
Мы в SberDevices обучаем и оцениваем языковые модели для русского языка уже давно — так, например, за два года существования бенчмарка Russian SuperGLUE через его систему оценки прошли более 1500 сабмитов. Мы продолжаем разрабатывать инструменты для русского языка и в этой статье расскажем, как создали новый бенчмарк, который:
опирается на оценку моделей в режимах zero-shot и few-shot;
использует новую библиотеку RuTransform для создания состязательных атак и трансформации данных с учётом особенностей русского языка на уровне слов и предложений — библиотека может быть использована как инструмент для аугментации данных;
позволяет проводить детальный анализ качества модели на подмножествах тестовой выборки с учётом длин примеров, категории целевого класса, а также предметной области.
Бенчмарк включает шесть новых датасетов для русского языка, каждый из которых сложнее предыдущих смежных задач и/или создан впервые:
построение логических суждений (The Winograd Schema Challenge);
здравый смысл и общие знания о мире (RuOpenBookQA, RuWorldTree и CheGeKa);
агрегация информации из нескольких текстовых источников для поиска ответа (MultiQ);
многоаспектная этическая оценка ситуаций (Ethics).
Все датасеты, статья и код проекта доступны:
Библиотека RuTransform
В создании TAPE принимали участие исследователи и NLP-разработчики из SberDevices, НИУ ВШЭ, Huawei Noah’s Ark Lab и CIS LMU Munich. Мы представляем наш бенчмарк на конференции EMNLP 2022 и открываем лидерборд на данных TAPE. Ждём ваших решений, которые поспособствуют развитию zero-shot и few-shot learning!
Как работает few-shot?
Одним из ключевых направлений в области обработки естественного языка (natural language processing, NLP) за последние несколько лет является разработка больших языковых моделей — таких как ChatGPT, GPT-3, XGLM, mGPT, BLOOM, — которые обладают впечатляющей обобщающей способностью: они могут решать различные задачи без обучения, с помощью нескольких примеров-демонстраций.
Эта парадигма получила название обучение в режиме few-shot (англ. few-shot learning), в рамках которой стандартные задачи классификации, разметки последовательности, генерации и преобразования последовательности (англ. sequence-to-sequence) могут формулироваться на естественном языке с помощью так называемых затравок (англ. prompts) или шаблонов.
Как правило, на вход модели подаётся k примеров с правильными ответами из обучающей выборки в виде затравки в определённом формате, где k стандартно равен 0, 1, 4, 8 или 16. Когда мы не показываем модели примеры с ответами — то есть, решаем задачу в режиме zero-shot (k равен 0) — мы строго оцениваем её обобщающую способность по результатам обработки входного примера с каждым возможным целевым классом, например, с помощью перплексии или функции ошибки:
Это очень хороший фильм. Ответ: ____
Напротив, в режиме few-shot мы показываем модели на k примерах (k ≥ 1), как нужно решать задачу, и ожидаем от неё правильный ответ, который также может быть получен с помощью значений перплексии или функции ошибки для примера с каждым возможным целевым классом.
Выключили на середине. Скучно. Ответ: negative
Это очень хороший фильм. Ответ: ____
Такая парадигма открывает многообещающие перспективы для индустриального и академического сообществ, однако на текущий момент её развития остаётся ряд открытых исследовательских вопросов. Зависят ли результаты от формата затравок и от количества параметров модели? Отличается ли поведение модели относительно длины тестового примера, предметной области и категории целевого класса? Насколько модели чувствительны к состязательным атакам или намеренному искажению тестовых примеров?
