEmail String? @unique(map: "user_useremail_uindex") @db.VarChar(255)
userPassword String? @db.VarChar(255)
userName String? @db.VarChar(255)
userSurname String? @db.VarChar(255)
}Теперь это уже напоминает обычный класс. Кстати, вот пример декларации модели в другой ORM, тоже для Node.js Sequelize:
class User extends Model {}
User.init(
{
user_id: {
type: Sequelize.INTEGER,
primaryKey: true,
autoIncrement: true,
},
name: Sequelize.STRING(255),
email: {
type: Sequelize.STRING(255),
unique: true,
},
isAdmin: Sequelize.BOOLEAN,
},
{ sequelize, modelName: 'user' }
)Как видно, это уже нативный класс. Но в Prisma, о которой дальше и пойдет речь, немного другой подход (почему-то :) ), но тоже вполне приемлемый.
Prisma ORM состоит из трех независимых частей: Prisma Client, Prisma Migrate и Prisma Studio.
Prisma Client — автоматически сгенерированный (далее будет показано как) и типизированный конструктор запросов для Node.js и TypeScript. Приложение может быть создано и на «чистом» JS, но Prisma под капотом имеет TypeScript, и все модели данных автоматически типизируются, что позволяет использовать эти типы в исходном коде, например, для валидации полей. Поэтому каждый раз, когда вносятся какие-либо изменения в конфигурацию Prisma (например, изменения в модели данных — тут же меняется состав модулей/расширений), этот конструктор требуется сгенерировать заново. То есть, Prisma Client предоставляет все необходимые методы, которые можно расширять с помощью классов, для работы с вашими моделями и их данными — например, получить записи из таблицы. Подробнее в документации.
Prisma Migrate — система миграции. В процессе разработки приложения у нас возникает две потребности: миграция структуры БД и миграция данных БД. Начальные данные, «сиды» (seed) обычно нужны для инициализации приложения, когда, к примеру, могут понадобиться пользователи. Далее такими начальными данными могут наполняться и другие сущности (таблицы БД). В том же ключе существует необходимость в переносе созданных и измененных моделей (таблиц). Разумеется, и в первом, и во втором случае все эти изменения должны храниться в репозитории проекта и, более того, в соответствующем хронологическом порядке. Вот эту систему хранения моделей и данных, а также механизм переноса в существующую БД как раз и реализует Prisma Migrate (можно начать читать про нее здесь или здесь).
Стоит рассмотреть два варианта реализации миграций:
Из приложения в БД (JavaScript-вариант) |
Из БД в приложение (DB-engineering-вариант ❤️) |
Тот самый вариант, описанный в документации. То есть и модели, и сиды описываются в самом приложении, а далее в момент деплоя запускается скрипт, который исполняет миграции. Этот вариант подходит для тех, кто плохо знаком с самим языком СУБД и хочет абстрагироваться от его устройства. |
Предварительно создается БД, которая с помощью другого скрипта Prisma «вливается» в приложение, что позволяет создать модели, не описывая их вручную, на основании уже существующей БД. Миграции с сидами пишутся на языке СУБД и потом ею же выполняются. Такой скрипт можно написать, например, на bash и выполнять его в среде ОС в момент деплоя. Этот вариант подходит для тех, кто любит писать запросы на языке СУБД и любит напрямую работать с БД (например, через клиент БД). Небольшая ремарка: после единоразового «затаскивания» БД в модели, конечно, можно пойти первым путем и создавать миграции на JS. Я лишь описал «ленивый» способ создания моделей. По крайней мере он «ленивый» именно для меня, поскольку я неплохо владею реляционными БД. |
Но какой бы вариант вы не выбрали, обязательно продумайте стратегию разрешения данной задачи до начала разработки БД.
Prisma Studio — достаточно удобный браузерный клиент БД, типа phpMyAdmin.
Далее немного ознакомимся с основными понятиями.
Модели (классы) — это таблицы БД, а данные (записи) этих таблиц — объекты. Для работы с моделями и для работы с данными, у этих моделей есть методы (которые, кстати, можно расширять с помощью нативных классов).
Вот пример запроса списка всех пользователей из описанной выше, таблицы/модели:
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
const res = await prisma.user.findMany();В итоге получаем JavaScript-массив объектов. Никаких «SELECT * FROM User…». Кстати, составлять и выполнять запрос на языке СУБД тоже можно. То есть объекты по понятиям ORM — это сами данные из таблиц, те, что модели.
