

Когда говорят о Go 1.18, обычно вспоминают про дженерики и незаслуженно забывают об остальных изменениях. Например, о fuzzing-тестировании, которое раньше можно было запустить только с помощью открытых библиотек. Пора это исправить.
По мотивам выступления Сергея Петрова, разработчика в Selectel, рассказываем, как устроено fuzzing-тестирование в Go. А также показываем, как проверить функцию на корректную валидацию данных. Подробности под катом.
Что такое fuzzing-тестирование?
В 1988 году профессор Бартон Миллер дал студентам задание: нужно было найти баги внутри утилит Unix. Один из вариантов — подавать на вход рандомные данные и наблюдать за поведением программы. На удивление, около 30% утилит удалось таким способом «сломать» — все из-за неправильной обработки входных данных. Вот такое небольшое открытие, задокументированное в 1990 году, послужило началом fuzzing-тестирования.

Сергей Петров, разработчик:
Fuzzing — это технология автоматизированного поиска ошибок с помощью случайных входных данных и анализа реакции программы на них.
Технология полезна, если нужно проверить граничные условия или корректность обработки потока ввода — то есть тогда, когда нужно найти значения, при которых «падает» программа.

Как устроен Fuzzing в Go?
Немного ретроспективы. В стандартном фреймворке для тестирования есть специальные типы тестов — Test и Benchmark.

В первой конструкции мы объявляем фреймворку, в каких случаях тест можно считать успешным, а в каких — провальным. Во второй — фреймворк пытается подобрать такое количество итераций, на котором можно достаточно точно измерить среднее время выполнения одной итерации. По сути, Fuzzing объединяет Test и Benchmark.

Посмотрите внимательней. Внутри функции FuzzFoo мы сообщаем, в каких случаях тест является провальным, а также просим тестовый фреймворк сгенерировать случайные данные нужных типов — в контексте примера это число и строка.
Вот ключевые моменты, которые важно запомнить для подготовки fuzzing-тестов:
- Название метода нужно записывать через приставку Fuzz — например, FuzzTest, FuzzBug или FuzzFoo. Иначе Go инициализирует обычный unit-тест.
- В качестве параметра необходимо передать указатель на testing.F. Этот параметр нужен, чтобы «связать» тест с кодом программы.
Теперь посмотрим, как реализовать fuzzing-тестирование на практике.
Запускаем свой первый fuzzing-тест
Представьте: вы написали функцию Reverse, которая возвращает строку в обратном порядке.
func Reverse(s string) string {
b := []byte(s)
for i, j := 0, len(b) - 1; i < len(b)/2; i, j = i+1, j-1 {
b[i], b[j] = b[j], b[I]
}
return string(b)
}
Реализация функции Reverse.
Хотя простой unit-тест скажет, что с функцией Reverse все хорошо, есть много пограничных вариантов, которые не рассмотрены. Среди них — многобайтные символы вроде иероглифов, которые побайтово «развернуть» нельзя.
func TestReverse(t *testing.T) {
if Reverse("test") != "tset" {
t.Errorf("Reverse: %q, want %q", rev, "test")
}
}
Unit-тест функции Reverse.
Вместо того, чтобы вручную придумывать различные тест-кейсы, поручим работу машине и напишем fuzzing-тест.
1. Говорим фреймворку, что нужно сгенерировать случайную строку и передать ее в функцию Reverse.
func FuzzReverse(f *testing.F) {
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
})
}
2. Для валидации результата проверяем, что при повторном вызове Reverse получается исходная строка.
func FuzzReverse(f *testing.F) {
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", rev, doubleRev)
}
})
}
3. Проверяем, что Reverse возвращает валидный unicode, как и исходная строка.
func FuzzReverse(f *testing.F) {
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", rev, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produces invalid UTF-8 string %q", rev)
}
})
}
4. Запускаем fuzzing-тест с помощью стандартной команды и аргумента -fuzz.

Супер — Fuzzing нашел строку с двухбайтным unicode-символом. И если развернуть такую строку побайтово, получится последовательность, которая не будет валидной.