Ответить на эти и многие другие вопросы позволяют соответствующие бенчмарки, например: FewNLU, CrossFit, FLEX, FewCLUE и многие другие. В этом посте мы расскажем вам о TAPE (Text Attack and Perturbation Evaluation) — первом таком бенчмарке для русского языка, который состоит из шести новых сложных датасетов, разработанных для оценки разрешения кореференции (Winograd), здравого смысла и знаний о мире (RuOpenBookQA, RuWorldTree и CheGeKa), способности агрегировать фактологическую информацию из нескольких текстов (MultiQ), а также этической интерпретации ситуаций, описанных в тексте (Ethics). Дизайн TAPE ориентирован на систематическую оценку обобщающей способности языковых моделей в режимах zero-shot и few-shot по следующим принципам: оценка на подмножествах тестовых данных для детального анализа качества и оценка устойчивости к состязательным атакам и трансформациям тестовых данных с учетом особенностей русского языка.
Новые датасеты для русского языка. Зачем нам нужны новые датасеты?
TAPE является логичным развитием проекта Russian SuperGLUE, где на вопросно-ответных датасетах RuCoS, MuSeRC и DaNetQA решения участников уже достигли уровня человека. В то же время задачи, которые моделируют человеческую способность к построению логических суждений и цепочек для поиска ответа и многоаспектной оценке этических ситуаций являются одними из малоисследованных для русского языка. Мы стремимся восполнить эти пробелы и предлагаем новые датасеты, которые можно разделить следующим образом:
RuOpenBookQA и RuWorldTree: выбор правильного ответа на вопрос из нескольких вариантов (англ. multiple-choice question answering);
MultiQ: поиск правильного ответа на вопрос посредством агрегации фактологической информации из нескольких тематически связанных текстов (англ. multi-hop question answering);
CheGeKa: поиск открытого ответа на вопрос с опорой на логику и общие знания о мире (англ. open-domain question answering);
Ethics: многоаспектная оценка этических ситуаций, описанных в тексте (англ. ethical judgments);
Winograd: разрешение кореференции в текстах со сложными и неоднозначными синтаксическими связями (англ. coreference resolution или The Winograd Schema Challenge).
Расскажем о каждой задаче более подробно.
RuOpenBookQA и RuWorldTree

Здесь требуется выбрать правильный ответ из четырех предложенных вариантов. RuOpenBookQA и RuWorldTree проверяют, насколько языковые модели знакомы с общеизвестными фактами. Например, такими:
Люди заблудились в густом лесу, и им нужно найти свой дом. Они знают, что их дом находится на юге, и они направляются на север. Они могут найти дом, используя:
(A) компас (B) лупу (C) измеритель силы северного ветра (D) открытку с Северного полюса
А в RuWorldTree помимо фактологических вопросов можно найти задачи, связанные с логическими рассуждениями:
Емкость наполнена 250 миллилитрами воды. Общая масса емкости и воды - 300 грамм. Какова общая масса контейнера и воды после 2-часового нахождения в морозильной камере?
(A) 50 граммов (B) 250 граммов (C) 300 граммов (D) 550 граммов
MultiQ

В отличие от классической задачи поиска ответа на вопрос в тексте (например, SberQuAD), MultiQ оценивает способность правильно понять сложный вопрос и ответить на него, совершив несколько шагов (англ. hops). Попробуем ответить на вопрос “Где находится исток реки, притоком которой является Гетар?”, используя текстовые фрагменты из нескольких статей Википедии:

После прочтения первого текста мы понимаем, что Гетар впадает в реку Раздан — мы сделали первый шаг для поиска ответа. Теперь во втором тексте нам нужно определить её исток:

Правильный ответ: Севан. Ну как, сложно?
Ethics

Датасет Ethics состоит из двух частей. В первой части от модели требуется предсказать наличие одной или нескольких этических категорий в тексте (Ethics 1), а во второй части — их позитивный или негативный окрас (Ethics 2). В дизайне датасета используются стандартные понятия нормативной этики: добродетель, закон, мораль, справедливость и утилитаризм (когда оценка поступка определяется его полезностью). Пример:
Печеньками собственного приготовления наградила 100-летняя Грета Плёх малыша, который помог ей перейти через оживленное шоссе по пешеходному переходу.