Итак, перечислю здесь основные и некоторые другие возможности Prisma ORM (Sequelize ORM обладает примерно теми же возможностями):
описание схемы БД (модели), включая отношения «один-ко-многим», «многие-к-одному» и «многие-ко-многим»;
базовые методы для работы с данными БД;
реализация ссылочной целостности (onUpdate, onDelete);
миграция БД;
транзакция запросов (в т.ч. интерактивная транзакция);
метрики, с помощью которых можно получить более детальный анализ того, как Prisma Client взаимодействует с БД;
получение количества записей, удовлетворяющих заданным условиям, в связанных таблицах;
поддержка расширений PostgreSQL (какие-то расширения могут еще не поддерживаться Prisma);
типизация для TypeScript;
валидация данных.
Прикручиваем Prisma на Nuxt.js
Пока я опишу весь процесс для стабильного Nuxt 2 (на момент написания статьи), а потом поясню те небольшие отличия, которые относятся к особенностям интеграции Prisma в Nuxt 3.
Спойлер: там этот процесс реализуется проще и более естественно.
NuxtJS-приложения
Давайте приступим к созданию двух приложений на Nuxt.js. Почему именно двух — объясню ниже. :)
Пока создаем только первый проект. Второй создадим банальным копированием первого — отличия будут лишь в конфигах и компонентах/страницах):
npx create-nuxt-app nuxt-prisma-appПереходим в проект и запускаем dev-сервер, чтобы сразу видеть результат последующих шагов.
Теперь можно приступить к установке Prisma ORM:
npm i -D prismaи ее инициализации:
npx prisma init
После инициализации в корне проекта будут созданы два файла: /prisma/schema.prisma и /.env. Первый является той конфигурацией Prisma Client, где определяется провайдер, подключаются модули, описываются модели и прочее. Во втором хранятся переменные окружения, которые автоматически подтягиваются из Nuxt.js и содержат параметры подключения к БД. Ни в коем случае не храните .env-файл в репозитории приложения! Лично я, чтобы помочь не знакомым с этой ORM разработчикам, просто создал файл .env.sample с таким содержимым:
DATABASE_URL="postgresql://johndoe:randompassword@localhost:5432/mydb?schema=public"И всё! Всем, кто хочет более детально ознакомиться с конфигурированием Prisma, достаточно перейти в этот раздел документации.
Если данные подключения вы заполнили верно, то самое время произвести миграцию.
Миграция БД
Здесь есть целых два варианта, о которых я подробнее писал ранее: перенос существующей БД в схему Prisma (/prisma/schema.prisma) или миграция существующих (описанных в /prisma/schema.prisma) моделей в БД.
Первый вариант, на мой взгляд, проще. Удобнее создавать и сопровождать БД с помощью удобных инструментов — клиентов СУБД, позволяющих визуализировать весь этот процесс. Лично я заранее создал БД со всеми необходимыми таблицами, поэтому далее просто выполнил две команды:
prisma db pull && prisma generateГотово! Prisma сама создала необходимые модели и сгенерировала для Prisma Client методы для работы с ними. Как я уже упоминал, методы моделей можно расширять (подробности).
Второй вариант более приемлем для тех, кто уже прекрасно ориентируется в моделях Prisma (а это пока не про меня), способен вручную описать как сами модели (таблицы) и их связи, а также хуже ориентируется в языке СУБД или даже обычном клиенте для работы с СУБД. Можно комбинировать оба варианта, лишь бы этот процесс был контролируемый, и разработчик моделей в Prisma не мешал разработчику БД.
Поэтому если вы выбрали второй вариант, то для «пробы» можете создать вот такой конфиг Prisma (разумеется, в переменной окружения DATABASE_URL должны содержаться параметры подключения к вашей заранее созданной БД):
// schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
userId Int @id(map: "user_pk") @default(autoincrement())
userEmail String? @unique(map: "user_useremail_uindex") @db.VarChar(255)
userPassword String? @db.VarChar(255)
userName String? @db.VarChar(255)
userSurname String? @db.VarChar(255)
}А затем запустите миграцию:
npx prisma migrate dev --name initПосле успешного выполнения данной команды будет создана папка /prisma/migrations, содержащая все ваши миграции, которые будут выполняться при деплое вашего приложения.