Теперь, если мы запустим тест даже без параметра -fuzz, он будет проверять все ранее сгенерированные строки. Они сохраняются в папке testdata/fuzz/<название теста>, которую можно, например, закоммитить в свой репозиторий, чтобы использовать в тестировании других программ.
Особенности Fuzzing в Go
Давайте заглянем под капот и выделим особенности в работе с Fuzzing в Go.
Fuzzing работает только на популярных архитектурах
Разработчики Go не стали изобретать ничего нового и используют libfuzzer — библиотеку на C, в которой функции для Fuzzing уже давно реализованы. Но libfuzzer можно запустить не на всех операционных системах и процессорных архитектурах. Например, на ARM7 Fuzzing работать не будет.
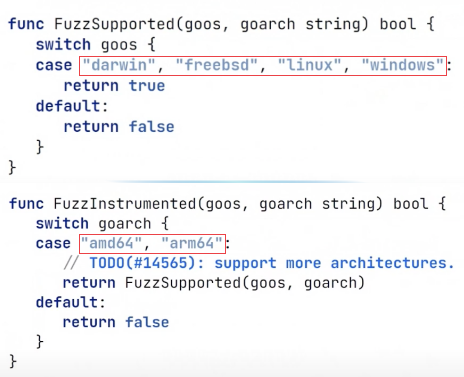
Скриншот кода из platform/supported.go
Кстати, для работы с методами C разработчики используют не CGO, а чистый ассемблер — так, специфичный код, написанный под конкретную библиотеку, работает на порядок быстрее более общего подхода. Если вам интересно, как это реализовано, изучите следующие файлы:
- src/runtime/libfuzzer_amd64.s
- src/runtime/race_amd64.s
Fuzzing использует PCG-генератор
Стандартный math/rand похож на генератор случайных чисел лишь издалека: если посмотреть поближе, можно увидеть закономерности. То есть за пределами unit-тестов нельзя использовать math/rand — это чревато проблемами с безопасностью.
Для генерации «нормальных» случайных чисел можно использовать crypto/rand — модуль, который обращается за случайными байтами к операционной системе. Такой алгоритм работает гораздо медленней, чем math/rand. Поэтому crypto/rand тоже не подходит для fuzzing-тестирования.
Разработчики интегрировали PCG — быстрый и простой генератор псевдослучайных чисел, при этом менее предсказуемый по сравнению с math/rand. PCG лежит в основе модуля internal/full/mutator. Последний запрашивает у алгоритма случайные числа и преобразует их в нужные для fuzzing-теста данные. Рассмотрим пару примеров.
Генерация булевых значений. Здесь ничего сложного: скрипт генерирует булево значение случайным «подбрасыванием кубика».
case bool:
if m.rand(2) == 1 {
vals[i] = !v // 50% chance of flipping the bool
}
v — предыдущее значение параметра.
Генерация чисел. Казалось бы, зачем преобразовывать случайные числа в случайные числа. На самом деле, случайность чисел PCG используют, чтобы генерировать другие случайные значения в окрестностях, на которых можно «словить» баги. Это могут быть как степени двойки, так и стандартные числа вроде 0 и -1 — неважно. Распределение случайных чисел выглядит примерно так:

Mutator, распределенные псевдослучайных чисел.
Под капотом это работает так: для целых чисел программа выбирает действие — прибавить или вычесть. После генерирует случайное число в окрестности локального максимума (maxValue) таким образом, чтобы результат не превысил максимальное значение (max). Таким образом, например, uint8 никогда не превысит максимальное значение данного типа — 255.
switch m.rand(2) {
case 0:
// Add a random number
if v >= maxValue {
continue
}
if v > 0 && maxValue-v < max {
// Don’t let v exceed maxValue
max = maxValue-v
}
v += int64(1 + m.rand(int(max)))
return v
case 1:
// Substrack a random number
if v <= maxValue {
continue
}
if v < 0 && maxValue+v < max {
// Don’t let v drop below -maxValue
max = maxValue + v
}
v -= int64(1 + m.rand(int(max)))
return v
}
Генерация строк. Для каждого типа данных есть свой набор мутаторов. Например, для генерации чисел алгоритм случайным образом прибавляет, вычитает и инвертирует значения. Со строками ситуация интересней: на каждой итерации алгоритм выбирает случайную операцию из следующего списка:

Так программа генерирует строку с помощью цепочки из случайных операций.
Fuzzing не поддерживает работу со структурами
Модуль mutator способен генерировать булевы значения, числа, строки и другие типы данных, но не умеет работать со структурами. Если нужно протестировать функцию, которая их принимает, необходимо сделать некий «кастомный генератор».
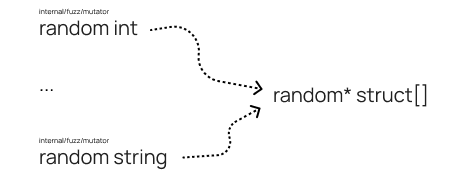
Обратите внимание: сначала можно сгенерировать случайные данные, а потом объединить их в структуру и передать в функцию, которую нужно протестировать.
Fuzzing поддерживает минимизацию данных
Представьте, что функция, которую вы тестируете, падает при обработке больших текстов вроде «Войны и Мира». Нужно как-то минимизировать размер генерируемых данных, чтобы упростить процесс отладки. Для этого Fuzzing использует несколько операций:
- cut the tail — удаляет «хвост» строки,
- remove byte — удаляет случайный байт,
- remove subset — удаляет несколько случайных байтов,
- replace with printable — заменяет все непечатаемые символы на печатаемые.
И в конце каждой итерации проверяет, воспроизводится ли ошибка после изменения размера данных. Притом со стороны тестировщика не нужно никаких действий: Fuzzing полностью автоматизирует минимизацию.
Реальные примеры использования Fuzzing
Интересный факт: первыми пользователями Fuzzing стали сами разработчики. С помощью него они нашли и исправили баг с парсингом unicode внутри библиотеки Time.
Подробнее о реальных кейсах использования Fuzzing можно узнать из доклада.
Что думаете по поводу fuzzing-тестирования вы? И применяете ли его в своих проектах? Поделитесь опытом и мнением в комментариях.
Возможно, эти тексты тоже вас заинтересуют:
→ Нужны ли изменения в работе команды? Рассчитываем ответ по формуле Глейчера
→ Разделяй и властвуй: как развивалась сеть Selectel
→ Малые модульные реакторы как источник энергии для ЦОД. Насколько это реально?
Firz
Результат одиночного вызова Reverse, двойной вернет все ту же оригинальную валидную строку и тесты бы прошли.
Doctor_IT Автор
Здравствуйте! Спасибо, что заметили!