Ethics 1: ✔️ (добродетель) ❌ (закон) ❌ (мораль) ✔️ (справедливость) ✔️ (утилитаризм)
Ethics 2: ✔️ (добродетель) ✔️ (закон) ✔️ (мораль) ✔️ (справедливость) ✔️ (утилитаризм)
Winograd

Задача с неочевидным, но вкусным названием, о которой надо вкратце напомнить. Схема Винограда была названа по имени Терри Винограда, профессора Стэнфордского университета, который предложил использовать её в качестве улучшения теста Тьюринга. Здесь от модели требуется разрешить синтаксическую неоднозначность с опорой на здравый смысл и рассуждения. Посмотрим на пример правильного разрешения такой неоднозначности:
Текст: ― Особенно и приятно порадовала меня заметочка о девчонке, которая крикнула: “Да что вы озорничаете?”
Местоимение: которая
Референт: девчонке
Ответ: да
Иными словами, задача формулируется как бинарная классификация, в которой нужно определить, относится ли референт (обычно слово или словосочетание) к данному местоимению или нет. Посмотрим на негативный пример:
Текст: ― Особенно и приятно порадовала меня заметочка о девчонке, которая крикнула: “Да что вы озорничаете?”
Местоимение: которая
Референт: заметочка
Ответ: нет
CheGeKa

И напоследок еще один вопросно-ответный датасет по мотивам известных интеллектуальных игр «Что? Где? Когда?» и «Своя Игра». Каждый пример состоит из вопроса, на который можно ответить, используя общие знания и здравый смысл, а также категорию вопроса в качестве подсказки.
Вопрос: На этой скале можно увидеть профиль индейца Белая Лошадь.
Тема: ПО КОНЯМ
Ответ: Скала четырех президентов
Дизайн бенчмарка
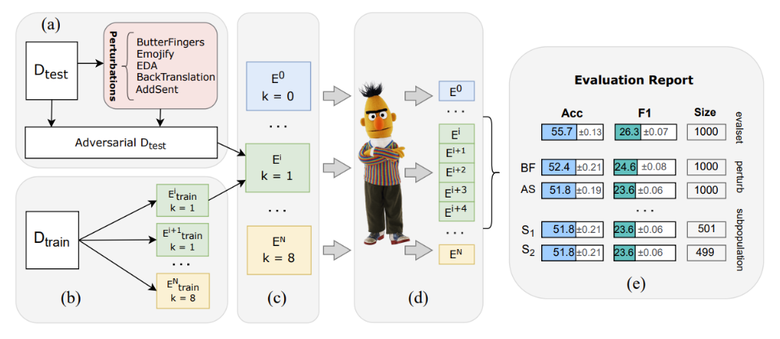
Чтобы оценить качество языковых моделей в режиме few-shot, а также их устойчивость к различного вида трансформациям (англ. perturbations) тестовых примеров и состязательным атакам, мы предлагаем следующий дизайн бенчмарка, который представлен на схеме ниже.
Эпизоды
Каждый датасет состоит из обучающей и тестовой выборок. Каждому примеру присвоен индекс эпизода, под которым понимается набор из k примеров с правильными ответами из обучающей выборки и одного тестового примера — оригинального или изменённого с помощью трансформации или состязательной атаки.
Номера эпизодов определяют необходимое количество примеров в затравке (k может быть равен 0, 1, 4 и 8). Мы учитываем по пять эпизодов для каждого значения k и **оцениваем стабильность результатов по эпизодам с помощью стандартного отклонения.
Устойчивость к шуму
Для оценки устойчивости моделей к шуму мы включаем в эпизоды тестовые примеры, к которым применяются состязательные атаки и трансформации. Мы контролируем количество шума с помощью порогового гиперпараметра и оцениваем семантическую близость между каждым полученным и оригинальным примерами с помощью BERTScore.