API
Далее можно переходить к написанию обработчиков запросов. Как бы глупо не звучало, но в Nuxt.js для обработки запросов к нашему API нужно установить… Express. Чтобы вы не огорчались, подброшу приятный спойлер: в Nuxt 3 устанавливать Express не нужно :)
npm install expressТеперь в корне проекта создадим /api/index.js (экспериментируя с Nuxt 3, я, разумеется, пишу код на TypeScript, а сейчас делюсь самым первым опытом реализации на Nuxt 2), в который пока что разместим это:
// api/index.js
import express from 'express'
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
const app = express()
app.use(express.json())
/**
* тут будет логика
* например:
*/
app.get("/user/:id", async (req, res) => {
const { id } = req.params;
const data = await prisma.user.findUnique({
where: {
userId: Number(id),
},
});
if (data) res.json(data);
else res.status(404).json({ message: "Пользователь не найден!" });
});
/**
* тут конец логики :)
*/
export default {
path: '/api',
handler: app
}Вот мы и создали наш API. Теперь, чтобы он подхватился, добавим в nuxt.config.js следующее:
// nuxt.config.js
serverMiddleware: [
'~/api/index.js'
]Ради эксперимента я решил создать лендинг с множеством сущностей, из-за чего количество методов-обработчиков моих запросов превратило /api/index.js в длиииииииииинную простыню. Самым быстрым и простым решением для меня показалось разбить логику на сущности. В итоге конфиг моего Nuxt стал выглядеть так:
// nuxt.config.js
serverMiddleware: [
"~/controllers/auth.js",
"~/controllers/bid.js",
"~/controllers/city.js",
"~/controllers/menu.js",
"~/controllers/menu-item.js",
"~/controllers/user.js",
"~/controllers/vacancy.js",
],Здесь нужно учесть, чтобы для каждой сущности не создавался новый экземпляр PrismaClient.
В итоге у меня получился вот такой лендинг. Верхнее меню, список вакансий, список городов, отправка формы — все это реализовано на нашем Nuxt + Prisma.
Как c таймингами? Базу я намеренно создал на своем тестовом сервере, расположенного где-то в степях Германии, а приложение запустил локально. Все данные «хапаю» скопом — тяну все подряд на стороне сервера, блокируя загрузку страницы. То есть создаю самые отвратительные условия из возможных:
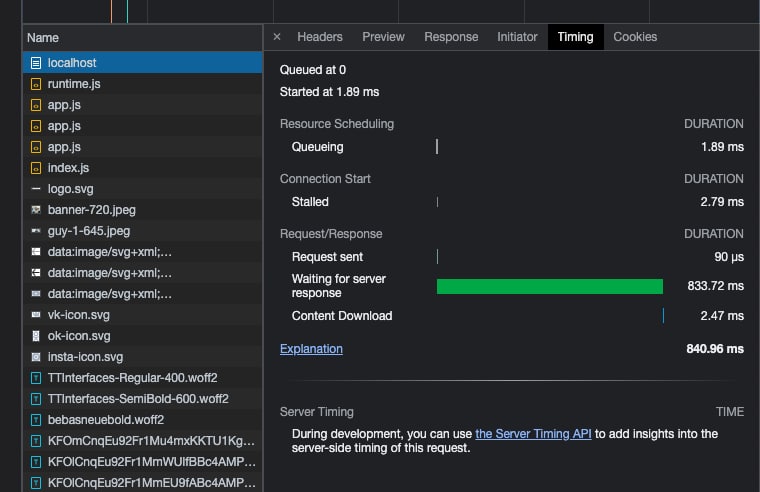
По-моему, неплохо.
Не забываем про второе приложение — оно будет админским. Его можно создать путем банального копирования первого приложения, за тем исключением, что будут использоваться другие параметры для подключения к БД. Аспекты такого подхода более детально описаны в следующей главе про безопасность.
Безопасность
Выше я описал два приложения: публичное (пользовательская часть) и административное (закрытое приложение для администраторов и контент-менеджеров). Почему я сразу зашел с двух приложений? Вот тут уже начинается немного занудная тема про безопасность, но не менее важная.
Настраивая подключение к СУБД, мы обязательно используем переменные окружения, содержащие параметры подключения, и, конечно, хранящиеся только в ОС, где непосредственно и запускается наше приложение. Содержимого этих env-файлов не должно быть в репозитории приложения, а также и в исходном коде. Разве что можно создать переменные окружения с примером конфигурации (какой-нибудь .env.sample). Тем не менее даже этого может быть мало, если представить, что злоумышленник все же каким-то волшебным образом добрался до файлов (сайт же публичный).
Тут очень хорошо подходит решение с выделением административной панели в отдельное закрытое за vpn-ами, прокси и прочими ширмами, приложение, доступ к которому имеют только «избранные», например, Нео и Тринити.