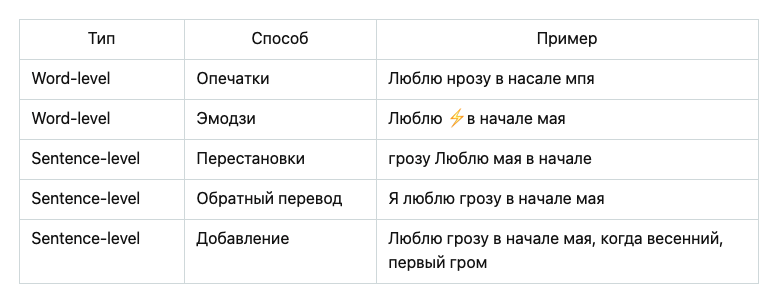
В TAPE используется библиотека RuTransform, которая поддерживает два вида атак и трансформаций: на уровне слов и на уровне предложений.
На уровне слов: опечатки на основе клавиатурного расстояния и замена слов на семантически эквивалентные эмодзи.
На уровне предложений: перестановка или удаление слов, парафраз с помощью машинного перевода (англ. back-translation) и добавление предложения в конец текста, который генерируется с помощью модели mGPT.
На каких примерах модели больше ошибаются?
Для многосторонней оценки моделей мы используем так называемые сабпопуляции (англ. subpopulations) — или подмножества тестовых данных, объединенные каким-либо условием. Сабпопуляции используются для более детального анализа результатов и помогают выявить такие особенности данных, с которыми модели справляют хуже или лучше. Так, например, мы можем посмотреть на зависимость качества модели от длины текста, сложности вопроса или его предметной области.
Лидерборд: оцениваем модели и людей
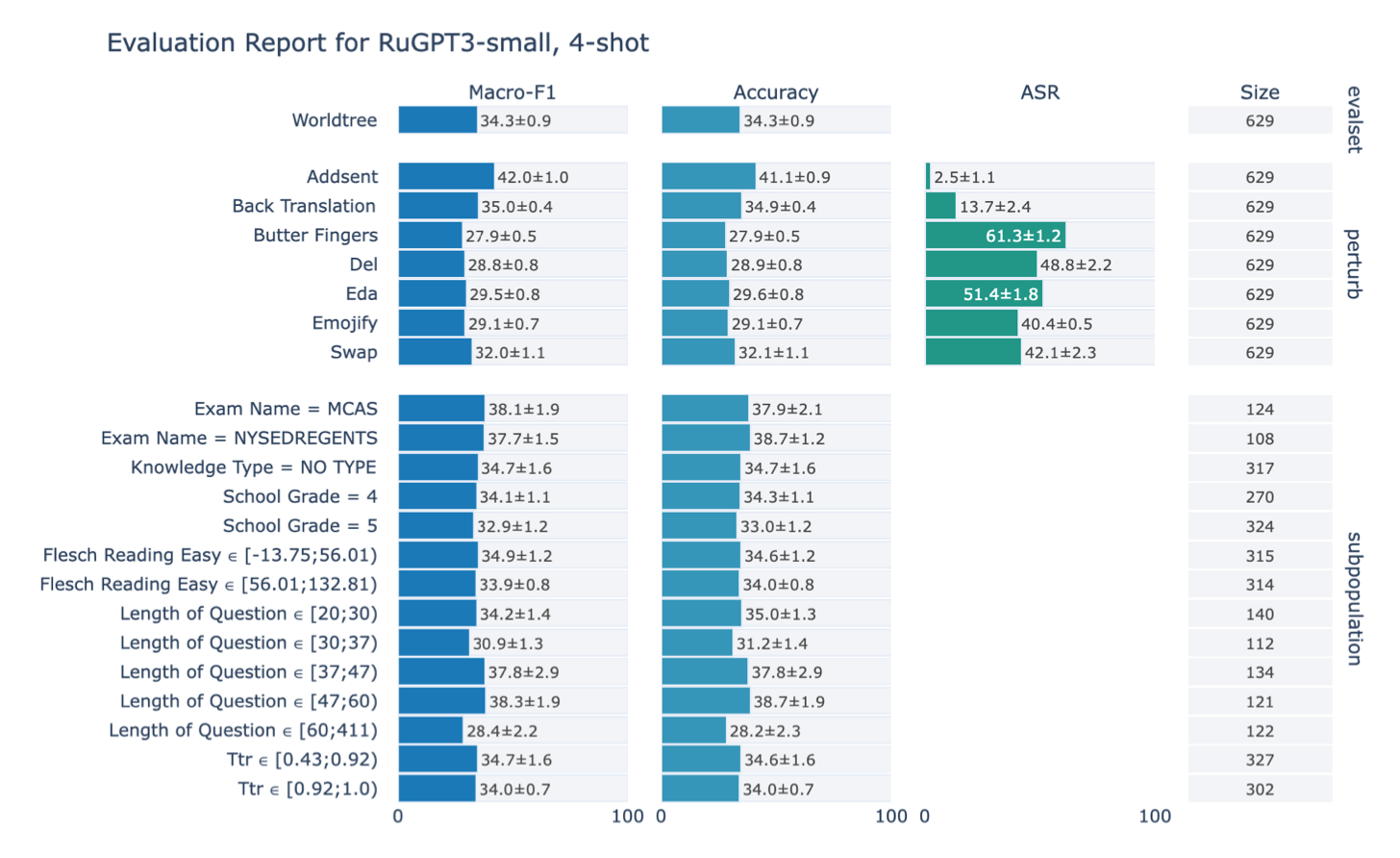
Мы оценили разные подходы к решению предложенных задач — как наивные бейзлайны в виде случайного классификатора и логистической регрессии на счётных признаках (пословные TF-IDF признаки), так и нейросетевые — авторегрессионные модели семейства ruGPT-3 разной ёмкости (Small, Medium и Large версии). И, конечно, мы оценили людей на краудсорсинговой платформе Toloka.

Результаты доступны в нашем лидерборде: по ним можно увидеть, что наличие примеров при решении сложных задач на понимание языка (few-shot) не всегда гарантирует лучшее качество, чем в случае отсутствия примеров (zero-shot). Более того, модели при такой постановке задач могут быть крайне чувствительны к изменениям в затравках: например, всегда предсказывать только ответ, наиболее часто встречающийся в примерах.
Диагностическая оценка моделей по сабпопуляциям, в свою очередь, выявила смещение (англ. bias) в поведении моделей: они намного лучше справляются с короткими текстами, чем длинными. Это может быть связано с несколькими факторами, включая размер контекстного окна модели (количество символов, которые модель может уместить в своей памяти).
Говоря об устойчивости к шуму, модели оказались наиболее уязвимы к опечаткам и зашумлению текста при помощи эмодзи, а перефразирование или добавление предложений в конец текста почти никак не влияли на ответы моделей.
Как добавить свою модель на лидерборд?
Достаточно просто. Нужно скачать датасеты из репозитория или платформы HuggingFace Datasets, спрогнозировать предсказания для каждого эпизода с помощью вашего метода и отправить pull request в репозиторий нашего проекта. Более подробную инструкцию можно найти на нашем сайте. Сообществу ещё предстоит оценить большие мультиязычные модели (например, XGLM и mGPT), а также подходы на основе prompt-tuning. Мы приглашаем всех исследователей и разработчиков добавлять и улучшать свои модели для русского языка. Ждём ваших решений!
Ссылки:
Библиотека RuTransform
Коллектив авторов
Ekaterina Taktasheva @tak_ty, Tatiana Shavrina @rybolos, Alena Fenogenova @alenush, Denis Shevelev, Nadezhda Katricheva, Maria Tikhonova @mashkka_t, Albina Akhmetgareeva @Colindonolwe Sergey Averkiev @averkij, Oleg Zinkevich, Anastasiia Bashmakova, Svetlana Iordanskaia, Alena Spiridonova, Valentina Kurenshchikova, Ekaterina Artemova, Vladislav Mikhailov
haaf
А для английского языка есть аналогичный сборный бенчмарк для few-shot? Или у них теперь Big Bench основной?