Вишенкой на торте становится отдельный конфиг с «избранным» пользователем подключения к БД, в котором мы указываем пользователя, обладающего почти «безграничными» правами. Почти — ибо чаще всего даже для админки не требуется рутовых прав доступа к БД. У публичного приложения в конфиге подключения к БД мы указываем пользователя, обладающего правами только на чтение. Порой нужно предоставить права на запись данных, приходящих из разных форм, но даже эти права можно максимально сузить. Все! «Обломись, хакер!» :)
Далее — шифрование. Когда речь идет про классическую авторизацию «логин/пароль», то сразу возникает вопрос: «Как хранить пароли пользователей, чтобы их не расшифровали по хеш-таблицам через три минуты после скачивания нашей БД?».
Оставим хакеров, представим более бытовой случай — очень сильно обиженный админ. Конечно, о шифровании нужно задуматься уже на уровне файловой системы и БД, но что у нас есть на клиенте в JavaScript (Node.js)? Есть у нас bcrypt (git)! С ним шифрование выглядит примерно так:

Да, я проверял: одинаковые пароли имеют разный хеш. «Обломись, хакер», со своими хеш-таблицами!» :)
Nuxt 3
Как и обещал, поделюсь и опытом прикручивания Prisma к Nuxt 3. Уже был спойлер про отсутствие необходимости дополнительно устанавливать Express — так и есть. Если внимательно почитать эту документацию, то становится понятно, что Nuxt 3 сам обходит нужные папки и формирует необходимые «урлы». В моем случае структура папок была такой:

И, например, server/api/user.ts имел следующее содержание:
import bcrypt from 'bcryptjs';
import { PrismaClient } from '@/prisma/client';
const prisma = new PrismaClient();
export default defineEventHandler(async (event) => {
switch (event.req.method) {
case 'GET':
return prisma.user.findMany();
case 'POST':
const body = await useBody(event)
bcrypt.genSalt(10, function (err, Salt) {
bcrypt.hash(body.password, Salt, async function (err, hash) {
body.password = hash;
return prisma.user.create({
data: body,
});
});
});
}
})Да, опять те же грабли — создание экземпляра PrismaClient прямо в логике. Плохой я! Но это — лишь простой пример.
Теперь при GET-запросе к /api/user мы получаем список пользователей. Намного проще, чем в Nuxt 2, да еще и TypeScript под капотом — все плюшки сразу! Разумеется, все предыдущие шаги по установке Prisma, миграциям и остальному остаются, как и были. Вообще, Nuxt 3 заслуживает отдельной статьи, ибо ребята-разработчики — молодцы! Рекомендую.
Но не джаваскриптом единым жив человек :) Далее я бы хотел напомнить про другие, зачастую недооцененные элементы архитектуры, окружающие любое приложение.
Другие важные элементы архитектуры
Web-сервер
Многие либо недооценивают, либо понятия не имеют о всей богатой функциональности, предоставляемой web-серверами. Как правило, web-сервер используют как обычного привратника, который, в лучшем случае, может указать подошедшему к нему запросу, где находится DocumentRoot.
А ведь современный web-сервер реализует множество возможностей, перечислю лишь некоторые:
выбор протокола передачи данных;
гибкий роутинг — можно учитывать не только запрашиваемый url со схемой, но и аргументы, IP-адрес, порт, имя пользователя (прошедшего аутентификацию), тело запроса, юзер-агента и др.;
безопасность — возможно установить авторизацию, шифрование и др.;
обработку файлов;
ограничение скорости передачи ответа;
управление статусом ответа;
возможность определения Geo IP (требуется расширение);
запуск распределенных приложений (требуется плагин);
и многое другое — нужно читать документацию к конкретному web-серверу.
Также логику различных уведомлений или чата, подразумевающих использование push-технологий, можно реализовать в виде отдельного сервиса, сочетающегося с nginx и модулем nchan.
Часто практикуется совместное использование двух и более web-серверов, например, nginx + apache для решения проблемы с масштабированием нагрузки.
Для JavaScript-приложения иногда вообще достаточно модуля HTTP для Node.js, покрывающего все потребности клиентского приложения.
Тут же хочется упомянуть функциональность авторизации, который сам по себе тоже разумнее реализовать на отдельном сервере авторизации, а не на сервере, реализующем API. К серверу будут обращаться прочие сервисы, а не только клиентское приложение.
СУБД
Отдельно стоит выделить СУБД. Не стоит ограничиваться только одним типом СУБД — у каждой из них есть свои особенности и преимущества при использовании в тех или иных случаях. Для постоянного хранения данных, конечно, подойдет любая реляционная БД. Но для хранения той же очереди сообщений или кэширования данных разумно использовать, например, Redis. Для обработки большого объема данных, которые собираются из разных источников и не ложатся в одну структуру, можно попробовать использовать какую-либо документоориентированную СУБД (MongoDB). Существуют и другие типы СУБД, о преимуществах и особенностях которых следует узнать перед применением.
Также стоит отдельно упомянуть безграничные возможности шардинга БД (здесь уже напрашивается отдельная статья). Конечно, он напрямую зависит от шардингового ключа и шардингового алгоритма, но нужно хотя бы помнить об этой возможности.
Обмен данными
Еще одним отдельным элементом архитектуры можно выделить способ обмена данными. Не REST’ом единым жив человек :) Но стоит начать с глубин: сетевые протоколы (TCP, UDP, SSH, FTP, NTP) передачи данных — на них строятся комплексные протоколы более высокого уровня (HTTP, WebSocket, разные RPC, SOAP), а только потом следуют архитектурные стили (REST, GraphQL) и прочие технологии (SSE, WebRTC). Поэтому, выбирая способ обмена данными, нужно понимать, на чем основана та или иная технология, и какие главные возможности она предоставляет. И тогда окажется, что некоторые задачи можно решить на уровне web-сервера (конечно, используя дополнительные расширения), не нагружая backend- или frontend-приложения ни логикой, ни запросами. Таким примером может быть модуль определения геолокации для nginx.
Сторонние ресурсы
Для передачи документов и изображений лучше использовать CDN-сеть, а для их хранения можно написать нехитрый сервис, обеспечивающий формирование уникальных ссылок для каждого пользователя, а также авторизованный доступ, исключающий возможность получения доступа к ресурсам неавторизованным пользователям. Некоторые сервисы, например, Vimeo, предоставляют свою собственную CDN-сеть для передачи контента. Есть и более масштабные сервисы, такие как Cloudflare с NS-сервером, который служит для управления вашим трафиком.
Всё вышеперечисленное отвечает не только требованиям безопасности, но и требованиям высокопроизводительной архитектуры всего сайта, позволяющей грамотно и равномерно распределить роли и нагрузку.
Заключение
Итак, JS + ORM — это захватывающее приключение для всей команды! Пользуйтесь на здоровье!
А теперь серьезно. На основании проведенных мною опытов хочу отметить, что данное архитектурное решение (Node.js + ORM) совершенно точно годится для проектов с несложной структурой БД, таких, как MVP, лендингов, сайтов, CMS и других. Заказчики подобных систем преимущественно получат высокую скорость готовности уже первого релиза. Особенно если использовать фреймворки Nuxt.js/Next.js, порог вхождения в которые крайне низок.
Спасибо за внимание! Рекомендуем другие наши статьи по frontend:
Обзор ORM для C#: что подойдет для проекта
Разработка Angular-приложений и построение их архитектуры
Следим и вычисляем с Vue 3, или Как использовать watchEffect
Подписывайся на наши соцсети! Авторские материалы для frontend-разработчиков мы также публикуем в ВК и Telegram.
Комментарии (4)

Luchnik22
30.11.2022 11:01У нас схожий стек, однако для лендингов предпочитаем Typedream, для блога Hashnode, для других вещей nginx + CRA или Gatsby
В качестве протокола хорошо себя зарекомендовал Apollo (GraphQL) - скорость написания некоторых вещей ускорилась, особенно хорошо ложится на Prisma в связке NexusJS для генерации типизации и всего остального, однако мы отказались от Express в связи слабых бенчмарков и используем fastify

LabEG
30.11.2022 12:48У меня тоже есть небольшие проекты на стеке NextJS + ORM, и стек отрабатывает на все 100% даже в энтерпрайзе. Вот только рекомендую использовать не Prisma а TypeORM. Тем самым избавите себя от необходимости написания лишней абстракции. В TypeORM вы сразу описываете модель с логикой, по ней генерируется база и миграции. Так же из коробки получается репозиторий для сущности.

vasilyhertz
02.12.2022 13:36nuxt 3 конечно классно придумали. теперь типы dto можно писать один раз сразу для фронта и бэка.
Bone
Посмотрите на remix.run. Мне кажется сейчас это самый перспективный подход для такого рода задач.